
14 Aug 2025
Inference of Germinal Center Evolutionary Dynamics via Simulation-Based Deep Learning
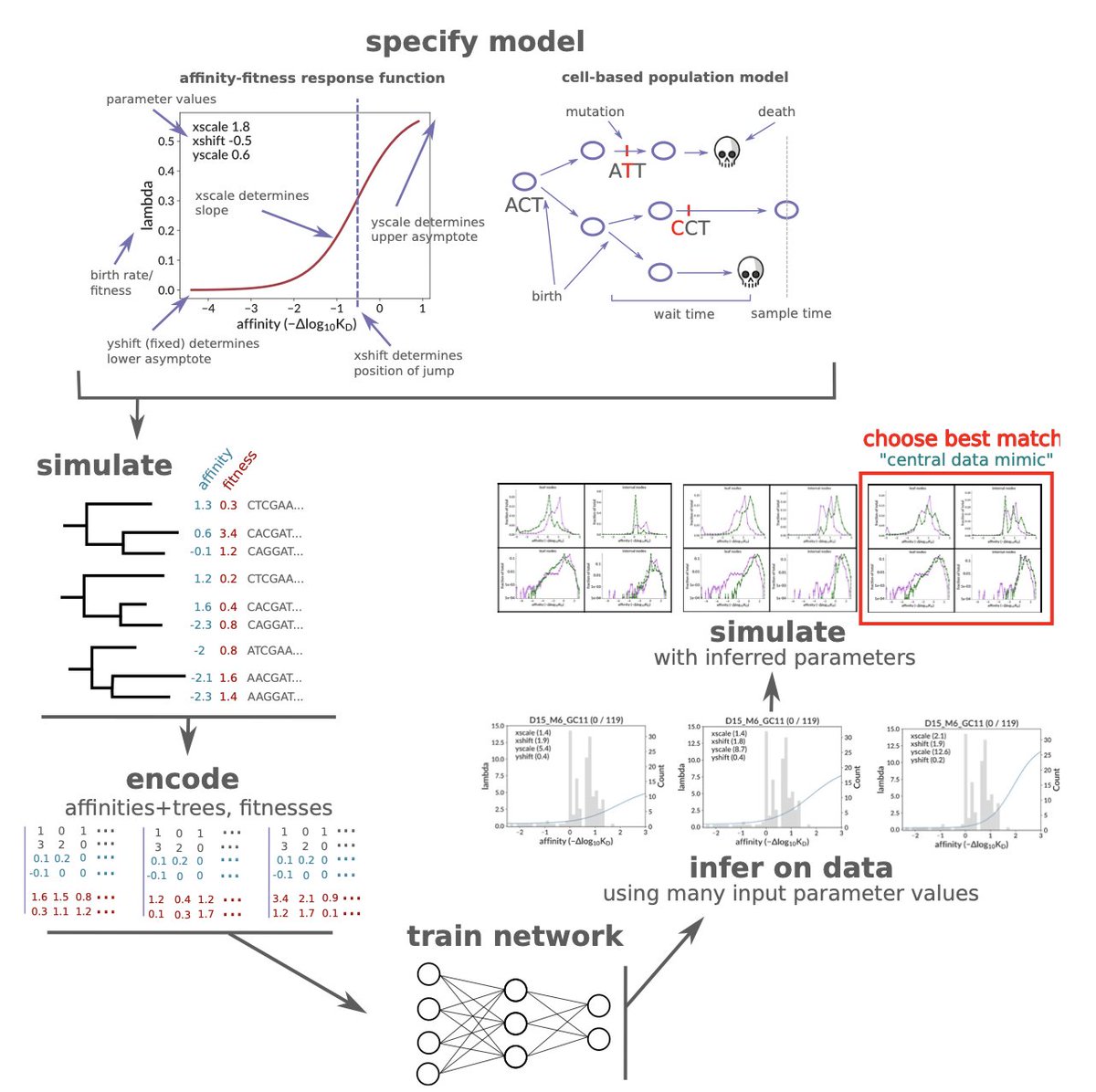
1. This novel study leverages simulation-based deep learning to uncover the relationship between B cell affinity and fitness within germinal centers (GCs), a critical component of the adaptive immune system. The research provides novel insights into how B cells evolve to produce high-affinity antibodies.
