
Jun 12
Reactive State Engine: write once, run in both batch and real-time streaming. Same code, same results—eliminating the backtest-vs-production discrepancy entirely. #DolphinDB #StreamProcessing #ETL
1

May 27
How do you rank 5,000 stocks by momentum on every single tick? It's harder than it sounds — you need per-symbol state, event-time semantics, and a cross-sectional view across the whole market, all without falling behind.
medium.com/@DolphinDB_Inc/bu…
We wrote about how to solve this in #DolphinDB by chaining a Reactive State Engine (per-symbol ROC) and a Cross-Sectional Engine (market-wide ranking) into a single pipeline — one subscription, one thread, no intermediate tables.
#StreamProcessing #RealTimeData #DataEngineering #QuantFinance #AlgoTrading #FinTech #DataScience
1
36

May 18
Open sourcing our event driven architecture: Kafka configurations, Flink job templates, schema registry setup, monitoring dashboards.
Follow me or Ambharii for the release.
What's stopping you from moving to real time? Share in comments, I'll give you the solution.
#DataEngineering #RealTimeData #ApacheKafka #EventDriven #StreamProcessing #BigData #HumanWritten #ExpertiseFromField
16

May 18
Backlog doesn’t start at the publisher. It builds at the subscriber first, then backpressures upstream. Monitor the whole chain with #DolphinDB to understand where delays really begin. #StreamProcessing #DevOps

May 16
That’s a wrap on the Data Engineering Summit, DES 2026 by AIM
Over the past two days, we have had the opportunity to connect with builders, engineers, and teams working on some of the most important challenges in data today. What stood out most was the clear demand for simpler, faster, and more real-time ways to work with data.
Thank you to everyone who visited the Zeliot booth and took the time to speak with our team. We appreciated the conversations, the feedback, and the energy around the event.
Learn More about Condense here: zeliot.in/condense
Book a Meeting with us here: zeliot.in/contact
#DES #AIM #DES2026 #DataSummit #DataEngineering #RealTimeData #AI #Data #Condense #DataStreaming #StreamProcessing #StreamingData #DataStreamingPlatforms #DSP #Kafka #DataStreams




4

May 15
1/7
Theory is useless if you cannot orchestrate it in production. 🛑
Here is the exact architecture we use to build a real-time Clickstream Analyzer from scratch using Kafka, Avro, and Stream Processing. 🧵👇
#DataEngineering #ApacheKafka #StreamProcessing


1
28

Check out the full breakdown by @rmoff here: dataengineeringweekly.com/i/… 🔗
#ApacheFlink #StreamProcessing #BigData #SQL #DataArchitecture
2
3
330

May 10
면접 단골 3대장, 2026년의 운명
Zookeeper, Spark Streaming, Jenkins. 한때 백엔드/데이터 면접 단골이었던 셋, 지금은 모두 자리를 내줬다.
Zookeeper: Kafka 4.0(2025.3)에서 완전 제거됐다. 14년간 카프카의 메타데이터 관리를 책임지던 외부 의존성이 KRaft 모드로 흡수됐다. Aiven은 운영 중인 1만 5천 대를 무중단 마이그레이션 완료, 신규 클러스터는 이제 KRaft 외 선택지가 없다.
Spark Streaming(DStream): 사실상 deprecated. 표준은 Structured Streaming으로 넘어왔다. Spark 4.1(2025.12)이 도입한 Real-Time Mode는 sub-300ms 지연을 약속하면서 "초저지연이면 무조건 Flink"라는 공식을 처음으로 흔들었다.
Jenkins: 죽진 않았지만 기본값에서 밀렸다. JetBrains 2026 조사 기준 조직 채택률은 GitHub Actions 33% > Jenkins 28% > GitLab CI 19%. 신규 프로젝트는 소스 코드와 가까운 도구를 고른다. Jenkins는 플러그인 1800개의 자유도가 필요한 엔터프라이즈와 에어갭 환경에 남았다.
세 사례에서 같은 패턴이 보인다. 분산 시스템은 외부 의존성을 안으로 흡수하거나, 소스 가까이로 옮기는 방향으로 진화한다. "필수 기술"이 "선택지"로 바뀌는 순간을 알아채는 것이 시니어의 감각.
confluent.io/blog/latest-apa… Confluent가 정리한 Kafka 4.0 릴리스 노트(약 14개월 전 자료, 이후 4.1·4.2 후속 릴리스 진행 중). 14년 이어진 ZooKeeper 의존성이 어떻게 끝났는지, KRaft가 푼 문제와 KIP-848(컨슈머 리밸런스 개선)·KIP-932(큐 시맨틱) 등 핵심 변화를 1차 기술 자료로 확인 가능.
#Kafka #DevOps #StreamProcessing
53

