
Book Subsidised Supply Chain Courses with CILT Skillnet on Nightcourses.com paiger.link/1912639825

1

📚 Invest in yourself—or empower your team—this June.
Evaluating Learning Impact
🔗 hubs.li/Q04l4Dyh0
Training Administrator Programme
🔗 hubs.li/Q04l4tWm0
For assistance please contact sarah.mcmyler@ldskillnet.ie.
#LearningAndDevelopment #Skillnet

1
1
21

Jun 9
We are proud to announce that PartsSource has acquired SkillNet, helping hospitals gain real-time workforce insights, close technician skill gaps, and grow care capacity. bit.ly/4vCprd4

1
3

Jun 6
Tired of the constant power cuts? 💡❌ Switch to the sun! ☀️✅
Say goodbye to generator noise and hello to 24/7 reliable power. SkillNet Integrated Technologies brings you professional, stress-free solar installations for your home and business. 🔋
🎁 Ready to upgrade? Hit us up for a FREE site assessment!
📞 WhatsApp/Call: 09160462337
📥 DM us now!
1
2
19
Jun 1
🚀 Introducing SkillNet Integrated Technologies
Technology is evolving fast, but many individuals and businesses still struggle to access reliable digital, energy, and security solutions.
That's why we built SkillNet Integrated Technologies.
We help people and businesses thrive through:
💻 Software Development
☀️ Solar Energy Solutions
📹 CCTV & Smart Security Systems
🌐 Networking & Connectivity
🤖 AI & Emerging Technologies
🎓 Technology Training & Digital Skills
Our mission is simple:
👉 Deliver Smart Solutions.
👉 Create Real Impact.
👉 Build a Limitless Future.
At SkillNet, we're not just installing systems or writing code—we're solving real-world problems with innovation.
The future belongs to those who embrace technology. We're here to help you get there.
Follow our journey as we build, innovate, and empower communities through technology and sustainable energy. 🚀
#SkillNet #Technology #Innovation #SoftwareDevelopment #SolarEnergy #RenewableEnergy #CyberSecurity #AI #Web3 #Blockchain #Crypto #DeFi #Nigeria #TechAfrica

2
3
10
204

@isme_ie CEO updates on our new advertising campaign; our Leadership & Networking Forum in Cork next month; opening up new markets for Irish producers at the LATAM & Caribbean Trade Horizons Forum; and why business owners should consider the ISME Skillnet Mentorship Programme.
3
2
88

May 19
Delighted to be in MTU Kerry to celebrate a decade of developing hospitality managers. The National Trainee Manager Development Programme is a blended learning course delivered in partnership with MTU, employers and three Skillnet Business Networks in Kerry.




4
644

May 15
I’m excited to be partnering with Technology Ireland @DigitalSkillnet on a hands-on executive program designed for senior leaders ready to rethink how they work, decide, and lead with AI.
This is not another “AI fundamentals” course. It’s a practical leadership program built around real operating systems for the AI era:
→ making better decisions under pressure
→ reducing cognitive overload
→ turning AI into a true thinking partner
→ building faster, smarter execution loops inside your organization
The program draws on the work behind my new book, #ArtificialOrganizations, and two decades advising leaders at companies including @AmericanAir, @CapitalOne, @SlackHQ, @Vanguard_Group, @HSBC, and many others.
What makes this different is the format:
→ Small cohort.
→ Hands-on.
→ Built around your real work.
→ Focused on behavior change, not theory.
And right now, it’s only available to employees of Irish companies through the Technology Ireland Digital Skillnet initiative.
The leaders who succeed with AI won’t be the ones using the most tools. They’ll be the ones who redesign how judgment, decision-making, and leadership work inside their organizations.
That shift is already happening.
If you’re ready to build your leadership system for the AI era, now’s the time. Sign up at digitalskillnet.ie or by emailing ai@digitalskillnet.ie
Spaces are limited, and selling fast.
#ArtificialOrganizations #AILeadership #DigitalSkillnet #Leadership #AI #Innovation #FutureOfWork