2. The study introduces a unique experimental approach called the “replay” experiment, which involves repeatedly exposing identical B cells to an antigen and observing their evolutionary dynamics over time. This setup allows for a detailed analysis of the affinity-fitness relationship in a controlled environment.
3. A key innovation is the use of a birth-death model with a population size constraint to simulate the GC dynamics. The model incorporates a sigmoid-shaped affinity-fitness response function, which maps the affinity of B cells to their reproductive success. This function is inferred using deep learning techniques.
4. The researchers employ a neural network to predict the parameters of the affinity-fitness response function. The network is trained on simulated data and then applied to real GC data, demonstrating its ability to accurately infer the relationship between affinity and fitness.
5. The study finds that the intrinsic fitness of B cells triples from naive (affinity 0) to affinity 1, and then triples again from affinity 1 to 2. This suggests a significant increase in reproductive success as B cells mutate to higher affinities.
6. The research also explores the effective birth rate of B cells, which accounts for population size constraints and competition. The effective birth rate is found to be more dynamic and context-dependent compared to the intrinsic birth rate.
7. The study validates its findings by comparing the inferred dynamics with summary statistics from real GC data. The results show a strong match, confirming the robustness of the simulation-based inference approach.
8. Limitations of the study include potential misspecifications in the model and assumptions about the GC dynamics. However, the approach provides a powerful framework for understanding complex biological processes that are otherwise difficult to analyze directly.
💻Code: github.com/matsengrp/gcdyn
📜Paper: arxiv.org/abs/2508.09871v1
#GerminalCenter #DeepLearning #EvolutionaryDynamics #ImmuneSystem #SimulationBasedInference #Biology #ComputationalBiology
2
706
30 Jun 2025
Coalescence and Translation: A Language Model for Population Genetics
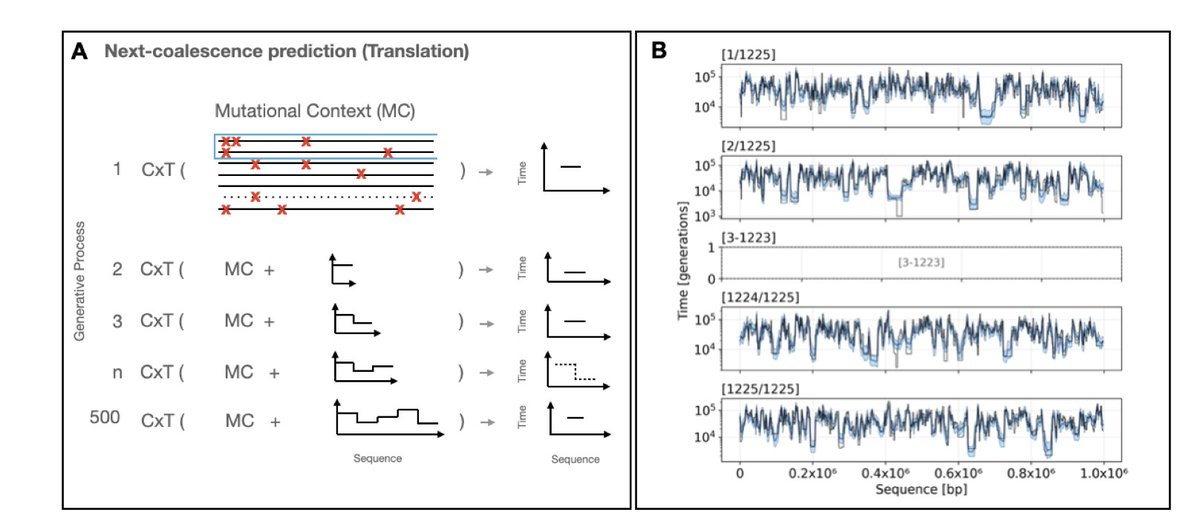
1.This study introduces cxt, a decoder-only transformer model that reframes coalescent time inference in population genetics as a sequence modeling problem, analogous to language translation. It translates local mutation patterns into coalescent times, enabling rapid and flexible inference of evolutionary history from genetic data.
2.Unlike traditional SMC-based methods, cxt does not rely on handcrafted likelihoods. Instead, it is trained on simulated data to predict the time to the most recent common ancestor (TMRCA) in an autoregressive fashion, using a next-coalescence prediction objective.
