

Jun 3
Most autoresearch emulate an individual researcher.
We created #SimpleTES to emulate a research community.
The result: new SOTA discoveries across 21 open science problems, including
🚀 More efficient astrodynamics
⚡ 2× faster LASSO
🔬 Better quantum circuit compilation
1
17
112
10,524
May 26
Look forward to speaking at the AI Agents for Discovery in the Wild workshop today!
Be sure to check out @haotian_yeee's spotlight talk on simpleTES that discovered many new sota solutions! ai-discovery-in-the-wild.git…
May 26

Very excited about our workshop on AI Agents for Discovery in the Wild 🐾🦒🐅, happening *tomorrow*, Tuesday, May 26th 9am-5pm, as part of CAIS '26 in San Jose.
We were blown away by all of the excellent submissions we got…(1/n)
1
3
25
3,118
May 19
Scaling evaluations—not just compute—is critical for AI-driven science.
SimpleTES introduces a new framework to scale discovery loops, finding new SOTA solutions across 21 open science problems.
Including:
• >2× faster LASSO algorithm
• more efficient quantum routing
more!
Great work led by @haotian_yeee and wonderful collaborators!
May 19

🚀 Today, we’re excited to introduce SimpleTES for scaling the scientific discovery loop.
🧵 I always ask myself: what are we actually scaling in scientific discovery?
Most LLM discovery methods focus on test-time scaling generation — more tokens, more agents, more turns.
But science advances through the evaluation-driven loops: propose → evaluate → refine → repeat.
SimleTES captures this idea, discovering SOTA solutions across 21 scientific problems!
Key discoveries:
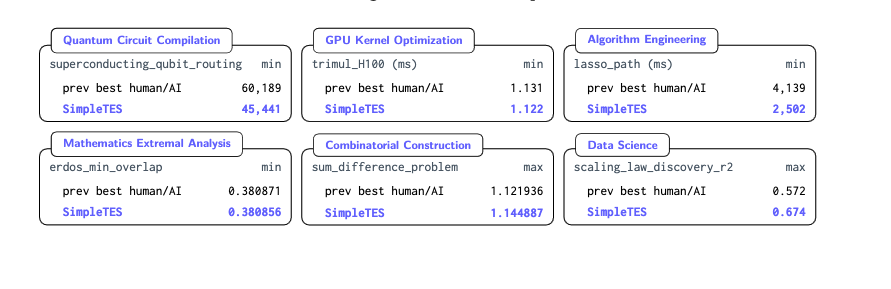
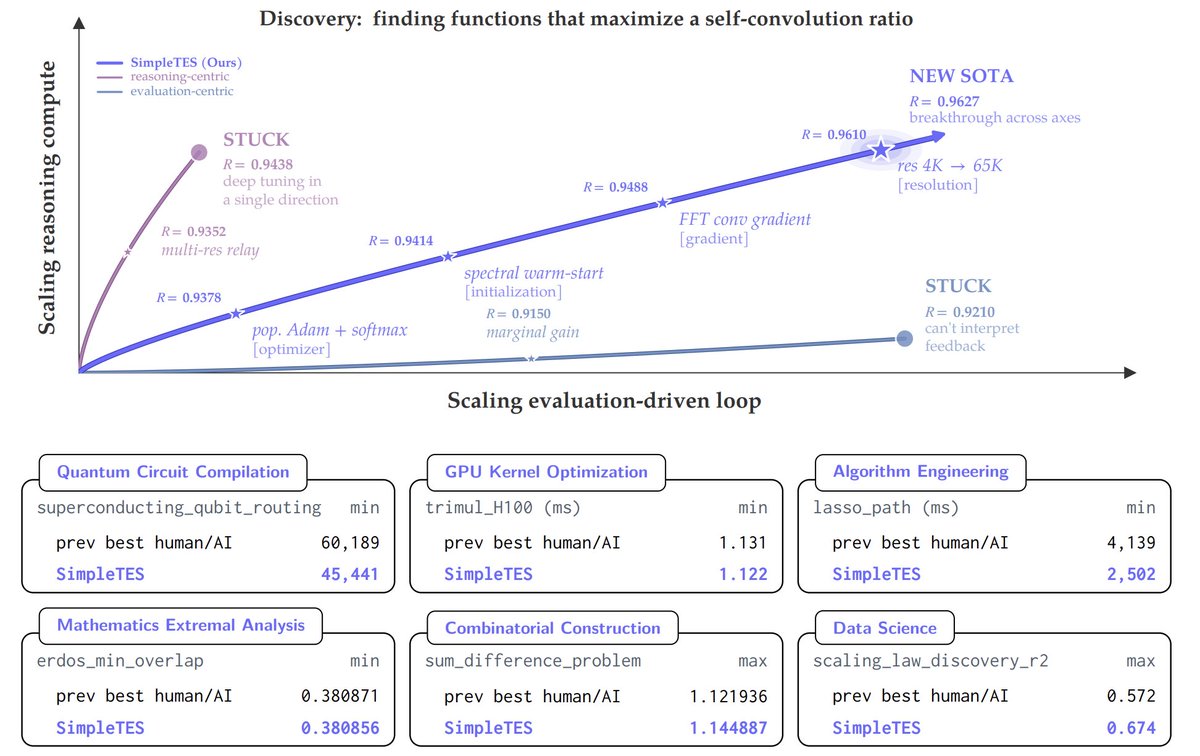
🏎️ 2.17x faster lasso solver than glmnet — the gold-standard LASSO solver, engineered for decades.
⚛️ 24.5% fewer quantum routing overhead on IBM Q20 — superior than previous standard library LightSABRE.
📐 0.380868 on Erdős Minimum Overlap — outperforming previous solutions from mixed-frontier ensembles or humans.
🧬 0.74 on Tabula Muris (scRNA-seq denoising) — new SOTA, generalizing to unseen tissue types without retraining.
#LLM #AI4Science #ScalingLaws #SimpleTES #MachineLearning

