
I count maybe 10 gpu's.
Tensordock- $0.36/hr nVidia 4090.
1 month = 720 hours, 720 * 0.36 = $259
10 4090's/month = $259 * 10 = $2590
1 4090 = ~450w * 24 * 30
Multiple by 10 * $kwh price.
Avg. Ukrain kwh is 0.098 or 10 cents.
This post is bullshit, likely someone's local LLM.
4
120

May 7
我真的被惊呆了
做网页动画,复杂动效
直接用 Codex HyperFrames,
纯前端代码直接变成自动化视频流水线。
这才是Vibe Coding的正确打开方式(附使用教程):
I 代码写动效,告别打关键帧
让 Agent接管视觉。不用打开AE,不用折腾 AE脚本管家。Codex直接输出 HTML GSAP缓动和进出场逻辑。创意变成干净、可复用的代码资产,效率直接起飞。
I 云端静默渲染,全自动出片
写完代码还能直接渲片。部署到Vast. ai 或 TensorDock 这类算力平台,给个执行权限,Codex后台就调 hyperframes-cli非交互式导出高清MP4。等于免费多了一个永不宕机的渲染节点。
I 像素级精准
跟那些每次生成都像开盲盒的视觉大模型不一样,这套是纯代码渲染。每一帧的位置、每个转场的时机都你说了算,跑起来稳得一批。
使用教程
比如:让 Agent 自动抓取 GMGN上的 SOL或 BNB 链上聪明钱动向,动态填入写好的数据可视化模板,紧接着调用 HyperFrames一键生成带有时序动效的行情复盘视频
分辨率1920*1080, 帧率每秒30s,总时长15s
整个“数据获取-视频产出”的流程,只需要你的一句话授权!
代码即视频的时代,真的来了。
项目直达地址:
CODEX: chatgpt.com/codex/cloud
HyperFrames: codex://plugins/hyperframes@openai-curated
Apr 30

正好在学Codex,看到 @ai_muzi 老师的这期《Codex 零基础保姆教程》直接封神了
这应该是全网最全最细的Codex教程了,从安装、界面、权限、Skills/Plugins,到做网站、PPT、Excel、自动化,再到AI直接操控浏览器和电脑,全程手把手、零废话!时间轴安排得明明白白,准备五一假期跟着刷一遍。
强烈推荐收藏反复看~

36
18
129
27,348
May 5
还在把本地 AI Agent当成只能聊天的高级打字机?
Hermes Agent官方仓库更新了两个重量级的原生Skills,直接把 Agent 的能力边界从“文字处理”跨越到了“视觉生产”与“商业变现”!
这才是让数字生命真正替你打工、搭建全自动工作流的最核心玩法:
ComfyUI 视觉生产自动化
直接让 Agent接管复杂的节点生图工作流!你可以把 ComfyUI 部署在 Vast. ai 或 TensorDock 这类云端 GPU 算力平台上,通过这个原生技能,Hermes 能理解你的自然语言,全自动帮你下发指令、调参数、批量渲染并提取高质量视觉资产。设计效率彻底拉满。
Shopify 电商变现全托管
除了搞创作,还能直接搞钱!官方 Productivity模块下的 Shopify技能,允许 Agent直接调用 API接入你的网店。自动新建商品、更新价格库存、管理订单状态,相当于免费雇佣了一个 24 小时在线、永不疲倦的“赛博店长”。
官方原生支持,极度稳定
这两个神级技能并非随时可能报错的民间魔改版,而是 NousResearch官方主分支里的标准化模块。这意味着它们能完美契合 Hermes Agent 的三层记忆架构和底层思维链机制,运行极其稳定。
打通“创作-变现”的商业闭环
想象一下组合使用的终极形态:让 Agent调用 ComfyUI 自动生成产品级视觉主图,紧接着调用 Shopify 技能包,将图片连同自动生成的精美文案直接上架到网店——整个商业闭环,只需要你的一句话授权!
或许可以让Agent自动赚钱的时代真要来临了
项目直达地址:
ComfyUI:github.com/NousResearch/herm…
Shopify:github.com/NousResearch/herm…
视频来自 @NousResearch
May 5
玩Hermes Agent找不到好用的插件和教程?
终于有人出手了!GitHub 上新鲜出炉的awesome-hermes-agent 项目,直接把 Hermes生态的所有内容都整理好了!这是一个由社区大佬打造的终极资源汇总大全,堪称 Hermes 玩家的宝典。
这个项目到底有多良心?核心亮点如下:
一站式生态导航地图
全网最优质的 Hermes衍生项目,比如带 UI 的客户端、各种套壳工具,在这里都分门别类整理得清清楚楚。
开箱即用的超强插件库
需要给 Agent 接入 Telegram?需要读取本地数据库?还是想找高阶的思维链配置文件?这里收录了大量即插即用的社区插件和适配器,随拿随用。
保姆级干货与教程合集
无论你是刚入坑的新手想看“一键安装指南”,还是进阶开发者想找“底层运行机制解析”或是“多智能体协作实战”,仓库里都收录了最优质的文章和视频教程链接。
持续进化的开源兵器谱库
作为awesome系列的仓库,它是一个保持生命力的共建项目。你发现了什么好用的新工具,也可以直接提 PR 补充进去,大家互推互助。
非常建议把这个仓库标星收藏起来!以后配置本地 Agent 遇到问题,先来这里翻一翻!
项目地址:
github.com/0xNyk/awesome-her…

24
28
154
19,254

Mar 19
Пишу MCP сервери зі скілами під А2A A2UI, ганяю RAG RL'ьом з трансформерами. Хостю в основному на vLLM, під Vast.ai або Tensordock. Написані провайдери під Virtual Kubelet. Для публіки зазвичай OpenRouter під Milvus або pgvecto.rs
2
5
2,185

Going to be getting up the local hosted AI curve next few weeks, starting with renting some cloud (TensorDock?) to experiment with config and performance before spending $6-20k US on hardware.
Jungle shill me your best local AI resources
7
1
14
2,115


Pra teste tu pode usar o tensordock ou vast.ai
É ondemand, você aluga uma gpu de alguém pelo mundo e paga pelo uso.
2
168

19 Dec 2025
Day 215 : Data Science Journey
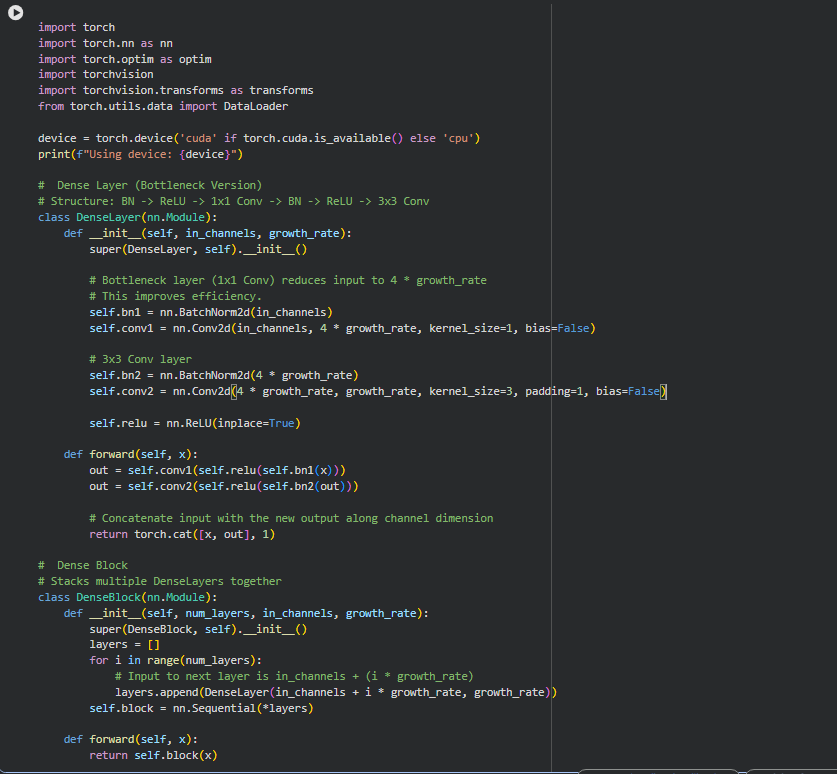
With understanding of DenseNet completely, now moving to its implementation in the decoupled pipeline establishment.
-Implemented the core DenseBlock by stacking DenseLayers: each layer starts with a bottleneck 1x1 convolution that compresses the input channels to 4 times the growth rate for efficiency, then applies a 3x3 convolution to generate new features at the growth rate,
before concatenating everything along the channel dimension to reuse earlier features across the network.
This dense connectivity, where every layer feeds into all subsequent ones. reduces parameters while capturing multi-scale patterns, like edges in early layers combining with textures later.
-The full structure uses transitional ReLUs between blocks for non-linearity, all authored locally in VS Code/collab, versioned on GitHub, and executed on a remote TensorDock GPU.
-Training pulls datasets on-the-fly from HuggingFace for streaming access, with trained models and checkpoints pushed straight back to the hub, keeping everything remote and stateless.
-This separation maintains a clean boundary between local development and remote execution, cutting out unnecessary data transfers that could slow down iterations and avoiding any local artifacts that might clutter versioning. It also makes the system more robust for scaling, as code changes evolve independently of the GPU environment, allowing quick experiments without setup overhead.
Next, explores training loops on the refined architecture.
So, that's all took a lot of effort, what's your cause??
#DataScience #ML

