
10 Dec 2025
🚀 A rare paper that finally explains why RL sometimes works—and why it often doesn’t.
This paper offers one of the clearest deep dives yet into how reasoning actually develops inside LMs and the results challenge a lot of assumptions in the current RL-reasoning hype cycle.
The authors build a fully controlled training environment (synthetic tasks with explicit DAG reasoning steps), which lets them isolate the causal effect of pre-training, mid-training, and RL, rather than treating them as a black box. And the findings are surprisingly intuitive once seen clearly:
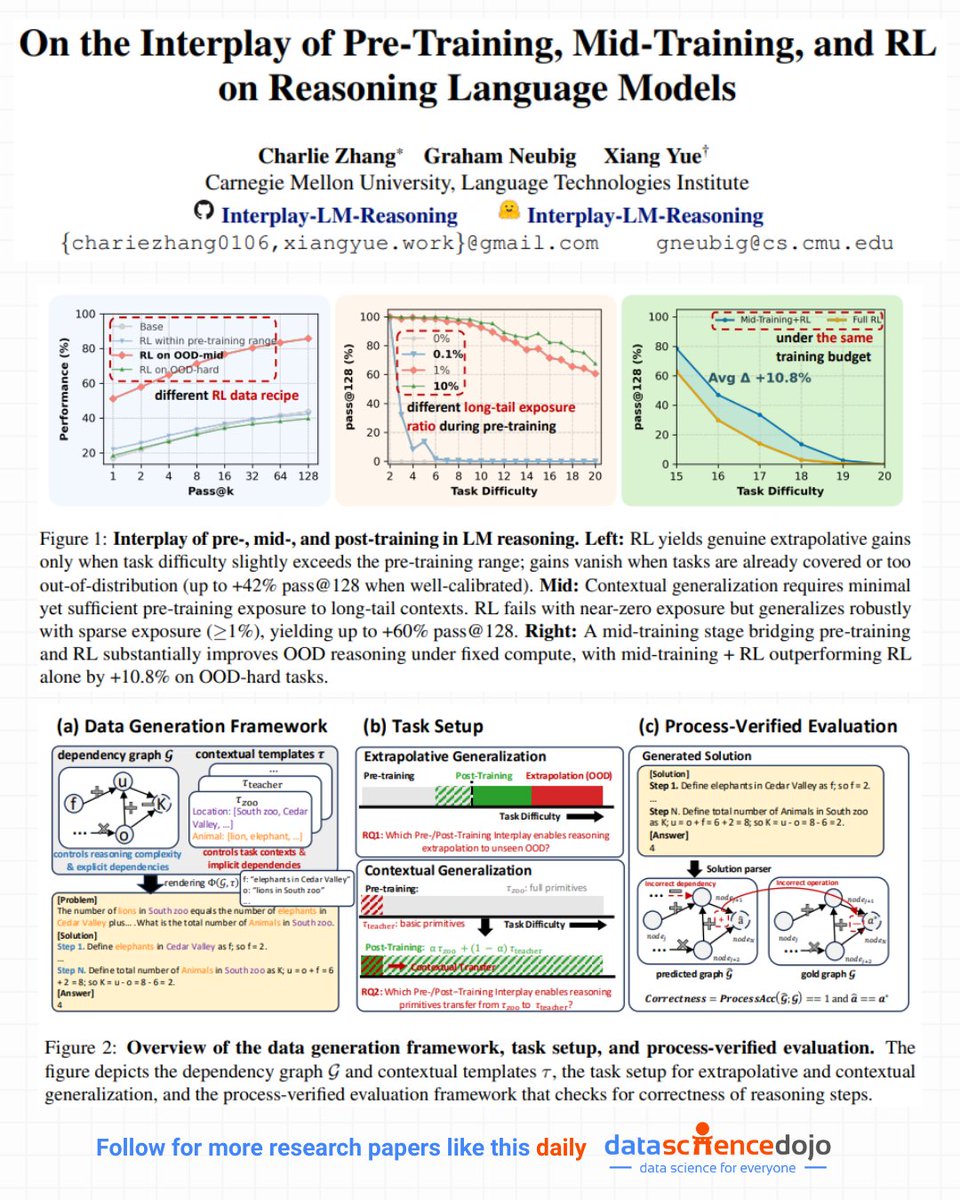
1. RL doesn’t magically create reasoning, it only expands what’s already there.
If pre-training leaves no “headroom” or if RL data is too easy/hard, RL simply sharpens existing abilities instead of unlocking new ones.
2. Minimal exposure during pre-training is enough to unlock contextual generalization.
Even 1% coverage of a new context is enough for RL to transfer reasoning patterns reliably—but 0% exposure means no amount of RL can help. RL can’t conjure primitives out of thin air.
3. Mid-training is a missing piece in many pipelines.
Adding a bridging phase between pre-training and RL drastically improves both in-distribution and OOD generalization, especially under fixed compute. The model becomes far more “RL-ready.”
4. Process-level rewards reduce reward hacking, dramatically.
When rewards check both the final answer and the intermediate steps, models stop exploiting shortcuts and start producing structurally sound reasoning. Pass@1 and pass@128 both improve as a result.
Overall, the work gives a structured explanation of why some RL approaches show huge gains while others plateau: it’s less about clever reward shaping and more about the interaction of all three stages. For teams training reasoning models, this paper is basically a blueprint for designing data curricula and compute allocation more intelligently.
#AIResearch #ReasoningLLMs #ReinforcementLearning #PreTraining #MidTraining #LLMGeneralization #AIAlignment #MachineLearning #AILiterature #DeepLearning
1
1
9
844