
You’re not allowed to use the customers data in an enterprise contract for any kinds of training! You think the contract said no to midtraining but OK for SFT/RL? I’ve seen one, there is no grey area.
And trust me, you do not want to get sued by F500s!
1
1
11
1,938

for this metric, it smells like the former.
as for the original scaled difflib metric from yesterday, that one seems more lenient.
tail knowledge stuff is probably the most reliable *in theory*, but can be brittle in a world with increasingly more synth & specialized midtraining
1
3
113

Jun 14
midtraining and posttraining will never overcome the og coherence of the pretraining distribution, without also losing the capabilities induced by the pretraining distribution, unless it's coherently mixed in with it
1
1
21
Jun 14
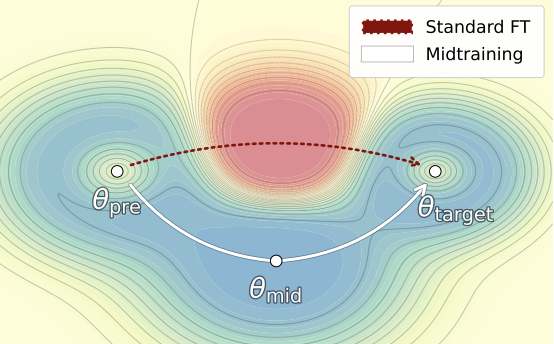
midtraining is important because it makes the laziest path at each step somehow arrive at a better answer than it would have otherwise
it takes the lazy person through the scenic paved route instead of the swamp
1
21

i feel more secure talking to those who left our dept than those who decided to stay. i feel like someone who’s in-between two worlds: 1) finished the training (shared goal w those who had no choice but to leave midtraining) and 2) those choosing to stay snd just suck it up
1
10

Jun 13
their RL methods have replicated way too many times in open source models released since then (both american and chinese ones). if they did in fact distill frontier models as part of the r1 training recipe (e.g. traces for midtraining, claude-as-judge, persobality tuning), then it has already been established that the effect was minimal and it was the least interesting or high leverage aspect of r1.
78

Jun 12
Ah I mean there is pre, mid and post training. I think style actually comes mostly from midtraining and I would be assuming that their datasets are the biggest problem there unfortunately
1
1
76



Jun 11
💡 Step 3: training, in two very different stages.
Midtraining on the corpus teaches the model what human behavior looks like. It shifts length, formatting, and word choice toward the human register.
Then we train one RL expert per benchmark, using verbal feedback from LLM judges where rewards aren't verifiable, and merge all 23 specialists into one model via expert distillation.
Fun ablation: the two stages do different jobs. Midtraining fixes the register; RL drives the benchmark gains.

2
8
1,362

Jun 10
not necessarily - it depends at which point in post-training you branch, and you wouldn't be redoing midtraining/pretraining
1
18

we at @GoodfireAI really appreciate the work you guys do! we've been looking at alternatives to olmo/tulu for mech interp work, and it seems there are still some comparative gaps in the nemotron series; for example, the teacher model suite for the MOPD phase of Nemotron 3 Ultra is unavailable. more partial-run checkpoints - say, between each stage (eg midtraining, SFT, RL, MOPD) - would also be very helpful.
we really appreciate the dedication to open source, not just open weights, and are excited to use nemotron more!
1
15
397
Beff (e/acc) retweeted

Jun 8
training on reddit data. call that midtraining
4
3
70
5,629

Jun 6
my 4yo niece's midtraining corpus consists of ''masha and the bear" and "miss rachel"
we aren't just sample efficient but world models are based on flawed concepts such as talking bears
sucks to be an LLM
13
984

Jun 5
In the case of Composer, the model sees lots of in-context instructions during midtraining. The context changes follow that template, so we are effectively giving it new instructions, which changes it predictions.
6
465

