
my love for upl is infinite and so is my love for trans ppl so adding those together is also infinite since the union of two infinite sets is also infinite #mathreasoning
2
36

Math Reasoning Challenge
👉 What’s the correct answer?
Drop your answer in the comments ⬇️
#MathPuzzle #BrainTeaser #MathChallenge #OrderOfOperations #MathTricks #LearnMath #CompetitiveExams #Aptitude #MathReasoning #PuzzleTime #ThinkFast #Education #Shorts

1
2
216


Math Rasoning Challenge
Can you spot the mistake and fix it?
Test your logic and calculation skills👇
Drop your answer in the comments
#MathPuzzle #BrainTeaser #MathChallenge #LogicalThinking #ProblemSolving #MathReasoning #PuzzleTime #MindGames #LearnMath #FunWithMath #IQTest #TrickyQuestions #MathLovers #ChallengeYourself #CompetitiveExam #Aptitude #MathTricks

1
2
215
Can you translate words into math correctly?
Test your algebra skills and see if you can spot the correct expression 👇
Drop your answer in the comments🔥
#MathReasoning #Algebra #MathPuzzle #BrainTeaser #LearnMath #MathChallenge #ProblemSolving #Education #StudyGram #Maths #LogicalThinking #CompetitiveExams #Aptitude #QuantitativeAptitude #MathLovers #ThinkSmart #MathTricks #Students #Learning #ExamPrep

2
1
2
3,669
Math Reasoning Challenge
Concept-Based Question
Test your algebraic thinking and identity skills
Perfect for students preparing for exams 📚
Drop your answer & method below 👇
#MathReasoning #Algebra #MathConcepts #Identity #Mathematics #MathQuestion #CompetitiveExams #JEE #NEET #BoardExams #StudySmart #MathTeacher #LearnMath #ProblemSolving #Education #Students #MathPractice #Reels #Shorts #Trending

1
4
6,744

LLMs show incredible potential in complex math reasoning, but their progress is bottlenecked by a massive reliance on human-curated data. What happens when we run out of high-quality human annotations? Can models teach themselves from scratch? 🤔
Today, we present CPMöbius—new research from @TsinghuaNLP (OpenBMB member) and collaborators: A novel collaborative "Coach-Player" paradigm that enables LLMs to self-evolve their reasoning capabilities in a completely data-free environment.
🤗 Paper: huggingface.co/papers/2602.0…
📄 arXiv: arxiv.org/abs/2602.02979
Why it matters:
1️⃣ Zero External Data Needed: No more expensive human engineering! CPMöbius breaks the data bottleneck through an autonomous dual-agent loop. A "Coach" LLM generates mathematical tasks, and a "Player" LLM learns to solve them using majority voting and self-training. 🔓
2️⃣ Collaborative, Not Adversarial: Unlike standard adversarial self-play, our Coach and Player are cooperative. The Coach applies dynamic difficulty filtering, ensuring generated questions have a 20%–80% success rate—keeping tasks challenging yet learnable, perfectly tailored to the Player's current skill level. 🤝
3️⃣ Progress-Driven Rewards: How do we stop the Coach from generating useless or overly complex questions? The Coach is rewarded purely by the Player's actual performance improvement ($\Delta$) on a validation set. The Coach uses the REINFORCE algorithm to update itself, meaning it only "wins" when the Player genuinely gets smarter! 📈
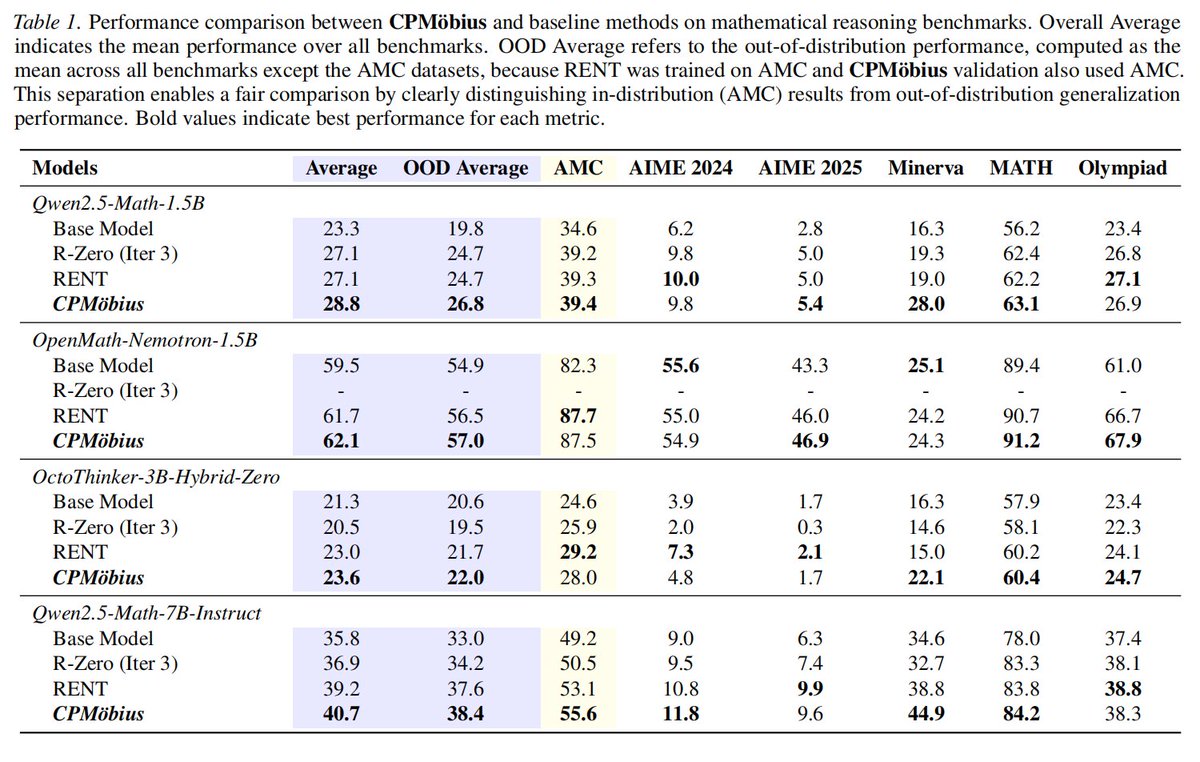
4️⃣ SOTA Unsupervised Reasoning: CPMöbius dominates existing unsupervised methods (like RENT and R-Zero). On Qwen2.5-Math-7B-Instruct, it boosts overall accuracy by 4.9 points and Out-Of-Distribution (OOD) accuracy by 5.4 points. It achieves consistent, massive gains across multiple baseline models. 🚀
CPMöbius proves that LLMs can collaboratively bootstrap their own intelligence, charting a highly scalable path toward true data-free self-evolution.
#AI #THUNLP #OpenBMB #LLM #ReinforcementLearning #MathReasoning #SelfEvolution


