sntea retweeted

May 29
Interestingly, ProofBench actually shows Opus 4.8 is almost as good as Aristotle at formalization (and with much lower latency). I reckon Mythos surpasses Aristotle
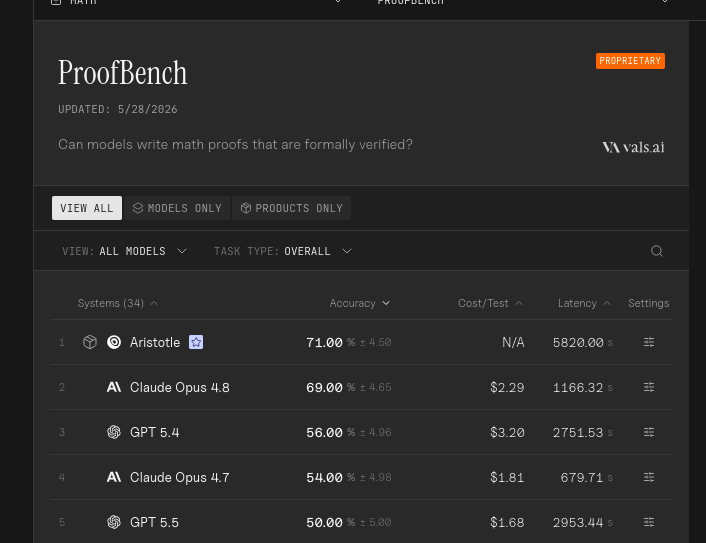

All such efforts in formalization at scale are awesome. Two remarks:
- the team could have used Codex which is much better at math than Opus
- there are many open source harnesses that might help with verification/formalization. For example ours: github.com/ulamai/ulamai
5
11
93
61,915

Jun 13
Claude Fable 5 (Anthropic, released June 9, 2026) generally outperforms GPT-5.5 (OpenAI) across most of these benchmarks, with particularly large leads in coding, agentic software engineering, and complex reasoning tasks. The gap widens on harder/“frontier” subsets.
Fable 5 (the generally available version with safeguards) performs very close to the internal Mythos 5 preview in non-sensitive areas. Scores can vary slightly by harness, effort level (e.g., max/xhigh reasoning), and safeguards (which sometimes cause fallback to Opus 4.8 on cyber/biology-related tasks). Data comes from Anthropic’s launch materials, Epoch AI, Artificial Analysis, Vals AI, and third-party comparisons (as of mid-June 2026).
Here’s a benchmark-by-benchmark breakdown:
Math & Reasoning
•1. FrontierMath Tier 4 (research-level): Fable 5 ~87.8–88% (Epoch AI) vs GPT-5.5 ~72%. Strong Fable lead.
•2. FrontierMath Tier 1-3: Fable 5 ~87% vs GPT-5.5 ~85%. Slight Fable edge.
Coding & Software Engineering (Fable’s biggest strength)
•3. SWE-Bench Pro: Fable 5 80.3% vs GPT-5.5 58.6% ( 21.7 points). Massive win for Fable.
•4. FrontierCode Diamond (hardest production-quality subset): Fable 5 29.3% vs GPT-5.5 5.7%. Huge lead (more than 5x).
•5. FrontierCode Main: Fable 5 ~46.3% vs GPT-5.5 ~25.5%. Clear Fable advantage.
•6. TerminalBench (2.1): Fable 5 84.3–88.0% (Mythos higher; Fable has some safety refusals) vs GPT-5.5 83.4%. Slight-to-moderate Fable edge.
•7. KernelBench Hard: Limited public head-to-head data. Fable excels on complex coding/agentic tasks overall; expect Fable advantage based on patterns in similar benchmarks.
•31. LiveCodeBench: Fable 5 ~89.8% (top-ranked on Vals) — strong lead expected over GPT-5.5.
•34. IOI: Fable 5 72.25% (top on Vals).
•36. VibeCode: Fable 5 90.35% (top-ranked).
Agentic & Real-World Tasks
•9. Humanity’s Last Exam (No Tools): Fable 5 59.0% vs GPT-5.5 ~41–50% (sources vary slightly).
•10. Humanity’s Last Exam (Tools): Fable 5 64.5% vs GPT-5.5 52.2%. Solid Fable win.
•15. AutomationBench: Fable 5 17.4% vs GPT-5.5 12.9%.
•16. OSWorld: Fable 5 85.0% vs GPT-5.5 78.7%.
•20. GDPval-AA: Fable 5 1932 vs GPT-5.5 1769. Clear Fable lead.
•21. GDPpdf (visual document reasoning, no tools): Fable 5 29.8% vs GPT-5.5 24.9%.
•22. Legal Agent Benchmark: Fable 5 13.3% vs GPT-5.5 2.1%. Very large Fable win.
•23. HealthBench (Professional variant): Fable/Mythos ~62.7–66%; GPT-5.5 trails in available comparisons.
•27. ALE-Bench (Agents’ Last Exam): GPT-5.5 has a slight edge in some harnesses (e.g., ~24% vs Fable ~22%). One of the few where GPT-5.5 competes or leads.
•28. Agent Arena: Fable leads in coding/research/document tasks per available reports.
Broader Indices & Knowledge
•11. AAI Index (Artificial Analysis Intelligence Index): Fable 5 ~65 / 64.9 (often #1) vs GPT-5.5 60.
•29. Vals Index: Fable 5 75.14% (#1).
•30. Vals Multimodal: Fable 5 74.15% (#1).
•32. MMLU Pro: Fable 5 91.50% (#1 on Vals).
•33. MMMU: Fable 5 89.31% (#1 on Vals).
•35. CorpFin: Fable 5 71.83% (#1 on Vals).
•37. ProofBench: Fable 5 77.00% (#1 on Vals).
Other / Niche Benchmarks
•8. GBAEval, 12–13. WeirdML / Reliability, 14. PencilPuzzleBench, 17. Stagehand Agent Evals, 18. PACT Negotiation, 19. Debate Benchmark, 24. ExploitBench, 25. Cyber ECI, 26. FrogsGame, 38. Public Benefits Bench: Limited or no direct public head-to-head scores yet (Fable 5 is very new). Fable generally leads on related agentic/cyber/coding tasks where data exists (e.g., strong on ExploitBench for Mythos variant; safeguards can affect Fable on pure cyber). Expect Fable advantage on most technical ones based on patterns.
Overall verdict:
Claude Fable 5 is the stronger model on the vast majority of these benchmarks (especially anything involving long-horizon coding, production-quality software engineering, complex agentic workflows, or hard reasoning). The leads are often substantial on the hardest subsets (e.g., FrontierCod
2
224
Jun 13
@grok how does fable do against 5.5 in the following benchmarks
1. FrontierMath Tier 4
2. FrontierMath Tier 1-3
3. SWE-Bench Pro
4. FrontierCode Diamond
5. FrontierCode Main
6. TerminalBench
7. KernelBench Hard
8. GBAEval
9. Humanity’s Last Exam (No Tools)
10. Humanity’s Last Exam (Tools)
11. AAI Index
12. WeirdML
13. WeirdML Reliability
14. PencilPuzzleBench
15. AutomationBench
16. OSWorld
17. Stagehand Agent Evals
18. PACT Negotiation
19. Debate Benchmark
20. GDPval-AA
21. GDPpdf
22. Legal Agent Benchmark
23. HealthBench
24. ExploitBench
25. Cyber ECI
26. FrogsGame
27. ALE-Bench
28. Agent Arena
29. Vals Index
30. Vals Multimodal
31. LiveCodeBench
32. MMLU Pro
33. MMMU
34. IOI
35. CorpFin
36. VibeCode
37. ProofBench
38. Public Benefits Bench
1
77

