
Yeah for those, you can usually give them your quote. Like how much you would be willing to accept the assignment for.
If you want actual BPOs, you have to sign up through REO portals.
There’s a few. Equator, ResNet, UsBank etc.
I would type those 3 into Calude and see if they can direct you to a signup page for agents
6

👀Got some requests to post this great paper review in English - fulfilling.
🤯Have We Finally Found Adam's Successor?
👽There are very few things in deep learning that have remained largely unquestioned for an entire decade. Adam is one of them.
Since 2014, countless papers have tried to replace it. Some promised faster convergence, others lower memory usage, and some showed impressive results on specific models. Yet when researchers train real systems, most still return to Adam or AdamW.
The reason is simple: outperforming Adam on one metric is easy. Matching it across all the metrics that matter is much harder.
This is where Gefen, a new optimizer by @nadavbenedek (Reichman University), Tomer Koren (Tel Aviv University and Google), and Ohad Fried (Reichman University), enters the picture.
The goal sounds almost impossible: keep Adam's performance, hyperparameters, and ease of use, while dramatically reducing its memory footprint.
According to the paper, they succeed.
Gefen reduces optimizer memory by 8x compared to AdamW while maintaining comparable performance across language and vision models, including GPT-2, Llama 3, and ResNet. In large-scale training, where optimizer states consume a substantial fraction of GPU memory, this can be transformative. Freed memory can be used for larger models or larger batches. In one experiment, the increased memory budget doubled the microbatch size per GPU and improved training throughput by 56%.
How does it work?
Adam stores two statistics for every parameter: a first moment (a running average of gradients) and a second moment (a running average of squared gradients). These statistics drive Adam's success, but they are also responsible for most of its memory consumption.
The paper's key theoretical result shows that when two parameters are strongly coupled through the Hessian, the ratio of their squared gradients tends toward one. In practical terms, their second-moment statistics become very similar. If two parameters repeatedly produce nearly identical squared gradients, storing separate second-moment estimates becomes wasteful.
Gefen therefore groups parameters and lets them share second-moment statistics. Instead of storing billions of independent values, a single value can represent an entire block of parameters.
Computing Hessians directly would be infeasible, so the authors infer these groups from the squared-gradient patterns observed during the first training step. The process is automatic and requires no architectural knowledge or manual tuning.
To reduce memory further, Gefen compresses the first moment using 8-bit quantization. Unlike most quantized optimizers, which rely on handcrafted codebooks, Gefen computes an optimal codebook using dynamic programming on a histogram of gradient values.
The result is a true drop-in replacement for AdamW: no new hyperparameters, no learning-rate retuning, and substantially lower memory consumption.
Will it replace Adam? It is too early to say. But it is one of the strongest attempts in years to preserve everything practitioners like about Adam while returning most of the memory it consumes.
Paper: arxiv.org/pdf/2606.13894
Code: github.com/ndvbd/Gefen

2
4
410

Kiklo.eu retweeted

📘Automatic Annotation of #Map Point Features Based on Deep Learning ResNet Models
By Yaolin Zhang, Zhiwen Qin, Jingsong Ma, Qian Zhang and Xiaolong Wang
👉See the paper: mdpi.com/2220-9964/14/2/88

1
1
39

Jun 14
都说现代ai都是华人在干,但是要数原创性的研究工作,deeplearning我只认何凯明的resnet,LLM嘛也就姚顺雨的ReACT!
1
1
440



Jun 14
mixing is a wrong metaphor IMHO because they are only per token same with Microsoft-China (aka ResNet) connections. The only mixing is attention. And obviously all frontier LLMs hack this a lot, especially for agentic rollouts. Same with profile/sampling separation.
1
4
2,170

Jun 13
Stepfun在努力,恭喜 张祥雨老师和孙剑老师的论文 ResNet 获得CVPR2026 Longuet-Higgins Prize (时间检验奖)!
阶跃 Step 3.7 Flash 拿下 Artificial Analysis 多个第一!
搭车招人!!
PS: 我不是男娘,我是研发工程师,不是hr/运营!!!!!!welcome to talk!!!

