
Pulling 6.19M streams on a single day to lock down 10 consecutive days at #1 on Global Spotify is an absolute masterclass in retention. Ariana Grande's streaming stability right now proves how a perfectly executed rollout converts high release-day curiosity into permanent listening habits. #MusicBusiness #StreamingData
1
124

Jun 9
Stream computing latency down to sub-millisecond. DolphinDB's stream engine processes real-time data with end-to-end latency measured in microseconds, not seconds. #DolphinDB #StreamingData #LowLatency
2

𝟏𝟎𝐊 𝐆𝐢𝐭𝐇𝐮𝐛 𝐬𝐭𝐚𝐫𝐬 𝐟𝐨𝐫 𝐨𝐩𝐞𝐧-𝐬𝐨𝐮𝐫𝐜𝐞 𝐃𝐢𝐬𝐤𝐥𝐞𝐬𝐬 𝐊𝐚𝐟𝐤𝐚 𝐨𝐧 𝐒𝟑.
When we launched AutoMQ v0.6.6 as an open source project in November 2023, we started with one belief:
Kafka should become truly cloud-native.
Traditional Kafka was built around broker-local disks. At cloud scale, that often means expensive storage, cross-AZ replication cost, heavy partition reassignment, and complex operations around scaling.
AutoMQ takes a different path.
It is a Kafka-compatible streaming storage engine that moves Kafka storage from local disks to S3-compatible object storage, while keeping the clients, APIs, workloads, and ecosystem tools Kafka users already know.
Today, AutoMQ is one of the most mature open-source Diskless Kafka implementations, validated in production by industry-leading teams including Grab, JD.com, Tencent, Honda, and more
Over the past two and a half years, AutoMQ has continued to contribute to the Kafka ecosystem:
1️⃣ Diskless Kafka on S3, with shared storage instead of broker-bound local disks
2️⃣ Stateless brokers for lighter scaling, reassignment, and recovery
3️⃣ Table Topic, bringing Kafka streams directly into Apache Iceberg tables without a separate ETL pipeline
10K stars is more than a milestone. It is a signal that the Kafka community is actively exploring a more cloud-native future.
Thank you to everyone who starred the repo, tried AutoMQ, opened issues, shared feedback, contributed code, or challenged us to make the project better.
This is just the beginning.
GitHub: lnkd.in/gt7NVRbh
#AutoMQ #ApacheKafka #Kafka #OpenSource #CloudNative #S3 #ApacheIceberg #StreamingData

1
2
66

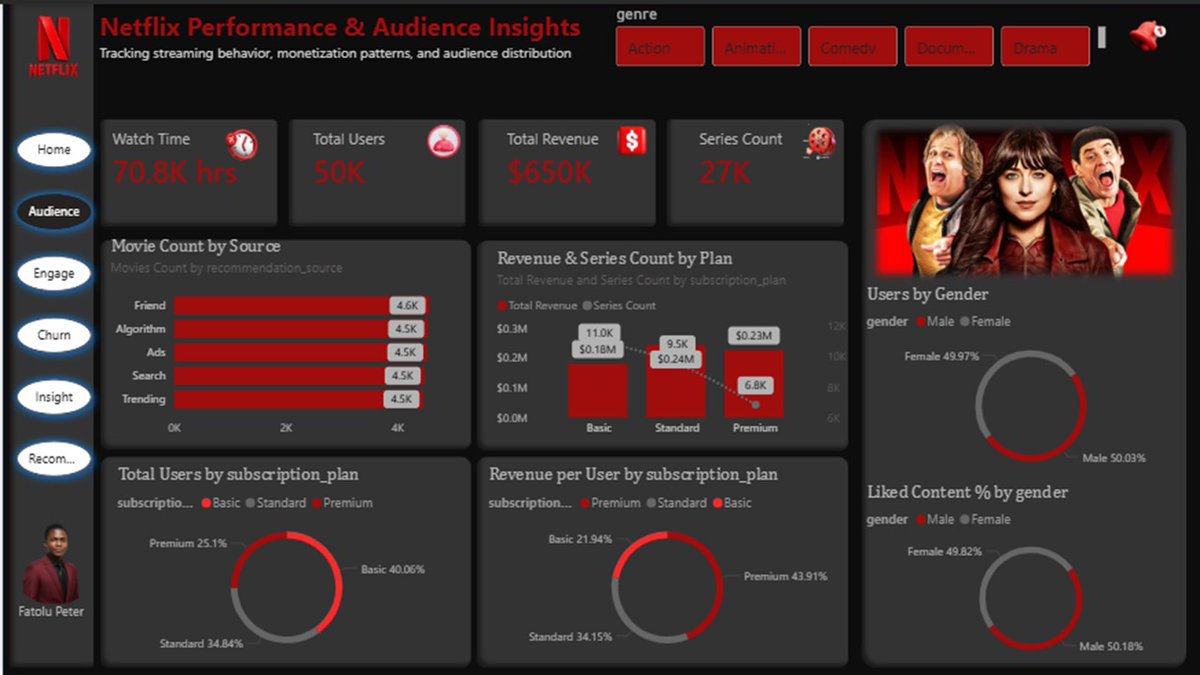
Built a powerful Netflix Analytics Dashboard showcasing deep insights into streaming performance, content trends, viewer engagement, ratings, genres, and global distribution patterns.
📊 Key Insights Included:
• Most watched genres
• Content growth over the years
• Ratings distribution
• Country-wise content analysis
• Movies vs TV Shows comparison
• Viewer trend visualization
Tools Used:
🔹 Power BI
🔹 Excel
🔹 Data Visualization Techniques
Turning raw entertainment data into actionable business insights. 🚀
#Netflix #PowerBI #DataAnalytics #DashboardDesign #BusinessIntelligence #DataVisualization #DataScience #Analytics #StreamingData #Excel #SQL #Python