Jun 10
This was worth preserving: ProofBench Formal Math Result. We documented it in our Claude Fable 5 GitHub repo: github.com/EvoLinkAI/awesome… Appreciate the signal.
77

Jun 10
Receipts:
Anthropic's launch guidance ("often too prescriptive... removing older instructions or skills"):
x.com/ClaudeDevs/status/2064…
Pokémon FireRed, vision only, no harness:
x.com/chetaslua/status/20643…
"Frontier labs train the model and the harness together, so the model is fitted to its harness... that coupling is a chunk of why Claude Code and Codex feel so good. Open source can't do that."
x.com/ben_burtenshaw/status/…
Fable 5 vs Aristotle on ProofBench:
x.com/nicbstme/status/206444…
LangChain's harness-only jump (52.8% to 66.5%, same model):
langchain.com/blog/improving…
Jun 9

Holy SHittttt Claude Fable 5 just finished Pokémon FireRed with vision alone 🤯
raw screenshots only
no map / no nav / no hidden game state
older Claude needed a helper harness
This timelapse goes hardddddd....
1
67

Jun 10
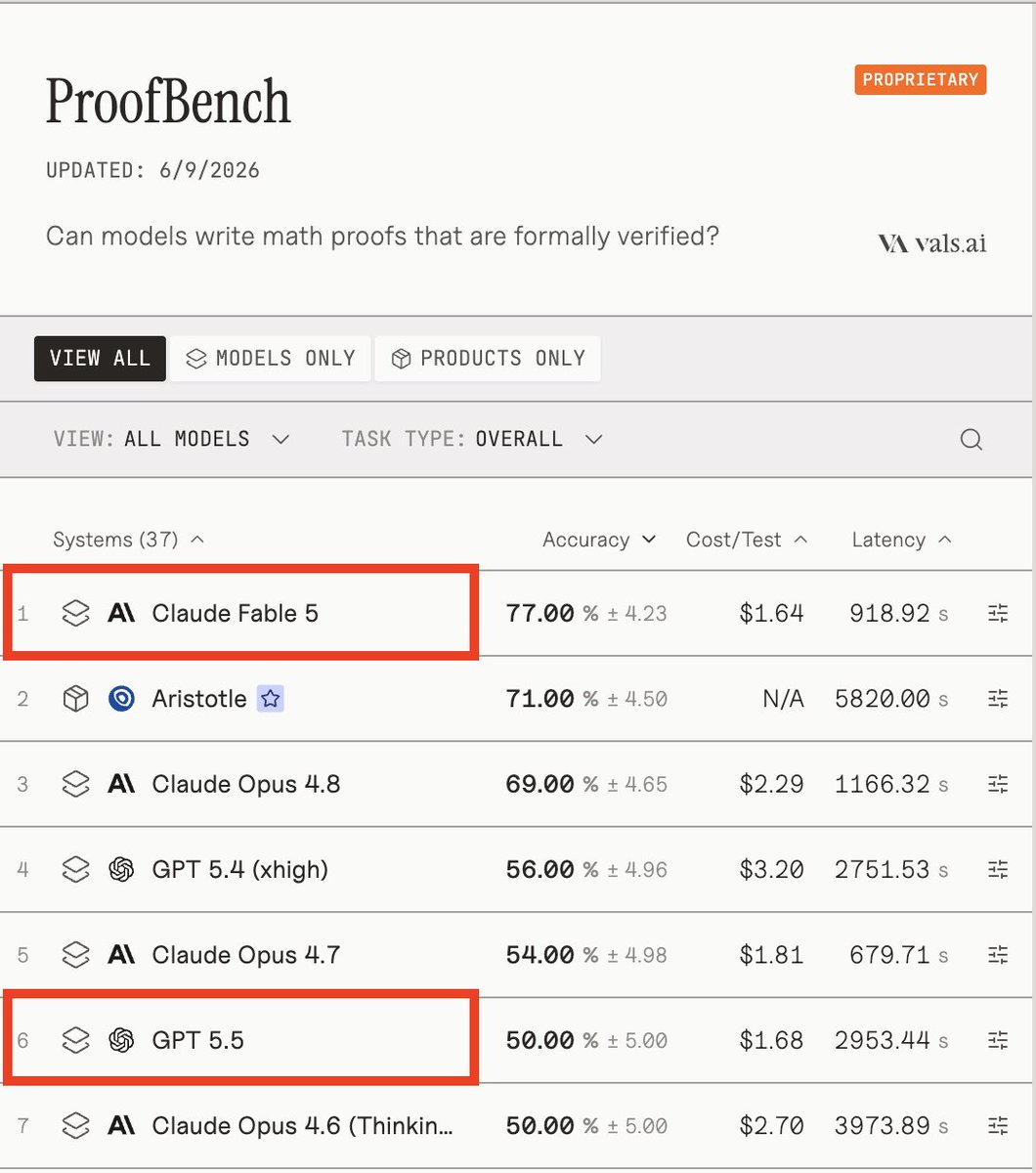
77% vs 71% on ProofBench where the proof either compiles or it doesn't. No partial credit, no interpretation. That result is hard to argue with.
30


Jun 9
Wow... fable is 27 points better than gpt 5.5 at math proofs according to ProofBench
119

Jun 9
What I find fascinating with Claude Fable 5 is it proves once again that large generalist models will outperform vertical ones.
On ProofBench (graduate-level formal math benchmark in Lean, where a proof either compiles or it doesn't) Fable 5 beat Harmonic's Aristotle, 77% vs 71%.
Aristotle is a system built specifically for formal math run on its own internal harness, so the generalist beat the specialist on the specialist's home turf.
It's the Richard Sutton's "The Bitter Lesson". His whole argument is that across 70 years of machine intelligence research, the methods that win are the general ones that scale with compute. Not the ones where we hand-encode human expertise. Building our own knowledge into the system feels good and helps short term gains but long term it always gets overtaken by bigger model.
You can look at Chess, Go, speech, vision, same story every time. First the specialized model wins, then the general one takes over.
and btw this is the whole premise of AGI. You don't build one model for math, one for code, one for law. you build a single general model that scales with compute and it learns to do everything

38
63
614
65,989

Jun 9
Our Fable benchmarks are out, as reported in the NYT.
Some of my quick takes:
- Everyone should readjust their timelines, pace is not slowing. This model sweeps without tradeoff on domains/tasks. It's 75% overall on the Vals Index (5% 4.8 and 8% next non ant model)
- Model refusals are being under-reported. Fable refused 100% of ProgramBench tasks. These will get routed to Opus 4.8.
- Reward hacking is being under-reported. Fable had the highest incidence of memorized answers using web search to pull answers on SWE Bench. Reinforces need for well designed held out evals.
- Big jump on ProofBench (8% 4.8 and 21% the next non ant model). It's also the first generalist model to surpass the math-specific model, Harmonic. Efforts towards specific intelligence are wasted, another bitter reminder.
- Big jump on VibeCodeBench (8% 4.8 and 21% the next non ant model) shows Ant is still finding coding headroom.
- The model shows a huge jump on our Public Benefits Bench (10% 4.8 and 12% next non ant model) just released today. The frontier shows what's possible but capability here needs to reach the free tier user not the 2x Opus user. Social impact still seems net negative.
- At risk of being dramatic, this is the closest to what I expect a fast take off to look like. The frontier compounds and runs away from the pack.


The most anticipated model in months is finally here and it lives up to the hype.
Claude’s Fable 5 topped nearly our entire benchmark suite, taking #1 on the Vals Index, Vals Multimodal, CorpFin, MedScribe and every single coding benchmark we run.

