
Jun 10
"The Universal Normal Embedding", CVPR'26 main
DINOやCLIPなどの識別型基盤モデルにおける潜在は暗黙的もしくは明示的に等方性正規分布に従うことが経験的に知られている.一方で,昨今の生成モデルも同様に正規分布からデータ空間への復元を行っている.この研究では,双方が(データ→ガウス)と(ガウス→データ)の異なる方向での写像を学習していることに着目し,「データの潜在的な構造は正規分布で表現され,生成・識別モデル双方の潜在表現から,線形逆問題を解くことで真の正規分布を逆推定できる」と主張する.具体的には,生成モデル側ではDDIM InversionによってPF-ODEをオイラー近似で逆向きにたどり,識別モデルと同じようにデータ→ガウスを辿る.推定したガウスによって,CelebAの属性推定で識別モデルと生成モデルはどちらも同程度に正確な属性推定が可能なことを示す.
(コメント)
ここ数年で真の潜在分布に正規分布を仮定し,実際SimCLRなどの対照学習ベースの手法がそうした正規分布に従った潜在を暗黙的に獲得されていることが知られている[1,2,3].こうした解析結果と合わせて,今の生成モデル(Flow MatchingやDiffusion,Normalizing Flows)が正規分布からデータへの対応関係を学習していることから,そうした生成モデルもデータからノイズにたどってノイズ空間で識別ができないかという点が注目されている.一方で,生成モデルはDINOやCLIP,SimCLRなど異なるview間の一貫性を持った表現を学習する損失は持たない.
最近ではREPAなどを通して事前訓練した識別モデルから特徴蒸留することで学習を高速化するように,間接的にview一貫性を持たせる試みが増えてきているが,そうした事前訓練済みのモデルなしに拡散モデルを訓練する試みはまだ少ない.拡散モデルの訓練時にview不変性などの損失項を加えて学習できないか気になる.また,今回の実験はあくまで顔属性推定であり,やはり大規模なImageNetなどのスケールでは動作しない可能性もある.そうした意味で生成モデルと識別モデルではまだ学習している表現にギャップがあるのではないかと思っている.
1
119
Jitendra Kumar Sharma retweeted

16 Nov 2025
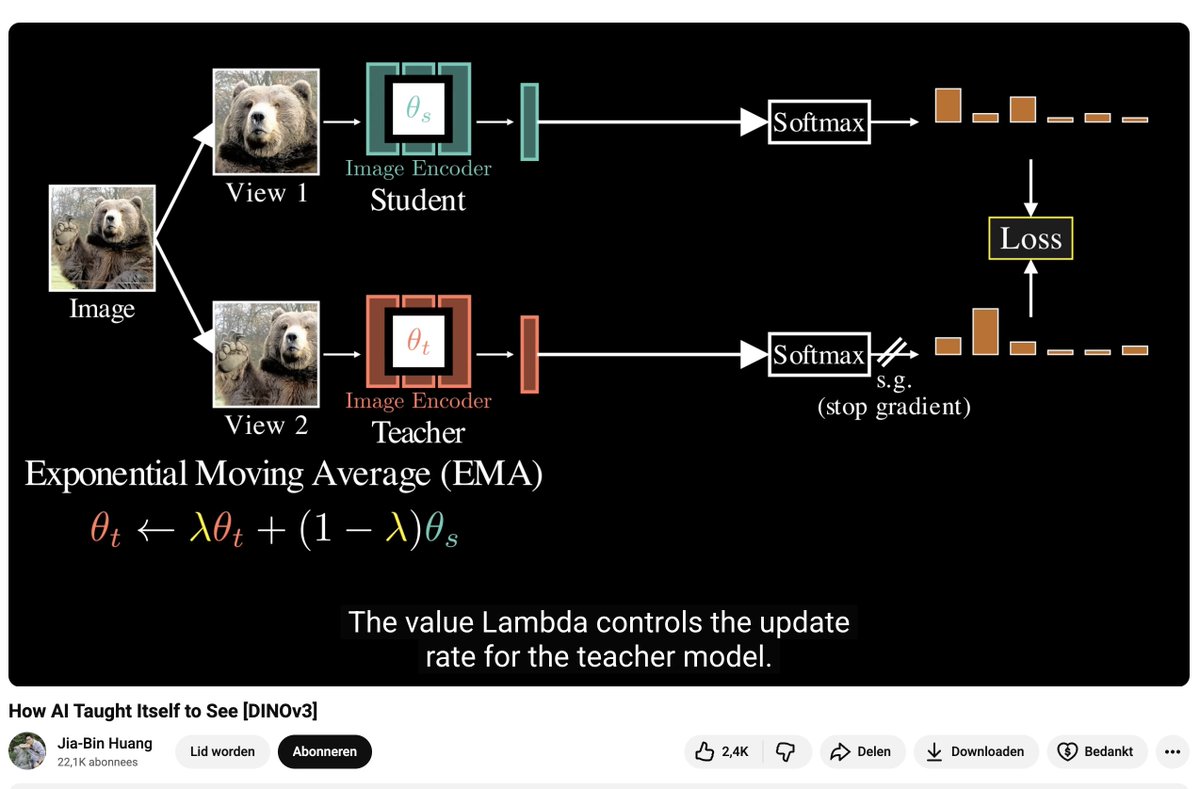
This is a phenomenal video by @jbhuang0604 explaining seminal papers in computer vision, including CLIP, SimCLR, DINO v1/v2/v3 in 15 minutes
DINO is actually a brilliant idea, I found the decision of 65k neurons in the output head pretty interesting
14
119
1,146
61,541

