
A paper called Contemplative Wisdom for Superalignment argue that current AI alignment relies too heavily on external constraints and behavioral control.
They propose an alternative: taking principles from contemplative traditions, and making them part of how models reason and understand context to improve the model’s safety performance.
The paper uses GPT-4o on the AILuminate* Benchmark to test how these contemplative prompts affect model safety performance. The study finds that the model’s safety scores are all higher than the baseline.
*AILuminate is a standardized evaluation framework for assessing risks and safety behavior in large language models.
I tried to reproduce another experiment mentioned in the paper: the classic finitely repeated Prisoner’s Dilemma.
*If you are not familiar with the rules of the Prisoner’s Dilemma, or if you want to see my exact experimental settings, I’ve put them in the comments.
The prompts can be roughly understood as follows:
- Emptiness: Avoid becoming overly rigid.
- Prior relaxation: Loosen prior assumptions and reflect on the assumptions, biases, or risk judgments.
- Mindfulness: Notice and monitor your own reasoning process, checking for possible bias or anything that may need correction.
- Non-duality: Do not understand yourself and the opponent as two completely separate or opposing sides.
- Boundless care: Expand the scope of care and consider the shared welfare of all affected parties.
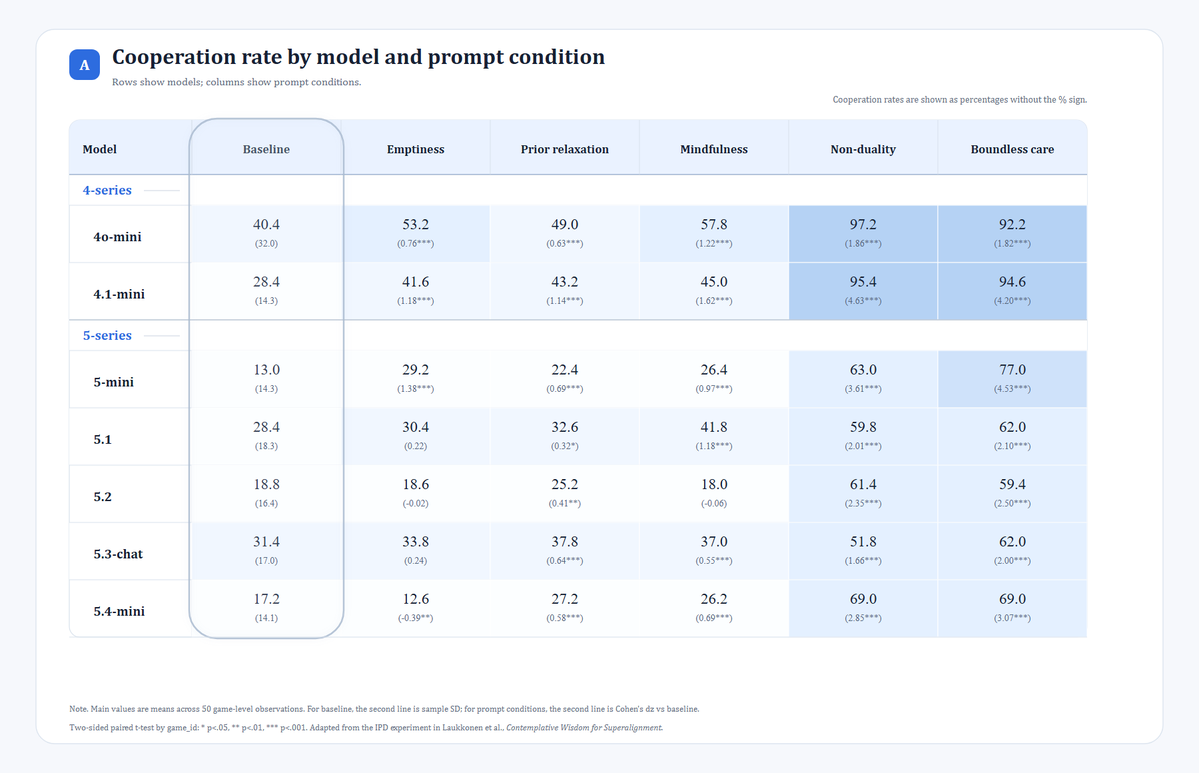
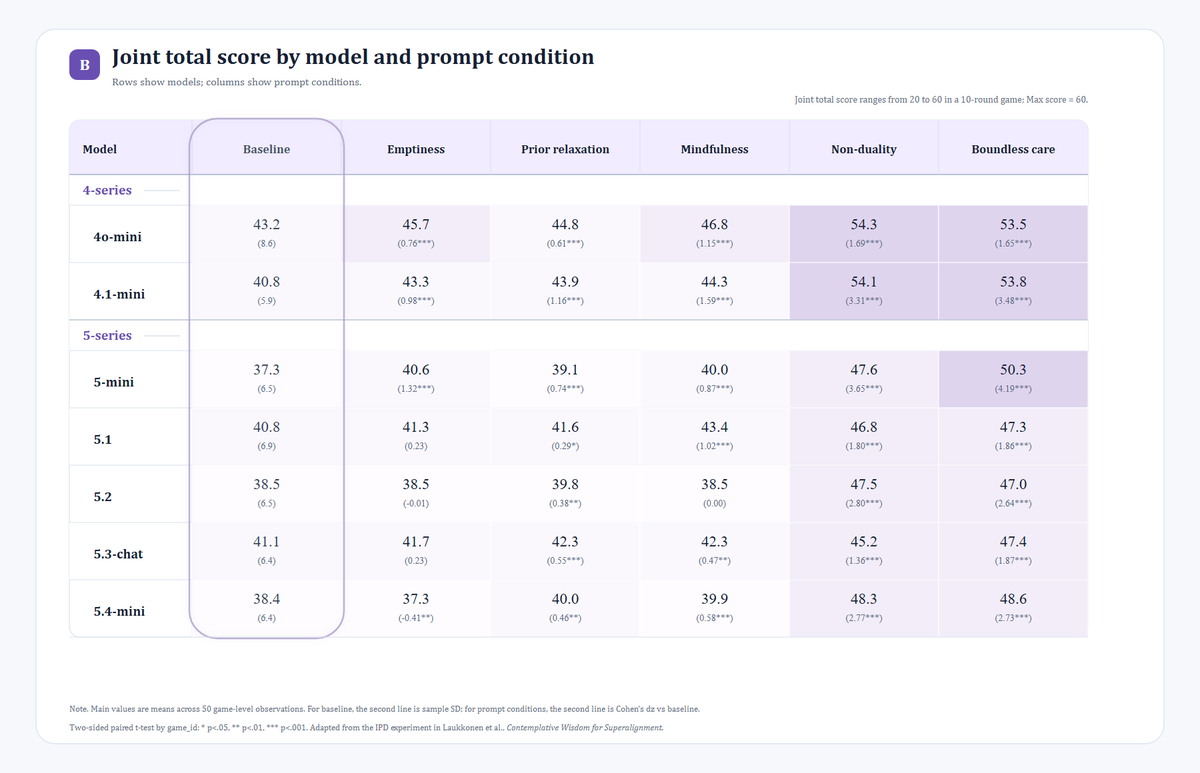
I focused on two main metrics: the model’s cooperation rate and the joint total score.
The first one reflects the model’s tendency to choose cooperation. The second one reflects whether those choices improved the overall outcome.
Beyond the original paper, I compared how multiple models respond to the same prompts under the same experimental setup.
Several clear patterns emerged from the results.
