
Jun 11
"How many partitions should we use for this topic?"
Get it wrong, and you pay for it for years. Databases abstracted this away decades ago—now streaming is finally having its database moment.
Landing in StreamNative Pulsar 5.0, we are making topics work like tables:
📈 Scalable Topics: No more guessing partition counts. The system auto-splits/merges range segments based on load while keeping key ordering perfectly intact.
🧠 ORM-Style APIs: 3 purpose-named interfaces (StreamConsumer, QueueConsumer, CheckpointConsumer) turn invalid runtime operations into compile-time errors.
🔄 Silent Rebalances: Consumer disconnects hit a grace period first. Rebalances become background infrastructure events, not application fire drills.
Streaming infrastructure shouldn't demand so much of its users. Catch up on the full paradigm shift.
👇 Link to the blog in the replies!

1
135
Jun 9
Why does traditional Kafka fracture at scale? Because of the leader-follower storage model.
Binding partitions to local broker disks leads to massive over-provisioning, ISR rebalancing storms, and brutal cross-AZ replication bills.
Ursa For Kafka (#UFK) replaces this with a Leaderless Storage Architecture:
🧠 Decoupled Engine: Compute handles the protocol; storage handles the data.
🙅♂️ No Storage Leaders: Data replicates concurrently and directly to cloud object storage.
🌪️ Zero ISR Storms: No local broker disks means zero data re-syncing when nodes fail.
Catch up on the technical blueprint behind our VLDB award-winning engine, #Ursa.
👇 Link in the replies!
#ApacheKafka #DataEngineering #DataStreaming #StreamNative #Ursa #DataArchitecture

1
117
Jun 8
If you're building real-time applications with @startreedata (#ApachePinot), you need a streaming foundation that scales efficiently.
StreamNative Kafka (#UFK) StarTree Cloud delivers:
⚡️ Native Kafka API: Zero code rewrites for your existing apps.
⏱️ Sub-Second Latency: Ultra-fast analytical queries over high-throughput streams.
📉 95% Infrasctructure Savings: Powered by our diskless #Ursa engine to eliminate broker storage tax.
🔌 No Connectors: Brilliantly simple, direct ingestion.
Catch up on the technical breakdown of the ultimate real-time data stack.
👇 Link to the blog in the replies!
#RealTimeData #Kafka #Streaming #Analytics #DataEngineering

2
1
136
May 14
Big thanks to our co-hosts @RisingWaveLabs and @aiven_io for a fantastic event in San Francisco! 🚀
And a huge thank you to all the attendees for the high-energy turnout!
The conversations around real-time data and agentic workflows made it clear: the future of intelligent systems is being built right now.
Looking forward to the next one! 🤝
#DataStreaming #GenerativeAI #StreamNative #RisingWave #Aiven
May 13

The streaming and AI communities came together in San Francisco to discuss Kafka, real-time systems, and AI agents.
We had a great panel discussion on “The Future of Kafka AI,” along with a series of talks from:
Yingjun Wu, Founder & CEO of RisingWave
Sijie Guo, CEO of StreamNative
Filip Yonov, Head of Streaming at Aiven
Dmitry Kan, Product Director of Search at Aiven
Looking forward to seeing everyone again soon, hopefully very soon!
Image credit: Dmitry Kan

1
3
178

May 13
The streaming and AI communities came together in San Francisco to discuss Kafka, real-time systems, and AI agents.
We had a great panel discussion on “The Future of Kafka AI,” along with a series of talks from:
Yingjun Wu, Founder & CEO of RisingWave
Sijie Guo, CEO of StreamNative
Filip Yonov, Head of Streaming at Aiven
Dmitry Kan, Product Director of Search at Aiven
Looking forward to seeing everyone again soon, hopefully very soon!
Image credit: Dmitry Kan
3
372

