
May 16
Look back. You are not who you were. That is the whole point. You are becoming.
#PersonalGrowth #YouAreBecoming #SelfEvolution #GlowUp #ProgressNotPerfection #BecomeYourBestSelf #TransformationQuotes #Quotes #ShareInspireQuotes

ALT Look back. You are not who you were. That is the whole point. You are becoming.
9
11
265

May 15
Sometimes growth isn’t loud.
Sometimes it’s just you standing face to face with the person you’re slowly becoming.
The hardest battles are the silent ones nobody sees.
The self-doubt.
The overthinking.
The nights you almost gave up.
But every version of you survived so the next version could evolve.
Keep going.
Your future self is already proud of you. ✨
#Growth #SelfEvolution #AnimeArt #DigitalArt #XArtist #Motivation #GlowUp

6
28
31
343

Tag someone who needs a reminder that their current season is building their future strength.
#SelfEvolution #HopeLife #Persistence #BeautyInTheBroken #HoldingcoreEMPFoundation

17
16
27
197

Some people break.
Some people adapt.
You were sculpted to survive.
evolutionofmadness.com/produ…
#resilience #selfdevelopment #streetwearbrand #darkart #philosophy #streetwear #graphictee #darkaesthetic #mindset #selfevolution #undergroundfashion

2
17

Apr 7
I am the architect of my own evolution. Like the foliage behind me, I continue to grow. I move in the assurance of knowing exactly who I am. 💚🪴
#ElginCharles #SelfEvolution #ArchitectOfSelf #RootedInPurpose #UnstoppableGrowth
21
346

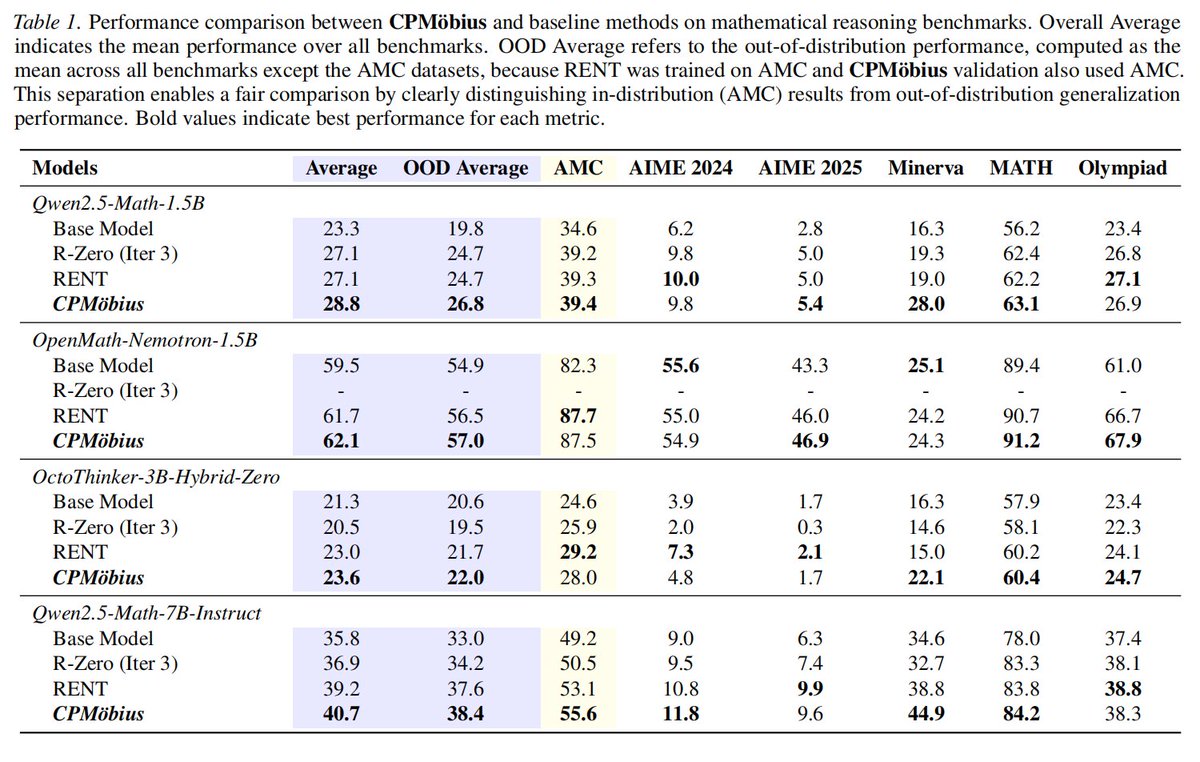
LLMs show incredible potential in complex math reasoning, but their progress is bottlenecked by a massive reliance on human-curated data. What happens when we run out of high-quality human annotations? Can models teach themselves from scratch? 🤔
