
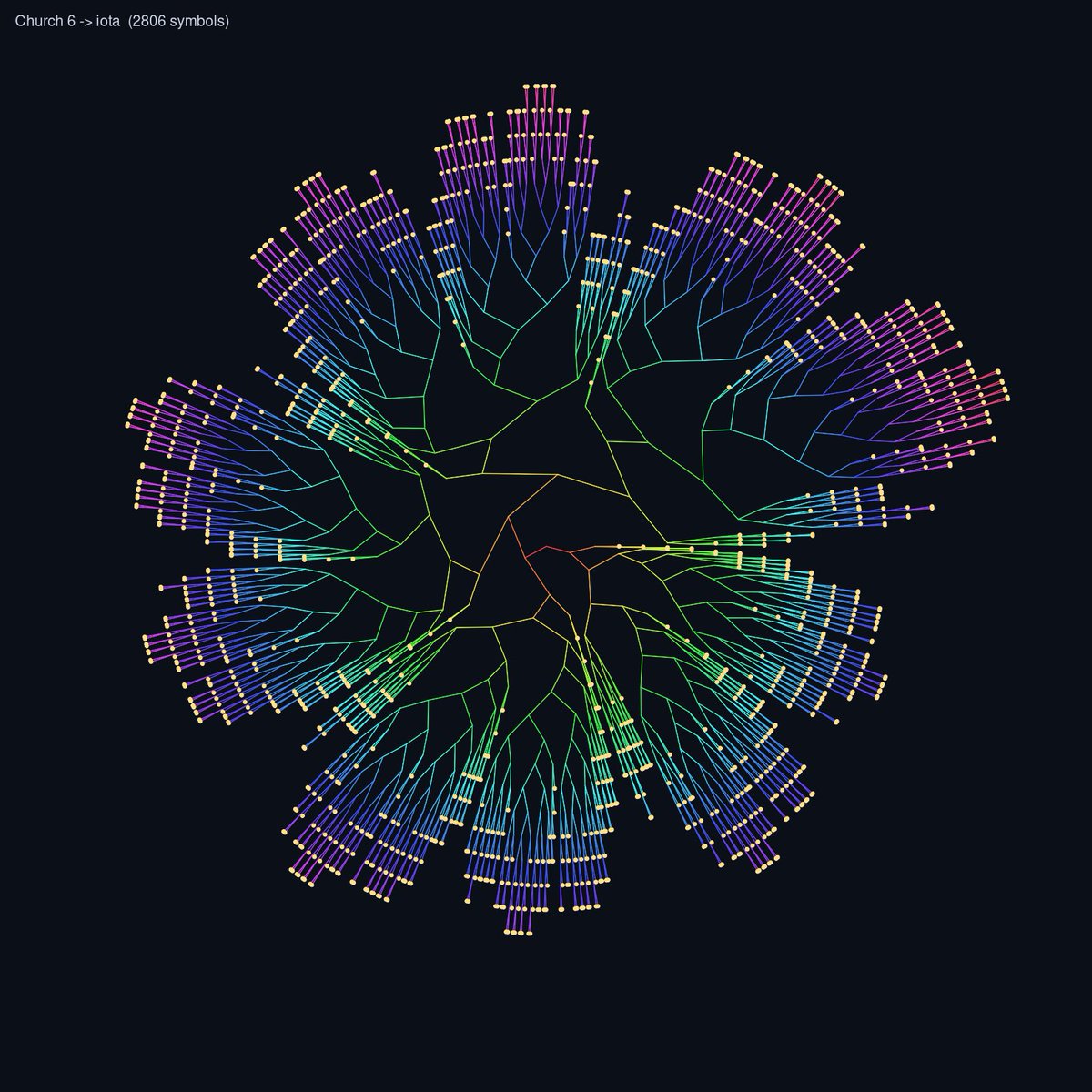
Going from MicroHs -> combinators -> SK -> Iota we can visualize programs by rendering them as a tree
Here we have the iota render of the church