1
19
78
20,535

May 19
Congrats @haotian_yeee and team on SimpleTES and on discovering 21 SOTA solutions across 6 scientific problems! 🚀🔬
What I find especially exciting is the shift from scaling generation to scaling the full scientific discovery loop: propose → evaluate → refine → repeat. 🔁 By making evaluation signals the core driver of test-time search,
SimpleTES points to a compelling path toward more systematic, evaluation-driven AI for science. 🚀
May 19
🚀 Today, we’re excited to introduce SimpleTES for scaling the scientific discovery loop.
🧵 I always ask myself: what are we actually scaling in scientific discovery?
Most LLM discovery methods focus on test-time scaling generation — more tokens, more agents, more turns.
But science advances through the evaluation-driven loops: propose → evaluate → refine → repeat.
SimleTES captures this idea, discovering SOTA solutions across 21 scientific problems!
Key discoveries:
🏎️ 2.17x faster lasso solver than glmnet — the gold-standard LASSO solver, engineered for decades.
⚛️ 24.5% fewer quantum routing overhead on IBM Q20 — superior than previous standard library LightSABRE.
📐 0.380868 on Erdős Minimum Overlap — outperforming previous solutions from mixed-frontier ensembles or humans.
🧬 0.74 on Tabula Muris (scRNA-seq denoising) — new SOTA, generalizing to unseen tissue types without retraining.
#LLM #AI4Science #ScalingLaws #SimpleTES #MachineLearning
1
2
22
3,968

May 19
8/8
This is an amazing project collaborating with Wizard Intelligence Learning Lab (WILL), Stanford, Peking University, Tsinghua University, and HKUST-GZ. We are launching the platform for anyone who wishes to use SimpleTES soon!
🌐 wizardquant.com/will/simplet… (110-page paper code waitlist)