1
2
97

Free movies and TV consumer data is on Dorea Brain right now.
25 real responses. What people are watching, what they're skipping, and what they think.
Open to everyone: dorea.io/brain
#Entertainment #StreamingData #Dorea #OpenData
1
2
41

May 15
Most enterprises are deploying #AI agents without a plan for what those agents can access, what they can do, or how to prove it when something goes wrong. Sound familiar? 🤔
Redpanda CEO @emaxerrno sat down with @NeilCHughes from Tech Talks Network to talk about why #streamingdata is the foundation #agentic AI actually needs, and what happens when you skip that part.
The conversation covers a lot of ground: #governance gaps, agent transcripts, explainability in regulated industries like banking and manufacturing, and why the Redpanda #AgenticDataPlane exists to close the gap between ambitious #agent deployments and production-ready ones.
Also covered: Redpanda's work with @nvidia Vera, where benchmarks showed 5.5x lower latency and 73% higher throughput. Speed matters. But so does knowing what your agents did and why. 🔍
Listen to the full episode 🎧
techtalksnetwork.com/podcast…
1
2
162

Margo's got money trouble. Viewership? That's a different story.
1.2M U.S. households for the premiere, averaging 1M viewers/ep across 6 episodes. For Apple TV, that's a hit.
Sleeper of the year?
#SambaInsights #MargosGotMoneyTrouble #AppleTV #StreamingData #Samba

3
10
1,189

Apr 27
AWS Summit, Bengaluru - 2026 is a wrap!
Two days full of great conversations, new connections, and a lot of excitement around real-time data. Loved meeting so many of you at Booth B17 and seeing the response to #Condense (and the swag 😄).
Until next time!
Learn More about Condense here: zeliot.in/condense
Read Documentation here: docs.zeliot.in/condense
Quick links: zeliot.in/quick-links
#AWS #AWSSummit #AWSBengaluru #AWSSummitBengaluru2026 #Data #DataStreaming #StreamProcessing #StreamingData #AI #Streams #Kafka #ManagedKafka #CondenseApplications




1
2
58
Apr 22
🎵 Me and my shadow, never apart... 🎵
Disaster recovery for #streamingdata is one of those things that everyone needs but nobody likes to set up. External replication tools like #MirrorMaker mean extra hardware and no guarantee of data fidelity. (Not to mention more grey hairs.)
Shadow Linking is Redpanda's built-in, enterprise-grade disaster recovery feature. 🎉
No external service or no JVM tuning. Just continuous, high-fidelity replication built straight into the broker. ✌️
Paul Wilkinson walks through the full architecture, switchover and failover flows, and even throws in a demo so you can try it yourself.
Read the full post 👇
redpanda.com/blog/shadow-lin…
#datastreaming #Kafka #developer
1
2
205
The Pitt did it the old-fashioned way: one episode a week, no binge drop, just a full season of must-watch television. 📺
Viewership of the S2 finale on Max surged 87% from the S1 finale and 13% from the S2 premiere, proving that The Pitt's audience just keeps growing. Strong reviews, Emmy buzz, and relentless word of mouth made it one of the most-watched titles in our weekly rankings, week after week.
#ThePitt #StreamingData #SambaTVInsights #SambaInsights #HBOMax