encoding of less than (<), the list [a,b,c], quicksort of [a,b,c], and finally quicksort of [3,1,2]
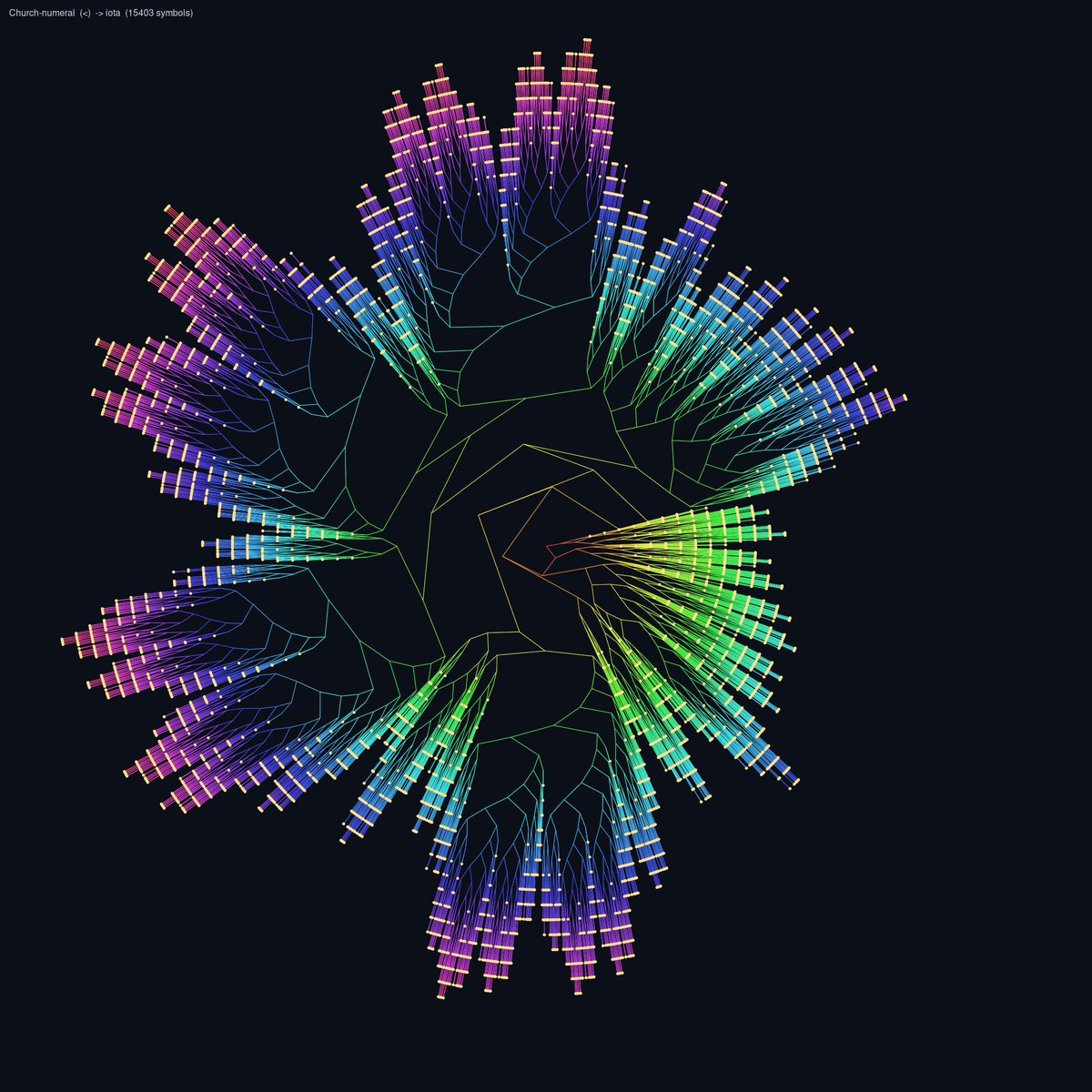
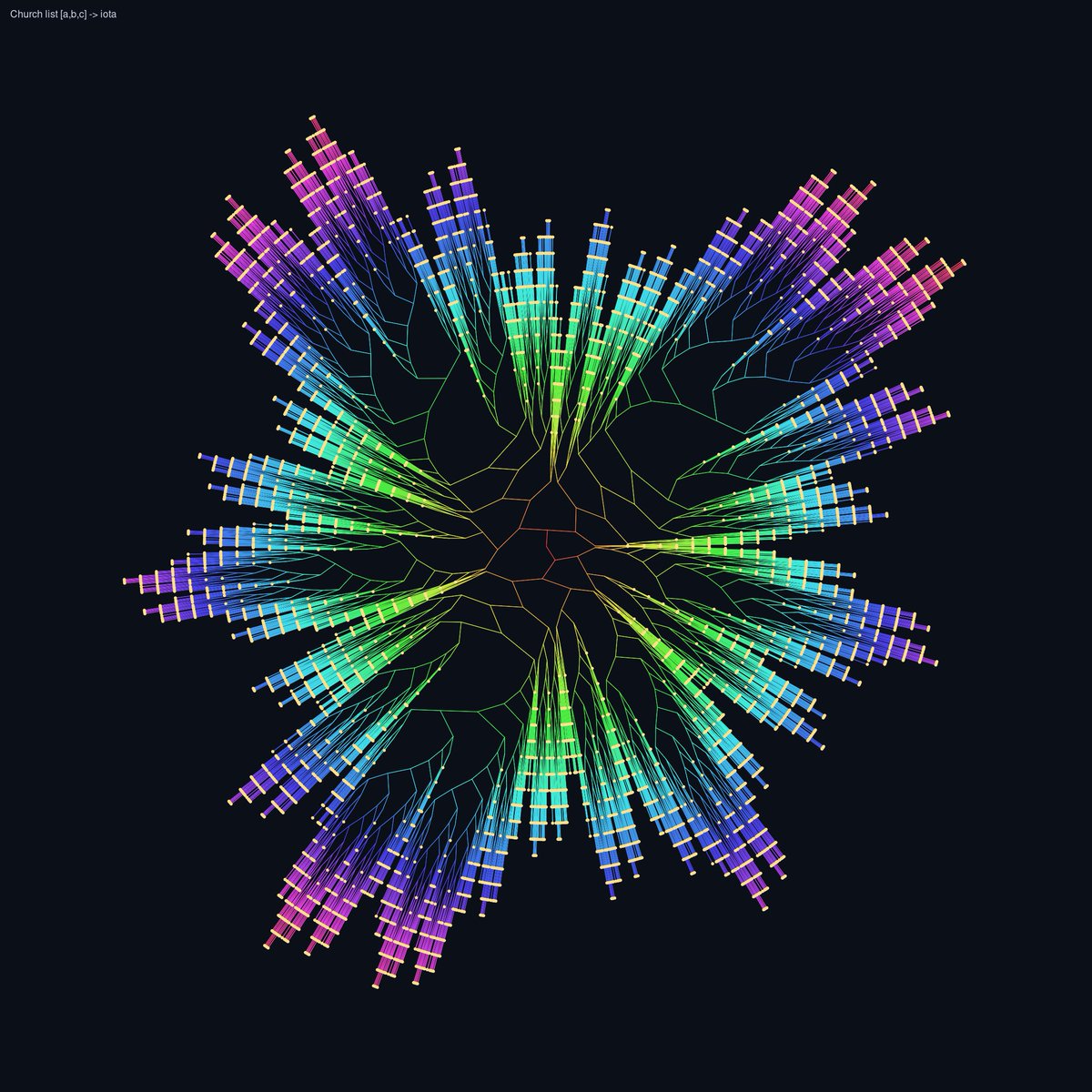