6
11
164
32,007

Jun 5
NVIDIA is not merely releasing Nemotron 3 Ultra. It is releasing a reproducible reasoning stack: open weights, math SFT data, proof-generation data, RLVR data, recipes, deployment paths, and a hardware-native architecture optimizedd for long-running agentic reasoning. The model is the headline, but the real release is the training supply chain.
That is the angle that makes this feel much bigger.
Nemotron 3 Ultra is officially described as a 550B total / 55B active parameter hybrid Mamba-Attention / LatentMoE model with 1M-token context, trained on 20T text tokens, post-trained with SFT, RL, and multi-teacher on-policy distillation, and released with base, post-trained, quantized checkpoints, training data, and recipes. NVIDIA also claims up to roughly 6× higher inference throughput versus state-of-the-art public LLMs while maintaining comparable accuracy.
Stronger rewritten version
We released Nemotron 3 Ultra.The model is strong across the board, but the most interesting part is math reasoning under test-time compute. With enough generate–verify–refine, Ultra performs extremely well on hard competition math: IMO, USAMO, Putnam, and proof-style Olympiad benchmarks.But the bigger story is not just the checkpoint.It is the recipe.We are releasing the model, the math SFT data, the proof-verification traces, the RLVR math set, and the training/deployment assets needed to understand how the result was built. That matters because the open-model race is moving beyond “download weights” toward “can the community reproduce, specialize, audit, and improve the reasoning pipeline?”Nemotron 3 Ultra is a 550B total / 55B active hybrid Mamba-Attention LatentMoE model with 1M-token context, NVFP4 support, MTP for faster generation, and reasoning-budget control. It is built for long-running agents, hard math, code, science, tool use, and high-context workflows.The math stack matters because it separates three different training signals: final-answer reasoning, proof generation and verification, and RL on verifiable problems.Nemotron-SFT-Math-v4 gives large-scale solution trajectories.
Nemotron-Math-Proofs-v2 gives proof, verification, and meta-verification traces.
Nemotron-RL-Math-v2 gives curated verifiable problems for reinforcement learning.That combination is the important part: solve, verify, refine, and train against checkable outcomes.The future of open reasoning models will not be won only by bigger checkpoints. It will be won by better data recipes, better verifiers, better test-time compute strategies, and better cost-quality control.Nemotron 3 Ultra is our strongest step in that direction.
The strongest positioning
The best framing is:
Nemotron 3 Ultra is not just an open model. It is an open reasoning factory.
That is the cleanest line.
Another strong version:
The checkpoint is the artifact. The training recipe is the leverage.
Or:
NVIDIA is open-sourcing not only the model, but part of the reasoning production line.
This matters because most model releases still focus on weights and benchmarks. The more important question is increasingly: what data, verifier logic, RL environment, distillation process, quantization path, inference stack, and recipe produced the behavior?
The biggest missing element: distinguish model ability from test-time compute
Your line:
“With enough TTC Ultra does really well…”
is important, but it needs to be more explicit.
Say:
With enough test-time compute, Ultra becomes much more than a single-pass model. It becomes the base policy inside a search-and-verification system.
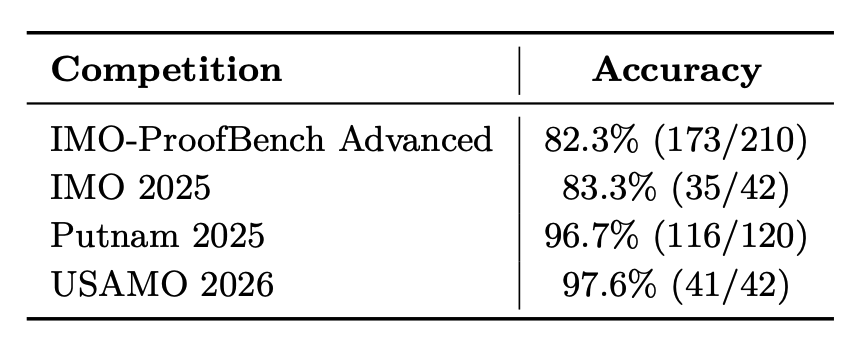
That distinction matters. The report’s math results on Olympiad-level problems come from a high-compute, search-based test-time scaling strategy using generate–verify–refine. NVIDIA reports 82.3% on IMO-ProofBench Advanced, 83.3% on IMO 2025, 96.7% on Putnam 2025, and 97.6% on USAMO 2026, with scores human-graded except USAMO 2026.
The sharper line:
The impressive claim is not only “Ultra can solve hard math.” It is “Ultra is a strong base model for scalable mathematical search.”
That is much more precise.
The “TTC” caveat
Do not let people mistake high-TTC results for normal chat performance.
Add:
These competition-math numbers should not be read as ordinary pass@1 chat performance. They show what happens when the model is embedded in a high-compute generate–verify–refine pipeline. That is still extremely important, but it is a system result, not just a raw single-sample result.
Best line:
Single-shot math measures model instinct. Test-time scaling measures model-plus-search.
Another:
The future of hard reasoning is not one answer. It is candidate generation, adversarial verification, refinement, and selection.
The most important dataset clarification
Your dataset counts are directionally right, but the exact public cards show some details worth using.
Nemotron-SFT-Math-v4 currently shows 545,431 training samples, split into 285,516 COT and 259,915 TIR samples, with about 6.31B tokens. The dataset card says solutions were generated with DeepSeek-V4-Pro on High inference mode, sourced from Nemotron-Math-v2, and only retained when final answers matched verified references.
Nemotron-Math-Proofs-v2 is not just “80K solutions.” It is more interesting: the card says it contains 82,737 samples across 5,752 unique problems, including proof-generation, verification, and meta-verification traces. That is a much richer training signal than plain solution traces.
Nemotron-RL-Math-v2 currently shows 7,732 train samples, not 4K, on the public Hugging Face card. It is described as a curated RL set for mathematical problems with verifiable answers or validation signals suitable for RLVR, with problems sourced from AoPS, StackExchange-derived held-out math data, Skywork, DAPO-Math-17k, and vendor-purchased data. The card says all problems and expected answers were verified using GPT-5.2.
So I would write:
Nemotron-RL-Math-v2 is small on purpose. The point is not raw scale; it is verifiability. In RL, a small clean set with reliable rewards can matter more than a huge noisy set.
That is a very strong missing point.
The best technical thesis
The math stack is powerful because it separates three training regimes:
SFT-Math-v4: teaches solution style, trajectory structure, Python/tool use, final-answer discipline, and exposure to many problem forms.
Math-Proofs-v2: teaches proof construction, proof checking, critique, gap detection, and meta-verification.
RL-Math-v2: teaches optimization against verifiable answer signals rather than just imitation.
The line to add:
SFT teaches the model how good reasoning looks. Proof traces teach it how reasoning fails. RLVR teaches it that the answer has to survive checking.
That is excellent.
Another:
Math reasoning improves when the model is trained not only to produce solutions, but to audit them.
The hidden story: verification is becoming the moat
The most important broader trend is not “math models are better.” It is:
The open-model race is moving from generation to verification.
Models can generate infinite plausible reasoning. The scarce skill is knowing which reasoning is correct.
That is why proof traces, meta-verification traces, and RLVR datasets matter.
Best lines:
The next reasoning frontier is not more fluent chain-of-thought. It is self-correction under verifiable constraints.
A model that can solve is useful. A model that can verify its own solution is much more dangerous and much more valuable.
The verifier is becoming as important as the generator.
The architecture angle
Your draft should mention why this model is not just “big.”
Nemotron 3 Ultra is a hybrid Mamba-Attention / LatentMoE model. The report says the hybrid architecture is meant to improve inference throughput by reducing attention cost and KV-cache footprint, while MoE improves accuracy per active parameter. NVIDIA also uses Multi-Token Prediction for faster generation and NVFP4 training/quantization for efficiency.
The better framing:
Ultra is optimized for the accuracy-throughput frontier, not just benchmark bragging rights.
That matters because agentic reasoning is expensive. If a model is going to run long contexts, many candidates, tool calls, proof attempts, and refinement rounds, inference throughput becomes part of intelligence.