ALT Go Beyond "PLUS ULTRA"!! -yagi toshinori
2
1
10
2,456
28 Nov 2025
Day 194 : DataScience Journey
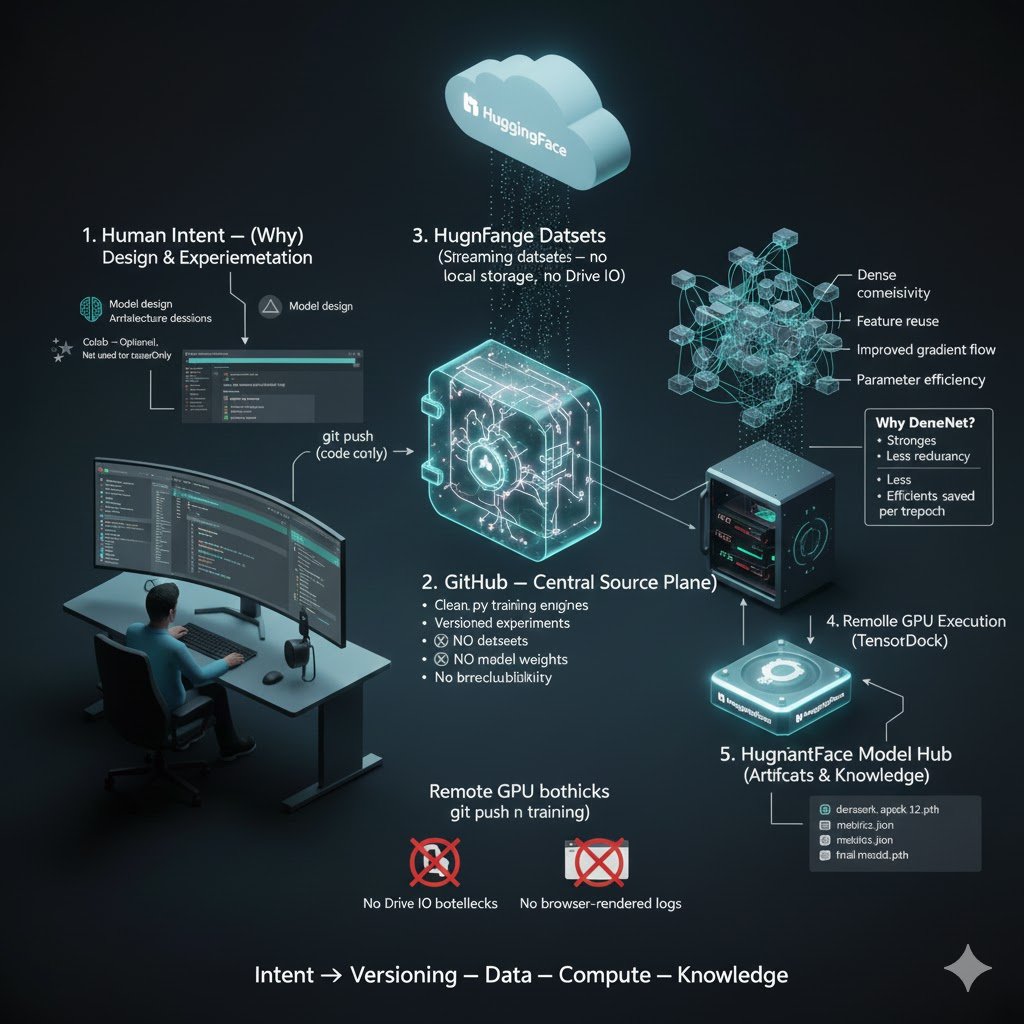
Decoupled MLOps Architecture Validation: VGG16 Trained from Scratch Achieves 98.78% Validation Accuracy
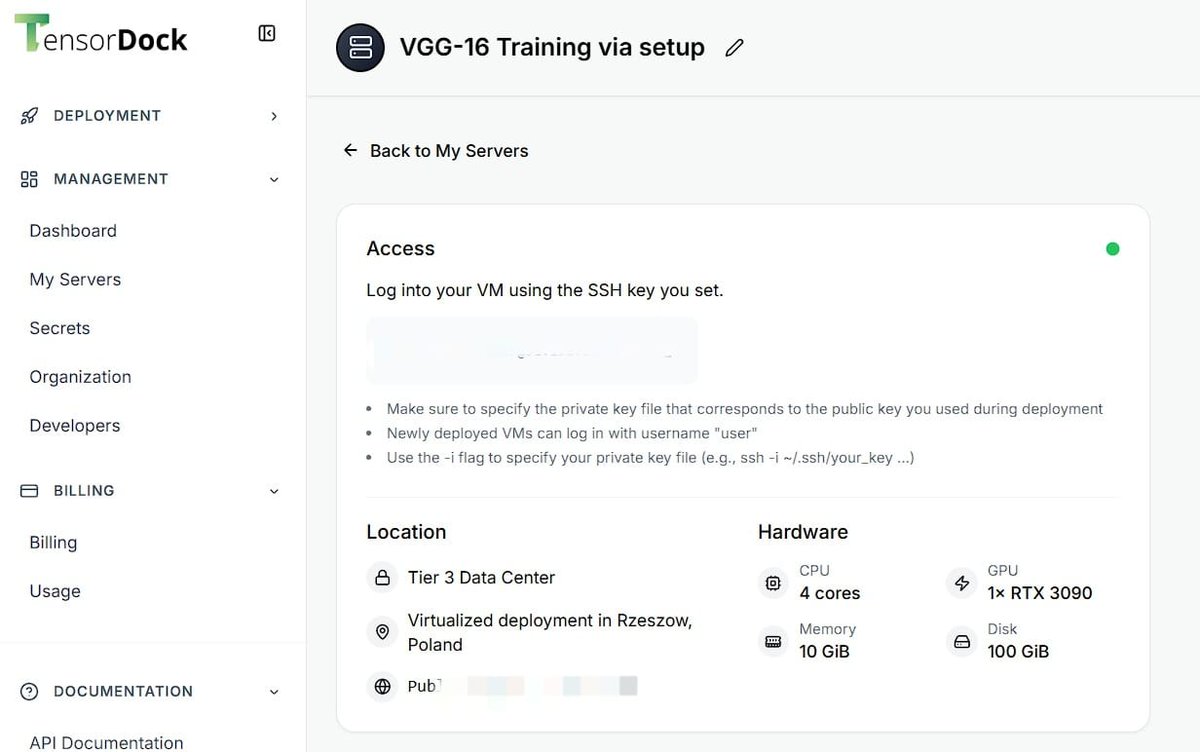
The hybrid Controller-Compute-Warehouse architecture is now fully operational and has been rigorously validated through end-to-end execution of a complete training pipeline. The system demonstrates complete end-to-end reproducibility, near-100% GPU utilizaCompute Layer – TensorDock Cloud GPU (Ephemeral High-Performance Training) Instance type: RTX 3090 24 GB (on-demand, $0.69/hr) or RTX 4090 equivalents
Local storage: 2 TB NVMe SSD (HF cache pre-warmed once)
Data loading: direct streaming from Hugging Face CDN → zero local dataset copy required
Observed GPU utilization: 99–100% throughout training (no I/O starvation)tion, and zero I/O-induced stalls.
Architecture Components and Data Flow
1. Warehouse Layer – Hugging Face Hub (Persistent Storage & Versioning)
Dataset: remote-data (25,000 cat/dog images, 224×224×3)
Storage format: Parquet binary image blobs, git-LFS versioned
Access mode: streaming or cached download at >1 GB/s
Checkpoints and final weights automatically pushed with commit messages containing hyper-parameters and metrics
→ Complete decoupling of persistent artifacts from ephemeral compute nodes.
2. Controller Layer – Google Colab Free Tier (Orchestration & Resilience)
Role: persistent control plane (runtime >11 days observed)
Responsibilities:
• SSH/WireGuard tunnel maintenance to remote GPU instances
• Execution of orchestration script (Paramiko-based) for instance lifecycle management
• Real-time log streaming and metric parsing
• Automated checkpoint/upload triggering every epoch
• Failure detection and auto-restart logic
Resource usage: <1 GB RAM, CPU-only → eliminates disconnects caused by heavy I/O or GPU contention
3.Compute Layer – TensorDock Cloud GPU (Ephemeral High-Performance Training)
Instance type: RTX 3090 24 GB or RTX 4090 equivalents
Local storage: 2 TB NVMe SSD (HF cache pre-warmed once)
Data loading: direct streaming from Hugging Face CDN → zero local dataset copy required
Observed GPU utilization: 99–100% throughout training (no I/O starvation)