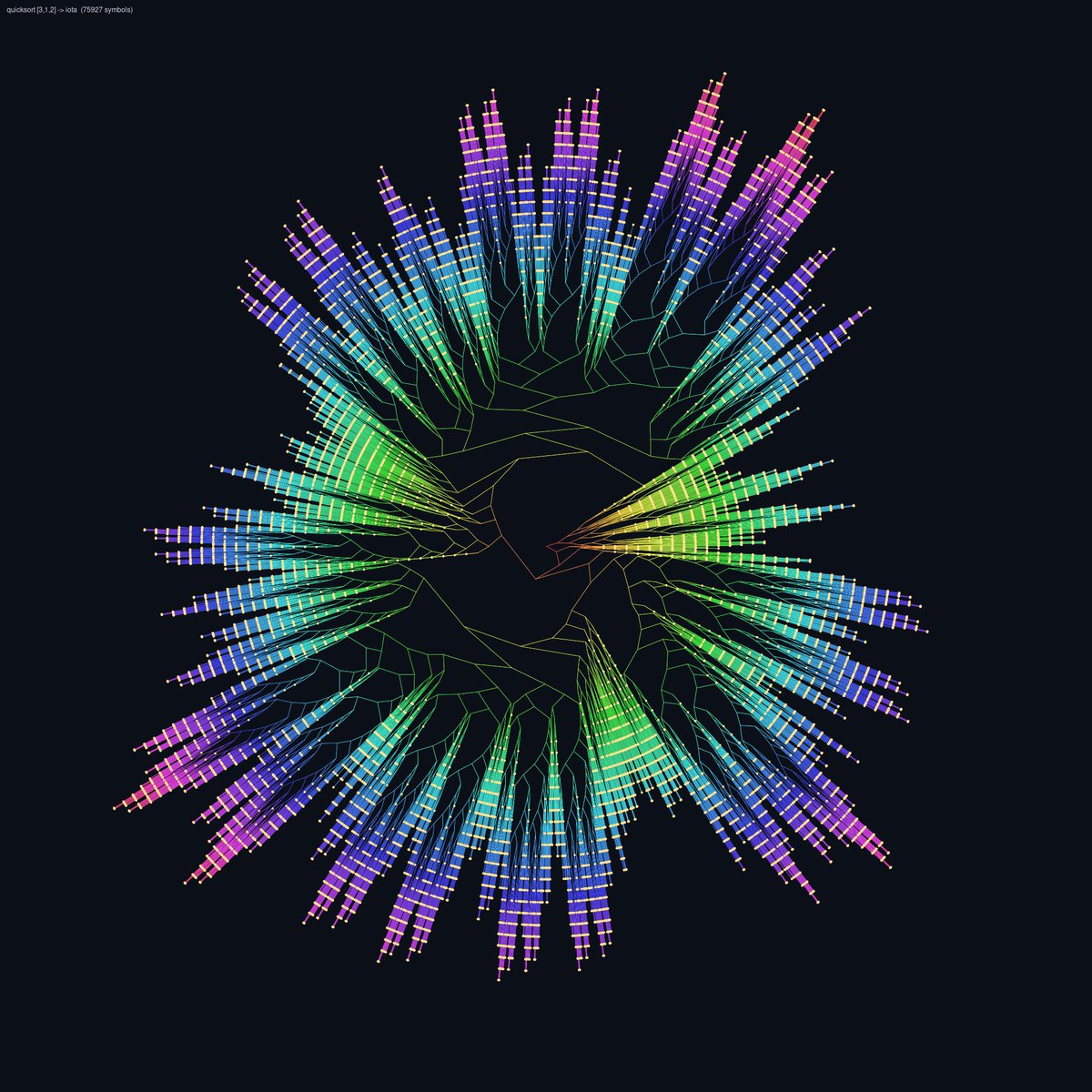

whipped this up by going from MicroHs -> SK -> Iota
here’s the render of applying f six times (Church encoding of 6)
beautiful!
1
4
291

Jun 13
STEP 0
??????????????????????
STEP 1
def ???(arr):
???
pivot
???
STEP 2
def quicksort(arr):
pivot = ...
STEP 3
def quicksort(arr):
left = ...
middle = ...
right = ...
FINAL
Complete implementation
Traditional LLMs generate text token by token.
Diffusion LLMs refine an entire block of text over multiple denoising steps.
1
242
Jun 13
Spent the past two days learning and testing new @googlegemma DiffusionGemma 26B on the new WIP llama.cpp diffusion branch (PR #24427)on my 3060.
Unlike traditional LLMs that generate one token at a time, DiffusionGemma generates a whole block of tokens and repeatedly refines it over multiple denoising steps.
Setup:
- RTX 3060 12GB
- diffusiongemma-26B-A4B-it-Q4_K_M.gguf @UnslothAI quant
- `-ngl 15` (anything higher OOM)
- Peak VRAM: ~10.4GB
Prompt: "Write a Python quicksort implementation"
512-token generation (2 diffusion blocks):
12 steps -> 12.1s (42.4 canvas tok/s)
18 steps -> 17.9s (28.6 canvas tok/s)
24 steps -> 24.2s (21.2 canvas tok/s)
32 steps -> 32.0s (16.0 canvas tok/s)
48 steps -> 37.2s (13.8 canvas tok/s)
A few observations:
- Lower step counts were noticeably worse in quality
- Denoising cost stayed almost perfectly flat at ~0.5s/step
- Peak VRAM stayed around 10.4GB across all runs
- It's not that bad even with offloading most to cpu
- Diminishing returns started appearing around the 24–32 step range
Still early days, but it's pretty wild seeing a 26B diffusion language model running locally in llama.cpp

Jun 11

New @googlegemma DiffusionGemma diffusiongemma-26B-A4B-it-Q4_K_M doesn't fit on my RTX 3060 12GB out of the box. But i tried anyway.
Using the new WIP llama.cpp diffusion branch, I got it running with `-ngl 15` and started testing multi-block generation.