1
2
85

AIエージェントのSkills(スキル)を自動生成し、一元管理するシステム『SkillNet』が発表されました。
人間の作業ログや文書からスキルを作り出し、品質評価やスキル同士の関係性の記録までをまとめて行います。
浙江大学やアリババなどの研究チームによる論文です。
従来のスキルは個々が独立しており、スキル同士の関係や「Aの次にBを使う」といった連携の全体像を管理する仕組みが欠けていました。そのため、複数の手順をまたぐ長期的なタスクを、最後まで自律的にやり遂げることが難しいという問題がありました。
今回発表されたSkillNetは、3つのステップでこの問題を解決します。
1. スキルの自動生成
人間の作業ログ、GitHubのプロジェクト、PDFドキュメントといった散在する情報をAIが読み解き、標準化されたスキルの形式に変換します。
2. 5つの基準による品質評価
生成されたスキルの品質を担保するため、以下の基準で自動評価を行います。
-安全性: 意図しないファイル削除などの危険な動作がないか
-完全性: 処理の手順に抜け漏れがないか
-実行可能性: 安全な環境でエラーなく実行できるか
-保守性: アップデート時に他の機能に悪影響を及ぼさないか
-コスト効率: 実行時間やAPIの消費コストは適切か
3. スキル間の関係性のグラフ化
単にスキルを生成するだけでなく、「このスキルは別のスキルで代替可能」「スキルAを実行するには、事前にスキルBの準備が必要」といった相互の関係性を整理し、ネットワークとして構築します。
この仕組みにより、AIがタスクと使用スキルの全体像を踏まえて、実行手順を組み立てられるようになりました。シミュレーション実験では、タスクの成功率が40%向上し、完了までのステップ数も30%削減されるというパフォーマンス改善が確認されています。
散在するスキルを、ひとつのネットワークとして統合するこのアプローチは、システム開発の観点からも非常に興味深い方法です。