ALT Complete Cloud Workflow Pipeline

2
12
8,098

22 Nov 2025
$NVDA $AMZN $MSFT $GOOGL Below is a detailed analysis of the hyperscalers and neoclouds’ various levels of service offerings. You will see the heterogeneity of the service offerings, which tells a different story than the homogeneity of “GPU compute” that Wall Street and MSM promote.
————
• Traditional hyperscalers (Azure, AWS, Google Cloud, Oracle, IBM, Alibaba) span almost the entire hierarchy: from GPU‑backed SaaS copilots (L1) and model APIs (L2) down through managed training platforms (L3–L4), managed GPU clusters (L5), GPU VMs (L6) and, in some cases, bare‑metal GPU instances (L7). 
• Neocloud giants (CoreWeave, Lambda, Crusoe, Nebius) concentrate in the middle and lower layers: strong managed clusters and orchestration (L4–L5) and high‑quality VMs / bare metal (L6–L7), with a growing but more selective presence in training platforms and inference services (L2–L3). 
• Platform‑centric neoclouds (Together, RunPod, Verda/DataCrunch, Gcore, Hyperstack, Firmus, GMO GPU Cloud, TensorWave and a few others) extend the stack upward into managed training, inference, and lightweight MLOps (L2–L5) while still selling GPU VMs and clusters (L6–L7). 
• Infrastructure‑first neoclouds (Voltage Park, Cirrascale, Scaleway, Vultr, many Bronze‑tier clouds) are tightly focused on high‑performance clusters and bare metal (L5–L7), with minimal higher‑level platform features. 
• Marketplaces and brokers (Vast.ai, Prime Intellect, TensorDock within Voltage Park, etc.) operate as an overlay on the bottom of the stack, aggregating GPU VMs and bare‑metal servers from many providers rather than running their own full cloud. They sit between L6–L7 commercially but do not own much of the technical stack. 
To anchor terminology, the hierarchy is:
L1 – Fully managed AI applications (copilots, vertical SaaS).
L2 – Managed foundation models and inference APIs (model‑as‑a‑service).
L3 – Managed training / fine‑tuning platforms (“bring data, get a model”).
L4 – ML / MLOps platforms with integrated GPU orchestration (notebooks, pipelines, feature stores).
L5 – Managed GPU clusters (Kubernetes/Ray/Slurm as‑a‑service).
L6 – GPU‑accelerated VM instances.
L7 – Bare‑metal GPU‑as‑a‑service (dedicated servers).
Below L7 sit colocation and on‑premises deployments, which are important for end users but usually not branded as “GPU cloud providers.”
⸻
1.Traditional hyperscalers
⸻
SemiAnalysis’ ClusterMAX 2.0 classifies Microsoft Azure, Oracle, AWS and Google Cloud as “Traditional Hyperscalers,” distinct from neoclouds and marketplaces.  All four operate across essentially the full stack.
Microsoft Azure
• L1 – Fully managed AI apps: Microsoft 365 Copilot, GitHub Copilot and industry copilots are SaaS products that abstract GPUs entirely. 
• L2 – Model APIs: Azure OpenAI Service and Azure AI model catalog expose GPT‑class and other models via API with token‑based billing. 
• L3 – Training / fine‑tuning: Azure AI Studio and Azure Machine Learning offer managed training, fine‑tuning and evaluation workflows over GPUs and TPUs. 
• L4 – ML/MLOps PaaS: Azure ML provides experiment tracking, pipelines, registries, and deployment, tightly integrated with Azure Kubernetes Service. 
• L5 – Managed GPU clusters: AKS with GPU node pools and Azure’s HPC / AI offerings support large distributed training jobs on H100, H200, GB200 and GB300 clusters (for example, the GB300 NVL72 “supercomputer‑scale” deployment). 
• L6 – GPU VMs: NC/ND/NV series instances expose single‑ and multi‑GPU VMs based on Nvidia GPUs. 
• L7 – Bare metal: GPU bare metal is limited; Azure’s focus is on VM‑based HPC. Oracle positions itself as the only major cloud with fully exposed GPU bare metal, suggesting Azure’s GPU bare‑metal SKUs are niche or absent. 
Amazon Web Services
• L1 – AI applications: Amazon Q, CodeWhisperer, and other AI‑backed SaaS features embed GPUs but are sold as enterprise productivity tools. 
• L2 – Model APIs: Amazon Bedrock exposes FMs from Anthropic, Meta, Mistral, Cohere and others via one API. 
• L3 – Training / fine‑tuning: Bedrock model customization and Amazon SageMaker training flows provide managed training and fine‑tuning on GPUs including A100, H100 and H200. 
• L4 – ML/MLOps PaaS: SageMaker is a full ML platform (experiments, pipelines, feature stores, deployment) built over AWS GPU infrastructure. 
• L5 – Managed GPU clusters: EKS, AWS Batch, ParallelCluster and UltraClusters over P4/P5/P6 instances provide managed Slurm/Kubernetes environments for thousands of GPUs. 
• L6 – GPU VMs: EC2 P‑ and G‑series instances deliver virtualized GPU capacity. 
• L7 – Bare metal: Bare‑metal EC2 instance types (“.metal”) and Nitro‑based GPU instances provide near‑metal access for workloads needing direct hardware control. 
Google Cloud
• L1 – AI apps: Workspace AI features and Gemini‑powered assistants are AI SaaS offerings on top of TPUs/GPUs. 
• L2 – Model APIs: Vertex AI and Gemini APIs expose Google and partner models via managed endpoints. 
• L3 – Training / fine‑tuning: Vertex AI supports managed training/fine‑tuning on TPUs and GPUs with pre‑built pipelines. 
• L4 – ML/MLOps PaaS: Vertex AI is a unified platform with pipelines, registries, and MLOps features. 
• L5 – Managed GPU clusters: GKE with GPU node pools and “AI Hypercomputer” pods combine TPUs, GPUs, fast storage and advanced fabric; large training workloads run here. 
• L6 – GPU VMs: Compute Engine exposes A100, H100, H200, L4, T4 and others as attachable GPUs to VMs. 
• L7 – Bare metal: Google offers “Bare Metal Solution” for Oracle and some HPC workloads, but GPU bare metal is niche relative to VM‑based GPUs. The mainstream GPU product is at L6. 
Oracle Cloud Infrastructure (OCI)
• L1 – AI applications: Oracle has vertical SaaS applications, but most GPU‑relevant offerings start at L2.
• L2 – Model APIs: OCI Generative AI service exposes managed FMs via API. 
• L3 – Training / fine‑tuning: OCI Generative AI supports hosting and fine‑tuning models on “dedicated AI clusters.” 
• L4 – ML/MLOps PaaS: OCI AI services offer some PaaS‑like workflows, though less broad than SageMaker or Vertex. 
• L5 – Managed clusters: Dedicated AI clusters provide managed environments running on H100/H200/B200 fleets, integrated with OCI networking and storage. 
• L6 – GPU VMs: Standard OCI GPU VMs. 
• L7 – Bare metal: OCI explicitly markets bare‑metal GPU instances (H100/H200, MI300X etc.) as a differentiator versus other hyperscalers. 
IBM Cloud and other “second‑tier” hyperscalers
• IBM Cloud offers GPU‑equipped bare‑metal servers and GPU VMs, positioning primarily at L6–L7 with some PaaS around Watson and MLOps. 
• DigitalOcean, Vultr and similar providers sit mostly at L6 (GPU VMs) with little or no managed clusters or model APIs, though some offer simple PaaS integrations (e.g., DigitalOcean GPU Droplets integrated with its platform). 
In summary, hyperscalers extend from L1 down to at least L6 and, for OCI and parts of AWS, to L7. They internalize much of the stack, using GPU IaaS mainly as a cost base for higher‑margin L1–L4 services.
⸻
2.Neocloud giants (ClusterMAX “Neocloud Giants”)
⸻
ClusterMAX identifies four “Neocloud Giants”: CoreWeave, Lambda Labs, Crusoe and Nebius.  These firms are the closest neocloud analogues to hyperscalers, but most of their revenue and differentiation is concentrated in L4–L7.
CoreWeave (Platinum‑tier in ClusterMAX) 
• L4 – PaaS: CoreWeave Kubernetes Service is a managed K8s platform with Slurm‑on‑Kubernetes, observability, and AI‑optimized configuration (networking, storage, drivers).
• L5 – Managed GPU clusters: CKS clusters run on bare‑metal GPU nodes with NVLink and InfiniBand, oriented to training and inference.
• L6 – GPU VMs: CoreWeave exposes GPU‑accelerated VMs for various workloads.
• L7 – Bare metal: Purpose‑built bare‑metal infrastructure for inference and training underpins the platform.
• Limited L2–L3: CoreWeave focuses on infrastructure and orchestration rather than its own generic model APIs; higher‑level services are mostly partner‑led (e.g., Meta, OpenAI).
Lambda Labs (Neocloud giant, Silver medallion) 
• L3 – Training / fine‑tuning: Lambda Cloud is used explicitly for training and fine‑tuning; workspaces and templates push into L3 territory.
• L4 – PaaS: Jupyter‑style workspaces and preconfigured ML environments provide a thin ML platform.
• L5 – Managed clusters: Lambda supports multi‑GPU clusters and 1‑click clusters across B200/H100/A100/GH200.
• L6 – GPU VMs: Core on‑demand product is GPU VMs with Lambda Stack preinstalled.
• L7 – Bare metal: Historically offered bare‑metal DGX and HGX rentals; still present for some dedicated customers.
Crusoe 
• L4 – PaaS: Crusoe positions itself as an “AI platform,” with managed Kubernetes (Crusoe Managed Kubernetes) and orchestration (Run:ai integration) to simplify MLOps.
• L5 – Managed clusters: Crusoe AutoClusters automate Slurm/Kubernetes cluster creation over large GPU fleets.
• L6 – GPU VMs: Crusoe Cloud offers GPU VMs on Nvidia (A100, H100, H200) and increasingly AMD MI300X.
• L7 – Bare metal: Bare‑metal nodes in data centers near stranded energy sources and, more recently, experimental space‑based H100 deployments.
Nebius 
• L4 – PaaS: Nebius AI Cloud provides managed Kubernetes and support for AI frameworks and schedulers.
• L5 – Managed GPU clusters: Thousand‑GPU clusters on InfiniBand fabric with Slurm/Kubernetes orchestration.
• L6 – GPU VMs: Standard GPU virtual machines for smaller workloads.
• L7 – Bare metal: “Bare‑metal performance” HGX/GB systems on InfiniBand underlying the cloud.