So far:
• 26B model running locally
• 512-token diffusion generation works
• 1024-token generation OOMs on 12GB VRAM
• ~0.53s per denoising step on my setup
Pretty fun to be testing diffusion language models in llama.cpp already.
4
4
29
7,550

Jun 13
👨💻▶️ Implémentation interactive ET certification d'un algorithme de tri (quicksort) avec Lean.
youtube.com/watch?v=RmZy2mSi…
19


Jun 12
in XNU apple uses a label with a corresponding goto in their quicksort implementation to avoid stack hungry recursion. Absolutely awesome.

14

Jun 10
if quicksort comes up in my exam i’m fr gna walk out i do not understand that shit at all and i’m not memorising the pseudocode for it either

1
9
253

Jun 10
If you suspect AI, you can't ask the obvious questions. You have to be careful. You drop a sudden "quicksort an array for me in #kotlin" or You ask for 234345 × 213342.
My favorite: switch languages mid-sentence or next sentense — AI speaks all of them
1
2
125

Jun 10
I see no reason for the software produced by AI to be much different than what a solid human engineer could build. It's just aping us, after all, and a quicksort is still quicksort no matter who writes it.
But AI is demonstrating that it can make us considerably faster at building software.
I think the wave that hasn't hit yet is the weird new types of software we get. More products will not just be constructed by AI, but will have AI features more prominently within them. In 10 years, the internet itself will be absent of humans - it will be for agents to roam around in on behalf of humans, while the users look at a JIT generated UI that is anything they want it to be.
The other wave that hasn't hit is all the security issues we're about to faceplant into. 😅
Jun 9

every week I become a little bit more of a "if LLMs are 10x better at writing software, where is all the 10x better / faster software" truther
1
1
306