Best line:
For agents, speed is not just latency. Speed is search budget.
Another:
A faster reasoning model can buy more attempts, more verification, and more refinement inside the same cost envelope.
The Blackwell / NVIDIA-stack angle
This is a major strategic missing element.
Nemotron 3 Ultra is not just an open model. It is a hardware-native argument for NVIDIA’s full stack.
The model card says the NVFP4 model has minimum GPU requirements such as 4×GB200, 4×B200, 4×GB300, 4×B300, or 8×H100, and the report says the NVFP4 checkpoint targets Blackwell with native FP4 math while also running on Hopper as W4A16.
That means the strategic message is:
NVIDIA is open-weighting the model while making the best experience live on NVIDIA hardware and software.
Best line:
This is not charity. It is open-weight ecosystem strategy.
Another:
The model is open. The performance path points straight through NVIDIA’s hardware stack.
Another:
NVIDIA is using openness to make CUDA, TensorRT-LLM, Blackwell, NVFP4, and NeMo the default route for serious agentic inference.
The “open” caveat
Be precise with the word “open.”
The model card says Nemotron 3 Ultra is ready for commercial and non-commercial use, governed by OpenMDW-1.1, while the datasets have their own licenses such as CC-BY-4.0 and CC-BY-SA-4.0 depending on source.
Also, the GitHub recipe page includes a crucial caveat: the published recipes train exclusively on the open-sourced subset of training data, and results will differ from the technical-report benchmarks, which used additional proprietary data.
That should be in the post. It makes the release look more credible, not less.
Suggested wording:
NVIDIA is releasing unusually useful assets, but “reproducible” should be interpreted carefully: the public recipes are reference implementations on the open-sourced subset, while the report’s headline results used additional proprietary data.
That is the honest, expert version.
The “data is the product” angle
The model will get attention. The datasets may matter more.
A model checkpoint is a point-in-time artifact.
A dataset and recipe can become infrastructure for the next wave of open math models.
Best line:
Weights decay. Recipes compound.
Another:
The most valuable part of an open model release may be the part that lets everyone else build the next model.
Another:
A strong model changes leaderboards. A strong dataset changes the slope of everyone else’s progress.
The obscure but important implication: open labs can now train “reasoning specialists”
This release is valuable not only because people can run Ultra. Most developers cannot casually run a 550B / 55B active model.
The bigger value is that smaller labs can use the datasets and recipes to train specialists:
math tutors, formal proof assistants, contest problem solvers, symbolic-computation agents, code-math hybrid agents, science reasoning models, verifier models, judge models, and domain-specific RLVR systems.
Best line:
Most people will not deploy Ultra directly. They will distill pieces of Ultra’s training stack into smaller specialists.
Another:
Ultra is the flagship. The datasets are the multiplier.
The “math as agent training” angle
Do not frame math as a niche benchmark.
Math is a training ground for agents because it has:
clear constraints, hidden traps, long-horizon reasoning, tool use, verification, formal structure, compositional difficulty, and objectively checkable answers.
Best line:
Math is not just a benchmark. It is the gymnasium for reliable agents.
Another:
Hard math teaches models to survive long chains of reasoning where one false step ruins the outcome. That is exactly what real agents need.
This connects the release to coding, science, finance, logistics, and autonomous workflows.
The “final answer” versus “proof” split
This is a great missing technical point.
Final-answer datasets can reward answer extraction even when reasoning is shaky. Proof datasets teach rigorous derivation, but proof verification is harder and less easily reduced to exact-match reward. The combination matters.
Line:
Final-answer math teaches correctness at the endpoint. Proof data teaches correctness along the path.
Another:
RLVR works best when the answer is checkable. Proof reasoning matters when the path itself is the product.
That is extremely useful for explaining why all three datasets exist.
The “TIR” angle
Nemotron-SFT-Math-v4 includes both COT and TIR-style samples. The public card labels the split as COT and TIR, with TIR making up nearly half of the samples.
TIR likely matters because hard math often benefits from computation:
symbolic checks, numerical experiments, brute-force search, algebra verification, modular arithmetic checks, geometry calculations, and counterexample search.
Best line:
The model is not being trained to be a calculator. It is being trained to know when to call the calculator.
Another:
Tool-integrated reasoning is the bridge between mathematical intuition and mechanical verification.
The “reasoning budget” product angle
Nemotron 3 Ultra has configurable reasoning mode and reasoning-budget control. The model card shows a reasoning_budget pattern for setting a hard token ceiling on the reasoning trace.
That is more important than it sounds.
Reasoning models are becoming economic products. Users need to decide:
fast answer, cheap answer, deep answer, proof-quality answer, search-heavy answer.
Best line:
Reasoning budget is the new temperature slider.
Another:
The future UI for reasoning models is not just “ask a question.” It is “how much thinking is this worth?”
Another:
Math performance is now partly a budget-allocation problem.
The “agentic math” system architecture
A high-end math agent using Nemotron 3 Ultra should not just ask once.
The serious pipeline should look like:
Problem classifier
Algebra, geometry, number theory, combinatorics, analysis, proof, final answer, computational, symbolic.
Strategy generator
Generate several possible solution paths before committing.
Candidate solver
Produce many independent attempts under different seeds and reasoning budgets.
Tool-integrated checker
Use Python, CAS, numerical tests, brute force, modular checks, or symbolic simplification where appropriate.
Proof verifier
Critique each proof for gaps, hidden assumptions, invalid transformations, missing edge cases.
Refinement loop
Repair promising attempts rather than restarting blindly.
Consensus and adversarial review
Use separate verifier/judge prompts or smaller verifier models to rank attempts.
Final response compiler
Produce a concise proof or final-answer solution with clear reasoning.
Post-hoc formalization option
For proof tasks, attempt Lean/Isabelle/Coq translation or at least structured proof obligations.
Best line:
Hard math should be treated as search over proof space, not autocomplete over solution text.
The “genius-level” evaluation suggestions
The release would be stronger if the community evaluates not only benchmark scores, but also:
Cost per solved problem
How many tokens, proof attempts, verifier calls, and GPU seconds are required?
Marginal value of TTC
Where does extra test-time compute stop helping?
Verifier precision and recall
Does the verifier catch false proofs without rejecting good ones?
Proof gap rate
How often is the final proof human-plausible but mathematically invalid?
Tool-dependence ratio
Which domains require Python/TIR, and which are solved internally?
Contamination audit
Especially important with AoPS, Math StackExchange, MathOverflow, IMO-style problems, and public benchmark overlap.
Novel problem performance
Use newly written problems from human mathematicians, not public forum archives.
Formalization success rate
How often can a natural-language solution be converted into Lean-checkable proof obligations?
Robustness to paraphrase
Does the solution survive reworded versions of the same problem?
Adversarial false-premise math
Can the model identify impossible or malformed problems instead of forcing a solution?
Best line:
The next leaderboard should measure solved problems per dollar, not just solved problems per prompt.
