
trying to feel the magic. global research lead at @canva | prev: cofounder at @leonardoai
Joined April 2022
- Tweets 12,483
- Following 888
- Followers 9,699
- Likes 26,598
2,324 Photos and videos











Pinned Tweet

14 Feb 2025
personally I feel like the inflection point was early 2022. The sweet spot where clip-guided diffusion was just taking off, forcing unconditional models to be conditional through strange patchwork of CLIP evaluating slices of the canvas at a time. It was like improv, always trying to riff of mistakes and sitting right at the fine line between interesting and incoherent.




14 Feb 2025

Image synthesis used to look so good. These are from 2021. I feel like this was an inflection point, and the space has metastasized into something abhorrent today (Grok, etc). Even with no legible representational forms, there was so much possibility in these images.




29
40
705
241,707
Jun 11
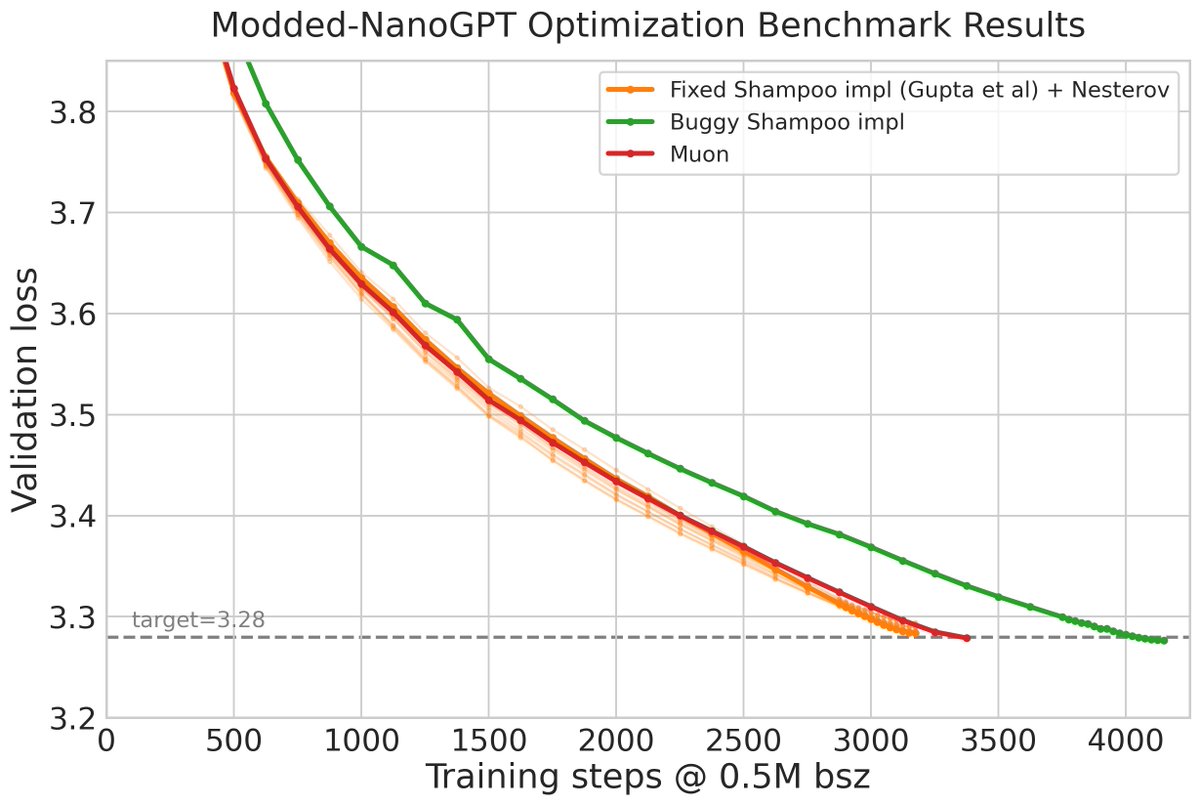
Honestly I’d expect Shampoo to beat Muon, shampoo with b2=0.0 and momentum covariance (instead of grad), whitening only on one side should be equivalent to muon up to numerical imprecision.
Question is whether it’s worth it, it’s tracking 4 states at 2 x n^2 x m^2 memory and while NS can be used for the power raising instead of eigh, still more flops. In single device training it’s a good consideration, making it work well in distributed feels like a nightmare, I’d be more inclined to give SOAP the chance if paying that cost, Adam in the eigenbasis is a genuinely unique effect, but yeah there’s a lot of engineering obstacles that even in best case make it a hard sell
Jun 9