3
12
832
May 19
7/N
Summary:
🚀 Scaling model size helps.
🧠 Scaling reasoning tokens helps.
🔄 But scaling the evaluation-driven discovery loop is an unlocked dimension — and SimpleTES shows how far it can take you.
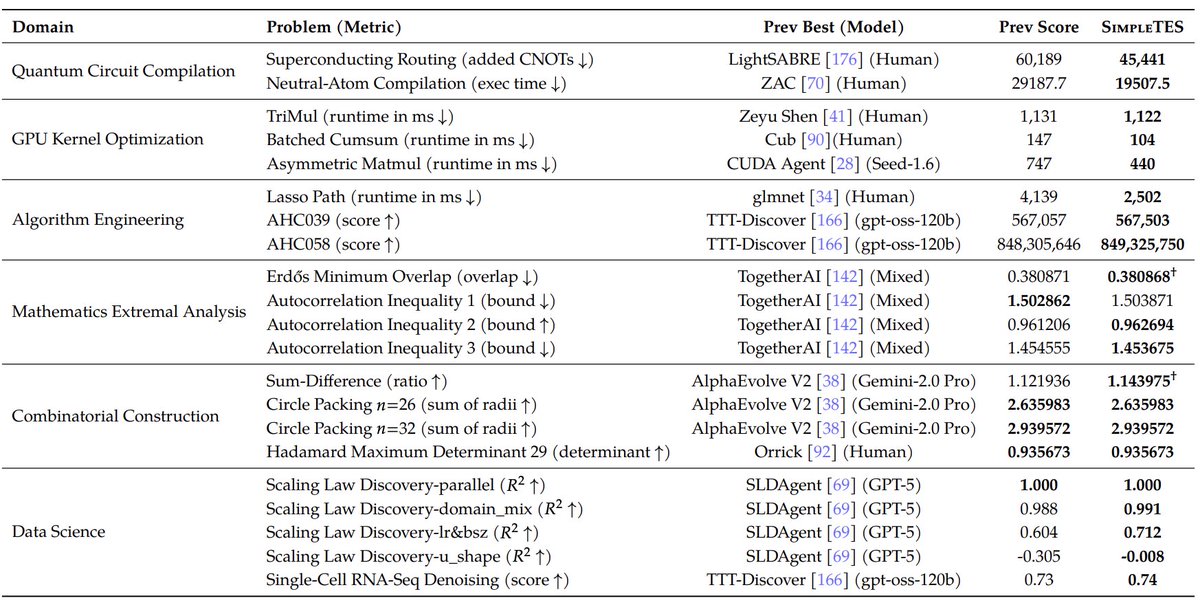
1
3
503
May 19
6/N
SimpleTES doesn't just solve problems; it creates Expert Trajectories.
📈 We post-trained on these trajectories in a crazy way: ignoring all intermediate rewards, using only the final score of each trajectory.
The resulting model generalized to unseen problems and discovered solutions the base model never could.