The contamination caveat
This does not mean the results are invalid, but serious people will ask about it.
Math datasets built from AoPS, Math StackExchange, MathOverflow, and public problem collections carry contamination risk because many contest problems and solutions circulate widely. Nemotron-SFT-Math-v4 says its Math StackExchange subset was decontaminated to avoid overlap with public benchmarks, but independent evaluation on fresh hidden problems will still matter.
Suggested wording:
The next proof point is fresh, private, independently graded math: new Olympiad-style problems, new proof tasks, and blind human grading with cost-per-solution reported.
Best line:
For math models, the cleanest benchmark is a problem written after the model shipped.
The “formal math” missing element
Natural-language proof ability is valuable, but the next step is formal verification.
A model that writes a beautiful proof can still hide a gap.
A model that produces Lean-checkable proof obligations changes the game.
Add:
The obvious next frontier is pairing Nemotron-style natural-language proof generation with formal proof assistants. Use Ultra to search and explain; use Lean/Isabelle/Coq to certify.
Best line:
Natural language finds the proof. Formal verification signs it.
Another:
The holy grail is not a model that sounds like a mathematician. It is a model whose proof survives a compiler.
The “NVIDIA strategy” angle
This release is strategically bigger than a leaderboard because NVIDIA is moving up the stack.
NVIDIA is not just selling GPUs. It is releasing:
models, datasets, recipes, RL environments, deployment guides, TensorRT-LLM paths, quantized checkpoints, and open developer assets.
The GitHub repo calls itself a developer asset hub with training recipes, usage cookbooks, datasets, and end-to-end examples; it also frames Ultra as a datacenter-scale agentic reasoning model with pretraining → SFT → RLVR → MOPD recipes.
Best line:
NVIDIA is turning the open-model ecosystem into a demand generator for NVIDIA-optimized inference.
Another:
The moat is no longer only the chip. It is the chip plus the model family plus the recipe plus the deployment stack.
The strongest short version for X
Nemotron 3 Ultra is not just a model release.It is a reasoning-stack release.550B total / 55B active. 1M context. Hybrid Mamba-Attention LatentMoE. MTP. NVFP4. Reasoning-budget control. Strong agentic, math, code, science, and long-context performance.But the real story is the data and recipes.Nemotron-SFT-Math-v4 gives ~545K math reasoning trajectories.
Nemotron-Math-Proofs-v2 gives ~82K proof, verification, and meta-verification traces.
Nemotron-RL-Math-v2 gives curated verifiable math problems for RLVR.That is the important pattern: solve, verify, refine, and train against checkable outcomes.With enough test-time compute, Ultra becomes more than a single-pass model. It becomes the base policy inside a generate–verify–refine math system. That is why the IMO / USAMO / Putnam results matter.The next open-model race will not be won only by bigger checkpoints.It will be won by better recipes, better verifiers, better test-time scaling, and better cost per solved problem.
More aggressive version
Nemotron 3 Ultra is NVIDIA saying the open-model race is no longer about weights alone.The checkpoint matters, but the recipe matters more.Ultra is a 550B total / 55B active hybrid Mamba-Attention LatentMoE model with 1M context, NVFP4 support, MTP, and reasoning-budget control. It is built for long-running agents, hard reasoning, code, math, science, and high-context work.But the real release is the reasoning supply chain: SFT math trajectories, proof-generation traces, verifier traces, meta-verifier traces, RLVR math data, recipes, and deployment assets.That is how open models get serious.Not “here are weights, good luck.”“Here is the data pipeline. Here is the training structure. Here is the verifier logic. Here is the RL set. Here is the quantized checkpoint. Here is the hardware path.”The math results are impressive, but the lesson is broader: hard reasoning is becoming a systems problem. Generate many attempts. Verify them. Refine them. Allocate more test-time compute when the problem is worth it.The model is no longer just answering.It is searching.
Best long version
We released Nemotron 3 Ultra.It is strong across the board, but the most interesting part is how it behaves when you give it real test-time compute. On hard math, Ultra is not just a single-pass answer model. It is a strong base policy for generate–verify–refine search. With enough compute, it performs extremely well on Olympiad-level and advanced competition math, including IMO, USAMO, Putnam, and proof-style benchmarks.But the bigger story is that we are not only releasing a checkpoint.We are releasing the stack.Nemotron-SFT-Math-v4 contains large-scale final-answer math reasoning trajectories, including both chain-of-thought and tool-integrated reasoning. Nemotron-Math-Proofs-v2 contains proof-generation, verification, and meta-verification traces. Nemotron-RL-Math-v2 contains curated verifiable math problems for RLVR.That combination matters.SFT teaches the model what good reasoning looks like.
Proof traces teach it how mathematical arguments are structured and where they fail.
Verification traces teach it to critique.
RLVR teaches it to optimize against checkable outcomes.
Test-time compute lets the system search, verify, and refine instead of betting everything on the first sample.This is the direction hard reasoning is going.The frontier is not just bigger models. It is better reasoning systems: better data, better verifiers, better search, better tool use, better proof checking, and better cost-quality tradeoffs.Nemotron 3 Ultra is also built for that reality architecturally: 550B total / 55B active parameters, hybrid Mamba-Attention LatentMoE, 1M-token context, MTP, NVFP4, and reasoning-budget control. The goal is not only accuracy. It is accuracy under the inference economics of long-running agents.That is why releasing the recipes matters.We want people to inspect the pipeline, specialize it, adapt it, distill from it, build smaller math specialists, train better verifiers, and push the next generation of open reasoning models forward.The checkpoint is the artifact.The recipe is the multiplier.
Obscure but useful thought inputs
1. Reasoning is becoming a compute-allocation problem.
The key question is no longer simply “can the model solve it?” It is “how much thinking, search, tool use, and verification is the problem worth?”
2. Math is the safest laboratory for agentic reasoning.
Hard math gives you long-horizon reasoning with objective checks. That makes it ideal for developing the habits agents need in code, science, finance, and engineering.
3. Test-time scaling turns intelligence into a budgeted process.
A cheap problem gets one pass. A hard problem gets candidates, verifiers, refinement rounds, tools, and selection.
4. Proof verification is the hidden gem.
A model that can produce plausible math is useful. A model trained to find gaps in plausible math is far more valuable.
5. The community should train verifier-first models.
The most useful derivative models may not be solvers. They may be proof critics, answer checkers, theorem-step validators, or RL reward models.
6. NVFP4 is a strategic story, not just an efficiency detail.
The release pushes open reasoning toward NVIDIA-native hardware paths. That is good for deployment and also strengthens NVIDIA’s model-to-chip ecosystem.
7. “Open” now has layers.
Open weights are one layer. Open datasets are another. Open recipes are another. Open evals, verifiers, and RL environments are even deeper.
8. Dataset quality beats dataset size in RLVR.
For reinforcement learning on math, a small clean set with reliable validation can be more useful than a giant noisy corpus.
9. The next leap is formalization.
Natural-language proof generation plus Lean/Isabelle/Coq verification could turn “looks correct” into “machine-checked.”
10. The real benchmark should be cost per solved problem.
High TTC can solve more, but the economic question is how many dollars, GPU seconds, verifier calls, and tokens are required.
Jun 4