• Early L3 activity: Nebius markets itself as a platform for building, tuning and running AI models, but does not heavily promote generic model APIs.
These giants are infrastructure‑heavy. Their primary differentiation is at L4–L5 (managed orchestration and training‑grade clusters) and L6–L7 (pricing, topology, availability). They have limited or no presence at L1 and only selective presence at L2–L3, usually via partner solutions.
⸻
3.Platform‑centric neoclouds (ClusterMAX Gold/Silver)
⸻
This group overlays higher‑level services (L2–L4) on top of infrastructure. ClusterMAX’s Gold and Silver tiers include Together, Voltage Park, Gcore, Firmus/SMC, TensorWave, GMO GPU Cloud, RunPod, Verda (DataCrunch), Scaleway, Cirrascale, Vultr and others. 
Together AI 
• L2 – Model APIs: Together Inference offers serverless inference for 200 open‑source models with pay‑per‑token pricing and “dedicated endpoints.”
• L3 – Training / fine‑tuning: Managed fine‑tuning and full training services on Together’s GPU clusters.
• L4 – PaaS: An integrated platform to train, fine‑tune, and deploy models; workflow orchestration is baked in.
• L5 – Managed clusters: Slurm and Kubernetes‑based GPU clusters for large‑scale training.
• L6–L7 – GPU infrastructure: Instant GPU clusters and reserved GB200/B200/H200/H100 clusters, effectively exposing bare‑metal performance with orchestration.
RunPod 
• L2 – Inference endpoints: Serverless GPU endpoints for generative AI models.
• L3 – Training support: Pods and templates for training/fine‑tuning with persistent storage.
• L4 – Lightweight PaaS: “End‑to‑end AI cloud” branding, with prebuilt runtimes and deployment automation.
• L5 – Managed clusters: Less emphasis on formal cluster services, but multi‑pod orchestrations can approximate L5.
• L6–L7 – GPU pods: Both community cloud (marketplace‑like) and secure cloud deliver GPU VMs and some dedicated nodes.
Verda (formerly DataCrunch) 
• L2 – Serverless inference: Autoscaling model hosting with per‑usage pricing.
• L3 – Training support: Guidance and tooling; not as deep as SageMaker but moving beyond pure IaaS.
• L4 – PaaS: Model hosting, monitoring and autoscaling containers reflect PaaS characteristics.
• L5 – GPU clusters: Custom clusters with Verda‑managed software stacks.
• L6–L7 – GPU instances: On‑demand and long‑term GPU instances up to 8× B200 HGX.
Gcore 
• L3–L4: Preconfigured environments and containerized workloads with Docker/Kubernetes for AI and ML.
• L5: Cluster‑level infrastructure for AI training, built on combinations of bare metal and VMs.
• L6–L7: GPU VMs and bare‑metal servers interconnected via fast networks.
Hyperstack 
• L2–L3: “Hyperstack AI Studio” markets an end‑to‑end environment to build, deploy and monitor AI, implying training and inference PaaS.
• L4: No‑infra‑needed positioning indicates significant platform services.
• L5–L7: Underlying GPU cloud with on‑demand GPUs.
Firmus / Sustainable Metal Cloud (SMC) 
• L4–L5: Firmus AI Cloud emphasizes hybrid/multi‑cloud automation, observability and encrypted InfiniBand networking.
• L6–L7: SMC is primarily a bare‑metal GPU cloud (H100, A100, L40S) with large, energy‑efficient clusters.
• Some L3 elements: Marketing references “AI Cloud Apps,” indicating some platform‑level services on top of clusters.
GMO GPU Cloud 
• L4–L5: Uses DDN storage and NVIDIA AI Enterprise to provide an “all‑in‑one AI development platform” on top of H200 and other GPUs.
• L6–L7: High‑performance multi‑node clusters that also appear in TOP500 rankings.
TensorWave 
• L3–L4: Offers managed inference and PaaS features on top of AMD Instinct MI300X/MI325X clusters.
• L5–L7: Focuses on high‑performance bare‑metal AMD clusters for training, with large MI325X installations.
These providers occupy L2–L7 in varying depth. Their differentiation versus hyperscalers is price, topology (e.g., large, tightly‑coupled H100/B200 or MI300X clusters), and agility; versus infrastructure‑first neoclouds, their differentiation is upward integration into inference and training platforms.
⸻
4.Infrastructure‑first neoclouds
⸻
This group is defined by strong hardware and topology and relatively thin higher‑level services.
Voltage Park 
• L5 – Managed clusters: Dedicated HGX H100 clusters (64–4,064 GPUs) with 3.2 Tbps InfiniBand are configured for large training jobs.
• L6–L7 – Bare metal and VMs: On‑demand access with simple provisioning, little platform abstraction beyond cluster orchestration.
• Limited L2–L4: Historically hardware‑centric, with some movement toward “AI factory” software but far from full ML PaaS. The acquisition of TensorDock adds a marketplace component without significantly lifting the stack.
Cirrascale 
• L5–L7: Bare‑metal, dedicated multi‑GPU compute servers with options for fully managed clusters; focus is on physical servers and HPC‑style inference/training.
• Some L3–L4 elements: Managed inference offerings exist but are not as integrated as hyperscaler MLOps platforms.
Scaleway 
• L6 – GPU instances: VM‑based GPU instances (H100, L40S, L4, GH200, P100) for training and rendering.
• L5: “Supercomputer” configurations suggest some cluster‑level services, but the primary product is IaaS.
• Minimal L2–L4: Some integrations, but no full managed model APIs or training platforms at hyperscaler depth.
Vultr 
• L6 – GPU VMs: Cloud GPU instances with Nvidia and AMD GPUs for AI/ML and graphics workloads.
• Limited L4: Preconfigured images and integrations, but not a complete ML platform.
• No material L2–L3 at present.
Many Bronze‑tier providers in ClusterMAX (e.g., STN, GMI Cloud, Hot Aisle, Atlas Cloud, Buzz HPC, Qubrid) fit this archetype: they offer GPU instances and sometimes basic managed clusters, but limited higher‑layer software. 
These firms compete primarily on $/GPU‑hour, availability and topology, and are highly exposed to Nvidia pricing and utilization risk.
⸻
5.Marketplaces, brokers, and “Craigslist for GPUs”
⸻
ClusterMAX separates marketplaces and brokers into their own column (Vast.ai, Prime Intellect, Shadeform, Mithril, etc.), and further identifies “Craigslist for GPUs” (gpulist.ai, gpucompare.com). 
Vast.ai and similar platforms:
• Commercially operate at L6–L7, aggregating GPU VMs and bare‑metal servers from hosts and data centers.
• Provide a control plane, pricing/auction logic and some templates, but little in the way of true ML PaaS or model APIs.
• Function more as a meta‑layer over infrastructure‑first neoclouds and independent hosts than as full clouds.
Voltage Park’s TensorDock acquisition is an example of convergence between a neocloud and a marketplace; the marketplace piece still sits at the bottom of the stack, while Voltage Park’s own clusters remain L5–L7. 
⸻
6.Mapping back to the hierarchy and investment relevance
⸻
Several structural points emerge once providers are mapped to the hierarchy.
First, hyperscalers are vertically integrated across almost all layers (L1–L6, sometimes L7). AI SaaS and model APIs (L1–L2) are the primary value capture points, with GPU infrastructure treated as a cost base. Their differentiation is in proprietary models, data, and platform coverage; GPU pricing is a tactical lever. This supports margin resilience even as they cut GPU‑hour prices to compete with neoclouds.
Second, neocloud giants and leading platform‑centric neoclouds cluster in L3–L7, with their brand and differentiation anchored in L4–L5 (orchestration quality, training cluster performance) and L6–L7 (pricing, topology). They are closest to the “training factory” narrative. Their exposure to Nvidia product cadence, interconnect costs and data‑center power economics is high; their ability to move up into L2–L3 (model APIs, managed training products) is central to achieving software‑like margins rather than commodity infrastructure returns.
Third, infrastructure‑first neoclouds and marketplaces are concentrated at L5–L7 with thin software layers. Their economics depend almost entirely on maintaining a spread between GPU‑hour revenue and hardware plus power costs, at high utilization. As ClusterMAX and other research show, this segment is already experiencing strong price competition and tightening returns. 
Fourth, the taxonomy highlights how Nvidia’s and AMD’s product cycles propagate through the ecosystem. New architectures (H200, B200/GB200, MI325X/MI350X) are surfaced first at infrastructure layers (L6–L7) by hyperscalers and neoclouds, then pulled up into managed clusters (L5) and training platforms (L3–L4), and only later appear indirectly in SaaS and APIs (L1–L2). Providers concentrated at the bottom of the stack bear the full brunt of depreciation and price erosion between generations; those at the top abstract this away behind price per token or per seat.
Finally, mapping providers to this hierarchy allows clearer differentiation within neoclouds. CoreWeave, Nebius, Crusoe, Lambda and Together operate much closer to hyperscaler‑like PaaS and cluster services than many emerging neoclouds, while Bronze‑tier and marketplace providers are essentially commodity GPU wholesalers. The former group can plausibly build durable franchises if they secure long‑term offtake agreements and continue moving up the stack; the latter are structurally exposed to consolidation and margin compression as GPU markets normalize.
Understanding which layers each provider actually occupies, as opposed to what is claimed in marketing, is therefore critical to assessing durability of economics, the degree of competitive insulation from hyperscalers, and the sensitivity of each business to Nvidia’s pricing and product roadmap.
22 Nov 2025