Jun 4
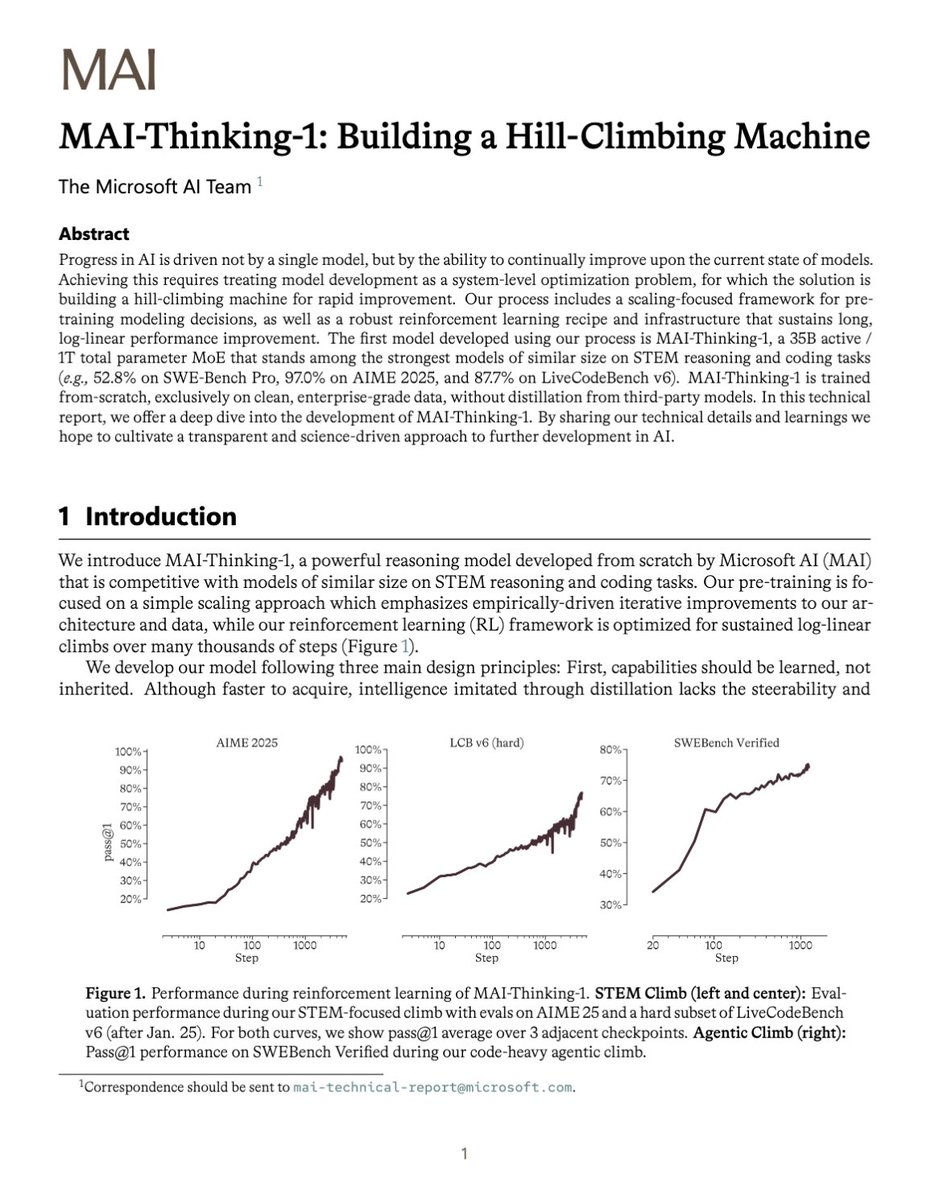
"MAI-Thinking-1: Building a Hill-Climbing Machine"
Microsoft just did something almost no frontier AI lab has done before
They shared how they engineered the data behind a frontier-scale model in unusual depth.
From data collection and eval decontamination, to data mix scaling, this paper lays out how they managed 30T pretraining tokens plus 3.55T midtraining tokens
Surprisingly, they also used no third-party distillation and no open-source training datasets
The model itself is not a jaw-dropping release, but the paper might be the best open look yet at a frontier-scale data factory and hill-climbing loop.
8
34
228
20,797