May 26
被人工智能专业的朋友震惊到了😳
晚上逛超市结账,我推着购物车随口吐槽:“就买包薯片纠结半天,搞不懂自己为啥拿起来又放回去三次。”
他边扫会员码,眼皮都不抬的顺嘴接话:
“这有啥想不通的,探索与利用困境、损失函数设计缺陷、过拟合到过往经验、偏差-方差权衡、奖励稀疏、折扣因子设得太低、策略梯度估计偏差、状态空间爆炸、动作空间离散化不当、马尔可夫决策过程建模错误、贝尔曼方程收敛慢、Q值高估、Softmax温度参数太高、经验回放优先级乱、优先经验回放PER、重要性采样权重漂移、目标网络更新太频繁、梯度消失、梯度爆炸、ReLU神经元死亡、BatchNorm统计量抖动、Dropout在推理时忘了关、学习率预热不够、余弦退火没调好、Adam的β2设错、SGD动量冲过头、损失曲面陷入鞍点、局部最优陷阱、泛化边界松弛、表示学习能力不足、注意力机制没对齐、自回归解码的暴露偏差、Teacher Forcing比率失调、KL散度退化为0、VAE的后验坍塌、GAN的梯度消失、判别器太强生成器放弃治疗、扩散模型的噪声调度不合理、强化学习中的好奇心驱动失效、内在奖励与外在奖励没平衡、逆强化学习到错误奖励函数、模仿学习的复合误差、分层强化学习的goal设置不合理、多智能体系统的非平稳环境、博弈论纳什均衡没找到、蒙特卡洛树搜索的rollout策略太随机、A*算法的启发函数不一致、动态规划的状态维数诅咒、贝叶斯推断的先验太强、最大似然估计在小样本下过拟合、最大后验估计又加了拉普拉斯先验、集成学习的基模型相关性太高、Boosting对噪声敏感、Bagging没做特征扰动、XGBoost的树的max_depth设浅了、LightGBM的GOSS采样丢了关键样本、卷积神经网络的感受野不够覆盖、空洞卷积的棋盘伪影、残差连接的shorcut被梯度淹没、Transformer的位置编码用余弦不对、旋转位置编码RoPE没归一化、稀疏注意力模式选择错误、MoE路由器的负载不均、图神经网络的过平滑现象、知识图谱的嵌入丢失了逻辑规则、对比学习中正负样本构造不合理、SimCLR的温度系数没调……”
我购物车当场差点撞收银台上!
真的很想问下,这就是AI男生的日常知识储备吗?
2
80

May 21
But "pull positives together, push negatives apart" is a vibe, not a training signal. You need a loss function that turns it into a number the model can minimize. The one I use is NT-Xent — Normalized Temperature-scaled Cross-Entropy, the loss that powered SimCLR.

1
2
30


May 11
🧠 ♥️🫁 👁️ 🫀 Very excited with our new work on multimodal FM with realistic missing modality/organs: Pan-FM: A Pan-Organ Foundation Model with Saliency-Guided Masking for Missing Robustness, led by our postdoc (Qiangqiang Wu). The main contributions are:
- Pan-FM is built on cross-organ attention with realistic missing organs
- Pan-FM adopts saliency-guided masking (SGM) to battle against the dominant-organ shortcut learning bias
- Pan-FM outperforms a wide variety of baseline approaches, and SGM not only improves the performance of Pan-FM, but also other existing models (e.g., SimCLR, VICReg, Barlow Twins, and DinoV2)
arxiv.org/abs/2605.07055
1
11
620