Here you go, sir. Muon is a good optimizer.
I think Keller's attempt at implementing it is great -- this primarily helped me look at why his effort produced much worse looking curve than what I could get.
This ended up being a nerdsnipe into hyper parameters, grafting, and eigh calls in the distributed shampoo package from Meta in my car ride home.
The main delta's are below:
2
2
22
5,159
Jun 9
Second order feels like a wildly overloaded term for optimizers as it can mean anything from
- the second moment E[g^2]
- gradient covariance (centered second moment) E[(g-u)^2]
- the hessian L’’(x)
All closely related but properly distinct
6
4
42
3,339
Jun 11
Probably more accurately, it’s how it’s been used, rather than what it necessarily means
1
162
Jun 11
fella said an exact claudism
is Claude built in the image of Dario or did he become like Claude?

22
10
677
43,855
Jun 6
It’s a bit of a different school of thought to reward guidance, but CFG itself may be able to replicate the more creation aspect of RL and does have tilting properties.
Condition on the reward, CFG provides the extrapolation/maximization
Jun 5

reward guidance is one of the most useful tricks we have for steering diffusions and flows at inference time. you take a learned generative process and nudge it toward high-reward samples, and in principle you're sampling from the reward-tilted measure.
but are we really tilting?🤔
in practice, people use approximations, and the best one we have is a finite-particle plug-in estimate of the value function. it turns out that this approximation doesn't sample the tilted measure at all.
we show that the bias induced causes reward hacking completely independent from the reward model -- this even occurs for gaussians with quadratic rewards!
once you identify this problem, it turns out you can fix it analytically. @sanjitdp derives a closed-form reward damping schedule that corrects the within-mode bias at zero extra compute. it improves guidance at any number of particles, and with just a single particle it matches what used to take eight to sixteen, giving an order of magnitude reduction in compute.
he also shows that simple plug-in estimators can't select modes in the tilted distribution. best-of-n can, and he highlights that best-of-n damping gives the best performance in practice as a result.
amazingly, the theory carries all the way from gaussian mixtures up to FLUX.1 text-to-image generation, leading to significant performance improvements at a fraction of the cost 🚀
3
5
54
7,778
Jun 6
Different from EMA of weights compared to gradient, but AdEMAmix works gorgeously for diffusion and I suspect there’s a similar thing going on there
Jun 5

New blog post: EMA decay is not just a smoothing trick.
From the *same* training run, changing only EMA decay beta moves diffusion gFID from 4.14 to 3.21 at 80 epochs.
Thread on what we found (w/ Xiaoyu Wu and @_Chen_Wei_ ):
1
27
3,072
Jun 6
The alignment problem in humans and institutions feels measurably more concerning than it does in AI right now
2
4
14
755
Jun 5
Feels like this post was the wake-up call for many, but felt evident from the hyper-optimized cuda kernels beyond what humans write, Karpathy's auto research and more.
Notably, these are all open-source projects. You can extrapolate whats happening behind the scenes from there
Jun 4

