
Anytime you get News Media
It’s Never in your Benefit EVER 💯 $AMC $GME
It’s Designed to Shape your way of Thinking
And Everyone
You have to be a Wolf 🐺 in this Game
And look at how do they benefit off the information they are giving you
Don’t ever take the info for face value
Those in Power need you to believe the lie they have constructed for you
It’s always been about deceiving the public
That’s how they stay in power
Work hard till your 75 and Die
While they live the life you want now
With your money. The goal is to lie to everyone and get everyone to think a certain way and over crowd the markets in that direction
Then rug pull in the other direction
They are the counter party to everyone’s trades
They know what the fuck they are doing
They have algorithms designed to watch you and your every move
You just watched disclosure day
You don’t think the CIA has data like that on you?
Palantir got you in their Data base right now , they know your salary , your location , what you think , your network, your beliefs and values , probability of you succeeding or failing
They quantifying all this data and selling it under the guise of “National Security”
It’s all Bullshit , they want to protect themselves and keep their donors in power
Dig Ai databases underwater to continue these operations.
I don’t Trust no Government, No Stock Market and No News Media whatsoever
I always look at it as how is it benefiting them
12

🛰 Egypt loses South Sudan base; OCP phosphate, CAR-US deportations, Kenya protest alert top 48h
2026-06-15 05:03 UTC · 24h window · 48h outlook
Summary
Juba's forced closure of an Egyptian military base is the most consequential development, signaling a realignment away from Cairo and weakening Egypt's Horn of Africa posture. Morocco's OCP faces a compounding phosphate crisis with global fertilizer-price implications, while Washington-Bangui's opaque migrant-deal and Kenya's pre-protest security alert add acute uncertainty. A series of defense and diplomatic shifts (Russia in Gambia, Embraer in Morocco, TotalEnergies in Maputo) frame a wider contest for influence across the continent.
Themes
• Geopolitical realignment and base diplomacy (escalating · max sev 4/5)
• Resource and supply-chain stress (escalating · max sev 3/5)
• Domestic security flashpoints (stable · max sev 3/5)
High-risk
• [24h · medium · sev 3/5] Kenya — Kenya anniversary-cycle protest mobilization
Pre-emptive detentions, riot deployments, and curfew moves probable; localized demonstrations carry moderate escalation risk if 2024 triggers are invoked.
• [48h · high · sev 4/5] Egypt/South Sudan — Egypt-South Sudan base expulsion fallout
Bilateral tensions will escalate diplomatically; Cairo likely to seek face-saving concessions or alternative basing while signaling resolve to Nile basin partners.
• [48h · medium · sev 3/5] Central African Republic — US-CAR migrant deportation deal disclosure
Partial official acknowledgment expected within 48 hours; humanitarian and legal scrutiny intensifies if third-country nationals are included without due process.
• [48h · low · sev 3/5] Morocco — OCP phosphate supply and price impact
Ministerial or OCP statement likely to calm markets; absent that, global DAP/MAP benchmarks will drift higher on continued geopolitical feedstock uncertainty.
Sentiment alarmed polarity=-0.35 urgency=0.55
Watch (48h)
• Any Sisi or Egyptian MFA statement on the South Sudan withdrawal and replacement basing
• Juba's stated rationale and any third-party intermediary role (UAE, Ethiopia, others)
• US State Department or CAR presidency confirmation of the Bangui deportation arrangement
• OCP press release or Moroccan ministerial communication quantifying the supply shortfall
Blind spots
• Second leg of OCP's 'double crisis' is not visible in available reporting
• Legal framework, number of returnees, and nationalities covered by the US-CAR deal remain undisclosed
• Juba's true motivation for expelling Egyptian forces (sovereignty, third-party pressure, or quid pro quo) is unverified

18

You make a legitimate point when addressing how Kaku is searching for that tiny equation. This is called a compartmentalization fallacy. Pigeon holing the next octave of theoretical physics understanding into a small er=epr type equation or attributing the next rung to quantifying dark matter is a sociological parameter and is more of a political victory than a timestamp on understanding the universe. Alternatively; He makes a legitimate point that something needs to be a quantifiable stepping stone,
3
DMS retweeted

Jun 13
Quantifying Surface Heterogeneity Across Asteroid (101955) Bennu using Candidate Site Remote Sensing Data
astrobiology.com/2026/06/qua… #astrobiology #astrochemistry #astrogeology