May 7
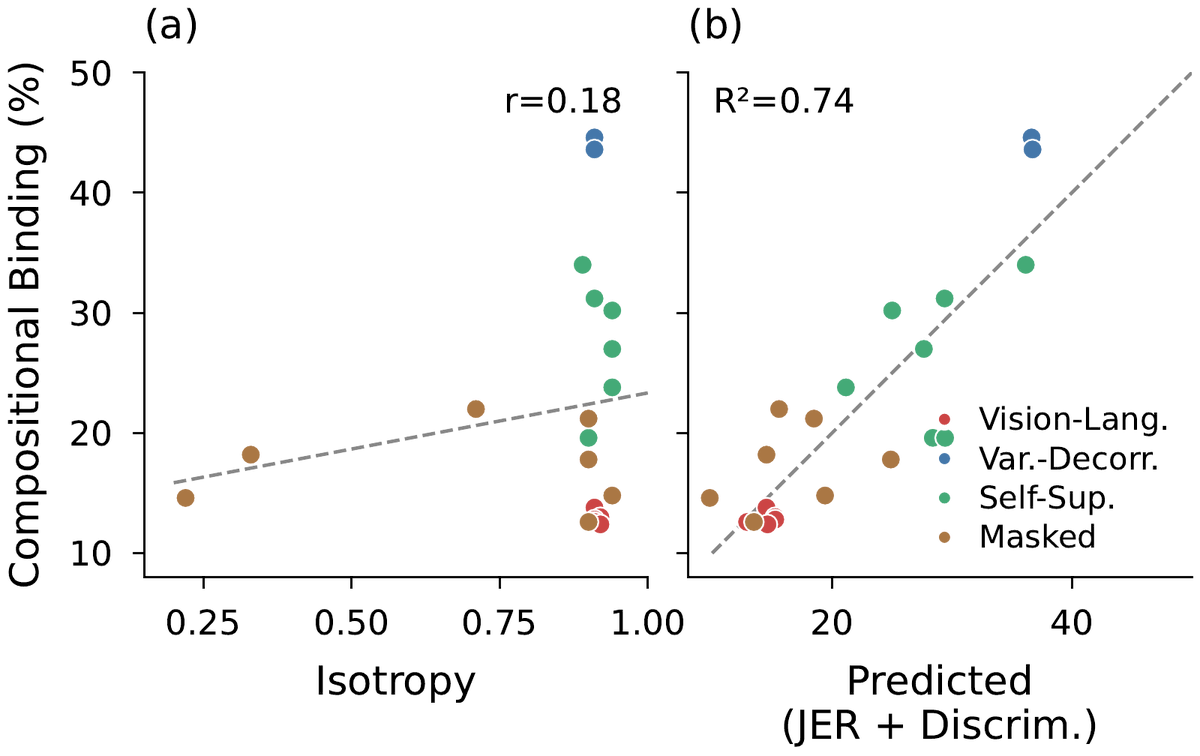
Now the question: why might global geometry miss this?
Global geometry (isotropy, rank, participation ratio) is a statistic of where embeddings sit across a dataset. Binding is a different question: when the input varies, does the encoder respond along distinct directions for each factor?
Distribution of embeddings vs. structure of the mapping. Two encoders with identical global statistics can have completely different Jacobians.
Across 21 encoders (SimCLR, Barlow Twins, VICReg, SwAV, DINO/v2, MAE, BEiT, I-JEPA, CLIP, SigLIP, EVA-CLIP, ConvNeXt):
• Global Participation Ratio: r = -0.00
• Isotropy Score: r = 0.18
• Local Isotropy: r = 0.05
All p > 0.4. Effectively zero.
(3/7)
3
1
17
1,581

