
Jun 11
🚀 Just built A Spring Boot REST Client integration from scratch!
As a beginner, I implemented all 4 CRUD operations using Spring's new RestClient API:
Followed Springboot Traditional Project Structure
📦RestClient.RestClient
├── ⚙️ config
├── 🎮 controller
├── 📦 entity
├── 🚨 exceptions
├── 🛡️ handler
└── 🔧 service
✅ GET — Fetch a resource
✅ POST — Create a resource
✅ PUT — Update a resource
✅ DELETE — Delete a resource
Used JSONPlaceholder for Testing Api and to test the data.
And also implemented:
🔴 Custom Exception Handling
🌐 Global Exception Handler with @ControllerAdvice
📦 Clean separation with Controller → Service → Config layers
💡 RestClient is Spring's modern way to call external APIs —
cleaner, simpler, and more readable than the old RestTemplate!
Key learnings:
• Rest Client is cleaner and more intuitive than Rest Template
• Always separate your base URL from URI paths
• Global exception handlers make APIs production-ready
• Small bugs teach the biggest lessons 💡
🚨 What happens when a user requests a Todo that doesn't exist? Bad API → returns a confusing 500 error ❌
Good API → returns "Todo with id {id} not found"
✅ This is how I handle it in Spring Boot using:
✅ RestClient's onStatus()
✅ Custom Exception class
✅ Global Exception Handler Small details make great APIs! 🚀
#SpringBoot #Java #REST #API #Learning #BackendDevelopment
1
40

May 30
今から話す資料です! #jjug_ccc #jjug_ccc_c #jjug_ccc_cd
RestTemplate非推奨化に備えよう!RestClient入門、そしてリニューアルされたSpring Retryでリトライして、WireMockでテストする。 | tada #docswell
docswell.com/s/MasatoshiTada…
20
33
4,243

📢JJUG CCC 2026 Spring セッション紹介📢
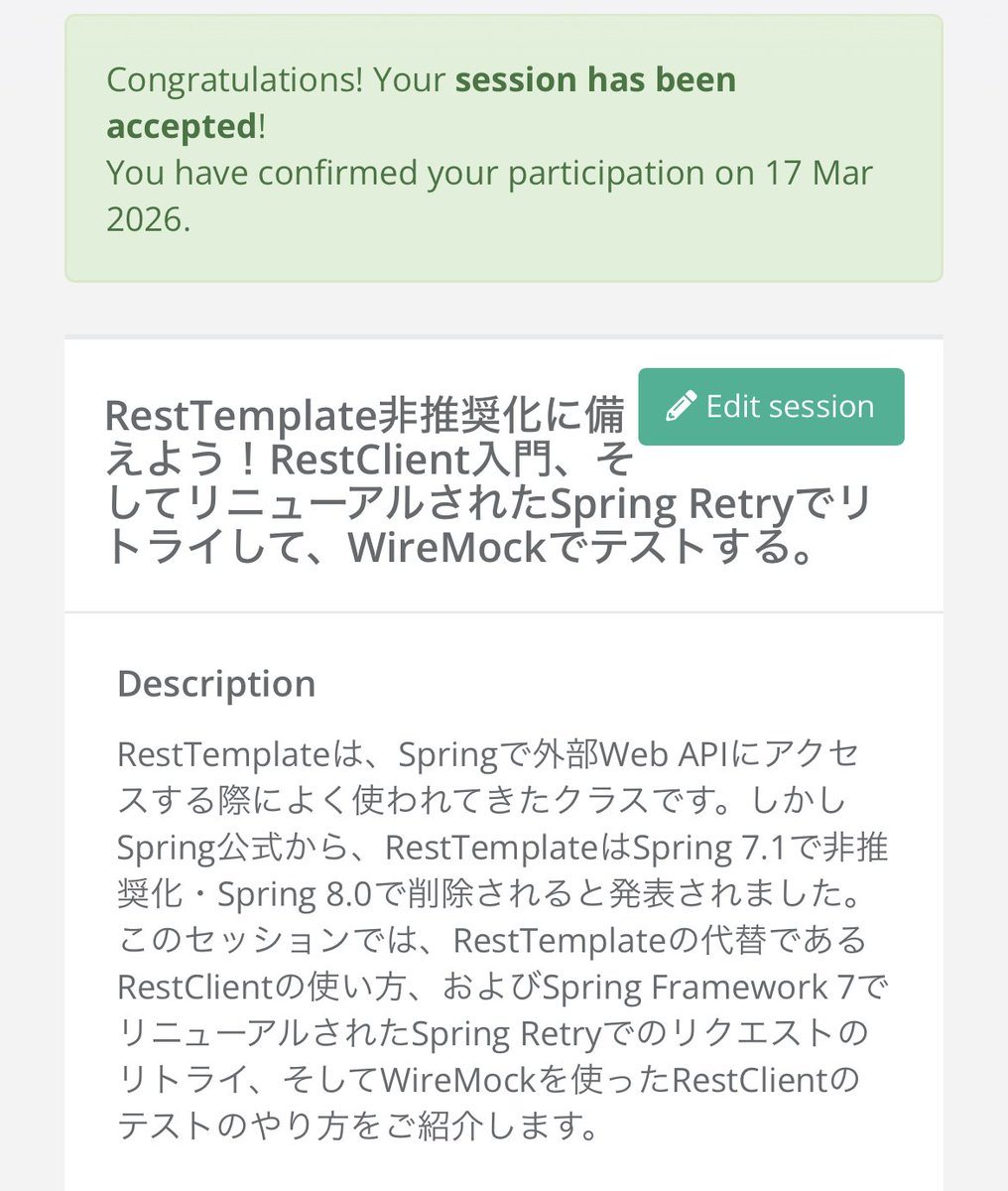
「RestTemplate非推奨化に備えよう!RestClient入門、そしてリニューアルされたSpring Retryでリトライして、WireMockでテストする。(10:00〜 Room CD)」Masatoshi Tadaさん
🎟️参加登録:x.gd/WL6eb
#jjug_ccc
6
9
1,192

