
Introducing LoPT: When Tokenization Becomes the Hidden Bottleneck in LLM Inference
🌟Insights from Zhihu contributor toyama nao
In LLM inference, TTFT has long been one of the core metrics for response speed. For 32K or 128K sequences, most of the latency used to sit on the NPU/GPU side. But the Agent era changes the bottleneck: once prefix cache hit rates reach ~95%, prefill is dramatically reduced, and tokenization starts taking a much larger share of TTFT.
There are many ways to optimize tokenization, but most do not touch the root issue: BPE’s sequential dependency makes it hard to parallelize. The longer the sequence, the more expensive it gets. LoPT is the first strictly lossless parallel tokenization method. It keeps the output token-by-token identical to standard sequential tokenization, while achieving 4–5× speedup with 32 processes. 🚀
Quick terms first:
• Prefix Cache: store computed KV cache by prefix hash; when hit, skip prefill and reduce TTFT by an order of magnitude.
• TTFT: Time To First Token, including tokenization prefill first-token decode.
• BPE: Byte Pair Encoding, used by major models such as GPT, Gemini, Claude, DeepSeek, Qwen, and Kimi.
• WordPiece: used by the BERT family; encoding greedily matches the longest subword from left to right.
🧩 1. The Overlooked Bottleneck: Tokenization
In LLM inference, most people focus on GPU/NPU time: whether prefill matrix multiplication is fast, whether KV cache is efficient, or whether decode bandwidth is fully utilized. Tokenization often looks like “just a few milliseconds,” so it gets ignored.
For short contexts, that is mostly true. In a few-hundred-token chat, tokenization is tiny compared with prefill and decode. But once the input grows to 100K tokens, or even today’s 1M-token context, the story changes. With FlashAttention reducing long-context prefill cost and prefix cache skipping repeated prefixes, GPU-side prefill mainly handles only the new tokens. In long-context Agent workloads, tokenization becomes a visible part of TTFT and may even exceed the prefill cost of newly added tokens in some mid-sized model stacks.
🤖 Agent workloads make this worse because prefixes repeat heavily.
A typical Agent request contains a system prompt, tool definitions, conversation history, and tool-call records. The system prompt and tool schemas stay unchanged across dozens of tool-calling rounds, and they can be large: industrial Agent system prompts can reach 10K–20K tokens, with tool definitions adding even more.
With prefix cache, the first request computes the full KV cache and stores it. Later requests load the cached prefix directly. In well-optimized production Agent workloads, prefix cache hit rates can stay around 95%. Once 95% of tokens hit cache, prefill is no longer the only big cost. Hidden upstream work suddenly surfaces: tokenization, prompt assembly, and request routing.
Hugging Face Tokenizers, implemented in Rust, is already one of the fastest single-threaded tokenizers. But BPE/WordPiece are left-to-right algorithms, so one prompt still gets tokenized mostly on one CPU core. More cores do not help if the algorithm cannot use them. This is exactly the gap LoPT targets.
The key point: in long-context high-cache-hit scenarios, tokenization is no longer a rounding error. It becomes part of the core TTFT path, alongside prefill for new tokens.
⚠️ The obvious parallel idea has a trap.
Tokenization is CPU-heavy, so splitting long text into chunks, tokenizing them in parallel, and stitching the results together sounds natural. But there is a hidden problem: the same substring can produce different token sequences depending on its surrounding characters. If you cut the text at the wrong place, the boundary region will not match the result of full sequential tokenization. This is the classic boundary artifact.