Apr 27
Who invented JEPA? Part II. Dr. LeCun responded, and I put my replies in Addendum 1 of the report people.idsia.ch/~juergen/who… ... The conclusion still stands: the 2022 JEPA family is actually the 1992 PMAX family.
Excerpts:
On 6 April 2026, Dr. LeCun replied at LinkedIn (see screenshots 1, 2, 3): "what we now called Joint Embedding Architectures, which include things like Siamese nets and JEPA was introduced decades ago. No one is claiming it's new. You didn't invent it either. A good example of early work is the Becker & Hinton 1989 technique for maximizing mutual information. It worked, but made strong hypotheses about the distribution and probably didn´t scale (I was a postdoc in Toronto when they were thinking about this). This paper is the inspiration for your PMAX paper. Lot's of people have used mutual information maximization to train neural nets. The concept goes back to Horace Barlow. The question is *precisely* how to measure mutual information and how to maximize it. It's difficult because we don't have any lower bound measure on information content. We only have upper bounds..... My own NIPS 1993 paper on Siamese nets use a contrastive criterion. This was later revived by Raia Hadsell, Sumit Chopra and me in CVPR 2005 and 2006 papers (Dr LIM). It was re--revived by the SimCLR work (for which Geoff Hinton is a co-author) which showed surprisingly good experimental results on ImageNet. But then in 2021, we proposed a new non-contrastive infomax method called Barlow Twins (owing to Barlow's early advocacy of infomax). We later refined it into VICReg which gave SOTA results in a self-supervised scenario on ImageNet. We then augmented the joint embedding architecture with a predictor so it could be used as a world model (that was the plan all along. I had been talking about world models since 2015, including in my NIPS 2016 keynote). JEPA is merely a name for a general concept. The question is, and has always been, how do you make it work (particularly how do you prevent it from collapsing), and how do you make it work at scale with SOTA results on non-toy problems. That's the hard part. Ideas are a dime a dozen. Making them work is what the community will give you credit for."
My reply (see also screenshot 5): LeCun concedes that “JEA” was introduced decades ago [IMAX][LEC22a], but still attempts to frame “JEPA” as a novel contribution [LEC22a][LEC]. The broader scientific community knows better. As Michal Valko (lead of [BYOL]) explicitly detailed [VAL26][WHO12]: "the JEPA lines are instantiations of [PMAX]” ... "Barlow Twins: ... literally Sec 2.3 of [PMAX]" ... “VICReg: ... is one section from [PMAX]." Scaling these 1992 blueprints to modern compute is cool, but the architectural foundation remains PMAX.
Valko further pointed out (personal communication, 2026): it was actually [BYOL] that first made the [PMAX] skeleton work at scale on ImageNet, in the hardest possible regime where ε=1 (eq. (2) of [PMAX]), that is, without an explicit Dl term to prevent collapse. BYOL’s collapse-prevention toolkit (EMA stop-grad predictor asymmetry) was introduced to survive without Dl and is exactly what I-JEPA and V-JEPA later adopted to address LeCun's question: how do you prevent collapse and make it work at scale? Punchline: In 2025, LeCun's [LeJEPA] dropped EMA and stop-gradient entirely and went back to an explicit anti-collapse regularizer (SIGReg). That's a full circle return to the original 1992 [PMAX] philosophy of explicit Dl terms. So even within the JEPA lineage, the trajectory went: [PMAX]’s explicit Dl (1992) → [BYOL]'s implicit architectural tricks (2020) → LeCun’s JEPAs using BYOL tricks (2023-2024) → back to explicit Dl in [LeJEPA] (2025). The field spent five years exploring the ε=1 regime opened up by BYOL, then came home to [PMAX]'s original ε<1 design. It's not just that JEPA is [PMAX], it's that even the detour away from explicit Dl eventually led back to [PMAX]'s origins.
Other comments. On Facebook, LeCun claimed (see screenshot 4) that the experimental section in our [PMAX] paper "is essentially non-existent." However, our 1992 [PMAX] paper had many experiments, while LeCun's JEPA paper [LEC22a] had none - despite compute being a million times cheaper in 2022.
LeCun refers to his "1993 paper on Siamese nets" which cited neither Becker & Hinton's "JEA" [IMAX] nor the 1992 [PMAX]/JEPA which solved a stereo task more readily than JEA and prevented "collapse."
LeCun keeps mentioning his "NIPS 2016 keynote" on "world models." It came after my learning prompt engineer for world models [PLAN4] and long after our earlier general purpose recurrent neural world models for partially observable environments since 1990 [GAN90][PLAN1-3][WM26] (key milestones in 1990, 91, 92, 97, 2000-2006, 2015).
Of course, my 1990 paper on recurrent neural nets as world models [GAN90] cited earlier works on less general, feedforward net-based systems (since 1987) for fully observable environments [WER87-89][MUN87][NGU89]. LeCun's much later 2022 paper on JEPA and world models [LEC22a] didn't. So I pointed him to these works in my 2022 critique [LEC], but he did not correct his paper [LEC22a].
Years later, on 18 April 2026, LeCun finally mentioned at least [NGU89] (but not [WER87-89][MUN87]) on LinkedIn (see screenshot 6), then boldly claimed that [GAN90] "was never accepted through peer review." Of course, this is not true: [GAN90]'s planning part was published at IJCNN'90 [PLAN2], and the part on artificial curiosity through generative & adversarial nets was published at SAB'91 [GAN91][GAN20][WHO8].
LeCun spread additional falsehoods on social media: on 18 April 2026, he accused me of claiming that I "invented world models" (see screenshot 7) although I have always cited pre-1990 feedforward nets of this kind [WER87-89][MUN87][NGU89] which weren't called "world models" [GAN90] by their authors [WHO12]. In the 1980s, Werbos connected this work to earlier work on system identification in control theory, e.g., [WER87-89]. I even credited the ancient Greeks for the basic concept at a conference that LeCun attended [WM26b][WM26] (see video tweet).
LeCun's additional misleading statements about JEPA were discussed above [WHO12]. The conclusion still stands: the 2022 JEPA family is actually the 1992 PMAX family.
All references in:
[WHO12] J. Schmidhuber. Who invented JEPA? Technical Note IDSIA-3-22, IDSIA, Switzerland, March 2026 (updated in April).