In Spring Boot you now have the preferred RestClient; the replacement for RestTemplate. A great many applications has no need for WebClient with netty as a backend, no need for handeling back-pressure since there is no real back-pressure.
2
49
May 6
10:00から「RestTemplate非推奨化に備えよう!RestClient入門、そしてリニューアルされたSpring Retryでリトライして、WireMockでテストする。」というセッションします!ぜひ来てね。 #jjug #jjug_ccc

JJUG CCC 2026 Springのタイムテーブルを公開いたしました!みなさまが期待しているセッションがいつ行われるのかをご確認ください!
sessionize.com/api/v2/x15nre…
参加登録はこちらから:
jjug.doorkeeper.jp/events/19…
#jjug #jjug_ccc
4
14
3,068

May 5
🧵 THREAD: RestClient vs WebClient vs RestTemplate. These three names get thrown around constantly in Spring discussions, but they are not interchangeable, and choosing the wrong one creates unnecessary complexity fast.

1
2
11
548

Apr 28
My top 3 API testing VS Extention right now.
1 LiteClient
2 RestClient
3 ThunderClient
Smooth DX, no need to create accounts, ability to commit docs to GitHub more features.
3
49

Apr 26
RestClient/RestTemplateレイヤーで透過的にCircuit Breakerを導入したかったのでClientHttpRequestInterceptorを作った。
github.com/making/circuit-br…
1
7
846

Apr 14
The Night the Ledger Held Its Breath
2:17 AM, Tuesday. The payments cluster was quiet. Too quiet, honestly.
Buried in our Spring Boot mesh sat a service called Ledger Orchestrator, the middleman for high-value transactions between risk engines, fraud checks, and settlement. It made most of its calls through Spring's RestClient.
That night, a downstream fraud service quietly started dragging its feet. No 500s, No alerts, No pager, just responses that took a little longer, and then a little longer than that.
The Orchestrator didn't know any better. It kept dialing out, kept opening sockets, kept trusting the network. The catch? Nobody had ever set a connect timeout on the client.
RestClient was happy to sit on a half-open TCP handshake more or less forever. Threads stacked up. The pool jammed. CPU looked fine on the dashboards, which was the cruel part. From the outside everything looked healthy but inside? the service was running out of air.
By 2:26 the latency graphs were vertical. A $2M transfer was just stuck. Retries kicked in, because retries always do, and each one spawned another connection that was also going to hang.
The system wasn't failing fast, it was failing in slow motion, and not telling anyone.
Ralph got the page. He'd seen this shape before. No exception storms, just quiet paralysis. He opened the config, scrolled for thirty seconds, and there it was: read timeout set, connect timeout missing. The service was technically allowed to wait forever before it even started talking.
Fix on the spot? Connect 2s, Read 5s. Retries capped with backoff. Rolling restart.
Almost instantly, hung calls started failing cleanly, circuit breakers tripped, load shed itself and the platform exhaled.
A connect timeout isn't a nice-to-have. It's the line where your service admits the network might not be there. Skip it, and you're assuming every hop between every region and every cloud is going to behave. In finance, that assumption will bite you. It's just a question of when.
RestClient is a nice piece of engineering. It won't save you from your own defaults.
Ralph's writeup the next morning had one line everyone remembers:
"Systems don't fail because of big bugs. They fail because of small waits."
In distributed systems, the scariest thing isn't an error in the logs. It's silence.
2
2
5
63
Apr 13
Spring Framework 7.0.7からRestClientでMockRestServiceServerを使えるようになった(個人的には使わないけど)。
github.com/spring-projects/s…
5
17
3,963