96

Building AI-assisted ultrasound interpretation for under-resourced clinics in Kenya, Kenya has roughly 1 radiologist per 270,000 people, so most rural areas have zero coverage. We've got a working biometry model (ResNet-18 on HC18 data), backend mobile app in progress.
20

Jun 12
Great read. Yes the zero padding of the 3x3 conv in ResNet (and ConvNeXt etc) is actually what makes a convnet LESS good to use in a sliding manner than a ViT, which sounds crazy at first!
1
9
1,796

Jun 12
Noci et al. explicitly cited Stable Resnet paper and acknowledged the overlap, whereas this work did not. That said, both papers are interesting contributions.
1
192

I don't think it's a grand conspiracy or anything, just that we seem to have created an odd ahistorical narrative where we're a bit bored of summer internationals altogether and resnet having to go play them.
I resent the bloody lions, to be frank, don't care about 'em...
1
1
35

データが少なく、リアルタイム性が求められる画像認識プロジェクトで選定に迷っている企業担当者へ
ResNetは残差学習で深層化を安定化させ、主要フレームワークやエッジチップで最適化済み。独自データが10万件未満や推論10ms以下の現場では最も高いROIを実現する傾向がある。
最新モデルへ移行すべきか、ResNetを極限まで最適化して運用すべきか、どちらが事業に合理的だろうか?ai-market.jp/technology/what…
1
1
24

最新モデルに移行すべきか悩む経営・開発担当へ
ResNetは2026年でも推論速度とROIの最適解。独自ドメインで学習データが10万件未満、または推論レイテンシが10ms未満の現場では特に有利で、エッジ最適化も成熟済み。
まずはデータ量とレイテンシ要件を基準に検討してみては?ai-market.jp/technology/what…
1
40
studyforever retweeted

Jun 11
训练神经ODE这种连续深度模型,理论分析常是黑盒——我们不知道学习动力学到底怎么演化。不理解这点,就难设计可控训练策略,也没法把结论推广到ResNet、自回归等常见架构。这篇论文从统计物理引入动态平均场理论(DMFT),在高维极限下把多体相互作用简化为单粒子过程,通过自洽方程精确求解在线SGD的学习曲线,首次为神经ODE提供了从前向传播到训练误差的解析刻画。
arxiv.org/abs/2606.07247
3
12
492

