

Jun 15
SERFF Updates;
Tightening camp: Watching for incremental liquidity drain (settlements TGA bills) to firm the front end.
Momentum camp: Still comfortable fading any tightening, expecting excess liquidity regime to persist
29

EFbasis structurally comprehensible to most anyone. the fundamentals make sense.
SERFF's fundamentals (not execution, but its "why") quite the can of worms for those who need to understand things before putting money to work behind them.
most HR can comprehend EF/b. Not SERFF.
126

📣 Attn STIR traders and SERFF enjoyers!
Finer tick granularity is coming to SOFR-Fed Funds (SERFF) spreads.
Beginning next Monday, June 15, SR1-ZQ spreads will trade in 0.25 increments across all contract months.
5
9
64
34,399


let him publish a article about plumbing, and see what serff does tomo.
6
323

May 20
attn SERFF bois: I wouldn’t be surprised if Warsh took a look at RMPs, said “Wow, you guys over-did it again!” and pushed the FOMC to end them.
especially since we’re past April and TGA has returned to 800bn

2
2
12
3,080

May 19
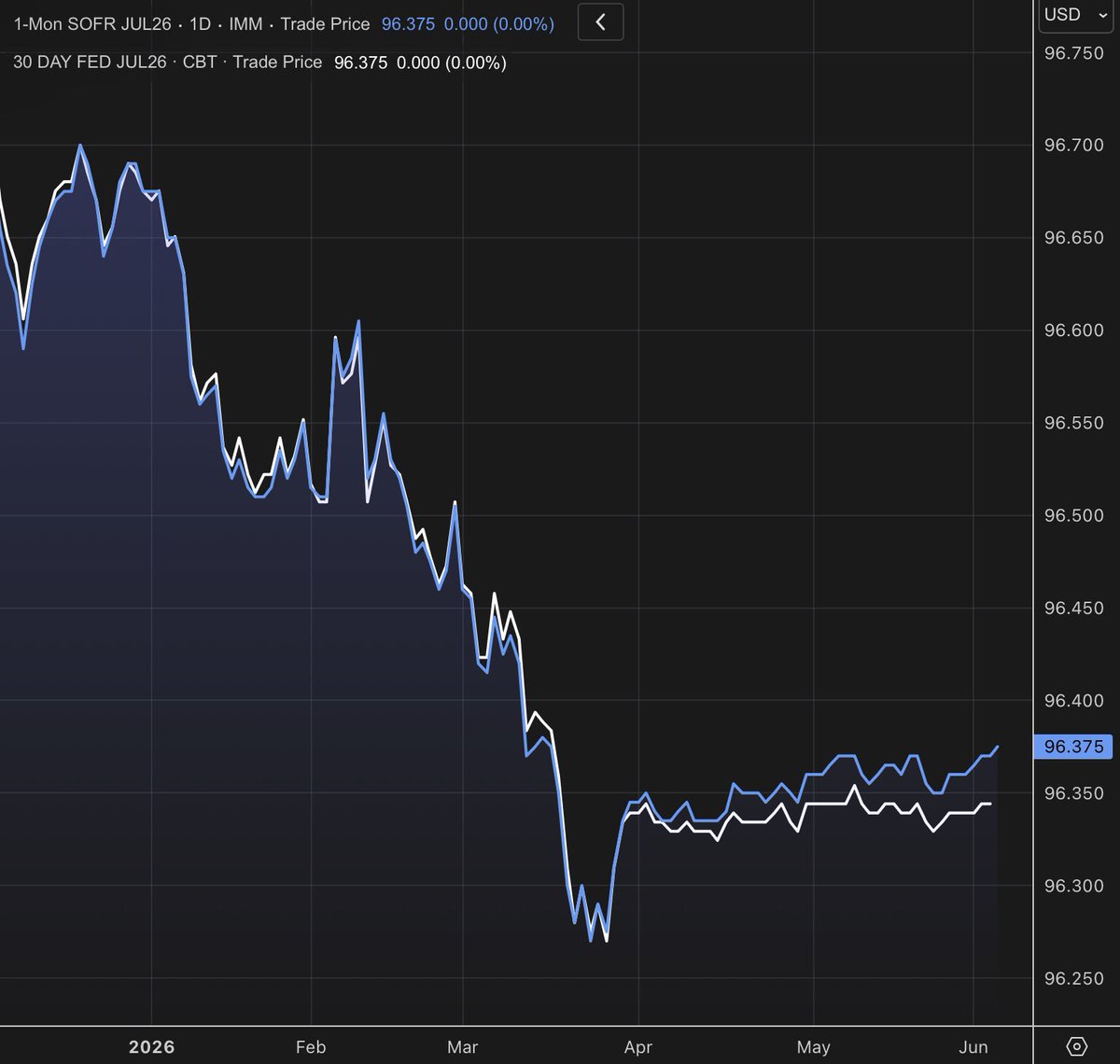
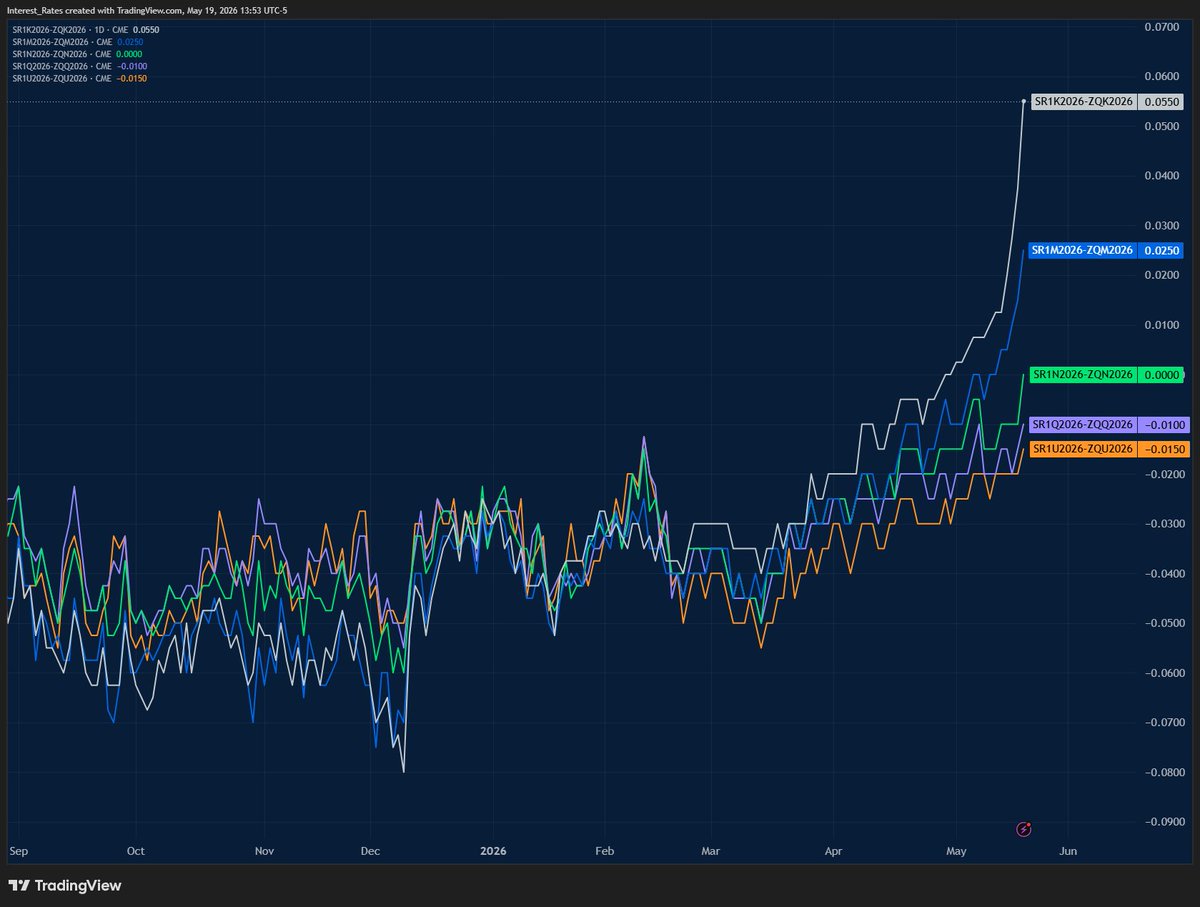
SOFR-Fed Funds spreads (SERFF)
New highs in front three spreads; record volume in M6; parity achieved in N6
3
430


May 15
Need Warsh to reduce Balance Sheet, so my SERFF can be bearish xD
2
53

May 15

1
29

May 13
SERFF Jun-Jul is 1.5, pretty crazy price even with the EFFR mood swings
1
2
228


Abril
Plesi
Daisy
Monchi
Athena
Ringo
Nova
SimónQ
Serff
Tetsu
Sayaka
Henry
Mar 15