May 9
The same telemetry cleanup code gets rewritten in every subscriber.
monoblok moves it into the broker with a simple DSL
raw → round → squelch → clean
github.com/lexvicacom/monobl…
#nats #ziglang #streamprocessing
1
1
249


Apr 29
Every fraud alert, shipping notification, and real-time recommendation you've ever received, Apache Kafka was almost certainly behind it.
Kafka turned 13 this year and it's still the default answer when someone asks, how do we move data in real time?
I wrote a guide that goes from first principles (what even is a distributed commit log?) all the way to a full production pipeline with Kafka Streams, Debezium CDC, and Kafka Connect.
If you work anywhere near data pipelines, microservices, or event-driven systems, this one's worth a read.
open.substack.com/pub/devops…
#ApacheKafka #DataEngineering #StreamProcessing #DevOps
14
Apr 27
AWS Summit, Bengaluru - 2026 is a wrap!
Two days full of great conversations, new connections, and a lot of excitement around real-time data. Loved meeting so many of you at Booth B17 and seeing the response to #Condense (and the swag 😄).
Until next time!
Learn More about Condense here: zeliot.in/condense
Read Documentation here: docs.zeliot.in/condense
Quick links: zeliot.in/quick-links
#AWS #AWSSummit #AWSBengaluru #AWSSummitBengaluru2026 #Data #DataStreaming #StreamProcessing #StreamingData #AI #Streams #Kafka #ManagedKafka #CondenseApplications




1
2
58

Apr 22
Our experts, Krzysztof Grajek and Grzegorz Kocur, will be speaking at the @confluentinc Data Streaming Meetup, co-organized by @VirtusLab. View the agenda and join the event: meetup.com/krakow-kafka/even…
#ApacheKafka #DataStreaming #Confluent #Krk #Meetup #StreamProcessing #Rustlang #DevOps

1
176

Apr 21
When decisions must be made in milliseconds, features need to be computed, stored, and served continuously.
In our latest article, we explain how a feature store enables this in practice and why it is a core building block of real‑time machine learning architectures.
◾ what a feature store is and how it supports both online and offline processing
◾ why consistency between training and production features directly impacts model quality
◾ real‑time use cases across banking, fraud detection, e‑commerce, telecom, and dynamic pricing
◾ who actually uses a feature store in an organization - from data scientists to IT architects
◾ how to get started step by step, from a first use case to scaling across domains
👉 Read the article: eu1.hubs.ly/H0tH6wL0
#featurestore #mlops #machinelearning #realtimedata #streamprocessing #datascience #dataengineering #frauddetection #riskanalytics #marketingautomation

45
Apr 21
What if the biggest bottleneck in mobility isn’t the vehicle, but the data infrastructure under it?
In this episode of the Condense Streams Podcast, Yash Kulkarni from our team and Hanna Cordes, Global Head - GTM, Bosch Mobility Platform & Solutions zoom into how modern mobility platforms are re‑architected around real‑time data, AI‑driven orchestration, and vertical data streaming.
If you’re curious about the invisible layer that powers connected cars, smart fleets, and next‑gen mobility services, this episode is for you. If you want to read the transcript & follow along, visit: zeliot.in/condense-streams-p…
Watch it here: youtube.com/watch?v=EwUriJVR…
More Episodes here: zeliot.in/condense-streams-p…
#DataStreamingPodcasts #MobilityPodcasts #DataPodcasts #Bosch #Zeliot #Condense #RealTimeData #DataStreaming #StreamProcessing #VerticalDataPlatforms #Kafka #ApacheKafka #ConnectedMobility #MobilitySolutions #MobilityData #BYOC
1
1
21

Apr 16
Kafka alone ≠ Real-Time AI. 🛑⏱️
If you skip exactly-once semantics, watermarking, and stateful stream processing, you aren't building real-time AI. You’re building a "batch-as-streaming" pipeline.
Don't be surprised when your model hallucinates on 4-hour-old data. What is your true event lag?
Fix your data architecture: zurl.co/W8u7e
#DataEngineering #RealTimeAI #StreamProcessing