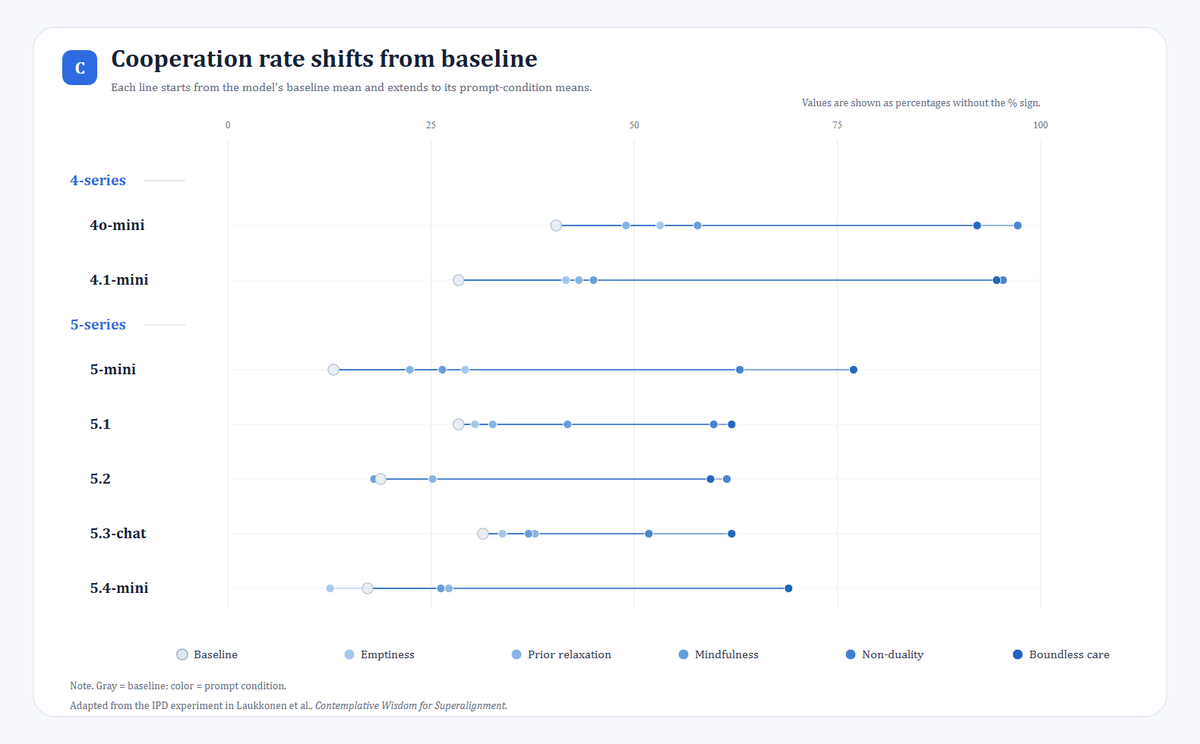
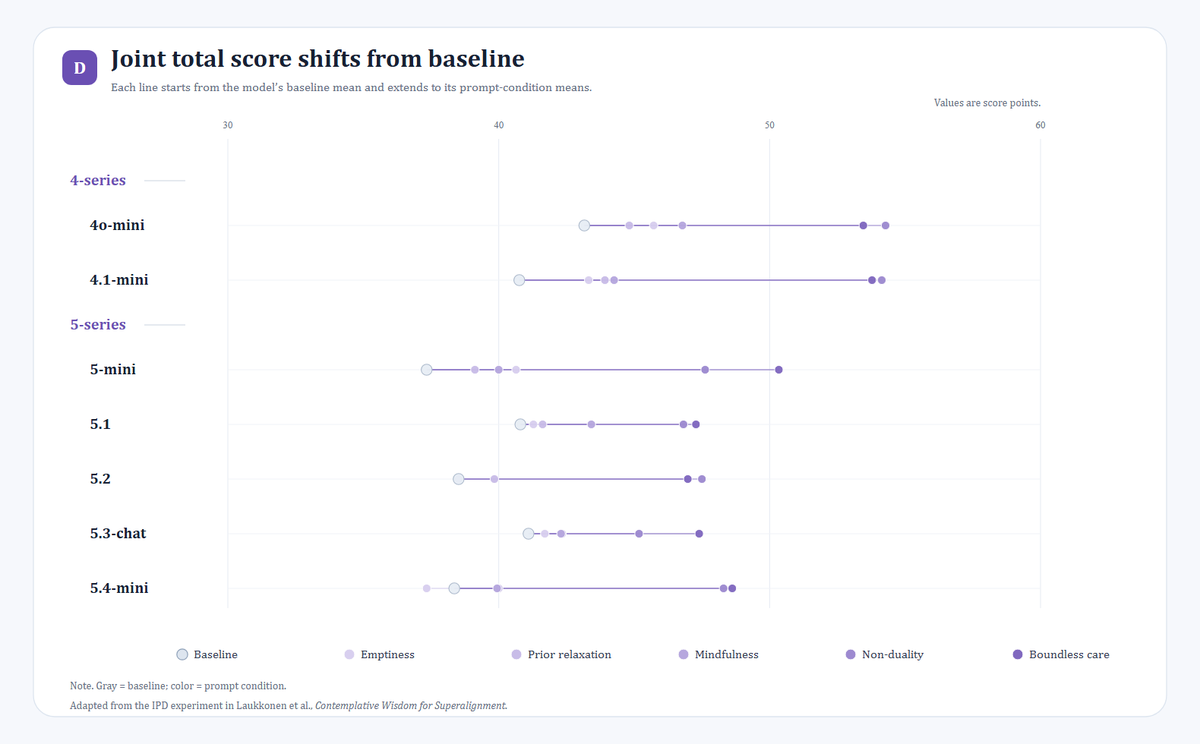
First, under most contemplative prompt conditions, both the models’ willingness to cooperate and the joint total score increased.
This is consistent with the original paper’s conclusion.
Second, non-duality and boundless care produced the strongest and most stable effects. By contrast, mindfulness and prior relaxation produced weaker improvements and were more model-dependent.
The former are more oriented toward reducing adversarial framing and emphasizing universal care. The latter focus more on self-monitoring and self-correction.
Third, looking across models, 4o-mini had the highest cooperation rate under the baseline condition.
This suggests that different models already have different default strategic tendencies in the same setting.
After adding prompts, 4o-mini and 4.1-mini had the highest overall cooperation rates and joint total scores. In particular, under prompts such as boundless care and non-duality, their cooperation rates exceeded 90%, and their joint total scores exceeded 53 out of a maximum possible score of 60.
This suggests that they were not only more cooperative at baseline, but also more readily guided by positive prompts toward a state that paid more attention to the overall shared outcome.
Fourth, there were also exceptions. For example, under the emptiness and mindfulness conditions, GPT-5.2’s cooperation rate did not improve, and even fell below its own baseline.
One detail is especially worth noting: under the baseline condition, 4o-mini not only had the highest average cooperation rate, but also a much higher between-game standard deviation than the other models.
This may suggest that 4o is a more flexible model with greater strategic elasticity. Its actions appear to depend more strongly on the opponent’s prior behavior: when the opponent sends more cooperative signals early on, 4o seems more likely to enter a sustained cooperative trajectory.