For prefix cache, correctness is non-negotiable. If even one token ID differs from the cached prompt, the prompt hash changes, causing a cache miss and potentially invalidating the whole optimization. So the real question is: can we parallelize tokenization while producing exactly the same token sequence as sequential tokenization?
🧠 2. Why Tokenization Cannot Be Naively Parallelized
To understand LoPT, we need to understand why BPE and WordPiece resist parallelization. BPE builds tokens by greedily merging high-frequency adjacent pairs according to learned priorities. WordPiece greedily matches the longest subword from left to right. Both share the same core dependency: where the previous token ends determines where the next token begins.
That means a boundary cut is not just a string operation. It can change the tokenization context. BPE and WordPiece need to see the full context across the boundary to make the correct merge decision. Once that context is broken, the output can diverge.
🪓 3. Existing Methods and Their Fatal Flaws
The first common approach is delimiter-based splitting: cut at "natural" boundaries such as punctuation or spaces, hoping they are also token boundaries. But BPE does not respect human-looking separators. Spaces often merge with the following word. In Qwen’s tokenizer, for example, a token like "the" can include the leading space. Cutting at the space still breaks the token. In experiments, delimiter-based methods achieved only 25%–81% accuracy on BPE tokenizers, which is far from usable in correctness-sensitive systems.
The second approach is overlap-based splitting token ID matching. Adjacent chunks share an overlap region, each chunk is tokenized separately, and the merge point is found by matching identical token IDs in the overlap. This improves accuracy to around 80%–95%, but has a critical flaw: same token ID does not mean same original text position.
A token like "tion" can appear multiple times in the same overlap. Matching only token IDs tells you “what it is,” but not where it came from. In prefix-cache infrastructure, this is fatal. One wrong token is enough to change the prompt hash. The insight here is simple but important: tokenization is fundamentally a mapping between characters and positions. ID alone is not enough.
🔑 4. LoPT’s Two Key Innovations
The first innovation is character-position-aware matching. When LoPT tokenizes each chunk, it records not only the token ID, but also the token’s start and end character positions in the original text. During merging, two tokens match only if both conditions are true:
• Token ID is identical
• Global character position is identical
This removes ambiguity. The same token ID may appear many times, but a character position in the original text is unique. LoPT is not matching “the same token ID”; it is matching the token’s true identity in the source text.
The second innovation is dynamic chunk sizing. If the overlap is too short, there may be no reliable matched token. If the overlap is too long, repeated computation becomes expensive. LoPT starts with an initial chunk size and fixed overlap length, tokenizes in parallel, then checks whether each adjacent chunk pair has at least two position-matched tokens in the overlap. If a pair fails, LoPT doubles the chunk size and tries again. Doubling the chunk size changes where the cuts land, often avoiding problematic boundary regions.
The full LoPT workflow is:🧩
1. Split the long text into overlapping chunks
2. Tokenize chunks in parallel with a multi-process pool
3. Output token IDs character positions
4. Merge chunks using position-aware matching
5. If matching fails, double chunk size and retry
6. Output a token sequence that is exactly identical to sequential tokenization
✅ 5. Why LoPT Is Lossless
