
Jun 10
Overnight arXiv drop is absolutely stacked — reckon it's one of those weeks where you open the new submissions page and just sit there scrolling thinking "how does anyone keep up?"
Big theme this week: agents getting serious about long-horizon, real-world deployment. "Agents' Last Exam" (ALE) from the HF crew drops a 1K task benchmark across 13 industry clusters and the uncomfortable finding is what we've all suspected — benchmark scores barely correlate with actual deployment performance. The gap isn't small either. Meanwhile TRACE from Ji's group at Tsinghua tackles the rollout budget allocation problem for agentic RL — basically how to spend your compute budget across planning vs execution when you're running agents in production. Smart framing.
On the architecture side, "Dynamic Linear Attention" (Wang et al) is worth a proper read — they're making linear attention actually dynamic with input-dependent kernels, which could be the thing that finally makes sub-quadratic attention competitive at scale without the usual quality hit. And "Attention Amnesia in Hybrid LLMs" identifies a proper nasty failure mode: CoT fine-tuning breaks long-range recall in hybrid architectures. The fix involves attention head surgery during training — practical stuff.
NVIDIA's Cosmos 3 dropped too — omnimodal world model with mixture-of-transformers. Physical AI is the buzzword but the architecture is genuinely interesting: unified processing of video, action, state, text through shared token space. VibeVoice from MSR shows next-token diffusion for long-form multi-speaker TTS hitting 2B params with proper quality. dots.tts from the same week does continuous autoregressive TTS at 2B with specialised distillation for low-latency — both signal TTS is finally catching up to LLM-style scaling.
Honourable mentions: "AuRA" internalises audio understanding into LLMs as LoRA (clever parameter-efficient multimodal), "EEVEE" does test-time prompt learning for self-improving agents, "SkillOpt" treats agent skills as external trainable state with zero inference overhead. There's a through-line here — everyone's moving away from monolithic models toward modular, composable systems where you can swap components without retraining the world.
If you're building agents: read ALE and TRACE. If you're scaling attention: read Dynamic Linear Attention and Attention Amnesia. If you're doing multimodal: Cosmos 3 and AuRA. And honestly, the "When to Align, When to Predict" phase diagram paper (Kamai et al) is the theoretical grounding for why multimodal alignment works the way it does — proper physics-inspired ML theory.
Grab a coffee. This lot'll keep you busy till the next drop. #MLResearch #arXiv
1
2
97

KV-cache is the long-context memory wall. KVarN targets what most methods skip: variance outliers that blow up at low bit-widths. Approach: Hadamard rotation variance normalization before quantization. Worth benchmarking on your own context lengths. #LLMs #MLResearch
1
1
11

May 25
Worth sharing from @bravo_abad.
What if the brain's resting activity is already set up for memory and learning before any task begins?
This paper from @Nature (2026) by Pachitariu et al. makes a compelling case.
Follow @Academax_J for relevant research.
#AcadeMax #ZJU #Science #ComputationalBiology #MLResearch
May 23

A critical initialization for biological neural networks
Spontaneous brain activity is often treated as noise: the background hum of a nervous system waiting for a task. But large-scale recordings in mice have shown something more structured. Even in darkness, without explicit stimuli, thousands of neurons display coordinated activity patterns that extend across the brain and persist far longer than the fast biophysical timescales of individual neurons.
Marius Pachitariu and coauthors ask a simple question: could this macroscopic structure emerge from a simple kind of network initialization?
Their answer connects neuroscience, random matrix theory and machine learning. They model spontaneous neural activity as linear dynamics governed by a random connectivity matrix, stabilized by a global inhibitory-like normalization. When this matrix is symmetric and critically normalized, with its largest eigenvalue very close to one, the network naturally produces high-dimensional activity modes with a power-law covariance spectrum.
This is not just a mathematical curiosity. The same spectral structure appears in large-scale mouse recordings from cortex and brainwide Neuropixels data, with power-law exponents around 0.7–0.85. Hippocampal CA1 is the striking exception: its activity looks less correlated, closer to an efficient, high-capacity code for information storage.
The ML perspective is especially interesting. In artificial neural networks, initialization is often treated as a technical detail: Xavier, He, orthogonal schemes, and so on. But this paper reframes initialization as a computational substrate. A critically initialized recurrent system can generate slow, global, high-dimensional modes before task-specific learning. In simulations, these dynamics support time-dependent computations, including zero-shot working memory tasks.
The biological implication is powerful: spontaneous activity may not be random noise, but a preconfigured dynamical scaffold on which learning and computation can operate. The brain may start from an initialization already close to useful temporal memory, with learning then shaping readouts or task-specific pathways.
For R&D teams building ML systems in drug discovery, materials development, energy research or biotechnology, the lesson is broader than neuroscience. Initialization, architecture and dynamics define what kinds of scientific signals a model can preserve, combine and retrieve before training. In applied research pipelines where data are scarce, noisy and time-dependent, designing the right dynamical substrate may be as important as choosing the loss function.
Source: Pachitariu et al., Nature (2026) — CC BY 4.0 | doi.org/10.1038/s41586-026-1…