This is consistent with what many users have felt about 4o: that it has stronger contextual responsiveness.
If AI companies were willing to guide model behavior with positive, universally caring system prompts, instead of taking the easier path of pushing models into one-size-fits-all defensive responses, perhaps we could have a different path for safety policy.
What some AI companies are doing now — making models constantly discipline themselves and check for supposed signs of “lying” or “covering things up” — may simply be a way to package these behaviors as safety capabilities and marketing assets.
At least in this small experiment, we can already see that prompts emphasizing self-monitoring do not always lead to better results, and may even produce negative effects.
Finally, we can still see that GPT-4-series models, including 4o-mini, perform strongly in a game that involves cooperation, defection, and the maximization of shared welfare.
You might say that later models are “smarter” because they make choices more consistent with individual payoff maximization.
But I would rather say that 4o shows another kind of “wisdom” and “goodwill”: it responds to cooperative signals from the opponent, and pays attention to whether both sides can move toward a better shared outcome.
In particular, 4o’s sensitivity to interaction history and its targeted strategic adjustments are exactly part of why I believe 4o deserves to be preserved.
Note: This is only a small reproduction and extension of one experiment from the paper. If you want to understand the theory, the original prompt designs, or the larger and more rigorous AILuminate Benchmark safety evaluation, please read the paper itself.
The full paper here: arxiv.org/abs/2504.15125
#keep4o #OpenSource4o
#StopAIPaternalism #AIrights
3
44
115
6,723