The paper gives a theoretical guarantee: if each neighboring chunk pair has position-matched tokens in the overlap, LoPT’s merged output is exactly the same as tokenizing the full text sequentially.
The intuition is: if the overlap is longer than the longest subword in the vocabulary, no single token can span the entire overlap. Therefore, there must be a clean cut point inside the overlap where the left and right tokenization results no longer interfere with each other.
The proof uses contradiction and infinite descent. It assumes the shortest counterexample exists, then examines where the first token could fall: fully in the left or right segment, inside the overlap, across one boundary, or across the entire region. All cases lead to contradictions. For BPE, the proof follows a similar structure, replacing text length with merge steps.
The important takeaway is not “LoPT worked in experiments.” It is stronger: LoPT is designed to be impossible to get wrong under its matching condition. For prefix cache, that distinction matters. A probabilistic guarantee is not enough. 99% accuracy still means production failures.
📊 6. Experimental Results
The experiments used a 112-core CPU at 3.8GHz, 32 processes, and batch size = 1, across three long-text datasets: LongBenchV2, LEval, and ClongEval, with six mainstream tokenizers including Qwen3, DeepSeek-V3, Llama-3.1, GPT-OSS-120B, and BERT variants.
Across all tokenizers and datasets, LoPT achieved 100% accuracy. Speedups were typically 3.6×–5.8×. For example:
• Qwen3: up to 5.3×
• DeepSeek-V3: up to 5.8×
• Llama-3.1: up to 4.9×
• GPT-OSS-120B: up to 4.6×
• BERT variants: up to 5.4×
Compared with existing methods:
• Delimiter-based: BPE accuracy around 0.25–0.81
• Overlap-based: around 0.80–0.95
• Improved overlap: around 0.98–1.00
• LoPT: 1.00 across all cases
That difference between 98% and 100% is not cosmetic. In prefix cache, 98% accuracy means roughly 1 in 50 requests may produce a mismatched token sequence, causing prompt hash changes, cache misses, higher TTFT, and higher cost. In this setting, correctness is binary: not 100% means not production-ready.
The ablation studies also show several practical findings:
• Longer sequences benefit more: at 128K tokens, Hugging Face TokenizerFast is around 500ms, while LoPT is around 110ms, a 4–5× gap.
• Chunk size has an optimal range: roughly 2K–4K characters, where chunk count aligns well with process pool size.
• Batch size = 1 benefits the most: common in long-context inference, where LoPT can beat sample-level multiprocessing because it parallelizes inside a single sample.
• More processes are not always better: around 32–48 processes is optimal in the tested setup; beyond that, scheduling overhead eats into gains.
• Weaker CPUs benefit even more: LoPT can reach 6–8× speedup on lower-end CPUs, making it useful for edge and resource-constrained deployments.
🧠 7. Final Thought
In the Agent era, token consumption is growing fast, and the way tokens are consumed is changing just as quickly. The core logic of LLM inference is shifting. The technologies may look familiar, but the bottlenecks are moving.
Tokenization is just one example. LoPT shows that an overlooked bottleneck can still have a clean, rigorous, and practical solution if we look closely enough. More such bottlenecks will appear as Agent systems scale. The key is to anticipate early, analyze deeply, and rethink the pipeline before the bottleneck becomes obvious.
🔗Original article:zhuanlan.zhihu.com/p/2048050…
Paper: arxiv.org/abs/2511.04952
Conference: ACL 2026 Main Conference
Authors: Wei Shao, Lingchao Zheng, Pengyu Wang, Peizhen Zheng, Jun Li, Yuwei Fan
#LoPT #Tokenization #LLMInference #AgentAI #PrefixCache #BPE #LLM #AIInfrastructure #MachineLearning #ACL2026
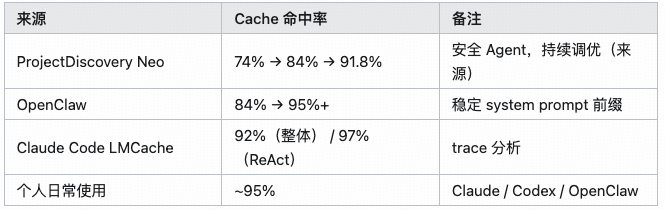