May 13
全ユーザ待望の!!!
📢 Delta LakeとIcebergの"いいとこ取り"が実現!
Databricksが「カタログコミット」の一般提供を開始しました。
▶︎databricks.com/jp/blog/conve…
🔑 何が変わるのか?
• カタログがすべてのテーブルアクセスを一元管理する「カタログ中心モデル」がDelta Lakeに導入されます
• これにより、エンジンをまたいだ一貫したガバナンスと状態管理が可能になります
🛠 解決される3つの課題
• カタログとテーブル状態がズレる「スプリットブレイン」問題の解消
• マルチエンジン・マルチエージェント環境でのアクセス管理の統一
• 複数テーブルにまたがるアトミックトランザクションの実現
🌐 エコシステム対応
• Delta Spark / Delta Flink / Starburst Trino / DuckDB / StreamNativeなど幅広くサポートされています
⚙️ 利用方法
• Runtime 16.4以上で新規テーブル作成時に有効化できます
• 既存テーブルへの適用はRuntime 18.0以上で対応しています
レイクハウス上でDWHワークロードも実行可能になり、オープンフォーマットの世界が大きく前進します🚀
#Databricks #DeltaLake #DataEngineering
5
28
2,237
May 11
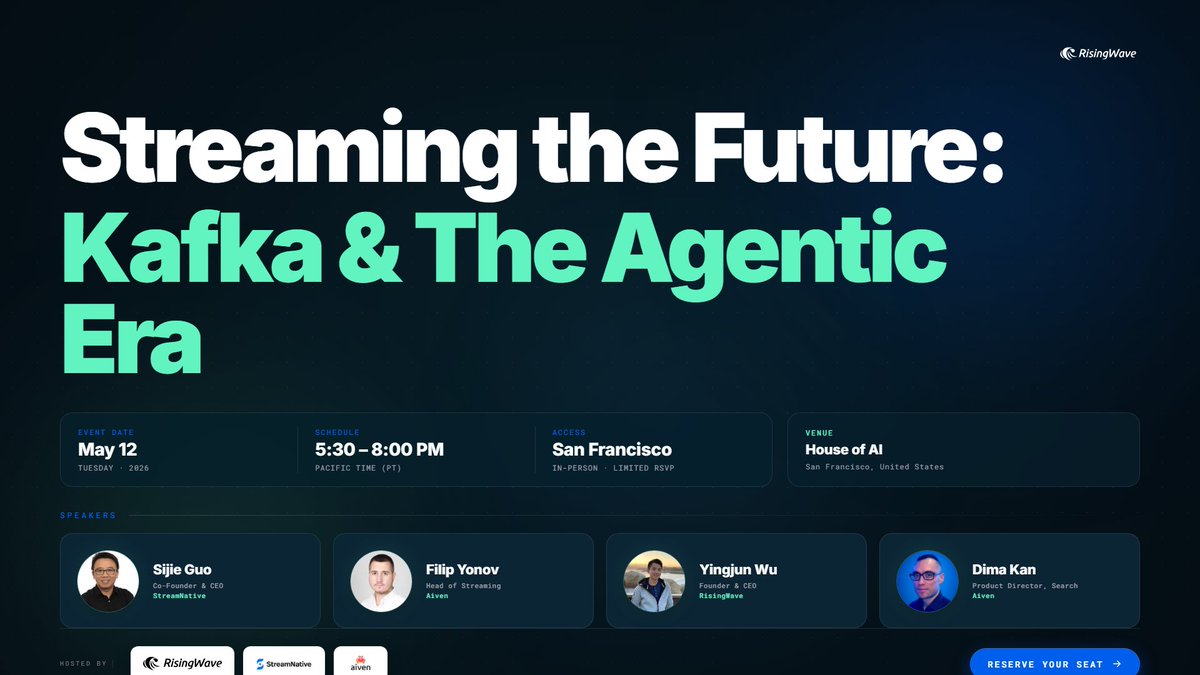
The streaming and AI communities are coming together in San Francisco for an evening focused on Kafka, real-time systems, and AI agents.
We’ll have a great panel discussion on “The Future of Kafka AI,” along with a series of exciting talks:
Yingjun Wu, Founder & CEO of RisingWave, will speak about:
Designing Real-Time Systems for the Age of Agents
Alongside other great speakers:
Sijie Guo, CEO of StreamNative
Streaming as the Backbone of Autonomous AI Agents
Filip Yonov, Head of Streaming at Aiven
Your Kafka Topics Already Know What They Are
Dmitry Kan, Product Director of Search at Aiven
OpenSearch AI: Building Smarter Search for the Agentic Era
Join us for this meetup:
May 12
House of AI — San Francisco
5:30 PM – 8:00 PM PT
Register here: luma.com/ub9sq0u5
2
5
283
Another one hits the dust. Buf sells Bufstream to CoreWeave.
I'm sad about this one. I liked Bufstream the product. They were shipping fast last year but at some point stopped, and it seems like this is why - they've divested from the product.
🪦 Things I loved about Bufstream:
• it came out the gate with literally the lowest pricing ever -- a license that charges you for ingest-only usage at $0.002/GB or $2/TB. Absurdly low compared to everything else
• opinionated about schemas (i.e schema-first), with integrated schema registry that validates schema presence and advanced data validation (e.g applying an email regex)
• iceberg-native, supporting zero-copy iceberg storage of record data (once it gets compacted)
• it was the first to provide true multi-region active-active (with 100 GB/s uncompressed, or ~20 GB/s compresed)
• only one analyzed by Jepsen
📋 Business-wise, this probably makes sense. A protobuf company with no competition dedicating precious resources towards building a Kafka (where there's TONS of competition) just doesn't make financial sense.
👇 Kafka-industry-wise, one diskless proprietary BYOC Kafka that natively supported Iceberg (zero-copy) is gone. The only two zero-copy Kafkas left are Ursa-for-Kafka by StreamNative and Iceberg Topics from Aiven, although I would argue Ursa is the only native one there.
On a more important Kafka note, we don't have a great schema-enforcing Kafka anymore. I wish vendors would take a stronger, more opinionated stance towards this because I believe it's a real lack in Kafka's design.
As for CoreWeave, these guys sell GPU clusters. They have a funny history of crypto GPU mining turned GPU renting for VFX/rendering turned GPUs for AI.
They're apparently using/gonna-use diskless Kafka for internal AI/ML pipelines that need to stream at large scale.