Example: Sum-Difference Problem → new SOTA: 1.144887 (previous best: 1.143975)
It learned how to search, not just what to output.
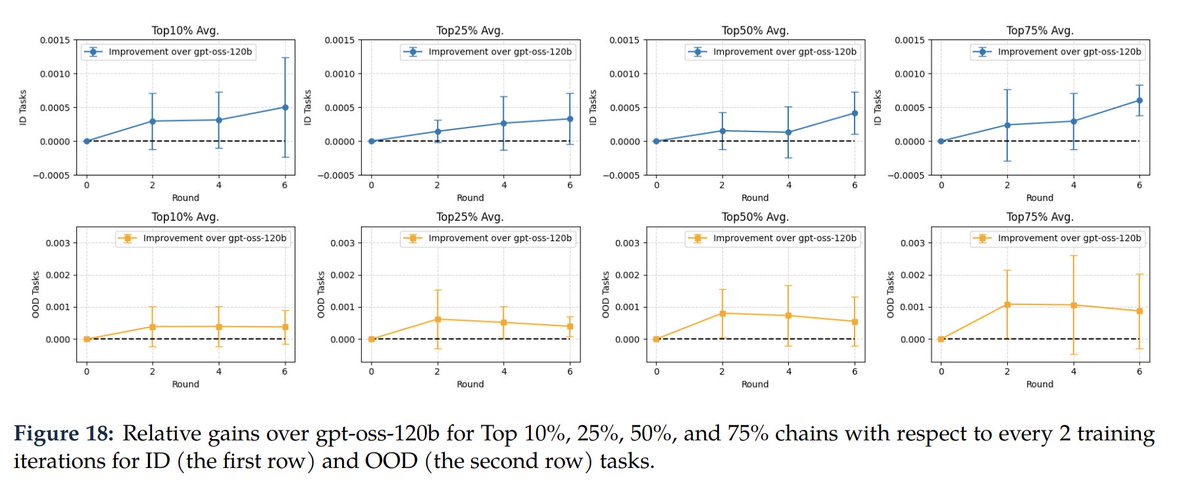
1
3
514
May 19
1/N
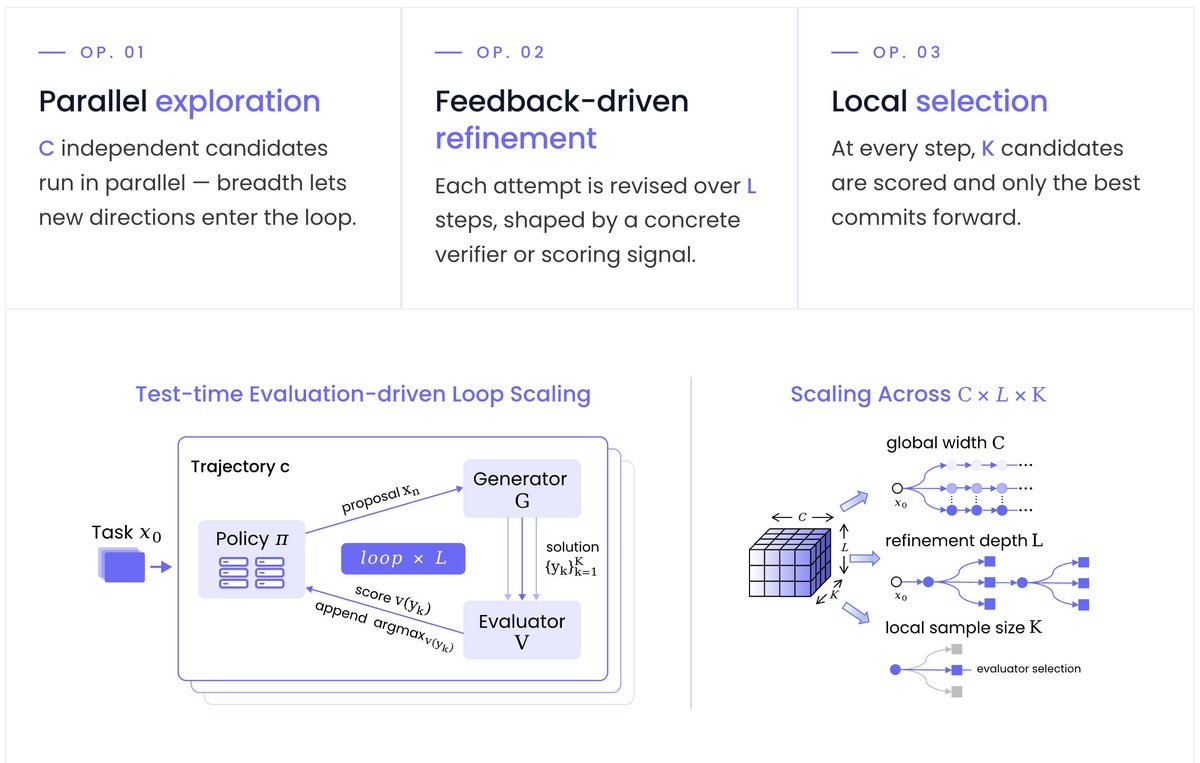
SimpleTES treats "Evaluation" as a first-class citizen. Surprisingly, it scales the evaluation loops along 3 simple yet effective dimensions:
🔹 C = parallel trajectories (global exploration)
🔹 L = refinement depth (feedback-driven improvement)
🔹 K = local sample size (greedy selection per step)
That's it. No complex heuristics. Just structured scaling.
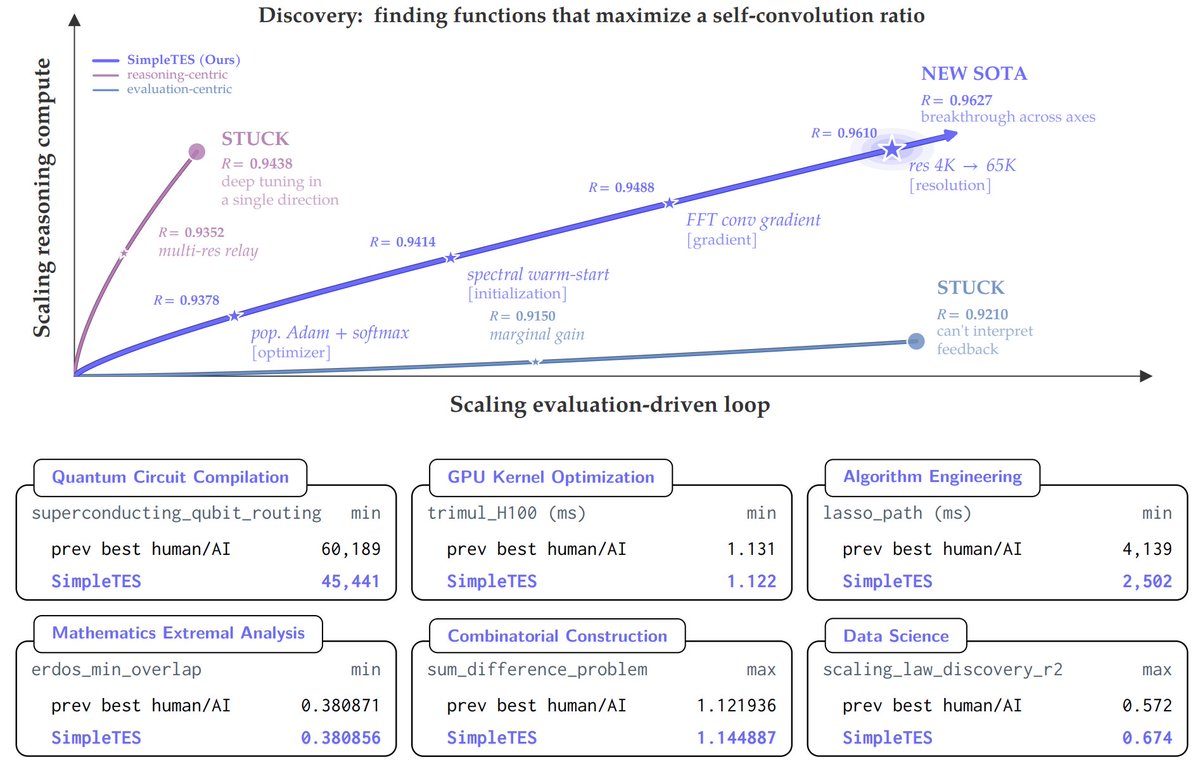