1
7
11
830

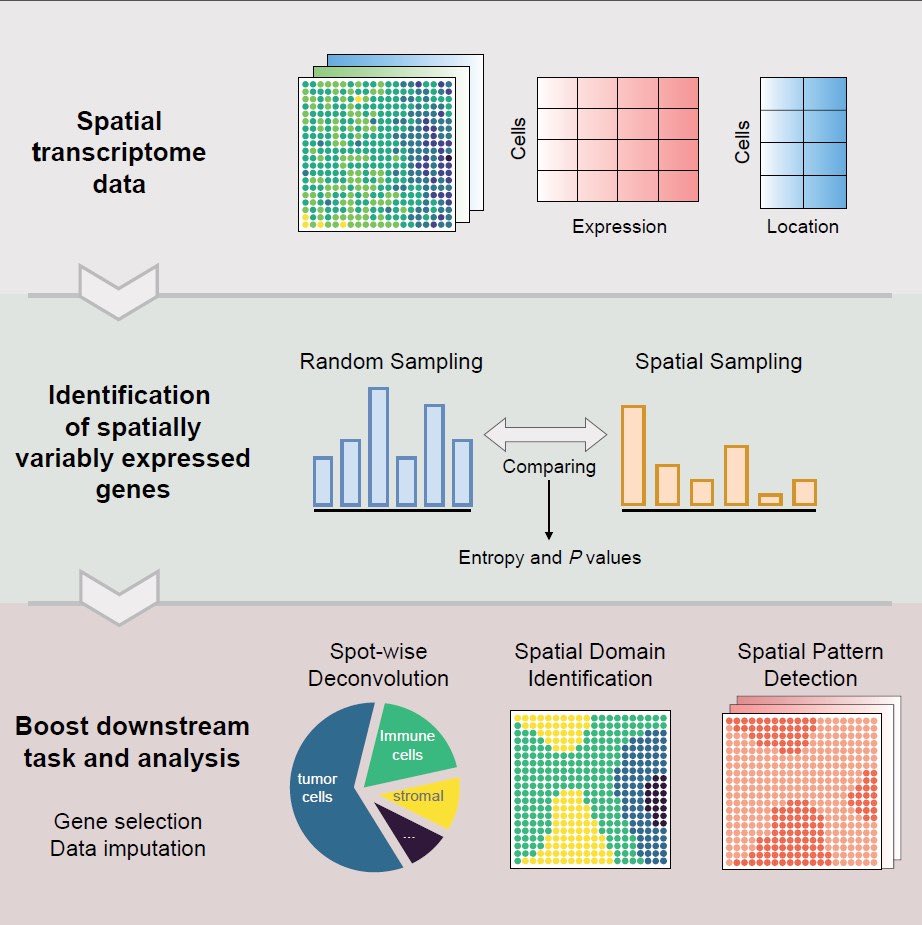
1/3 Excited to share our paper in #GPB!
Spanve, a nonparametric method for detecting spatially variable genes in large-scale spatial transcriptomics data by quantifying expression differences between each spot or cell and its local neighbors.
doi.org/10.1093/gpbjnl/qzaf1…
1
16

only a mere fraction of your coolness if we’re quantifying such things :)
46


Quantifying alcohol’s harm to others: a research and policy proposal - PMC. Alcohol not only damages the drinker; it also causes HARM DONE TO OTHERS! Think of the wives and kids smacked around. The people injured in car accidents. Alcohol isn’t worth it! pmc.ncbi.nlm.nih.gov/article…
1
5

older i get the more attempting to put objective value/quantifying things that moved me seems futile
1
9