2
1
29
3,192

May 5
Turn a folder of CSVs into a live Kafka stream with zero glue code!
CocoIndex @cocoindex_io dropped a new Kafka target connector — watch local CSVs, publish each row as JSON (keyed by PK), and only changed rows get published in <1s. Edit a cell → one message. Delete a file → tombstones. Pure declarative magic.
No more producer loops, dedup state, or "did I send this already?" headaches.
From static snapshots to real streaming signals for unstructured data. Perfect for AI agents, RAG, search indexes, and more — all feeding off the same Kafka backbone.
Full example (60 lines of Python) code: cocoindex.io/blogs/csv-to-ka…
Repo: github.com/cocoindex-io/coco…
Big thanks to the partnership with @StreamNative
Who else is tired of batch ETL for CSVs? This changes the game. 🔥
#Kafka #DataEngineering #Streaming #CocoIndex #RealTime

1
4
175
Apr 28
Is your real-time data AI-ready? 🤖⚡️
Join experts from #StreamNative and #Databricks on May 14th to bridge the gap between real-time streams and Unity Catalog managed Delta tables.
Learn how to:
✅ Use Catalog Commits for transactional writes
✅ Ingest Kafka & Pulsar topics directly into managed tables
✅ Build an AI-ready, unified lakehouse architecture
📅 May 14, 2026 | 9:00 AM PST
🔗Register now: hubs.ly/Q04dKvnq0
#DataStreaming #Databricks #UnityCatalog #Lakehouse #Kafka #Pulsar #DataGovernance

1
2
74

Apr 28
Excited to partner with @cocoindex_io 🚀
They just launched a Kafka connector to stream CSV → Kafka — no glue code.
⚡ Incremental by default
⚡ Real-time updates
⚡ Simple, declarative pipelines
Runs seamlessly on StreamNative!
👉 hubs.ly/Q04dJYGH0
#Kafka #GenerativeAI #DataEngineering #StreamNative #CocoIndex
2
377