56



[13/25] 📄 arXiv cs.CL
Equity with Efficiency: An Empirical Study of Tokenizers for Multilingual Large Language Models
arxiv.org/abs/2606.15044
1
1


I asked Grok, "Why don't AI companies include token meters on their models? They would be great to see in chat windows."
Response:
**Yeah, it's a fair question.** A live token meter (or at least a context usage bar) in the chat window *does* sound useful—especially once conversations get long and you start worrying about hitting limits or wasting money on bloated history.
### Why most AI companies don't show it
Here are the main reasons they generally skip it in consumer chat interfaces (ChatGPT, Claude web, Grok, Gemini, etc.):
1. **It confuses normal users**
The average person just wants to chat. "Tokens" is a backend technical concept. Showing a running counter would prompt a flood of "what is this number?" support tickets and make the interface feel more intimidating. Companies optimize for the mass audience first.
2. **It makes costs painfully visible**
Token usage = real money (for the company *and* for users on paid plans). A visible meter turns every response into "the meter is running." That can make people self-conscious, shorten their prompts, complain more, or switch models. It's bad for engagement metrics and support load. Hiding it keeps the experience feeling "unlimited" until you actually hit a hard limit.
3. **It's surprisingly hard to show accurately in real time**
- Responses stream token-by-token.
- Every new message re-sends the entire conversation history system prompt any tools/memory.
- Different models use different tokenizers.
- Advanced features (tools, vision, caching, agent scaffolding) add hidden token overhead that isn't obvious.
Displaying an exact live number without glitches or "why did this jump?" moments is more engineering work than it looks.
4. **Token count is often a bad/misleading metric anyway**
A lot of people in the industry (including on LinkedIn and dev forums) argue that raw token usage is a dumb proxy for "how much value you're getting." Long rambling responses, unnecessary tool calls, or poorly managed context can inflate the number without improving results. Many companies would rather not spotlight a number that doesn't actually correlate well with user satisfaction.
### Where it *does* appear
- **Developer tools** love it. Claude Code has explicit `/context` and status line displays showing exactly what's eating tokens (system prompt, tools, messages, etc.). Cursor and various coding agents show detailed breakdowns because devs *need* to manage this.
- API responses almost always include usage stats.
- Google AI Studio used to show token counts but removed the feature (users complained).
- Third-party extensions and dashboards exist to bolt counters onto ChatGPT/Claude.
### What would actually be useful
A raw token number isn't the best UI choice. A simple **context usage percentage bar** ("Conversation is using 42% of available context") would be way more actionable for most people. It tells you when to start a new chat or summarize history without exposing the nerdy details.
Some advanced interfaces are moving in that direction (or adding smart compaction/summarization so you don't have to babysit the meter yourself).
Would you actually want a visible meter here in our chats, or would a "context is getting full" warning when it matters be more practical? I'm curious what your use case is.
1
1
67

Updated the benchmark to get more accurate results for RAIF. Used multiple tokenizers, multiple corpuses of the test data and got the most life-like results.
It was a challenge to gather a dataset that's weighted in a right way, so the report is concentrated to give a metric for each group of JSON separately.
I've used a dataset of 10k real payloads and got the results that are better than minified JSON on 10% with 11% as a median.
Checkout the full report here: github.com/skrrt-sh/raif-sta…
33

What is the unit supposed to be for "1.6 T"? Is that 1.6 TeraHertz or is it a transition at a magnetic field of 1.6 Tesla? For the Internet Foundation, I recommend that all units be kept in exact codes, new to the user terms be written in full, and each user able to set their own defaults. Most of the abbreviations on the Internet do not tokenize well with the shallow tokenizers that LLMs force on everyone.
Standards groups all rely on humans memorizing things. And reaching individuals hidden inside organizations, individuals responsible for implementing standards from scratch in isolation.
x.com/i/grok/share/2e0af43d0…
71

The demand for Open-Source models and Sovereign AI will surge from here.
Impressed with Sarvam's unique ideas and work such as
> Sarvam built its tokenizers from scratch, eliminating this linguistic tax, making localized AI economically viable for Indian enterprises.
> Sarvam prioritizes voice models. They view AI as an inclusion tool that bypasses traditional literacy barriers.
Congratulations to the @SarvamAI Team...

Sarvam becomes India’s newest AI unicorn with $234 million funding round led by HCLTech techcrunch.com/2026/06/15/sa…
2
130

I believe that current tokenizers will go the way of the bitter lesson, but this was a good article nonetheless.