3.cxt achieves state-of-the-art accuracy across a range of demographic scenarios, outperforming or matching both Singer (ARG-based) and Gamma-SMC (SMC-based) models. It is particularly effective in non-constant population size models, such as sawtooth and island scenarios.
4.The model is highly efficient: cxt can infer over a million pairwise coalescence times in under five minutes using a single NVIDIA A100 GPU, allowing for genome-scale analysis at population scale.
5.A key innovation is its ability to generate well-calibrated approximate posterior distributions over TMRCAs. This enables principled uncertainty quantification, a feature often lacking in other deep learning approaches.
6.cxt generalizes well out-of-distribution, as shown by its performance on unseen species and demographic models in stdpopsim v0.3. Fine-tuning further improves accuracy in novel settings, demonstrating its potential as a flexible foundation model.
7.The model’s broad training across stdpopsim v0.2 species allows it to act like a context-sensitive database, capable of returning different coalescence distributions depending on the input, without needing retraining.
8.cxt’s posterior predictions were validated using empirical coverage and variance under varying mutation rates. Results show consistent calibration and sensitivity to mutational density, even in challenging inference windows.
9.The method was applied to 1000 Genomes Project data, successfully identifying known genomic regions with atypical coalescence histories—e.g., a recent sweep at the LCT locus and deep coalescent times in the HLA region—demonstrating its utility in real-world data.
10.Architecturally, cxt modifies GPT-2 to handle continuous mutational input projected into latent space. Coalescent times are discretized and learned autoregressively, with rotary positional embeddings encoding local genomic distance.
11.The authors introduce the "next-coalescence prediction" task, analogous to next-token prediction in language models, but tailored to sequential TMRCA estimation. This formulation enables structured learning of genealogical processes.
12.The approach is scalable, generalizable, and conceptually distinct from prior DL-based tools like CoalNN or ReLERNN. By modeling the generative process directly, cxt can capture richer evolutionary patterns without relying on predefined summary statistics.
13.The authors view cxt as a foundational model for coalescent inference, with future directions including modeling selection, multi-lineage coalescence, and extending to larger sample sizes or new species via fine-tuning.
14.While the current implementation uses fixed 2kb windows, the authors discuss tradeoffs in resolution, model complexity, and memory efficiency, suggesting avenues for optimization such as adaptive window sizes and local attention mechanisms.
15.Crucially, cxt requires only mutation rates for calibration, bypassing the need for recombination rate inputs. This simplifies deployment while maintaining accuracy and adaptability across species and parameter regimes.
💻Code: github.com/kr-colab/cxt
📜Paper: biorxiv.org/content/10.1101/…
#PopulationGenetics #CoalescentTheory #LanguageModels #Genomics #DeepLearning #TMRCA #ARG #TransformerModel #SimulationBasedInference
2
668
30 Jun 2025
Coalescence and Translation: A Language Model for Population Genetics
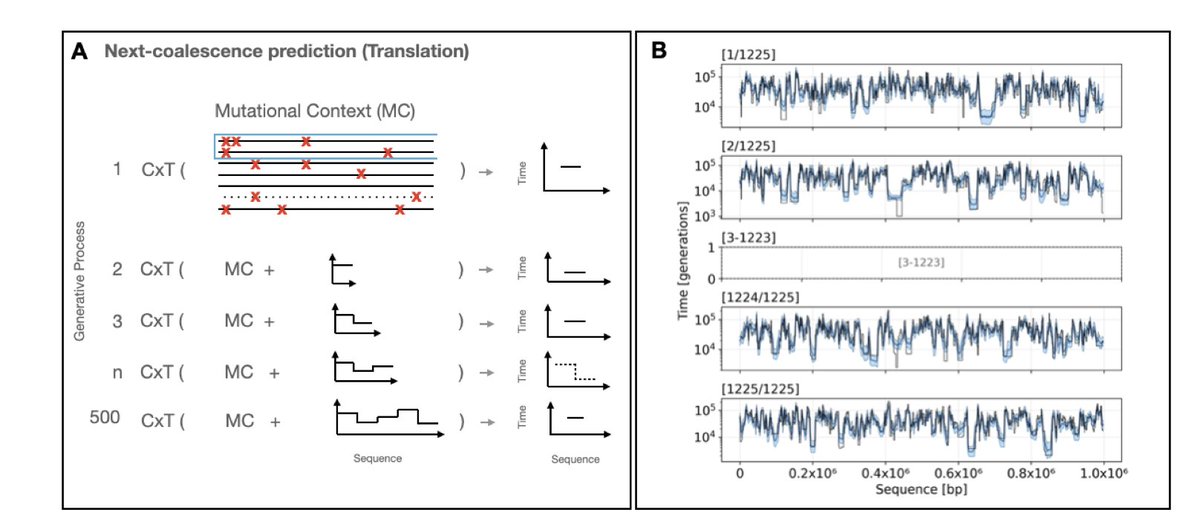
1.This study introduces cxt, a decoder-only transformer model that reframes coalescent time inference in population genetics as a sequence modeling problem, analogous to language translation. It translates local mutation patterns into coalescent times, enabling rapid and flexible inference of evolutionary history from genetic data.