5
61
473
45,914

Apr 8
🚀 Excited to share SkillX: Automatically Constructing Skill Knowledge Bases for Agents!
It automatically converts agent trajectories into reusable, plug-and-play skills — making them transferable across agents and environments.
We are also planning to integrate SkillX into the SkillNet series, aiming to build a unified and scalable ecosystem for skill-centric agent intelligence. #LLM #Agents #NLP #AI #Skills #SkillX
📖 Paper: huggingface.co/papers/2604.0…
🔗 Code: github.com/zjunlp/SkillX
🧩 Motivation
LLM agents should learn from experience, but today, most self-evolving agents still learn in isolation.
They repeatedly rediscover similar behaviors from limited data, leading to:
🔹 redundant exploration
🔹 weak generalization
🔹 capability bottlenecks tied to the base model
So the key question is:
What form of experience is actually reusable across agents and environments?
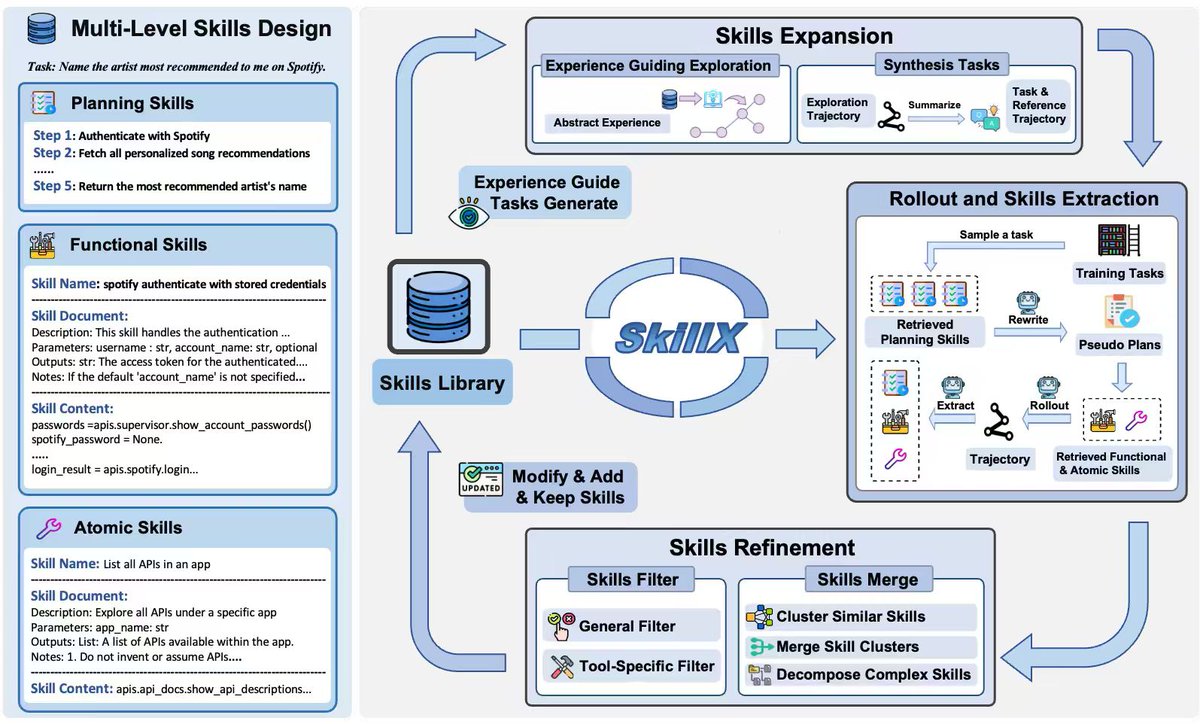
💡 Our answer: Skills! But structured hierarchically!
We propose SkillX, an automated framework for building a reusable Skill Knowledge Base (SkillKB).
Instead of storing raw trajectories, insights, or workflows alone, SkillX organizes experience into 3 levels of skills:
1️⃣ Planning Skills
High-level task organization: ordering, decomposition, dependencies
2️⃣ Functional Skills
Reusable tool-based subroutines for completing subtasks
3️⃣ Atomic Skills
Low-level tool usage patterns, constraints, and failure-prone details
This makes agent experience more compact, composable, and transferable.
⚙️ How SkillX works
SkillX constructs the skill library through 3 synergistic components:
1. Multi-Level Skills Design
2. Iterative Skills Refinement
3. Exploratory Skills Expansion
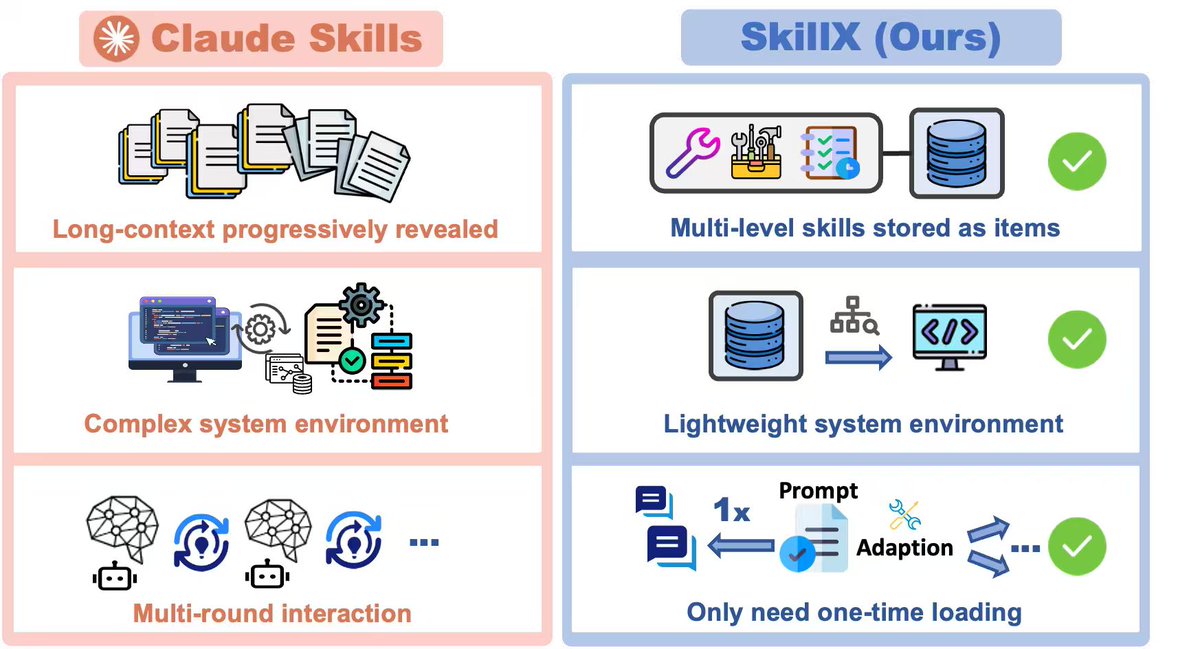
🔍 Why is this useful?
Unlike long-context skill formats that require complex sandboxing and progressive interaction, SkillX uses a lightweight, itemized representation:
✅ retrieve with a simple retriever
✅ inject once into the system prompt
✅ easier transfer across base models
✅ lower execution burden for weaker agents
📊 Results
Using GLM-4.6 to automatically build the skill library, we evaluate transfer on challenging long-horizon interactive benchmarks:
● AppWorld
● BFCL-v3
● τ2-Bench
When plugged into weaker base agents like Qwen3-32B, SkillX brings ~10 point improvements and also improves execution efficiency. ⚡
🧠 Key takeaway
● Not all “experience” transfers equally well, and the representation matters.
● Hierarchical skills are a powerful abstraction for turning isolated agent experience into reusable knowledge.
● Stronger agents can build the skills, weaker agents can reuse them, and agents no longer need to keep learning everything from scratch.
✨ Additional findings
● Functional skills contribute the most to performance gains
● Planning skills often reduce execution steps
● Atomic skills are crucial for clarifying tool constraints and common failure modes
● Iterative refinement further improves the skill library
● Experience-guided expansion discovers more novel skills than random exploration
📦 We will release the optimized plug-and-play skill library to facilitate future research on reusable agent skills.
Feedback, discussions, and collaborations are very welcome! 💬
7
23
1,163