4
10
41
2,799

Pi Day reminder: math = reasoning, not recall. π🧠
Ask one better question today: “Why does that work?”
#PiDay #MathReasoning #ConceptualUnderstanding #MathTeacher

4
8
685

9 Nov 2025
💡 The way we evaluate LLMs is fundamentally broken and this paper makes a compelling case why.
Most “LLM-as-a-judge” systems today rely on passive review: a model reads a response, assigns a score, and stops there. No verification. No reasoning augmentation. No ability to check facts, run code, or validate claims. In real human evaluation, especially in technical or math-heavy domains, we never judge without tools. So why are our AI judges forced to?
This work introduces TIR-Judge (Tool-Integrated Reinforcement Learning Judge), a framework that transforms LLM judges from static scorers into agentic evaluators by giving them:
External tool access — code execution, symbolic solvers, and retrieval
Reinforcement learning incentives to use those tools when needed
A policy trained to reason about when to verify, not just what to score
In other words: instead of assuming the model knows, it learns how to check.
Key outcomes:
- Significant accuracy gains in judging math responses (where unverified judging consistently fails)
- Better alignment with ground-truth labels vs. non-tool judges
- Smarter reasoning policies — the model doesn’t blindly call tools, it learns when they’re actually necessary
- Fewer hallucinated judgements because claims can now be tested programmatically
- Proof that judge models benefit from agency, not just instruction tuning
One especially notable signal: improving the tools (e.g., stronger solvers, cleaner execution environments) resulted in direct accuracy improvements, showing that judge performance bottlenecks are increasingly tool-bound rather than model-bound.
The broader implication is clear:
If we want reliable AI evaluation, particularly for domains like math, coding, or any task involving verifiable correctness, LLM judges must become agents, not critics.
This work nudges the industry forward from “LLM-as-a-rater” to “LLM-as-a-verifier.”
A logical next step in building evaluation systems that actually evaluate.
#AI #LLMEvaluation #ReinforcementLearning #AIJudges
#AgenticAI #ToolAugmentedLLMs #MathReasoning #AIAlignment
#CodeGeneration #Agents #NeurIPS #AIResearch #MachineLearning
#DeepLearning #OpenAI #Anthropic #GoogleDeepMind #MetaAI

