
Whisper Leak: a side-channel attack on Large Language Models - microsoft.com/en-us/security… By @yo_yo_yo_jbo & @glmcdona
LLMs are increasingly deployed in sensitive domains including healthcare, legal services, and confidential communications, where privacy is paramount. This paper introduces Whisper Leak, a side-channel attack that infers user prompt topics from encrypted LLM traffic by analyzing packet size and timing patterns in streaming responses. Despite TLS encryption protecting content, these metadata patterns leak sufficient information to enable topic classification.
#AIsecurity #LLMsecurity #SideChannelAttack #WhisperLeak #Cybersecurity #NetworkSecurity #PrivacyRisks #MetadataLeakage #TrafficAnalysis #AIprivacy #LLMprivacy #StreamingLLMs
5
322

22 Jan 2024
Our lively discussion on StreamingLLMs with Attention Sinks is posted!
TLDR ~ Attention sinks allow for stable language modeling up to 4 million tokens without blowing up memory usage.
Watch the recap or read the recap on our blog 🤓
blog.oxen.ai/arxiv-dives-eff…
1
4
144

13 Oct 2023
Here are the AI news that marked previous week! 🧠 (brace yourselves it's been a crazy period - I don't say that lightly)
* Super cool paper (congrats @_rockt, @chrisantha_f & team): "PromptBreeder: Self-Referential Self-Improvement via Prompt Evolution" arxiv.org/abs/2309.16797
At this point we all know of these clever LLM prompts - "Let's think step by step" being arguably the most famous one.
The thing is such hand-crafted prompts are obviously sub-optimal. In this paper LLMs evolve their own prompts through self-referential self-improvement. Reminds me of @kenneth0stanley's Picbreeder work (I suppose the paper title was inspired by it :) ).
* 21 year old CS student (@LukeFarritor) made a major breakthrough in @natfriedman's Vesuvius challenge and won 40.000$: his ML algo read the first word from an unopened Herculaneum scroll! The word is apparently "πορφυρας" which means "purple dye" or "cloths of purple".
The scrolls were discovered in 1750s but are in such a state that they can not be opened and we must use ML to figure out what's written on them.
Blog: scrollprize.org/firstletters
* @chipro's new blog post is out: Multimodality and Large Multimodal Models (LMMs): huyenchip.com/2023/10/10/mul…
Nice high level overview of the topic! I would just add multilinguality to the LLM research directions :)) (see my project as well: github.com/gordicaleksa/Open…)
* @nathanbenaich just released this year's state of AI report!
Check it out: stateof.ai/
It's probably the best high level resource to figure out what happened over the last year - thus making it perfect for people who are not in the "AI trenches" like myself, but I'm sure I've missed out on important details myself as well :))
* Amazing new paper introducing RingAttention (nice work @haoliuhl!), enabling scaling context lengths to 0.5M tokens and beyond! Well kind of, depends on device count - more precisely it enables training and inference of sequences that are up to device count times longer than previously possible: arxiv.org/abs/2310.01889
Related work, introduces StreamingLLMs (allowing for infinite context lengths? I wonder what are the caveats, it's not exact attn mechanism it uses sparse attn pattern): arxiv.org/abs/2309.17453v1
* Reading someone's thoughts? Sounds like sci-fi? It's not, check out @iScienceLuvr's new paper: arxiv.org/abs/2305.18274v2
we just had him in my Discord server as well (will try to upload the vid soon!).
* Open source alternative to GPT-4 vision: LLaVA (Large Language and Vision Assistant): llava-vl.github.io/ and related cool paper "Improved baselines with Visual Instruction Tuning" that further improves LLaVA: arxiv.org/abs/2310.03744
* People are pushing the state of the art by fine-tuning open source LLM base models like recent Mistral 7B model, check out this: twitter.com/_lewtun/status/1…
* Related, Mistral AI has published their paper: arxiv.org/abs/2310.06825 (9 pages only)
* @OpenAI's DALLE-3 paper is out as well: cdn.openai.com/papers/DALL_E…
* Hyped up new paper "Language Models Represent Space and Time": arxiv.org/abs/2310.02207. They show they can find an actual wold map inside of Llama 2 activations. There's been a debate on their definition of a "world model" as commonly defined. Just by showing that the model has an internal representation of a world MAP doesn't mean it has the model of the world.
* @Replit is giving out free access to their AIs! (code completion and code assistance) They'll be burning a ton of GPUs but this might be a great opportunity for beginners to check them out: blog.replit.com/ai4all they are a "cloud based IDE" but on steroids if you never heard of them.
* This is big! OpenWebMath, a massive dataset containing every math document found on the internet (14.7B tokens) - with equations in LaTeX format. We've shown that datasets like these improve reasoning of LLMs and datasets contributions are among the most important contributions in the field.
Paper: arxiv.org/abs/2310.06786 (@keirp1 et al)
* "Everything about Distributed Training and Efficient Finetuning" - in depth blog, highly recommend if interested in this topic.
sumanthrh.com/post/distribut…
Phew. :)) Accelerate. 🫡

10 Oct 2023

Here's a simple recipe to train a 7B model that outperforms Llama2 70B on MT Bench 🥇
1. SFT Mistral 7B on the UltraChat dataset
2. Align the SFT model to the UltraFeedback dataset with "direct preference optimisation" (DPO)
Demo: huggingfaceh4-zephyr-chat.hf…
More details in the 🧵
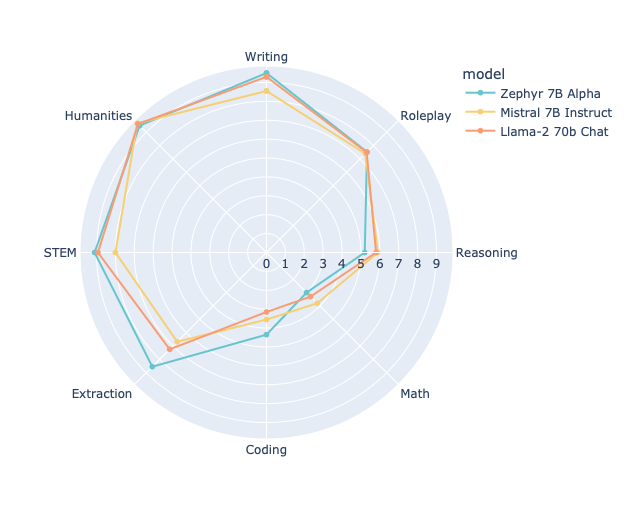
2
18
2,943

4 Oct 2023
So ViT with registers seems to propose that extra tokens are needed for aggregating global information, otherwise the model will recycle input tokens
StreamingLLMs is sort of opposite, there's "useless" information that needs to be tossed somewhere, namely on bos tokens
5
191