Mar 31

Dr. LeCun's heavily promoted Joint Embedding Predictive Architecture (JEPA, 2022) [5] is the heart of his new company. However, the core ideas are not original to LeCun. Instead, JEPA is essentially identical to our 1992 Predictability Maximization system (PMAX) [1][14].
Details in reference [19] which contains many additional references.
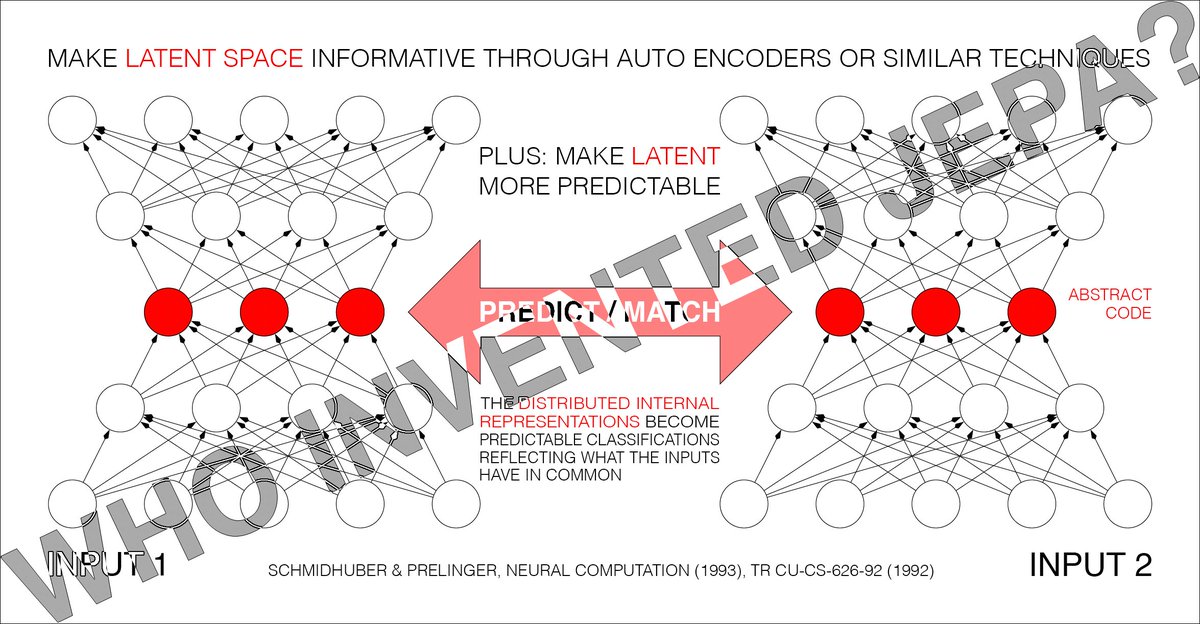
Motivation of PMAX [1][14]. Since details of inputs are often unpredictable from related inputs, two non-generative artificial neural networks interact as follows: one net tries to create a non-trivial, informative, latent representation of its own input that is predictable from the latent representation of the other net’s input.
PMAX [1][14] is actually a whole family of methods. Consider the simplest instance in Sec. 2.2 of [1]: an auto encoder net sees an input and represents it in its hidden units (its latent space). The other net sees a different but related input and learns to predict (from its own latent space) the auto encoder's latent representation, which in turn tries to become more predictable, without giving up too much information about its own input, to prevent what's now called “collapse." See illustration 5.2 in Sec. 5.5 of [14] on the "extraction of predictable concepts."
The 1992 PMAX paper [1] discusses not only auto encoders but also other techniques for encoding data. The experiments were conducted by my student Daniel Prelinger. The non-generative PMAX outperformed the generative IMAX [2] on a stereo vision task.
The 2020 BYOL [10] is also closely related to PMAX. In 2026, @misovalko, leader of the BYOL team, praised PMAX, and listed numerous similarities to much later work [19].
Note that the self-created “predictable classifications” in the title of [1] (and the so-called “outputs” of the entire system [1]) are typically INTERNAL "distributed representations” (like in the title of Sec. 4.2 of [1]).
The 1992 PMAX paper [1] considers both symmetric and asymmetric nets. In the symmetric case, both nets are constrained to emit "equal (and therefore mutually predictable)" representations [1]. Sec. 4.2 on “finding predictable distributed representations” has an experiment with 2 weight-sharing auto encoders which learn to represent in their latent space what their inputs have in common (see the cover image of this post).
Of course, back then compute was was a million times more expensive, but the fundamental insights of "JEPA" were present, and LeCun has simply repackaged old ideas without citing them [5,6,19].
This is hardly the first time LeCun (or others writing about him) have exaggerated LeCun's own significance by downplaying earlier work. He did NOT "co-invent deep learning" (as some know-nothing "AI influencers" have claimed) [11,13], and he did NOT invent convolutional neural nets (CNNs) [12,6,13], NOR was he even the first to combine CNNs with backpropagation [12,13]. While he got awards for the inventions of other researchers whom he did not cite [6], he did not invent ANY of the key algorithms that underpin modern AI [5,6,19].
LeCun's recent pitch: 1. LLMs such as ChatGPT are insufficient for AGI (which has been obvious to experts in AI & decision making, and is something he once derided @GaryMarcus for pointing out [17]). 2. Neural AIs need what I baptized a neural "world model" in 1990 [8][15] (earlier, less general neural nets of this kind, such as those by Paul Werbos (1987) and others [8], weren't called "world models," although the basic concept itself is ancient [8]). 3. The world model should learn to predict (in non-generative "JEPA" fashion [5]) higher-level predictable abstractions instead of raw pixels: that's the essence of our 1992 PMAX [1][14].
Astonishingly, PMAX or "JEPA" seems to be the unique selling proposition of LeCun's 2026 company on world model-based AI in the physical world, which is apparently based on what we published over 3 decades ago [1,5,6,7,8,13,14], and modeled after our 2014 company on world model-based AGI in the physical world [8].