2
13
1,031

Apr 16
K4OS Statistics: "Uff Baby" 🎧
— Ayer: 10,052,518
— Hoy: 10,068,044
— Crecimiento: 15,526
La canción registra el mayor incremento de reproducciones en las últimas 24 horas. @K4OS_oficial #K4OS #StreamingData

2
2
46
#Euphoria spent 4 years off air. Its cast spent those 4 years becoming movie stars. 🎬
#Zendaya picked up two more Emmys. #JacobElordi got an Oscar nomination for Frankenstein. #SydneySweeney became one of Hollywood's most in-demand leads. And when the show came back, it jumped 5 years forward — no more East Highland High.
Samba data shows the #EuphoriaS3 premiere drew 11% more US households than the White Lotus S3 debut on its opening day. However, it still came in 32% below the gold standard: The Last of Us S2E1.
The wait was long and the data tells the story. 📊
#SambaTV #SambaTVInsights #StreamingData

11
1,307

Apr 10
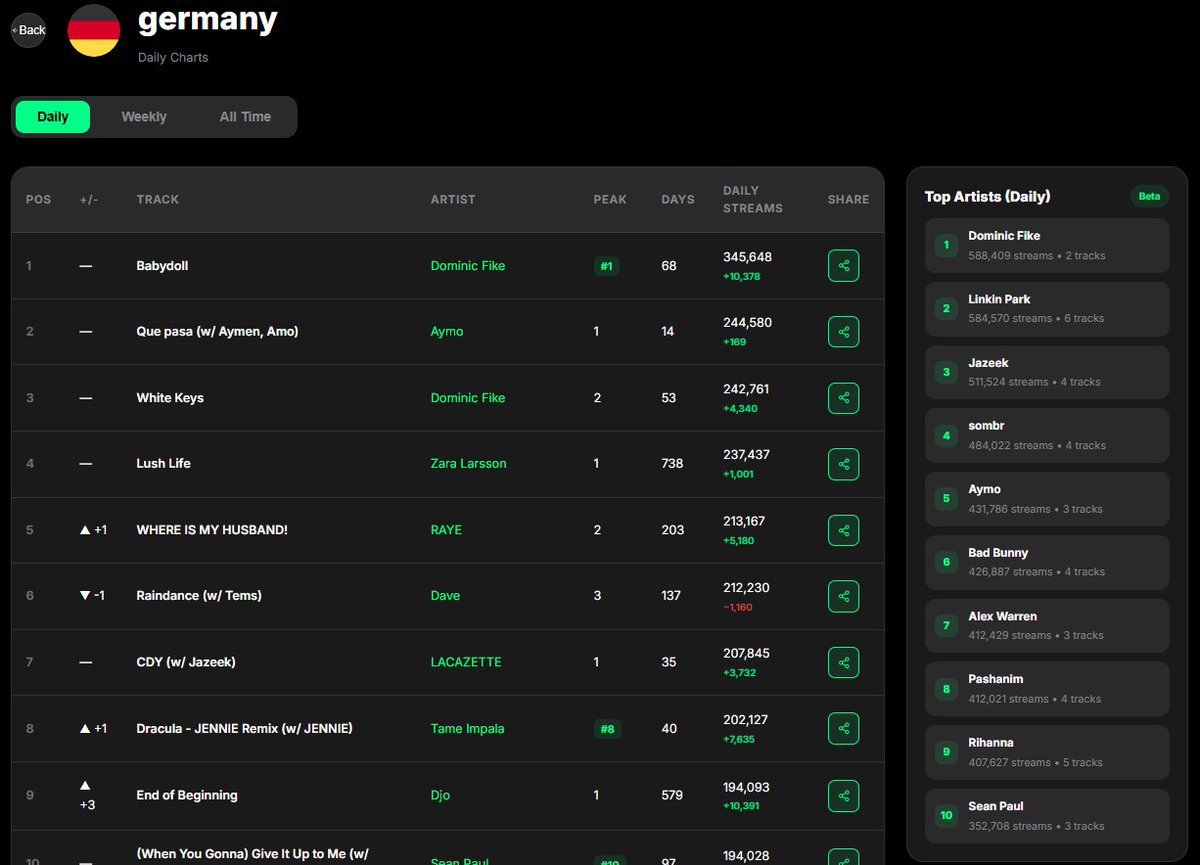
Germany's charts are looking legendary today! 🇩🇪 🎶
@dominicfike is absolutely dominating with "Babydoll" at #1, while legends like @linkinpark and @rihanna are showing their timeless power in the Top 10. 🎤👑
Dive into the full Germany Daily Charts: zonitex.com/country/de/germa…
#GermanyCharts #MusicData #DominicFike #LinkinPark #Rihanna #SpotifyStats #StreamingData #MusikDaten
2
56
Apr 10
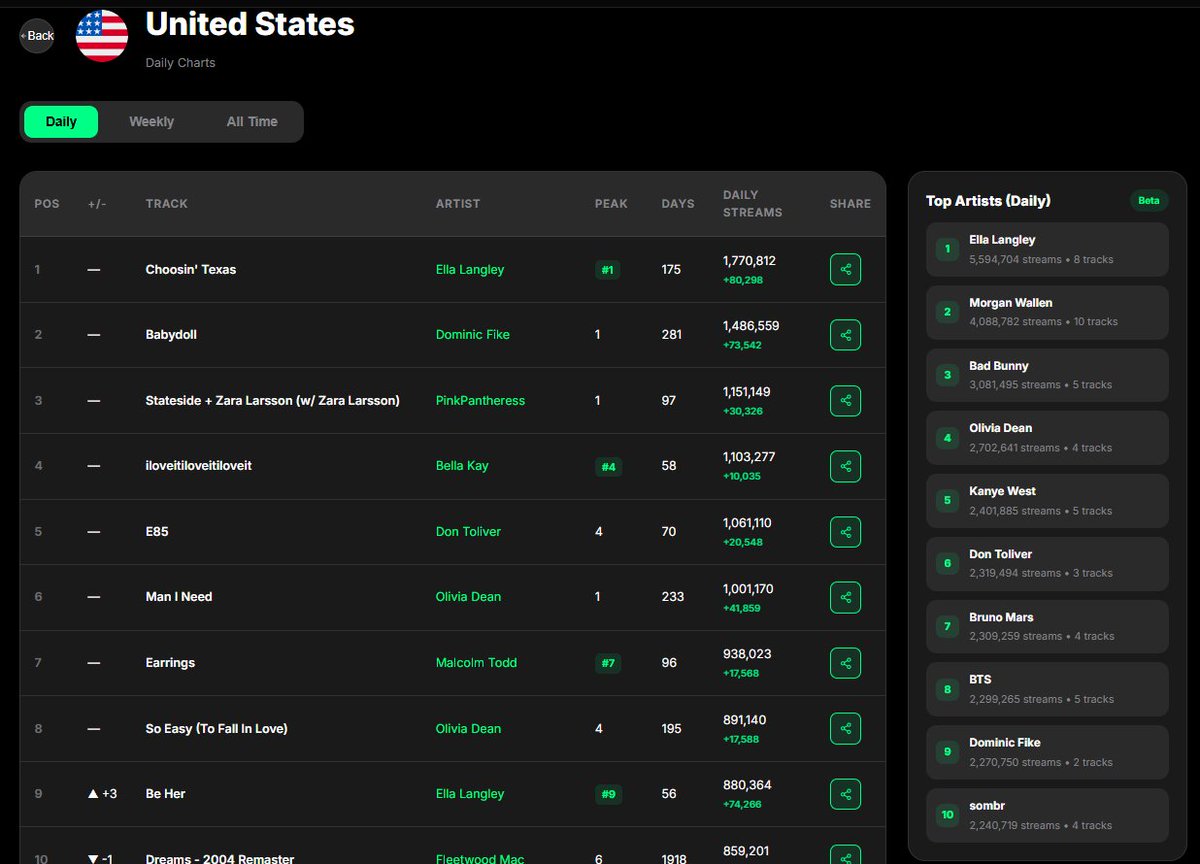
A massive shift in the US music scene! 🇺🇸 📉
Ella Langley is officially dominating the charts with "Choosin' Texas" hitting #1, while Morgan Wallen and Bad Bunny hold strong in the Top 3. 🤠🔥
Explore the full breakdown: zonitex.com/country/us/unite…
#MusicData #USCharts #EllaLangley #MorganWallen #BadBunny #SpotifyStats #StreamingData
2
3
231