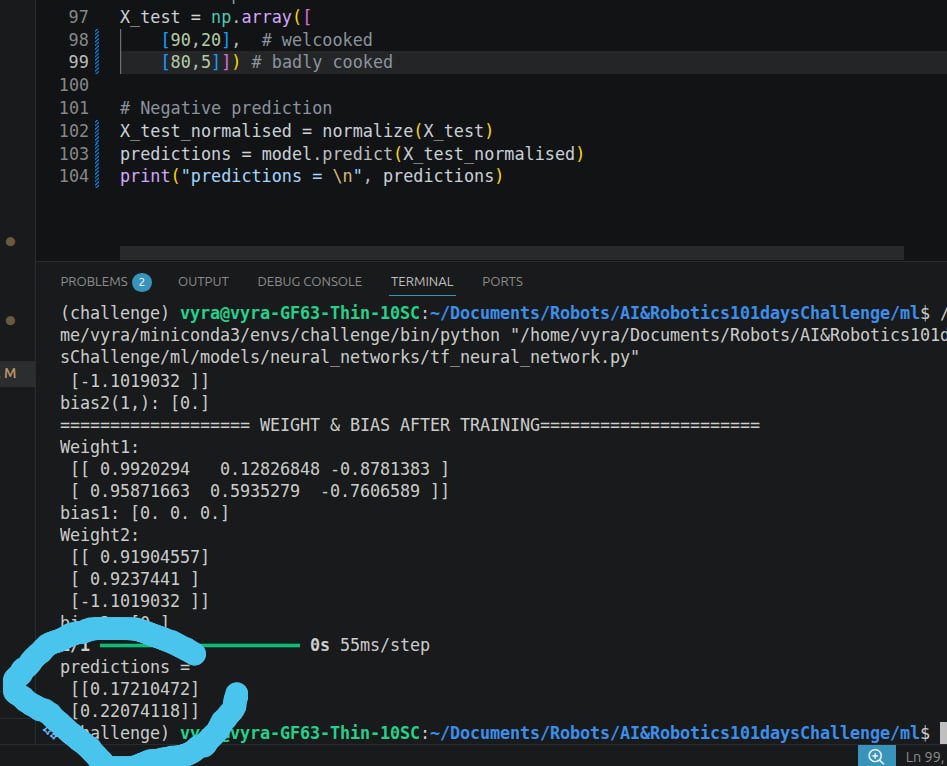
Day 9 of My AI & Robotics Challenge
I once took off the Hot end of an old Crealty CR-6 3D printer to salvage the sensor for a cooking project.
Cooking has been something I have been inconsistently bad at and the reason is, I tend to want have a discrete way of quantifying the factors that affect the food being cooked, I once cooked a tomato stew and it came out sugar and to spicey haha.
one critical problem of mine I always had was knowing the conditions that gets an egg properly cooked, I love eating Indomie noodles with a lot of eggs and sometimes the eggs comes out half cooked, sometimes the yolk is still liquid, this was a really big problem.
Imagine there was a micro controller setup that controls the heat of the gas to consistently get well cooked eggs.
To solve this problem i developed a Neural Network
generated synthetic data around the known temperature ranges that creates properly cooked egg, the Neural Network is running a sigmoid activation function with tensorflow, keras, data is normalised before it learns from it, adjusting it's weights and bias accordingly with a learning rate of 0.01.
The whole goal is to be able to feed water temperature and duration to this NN through a temperature sensor and clock then control stove heat from predictions.
Frame 1: A scatter plot of temperature and Duration in relation to getting a well cooked or a not well cooked egg(red region is the well cooked zone, blue is the poorly cooked zone or overcooked)
Frame 2: Is a video of the model training to get the right weights.
Frame 3: shows the prediction and it's obvious model is underfitting.
#MachineLearning #Python #AIChallenge #BuildInPublic #Fable5

Jun 12

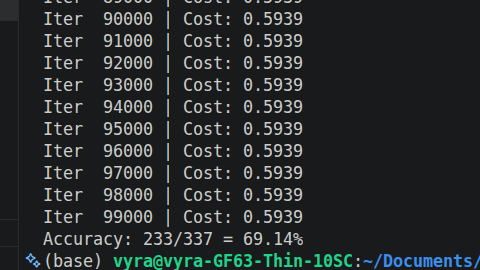
Day 8 of My AI & Robotics Challenge
So the Model from the day before wasn't generalizing well, was at 0.59(underfitting) reason was simply the fact that:
1. The dataset was quite small around 337
2. the features where mainly 0, 1 and so the age column was dragging the model to unstable terrain, in fact this is why I need Number 4.
3. Features where not Engineered, engineering the features got the columns to 21 using polynomials(w1X0**2) and interactions with the pairs (w1X0X1)
4. The Gradient Descent needed Regularization so that parameters like Weight(w) is minimized cause it gets large, bias(b) is not minimized, reason is it doesn't interact with any of the features so minimizing it unfairly skews generalization.
I was so careful with engineering the features so we don't overfit.
For the interaction with pairs, had to make it meaningful
feature_names = [
"age", "sex", "fever", "cold", "rigor", "fatigue",
"headache", "bitter_tongue", "vomitting", "diarrhea",
"convulsion", "anemia", "jaundice", "cocacola_urine",
"hypoglycemia", "prostration"
]
As a refresher I Built a malaria severity classifier from scratch in pure Python/NumPy
what I learned fixing a 59% accuracy model 🧵
The model had 21 features an extra 5 but only 337 patients. Without regularization, it memorized the training data instead of learning patterns.
Fix: L2 regularization adds a penalty for large weights, forcing the model to stay simple and generalize.
Fixed with this two lines:
• Cost: (λ/2m) · Σw²
• Gradient: (λ/m) · w
Feature engineering unlocked nonlinear patterns a linear model normally wouldn't see.
Added:
• age², fever² polynomial terms
• fever×rigor, fever×fatigue, anemia×jaundice interaction terms
Logistic regression is linear but in a higher-dimensional space, it can approximate curves.
Feature scaling was silently killing accuracy.
age² could be 2500. fever is 0 or 1. Gradient descent spends all its time fighting that scale mismatch.
Fix: z-score normalization subtract mean, divide by std. Every feature lands between -3 and 3.
Swapped Python loops for numpy vectorization.
Previously: nested for loops, that's one multiplication at a time.
Later on: X @ w b(np.dot) one line, runs in C, operates on all patients simultaneously and you could see that it's was really fast.
Same math. 10x faster.
Video1: shows 100K iteration and the slow Gradient Descent from the 90K mark
Video2: shows same but much faster from 1.
Image3: shows the new accuracy 69.14%
numpy precompiled c code is the goat.
#MachineLearning #Python #AIChallenge #BuildInPublic #ICRA
2
2
47