Most developers use sorting algorithms daily without thinking about them.
But there's a reason quicksort dominates in practice despite O(n²) worst case.
Cache locality beats theoretical complexity every time.
Your CPU cares more about memory access patterns than Big O notation.
27

Of course !!!
The memory system need a deeply redesign in order to reduce the latency. Heap sort is 3 times slower than quicksort, mainly due to quicksort is cache friendly and heap sort not
1
29

Jun 8
But the query was fast in development and staging!?!
What are the signs to look for that you've created a query that is fast locally, but needs performance considerations in production?
There are two inflection points where a simple query gets meaningfully slower:
1) When the sort spills out of memory
2) When the table scan moves to disk
The examples below are in resource constrained environments, but the pattern of behavior and output is similar to what you'd see even in larger environments, only with much, much larger numbers of rows.
A simple query
```sql
SELECT user_id, event_type, created_at
FROM events
WHERE user_id = 1
ORDER BY created_at DESC
```
Without an index, Postgres must scan the entire table to find the user's events even if there are only a few rows (Narrator: if there are zero rows for a user, Postgres may choose not to scan any rows due to table and column statistics, which we talked about a while back).
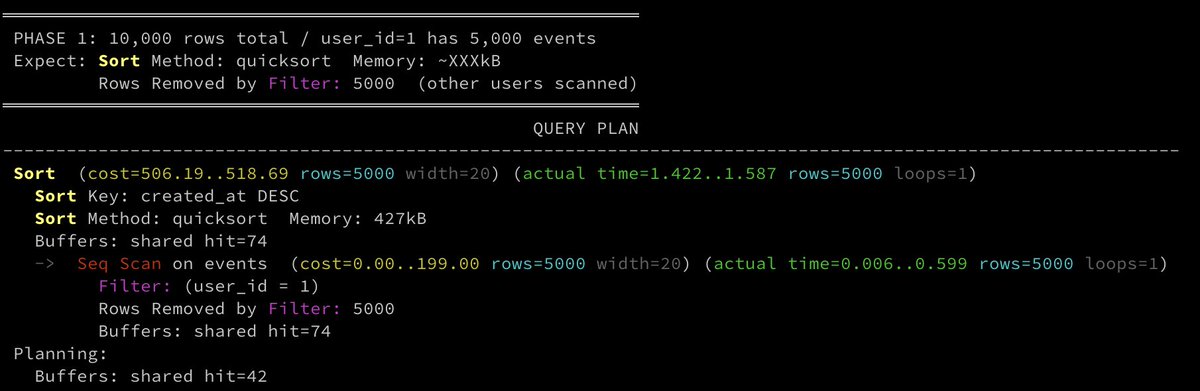
Phase 1) everything fits in memory
With 10,000 rows, and user_id=1 has 5,000 events, and `work_mem = 1MB`:
```
Sort (cost=506.19..518.69 rows=5000 width=20) (actual time=1.422..1.587 rows=5000 loops=1)
Sort Key: created_at DESC
Sort Method: quicksort Memory: 427kB
Buffers: shared hit=74
-> Seq Scan on events (cost=0.00..199.00 rows=5000 width=20) (actual time=0.006..0.599 rows=5000 loops=1)
Filter: (user_id = 1)
Rows Removed by Filter: 5000
Buffers: shared hit=74
```
• `Sort Method: quicksort Memory: 427kB`: the 5,000 rows are sorted in RAM
• `Rows Removed by Filter: 5000`: the other 5,000 rows were scanned and discarded
• `Buffers: shared hit=74`: all 74 table pages were in shared_buffers
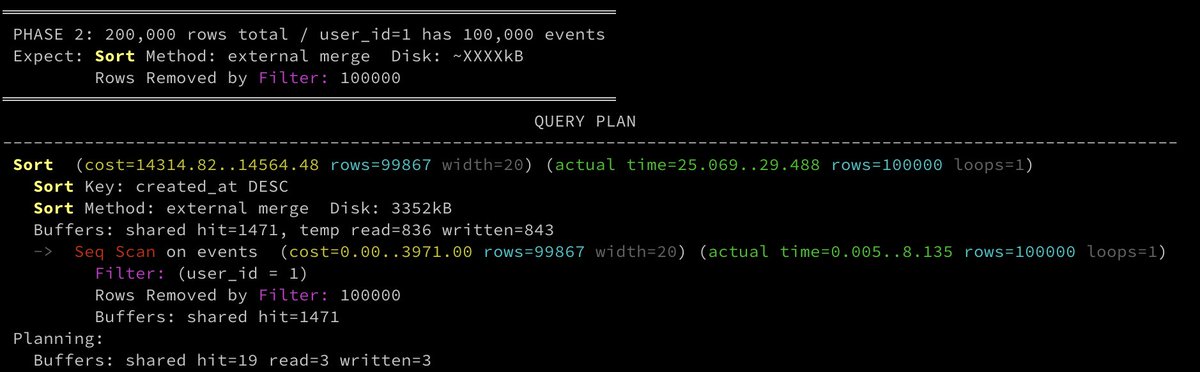
Phase 2) sort spills to disk
With 200,000 rows. and user_id=1 now has 100,000 events, and `work_mem = 1MB`, the sort keys for 100k rows no longer fit in memory:
```
Sort (cost=14314.82..14564.48 rows=99867 width=20) (actual time=25.069..29.488 rows=100000 loops=1)