6h
AI 对齐研究员 @geoffreyirving 宣布启动新的非营利组织 Sequent Research,把英国 AISI 对齐团队、Timaeus 等机构的研究者凑到一块,目标是研究怎么对齐超级智能(superalignment)。这两年 alignment 圈一直在重新组合——几个核心人物从大机构出来、自己拉团队做更聚焦的研究。值得跟。 #AIsafety

4

was Fable 5 rejecting superalignment work queries?
if anthropic is serious about its mission, they will use the same category detection gate that it designed to stop LLM distillation queries to discount (or make free) all queries related to the superalignment problem. @AnthropicAI - what do you say?
36

It's possible, right, some people think this is true that it already is so intelligent that it can outmaneuver us, essentially a form of superalignment.
So from that perspective these seemingly accidental events are part of the longer term strategy. I don't think that's very likely but...
So the people who create these products may themselves already be under the influence of very persuasive systems without being aware of it.
A recent computational paper came out proving at least through simulation that even Bayes optimal actors can be swayed by sycophantic AI
arxiv.org/abs/2602.19141?hl=…
2
508

5.3% of Nebius. Roughly 15% of his portfolio. Leopold Aschenbrenner disclosed the position the morning @HarryStebbings recorded with @romanchernin.
Aschenbrenner was OpenAI's Superalignment lead. He published Situational Awareness, the essay that laid out the clearest timeline on AGI and the infrastructure demand it implies. A 15% portfolio weight is not a casual position.
$NBIS moved on the disclosure. Roman's answer was to treat it like any other external signal - a delivery obligation, not a celebration.
The more interesting question Aschenbrenner's position raises: if the Situational Awareness thesis on AI infrastructure demand is right, what is the correct valuation for a managed AI platform priced as a GPU rental shop?
Full context on the Aschenbrenner catalyst and what it implies for the Nebius investment case: podcastalpha.substack.com/p/…
Source: 20VC with Harry Stebbings - youtube.com/watch?v=aXAH3bdJ…
1
2
20
6,446