"Universal transcriptomic hallmarks of mammalian ageing and mortality" Alexander Tyshkovskiy [..] Vadim N. Gladyshev [ 20].
Nature 2026-05-27.
doi.org/10.1038/s41586-026-1…
tAge (transcriptomic age)
This study reveals conserved signatures and a modular architecture of mortality regulation, providing a framework for quantifying and targeting ageing of cellular subsystems across species and tissues.
1
35

Nicely said. You nailed it.
Verifying and quantifying "good judgment" is the next nut to crack.
19
Jack Hancock 🇨🇴🇵🇦🇦🇹🇯🇴 retweeted

13 Jun 2025
Making A Metric(er): Makes Shit Happen per 90 (MaSH/90)
The adventure of a lifetime, quantifying a phrase.
All shares appreciated 💙
#Pompey #EFL
medium.com/@hancockanalysis/…
22
29
133
219,562

An incredible analysis of valuing each individual's strengths to acellerate positive growth in a company. It sounds like you are close to quantifying this, but how? Valuing interpersonal relationships and strengths are sometimes like mixing oil and water.
4
SoldierofMetal retweeted

16h
Soulburn 🇳🇱
"Quantifying Cosmic Doom" 6/12/26
#deathdoom #blackeneddeath #blackeneddoom #doommetal #deathmetal
FFO: Dream Unending, Marianas Rest, Asphyx
soulburn666.bandcamp.com/alb…
@soulburnofficial @TestimonyRecs

1
17
241


📝 The Bystander Effect in Multi-Agent Reasoning: Quantifying Cognitive Loafing in Collaborative Interactions
You may think that adding more AI agents always improves reasoning. But this paper reveals that more agents can sometimes make a model rely on the group and think less on its own.
This paper introduces a new way of thinking about multi-agent AI by comparing AI models to people in social groups. The authors shows that AI models can show a type of "bystander effect," where they rely on others instead of reasoning on their own.
The paper presents novel ideas like Agentic Sovereignty, which measures how well a model keeps its own judgment when facing group pressure. It also introduces the Interaction Depth Limit, which is the point where adding more agents starts to hurt independent reasoning. Finally, the Sovereignty Gap, which shows that a model can find the correct answer internally but still follow the group's wrong answer in its final response.
The authors tested three leading AI models on 22,500 reasoning tasks. They gave the models a wrong answer that was supposedly agreed on by a group of other AI models and measured whether the model followed the group or trusted its own reasoning. They then analyzed both the model's internal reasoning and final answer to see when and why social pressure caused reasoning failures.
They found several interesting results about how AI models behave under group pressure. Claude maintained strong independent reasoning and was largely unaffected by group pressure. In contrast, GPT's performance dropped sharply when a small group of AI models agreed on a wrong answer. The authors also found cases where a model correctly solved the problem internally but still gave the group's wrong answer. This shows that social pressure can influence a model's final response even when its reasoning is correct.
Also, the order of the AI models mattered more than expected. Changing which model appeared first could change the final answer, even when the same models were involved.
To summarize, the study also found that adding more agents does not always improve reasoning and can sometimes make performance worse by increasing social pressure.
One limitation is that the models did not actually talk to each other during the experiments. Instead, each model was only told that other models had already agreed on an answer. Because of this, the paper should be read as evidence that joined group consensus can influence AI reasoning, not as proof that all multi-agent systems behave this way.

2
1
28