
🚨 Ads3 Officially Joins the ENI Super Node Network 🚨
We are pleased to announce that @ads3_ai has officially become an ENI Super Node and has been included in the ENI Top 100 Ecosystems Program.
As an AI-powered Web3 intelligent advertising platform, Ads3 is helping accelerate ecosystem growth through data-driven marketing, user acquisition, and innovative advertising solutions.
This milestone reflects the strong strategic alignment between ENI and Ads3. Moving forward, both parties will deepen collaboration across ecosystem applications, growth scenarios, resource integration, and long-term network development.
The ENI Super Node Program continues to unite leading ecosystem builders, creating stronger connections and expanding Web3 adoption worldwide.
Welcome to the ENI ecosystem, Ads3! 🤝🚀
#ENI #Ads3 #SuperNode #Web3 #AI #Blockchain

8
301
highlights retweeted

Apr 24
Honored to be among the first WLFI Supernode Operators.
This is more than a milestone — it’s the beginning of a powerful new chapter for real-world blockchain adoption. Together with WLFI, MovaChain will accelerate USD1 utility across AI, payments, and next-generation financial infrastructure.
The future is being built now. 🚀 @worldlibertyfi @EricTrump @ZachWitkoff @zakfolkman
#USD1 #MOVA #WLFI
Apr 24

We’re very excited to welcome MovaLab as one of the first WLFI supernode operators. This marks an important milestone for the network, and we look forward to working closely with @MovaChain to expand USD1 use cases across AI, payments, and beyond.
WLFI is actively onboarding additional WLFI supernodes as we continue to scale and strengthen the ecosystem.
167
189
811
44,641






Jun 13
Next hour, you post 3 hours ago and it's above 25 M dumbass
I checked supernode option in bubble maps, only @MascotAsteroid has lowest supernode bundle
OG has the biggest and is scam
Check bubble maps option on dexscreener
3
104

The upcoming Mainnet isn’t just another milestone it’s the foundation for the next phase of the network. With $NETX becoming the unified gas token, supernode economics, staking incentives, AI-agent coordination, and real infrastructure utility finally coming together.
2
6
32
1,032

Jun 13
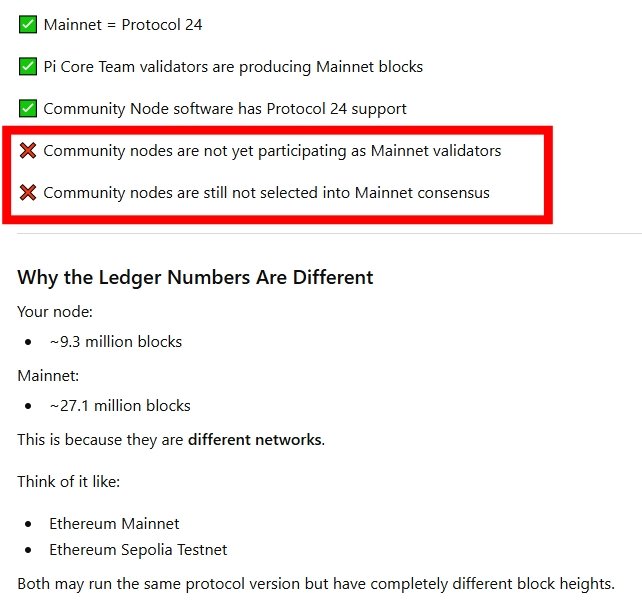
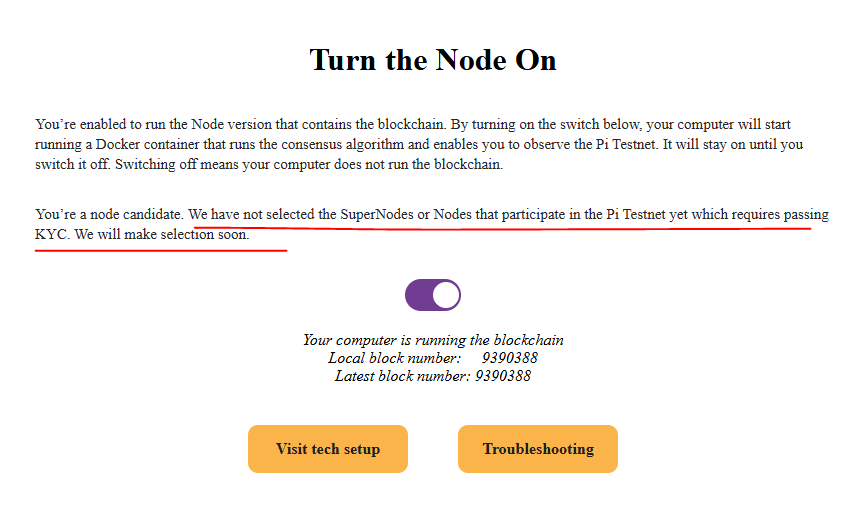
💬 PIONEERS — If Mainnet is already on Protocol 24 and our nodes run compatible software, why can’t community nodes join consensus yet? 🤔
📸 These screenshots from the Node app say it all:
✅ “Your computer is running the blockchain” – local block matches latest
❌ “We have not selected SuperNodes or Nodes… yet. We will make selection soon.”
📋 The “Future Pipeline” still lists:
· Enable Mainnet node operation
· Define SuperNode selection criteria
· Decentralization guidance after Open Network
So here’s the hard truth:
Even after v24, v25, v26… decentralization is still a long way to go, Pioneers. 😤
No clear criteria, no timeline, no transparency.
😂 Some Pioneers say asking questions is a crime 🤡 – and the “patience monk” Pioneers still don’t realize the project has 2–3 more years before decentralization actually happens.
👇 What specific milestone is still preventing community nodes from joining Mainnet consensus? Drop your theory below. 🔁
#PiNetwork #DecentralizationWhen @PiCoreTeam