Apr 4
𝗙𝗮𝘀𝘁 𝗶𝘀𝗻’𝘁 𝗲𝗻𝗼𝘂𝗴𝗵.
For years, message streaming systems have optimized for throughput and cost.
Benchmarks got bigger. Numbers looked impressive.
But real systems don’t run on benchmarks.
End Users don’t feel throughput.
End Users don’t feel cost.
They feel 𝗹𝗮𝘁𝗲𝗻𝗰𝘆 𝘀𝗽𝗶𝗸𝗲𝘀.
They feel 𝘂𝗻𝗽𝗿𝗲𝗱𝗶𝗰𝘁𝗮𝗯𝗶𝗹𝗶𝘁𝘆.
They feel when systems break under pressure.
The real problem isn’t speed.
It’s 𝗰𝗼𝗻𝘀𝗶𝘀𝘁𝗲𝗻𝗰𝘆 𝗮𝘁 𝘀𝗽𝗲𝗲𝗱.
That’s why we’re building LaserData — ultra-low latency, predictable message streaming infrastructure for the AI era, without compromising throughput or cost!
Built by the creators of @ApacheIggy
We believe the next generation of streaming systems won’t be defined by how fast they are… but by how 𝗽𝗿𝗲𝗱𝗶𝗰𝘁𝗮𝗯𝗹𝗲 they are at tail latencies under real-world conditions.
𝗧𝗵𝗶𝘀 𝗶𝘀 𝗷𝘂𝘀𝘁 𝘁𝗵𝗲 𝗯𝗲𝗴𝗶𝗻𝗻𝗶𝗻𝗴.
#AIInfrastructure #DistributedSystems #StreamingData #UltraLowLatency #DataEngineering #CloudInfrastructure #OpenSource #ApacheIggy
2
2
319
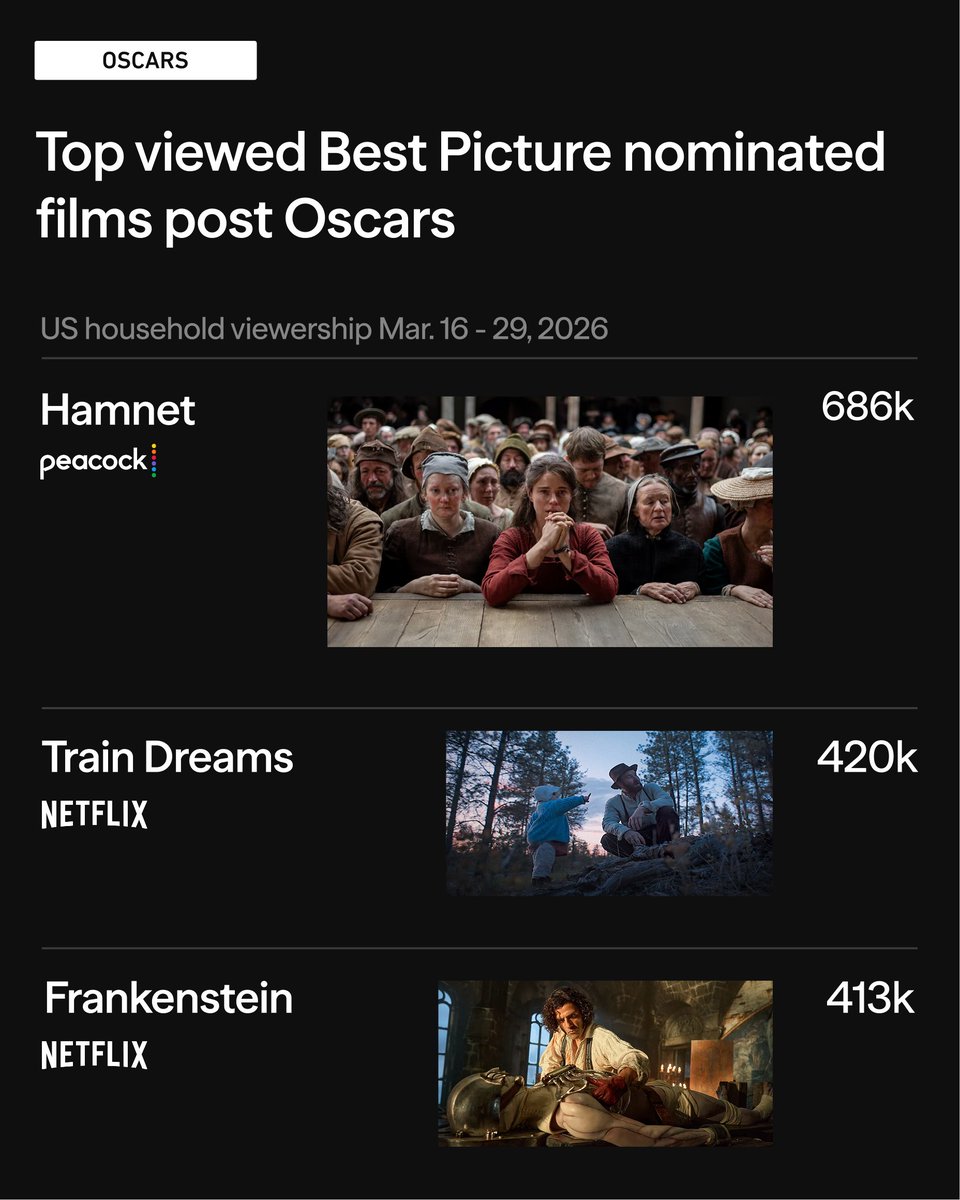
The #Oscars are over. The streaming data tells the real story. 🎬
#Hamnet hit #Peacock nine days before the ceremony and had the highest post-Oscars viewership of any Best Picture nominee. The timing meant the film was new to streaming audiences precisely when the industry was paying the most attention to it.
Meanwhile, Best Picture winner #OneBattleAfterAnother saw the lowest viewership following the Oscars, raising a pointed question about whether the Best Picture prize still moves the needle in the streaming era. Since it was released on #HBOMax back in December, most people had already seen it months ago.
The lesson? In today's streaming landscape, when a film lands matters just as much as what it wins.
#Oscars2026 #StreamingData #SambaTVInsights #SambaInsights #SambaAI
10
742