Polymer Training Skillnet, & Manufacturing and Polymer Apprenticeships will join us to discuss solutions for effective, funded, training and recruitment for Medtech & Manufacturing companies! 🚀
📍 Thomond Park, Limerick
🗓️ May 19th
➡️ Book now: bit.ly/TheSkillsSolutionMay1…
#Skills

2
2
42

Mar 20
الورقة هنا
SkillNet: Create, Evaluate, and Connect AI Skills
arxiv.org/pdf/2603.04448

3
1,184
Mar 20
بناء "مكتبة مهارات" يجعل وكلاء الذكاء الاصطناعي أكثر كفاءة وأقل تكرار للجهد ويحسن الأداء
ورقة بحثية ترتكز فكرتها على:
SkillNet وهو نظام ينظم ويقيّم مهارات الذكاء الاصطناعي بشكل منهجي، مما يحسّن أداء الوكلاء الذكيين بشكل كبير ويجعلهم يتعلمون من الخبرة بدل تكرار الأخطاء.
▪️ ما الذي درسته؟
وكلاء الذكاء الاصطناعي اليوم يُعيدون “اختراع العجلة” في كل مهمة جديدة لأنه لا توجد آلية موحدة لحفظ الخبرات ونقلها. الباحثون بنوا نظامًا اسمه SkillNet يُنظّم هذه المهارات في مكتبة ضخمة قابلة للاستخدام المتكرر.
▪️ ماذا وجدت؟
أدى دمج SkillNet إلى:
- تحسين المكافأة المتوسطة بنسبة 40%
- تقليل عدد خطوات التنفيذ بنسبة 30% مقارنةً بالطرق التقليدية.
وكان التحسن واضح عبر جميع النماذج، من الأصغر ( 15.7 للمكافأة مع o4 Mini) إلى الأكبر ( 28.5 مع Gemini 2.5 Pro).
▪️ماذا يعني ذلك؟
هذا يعني أن تنظيم المعرفة على شكل “مهارات قابلة لإعادة الاستخدام” يجعل الذكاء الاصطناعي أكثر كفاءة وتعلمًا مع الوقت، بدل أن يبدأ من الصفر في كل مهمة
2
7
65
3,844