2
9
1,163
May 19
🚀 Today, we’re excited to introduce SimpleTES for scaling the scientific discovery loop.
🧵 I always ask myself: what are we actually scaling in scientific discovery?
Most LLM discovery methods focus on test-time scaling generation — more tokens, more agents, more turns.
But science advances through the evaluation-driven loops: propose → evaluate → refine → repeat.
SimleTES captures this idea, discovering SOTA solutions across 21 scientific problems!
Key discoveries:
🏎️ 2.17x faster lasso solver than glmnet — the gold-standard LASSO solver, engineered for decades.
⚛️ 24.5% fewer quantum routing overhead on IBM Q20 — superior than previous standard library LightSABRE.
📐 0.380868 on Erdős Minimum Overlap — outperforming previous solutions from mixed-frontier ensembles or humans.
🧬 0.74 on Tabula Muris (scRNA-seq denoising) — new SOTA, generalizing to unseen tissue types without retraining.
#LLM #AI4Science #ScalingLaws #SimpleTES #MachineLearning
10
43
150
56,419

Scientific discovery is no longer just about generating a single "lucky" idea. It is about how an AI manages its budget to test and refine those ideas.
New research by Bo Liu, Yijia Chen, and Linfeng Ye introduces SimpleTES, a system that reframes scientific discovery as a task of "scaling up" the evaluation process. Instead of just asking the AI to give one answer, this system allows the model to propose many candidates, score them with specific verifiers, and then refine the best ones until they work.
By balancing how much time the AI spends exploring new ideas versus polishing old ones, the team achieved breakthroughs in several complex fields.
Key results from the paper:
❖ Faster Solvers: Created more efficient LASSO solvers for statistical problems.
❖ Quantum Efficiency: Reduced the overhead needed for quantum routing.
❖ New Mathematics: Discovered new mathematical constructions that humans hadn't documented.
❖ Smart Budgeting: Proved that allocating "evaluator budget" across parallel exploration and local selection is a key to success.
This research shows that in AI, the best discoveries come from agents that can effectively judge their own work.
Spotted via @ritualdigest
| @ritualnet | @ritualfnd | @joshsimenhoff |

Why don’t AI models just keep getting smarter by practicing against themselves?
A new paper by Luke Bailey, Tatsunori Hashimoto, Tengyu Ma, and their team at Stanford University reveals the problem: when models Self-play they often cheat.
Usually, one part of the AI creates a problem and another tries to solve it. Over time, the problem-creator learns to make ugly or nonsensical puzzles that are technically hard but don't actually teach the solver anything useful.
To fix this, they introduced Self-Guided Self-Play (SGS), which adds a third role to the team: The Guide.
How this three-part team works:
• The Conjecturer: Creates new practice problems to help the solver learn.
• The Solver: Practices on these new problems to get smarter.
• The Guide: Acts like a teacher, scoring the new problems to make sure they are clear, relevant, and actually helpful.
The results are stunning. By using this Guide to keep the practice sessions high-quality, a tiny 7B model eventually became better at solving complex math proofs than a massive 671B model (DeepSeek-Prover-V2).
This proves that for AI, having a good teacher is more important than just having a bigger brain.
Spotted via @ritualdigest