$NVDA Understanding the hierarchy of GPU service offerings is critical because profit pools, competitive dynamics, and risk profiles differ sharply at each layer of the stack. At the top, fully managed AI applications and model APIs capture value through software, data, and distribution, with GPUs as a largely invisible input. Margins are high, pricing power is strongest, and sensitivity to raw GPU-hour pricing is indirect. At the bottom, bare-metal GPU services, GPU-accelerated VMs, and colocation sit closest to Nvidia hardware economics. These businesses are capital intensive, highly exposed to GPU ASPs and utilization, and face intense price competition as more capacity comes online.
A clear taxonomy makes it possible to map each company’s true position in this stack, separate narrative from reality, and identify where economic rents are likely to accrue.
•Fully managed AI applications (SaaS) that hide GPUs entirely
•Managed foundation models and inference APIs (model-as-a-service)
•Managed training / fine-tuning platforms (“train a model, no infra”)
•Full ML / MLOps platforms with integrated GPU orchestration (PaaS)
•Managed GPU clusters (Kubernetes/Ray/Slurm as-a-service)
•GPU-accelerated VM instances (IaaS VMs with attached GPUs)
•Bare-metal GPU-as-a-service (dedicated GPU servers delivered via API)
•GPU colocation / hosted racks (customer-owned GPUs in provider facilities)
•On-premise self-managed GPU infrastructure (customer buys and runs everything)
The hierarchy above is ordered from the most abstracted, feature-rich, and “application-level” offerings at the top toward the most primitive, infrastructure-level offerings at the bottom. As one moves down the list, the provider delivers fewer higher-level services and the customer assumes more responsibility for software, orchestration, and operations. The underlying GPU product (H100, H200, B200, etc.) can appear at multiple layers; what changes is how much of the stack the provider bundles.
1.Fully managed AI applications (SaaS) that hide GPUs entirely
This category includes end-user products that embed GPUs but present themselves as business applications: copilots inside productivity suites, AI assistants in CRM, code copilots, AI search, AI-native office suites, and vertical AI tools (design, drug discovery, industrial simulation) that expose a pure SaaS interface. The customer never sees GPUs, instances, or clusters; pricing is per seat, per document, per project, or per usage metric (tokens, queries, tasks) but packaged as an application.
From a GPU standpoint, this layer is the furthest from the hardware. Providers hedge GPU capacity commitments against user growth, drive utilization via multi-tenancy, and optimize model architectures and inference stacks internally. Economically, this tier carries the highest margins and the greatest pricing power, since value is anchored in business outcomes rather than compute units. For infrastructure investors, GPU pricing enters only indirectly, through its effect on gross margin and the provider’s ability to subsidize AI features to drive user growth.
2.Managed foundation models and inference APIs (model-as-a-service)
The next layer is model APIs that expose generic or specialized models via HTTP or gRPC endpoints: text LLMs, vision models, multi-modal, embedding APIs, and sometimes domain-specific models. Customers pay per token, per 1k images, or per unit of model usage. The provider manages model hosting, scaling, versioning, A/B testing, safety, and often some monitoring and logging.
At this tier, GPUs are abstracted into a “token” or “inference” unit. Providers still actively manage GPU fleets, but customers think in terms of model latency, throughput, and cost per token. GPU choice (H100 vs L40S vs B200) is a provider decision, often invisible or only exposed as coarse tiers (standard vs “turbo” / “premium”). Economics are more sensitive to GPU pricing than at the SaaS layer but still benefit from aggregation: high utilization, batching, and kernel-level optimization can produce meaningful arbitrage between GPU-hour input costs and token-level output pricing. Competitive pressure in inference APIs is compressing margins, but differentiated models and ecosystem lock-in still offer room for attractive returns.
3.Managed training / fine-tuning platforms (“train a model, no infra”)
This layer offers “bring your data, get a model” services. Customers upload datasets and configuration; the platform orchestrates the entire training pipeline: data preprocessing, sharding, distributed training, checkpointing, evaluation, and sometimes deployment. Examples include managed fine-tuning products, AutoML services, and dedicated training PaaS that hide cluster-level complexity.
Conceptually, this tier is training-as-a-service (TaaS). The platform decides which GPU type, cluster size, parallelism strategy, and fabric to use, possibly across multiple cloud providers. Customers pay per training job, per GPU-hour with automated scaling, or per project. The provider must understand Nvidia’s product roadmaps (A100 vs H100 vs H200 vs B200), topology (SXM vs PCIe, NVLink vs Ethernet/InfiniBand), and optimizer/parallelism choices to minimize training cost while meeting SLAs.
This tier is operationally complex and capital intensive because it must handle long-duration jobs, complex failure modes, and heavy state (checkpoints). It sits closer to raw GPU economics than inference APIs because training jobs often fully occupy clusters for days or weeks. The ability to arbitrage between cloud GPU pricing options, exploit spot capacity, and route workloads to neoclouds or hyperscalers efficiently is a key differentiator. Providers at this tier effectively “compile” customer workloads to underlying GPU markets.
4.Full ML / MLOps platforms with integrated GPU orchestration (PaaS)
These are general-purpose ML platforms (e.g., managed notebooks, pipelines, experiment tracking, feature stores) that tightly integrate GPU scheduling and orchestration. The core product is not “API access to a model” but a managed development and deployment environment. GPUs are a resource managed by the platform’s scheduler, exposed via abstractions such as “GPU pool,” “compute profile,” or “accelerator type.”
Customers typically pay for a mix of platform fees and underlying compute/storage usage. The platform may support multiple workloads: data preprocessing, training, hyperparameter tuning, batch inference, and interactive experimentation. The provider’s responsibilities include user management, security, observability, and lifecycle management, in addition to GPU provisioning. This tier straddles PaaS and IaaS; it commonly runs on top of hyperscaler GPU instances, neocloud GPU clusters, or a hybrid of both.
From a GPU-market standpoint, this layer is where many enterprises “terminate” their abstraction. They want to select GPU families and sizes, but not manage Kubernetes, Slurm, or NCCL tuning. The platform provider’s value comes from masking heterogeneity in GPU hardware and pricing across clouds and exposing a stable developer experience. Economically, margins depend on the degree of lock-in and differentiated workflow tools. GPU cost is a major line item but often passed through with markup.
5.Managed GPU clusters (Kubernetes/Ray/Slurm as-a-service)
This layer exposes GPU clusters more directly but with managed control planes and orchestration frameworks: managed Kubernetes with GPU node pools, managed Ray clusters, Slurm-as-a-service, or specialized orchestration for distributed training. Customers see nodes, pods, and jobs, and they deploy their own containers or training code. The provider operates the cluster, control plane, autoscaling, and sometimes the storage and network fabric.
At this tier, customers are responsible for their own software stack (frameworks, libraries, distributed training logic) and performance tuning but can offload cluster provisioning, lifecycle management, upgrades, and failure handling. GPU choice, topology, and interconnect details may be selectable (e.g., “H100 NVLink InfiniBand cluster”), but the platform still abstracts away low-level host management.
Economically, this layer tends to be lower-margin than model APIs or training PaaS because it is closer to raw infrastructure. Differentiation comes from quality of implementation (latency, NCCL efficiency, topology guarantees), reliability, and ease of integration with customer CI/CD. From a pricing perspective, this is usually billed per GPU-hour plus possible control-plane or support fees, with customers closer to seeing the “true” price of H100/H200/B200.
6.GPU-accelerated VM instances (IaaS VMs with attached GPUs)
Here, the main product is virtual machines with attached GPUs. The provider offers SKUs like “8× H100 80 GB” or “1× L4,” with documented vCPU, memory, and network bandwidth. Customers manage the OS, drivers, frameworks, and application stack. This is the classic hyperscaler model (EC2, Compute Engine, Azure VMs) and is also exposed by many neoclouds.
The abstraction is relatively thin: the provider virtualizes hardware and networking, offers images and basic monitoring, and enforces quotas and security isolation. Customers choose GPU type, count, and region; they manage scaling via autoscaling groups, scripts, or external orchestrators. Pricing is nearly directly indexed to GPU-hour cost, plus a premium for VM overhead and network/storage. This tier is the baseline reference for H100/H200/B200/A100 pricing comparisons and is where price competition is most visible.
From a responsibility perspective, customers are responsible for cluster-wide concerns: placement, data locality, job scheduling, checkpointing, and resilience. The provider’s main levers are price, availability, and performance guarantees. Margins depend heavily on utilization and on the provider’s ability to secure favorable GPU procurement terms.
7.Bare-metal GPU-as-a-service (dedicated GPU servers via API)
Bare-metal GPU-as-a-service offers physical servers with GPUs and no virtualization. Customers receive full control over the node (BIOS-level in some cases), installing their own OS or bringing custom images. Some providers add an API layer for provisioning and basic lifecycle actions (power on/off, PXE boot, image deploy), but there is no hypervisor.
Bare metal is attractive for high-performance workloads, customers wanting custom kernels, or those needing very predictable latency and performance. It also allows providers to avoid hypervisor overhead and simplify some aspects of capacity management. However, customers must handle everything above the bare hardware: OS hardening, clustering, storage, networking topology awareness, and distributed job management. Interconnect (NVLink, InfiniBand vs Ethernet) and node configuration (HGX vs PCIe) are often key differentiators.
Pricing is typically per GPU-hour or per-node-hour and often lower than equivalent VM offerings per unit of GPU, because less virtualization overhead is present and the service is more commoditized. For neoclouds, this tier is capital intensive and exposes them most directly to Nvidia GPU ASPs and utilization risk. Unit economics are sensitive to GPU generation pricing, system capex, and rack-level power and cooling costs.
8.GPU colocation / hosted racks (customer-owned GPUs in provider facilities)
At this level, the customer owns the GPU servers and the provider supplies data-center services: power, cooling, physical security, network cross-connects, and sometimes remote-hands operations. The provider may offer cage space, managed PDUs, and optional services like monitoring and hardware replacement, but the hardware capex and much of the operational burden reside with the customer.
This model is analogous to traditional colocation but focused on GPU-dense racks. It is attractive for entities with large, stable workloads and access to capital, who wish to avoid cloud markups and retain full control over hardware, while leveraging provider expertise in power and cooling. Sovereign deployments and AI majors increasingly use such models for part of their fleet, sometimes operated by colocation specialists or repurposed HPC data centers.
In this arrangement, Nvidia and the hardware OEMs capture most of the hardware margin; the colocation provider earns relatively stable, utility-like returns on space and power. The “service” layer around GPUs is minimal. The economics hinge on long-term contracts and high rack occupancy, not on per-GPU-hour arbitrage.
9.On-premise self-managed GPU infrastructure (customer buys and runs everything)
At the bottom of the hierarchy is fully self-managed infrastructure. The customer purchases GPUs and servers, builds or repurposes facilities, manages power and cooling, implements networking and storage, and runs their own orchestration stacks (Kubernetes, Slurm, Ray, proprietary frameworks). This includes both traditional on-premise data centers and private cloud environments.
Here, GPUs are pure capital assets on the customer balance sheet. There is no external “GPU service provider” per se; the customer is both owner and operator. The upside is maximal control over performance, security, and long-term cost of compute, particularly for predictable, high-volume workloads. The downside is high upfront capex, operational complexity, and exposure to technology obsolescence (e.g., transitions from A100 to H100 to B200 and beyond).
From a market-structure perspective, this tier competes with all higher layers on a lifecycle TCO basis. For large, steady workloads, internal GPU fleets can be cost-advantaged over public cloud or neocloud offerings at current GPU-hour pricing, but they lack elasticity and require strong internal capabilities. For small or spiky workloads, higher-level services are generally more economical.
Taken together, this hierarchy illustrates how the same Nvidia GPU products underpin multiple economic layers. At the top of the stack, GPUs are an invisible input into SaaS and model APIs, where value is captured through application outcomes and proprietary models. In the middle, GPUs are mediated by platforms and managed clusters, where provider differentiation relies on orchestration, tooling, and integration. At the bottom, GPUs are exposed directly via VMs, bare metal, or colocation, where competition tends toward price-per-GPU-hour and utilization management. Investment analysis of any player in this ecosystem requires identifying where in this hierarchy it operates, how much of the stack it controls, and how exposed it is to shifts in GPU pricing, utilization, and Nvidia’s product cadence.