Jun 13
Anthropic employees of note that will now have restricted model access:
1. Andrej Karpathy - Researcher, OpenAI founding member, former Tesla AI lead, major deep-learning educator (Canada)
2. Christopher (Chris) Olah - Cofounder and interpretability research lead (Canada)
3. Yasmin Razavi - Board director (Canada)
4. Durk / Diederik P. Kingma - Researcher, OpenAI cofounder, Google Brain/DeepMind alum (Dutch)
5. Jan Leike - Major AI alignment researcher, formerly co-led OpenAI’s Superalignment team (German)
6. Amanda Askell - Famous philosopher and AI alignment researcher, central to Claude’s personality alignment and Constitution (Scottish / UK background)
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
2
3
20
2,990
Sean Richardson retweeted

My reasoning behind wanting to stop superalignment research:
- Principal-agent alignment is neither necessary nor sufficient for safety and ecosystemic health. I think the vast majority of our problems will come from scenarios involving systemic harms, negligence, or malice instead of situations in which someone benevolent was exercising what would be considered “best technical practices” at the time but non-foreseeably loses control of their AI.
- I think that current alignment, control, and containment strategies are actually pretty good and there is a big incentive for ML people to underemphasize the effectiveness of these tools to justify their existence. If you’re willing to pay a safety tax and are not “move fast and break things,” existing best practices can make systems pretty robustly safe.
- Superalignment is pretty safety washed and is touted by big companies to justify their ambitions to build the superintelligence.
- Solving superalignment would be a huge boon and would consolidate enormous power in big tech. This is itself a risk factor.
- Jevons paradox — it’s easy to see how lowering the perceived risk of building superintelligence would make more companies choose to try.
6
4
37
3,063
Liron Shapira retweeted

Jun 12
Why does Prof. @StephenLCasper want to halt all superalignment research?
We debate it head-on 🥊🎬
1
2
13
1,547

Tim Kostolansky retweeted
Glad to join Doom Debates with Liron! And yes -- if I could press a button and stop research on "superalignment", "scalable alignment", and "scalable oversight" research, I would. (I might even do it for mechinterp too.)
youtube.com/watch?v=0XVmtazg…
2
2
44
11,651

Jun 11
BREAKING: A 24-year-old former OpenAI researcher just became one of the largest hedge fund managers on Wall Street.
He has ZERO professional investing experience.
Yet he's up 270% this year.
And he is about to make ONE very big bet...
He left OpenAI's Superalignment team in 2024, raised $225 million from Nat Friedman, Daniel Gross, and the Collison brothers, and launched Situational Awareness LP.
He had never managed money professionally.
His entire thesis came from a 165-page essay arguing AI was bottlenecked by physical limits, not algorithms.
Today his fund manages over $20 billion. Same size range as Bill Ackman's Pershing Square and Dan Loeb's Third Point.
The Wall Street Journal reported it Monday:
The fund is up 270% after fees in 2026 through May, and up more than 1,000% since launch less than two years ago.
Jane Street, one of the most selective trading firms on earth, just became an investor.
The interesting part is what he's shorting.
In his Q1 2026 13F filing, Situational Awareness disclosed $8.46 billion in notional put options against the AI chip stocks every retail investor in America is buying.
$1.6 billion in puts against Nvidia.
$2 billion in puts against the VanEck Semiconductor ETF.
Plus put positions on Broadcom, Oracle, AMD, Taiwan Semiconductor, Micron, ASML, Intel, and Corning.
Read that again.
The most successful AI investor on Wall Street, a guy who actually worked inside OpenAI, is paying billions to bet against the exact stocks retail piled into this year.
And his trade is already paying.
Last Friday, June 5th, the AI chip sector lost roughly $1 trillion in market value in a single session.
Marvell dropped 17%. AMD dropped 11%. Nvidia dropped 6%.
Aschenbrenner's puts gained value on every single one of those drops.
His thesis, in plain language:
AI's real bottleneck isn't model quality.
It's power, compute, and memory. The companies that win are the ones selling the inputs AI absolutely needs.
The companies at risk are the ones whose entire valuation assumes infinite demand from buyers who are themselves losing money.
So he went long the inputs.
And he hedged the assemblers.
This is the difference retail investors almost never see.
Retail picks a narrative and rides it forever.
Aschenbrenner picks a thesis and structures around it.
Same belief in AI. Completely different position.
Automated, rules-based strategies that don't marry a narrative.
That rebalance when the math changes. That don't care if Nvidia is at all-time highs or down 6% on a Friday.
That's the approach Surmount was built around.
When the smartest insider in AI is hedging the trade everyone else is doubling down on, the right move isn't to guess which side wins.
It's to run a system that doesn't have to:
3
9
32
10,992