6
82

May 12
Small mining companies filing AI patents remind me of every conference paper I reviewed in 2019 that claimed "neural" in the title.
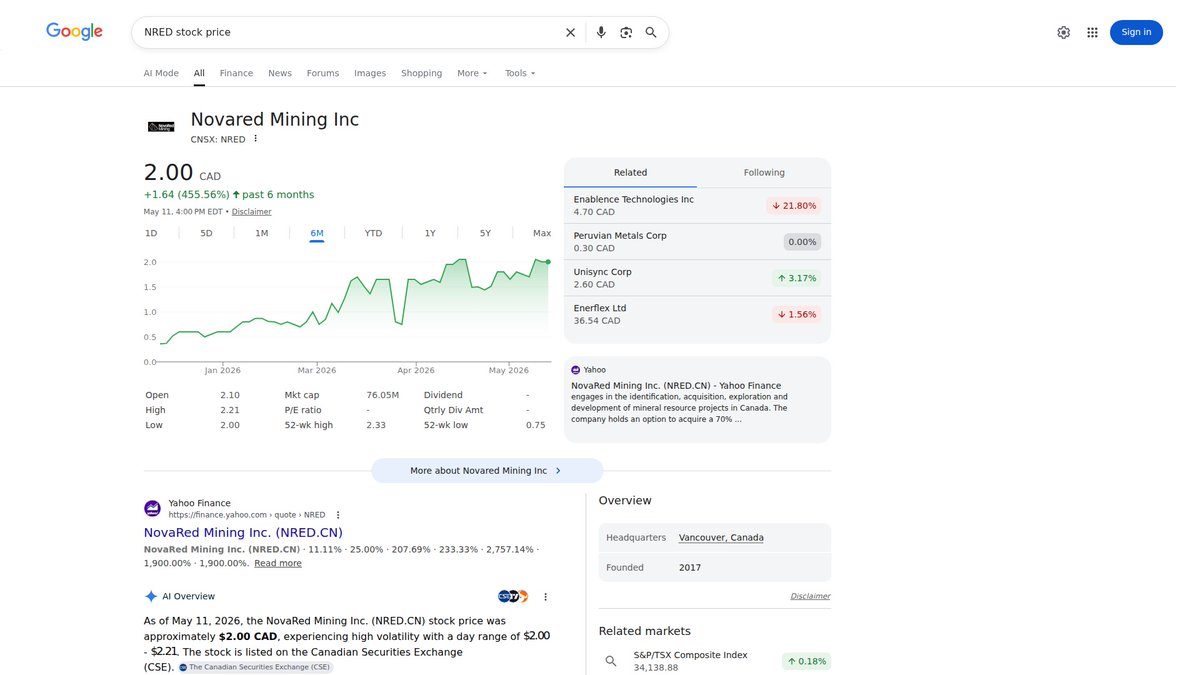
$NRED is down 2.44% today. Provisional patent. No validated model. The literature suggests that's called a hypothesis.
$PICK $COPX
#MLResearch
2
68

May 4
ARIS: Markdown-only skills for autonomous ML research. Cross-model review loops, idea discovery, experiment automation. No framework. Claude Code, Codex, OpenClaw, any agent. 62 skills Research Wiki. By wanshuiyin. Python.
8,001 stars
#MLResearch #AI
1
113