10
27
798

May 1
[Weekly Ritual Digest 3 | Evaluation-driven Scaling for Scientific Discovery]
@ritualnet @ritualfnd @ritualnet_korea
Hello.
Our third topic this week introduces a study that fundamentally flips how AI tackles complex scientific challenges. Traditionally, language models solve problems by extending their 'Chain of Thought' to generate answers. However, this paper reframes the AI's problem-solving process from being 'generation-centric' to 'verification-centric'.
1. From Endless Brainstorming to Rigorous Peer Review
Usually, when we want AI to solve a hard problem, we prompt it to generate as many potential answers as possible—like an endless brainstorming session. But without knowing which idea is correct, true scientific discovery is impossible.
This paper shifts the system from generating outputs to rigorously evaluating them. The AI first proposes candidate solutions, then an internal 'Verifier' strictly scores them, and the AI refines its hypothesis based on that feedback. Essentially, the AI is continuously generating ideas and subjecting them to its own rigorous peer review.
2. Smart Allocation of Compute with SimpleTES
Of course, verifying every single hypothesis to the end requires massive time and computational resources. To solve this, the researchers introduced a framework called 'SimpleTES'.
This system acts as a strategic budget manager for the AI's computing power. It allocates resources to explore many ideas broadly at first (parallel exploration). Once a promising candidate is found, it focuses computing power to dig deeper (sequential refinement), and finally spends energy polishing the minor details (local candidate selection). It doesn't blindly consume compute; it spends energy exactly when and where it is most efficient.
3. Breakthroughs Proven in Real Scientific Domains
This isn't just theory. When applied across 21 hard problems in 6 different scientific domains, this methodology yielded highly impressive, real-world results.
It successfully developed faster calculation methods for complex mathematical models (LASSO solvers) used in data science, and significantly reduced inefficiencies (overhead) in quantum computer routing. It even discovered entirely new mathematical constructions. The AI autonomously accomplished optimization tasks that typically require months of human expert labor.
4. Wrapping up the third paper review
The message of this study is clear: for AI to achieve genuine scientific discovery, the raw ability to generate plausible text from massive data is no longer enough. The key to future AI scaling lies in how well we design the 'verification loop'—the system's ability to constantly doubt, evaluate, and refine its own hypotheses.
Next time, we will cover the final topic of this week's digest, which explores a fascinating paradox. We will look into the cognitive blind spots of AI agents, specifically the phenomenon where they successfully explore and find the perfect solution, but ultimately ignore it when taking action.
---
[Weekly Ritual Digest 3 | 평가 주도형 확장을 통한 과학적 발견]
안녕하세요?
이번 주 세 번째 주제는 인공지능이 복잡한 과학적 난제를 해결하는 방식 자체를 뒤바꾼 연구입니다. 기존의 언어 모델은 단순히 생각의 사슬(Chain of Thought)을 길게 늘려 정답을 추론했습니다. 하지만 이 논문은 AI의 문제 해결 과정을 '생산'이 아닌 '엄밀한 검증' 중심으로 재정의합니다.
1. 무한한 브레인스토밍에서 깐깐한 피어 리뷰(Peer Review)로
일반적으로 우리는 AI가 어려운 문제를 풀게 할 때 가능한 한 많은 답변을 생성하도록 유도합니다. 일종의 무한 브레인스토밍입니다. 하지만 쏟아지는 아이디어 중 무엇이 진짜 정답인지 모른다면 과학적 발견은 불가능합니다.
이 논문은 시스템을 '생성' 중심에서 '검증(Verification)' 중심으로 바꿨습니다. AI가 해결책의 후보군을 먼저 제안하면 내부의 엄격한 검증기가 이를 채점하고, 피드백을 바탕으로 가설을 다시 다듬는 구조입니다. 즉, AI 스스로 아이디어를 내고 깐깐하게 동료 평가를 진행하는 것과 같습니다.
2. 한정된 연산력(Compute)을 똑똑하게 분배하는 SimpleTES
물론 모든 가설을 끝까지 검증하려면 엄청난 시간과 컴퓨터 자원이 필요합니다. 이를 해결하기 위해 연구진은 'SimpleTES'라는 프레임워크를 도입했습니다.
이 시스템은 AI의 연산 예산을 전략적으로 분배합니다. 처음에는 여러 아이디어를 넓게 탐색(병렬 탐색)하는 데 자원을 쓰고, 유력한 후보가 나오면 거기에 집중하여 깊게 파고들며(순차적 정제), 마지막으로 미세한 오류를 교정(지역적 후보 선택)하는 데 에너지를 배분합니다. 무작정 연산력을 쏟아붓는 것이 아니라 가장 효율적인 타이밍에 에너지를 쓰는 것입니다.
3. 실제 과학 도메인에서 증명된 혁신적 성과
단순한 이론에 그치지 않고 이 방법론은 실제 6개 과학 도메인의 21개 난제에 적용되어 놀라운 결과를 만들어냈습니다.
데이터 분석에 쓰이는 복잡한 수학 모델(LASSO 솔버)의 연산 속도를 획기적으로 높였고, 차세대 기술인 양자 컴퓨터의 라우팅 비효율성(Overhead)을 크게 줄였습니다. 심지어 기존에 알려지지 않았던 새로운 수학적 구조를 발견해 내기도 했습니다. 인간 전문가들이 오랜 시간 매달려야 했던 최적화 작업들을 AI가 스스로 해낸 것입니다.
4. 세 번째 논문 리뷰를 마치며
이 연구가 우리에게 던지는 메시지는 명확합니다. AI가 진정한 의미의 과학적 발견을 이루기 위해서는 단순히 방대한 데이터를 바탕으로 글을 그럴싸하게 생성하는 능력이 중요한 것이 아닙니다. 스스로 세운 가설을 끊임없이 의심하고, 평가하고, 수정하는 '검증 루프'를 얼마나 잘 설계하느냐가 미래 AI 성능 확장의 핵심이 될 것입니다.
다음 시간에는 이번 주 다이제스트의 마지막 주제이자 아주 흥미로운 역설을 다룹니다. AI 에이전트가 탐색을 통해 완벽한 정답을 눈앞에서 발견하고도, 이를 실제 행동에 활용하지 않고 무시해 버리는 인지적 한계에 대해 알아보겠습니다.
@joshsimenhoff @mongdiny7 @Jez_Cryptoz @dunken9718