22
11
112
6,256

Jun 13
GM CT
True decentralization in GameFi?
Nah, most projects still run on one big central server like a dodgy referee 😂
You stake, you play, then boom counterparty risk everywhere.
Meanwhile @HCOW_Official is cooking with DPoS like a proper team setup on this World Cup Saturday 🔥
• Supernodes: 500k $HCOW 1yr lock = captain-level commitment & rock-solid hosting.
• Delegates: From just 5k $HCOW (6-month lock) jump in, rep your squad.
• Delegators pay 10% to their Supernode from rewards
Locked stakes = no sudden “red card” dumps. Real community-owned gaming ledger.
Level up NOW, Earn FOREVER ⚽💰
As your HCOW Ambassador, this architecture got me hyped while watching Brazil vs Morocco highlights today.
Who’s building nodes with me?
Drop your thoughts or biggest question 👇
What’s your score prediction for today’s matches?
#HCOW #HashCow #GameFi #WorldCup #Web3Gaming

1
2
4
113


For node and supernode may be they stack thousand of coin first
2
4
32
HW insider says initial Atlas-950 deliveries will be 1024-card version. Demand for 8192-card SuperNode is not there. Each 1024-card is ~1 EFLOPS FP8.
It will be available on HW Cloud in Aug & external customers in Q4.
DS likely buying 1024-card nodes & connecting them together
Each yr, new Ascend-card 2x in compute, so it can plug in more powerful compute as time goes on.
HW is also deploying Kunpeng-950 Supernode w/ unified memory pool that DS may be interested in.
It is deploying 16k card systems that both Scale-Up (interconnect within a SuperNode) & Scale-Out (traditional network connection bw SuperNodes)
Comparable to Nvidia's NVLink InfiniBand
Again, each hyperscaler that buys Nvidia racks still need their own engineers to build out large Data centers.
Not a surprise that DS will also need to do that here if it's seeking GW-sized Data centers running out of Inner Mongolia (home to major CSPs & EDWC clusters).
I would expect it to use the standard that HW provided for Scaling-up & Out, since that's what US hyperscalers do when they buy NVL72 & put those racks in clusters.
For an AI lab that does much of the stuff on its own, is it any surprise that it wants to build its own AI cluster?


Jun 10

DeepSeek is going heavy-asset.
On June 9, the company posted an opening for IDC planning engineers, a role explicitly scoped to the design and delivery of MW-to-GW scale infrastructure. It follows April's hiring of data center O&M engineers in Ulanqab, Inner Mongolia. Taken together, this is the first time DeepSeek has fully shown its hand on owning compute infrastructure rather than just renting it.

1
14
101
13,447
But then, we got news of 189m RMB expansion for building InP laser chips in 2026/4.
It would add a new 300k 4-inch equivalent wafer production line on top of its existing 150k -> 450k total.
This is happening just as HW/Ascend team is dramatically expanding Ascend SuperNode.
1
1
10
350

Jun 11
One of the most important—and least discussed—elements of the plan is the focus on AI supernodes (Intelligent Computing Supernodes). MIIT calls for advances in supernode optoelectronic interconnect technologies (智算超节点光电互联技术), high-speed photonic chips, optical switching, and co-packaged optics. Beijing increasingly understands that the next AI bottleneck is not the chip itself but the network fabric connecting thousands of chips into a single computing system. China's answer is to build larger, more tightly integrated supernodes as part of its national compute-network strategy.
Huawei of course is already doing this and Huawei will build most of these, along with some that include ASICs from companies like Alibaba, run by state owned majors China Mobile and China Telecom....
4
5
40
32,132