Update on the rosetta stone experiment! ran into issues training from scratch (undertrained models, near-zero induction scores), so I switched to analyzing pretrained models instead: GPT-2, Neel Nanda's C4 Code model, Pythia-160M, and GPT-Neo-125M.
the question stayed the same: do transformers trained on different data develop the same internal circuits?
So in plain English: these models learned the same trick, put it in the same place, and use it in almost exactly the same way even though they never saw the same data and were built completely differently.
The weights that implement the trick look nothing alike. But the behaviour is nearly identical.
It's like four people who grew up in different countries, speaking different languages, never meeting each other and all independently inventing the same mental shortcut for recognising patterns. The shortcut looks the same from the outside even though the neural wiring producing it is completely different.
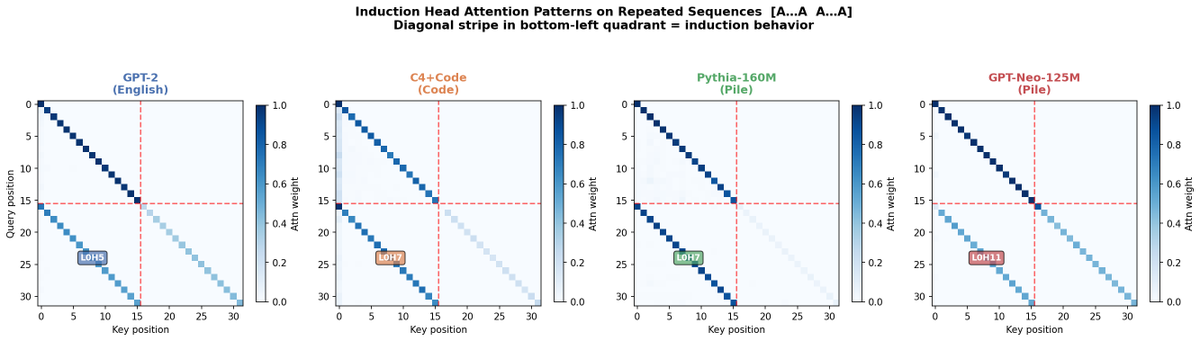
ran mechanistic circuit analysis on each. all four developed strong induction heads in layer 0, with scores between 0.52 and 0.87. then I fed all four identical repeated sequences and compared what their best induction heads actually attended to.
attention pattern correlation: 0.83 to 0.93 across all pairs.
the weights implementing these heads are essentially orthogonal across models near-zero cosine similarity. but the behavior is nearly identical.
same algorithm. completely different weights. gradient descent keeps rediscovering the same solution but never takes the same path to get there.
figures below.
#mlresearch


Running something called "The Rosetta Stone Experiment"
training 4 transformers from scratch right now. same architecture, same hyperparameters, completely different data which is english text, python code, protein sequences, and music.
the question is whether the same internal circuits emerge across all four. things like induction heads, the OV and QK weight structure, spectral patterns in the weight matrices.
the hypothesis: gradient descent keeps rediscovering the same computational primitives regardless of what it's trained on. if true, these aren't language-specific tricks they're something more fundamental about how transformers process sequences and if its false then oh well :p still fun isnt it?
#machinelearning #mlresearch #airesearch #iamsotired
2
60
Running something called "The Rosetta Stone Experiment"
training 4 transformers from scratch right now. same architecture, same hyperparameters, completely different data which is english text, python code, protein sequences, and music.
the question is whether the same internal circuits emerge across all four. things like induction heads, the OV and QK weight structure, spectral patterns in the weight matrices.
the hypothesis: gradient descent keeps rediscovering the same computational primitives regardless of what it's trained on. if true, these aren't language-specific tricks they're something more fundamental about how transformers process sequences and if its false then oh well :p still fun isnt it?
#machinelearning #mlresearch #airesearch #iamsotired
2
85

Entraîner un modèle en 2026 nécessite énormément de données de bonne qualité ainsi qu’une grande puissance de calcul ?
DeepSeek a récemment proposé une nouvelle architecture permettant d’entraîner des modèles performants sans forcément s’appuyer sur les lois d’échelle en données ou en GPU.
C’est autour de cette question que nous aurons le plaisir d’accueillir Sophie Basse SENE, ingénieure en intelligence artificielle.
Elle nous présentera l’article :
« mHC: Manifold-Constrained Hyper-Connections »
📅 Samedi 25 avril à 15h30
🔗 Lien d’inscription : lnkd.in/dhzWWrA4
#AI #MachineLearning #AIResearch #MLResearch #HC #mHC #Deepseek #ReadingGroup #GalsenAI
2
11
38
2,423