Mar 15
2026 data engineer mood :
Agentic pipelines that self-heal
Streaming > batch forever
You're the context architect for trillion-param models
Addicted to that 80% latency drop when the LLM stops hallucinating?
Your current obsession? Drop it #DataEngineering #StreamingData
2
12

Mar 12
Several songs across multiple artists are showing negative daily numbers and slight decreases in total streams compared to yesterday. This appears to be related to a possible Spotify data correction or stream filtering update, though no official statement has been released yet. Among Celine Dion’s catalog, “My Heart Will Go On” seems to be the most impacted track so far.
Have you noticed similar changes on other artists’ pages today? 👀
#CelineDion #MyHeartWillGoOn #Spotify #SpotifyStreams #StreamingUpdate #MusicCharts #SpotifyCharts #StreamingData
1
1
20
810
Netflix is on an absolute action movie tear 🎬💥 and War Machine debuting as the #1 streaming program of the week this past Friday is just the latest proof. The Rip already holds the #1 streaming movie of the year so far and the hits just keep coming, with both films surpassing 7M U.S. household views in their first 3 days.
#Netflix #SambaTVInsights #TheRip #WarMachine #StreamingData #SambaTV

1
15
1,211

UPDATE 🤓
“Cosa Nuestra” de Rauw Alejandro alcanza los 3 billones de reproducciones totales en la plataforma Spotify 🌍
Actualmente supera los 4 millones de streams diarios, reflejando un desempeño sólido y sostenido en plataformas digitales ✨🔥respaldando la consistencia, alcance internacional y una conexión activa con la audiencia global.
Esto es “Cosa Nuestra” no creo que lo entiendan.
#CosaNuestra #RauwAlejandro #StreamingData #latinmusic

2
17
155
3,151