Today, we present CPMöbius—new research from @TsinghuaNLP (OpenBMB member) and collaborators: A novel collaborative "Coach-Player" paradigm that enables LLMs to self-evolve their reasoning capabilities in a completely data-free environment.
🤗 Paper: huggingface.co/papers/2602.0…
📄 arXiv: arxiv.org/abs/2602.02979
Why it matters:
1️⃣ Zero External Data Needed: No more expensive human engineering! CPMöbius breaks the data bottleneck through an autonomous dual-agent loop. A "Coach" LLM generates mathematical tasks, and a "Player" LLM learns to solve them using majority voting and self-training. 🔓
2️⃣ Collaborative, Not Adversarial: Unlike standard adversarial self-play, our Coach and Player are cooperative. The Coach applies dynamic difficulty filtering, ensuring generated questions have a 20%–80% success rate—keeping tasks challenging yet learnable, perfectly tailored to the Player's current skill level. 🤝
3️⃣ Progress-Driven Rewards: How do we stop the Coach from generating useless or overly complex questions? The Coach is rewarded purely by the Player's actual performance improvement ($\Delta$) on a validation set. The Coach uses the REINFORCE algorithm to update itself, meaning it only "wins" when the Player genuinely gets smarter! 📈
4️⃣ SOTA Unsupervised Reasoning: CPMöbius dominates existing unsupervised methods (like RENT and R-Zero). On Qwen2.5-Math-7B-Instruct, it boosts overall accuracy by 4.9 points and Out-Of-Distribution (OOD) accuracy by 5.4 points. It achieves consistent, massive gains across multiple baseline models. 🚀
CPMöbius proves that LLMs can collaboratively bootstrap their own intelligence, charting a highly scalable path toward true data-free self-evolution.
#AI #THUNLP #OpenBMB #LLM #ReinforcementLearning #MathReasoning #SelfEvolution