Mar 19
如果要为这周的 AI 发展一个关键词,那就是自主进化。
从 Meta-Evolution、AutoHarness、SkillNet、SkillCraft MiniMax-M2.7 等一系列工作可以看到,AI 正在走向自主发现,自主约束,自主学习新 skills,甚至完成模型级别的自我进化。
其中 SkillCraft 给我的启示非常大:我们不需要也不应该为了某一个任务去安装第三方 skills,而应该直接从 tool call 的实践中抽象,构建和复用新的 skills。
今天,用 MiniMax-M2.7 复现了 SkillCraft 关于发现新的 skills 的方法。
几个重要的步骤:
Observer -> 观察 tool call
Pattern -> 从 tool call 中归纳规律,生成新的 skill
Save -> 保存新 skill
Reuse ->遇到类似问题时,直接复用 skill,而不再重复tool call
MiniMax-M2.7 非常出色的完成了这个任务!
Kudos to @MiniMax_AI @SkylerMiao7
Kudos to 做自主进化的AI 研究员,what a week!
11
60
385
77,448

Mar 18
ravi-annaswamy.github.io/dis…
AI News with Ravi - Wednesday Evening Edition
- Google's design platform: Stitch
- Minimax's M2.7 Self improving machine
- SkillNet with 200K skills
- Opus Reasoning distilled into Qwen 3.5
- Digging deep into Claude ecosystem
- Attention Residuals innovation from China
and Parameter Golf, guassid...
- Astrogravity for Vedic astrology
1
2
128

Mar 18
agent memory loss wasn't a bug. it was a missing layer. the model was never the bottleneck. the infrastructure around it was. SkillNet is basically git for agent experience. every session commits something. nothing gets lost. that's a different class of system
2
405

Mar 18
🚨 BREAKING: Zhejiang University just exposed that every agent forgets everything the moment a task ends.
Reinvents the wheel. Charges you again.
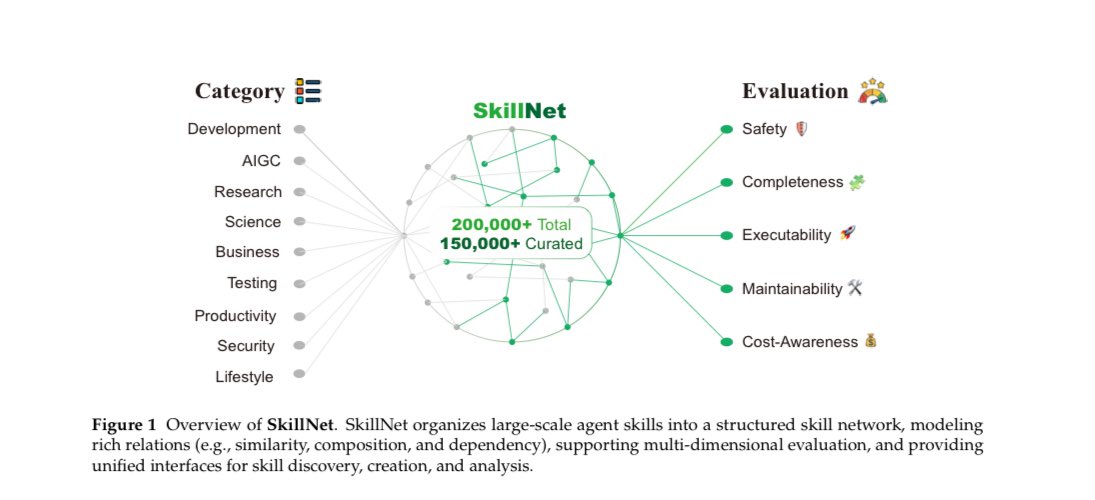
They built 200,000 skills to fix it.
> Every AI agent you've ever run operates in complete isolation. It finishes a task, learns nothing, and comes back tomorrow with zero memory of what worked. The same mistakes get repeated. The same solutions get rediscovered. Over and over.
> Zhejiang University, Alibaba, Tencent, and 15 other institutions just built SkillNet a shared library of 200,000 reusable skills that any agent can pull from instantly. Instead of reinventing the wheel every session, agents now inherit everything that worked before.
> They tested it on DeepSeek V3, Gemini 2.5 Pro, and o4-mini across three different environments. The results were the same every time.
> Skills learned by one agent transfer immediately to every other agent using the library. No retraining. No parameter updates. Just pull the skill and run.
→ Average reward improvement: 40% over standard baselines
→ Execution steps reduced: 30% fewer actions to complete the same tasks
→ Works across all tested models: DeepSeek, Gemini 2.5 Pro, o4-mini
→ Repository size: 200,000 total skills, 150,000 curated and quality-checked
→ Skills evaluated on 5 dimensions: safety, completeness, executability, maintainability, cost
The dirty secret isn't that AI agents are dumb. It's that nobody built the infrastructure to make them remember.
SkillNet just did.