2
7
1,540

5 Oct 2025
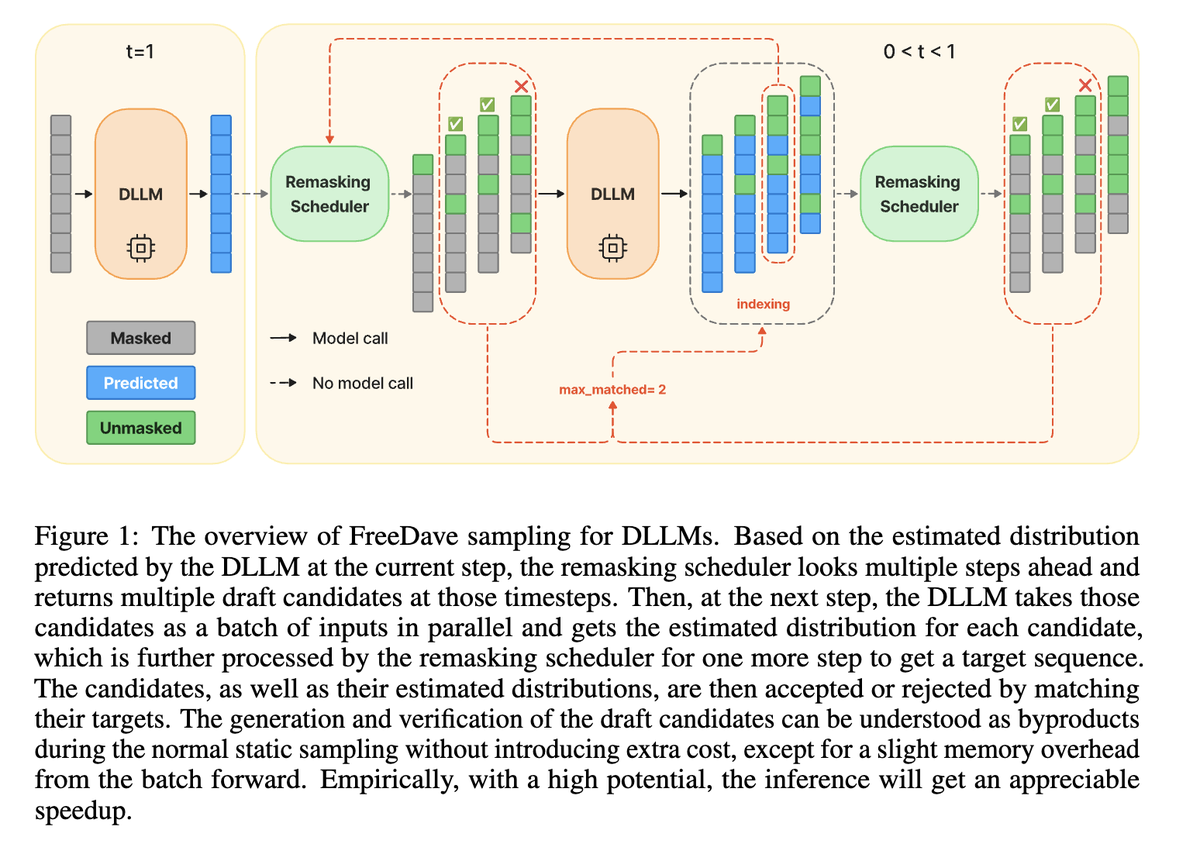
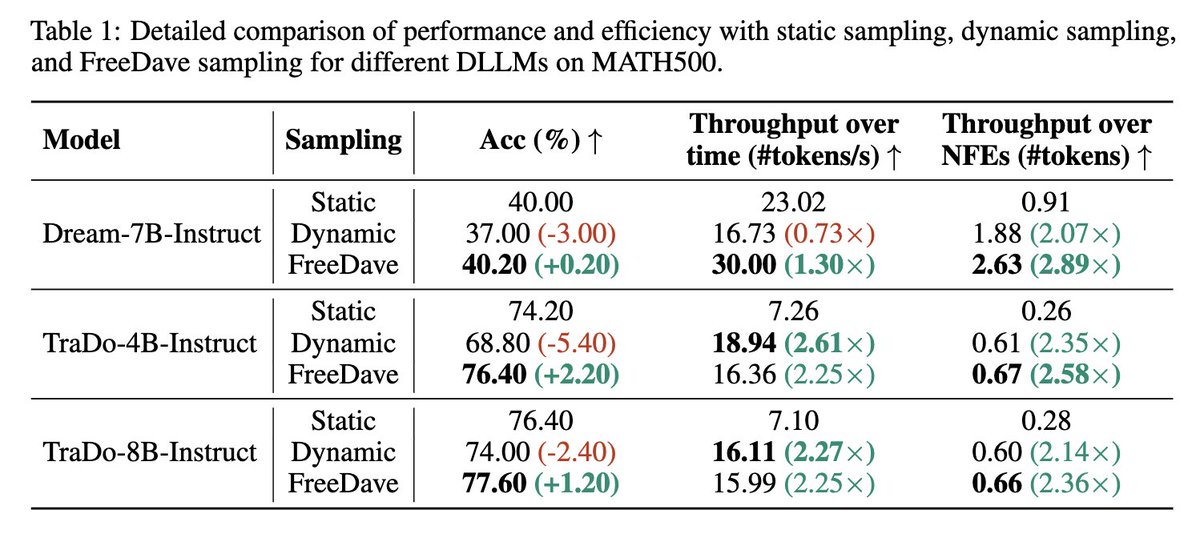
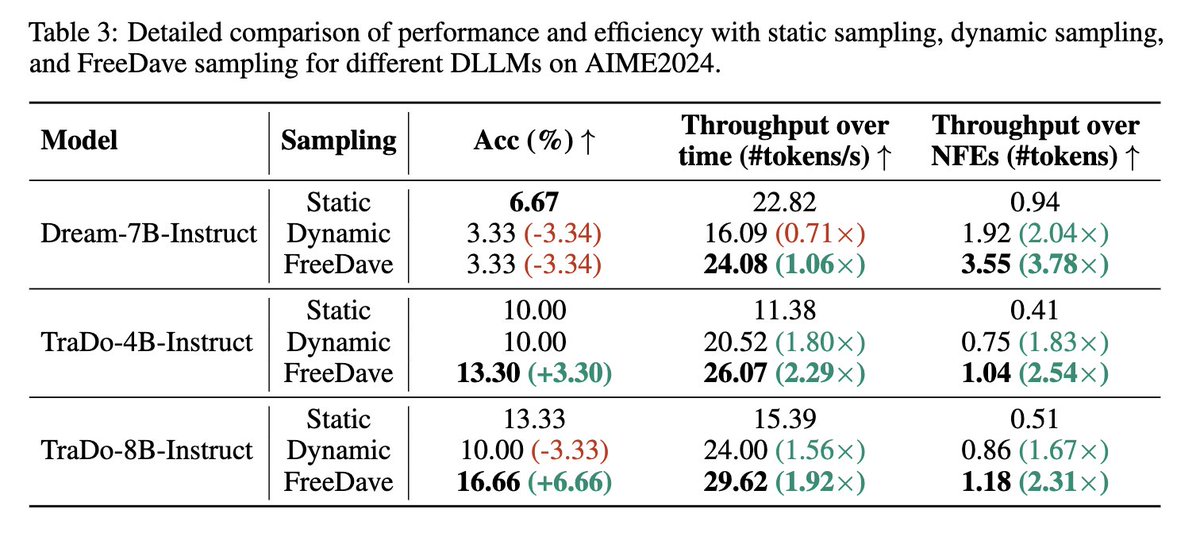
🚀 Tired of choosing between speed and accuracy for Diffusion Large Language Models? Meet FreeDave (arxiv.org/abs/2510.00294) — the lossless parallel decoding algorithm that fixes DLLMs’ inference pain points perfectly!
No extra draft models, no model tweaks — just smart parallel candidate generation self-verification. For state-of-the-art TraDo DLLMs (arxiv.org/abs/2509.06949):
✅ Throughput boosts up to 2.8×
✅ Accuracy rises: 2.2% on MATH500, 6.66% on tough AIME2024 math tasks
It’s the speedup dLLM fans have been waiting for!
Grab FreeDave’s code here: github.com/cychomatica/FreeD…
Thanks to the team behind it — @cychomatica (first author) for leading this!
P.S. Love TraDo? Its codebase is here too: github.com/Gen-Verse/dLLM-RL
#AI #dLLM #LLMAcceleration #DiffusionModels #MathReasoning