Jun 3
The new MAI-Thinking-1 model by Microsoft might be good, but the training pipeline they have used is very interesting and valuable for every ML guy.
Here's how they trained MAI-Thinking-1 step by step (in very simple words):
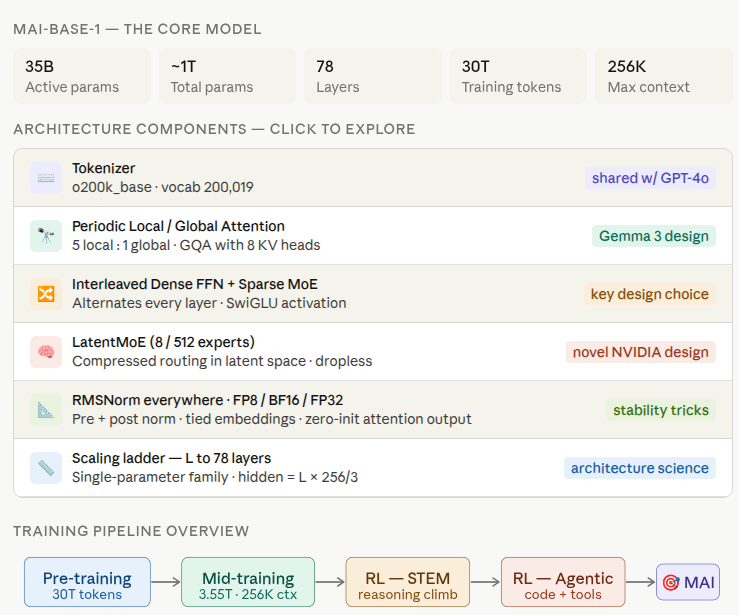
MAI-Base-1 was trained in three phases with progressively increasing sequence lengths: pre-training, midtraining phase 1, and mid-training phase 2.
Phase 1 - Pre-training: 30 trillion tokens, 16K context
30T tokens. No synthetic data. No distillation from other models.
Every byte of data was processed in-house from scratch, web text, books, GitHub code, academic papers, news.
They specifically went out of their way to get rid of AI-generated content from the training corpus.
The philosophy was: intelligence imitated through distillation lacks the steerability needed for long, enduring improvement.
If you want a model that keeps getting better, it has to learn from humans, not copy from other models.
They trained on 8,192 GB200 GPUs with a global batch size of 134M tokens.
The loss spiked a few times early on (they traced it to coding data causing expert routing imbalance), but they never skipped a batch, never touched the config mid-run. Loss recovered every time on its own.
One under-discussed trick: they zero-initialized the attention output projection.
Sounds minor, but here's what happens without it - at the start of training, attention softmax is nearly uniform, so the model does average-pooling over every token.
That makes all token representations look similar, which makes the MoE router send everything to the same few experts.
Collapsed routing cascades through 78 layers and tanks training stability.
Zero-init means the model starts as a pure stack of feedforward layers.
Attention gradually "turns on" over the first few billion tokens, and by then the router has learned a sensible distribution.
Phase 2 - Mid-training 1: 3.4T tokens, 64K context
The base model can predict text well now, but it tops out at 16K context.
Mid-training 1 is where they extend to 64K by repacking the same data mixture at the longer sequence length - no distribution shift, just longer sequences.
They also shift the data mix here: heavier on STEM, math, and code. The model isn't learning new facts now, it's deepening the structure of what it already knows.
They also introduced memorization-aware epoch capping - if a data source is getting "too easy" (NLL approaching zero, meaning the model has basically memorized it), it gets a stricter cap on how often it's repeated. No point showing the model things it's already solved.
Phase 3 - Mid-training 2: 150B tokens, 256K context
The final context extension push. 256K tokens is roughly a 200-page book in one shot.
This phase runs on only 4,096 GPUs (down from 8,192) because the longer sequences require a different parallelism strategy - they switch to ZeRO-3 / FSDP here for memory reasons.
Only 150B tokens, but the purpose is surgical: teach the model to actually use long context without forgetting everything it learned before.
After all three phases: MAI-Base-1.
A 35B active / ~1T total parameter sparse MoE that beats DeepSeek V3.2 on every held-out eval benchmark while using only 62% of its active parameters.
Now the interesting part: the post-training pipeline
Pre-training gives you a model that predicts text. RL is what teaches it to reason.
And here's what makes Microsoft's approach unusual: they started the RL climb from zero reasoning traces.
No warm-starting from DeepSeek's thinking traces, no distillation from o1 or Claude. T
he model had never seen a chain-of-thought. They had to teach it to think from scratch.
They ran three parallel RL climbs on three specialist models:
1. STEM specialist: math, physics, chemistry, competitive coding
2. Agentic specialist: code execution, tool use, real-world software tasks