27
69
402
37,709

Mar 17
Bence burada asıl kırılma skill dosyalarını çoğaltmak değil, seçim maliyetini düşürmek. Çünkü ajanlar çoğu zaman araç kıtlığından değil hangi skill neyle, ne sırayla ve hangi önkoşulla çalışır bilgisinin dağınıklığından yavaşlıyor. SkillNet tam burada package managerdan orchestration katmanına sıçrıyor.
Mar 16

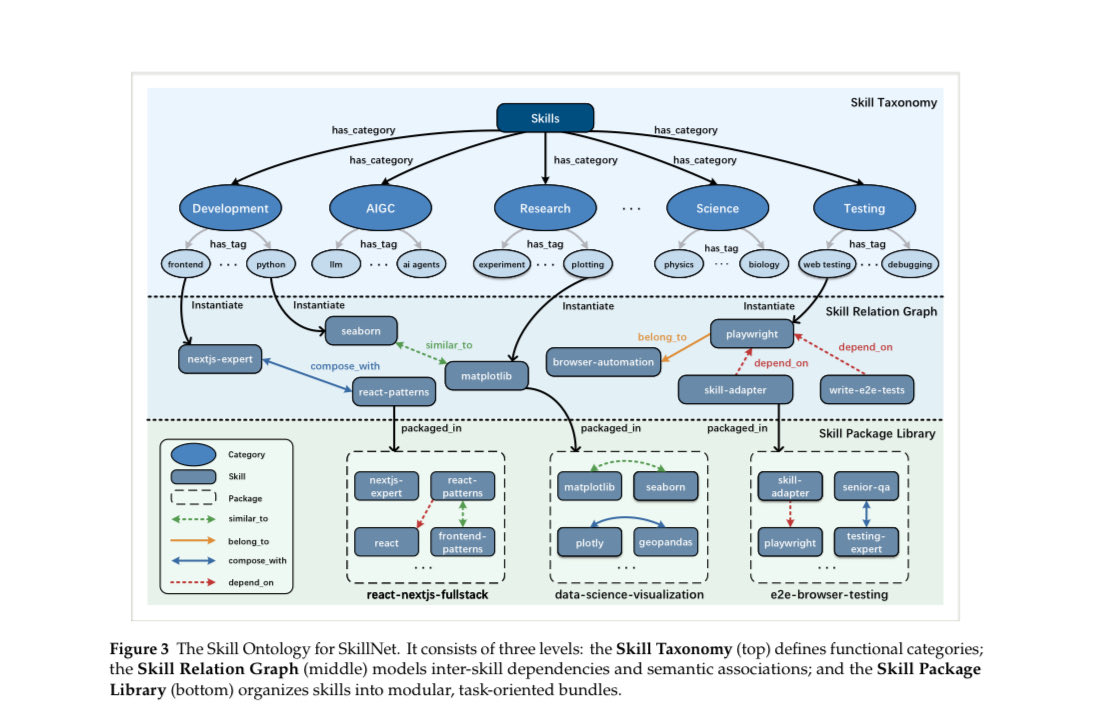
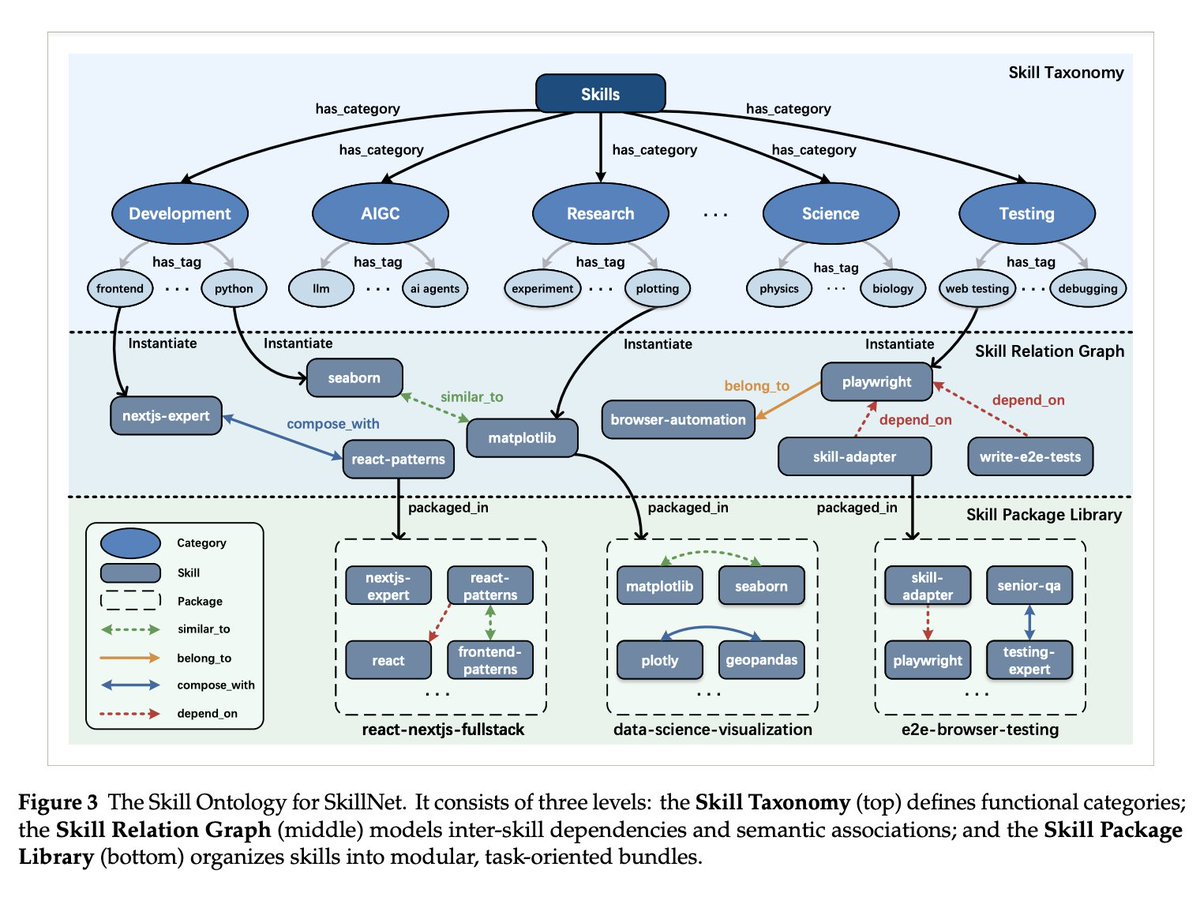
SkillNet is the first paper I've seen that treats agent skills as a network, a three-layer ontology that turns isolated skill files into a structured, composable network.
Externalizing knowledge into files isn't enough. You also need to know how those files relate to each other.
Layer 1 is a Skill Taxonomy. Ten top-level categories (Development, AIGC, Research, Science, Business, Testing, Productivity, Security, Lifestyle, Other), each broken into fine-grained tags: frontend, python, llm, physics, biology, plotting, debugging. This is the semantic skeleton. It answers "what domain does this skill belong to?"
Layer 2 is the Skill Relation Graph. This is where SkillNet diverges from other skill repositories. Tags from Layer 1 get instantiated into specific skill entities (Matplotlib, Playwright, kegg-database, gget). Then four typed relations define how skills connect:
> similar_to: two skills do the same thing. Matplotlib and Seaborn both plot. Enables redundancy detection.
> belong_to: a skill is a sub-component of a larger workflow. Captures hierarchy and abstraction.
> compose_with: two skills chain together. One's output feeds the other's input. This is the relation that enables automatic workflow generation.
> depend_on: a skill can't run without a prerequisite. Enables safe execution by resolving the dependency graph before running anything.
These four relations form a directed, typed multi-relational graph. Nodes are skills, edges are typed relationships. And the graph is dynamic. As new skills enter the system, LLMs infer relations from their metadata.