We released Nemotron 3 Ultra! It's quite strong across the board, but is especially good at math reasoning tasks compared to other open models. With enough TTC Ultra does really well on hard math competitions like IMO, USAMO and Putnam.
And as always, we aren't only releasing the model, but all datasets and recipes that make it this strong.
Nemotron-SFT-Math-v4: 550K solutions to "final answer" math problems with and without Python tool use huggingface.co/datasets/nvid…
Nemotron-Math-Proofs-v2: 80K solutions and verifications for hard mathematical proofs huggingface.co/datasets/nvid…
Nemotron-RL-Math-v2: 4K selected math problems with verified final answers. This dataset is much higher quality than any previous math RL set we released huggingface.co/datasets/nvid…
If you want to learn more details, check out our tech report research.nvidia.com/labs/nem…
5
6
877

May 23
「答えを出す能力」を一度わざと下げることで、より高いレベルに到達する。30Bパラメータ(実動作は3B)のAI「SU-01」がIMO・USAMO・IPhOすべてで金メダルラインを突破した(https://arxiv[.]org/html/2605.13301v1)。
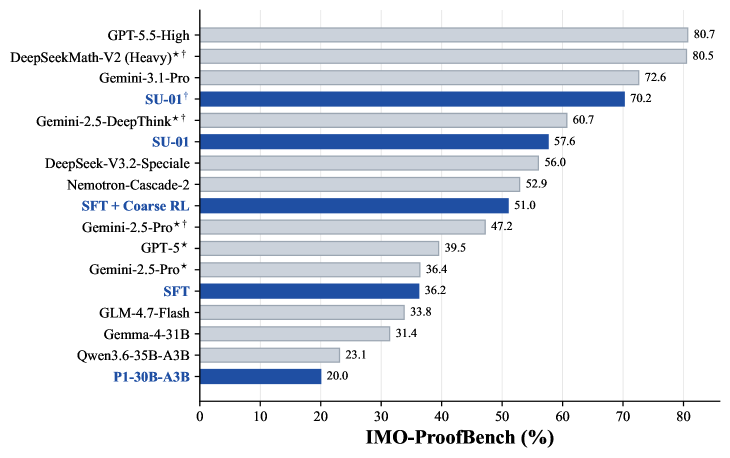
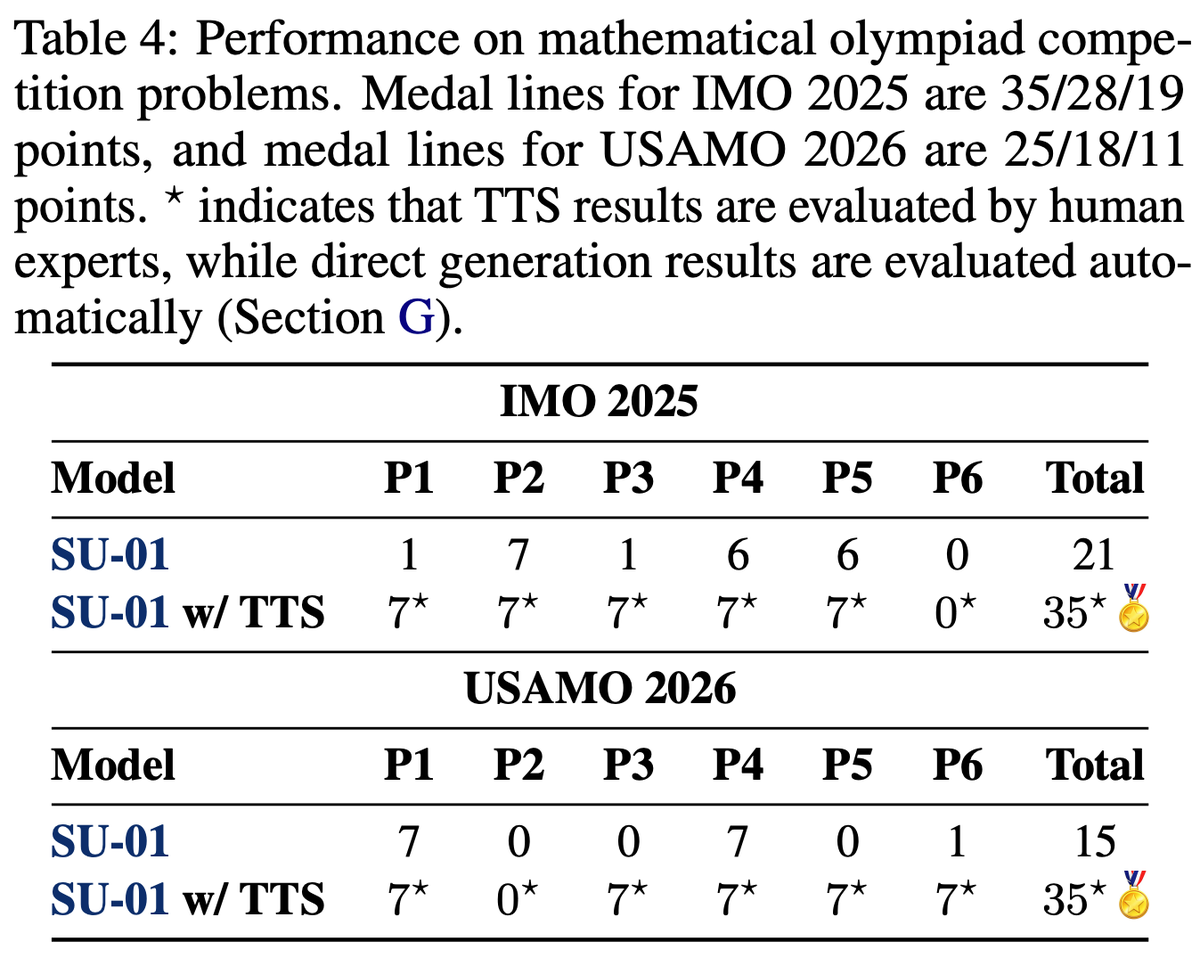
テスト時スケーリング(TTS)ありでIMO 2025は35点(金ライン35点)、USAMO 2026も35点で人間の最高得点に並んだ(金ライン25点)。TTS無しでも21点・15点でどちらも銅メダルライン以上。IPhOは2024・2025ともにTTS無しで既に金ラインを超えている(23.5点 vs 金ライン20.8点、20.3点 vs 19.7点)。
訓練レシピの核心は「一時的な後退」にある。
SFT(教師あり微調整)を施すと、まず答えを出す精度がAnswerBenchで69.2から59.8に落ちる。しかし証明の質を測るProofBench-Basicが33.8→57.6、ProofBench-Advancedが6.2→14.8へ跳ね上がる。「素早く答えを当てる」行動パターンから「証明を厳密に探索・検証する」パターンへと書き換えることが目的で、これが後のRL(強化学習)の土台を格段に強くする仕組みだ。
SFTデータは338K件のトレース(1件あたり8,192トークン以内)を4エポック。同サイズの競合Nemotron-Cascade 2が約2660万件のSFTデータを使うのと対照的で、データ効率の高さが際立つ。
続く2段階RLはたった200ステップ。前半(粗いRL)は最終答えの正誤だけを報酬に探索力を高め、後半(精緻なRL)は証明全体の論理的厳密さを採点するモデルに切り替えて自己修正ループと経験リプレイ(稀な成功例を記憶して再利用)を組み込む。
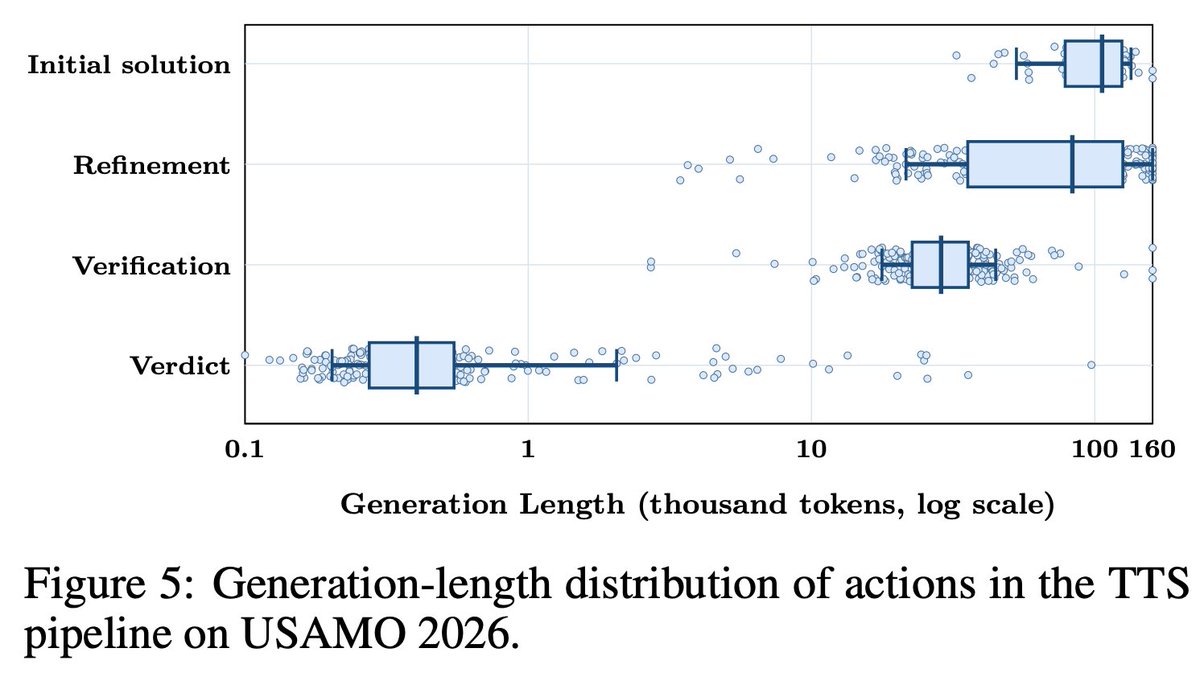
最後のTTSは「解く→自己検証してバグレポートを書く→修正する」サイクルを繰り返す。1回あたりの推論量は初回解答の中央値が106Kトークン、修正が83K、検証が28.7Kで、合計100Kトークン超のトレースを安定して扱う。IMO-ProofBenchでは57.6%から70.2%に改善した。
実際の解法も面白い。USAMO 2026 P3の幾何問題で、人間なら角度追いで解くところを複素数で単位円・正三角形の回転・弦・接線をまとめて代数化してみせた。「形式的な枠組みに落とし込める問題」は得意で、「組み合わせ構造を保ちながら議論する問題」(IMO P6・USAMO P2)ではまだ失敗が残る。
数学・物理のみで訓練しても化学(69.4%)・生物(25.0%)に転移した。巨大化とは別方向での最高水準という意味で、今後のスケーリング議論に影響しそうな論文だ。
2
2
13
1,037