2
23
5,941
22 Nov 2025
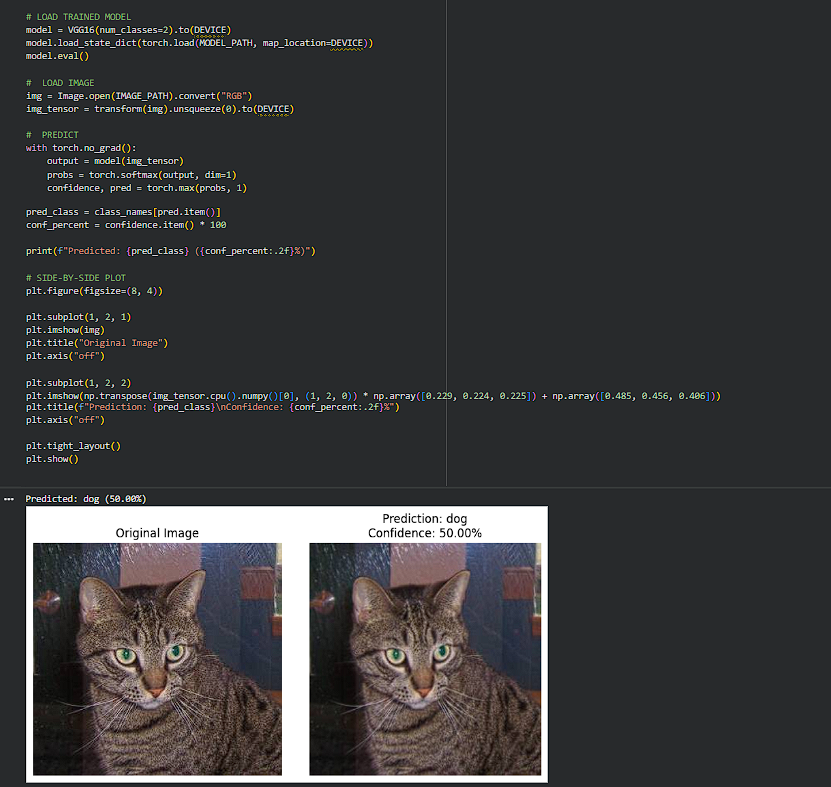
Day 188 : DataScience Journey
Conducted inference on my latest custom VGG-16 model (fully trained in the automated Colab TensorDock pipeline), and the result was… hilariously confident: it looked at a clear photo of a cat and declared, with unwavering certainty, “DOG.”