A Guide to RestClient in Spring Boot: buff.ly/6mXDcNy
2
25
1,705

Mar 26
Spring's RestClient throws exceptions on HTTP errors by default, but you need a strategy for handling them gracefully. Here's how to get started with error handling best practices.
youtu.be/MuYzEZk6-zI

1
19
99
4,829
Mar 17
2
29
931

Spring AI Tip 💡
Running local AI models with LM Studio (lmstudio.ai/) and seeing connection hangs when your Spring AI app calls the OpenAI-compatible API?
LM Studio doesn’t support HTTP/2, which causes the request to stall.
✅ Fix: disable HTTP/2 for 🍃RestClient.

11
96
6,186

Feb 27
I can barely get people to look at my packages. It’s completely dead for me these days. I’ve barely had over 1k downloads for the latest version of RestClient .Net. Very demotivating
7
424

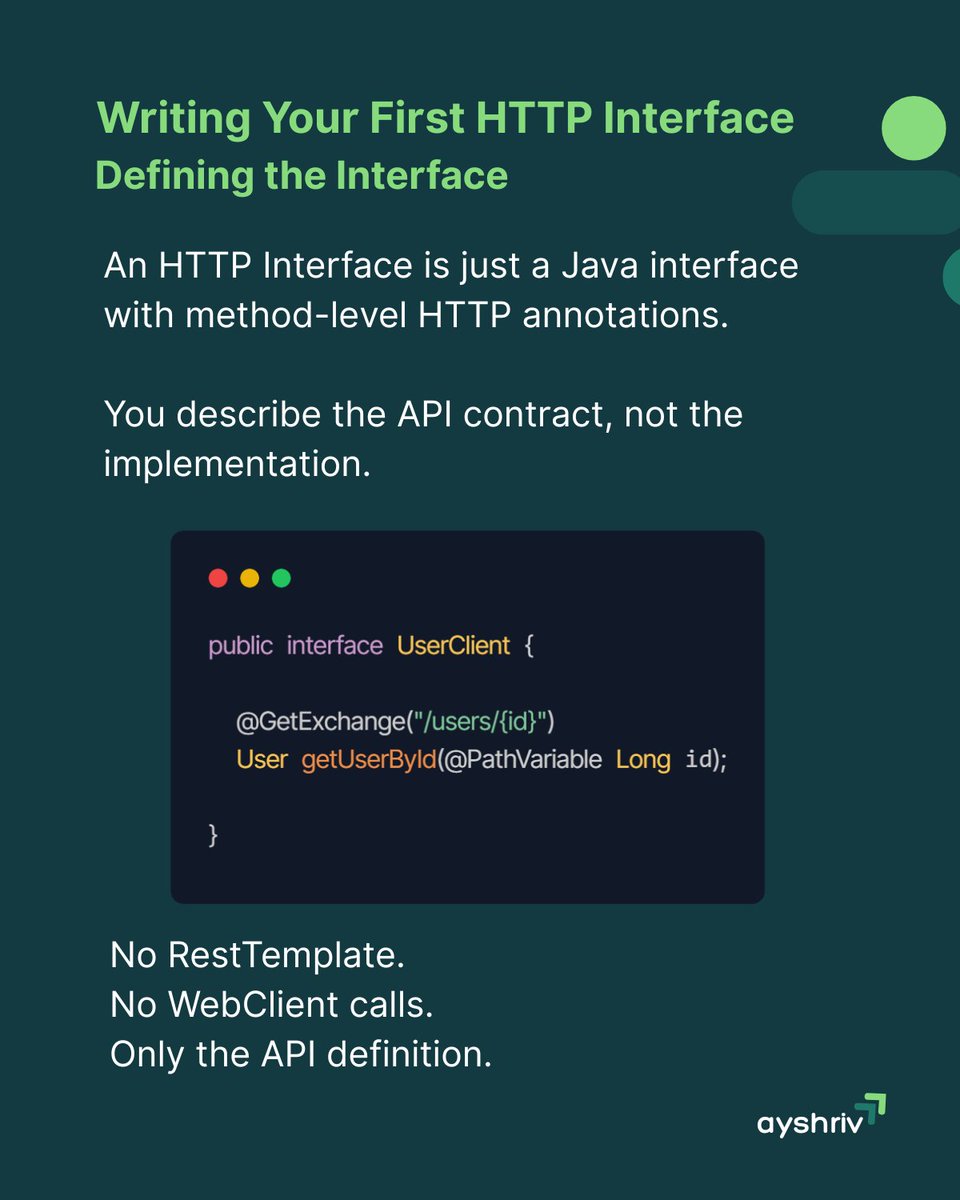
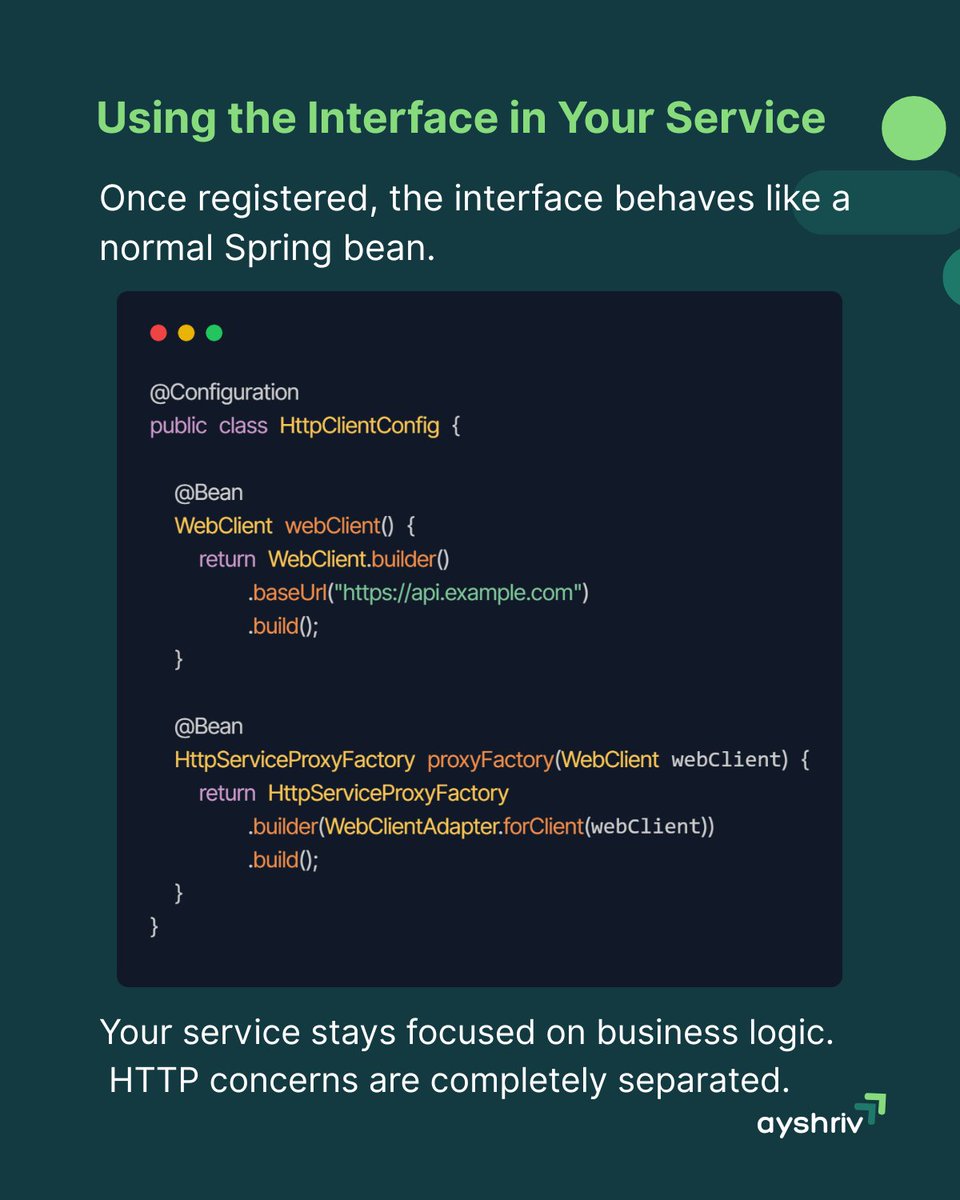
Spring Boot HTTP Interfaces let you define REST calls as pure interfaces.
No implementation class.
No HTTP boilerplate.
Just method annotations. Your service layer stays clean and focused on business logic.
#SpringBoot #Java #RESTClient #Backend #ayshriv #Architecture
2
6
49
1,847
Feb 3