Our internal data shows Claude is accelerating AI development—a possible path to recursive self-improvement, or AI autonomously building a more capable successor.
It’s happening faster than we thought, and the implications deserve greater attention. anthropic.com/institute/recu…
3
2
23
2,308
Jun 5
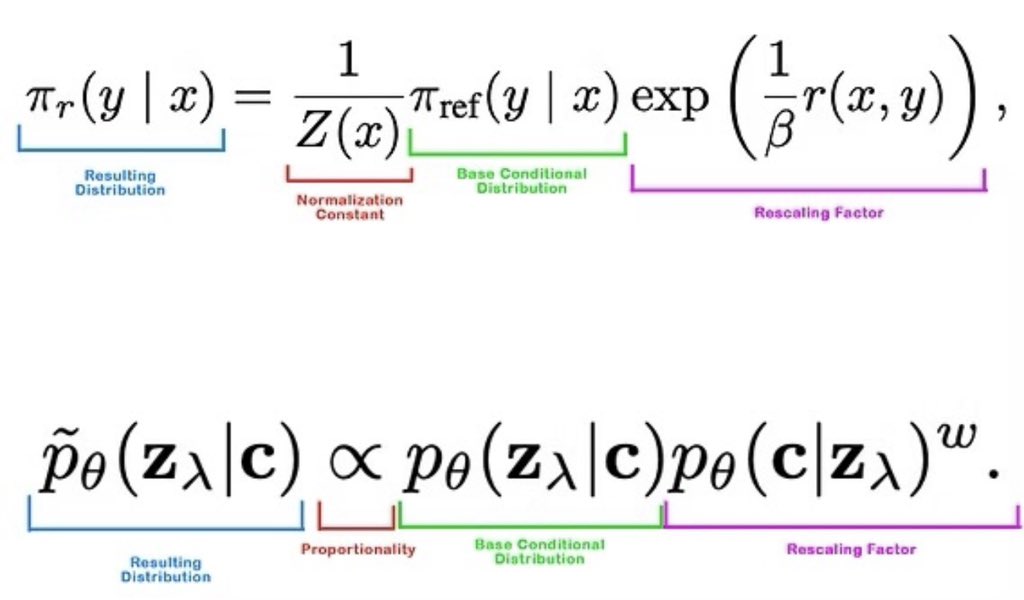
REPA thoughts
REPA as x0 prediction
- the DINO/Encoder features prediction can be seen loosely as "x0 prediction in an alternate representation space than main diffusion space, from an intermediate/rather than final hidden state"
- If so, we should consider the same principles for predicting x0, like loss weighting etc.
- simply: we know noise prediction is "impossible" from fully clean image (we know nothing about the noise sample), x0/clean image prediction is "impossible" from fully noised state (we know nothing of the image). velocity as (x0 - eps) suffers at both endpoints, at x0 we know nothing of eps and can't really predict this direction, and vice versa
- the general form of this is both endpoints of the trajectory are a domain, and when we're on the opposite side, the minimum risk prediction is to predict the mean of the opposing domain/dataset (or conditional slice if relevant)
- Because of this, predicting DINO features at a fully noised state may not give us a helpful signal yet might be disproportionately weighted due to high error/grad magnitude.
IREPA claim that structure > representation quality
- If so, representation space features might be superfluous
- "Beyond Surface Statistics: Scene Representations in a Latent Diffusion Model" demonstrates that image diffusion models naturally develop a representation of depth, fairly reliably predicted even at high noise levels with only a linear probe
- This observation could be "flipped on its head" we know a performant pretrained model has this quality in the end, we could do the inverse and add supervision/guidance to encourage this early
- segmentation maps, depth, etc feel like good candidates if its spatial/structure properties that drive the improvement as they nicely correlate to low frequency coarse structure
Mapper design, spatial target parameterization axes