3. Helpfulness & Safety specialist: instruction following, human preference, refusal calibration
Each specialist uses the same RL recipe but different reward signals.
The RL algorithm: GRPO with two key fixes
The base algorithm is GRPO (Group Relative Policy Optimization).
For each problem, sample 128 responses, score them, compute relative advantages, update the model. But vanilla GRPO has two failure modes at scale:
Entropy collapse - the model becomes overconfident, outputs the same answer pattern every time, and stops exploring.
They fixed this with adaptive entropy control: a simple feedback controller that monitors the model's output entropy and dynamically widens or tightens the trust-region clip bounds to keep it in a target range.
When entropy drops too low, the controller loosens the leash. When entropy runs too high (chaotic outputs), it tightens. No explicit entropy bonus term needed.
Gradient explosions - the unclipped branches of the GRPO objective (where the new policy moves in the "right" direction) can sometimes produce catastrophic gradient norm spikes.
They added a hard outer ratio clip on top of the standard trust-region clip. Two layers of protection instead of one.
The reward function
Three components:
1. Task reward: did the answer verify correctly? (SymPy for math, test-case execution for code, AI judge for everything else)
2. Language consistency reward: the model would start hallucinating foreign-language tokens inside its chain-of-thought as context lengths grew, which correlated with training instability. Penalize non-English words in the CoT.
3. Length penalty: adaptive by problem difficulty. Hard problems (low pass rate) get a weak length penalty - let the model think as long as it needs. Easy problems get a strong length penalty - stop the hedging and just answer.
Self-distillation: the key to surviving
Running RL for thousands of steps on a single continuous run is fragile. Numerical drift accumulates. Infrastructure fails. The base model gets updated. They solved all three with the same mechanism: self-distillation.
Periodically, they'd collect the best rollouts from the current RL run, run SFT on a fresh mid-trained checkpoint using those rollouts, and restart the RL climb from the new checkpoint.
The key finding: you need ~1M traces, sampled from later stages of the climb (not early checkpoints), with diversity of prompts mattering more than quantity per prompt. Random sampling of traces outperformed every clever selection strategy they tried.
This also gave them a way to swap in a better base model mid-climb without losing months of RL progress - just distill the current RL model's knowledge into the new base, then keep climbing.
The final merge: one unified model
After the three specialist RL climbs complete, they do a simple SFT on a fresh consolidated model using traces from all three specialists.
This gives one model that's good at STEM, agentic coding, and being helpful and safe.
Then one final lightweight RL climb on that consolidated model produces MAI-Thinking-1.
The result: 97% on AIME 2025. 52.8% on SWE-Bench Pro. 87.7% on LiveCodeBench v6.
From a model trained entirely from scratch, zero knowledge borrowed from any other model's outputs.
The pipeline is called the "hill-climbing machine."
The name is literal - not a one-shot training run, but a system designed to keep improving.
The interesting part isn't any single component. It's that every piece (the data pipeline, the RL recipe, self-distillation, the reward design) is built to sustain a long climb rather than peak fast and plateau.
Jun 2

Seven new models launching at Build: let’s go!
Reasoning. Code. Image. Transcribe. Voice.
Built from scratch on a clean data lineage, designed for efficiency, working seamlessly as a family of models
Thread 🧵
#MSBuild
ALT Graphic titled ‘Microsoft AI: 7 New Models’ showing icons for Image, Transcribe, Thinking, Voice, and Code models in a grid
1
9
41
10,002