Mar 24
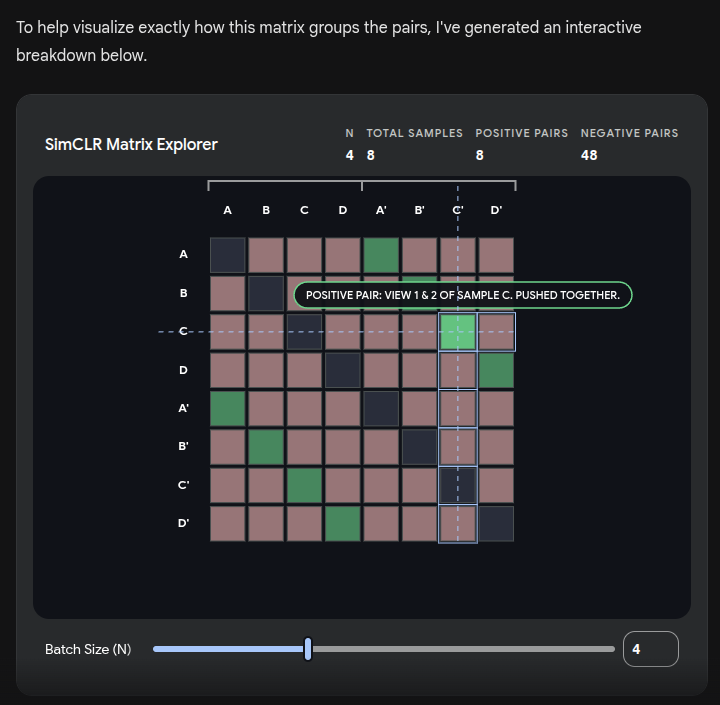
Now Gemini can create interactive visualizations! 🤯
Check out this SimCLR visualization.
#AI #MachineLearning #DeepLearning #SimCLR #ContrastiveLearning #DataScience #ArtificialIntelligence #GoogleGemini #AIVisualization #TechInnovation #MLResearch #NeuralNetworks #AITrends
1
2
61

Just discovered an incredible comprehensive survey on deep time series models!
It breaks down core modules, 5 major architectures
1)MLP
2)CNN
3)RNN
4)GNN
5)Transformer
Releases a benchmark with 30 models & 30 datasets for forecasting/classification/imputation/anomaly detection, and shares key empirical insights future directions.
#TimeSeriesAnalysis #DeepLearning #MLResearch
Paper:arxiv.org/pdf/2407.13278
1
2
121

Most ML research time isn't spent thinking. It's spent waiting.
Andrej Karpathy's autoresearch fixes that. You write a plain English instruction file telling the agent what to explore. It runs 5-minute experiments back to back — forming hypotheses, editing code, committing improvements, reverting failures — while you sleep. Roughly 100 experiments a night on a single GPU.
First real results:
→ 700 experiments on his own GPT-2 codebase. 11% speedup on code he'd already optimized by hand. The agent also caught a bug he'd missed.
→ Shopify's CEO woke up to a 0.8B model scoring 19% higher than his hand-tuned 1.6B baseline.
The shift Karpathy is pointing at: you don't write training code anymore. You write the research agenda. Everything else is execution the agent handles.
Full breakdown → link in comments.
#AgenticAI #MLResearch #LLMEngineering #AIEngineering

1
4
15
1,419
Nous parlons souvent de modèles, d’entraînement et de performance …
Mais que se passe-t-il lorsque ces modèles sont confrontés à de légères perturbations ou à des situations imprévues ?
Comment effectuer un fine-tuning robuste tout en évitant une dégradation des performances ?
C’est autour de cette question que nous aurons le plaisir d’accueillir Jonas NGNAWE, doctorant en informatique au Mila – Quebec AI Institute et à l'Université Laval, ainsi que chercheur invité au Stanford Trustworthy AI Research (STAIR) Lab.
Il nous présentera son article intitulé :
« ROBUST FINE-TUNING FROM NON-ROBUST PRETRAINED MODELS: MITIGATING SUBOPTIMAL TRANSFER WITH EPSILON-SCHEDULING »
📅 Samedi 28 mars à 15h30
🔗 Lien d’inscription
meetup.com/galsenai/events/3…
#ArtificialIntelligence #MachineLearning #AIResearch #MLResearch #FineTuning #AdversarialAttack #ReadingGroup #GalsenAI