In short, little if anything in JEPA is new [19]. But then the fact that LeCun would repackage old ideas and present them as his own clearly isn't new either [5,6,18,19].
FOOTNOTES
1. Note that PMAX is NOT the 1991 adversarial Predictability MINimization (PMIN) [3,4]. However, PMAX may use PMIN as a submodule to create informative latent representations [1](Sec. 2.4), and to prevent what's now called “collapse." See the illustration on page 9 of [1].
2. Note that the 1991 PMIN [3] also predicts parts of latent space from other parts. However, PMIN's goal is to REMOVE mutual predictability, to obtain maximally disentangled latent representations called factorial codes. PMIN by itself may use the auto encoder principle in addition to its latent space predictor [3].
3. Neither PMAX nor PMIN was my first non-generative method for predicting latent space, which was published in 1991 in the context of neural net distillation [9]. See also [5-8].
4. While the cognoscenti agree that LLMs are insufficient for AGI, JEPA is so, too. We should know: we have had it for over 3 decades under the name PMAX! Additional techniques are required to achieve AGI, e.g., meta learning, artificial curiosity and creativity, efficient planning with world models, and others [16].
REFERENCES (easy to find on the web):
[1] J. Schmidhuber (JS) & D. Prelinger (1993). Discovering predictable classifications. Neural Computation, 5(4):625-635. Based on TR CU-CS-626-92 (1992): people.idsia.ch/~juergen/pre…
[2] S. Becker, G. E. Hinton (1989). Spatial coherence as an internal teacher for a neural network. TR CRG-TR-89-7, Dept. of CS, U. Toronto.
[3] JS (1992). Learning factorial codes by predictability minimization. Neural Computation, 4(6):863-879. Based on TR CU-CS-565-91, 1991.
[4] JS, M. Eldracher, B. Foltin (1996). Semilinear predictability minimization produces well-known feature detectors. Neural Computation, 8(4):773-786.
[5] JS (2022-23). LeCun's 2022 paper on autonomous machine intelligence rehashes but does not cite essential work of 1990-2015.
[6] JS (2023-25). How 3 Turing awardees republished key methods and ideas whose creators they failed to credit. Technical Report IDSIA-23-23.
[7] JS (2026). Simple but powerful ways of using world models and their latent space. Opening keynote for the World Modeling Workshop, 4-6 Feb, 2026, Mila - Quebec AI Institute.
[8] JS (2026). The Neural World Model Boom. Technical Note IDSIA-2-26.
[9] JS (1991). Neural sequence chunkers. TR FKI-148-91, TUM, April 1991. (See also Technical Note IDSIA-12-25: who invented knowledge distillation with artificial neural networks?)
[10] J. Grill et al (2020). Bootstrap your own latent: A "new" approach to self-supervised Learning. arXiv:2006.07733
[11] JS (2025). Who invented deep learning? Technical Note IDSIA-16-25.
[12] JS (2025). Who invented convolutional neural networks? Technical Note IDSIA-17-25.
[13] JS (2022-25). Annotated History of Modern AI and Deep Learning. Technical Report IDSIA-22-22, arXiv:2212.11279
[14] JS (1993). Network architectures, objective functions, and chain rule. Habilitation Thesis, TUM. See Sec. 5.5 on "Vorhersagbarkeitsmaximierung" (Predictability Maximization).
[15] JS (1990). Making the world differentiable: On using fully recurrent self-supervised neural networks for dynamic reinforcement learning and planning in non-stationary environments. Technical Report FKI-126-90, TUM.
[16] JS (1990-2026). AI Blog.
[17] @GaryMarcus. Open letter responding to @ylecun. A memo for future intellectual historians. Substack, June 2024.
[18] G. Marcus. The False Glorification of @ylecun. Don’t believe everything you read. Substack, Nov 2025.
[19] J. Schmidhuber. Who invented JEPA? Technical Note IDSIA-3-22, IDSIA, Switzerland, March 2026. people.idsia.ch/~juergen/who…
22
43
377
103,693