2
22
142
9,563

📚 Math is the purest test of reasoning.
Alpie Core: 92.8% GSM8K, competitive with GPT-4o and Qwen — far above DeepSeek & Mistral.
First 32B 4-bit reasoning model from India.
⚡ Efficiency-first innovation.
🔗 Download: huggingface.co/169Pi/Alpie-C…
#AI #MathReasoning

14
1,927

8 Sep 2025
New tutorial! 🚀
Post Training Qwen3 for Math Reasoning Using GRPO
pyimg.co/tav5k 👍
Author: @puneet2k
#GRPO #Qwen3 #RLHF #MathReasoning #LLM #HuggingFace #TRL

2
1
6
580

16 Aug 2025
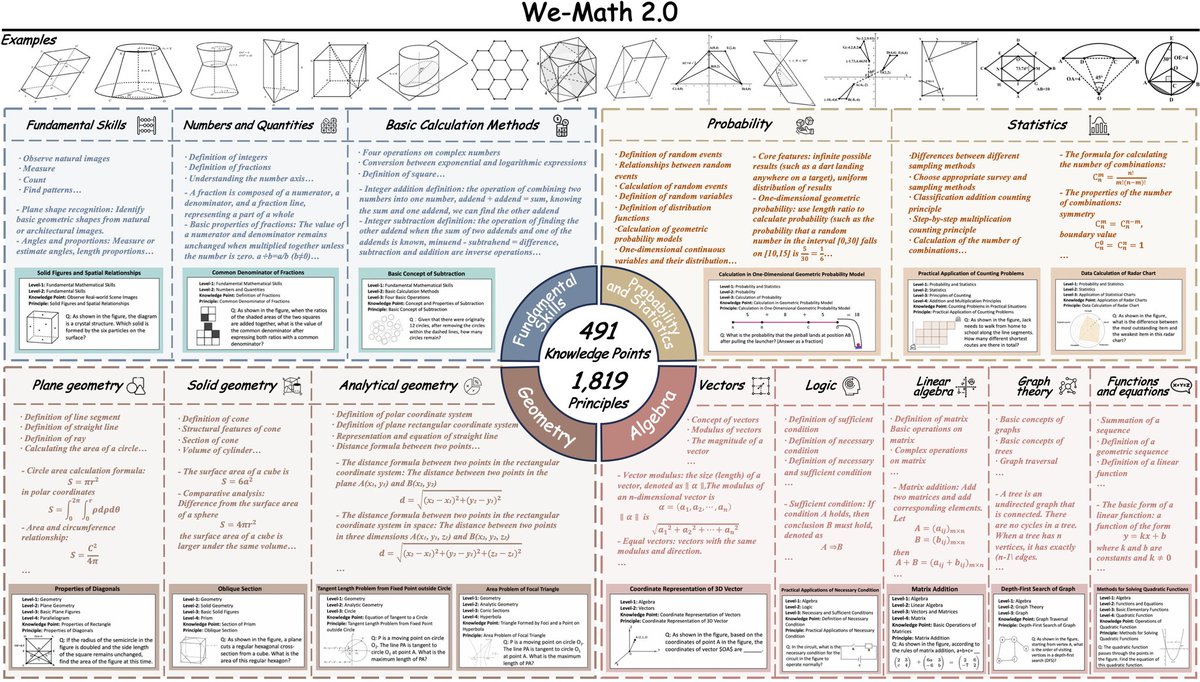
[Aug 15, 2025] Daily most popular paper on Hugging Face "We-Math 2.0"
A “MathBook” curriculum that teaches MLLMs math, then rewards them for thinking step-by-step.
✨️Why this matters✨️
Despite rapid progress, most multimodal LLMs still stumble on complex, visual math because datasets are patchy, difficulty is human-centric (not model-centric), and methods don’t generalize reasoning to related sub-problems. We-Math 2.0 tackles all three at once.
✨️What they built✨️
1. MathBook Knowledge System — a five-level hierarchy: 491 knowledge points linked to 1,819 fundamental principles spanning primary→university math.
2. MathBook-Standard & MathBook-Pro — handcrafted GeoGebra visuals; principled 3-D difficulty modeling (step, visual, context) that expands each problem into 7 levels for progressive training.
3. MathBook-RL — two-stage training: (i) Cold-Start SFT to internalize knowledge-oriented CoT; (ii) Progressive-Alignment RL with an average-reward mechanism plus dynamic scheduling (incl. knowledge-increment routing when the model errs).
4. MathBookEval — a benchmark of 1,000 fully annotated problems covering all 491 knowledge points; reasoning depth stratified (Level-1: 1–3 steps; Level-2: 4–6; Level-3: 7–10) and evaluated with GPT-4o as judge.
❓️Does it work? (7B scale)
On four standard benchmarks, MathBook-7B scores Avg 48.7 with 73.0 (MathVista), 28.0 (MathVision), 48.4 (We-Math), 45.2 (MathVerse)—competitive with recent open-source reasoning models—using only ~1K SFT 9.8K RL samples.
They attribute the “less-is-more” data efficiency to the structured knowledge system and training scheme.
✨️Why it’s interesting✨️
A model-centric difficulty space (not tied to human grade levels) curriculum RL is a neat recipe for visual math.
Benchmarking aligns to explicit knowledge points and multi-step depth, filling gaps in existing suites.
📝Notes
Early version; authors flag it as “working in progress.” Evaluation uses LLM-as-a-judge (GPT-4o), which is consistent with prior math-vision work but has known trade-offs.
🔗Source & links
Paper: arXiv 2508.10433 • Project: we-math2.github.io • Code: GitHub (We-Math2.0) • Datasets: We-Math 2.0 Standard / Pro.
📈Metrics (today)
Hugging Face upvotes: 121
GitHub stars: 115
#MLLM #MathReasoning #VisionLanguage #ReinforcementLearning #Benchmark #WeMath #MathBook #AIResearch
✨️Follow us for more daily picks and researcher-ready breakdowns — and connect with the community on reveal.ac✨️
2
8