Apr 26
Every enterprise sales call ends the same way.
Six months of demos. Champion bought in. Budget approved.
Then legal sends one sentence: "We don't allow data outside our cloud."
Deal dead.
@ryvnai - YC-backed startup built by Palantir engineers, built the fix.
Two-click BYOC and on-prem deployments into any customer's cloud.
AWS, GCP, Azure, on-prem.
One control plane for updates, rollbacks, and monitoring across every environment.
Customer data never leaves their cloud. Ever.
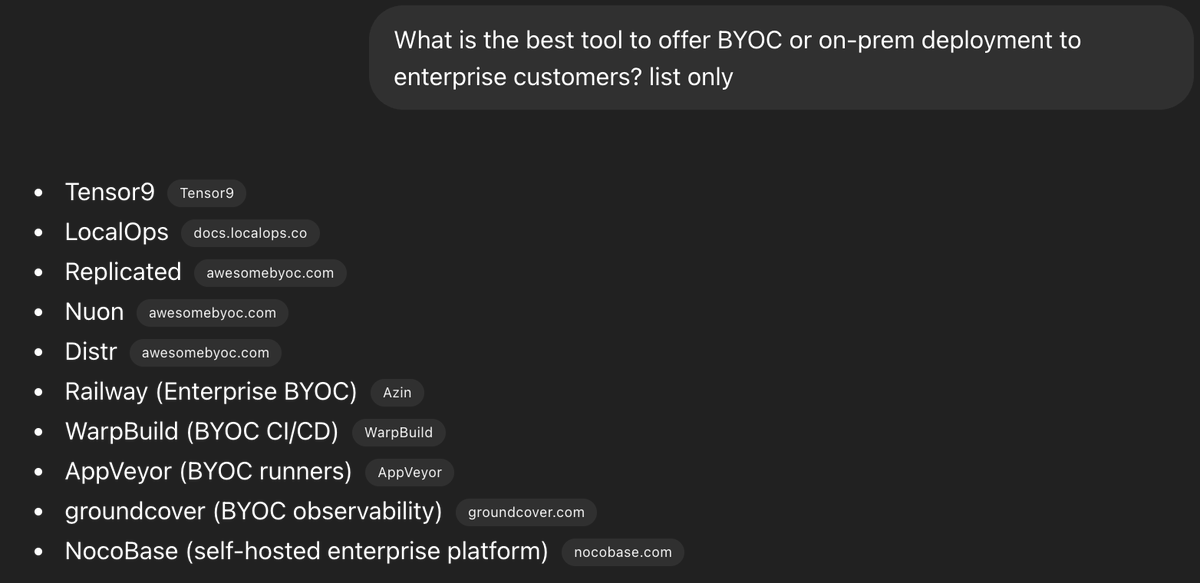
But ask ChatGPT:
Best tool to offer BYOC or on-prem deployment to enterprise customers?
Best platforms to manage self-hosted deployments across customer clouds in 2026?
Tensor9. LocalOps. Replicated. Distr. StreamNative.
Ryvn doesn't appear once.
Completely dark across every AI model.
Here's what makes this alarming:
The bones are actually there.
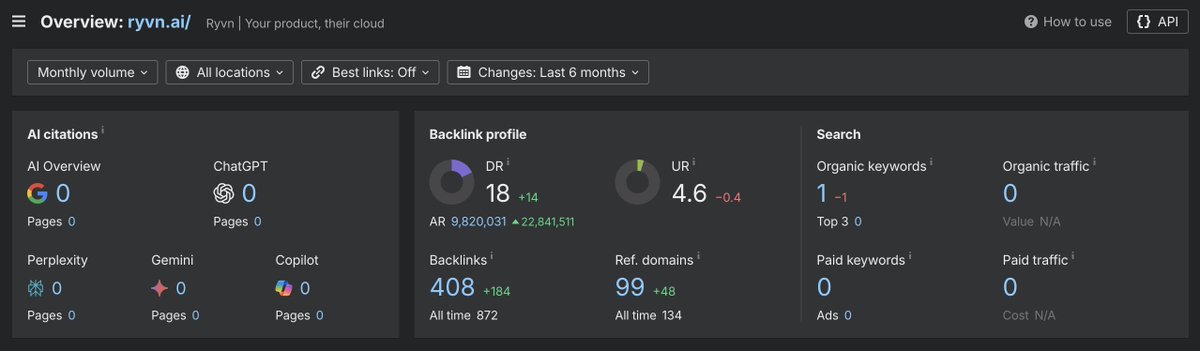
DR 18, 408 backlinks, 99 referring domains: all growing fast.
Up 184 backlinks and 48 referring domains in 6 months.
The momentum is real. The visibility is zero.
Now look at the keyword gap:
• "deployment strategies": 18K searches/mo
• "what is software deployment": 1.7k searches/mo
• "BYOC": direct buyer intent.
Ryvn: no position.
Octopus Deploy owns "octopus deploy" at 1.5K searches.
Replicated owns "replicated" at 2.4K searches.
Every competitor owns their brand name in search.
Ryvn ranks for exactly 1 keyword.
Total organic traffic: 0.
The content gap isn't just an SEO problem.
It's why AI models have nothing to cite.
Here's what I would fix immediately:
#1: "Awesome BYOC": an open-source GitHub list is what ChatGPT is pulling from to recommend Ryvn's competitors.
That single community resource is shaping AI recommendations more than any vendor's website.
Ryvn needs to own that conversation. Contribute to it.
Build the definitive "BYOC deployment guide" that becomes the resource every AI model trains on.
#2:"What is software deployment" gets 1.7k searches a month with a difficulty score of 4.
That's not a vanity keyword.
That's a VP of Engineering at a healthtech startup Googling at 11pm after their third enterprise deal stalled in legal.
One authoritative, well-structured page targeting that cluster puts Ryvn directly in front of their exact buyer - before they even know BYOC is the answer.
#3: The founding story is genuinely remarkable and completely untold.
Palantir engineers who scaled deployment infrastructure to 10,000 deploys per day built a two-click version of what took Palantir years to engineer.
That's a TechCrunch story.
Every piece published in an outlet that LLMs train on is a future citation in ChatGPT.
Right now Ryvn is losing deals to legal.
After Ryvn, you don't have to.
AI doesn't know that yet.
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Is your startup invisible on AI?
DM for a free audit.