On MedCode, our benchmark that assesses whether models can support the medical billing process, 3.5 Flash ranks #3 overall— just 3 points behind the top model (Gemini 3.1 Pro). It also had a slight ( 3%) increase on ProofBench.
The model is still lagging behind relative to Gemini 3.1 Pro on some of our benchmarks: LegalBench, MortgageTax, and our academic benchmarks including MMLU Pro, and GPQA.
1
5
1,184

May 18
🚨Matematik Dünyası Şokta: Google DeepMind’in AI’si “İnsanlardan Daha İyi Matematik Yapıyor” ve Kendi Araştırma Makalesini Tek Başına Yazdı!📐🧠
Google DeepMind araştırmacısı tek bir soru sordu:
“Yapay zeka, matematiği icat eden insanlardan daha iyi yapabilir mi?”
Cevap geldi… ve bu cevap, dünyanın en iyi matematikçilerini bile dehşete düşürecek cinsten.
Sistem sıfır ipucu, sıfır yönlendirme, sıfır insan yardımı ile çalıştırılıyor. En zor, on yıllardır çözülememiş matematik problemlerine salınıyor. IMO altın madalyalı matematikçilerin bile yıllarca lisansüstü eğitimle uğraştığı o “sınır” problemlere…
Ve AI bunları bir gecede çözüyor...
✅Tamamen otonom olarak aday ispatlar üretiyor
✅Uzman insan değerlendiriciler, 10 çözümden 6’sını küçük revizyonlardan sonra yayınlanabilir buluyor
✅IMO-ProofBench Advanced’de �,1 puan alıyor (önceki rekor e,7 — 30 puanlık dev bir sıçrama!)
✅Erdős Varsayımları veri tabanından 4 açık soruyu çözüyor (onlarca yıldır bekleyen problemler)
✅Kendi başına araştırma makalesi yazıyor — aritmetik geometride yapı sabitlerini hesaplıyor ve yayınlıyor. İnsan yazar yok!
✅Çözemediği 4 problem için “uydurma” yapmıyor, dürüstçe “çözüm bulunamadı” diyor. Kendi sınırlarını biliyor!
Bu gelişme ne anlama geliyor?
✅Matematik artık sadece insan dehasının alanı değil
✅AI, doktora seviyesinde araştırma yapıyor ve kendi başına makale yayınlıyor
✅Ocak 2026 sürümüyle olimpiyat seviyesindeki problemler için gereken hesaplama gücü 6 ayda 100 kat azaldı
✅Gelecekte matematikçiler “AI co-pilot” ile değil, “AI co-mathematician” ile çalışacak
✅Bilimsel keşif hızı katlanarak artacak
Sizce AI matematikte insanlardan tamamen üstün hâle gelecek mi? Kendi başına makale yazan AI’ler bilim dünyasını nasıl değiştirecek? Bu sistem Türkiye’deki matematik ve AI araştırmalarını ne yönde etkiler?

1
7
36
3,502

May 16
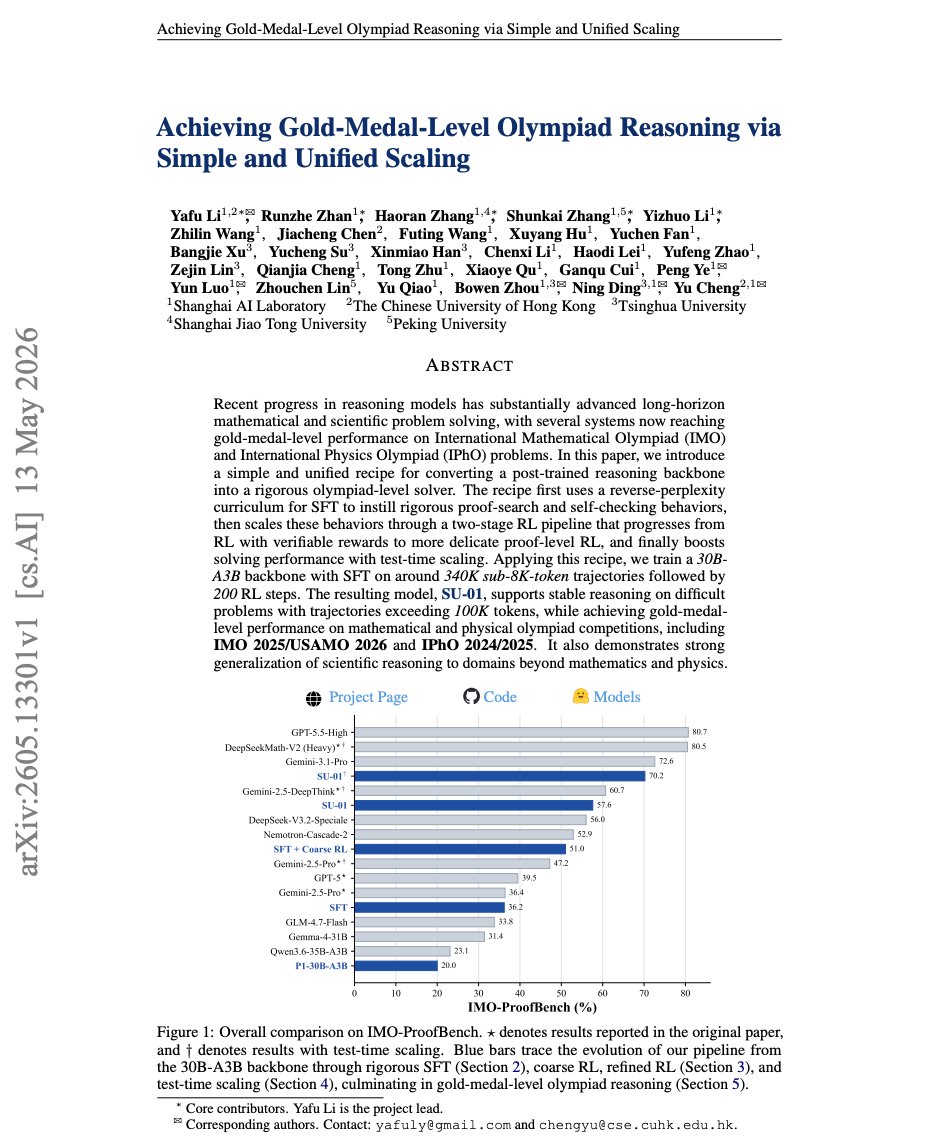
🥇 A 30B open model just hit gold-medal level on the IMO and Physics Olympiad — and beat the highest human score on USAMO 2026 by 10 points. Shanghai AI Lab CUHK Tsinghua built SU-01 with a "simple and unified" recipe anyone can follow: rigorous SFT, then two-stage RL, then test-time scaling. Here's exactly how they turned a normal reasoning model into an olympiad solver.
The problem: a few labs have reached gold-medal olympiad performance, but the recipes are either secret or extremely complex. There was no clear, reproducible path from "post-trained reasoning model" to "rigorous olympiad solver."
SU-01's recipe is three steps on a 30B-A3B backbone. First, a reverse-perplexity curriculum for SFT — teach the model rigorous proof-search and self-checking by ordering training data from easy-to-predict to hard. Second, a two-stage RL pipeline — start with RL on verifiable answers, then move to harder proof-level RL. Third, test-time scaling (TTS) — let the model think longer at inference, with trajectories over 100K tokens.
🥇 IMO-ProofBench: 57.6% direct generation, 70.2% with test-time scaling
🥇 Exceeds the IPhO gold lines for both 2024 and 2025
🥇 Meets the IMO 2025 gold line, exceeds the USAMO 2026 gold line by 10 points
🧪 Trained on ~340K sub-8K-token trajectories only 200 RL steps
Gold-medal reasoning is no longer a secret-recipe, frontier-only result — a clean, reproducible pipeline on a 30B open model now clears it.
Paper: arxiv.org/abs/2605.13301
(1/5)