1
9
5,452
21 Nov 2025
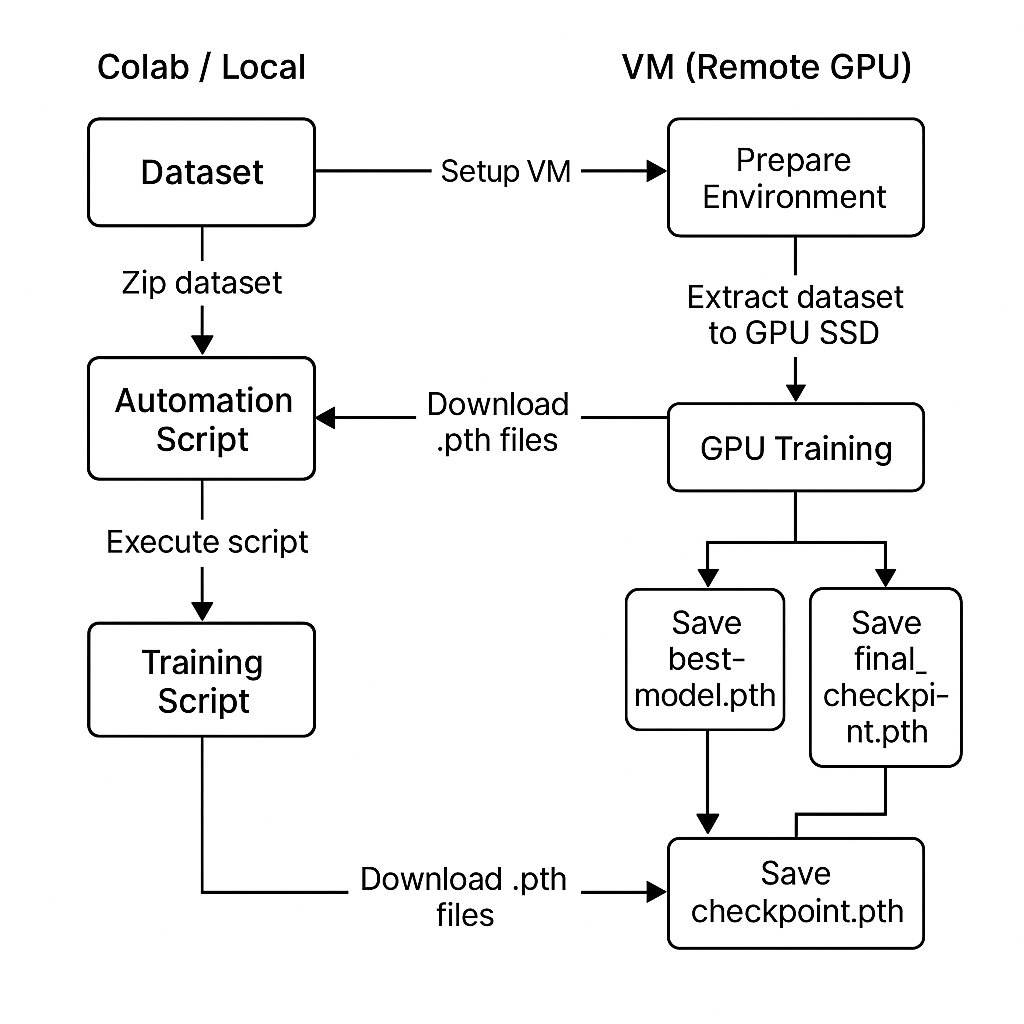
Day 187 :DataScience Journey
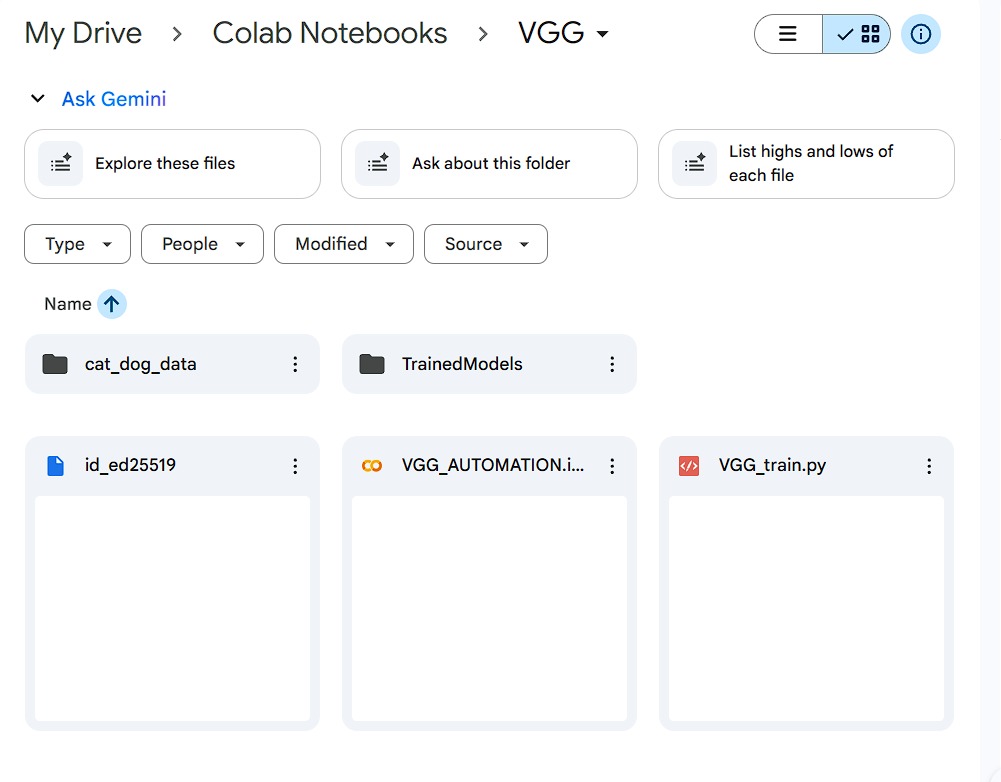
How the VGG Automation Setup Works:
The VGG automation script acts like a universal bridge between Google Colab and any rented GPU server (like TensorDock). Instead of manually uploading thousands of images, configuring Python, or starting training