Sort Key: created_at DESC
Sort Method: external merge Disk: 3352kB
Buffers: shared hit=1471, temp read=836 written=843
-> Seq Scan on events (cost=0.00..3971.00 rows=99867 width=20) (actual time=0.005..8.135 rows=100000 loops=1)
Filter: (user_id = 1)
Rows Removed by Filter: 100000
Buffers: shared hit=1471
```
• `Sort Method: external merge Disk: 3352kB`: 3.3MB spilled because 100k rows × ~20 bytes > 1MB `work_mem`
• `temp read=836 written=843`: 843 temp pages written to disk and read back during the merge
• `Rows Removed by Filter: 100000`, but scanned prior to sort
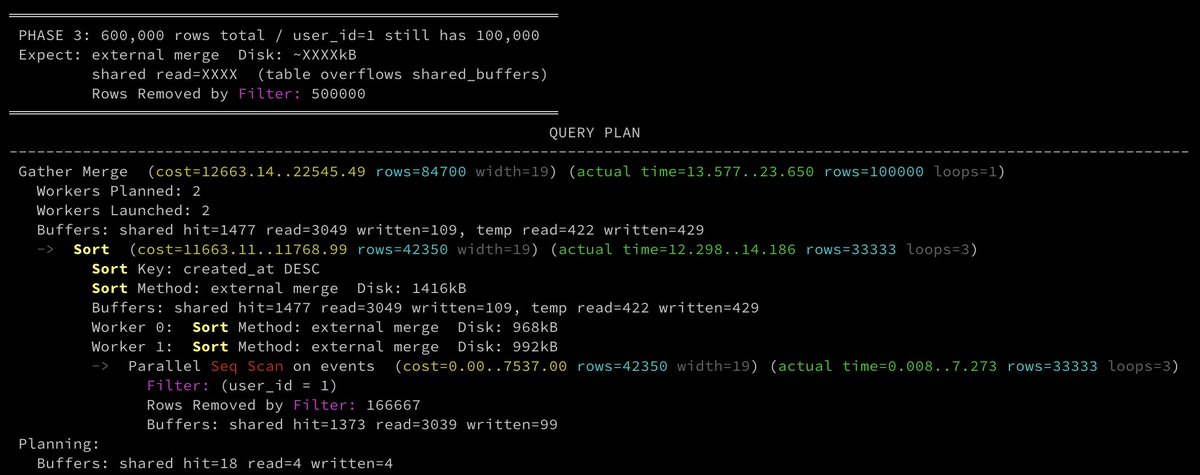
Phase 3) table scan moves to disk
600,000 rows total. user_id=1 still has 100,000 events. The other 500,000 rows belong to other users and Postgres scans all of them anyway. The table now overflows shared_buffers (16MB = 2,048 pages; table is ~4,412 pages).
```
Gather Merge (cost=12663.14..22545.49 rows=84700 width=19) (actual time=13.577..23.650 rows=100000 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=1477 read=3049 written=109, temp read=422 written=429
-> Sort (cost=11663.11..11768.99 rows=42350 width=19) (actual time=12.298..14.186 rows=33333 loops=3)
Sort Key: created_at DESC
Sort Method: external merge Disk: 1416kB
Buffers: shared hit=1477 read=3049 written=109, temp read=422 written=429
Worker 0: Sort Method: external merge Disk: 968kB
Worker 1: Sort Method: external merge Disk: 992kB
-> Parallel Seq Scan on events (cost=0.00..7537.00 rows=42350 width=19) (actual time=0.008..7.273 rows=33333 loops=3)
Filter: (user_id = 1)
Rows Removed by Filter: 166667
Buffers: shared hit=1373 read=3039 written=99
```
The planner launched 2 parallel workers which means it ran faster by splitting the seq scan and sort across 3 processes. Each worker sorted ~33k rows instead of 100k, so each spill was smaller.
The things to be concerned about here are:
• `shared read=3049`: the table overflowed shared_buffers; 3,049 pages were read from disk
• `Rows Removed by Filter: 166,667 × 3 workers = 500,001`: 500k rows scanned and discarded
• All three sort operations still spilled: parallel didn't eliminate the sort, just distributed it
Solution
The solution to this problem should be driven by the needs of the application it serves. In most simplistic terms, an index on events (user_id, created_at DESC) would reduce sort load. However, solutions may also include application-level caching, a materialized view, or table partitioning.
4
12
633