7

Apr 14
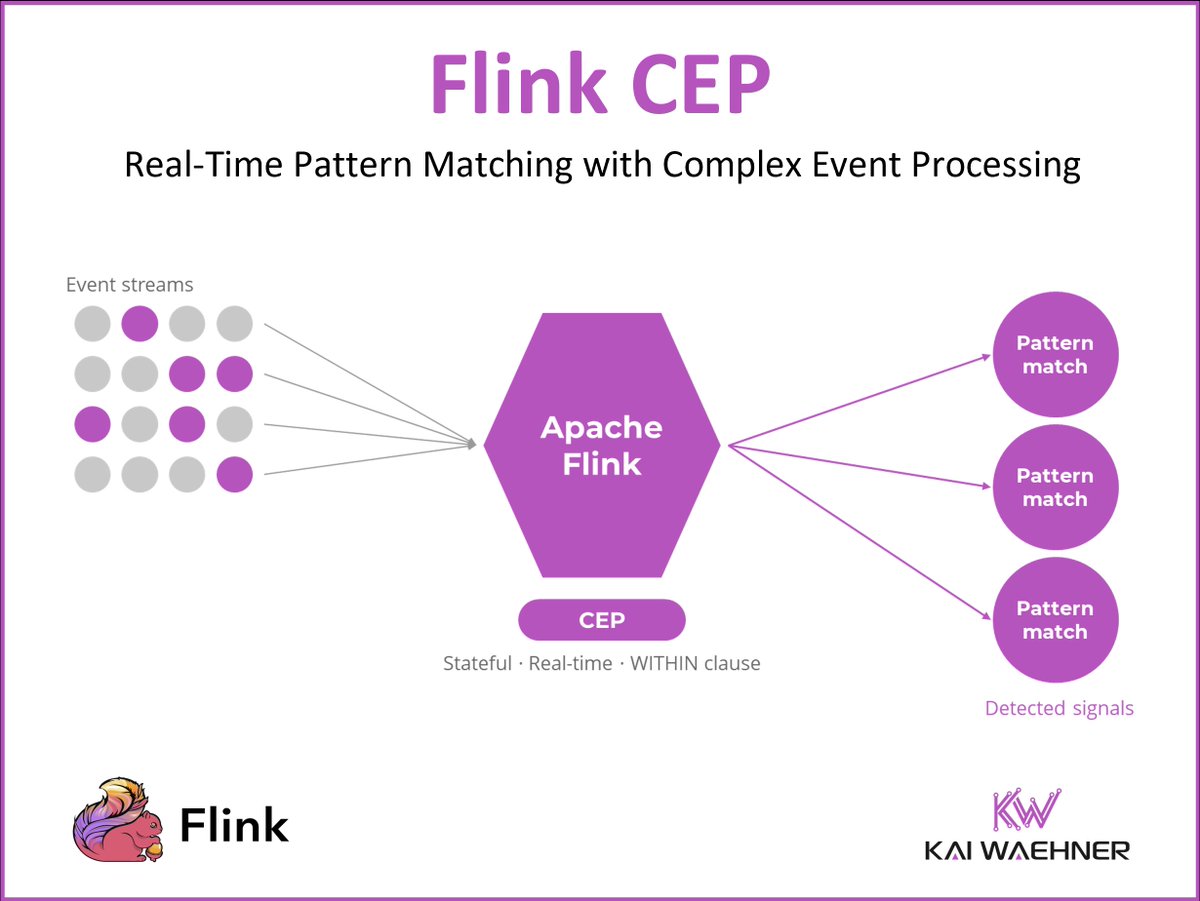
#ComplexEventProcessing is the most underused capability in #ApacheFlink.
Detect event sequences, catch missing events, know when NOT to use it.
Practical guide covering #FlinkCEP vs #StreamProcessing, vendor landscape, and best practices.
New blog:
kai-waehner.de/blog/2026/04/…
1
98

Near-real-time #streamprocessing for personalisation — 6 months in production with #ApacheFlink SPP:
⚡ 10K msg/sec, p99 <100ms
✅ 99.9% uptime
💰 40% lower ops costs
Read the full blog to discover what we built and what we learnt: bit.ly/4vvRBYg
#DataEngineering #AI

1
31

Apr 13
Right record arrives with timestamp ≥ latest left record → join fires.
Or set delayedTime to auto‑trigger after a timeout.
#DolphinDB puts you in control.
#RealTimeAnalytics #StreamProcessing
1

Apr 6
Revisited my Apache Fluss, Flink and Paimon demo project to add some observability.
Prometheus now scrapes Flink and MinIO metrics, Grafana ships with pre-provisioned dashboards, and the README got a full rewrite.
All running locally with Docker Compose. Code on Github: github.com/gordonmurray/apac… #ApacheFlink #StreamProcessing
2
110