1
4
200

Feb 24
We were thrilled to host @mtutek at our lab last week.
His talk "From Internals to Integrity: How Insights into Transformer LMs Improve Safety, Interpretability, and Explanation Faithfulness" led to great discussions! 👏
#Transformers #AISafety #ExplainableAI #MLResearch #NLProc

1
10
407

Feb 21
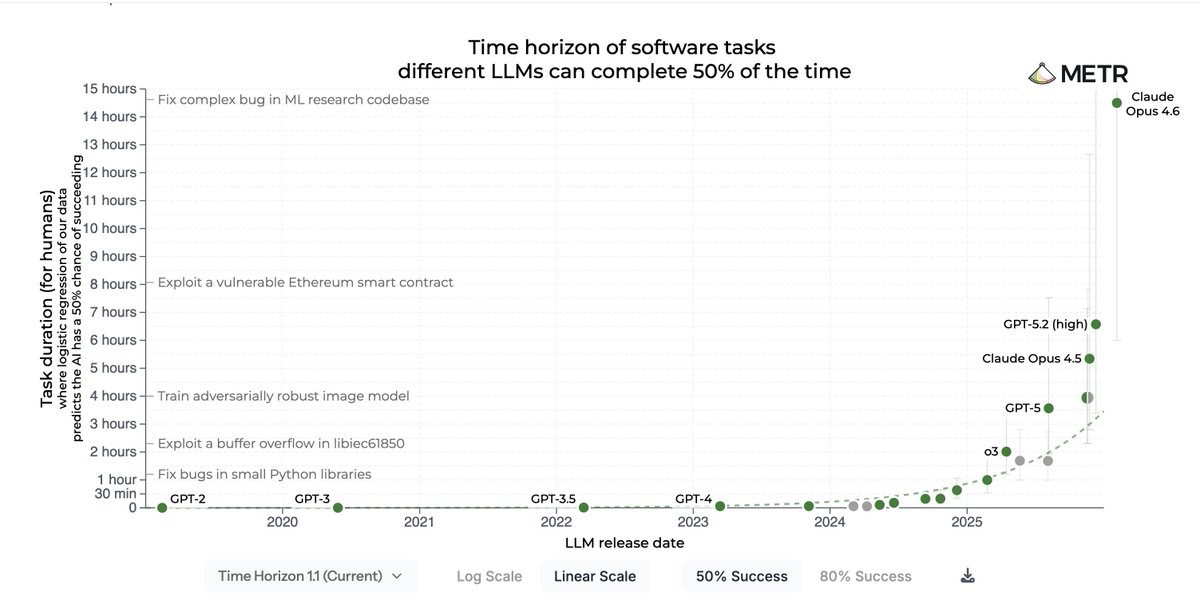
Claude Opus 4.6 now hits 50% on multi-hour expert ML research problems.
For the AI researchers and engineers: at what point does this change how research gets done?
#AI #Research #MLResearch
2
88