Jun 11
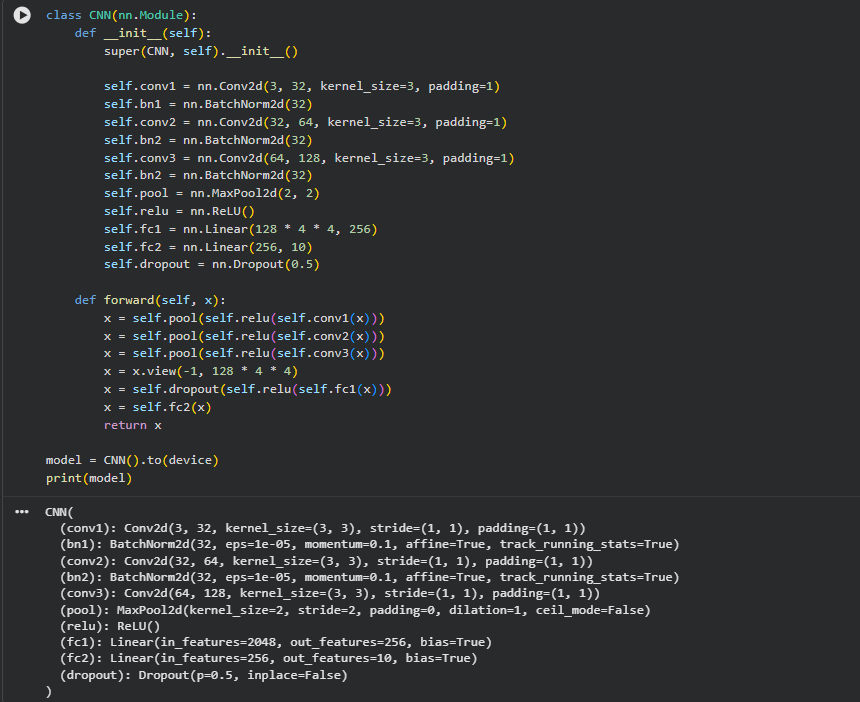
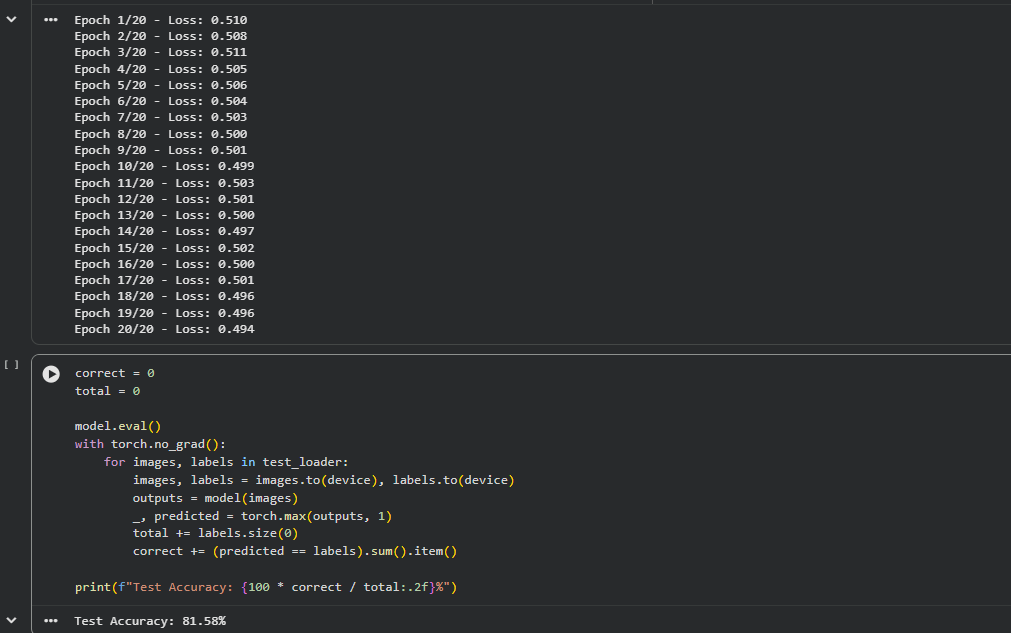
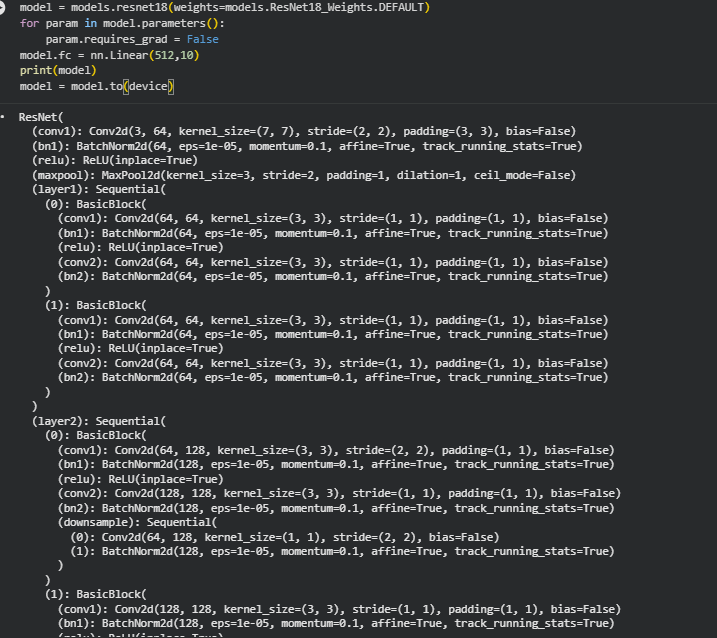
Day 12 -Worked on CIFAR-10 in PyTorch today. Added batch normalization and data augmentation to my CNN, improved its accuracy to ~81%.
Also tried a pretrained ResNet-18 and learned more about transfer learning.
#Day12 #ADAS #Pytorch #ComputerVision
3
29

Jun 11
1/5: Robustness to Input Corruptions
We evaluate pretrained models on corrupted vision and language data: ImageNet-C and FineWeb10B-C.
Across ResNet, ViT, GPT-2, and GPT-2 Medium, Muon achieves the best overall robustness, suggesting that Muon learns more corruption-resistant features.

1
1
2
325

Jun 10
■DenseNetとは?
前に見つけた特徴をみんなで使い回すCNN
✅ResNet
前の情報を一部ショートカットして後ろへ渡す
✅ DenseNet
過去の情報をどんどん共有。そのため、画像の特徴をムダなく使えて、
少ない計算でも学習しやすくなる
#AI
#G検定
#今日の積み上げ_892

2
45