2.Unlike traditional SMC-based methods, cxt does not rely on handcrafted likelihoods. Instead, it is trained on simulated data to predict the time to the most recent common ancestor (TMRCA) in an autoregressive fashion, using a next-coalescence prediction objective.
3.cxt achieves state-of-the-art accuracy across a range of demographic scenarios, outperforming or matching both Singer (ARG-based) and Gamma-SMC (SMC-based) models. It is particularly effective in non-constant population size models, such as sawtooth and island scenarios.
4.The model is highly efficient: cxt can infer over a million pairwise coalescence times in under five minutes using a single NVIDIA A100 GPU, allowing for genome-scale analysis at population scale.
5.A key innovation is its ability to generate well-calibrated approximate posterior distributions over TMRCAs. This enables principled uncertainty quantification, a feature often lacking in other deep learning approaches.
6.cxt generalizes well out-of-distribution, as shown by its performance on unseen species and demographic models in stdpopsim v0.3. Fine-tuning further improves accuracy in novel settings, demonstrating its potential as a flexible foundation model.
7.The model’s broad training across stdpopsim v0.2 species allows it to act like a context-sensitive database, capable of returning different coalescence distributions depending on the input, without needing retraining.
8.cxt’s posterior predictions were validated using empirical coverage and variance under varying mutation rates. Results show consistent calibration and sensitivity to mutational density, even in challenging inference windows.
9.The method was applied to 1000 Genomes Project data, successfully identifying known genomic regions with atypical coalescence histories—e.g., a recent sweep at the LCT locus and deep coalescent times in the HLA region—demonstrating its utility in real-world data.
10.Architecturally, cxt modifies GPT-2 to handle continuous mutational input projected into latent space. Coalescent times are discretized and learned autoregressively, with rotary positional embeddings encoding local genomic distance.
11.The authors introduce the "next-coalescence prediction" task, analogous to next-token prediction in language models, but tailored to sequential TMRCA estimation. This formulation enables structured learning of genealogical processes.
12.The approach is scalable, generalizable, and conceptually distinct from prior DL-based tools like CoalNN or ReLERNN. By modeling the generative process directly, cxt can capture richer evolutionary patterns without relying on predefined summary statistics.
13.The authors view cxt as a foundational model for coalescent inference, with future directions including modeling selection, multi-lineage coalescence, and extending to larger sample sizes or new species via fine-tuning.
14.While the current implementation uses fixed 2kb windows, the authors discuss tradeoffs in resolution, model complexity, and memory efficiency, suggesting avenues for optimization such as adaptive window sizes and local attention mechanisms.
15.Crucially, cxt requires only mutation rates for calibration, bypassing the need for recombination rate inputs. This simplifies deployment while maintaining accuracy and adaptability across species and parameter regimes.