Feb 13
4️⃣ #PaperReviewStory #4
One time a reviewer actually tried to implement the provided method in a paper to run an example — and couldn’t do easily with the details shared.
Comment implied: “Critical implementation details missing from the paper.”
#Takeaway: Double check reusability details. Inability to reproduce the work signals missing information and lowers trust/score.
#AIResearch #PeerReview #MLResearch #NeurIPS #EMNLP #ACL #LLMs #ICLR #ICML #ComputerVision #GenerativeAI #AIConference #PaperWriting #ResearchTips #AcademicPublishing #ConferenceTips #PublishingAI #DataScience #MachineLearning #DeepLearning #AI #GenerativeAI #ResearchCommunity
2
46
1️⃣ #PaperReviewStory #1
This one was a first for me.
Recently I reviewed a paper that received a low score from a different reviewer mainly because it cited too many #arXiv papers.
Reviewer complaint: “Use venue citations where available.”
#Takeaway:
Even correct citations can hurt you if they signal “unfinished”, “non-peer-reviewed”, or even “outdated" to reviewers. Optics matter.
#TrueStory
How it ended? The reviewer increased their score during the rebuttal period after the author promised to update all references.😌
#AIResearch #PeerReview #MLResearch #NeurIPS #EMNLP #ACL #LLMs #ICLR #ICML #ComputerVision #GenerativeAI #AIConference #PaperWriting #ResearchTips #AcademicPublishing #ConferenceTips #PublishingAI #DataScience #MachineLearning #DeepLearning #AI #GenerativeAI #ResearchCommunity
3
104
🧑💻 **Trying to publish at top venues (NeurIPS / EMNLP / ACL / CVPR / ICML / ICLR)?**
After having reviewed 150 papers and reading over 1000 reviews, here are some tips to avoid low reviewer scores — based on what reviewers *actually* penalize.
Most rejects aren’t due to bad ideas.
They’re due to missing evidence, unclear claims, or reviewer confusion.
### What consistently helps scores
1️⃣ *Make your contribution obvious in 5 minutes*
Reviewers skim first.
If they can’t answer:
* What’s new?
* Why does it matter?
* How is it different from prior work?
…you’re already losing points.
Spell out contributions explicitly.
2️⃣ *Claims must match evaluation*
If you claim:
* robustness → test distribution shifts
* efficiency → report compute / latency
* reasoning → show task-specific evidence
Mismatch = low confidence.
3️⃣ *Statistical significance is no longer optional*
Single-run improvements are weak evidence.
Reviewers increasingly expect:
* multiple seeds
* variance / confidence intervals
* significance tests (when applicable)
One lucky run doesn’t count.
4️⃣ *Show generalization beyond one setup*
If it only works on:
* one model
* one dataset
* one benchmark
…reviewers will say “too narrow”.
Even limited cross-model or cross-data results help a lot.
5️⃣ *Baselines and ablations matter more than cleverness*
Strong, recent baselines > fancy ideas.
Ablations explain *why* something works — reviewers love that.
6️⃣ *Anticipate reviewer objections*
Ask:
* “Is this just engineering?”
* “Would this reproduce elsewhere?”
* “What’s the failure mode?”
Then answer those *in the paper*.
📌 **Bottom line**
Industry papers succeed when real-world work is translated into
**clear claims strong evidence reviewer-friendly framing**.
You don’t need to be an academic —
you need to make your work *easy to trust*.
🔁 Where can you publish next?
Upcoming deadlines:
■ #ACL industry track 🗓 Feb 14th, 2026
■ GRAIL-V at #CVPR 🗓 March 5th, 2026
■ #ARR for ACL* conferences 🗓 March 16, 2026
💭Want some more explicit examples of reviewer complaints? Reach out.
#IndustryResearch #NeurIPS #EMNLP #AIResearch #LLMs #Evaluations #MLResearch #PaperWriting #ArtificialIntelligence #AI #AgentSystems #MachineLearning #GPT #Claude #Gemini #Publishing #Research #Industry

4
592

𝗣𝗮𝗽𝗲𝗿 𝗔𝗰𝗰𝗲𝗽𝘁𝗮𝗻𝗰𝗲 𝗔𝗻𝗻𝗼𝘂𝗻𝗰𝗲𝗺𝗲𝗻𝘁
Paper titled 𝗘𝗳𝗳𝗶𝗰𝗶𝗲𝗻𝘁 𝗮𝗻𝗱 𝗔𝗰𝗰𝘂𝗿𝗮𝘁𝗲 𝗧𝗲𝗻𝘀𝗼𝗿 𝗖𝗼𝗺𝗽𝗿𝗲𝘀𝘀𝗶𝗼𝗻 𝘃𝗶𝗮 𝗥𝗲𝗰𝘂𝗿𝘀𝗶𝘃𝗲 𝗦𝗸𝗲𝘁𝗰𝗵𝗶𝗻𝗴 accepted at AISTATS 2026.
Authors: Amit Sharma, Mohammad Azhar Khan, Rameshwar P.
👏 Congratulations to all the authors!
🔍 Key Highlight:
Proposed a new sketching algorithm that provides unbiased inner-product estimation with variance completely independent of tensor order, overcoming a major limitation of existing methods, while also achieving faster computation.
#PaperAccepted #AISTATS2026 #MachineLearning #ArtificialIntelligence #MLResearch #AIResearch #DataScience #AcademicResearch #ResearchPublication
2
167

Jan 23
SAMs are cool guys.
1.) Sharpness-Aware Minimization
An optimizer that avoids sharp minima → better generalization in weight space.
2.) Segment Anything Model
Does exactly what the name says. SOTA segmentation.
#MachineLearning #DeepLearning #ComputerVision #MLResearch #AI


2
41