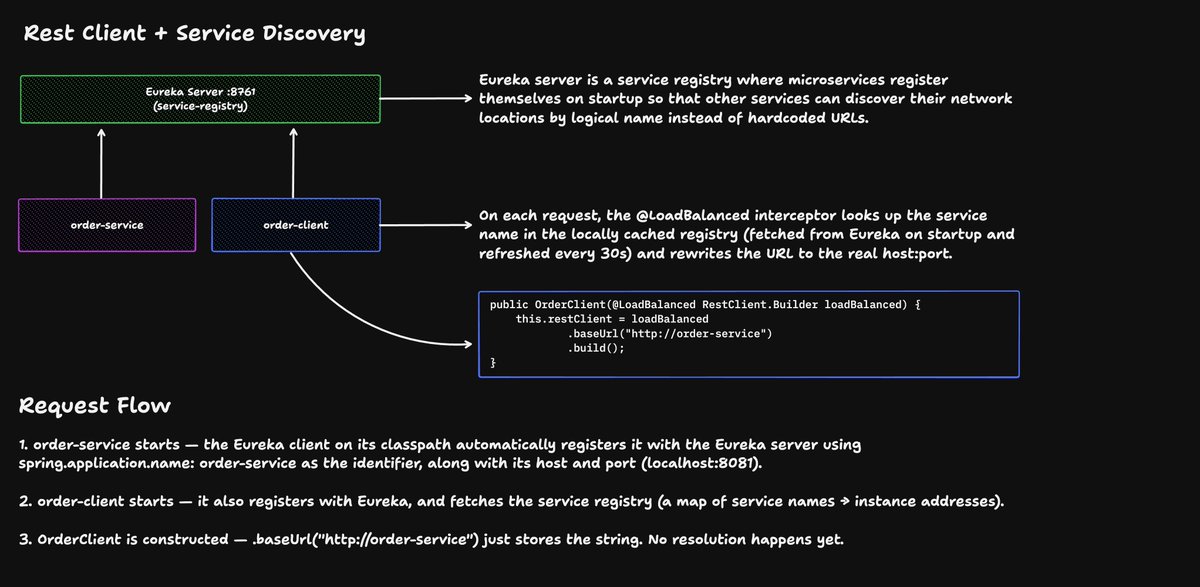
Service discovery with Spring Cloud Netflix Eureka 🎯
Instead of hardcoding URLs between microservices, services register with Eureka and discover each other by name. The LoadBalanced RestClient handles the magic of resolving "http://order-service" to the actual host:port.
1
6
64
2,827

Jan 16
ソースのみ。解説はいつか書く。たぶん。
Spring BootのRestClientでWeb APIクライアントを作る+WireMockでテストする|Masatoshi Tada zenn.dev/masatoshi_tada/arti… #zenn
1
8
414
Jan 16
原因はサッパリだけど、とりあえず解決はしたという記事。
RestClient WireMockで一部のテストだけ失敗する現象+対策|Masatoshi Tada zenn.dev/masatoshi_tada/arti… #zenn
1
2
3
1,010