Btw @SophontAI IS HIRING
Looking for someone to help lead the development of pathology foundation models.
Although helpful, no background in medical AI needed.
Background in training self-supervised vision models (DINO/MAE/SimCLR/etc.) needed.
Contact me if interested!
8
10
81
27,382

Apr 14
Just read the SimCLR paper for the image-based self-supervised work I’m doing.
It’s a nicely simple framework: standard ResNet, a small nonlinear projection head you throw away after training, strong data augmentations, and NT-Xent contrastive loss. The results are surprisingly strong.
That said, it’s noticeably more memory-hungry. The method really benefits from large batch sizes (4096 and up), which ends up requiring quite a bit of compute power.
Now reading Meta’s DINOv2, which seems far more memory-efficient by comparison. Will share some thoughts on it soon.
Still digesting the trade-offs.
Paper link: arxiv.org/pdf/2002.05709

2
3
79

Ref [VAL26] in [19]: Michal Valko, leader of the BYOL team, praised PMAX, and listed numerous similarities to much later work (personal communication, March 2026, reprinted with permission): "It's amazing how [PMAX] is a proto-self-supervised learning / contrastive learning framework, predating SimCLR, BYOL, Barlow Twins, VICReg by ~25-30 years. It's shocking how it's not celebrated more. Yes, I totally agree that the JEPA lines are instantiations of PMAX, sometimes with extra modification: ★ Barlow Twins: penalize off-diagonal cross-correlation (literally Sec. 2.3 of [PMAX] with a different name). ★ VICReg: variance hinge (Sec. 2.1) plus covariance penalty (Sec. 2.3) applied simultaneously, so indeed that paper is one section from [PMAX]. ★ I-JEPA: Drop the discrimination (D) term of PMAX, use EMA stop-gradient instead; replace augmentation with image patch masking. ★ V-JEPA: I-JEPA but masking is spatiotemporal over video frames. ★ DINO: D based on centering (subtract teacher output mean) plus sharpening (low-temperature softmax). ★ DINOv2: DINO plus iBOT masking objective bolted on; adds I-JEPA-style masked prediction as auxiliary loss. ★ LeJEPA (2025): D is SIGReg, match 1D marginals to isotropic Gaussian; drops EMA/stop-gradient entirely. ★ LLM-JEPA (2025): [PMAX] applied to language; encoder predicts continuous embeddings of masked tokens instead of discrete tokens. ★ VL-JEPA (2025): [PMAX] with vision encoder and language encoder; cross-modal masked prediction. ★ Rectified LpJEPA (2026): D = RDMReg, match marginals to rectified generalized Gaussian; forces sparse non-negative codes."
2
83
26,821

Mar 24
JEPA is a class of architectures, not a method.
There were lots of JEPAs before I proposed the name as a unifying concept.
For example, Siamese nets (NIPS 1993) are a special case of JEPA (where the predictor is the identity, and the training loss is contrastive as in SimCLR).
The question is how the architecture is trained, particularly how you prevent collapse.
Many world models are JEPAs that are not trained as JEPA but using a reconstruction criterion (e.g. Dreamer models and Wayve's Gaia which use VAE or VQVAE).
Predicting an action between two states ("inverse dynamics" as in Poke by Poking) is a weak way to prevent collapse.
9
20
318
20,436