Layer 3 is the Skill Package Library. Individual skills bundled into deployable packages. A data-science-visualization package contains Matplotlib, Seaborn, Plotly, GeoPandas with their relations pre-configured. You install a package, you get a coherent set of skills that already know how to compose with each other.
This is a good example of what comes after a flat package manager.
The paper also (you can test here skillnet.openkg.cn/) has a science case on a real research workflow: identifying disease-associated genes and candidate therapeutic targets from large-scale biological data.
Without encoded relations, the agent figures out the research pipeline from scratch every time. With them, it receives a pre-structured execution plan. The agent still reasons about which genes to focus on and which pathways to investigate. But the pipeline architecture is given.
So the skill metadata is actually doing routing work too. The metadata encodes the judgment a domain expert would make when choosing between tools.
I also like this framing from the paper: Skills are how memory becomes executable and workflows become flexible.
While the network effect and layered architecture is actually useful today, they also acknowledge this: "Low-frequency or highly tacit abilities are difficult to capture, particularly when they resist explicit linguistic description."
From my short research career, I'd say the hardest parts are hypothesis generation, experimental design judgment, and interpreting ambiguous results etc.
SkillNet handles the structured pipeline well; fetch data → analyze → validate → report. It doesn't handle the creative work where a scientist's (not just in science but in any white-collar field) intuition drives what's worth investigating in the first place.
Skills encode "how to run the analysis." They don't encode "what's worth analyzing." That gap is where domain expertise still sits.
1
18
1,604