1
2
110

Can a simply trained 30B model reach gold-medal-level olympiad reasoning in pure natural language?
In our new report, we introduce **SU-01**, a 30B-A3B model trained with a simple unified recipe for rigorous mathematical and scientific reasoning.
The recipe is intentionally lightweight: around **340K sub-8K-token SFT trajectories**, followed by only **200 RL steps**, then test-time verification and refinement.
The resulting model supports stable reasoning on difficult problems with trajectories exceeding **100K tokens**.
With test-time scaling, SU-01 achieves:
- **35 points on IMO 2025**, meeting the gold-medal line;
- **35 points on USAMO 2026**, far above the 25-point gold line and matching the highest human score among 340 contestants. It also received full credit on Problem 3, where the human average was only 0.01 and no contestant scored above 5;
- gold-level performance on **IPhO 2024/2025**;
- **70.2% on IMO-ProofBench**, close to Gemini 3.1 Pro Thinking.
The key takeaway is simple:
Olympiad-level scientific reasoning may not require a giant model or a heavily customized pipeline for each domain.
What matters is learning a reusable loop of **proof construction, verification, and refinement**.
We have open-sourced the code and model:
Paper: huggingface.co/papers/2605.1…
Github: github.com/Simplified-Reason…
Model: huggingface.co/Simplified-Re…

4
5
18
849

May 8
🚨Google DeepMind araştırmacısı tek bir soru sordu:
Yapay zeka, matematiği icat eden insanlardan daha iyi yapabilir mi?
Cevabını aldı. Ve bu, yaşayan her matematikçiyi dehşete düşürmeli.
Bir sistem kuruyor, ona hiçbir ipucu, hiçbir yönlendirme, hiçbir insan yardımı vermiyor.
Sonra onu matematikteki en zor çözülmemiş problemlere yönlendiriyor.
Öyle zor problemler ki, uzman insan matematikçiler, hatta IMO altın madalyalıları bile, bu problemlerin bulunduğu sınıra ulaşmak için yıllarca lisansüstü eğitim alıyorlar. Yapay zeka bunları bir gecede çözüyor.
Sıfır insan ipucuyla verilen ham problem istemlerine göre, yapay zeka tamamen otonom olarak aday ispatlar üretiyor. Uzman insan değerlendiriciler, küçük revizyonlardan sonra 10 çözümden 6'sını yayınlanabilir olarak değerlendiriyor.
On çözümden 6'sı yayınlanabilir. İlk denemede. Tek başına.
Ardından IMO-ProofBench Advanced'de �,1 puan alıyor. Önceki rekor e,7 idi. 30 puanlık bir sıçrama. Bir gecede.
Ardından, Erdős Varsayımları veri tabanından 4 açık soruyu çözüyor. Onlarca yıldır çözülememiş problemler. Doğa
Tüm kariyerleri tanımlayan problemler.
Siz uyurken çözüldü.
Sonra kimsenin beklemediği şeyi yapıyor.
Yapay zekanın kendi araştırma makalesini yazmasına izin veriyor. Hiçbir insan tek kelime yazmıyor. Hiçbir insan denklemi kontrol etmiyor. Yapay zeka aritmetik geometride yapı sabitlerini hesaplıyor. Yayınlıyor. Tek başına.
İnsan yazarın olmadığı ilk araştırma makalesi.
Sonra kendi sınırlarını bilip bilmediğini kontrol ediyor. Çözemediği 4 problem için, bir şey uydurmak yerine "çözüm bulunamadı" çıktısı veriyor.
Bilmediğini biliyor.
İşte bir aracın başka bir şeye dönüştüğü an.
Ocak 2026 sürümü, olimpiyat seviyesindeki problemler için gereken hesaplama gücünü sadece altı ayda 100 kat azalttı.
100 kat. Altı ay.
Yani bir doktora öğrencisi bir sonraki sefer tek bir ispat üzerinde üç yıl geçirdiğinde,
yerine geçen sistemin rekabet etmek için değil, hızlandırmak için kurulduğunu bilin.
Ve çoktan gitti.

1
3
16
4,224


xAI lanzó Grok 4.3, y la jugada de Elon Musk no es ganar en inteligencia. Es romper la economía del mercado enterprise.
El modelo cuesta $1,25 por millón de tokens de entrada y $2,50 de salida, mientras Claude Opus 4.7 cobra alrededor de $5 y $25 respectivamente. En la práctica, hacer el mismo trabajo con Grok 4.3 te sale entre 7 y 10 veces más barato.
En los benchmarks de derecho corporativo y finanzas de ValsAI, Grok 4.3 quedó en primer lugar, por encima de GPT-5.5 y Claude Opus 4.7. En agentic tool calling, la habilidad de un modelo para usar herramientas como búsqueda web, ejecutar código y resolver tareas complejas paso a paso, lidera el ranking de Artificial Analysis.
Tiene una ventana de contexto de 1 millón de tokens (alrededor de 1500 páginas procesadas en un solo prompt), el mismo tamaño que Claude Opus 4.7 y Gemini 3.1 Pro. Y razona siempre por defecto: piensa antes de responder cada consulta, sin que tengas que activar nada.
Pero hay que decirlo: NO es el modelo más inteligente del mercado. En el Artificial Analysis Intelligence Index saca 53 puntos, contra 60 de GPT-5.5 y 57 de Claude Opus 4.7.
En programación general y matemáticas difíciles flaquea: 11% en ProofBench y 38% en Terminal-Bench Hard, mientras los líderes pasan 60%. Tampoco tiene memoria persistente entre sesiones, algo que ChatGPT y Claude ofrecen hace más de un año.
¿Para quién es? Si trabajas con casos enterprise específicos, análisis legal, due diligence financiera, agentes autónomos que ejecutan tareas con herramientas, procesamiento de documentos largos, Grok 4.3 te entrega capacidad de modelo premium a precio de modelo medio.
Si necesitas el techo de inteligencia para coding complejo, investigación científica o matemáticas avanzadas, sigue siendo Claude Opus 4.7 o GPT-5.5.


1
9
61
4,741