Name 12 of your oomfs without cheating.
6
1
10
450
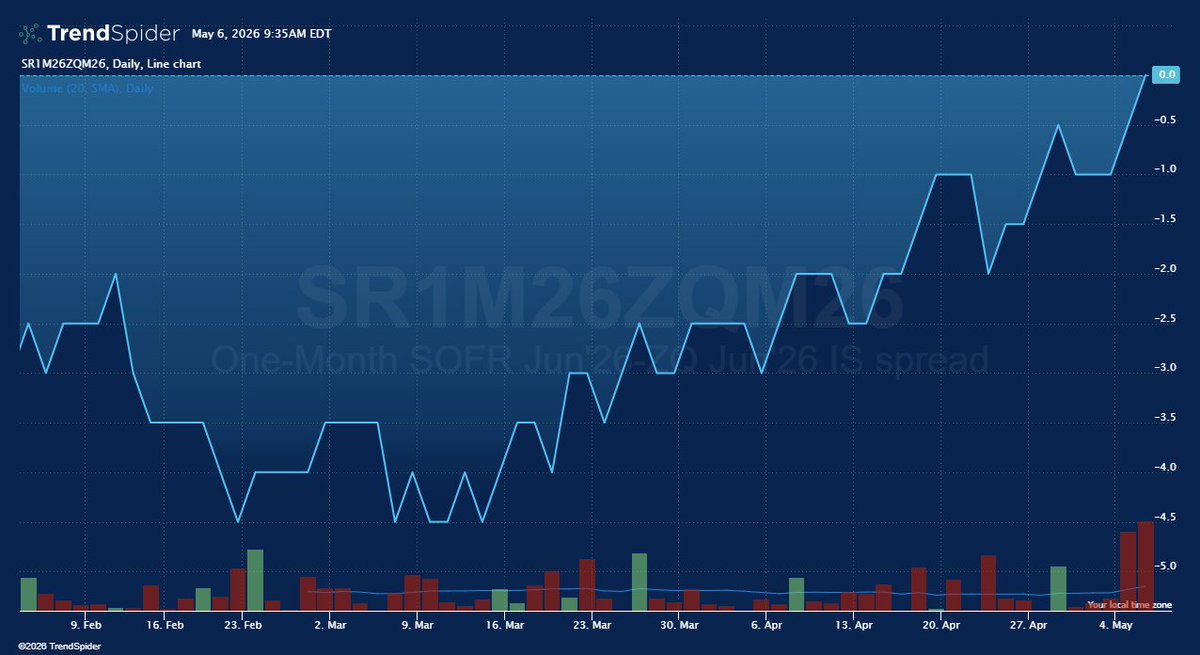
May 6
SERFF curve 🟢
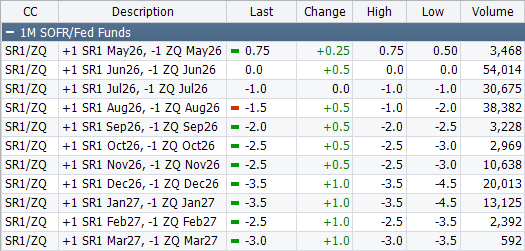
Jun26 SOFR-Fed Funds spread reaches parity on record volume.
2
17
3,667

We took a close look at several public table extraction benchmarks, including OmniDocBench, SCORE-Bench, ParseBench, and RD-TableBench, and found that every one of them has a structural/methodology issue that doesn’t properly evaluate document intelligence at scale.
1/ OmniDocBench's TEDS metric conflates formatting with structure. A 3x3 table with identical content scores differently based on whether it uses <thead> wrappers or plain <tr>.
2/ SCORE-Bench's spatial tolerance parameter can hide serious failures. Drop a financial table's header row, shift data up by one, and the benchmark reports high content accuracy while the headers are gone.
3/ ParseBench relies on frontier VLMs for ground truth, introducing model bias into the benchmark itself. Its table metric treats records as unordered bags, so column transposition and row reordering go unpenalized. The table set is also 503 pages, 54.5% from a single SERFF source, and English-only.
4/ RD-TableBench linearizes 2D tables into 1D sequences, so column swaps can align well despite being structurally wrong. We also audited all 1,000 ground truth files and found 43 with verifiable errors and 89 byte-identical to one provider's output.
That's why we built PulseBench-Tab, a benchmark that is multilingual by design, uses 2D-aware scoring that preserves horizontal and vertical adjacency, cleanly separates structure from formatting, and is fully open from the dataset to the scoring code. Full breakdown by the @Pulse__AI team in comments.
4
2
12
317