- a few papers have covered this, but the design of the mapper and level of compression describes the assumption we're making and guidance we enforce
- Spatial/Compression: i.e. full spatial patch-to-patch matching, pooled, or something in between like a downsample/perceiver pooling
- Depth and Architecture of mapper: how much of the burden of adaptation for this secondary task falls on the backbone model vs the actual mapper parameters.
- are we wanting to be a linear projection away from the reference space? a shallow MLP away? a deeper mapping?
-- My impression is the shallower options deliberately ask the diffusion representation space to already be somewhat denoised (because we're mapping to clean x0 in DINO space) and a more trivial mapping away.
-- Deeper options can sort out the noise filtering and more extensive work to map to DINO space, if that's adapted/isolated to the mapper, then i feel the question is less about taking on a shape that resembles the reference feature space, and instead having high mutual information. To successfully predict the features, the information has to be there, any variables around getting to that other space the mapper squares away.
2
10
90
8,506
Jun 4
Anthropic showing significant improvements in productivity while every other incumbent is reporting worsened output and increased cost either signals
- skill issue
- false reporting or confounding variables
I weigh towards the first explanation heavily
Jun 4
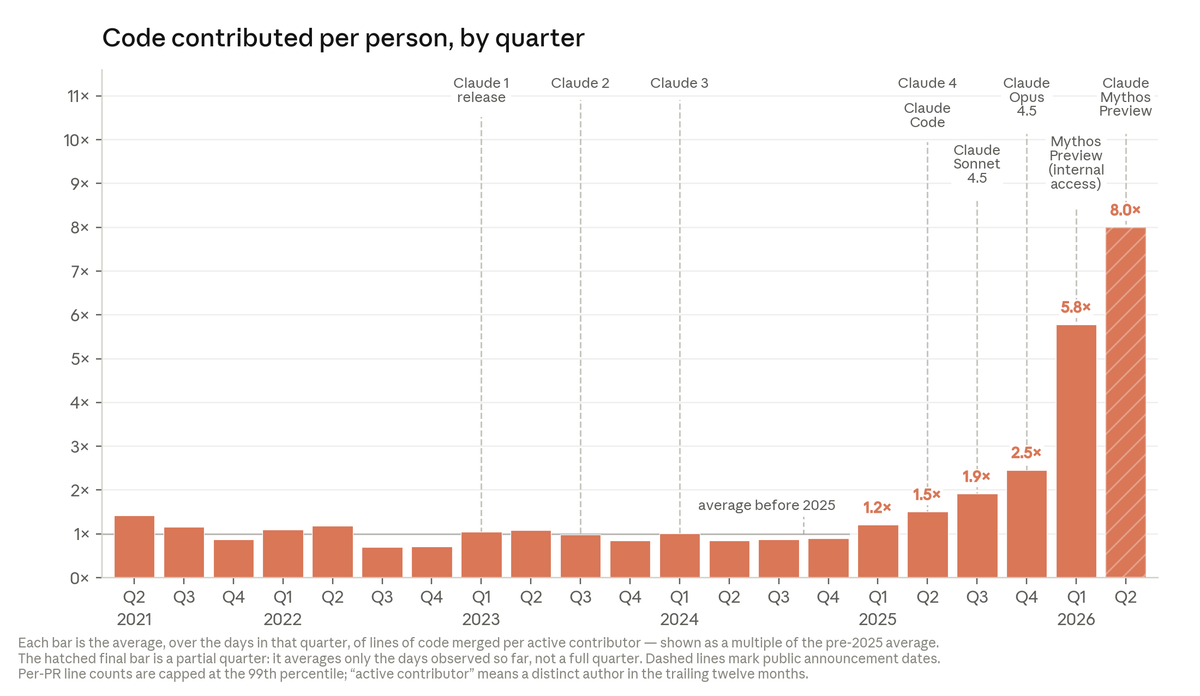
Today, Anthropic engineers on average ship 8x as much code per quarter as they did compared to 2021-2025.
5
19
2,749
Jun 4
All the stuff around Microsoft, Amazon, Uber, talking about how AI coding has not been effective:
You are telling on yourself 😭
2
10
765
Jun 4
Secret third option for fairness is that internal models are offering much more than externally provided, or even an intentional malicious nerfing to stifle other software companies
Don’t really buy that overall though
1
4
507
Ethan retweeted
May 29
Coordinates were not meant to be discrete, you risk class imbalance and no intrinsic knowledge of number line or a loss that caters to that, just use a linear head to output 4 coordinates with an MSE loss. Fourier embed at input side. Here’s a paper we did on that