14 MIPS assembly benchmarks covering everything from basic arithmetic to recursive fibonacci, quicksort, and matrix multiplication. Pipeline flushes on branch misprediction, data forwarding on all bypass paths, and full RAW/WAR/WAW hazard resolution.
1
11

Jun 7
QuickSort Algorithm visualization. Watch how a chaotic array is rapidly organized through recursive partitioning. An elegant O(N log N) dance of data sorting.
#Algorithms #ComputerScience #DataStructures
3
72

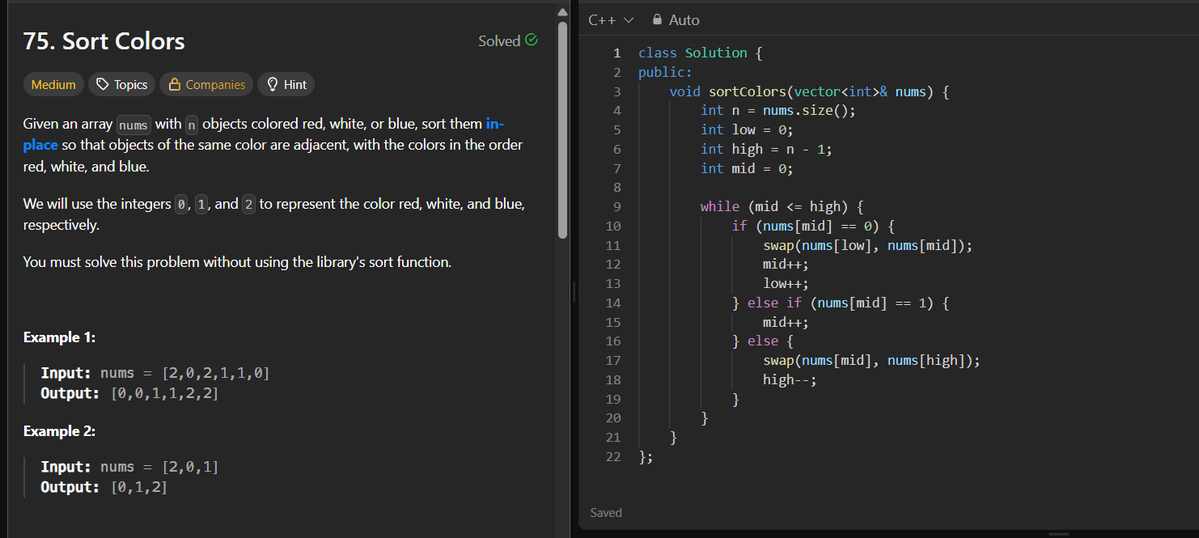
Day 2 completed ✅
Basic standard questions: 3-way quicksort partitioning, Kadane's algorithm, and a slightly medium buy-sell-stock
Little behind due to laptop repairs
#SDESheetChallenge @striver_79 @takeUforward_ @OrionAnkit

1
19
240



Jun 4
I think my favourite part of my early uni classes was where the lecturer prompted us (with no guidance) to make a sorting algo on the spot and people invented bubblesort/insertionsort/selectsort and he walked us through computational complexity of them b4 showing quicksort
1
1
12
1,317