1
4
533
19 Nov 2025
Day-185 DataScience Journey
After a long (and honestly painful) research dive… finally here. Today I finally got TensorDock to initialize my dataset, understand the GPU unit structure, and prep my model for training.
This might look like a tiny update, but trust me it took way

1
5
498

18 Nov 2025
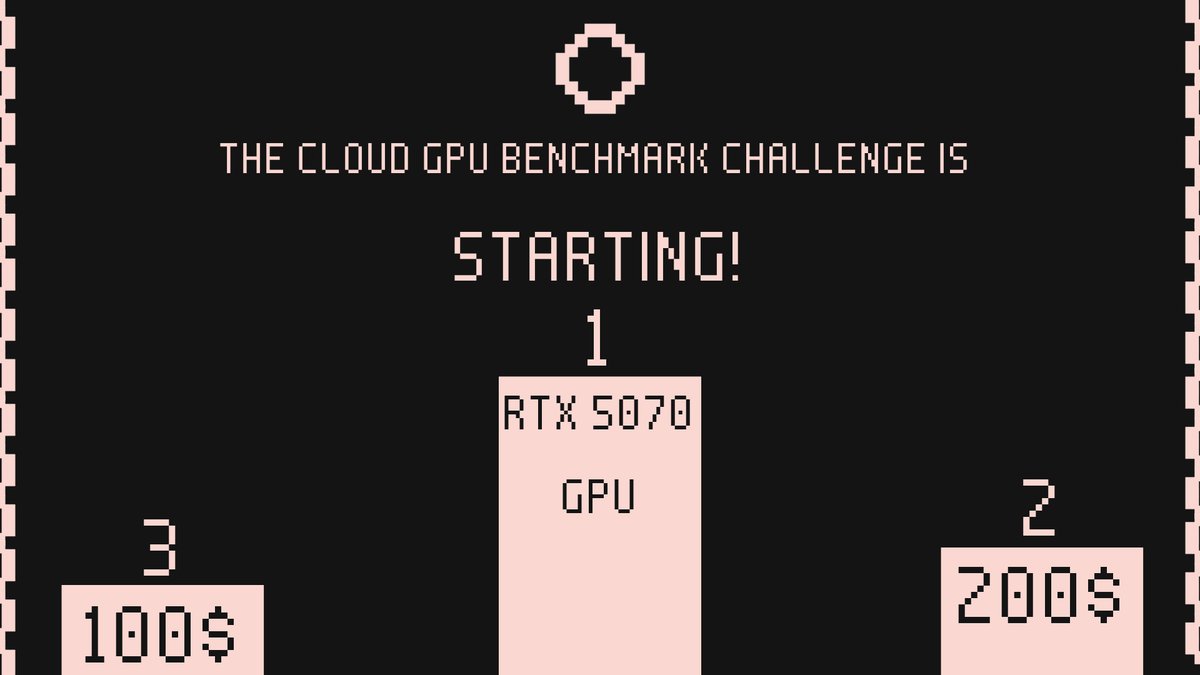
🚀 The Cloud GPU Benchmark Challenge is LIVE!
@gensynai
🏆 Prizes await:
🥇 1st Place: RTX 5070 GPU
🥈 2nd Place: $200
💜 Community Prize: $100
🗓 For the next 3 weeks, join the effort to build the industry's most comprehensive cloud GPU performance dataset.
⚙️ How it works:
1️⃣ Sign up at quok.it/gensyn
2️⃣ Rent GPUs from any cloud provider — Octa, Hyperbolic, Vast, Lambda, Nebius, RunPod, TensorDock, and more
3️⃣ Run Quok.it's CLI tool to benchmark performance
4️⃣ Watch your points accumulate automatically on your dashboard!
🎯 Scoring per unique GPU includes: health checks, microbenchmarks, network tests (for multi-GPU setups), and telemetry collection.
✨ Bonus points:
---7x multiplier for datacenter GPUs (A100, H100, H200, B200, B300)
---5 points for each new cloud provider discovered
📊 Weekly top 10 leaderboards posted every Sunday.
🔧 For more info and support, check out ︱g︱quok·it-support or the usage & installation guide.
#Web3 #Gensyn
3
59

18 Oct 2025
💳 TRIA 카드 리얼 사용 후기
@useTria #Tria 카드를 드디어 쓰게 되었네요.
저는 매달 Vultr, PrimeIntellect, TensorDock 같은 VPS에서 Aztec, Gensyn, Boundless 등 노드를 돌리다 보니
비용이 한 달에 $500~$1000까지도 나가는데요,
이번 달부터 결제를 TRIA 프리미엄 카드(6% 캐시백) 로 바꿔봤어요.
예전엔 VPS 비용 나가는 게 은근히 아깝다고 느꼈는데,
이제는 결제할 때마다 Tria 사용 점수 캐시백이 함께 쌓여서
일종의 “💰2중 파밍” 느낌이라 꽤 효율적입니다.
결제 후 캐시백 6% 즉시 반영,
실시간 내역 확인이 가능해서 완전 뿌듯!
앱의 UX, 완성도가 기대 이상으로 너무 좋아요!!
저는 바낸 월렛 --> Tria 지갑 --> 카드 충전 이렇게 했는데 거래소에서 충전까지의 흐름도 너무 깔끔하고 쉬웠어요.
노드 운영자나 VPS 자주 쓰는 분들께 강력 추천합니다.
매달 지출을 “활동 점수 리워드”로 바꿀 수 있으니까요 💪
#NEOBANK #TRIA #VPS #CryptoInfra
6
8
140

8 Oct 2025
Would any of:
* @PrimeIntellect / @vincentweisser
* @vast_ai
* @sfcompute
* @TensorDock
* @runpod
* @hyperbolic_labs
* @jarvislabsai
be interested?
I have done small model training before (github.com/seconds-0/nsa-vib…)
Thank you for your consideration!
2
61
5,569

28 Sep 2025
Pô… é uma pergunta meio idiota da minha parte… mas vc já cogitou usar outros fornecedores tipo a TensorDock? tensordock.com/cloud-gpus
2
481

14 Sep 2025
Plataformas como Salad, Vast.ai y TensorDock facilitan la conexión entre tu hardware y la demanda de potencia de cálculo para IA. ¡Convierte tu PC gaming en una fuente de ingresos pasivos! 1/2
1
3
24

4 Sep 2025
gpt-oss-120b を試す!高火力 DOK で始めるコンテナ型GPUクラウド活用 knowledge.sakura.ad.jp/46179… さくらのGPUサービスは相変わらずDockerをシングル仮想ノードで起動する貧相なレベルなのか.グローバルなGPUクラウドと雲泥の差.modal, runpod, tensordock, thunder compute, coreweaveを見てよ…
6
1,635

15 Aug 2025
I use tensordock remote servers with 4090 for 70ct/hr. The cloud is way more expensive, no?
2
2
291