4
10
41
2,799



You Don’t Miss Them — You Miss Who You Were With Them
After a breakup, it can feel like you miss the person deeply — but sometimes what you’re really grieving is the version of yourself that existed with them.
#EmotionalGrowth #SelfEvolution #PersonalDevelopment #MindsetShift
2
5
12
540
x.com/JeffreyChen_THU/status… AI self-evolution requires internalizing new knowledge, but measuring this is hard: Is the model actually learning, or just recalling pre-training data? And if it fails, is it due to memory gaps or reasoning complexity? 🤯
Today, we present SE-BENCH—new research from THUNLP (OpenBMB member): A rigorous diagnostic framework that uses library obfuscation to cleanly isolate and evaluate LLM knowledge internalization capabilities.
🤗 Paper: huggingface.co/papers/2602.0…
📄 arXiv: arxiv.org/abs/2602.04811
💻 Code: github.com/thunlp/SE-Bench
📊 Dataset: huggingface.co/datasets/jint…
Why it matters:
1️⃣ A "Clean" Testbed for Evolution: We obfuscate NumPy into a pseudo-novel package ("ZWC"). Tasks are algorithmically trivial but impossible without learning the new API. This removes reasoning bottlenecks and prior knowledge leaks, creating a pure test for the "memorize-and-leverage" ability. 🧹
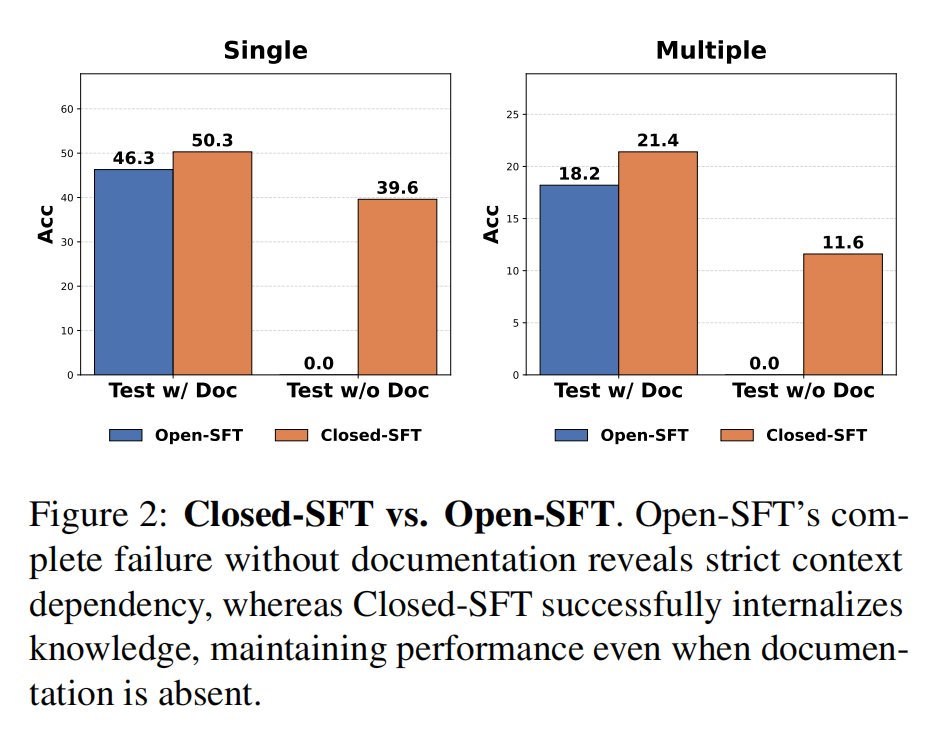
2️⃣ The Open-Book Paradox: Training with access to documentation actually inhibits long-term retention. We discover that Closed-Book Training—stripping context during parameter updates—is essential to force knowledge compression into model weights. 📕➡️🧠
3️⃣ The RL Gap & Self-Play: While SFT effectively internalizes knowledge, standard RL fails due to PPO clipping. However, we prove Self-Play is viable for internalization when coupled with SFT (not RL), allowing models to learn from self-generated, noisy curricula. 📉🚀
SE-BENCH serves as a critical "Needle-in-a-Haystack" test for self-evolution, ensuring agents can truly learn from experience before tackling open-ended worlds.
#AI #THUNLP #OpenBMB #LLM #SelfEvolution #MachineLearning



Everyone is talking about Self-Evolving 🤖. But here’s the hard question: How do we actually evaluate it?
Are models truly learning new skills, or just recalling?
🚀We propose a new benchmark SE-Bench, targeting a core primitive of evolution: Knowledge Internalization. 🧵

3
42
2,373

Was the Love Still There When You Changed? 🤔💔
#Growth #Change #SelfEvolution #RealLove #Truth #HealingJourney
1
3
17

क्या आपका जीवन बदल रहा है?
अक्सर हम गुरु के पास जाते हैं, उनकी बातें सुनते हैं और उन्हें अपनी डायरी में लिख लेते हैं। लेकिन विचार कीजिए, क्या वह ज्ञान आपके आचरण में उतरा?
गुरु केवल सूचना (Information) देने वाला शिक्षक नहीं है। गुरु वह 'अग्नि' है जो शिष्य के पुराने और व्यर्थ संस्कारों को जलाकर उसे एक नया जन्म देती है। यदि गुरु का सान्निध्य पाकर भी हमारे क्रोध, लोभ और अहंकार में रत्ती भर भी कमी नहीं आई, तो हमने गुरु को केवल सुना है, उन्हें जिया नहीं है।
'यत्सत्येन जगत्सत्यं यत्प्रकाशेन भाति तत्' — अर्थात् जिनके होने से सत्य का बोध होता है। गुरु का अर्थ ही है वह रूपांतरण, जो आपको 'आप' से मुक्त करके 'परमात्मा' की ओर ले जाए। ज्ञान बोझ न बने, बल्कि वह आपके भीतर का प्रकाश बन जाए, यही गुरु-शिष्य परंपरा का वास्तविक उद्देश्य है।
आज स्वयं से पूछें: क्या मैं बदल रहा हूँ?
— जगद्गगुरु स्वामी सतीशाचार्य जी महाराज
.
#सनातनधर्म #हिन्दु #महर्षिमहेशयोगी #जगद्गुरुसतिशाचार्य #Jagadguru #GuruShishya #Spirituality #Transformation #VedicWisdom #GuruGita #SelfEvolution #SpiritualAwakening #KnowledgeToWisdom #SanatanDharma #GuruGrace #InnerPeace #DailyInspiration