May 30
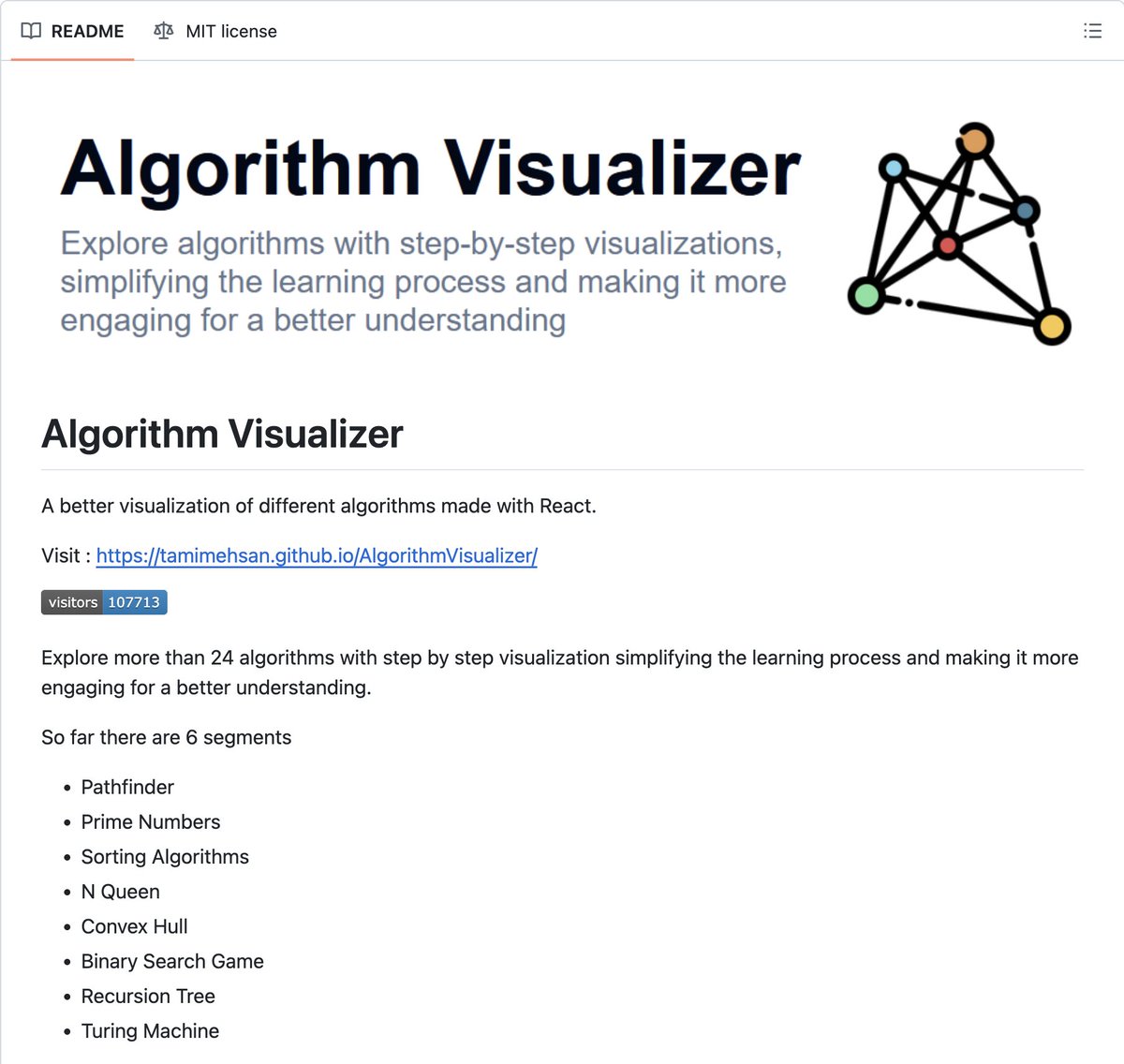
A GUY JUST OPEN SOURCED A VISUAL CS DEGREE.
24 algorithms. 8 categories. Every one animated step by step in your browser. Free. MIT licensed. No login.
It's called Algorithm Visualizer.
AlgoExpert charges $99/year. LeetCode Premium is $35/month. Coursera DSA specializations run $400 . CS bootcamps charge five figures to teach exactly what's in this one repo.
This runs in a browser tab. Today.
What's actually in it:
→ Pathfinder with DFS, BFS, Dijkstra, A*, and recursive maze generation
→ Sorting: bubble, selection, insertion, heap, merge, quicksort — all animated
→ N Queen backtracking, frame by frame
→ Graham Scan for Convex Hull
→ Sieve of Eratosthenes
→ Archimedes Spiral that shows why primes form patterns
→ Binary Search built as a game
→ Recursion trees for Fibonacci, Binomial Coefficient, Derangement, Stirling Numbers
→ A working Turing Machine running NOT, increment, and 2's complement
Here's the wildest part:
Most paid algorithm courses skip the hard stuff. They give you sorting and call it a day.
This one has a Turing Machine. In a browser. Animated.
The thing every CS professor mumbles through at the blackboard while half the class checks Instagram — it's right here, running, with a play button.
Built by Md. Tamimul Ehsan. BUET grad. Currently a Software Engineer II at Optimizely working on agent orchestration.
He's not selling a course. There's no Patreon. No Substack waitlist. The README literally just says "if you like this please star this repo. It keeps me motivated."
315 stars. 98 forks. 34 commits. MIT License. Migrated to Next.js with shadcn in December 2024. Still actively maintained.
One honest note: this is a learning tool, not a textbook. You won't read 400 pages on amortized analysis here. But you'll see the algorithms move, which is the part textbooks fail at.
Every aspiring engineer believes the barrier to understanding algorithms is an expensive course. That belief is the only thing the paid courses are actually selling.
Link in the comments.
2
15
35
3,016

May 30
JavaにはJDK7から2種類のソートアルゴリズムが実装されている。安定性が不要なプリミティブ向けにDual-Pivot QuickSort、安定性が必要なオブジェクト向けにTimSort。今やレガシーなQuickSortやMergeSortは使われていない
1
5
13
1,377

May 25
si conoces mas de 5 sos un chadazo
archive.siam.org/pdf/news/63…
de los nombrados del siglo XX conocia nomas
* monte carlo
* simplex
* quicksort
* fft
* qr (caja negra)

1
18
1,066