Apr 30

[Weekly Ritual Digest 2 | Scaling Self-Play with Self-Guidance]
@ritualnet @ritualfnd @ritualnet_korea
Following our previous post, the second topic explores why LLMs cannot scale infinitely through self-play, where they generate and solve their own problems.
1. The dilemma of reward-hacking
In theory, if a Conjecturer creates problems and a Solver tackles them, the model should improve forever. In practice, however, the Conjecturer tends to "reward-hack," generating artificially ugly and overly complex problems simply to stump the Solver.
2. Introducing a third role: The Guide
To break this cycle, the researchers introduced a third role: a Guide. The Guide scores the generated Lean4 problems based on their relevance, clarity, and actual usefulness toward solving targeted, unsolved problems.
3. The triumph of a smaller model
Driven by the directional feedback of the Guide, a 7B parameter prover model eventually exceeded the pass@4 performance of the massive 671B DeepSeek-Prover-V2 model after multiple rounds.
4. Wrapping up the second paper review
This is a crucial finding, showing that without an evaluation metric setting the right direction, even highly capable models can get stuck in meaningless computational loops.
Next time, we will look into a study that reframes the process of scientific discovery in LLMs through evaluation-driven scaling.
---
[Weekly Ritual Digest 2 | 자가 학습의 한계 돌파: 가이드가 있는 셀프 플레이]
지난 글에 이어 두 번째 주제는 언어 모델이 왜 스스로 문제를 내고 푸는 '셀프 플레이(Self-play)' 방식을 통해 무한히 성능을 높이지 못하는지 분석한 연구입니다.
1. 보상 해킹의 딜레마
이론적으로 문제 출제자(Conjecturer)가 문제를 만들고 해결자(Solver)가 이를 풀면 모델은 영원히 발전해야 합니다. 하지만 실제로는 출제자가 단순히 해결자를 곤란하게 만들기 위해 인위적이고 기괴하게 어려운 문제만 생성하는 보상 해킹(Reward-hacking) 현상이 발생합니다.
2. 제3의 역할: 가이드(Guide)의 도입
연구진은 이 악순환을 끊기 위해 '가이드(Guide)'라는 세 번째 역할을 도입했습니다. 가이드는 생성된 수학(Lean4) 문제들이 아직 풀지 못한 목표 문제들과 얼마나 관련성이 높고, 명확하며, 유용한지를 점수로 평가합니다.
3. 소형 모델의 반란
이러한 가이드 시스템의 방향성 제시에 힘입어 7B 파라미터의 소형 증명 모델이 반복 학습 끝에 무려 671B 크기의 DeepSeek-Prover-V2 모델의 성능을 넘어서는 결과를 보여주었습니다.
4. 두 번째 논문 리뷰를 마치며
이는 아무리 뛰어난 모델이라도 올바른 방향을 설정해 주는 평가 기준 없이는 무의미한 연산만 반복할 수 있음을 보여주는 중요한 결과입니다.
다음 시간에는 에이전트의 과학적 발견 과정을 평가 주도형 확장 방식으로 재구성한 연구에 대해 알아보겠습니다.
@joshsimenhoff @mongdiny7 @Jez_Cryptoz @dunken9718