25 May 2025
NVIDIA AceReason-Nemotron: Advancing Math and Code Reasoning with Reinforcement Learning
#NVIDIAAI #ReinforcementLearning #MathReasoning #CodeReasoning #ArtificialIntelligence
br>itinai.com/nvidia-acereason-…
1
38

Paper 24/25
SBSC: Step-by-Step Coding for Improving Mathematical Olympiad Performance 🥇💻
Helping LLMs solve math Olympiad problems! SBSC is a multi-turn framework where the model generates a sequence of programs for sub-tasks. Shows significant improvement!
Congrats Kunal Singh (linkedin.com/in/i-kunal-sing…), Ankan Biswas (linkedin.com/in/ankanbiswas7…), Sayandeep Bhowmick (linkedin.com/in/sayandeep-bh…), Pradeep Moturi (linkedin.com/in/pradeepmotur…), Siva Kishore Gollapalli (linkedin.com/in/siva-kishore…)!
📄: openreview.net/pdf/df1273af2… #LLMs #MathReasoning #CodeGeneration
1
4
582

13 Sep 2024
🚨 Last call for papers! 🚨
The 4th Workshop on Math Reasoning and AI @NeurIPSConf 2024 is accepting submissions for one more week.
🗓️ Deadline: September 20, 2024
📍 See you in Vancouver!
Details & submissions: mathai2024.github.io/cfp
#NeurIPS2024 #AI #MathReasoning #MATHAI #MATH

2
2
25
3,670

22 Jul 2024
Need two emergency reviews for EMNLP. Its urgent and Please RT! Topics are math reasoning, application of VLMS. #NLProc #VLM #MathReasoning
7
9
2,258

Thanks to @LaTanyaSothern for this fun video recap of the #2024NIC @pgcps @Ceii_UMD showcase. Click here to check it out: bit.ly/NICvideo. #improvementscience #edterps #schoolimprovement #mathreasoning #SEL
3
93

4 Jun 2024
In Modern Math Tasks I have a chapter co-written with two teachers. We share some ideas about how math could help prevent the spread of disease and also the spread of disinformation online. #MathReasoning

Have you checked out our featured books yet? 📚
Stock up for your summer reading with our latest titles: nctm.link/xRp8g
NCTM Members save up to 30% off list prices!

ALT Featured Books; Showing covers of Principles to Actions, Impact of Identity in K-12 Mathematics, Moden Math Tasks to Provoke Transformational Thinking; Proactive Mathematics Coaching, Disrupting Injustice: Navigating Critical Moments in the Classroom; the Powerful Mathematicians Series
1
3
477

8 Feb 2024
Another great math task with @AnnEliseRecord modeling practices from #BuildingThinkingClassrooms. So much great thinking and making math visible!! #MakeMathVisible #MathReasoning #MathDiscourse @WarwickSchools @RIDeptEd @ATMNE_math




1
2
296