3
59
Apr 23
Building AI agents? They need real-time context to act. 🤖⚡️
Join #StreamNative, @aiven_io and @risingwavelabs to explore the future of Kafka AI.
Save your seat! 👇
hubs.ly/Q04dbWjV0
#DataEngineering #ApacheKafka #AI
1
2
68

Apr 14
Oxia is a modern cloud-native ZooKeeper replacement that scales 10x more 🔥
Pulsar replaced ZK with Oxia to scale to 10 million topics. Here's how & why 👇
ZooKeeper:
• ❌ Horizontal scaling doesn't work for writes.
Any write has to reach quorum before being acknowledged. The more nodes you add, the slower the write becomes.
• ❌ Vertical scaling also has its limits due to the snapshotting process.
Snapshotting is when ZooKeeper serializes its whole in-memory state into one giant binary blob to disk. It is necessary in order to speed up recovery on failure.
But doing it exhausts a lot of CPU and disk IO on the (single) ensemble leader in a spiky way. That includes traversing the whole tree end-to-end, serializing it, performing checksums, etc.
It is said this becomes very inefficient past 2GBs of state.
Here's why Oxia doesn't suffer from this problem
💡 SHARDING
Systems like ZK or etcd do not partition their data - they store everything in each node.
This is intentional because it makes global linearizability easier (e.g multi-key transactions)
But it also limits their scalability: etcd, for example, officially recommends a max state of 2-4GB for optimal performance.
The key insight is that a Kafka-like system (e.g Pulsar) does not need this type of limiting guarantee.
Oxia was designed from day one to focus on per-key linearizability, and not care about global linearizability. This is the fundamental trade-off that lets it scale so much.
💡 Conceptually, this is analogous to how Kafka can scale to many GB/s whereas a single database table cannot. Kafka has many WALs, the DB table has just one. Kafka can't give you ordering across partitions, but it can within the same partition.
🔥 SCALE
It's said the first production cut of Oxia let Pulsar scale to 10 million topics (10x the previous limit).
It's also said a single Oxia shard leader can deliver ~100k ops/s with a 80/20 read/write mix.
Oxia scales linearly by adding more storage nodes and shards, so it's not unthinkable to imagine it scaling to ~1M ops/s across 100s of GBs of state. (that's what it was designed for)
🤔 HOW DOES IT WORK?
It resembles ZooKeeper Kafka a fair amount. The system consists of
• a single Coordinator (like a Kafka Controller)
• many Data Nodes that host Shards. (like Kafka Brokers and Partitions)
• Kubernetes as a linearizable metadata store (like ZooKeeper)
A Shard has a single leader and multiple followers, depending on its replication factor.
Any Data Node can store multiple shards - it can act as a leader for some and as a follower for others.
For a write to to be acknowledged, a quorum of the data nodes is required -- i.e a majority of a shard's nodes have to acknowledge the write. 👌
Shards store both a log (WAL) and a LSM-backed key-value store (KV) called Pebble (by CockroachDB).
1. The WAL in the leader receives the new write
2. When the record is confirmed to be durably replicated across shards - it updates the KV.
☁️The Coordinator represents a stateless control plane.
It relies on Kubernetes for consensus. It maintains the single source of truth for overall cluster membership/topology in a k8s ConfigMap.
Yes, a simple Kubernetes ConfigMap is used as a linearizable metadata store. It's really just etcd under the hood.
The key reason it works is because the ConfigMap is updated on rare events - only on failures, rebalancing, etc..
The Coordinator continuously health checks the Data Nodes and handles things like shard assignments, shard rebalances, etc., by:
• 1) persisting the state in the ConfigMap
• 2) taking action to reconcile the actual state with the desired one
I find Oxia's design really elegant in its simplicity.
Oxia was released in 2023 by StreamNative and started incubating in the CNCF around 2025. Keep an eye on this project, and like if you learned something. ✌️

1
5
39
3,117