💻Code: github.com/kr-colab/cxt
📜Paper: biorxiv.org/content/10.1101/…
#PopulationGenetics #CoalescentTheory #LanguageModels #Genomics #DeepLearning #TMRCA #ARG #TransformerModel #SimulationBasedInference
2
588

19 Jun 2025
No likelihood? No problem
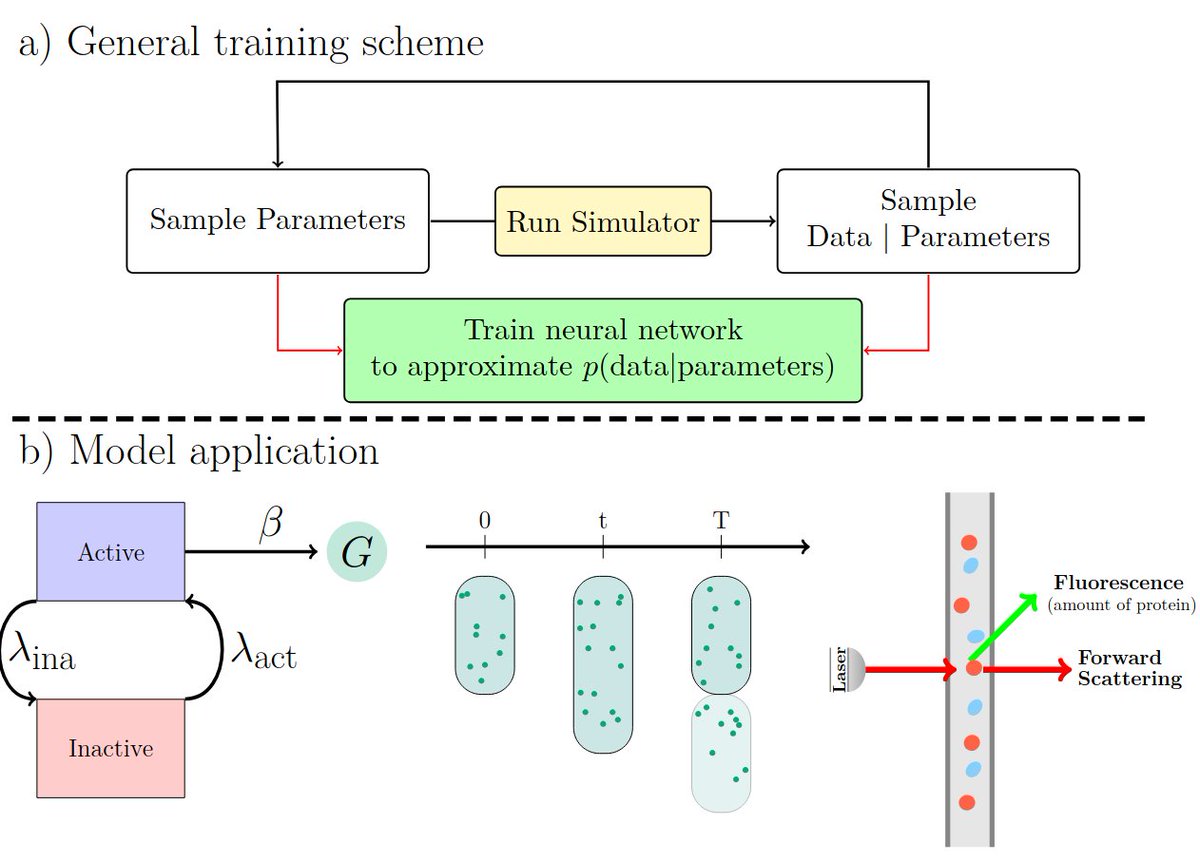
The class of stochastic models we can simulate is A LOT larger than the ones we can write likelihoods.
What if we could learn the likelihood directly from simulation? See the 🧵👇
arxiv.org/abs/2506.09374
#SimulationBasedInference #Neuralnetworks #AI
1
3
649

12 Oct 2023
🚀 Excited about the potential of L-C2ST? Dive into the full article for all the details: arxiv.org/abs/2306.03580. Your feedback is invaluable to us! Let's shape the future of SBI together. #DeepLearning #SimulationBasedInference
2
265

26 Jan 2022
Great to be at #LPA2022 & seeing very familiar faces @axccl 😉
I present #simulationbasedinference for particle accelerator control and the work I did based on #sbibm by @janmatthis . For those interested, here is my poster
doi.org/10.6084/m9.figshare.…
More to come soon, I hope.
1
1
6
22 Sep 2021
Starting the last day of #SBI2021 with a great dive and discussion in the result of excellent but surely hard work:
sbi-benchmark.github.io/
Just add it your bookmarks if you are into #SimulationBasedInference ! Thanks @janmatthis et al for this 💎
1
4

Postdoc in neural data science with @CellTypist
Data Science for Vision Research Lab - University of Tübingen, Germany
jobrxiv.org/job/data-science…
#ScienceJobs #computationalneuroscience #simulationbasedinference #machinelearning #datascience
12
4