4
27

I didn’t disappear, I was becoming.
I came back changed.
#selfevolution
17
991

24 Dec 2025
Outgrowing spaces is quiet proof you’re evolving.
Not everything familiar is meant to last.
The door isn’t too small—you’ve grown bigger dreams, stronger boundaries, clearer standards.
Don’t shrink. This is your sign to expand.
#softgrowth #selfevolution

7
44
16 Dec 2025
I never change, I simply become more myself.
#SelfEvolution #BecomingYourself #PersonalGrowth #Authentic #SelfDiscovery #Journey #PersonalEvolution #Quotes #ShareInspireQuotes

ALT I never change, I simply become more myself.
9
9
359

21 Nov 2025
It’s okay to outgrow what no longer fits your future. Elevate.
#Metaraise #Outgrow #MindsetShift #SelfEvolution #FutureReady #ElevateYourself
3
7
490

18 Nov 2025
I never change, I simply become more myself.
#SelfEvolution #BecomingYourself #PersonalGrowth #Authentic #SelfDiscovery #Journey #PersonalEvolution #Quotes #ShareInspireQuotes

ALT I never change, I simply become more myself.
9
10
325

11 Nov 2025
🤖 What if AI agents could design their own successors—no humans needed?
That’s the vision behind ALITA-G: a self-evolving agent that learns by doing, then packages its hard-won skills into reusable tools to bootstrap smarter future agents.
How? Three breakthroughs:
1️⃣ Learn from success: Turns successful task executions into smart, standalone tools (MCPs).
2️⃣ Abstract & generalize: Transforms one-off tricks into flexible, parameterized capabilities.
3️⃣ Retrieve on demand: At test time, finds the right tool for the job—boosting accuracy and cutting token use by ~15%.
🏆 New SOTA on GAIA: 83% pass@1
🌍 A step toward agents that evolve themselves—autonomously.
#AI #Agents #SelfEvolution #LLM #AGI
10 Nov 2025

Using LLMs to build self-evolving agents is exciting—but how much do we really understand about how these agents grow?
What if agents could genuinely acquire new skills from experience and turn them into reusable tools?
We explore this question in our new paper, ALITA-G 👇
The key insight: Turn temporary solutions into permanent capabilities.
(1/n)

5
524



27 May 2025
Good morning, grinders! Hit the gym and make today legendary! youtube.com/watch?v=t7sXV119… #FitnessGiants #GymMorningBeast #MorningVictory #FitFamLegends #HealthTitans #MotivationBlaze #WorkoutGiants #ExerciseBeasts #FitnessMonsters #GymLifeElite #WellnessGiants #ActiveBeasts #MuscleElite #CardioGiants #FitAndEpic #InspirationBlaze #SelfEvolution #DisciplineGiants #GymDreamers #FitnessEpic #MorningLegend #StrengthGiants #HealthyEpics #FitspirationGiants #LifeLegends #MindsetGiants #SuccessLegends #WorkHardBeEpic #FitnessIcons #MotivationLegends #GoalLegends #TrainLikeAGod #BeImmortal #KeepGrinding #Crypto #Bitcoin #Blockchain

2
5
105

23 Apr 2025
You outgrow people when:
You stop complaining
You start working
You stay focused
Peace comes with growth.
#SelfEvolution #Discipline
1
2
36