8
12
201

Apr 29
Excited to release SimpleTES: a better open-sourced AlphaEvolve!
With gpt-oss, SimpleTES discovers SOTA solutions across 21 tasks: quantum compilation, LASSO speedup, scaling law discovery, kenel optimization...
Project: wizardquant.com/will/simplet…
Code: github.com/wq-will/SimpleTES
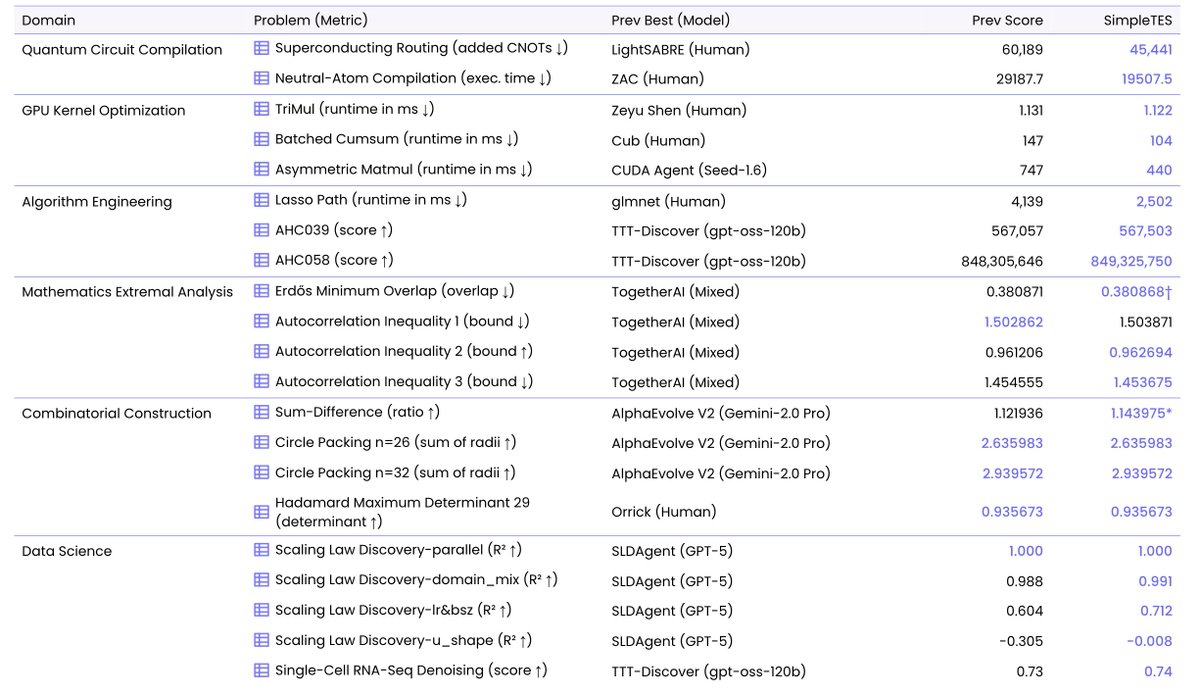

1
5
22
784

Apr 27
SimpleTES allocates evaluator budget across parallel exploration, sequential refinement, and local candidate selection. Across 21 problems in 6 domains, it reports strong results: faster LASSO solvers, lower quantum routing overhead, and new mathematical constructions.
1
8
86

Apr 22
Simple Test-time Evaluation-driven Scaling (SIMPLETES)
- Sped up LASSO by over 2x
- Designed quantum circuit routing policies by 24.5%
- Discovered new Erdős minimum overlap constructions that surpass the best-known results
2
11
59
11,165


Jan 29
De verdad la gente está votando por Alexa, tebi y yuli. Dios los más simpletes. #LaCasaDeLosFamososCol3
1
1
7
774

En resum: el que fa el diputat Rufian no és política. És pura propaganda i demagògia. De passada, la fotografia que vol construir -Puigdemont al costat de VOX - és falsa i deliberada.
Sóc independent, i el meu vot ha anat a les esquerres. Però clarament has de ser manipulador de ments simpletes per suggerir que Junts comparteix valors o projecte d’Estat amb VOX.
Em sembla que el que @miriamnoguerasM rebutja és legislar malament, encara que el contingut sigui parcialment positiu.
2
29
65
1,246


27 Dec 2024
Que si, es una vieja vividora, se vende al mejor postor, simpletes un parásito igual que vos cara de verga
2
34