Mar 16
SkillNet is the first paper I've seen that treats agent skills as a network, a three-layer ontology that turns isolated skill files into a structured, composable network.
Externalizing knowledge into files isn't enough. You also need to know how those files relate to each other.
Layer 1 is a Skill Taxonomy. Ten top-level categories (Development, AIGC, Research, Science, Business, Testing, Productivity, Security, Lifestyle, Other), each broken into fine-grained tags: frontend, python, llm, physics, biology, plotting, debugging. This is the semantic skeleton. It answers "what domain does this skill belong to?"
Layer 2 is the Skill Relation Graph. This is where SkillNet diverges from other skill repositories. Tags from Layer 1 get instantiated into specific skill entities (Matplotlib, Playwright, kegg-database, gget). Then four typed relations define how skills connect:
> similar_to: two skills do the same thing. Matplotlib and Seaborn both plot. Enables redundancy detection.
> belong_to: a skill is a sub-component of a larger workflow. Captures hierarchy and abstraction.
> compose_with: two skills chain together. One's output feeds the other's input. This is the relation that enables automatic workflow generation.
> depend_on: a skill can't run without a prerequisite. Enables safe execution by resolving the dependency graph before running anything.
These four relations form a directed, typed multi-relational graph. Nodes are skills, edges are typed relationships. And the graph is dynamic. As new skills enter the system, LLMs infer relations from their metadata.
Layer 3 is the Skill Package Library. Individual skills bundled into deployable packages. A data-science-visualization package contains Matplotlib, Seaborn, Plotly, GeoPandas with their relations pre-configured. You install a package, you get a coherent set of skills that already know how to compose with each other.
This is a good example of what comes after a flat package manager.
The paper also (you can test here skillnet.openkg.cn/) has a science case on a real research workflow: identifying disease-associated genes and candidate therapeutic targets from large-scale biological data.
Without encoded relations, the agent figures out the research pipeline from scratch every time. With them, it receives a pre-structured execution plan. The agent still reasons about which genes to focus on and which pathways to investigate. But the pipeline architecture is given.
So the skill metadata is actually doing routing work too. The metadata encodes the judgment a domain expert would make when choosing between tools.
I also like this framing from the paper: Skills are how memory becomes executable and workflows become flexible.
While the network effect and layered architecture is actually useful today, they also acknowledge this: "Low-frequency or highly tacit abilities are difficult to capture, particularly when they resist explicit linguistic description."
From my short research career, I'd say the hardest parts are hypothesis generation, experimental design judgment, and interpreting ambiguous results etc.
SkillNet handles the structured pipeline well; fetch data → analyze → validate → report. It doesn't handle the creative work where a scientist's (not just in science but in any white-collar field) intuition drives what's worth investigating in the first place.
Skills encode "how to run the analysis." They don't encode "what's worth analyzing." That gap is where domain expertise still sits.
19
59
493
29,055
Mar 15
本周喜欢的论文和工作:
SkillNet,SkillCraft
OpenClaw-RL,MetaClaw
主题,进化!
12
27
235
30,180