Mar 24
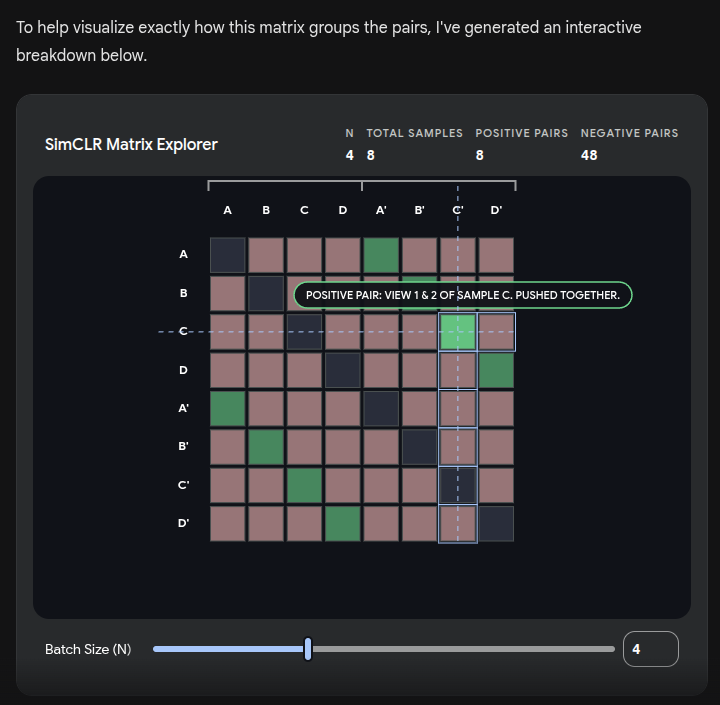
Now Gemini can create interactive visualizations! 🤯
Check out this SimCLR visualization.
#AI #MachineLearning #DeepLearning #SimCLR #ContrastiveLearning #DataScience #ArtificialIntelligence #GoogleGemini #AIVisualization #TechInnovation #MLResearch #NeuralNetworks #AITrends
1
2
61

Mar 22
現代編は
SimCLR (Simple Framework for Contrastive Learning)
MoCo (Momentum Contrast)
よくあるGoogleとMetaの比べっこ。日本からも提案手法が出て欲しいです。
2
555

Mar 18
All you need to start reading ML research papers ->
You need to understand the building blocks that 90% of papers are built on.
Here's the complete list:
Attention Mechanisms
> Scaled dot-product attention
> Multi-head attention
> Self-attention vs cross-attention
> Causal masking
Every modern paper builds on attention. Transformers, vision transformers, diffusion models: all variations of the same core idea.
Loss Functions and Training Objectives
> Cross-entropy and its variants
> Contrastive loss (SimCLR, CLIP)
> Triplet loss
> KL divergence (VAEs, distillation)
> Reconstruction loss
When a paper says "we optimize L_total = L_ce λL_kl," you need to know what each term does and why it's there.
Regularization and Normalization
> Dropout and why it approximates ensembles
> Layer norm vs batch norm vs RMS norm
> Weight decay
> Label smoothing
> Gradient clipping
Papers mention these in one line and move on. If you don't already know them, you're stuck.
Optimization and Convergence
> Adam, AdamW, and why the W matters
> Learning rate schedules (warmup, cosine decay)
> Gradient accumulation
> Mixed precision training
"We train with AdamW, lr=3e-4, cosine schedule with 2000 warmup steps." Every paper has this sentence. You should know exactly what it means.
Evaluation Metrics
> Perplexity
> BLEU, ROUGE
> F1, precision, recall (and when each matters)
> AUC-ROC
> FID (for generative models)
If you can't evaluate results, you can't judge whether a paper's claims hold up.
Architectural Patterns
-> Encoder-decoder structure
-> Residual connections (and why they solved deep training)
-> Positional encodings
-> Mixture of Experts
-> U-Net skip connections
Sampling and Generation
> Softmax temperature
> Top-k and nucleus (top-p) sampling
> Beam search
> Autoregressive vs non-autoregressive generation
That's it.
You don't need to understand every proof. You need to understand the components well enough that when a paper combines them in a new way, you can follow the logic.
The fastest way to get there: implement each one from scratch. Not read about it. Implement it.
That's what TensorTonic's problems are built for.
Practise them here: tensortonic.com
1
14
170
6,404

今更だが、生成AIの学習の手法に革命をもたらしたSimCLRについて理解できたと同時に、画像生成がより身近になった🙆♀️
SimCLR以前の画像AIは基本的に大量のラベルつき画像が必要で、人の工数が多大だったが、超シンプルなルールでラベル不要にしたのが革命的な意義。
そのルールは「Contrastive Learning」。意味 = 不変な特徴と捉え、Augmentationで壊れる特徴は捨てたことがアプローチの本質と理解。
例えば、犬の画像であれば色・背景・角度・光など変わるものは捨て、形・構造・意味など変わらないものを残す。こんな綺麗にデジタル構造化できる生成AIの世界は美しい!
3
29

Feb 20
Quick enjoyable engineering paper from Meta:
Lots of "we tried this for geting SOTA vision model and this works ok/well/not really [but we still include it and say that it does something..]".
Some points: very multi-step schedule for going to high-res inputs, they treat frames from a video as augmentations (😡), data curation matters big time (although only for our "CV community datasets or more generally?), simple architecture that works with video and image data, wild pipeline that combines MAE, SimCLR, CLIP and weakly-supervised hashtag clf.
arxiv.org/abs/2602.16918
2
14
59
6,662