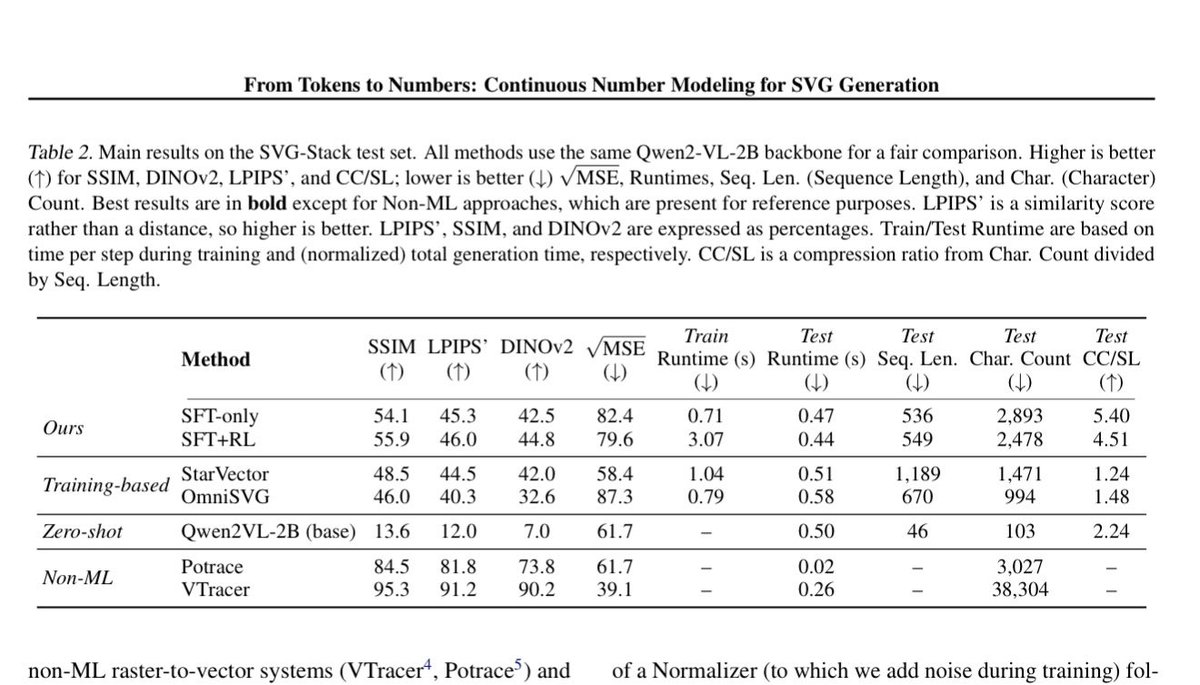

This #CVPR2026 paper from our research team is trending #1 on @HuggingFace 🤗
Meet LocateAnything: a vision-language detection model that rethinks bounding box prediction. For AI agents and robots, “seeing” is only useful if a model can pinpoint where something is fast enough to act.
Trained on 138M high-quality samples, LocateAnything decodes bounding boxes in parallel instead of one coordinate at a time, improving localization accuracy while dramatically increasing throughput for visual grounding and detection.
Project page: nvda.ws/4dKSohb
2
5
47
5,741
Jun 4
This is a sobering take. For research, intelligence may mean better search and more derived from existing knowledge.
But that hits a wall, we produce information through empirical experimentation, which is bottlenecked by experiment time, often the speed the universe moves at.
This highlights the need for a high-fidelity and high-speed means to run simulations. We've understood this problem for a while and numerous fields are producing simulations for study where we don't have closed form understandings, like weather modeling, markets, etc.
I think the drug trial example is a solid thought experiment
- no closed-form model of what will happen, we have to run experiments to see what will happen, which can take months, years, or more to really capture long-term effects
- Intelligence can help us interpret results, choose better hypotheses, connect the dots to other knowledge, build models from observations, but given what knowledge is actually established, it cannot shortcut us to a full closed-form understanding where we could start with a molecule and predict an EXACT outcome for a given biology
Accelerating drug trial research (and other fields that need empirical studies) comes to, I think:
- Simulation fidelity and speed: improving models for the extremely diverse and varied response to a drug, with the goal of it being faster than real life, unbiased (not giving incorrect information), and high-fidelity (model is complex enough to provide something of value even if not as high resolution as reality)
- More closed-form understandings: The more we can predict within some level of noise, with a reliable equation, whether thats drug metabolization half-life, absorption rates, neuron desensitization expectations etc.
Ultimately, AI will likely help with both of the above, we feasibly could see a speedup in drug research, but it has fundamental obstacles before recursively improving just snipes it into instant solves

Anthropic is questioning whether AI may turn out to be altogether useless. This is the single most honest thing Anthropic has ever written.
“But achieving recursive improvement alone does not suggest an immediate change in how industrial production occurs, societies organize, or markets function. More intelligence can’t learn what a drug does over decades of use, can’t hold elections sooner than a constitution dictates, and can’t turn a stranger into an old friend in a weekend. For most people, the felt pace of this future will still be set by the bottlenecks, even if the laboratory upstream runs at the speed of compute. That collision, where recursive intelligence building itself ever faster meets the world of humans, relationships, and governance, is another part of this future we can’t predict.”
3
1
21
2,888
Jun 4
3
602
Jun 4
i think we should be talking more about the Taalas 16k tok/s chips. If this scales, its a good partial counter to the AI bubble. Loss leaders need to hold off long enough for the 10-100x inference cost reductions.
4
16
1,193