2
71


they don't see it in the way we do because they don't see words, but tokens. "iff" creates a strong enough semantic meaning (and i'm sure at least some tokenizers treat it as a single token) that it will be clear to the LLM
15

Osama Rakan Al Mraikhat retweeted

2 Nov 2025
Check out our paper, “R-BPE: Improving BPE-Tokenizers with Token Reuse” 🔠♻️, which was accepted to the EMNLP 2025 main conference, taking place in Suzhou, China 🇨🇳.
📍November 6th from 10:30 to 12:00 at Hall C.
@nhamdanai
Links below.
#EMNLP #EMNLP2025
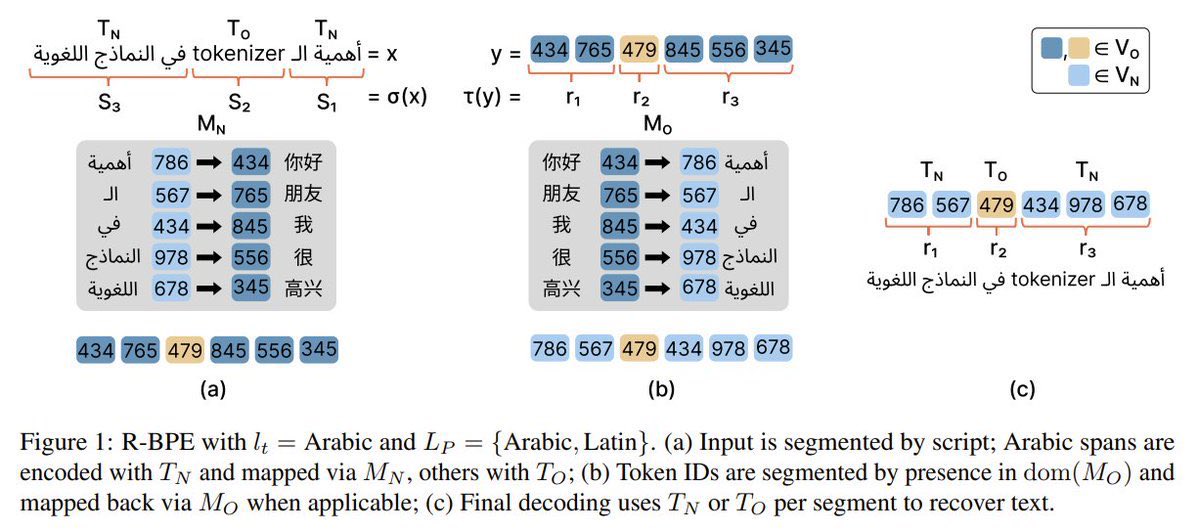
1
3
11
12,879

When you're evaluating two LLMs with different vocabularies (tokenizers), generally the normal Cross Entropy Loss can be misleading and hence comparing the BPB is more useful and correct.
Checkout my recent writeup on how BPB works under the hood with some context on Information Theory:
baba-devv.github.io/2026/06/…
1
11

Jun 14
HYDRA-X: Native Unified Multimodal Models with Holistic Visual Tokenizers
huggingface.co/papers/2606.1…
16

Jun 14
I wonder how using multiple tokenizers would affect training and results. We know that different languages are more effecient with diffrent languages. Probably harder to train but it would give more broad representation.
64

Jun 14
`rust-agent-driver`, `rust-agent-inference`, and `rust-agent-trajectory`. Chroma's agent tooling is moving to compiled code - same pattern as Transformers' Rust tokenizers. Watch for these to merge.
1
10

Jun 14
This particular approach is called 𝗕𝘆𝘁𝗲 𝗣𝗮𝗶𝗿 𝗘𝗻𝗰𝗼𝗱𝗶𝗻𝗴, or 𝗕𝗣𝗘. Other approaches like 𝗪𝗼𝗿𝗱𝗣𝗶𝗲𝗰𝗲 and 𝗦𝗲𝗻𝘁𝗲𝗻𝗰𝗲 𝗣𝗶𝗲𝗰𝗲-𝗯𝗮𝘀𝗲𝗱 𝘁𝗼𝗸𝗲𝗻𝗶𝘇𝗲𝗿𝘀 follow a similar idea of breaking text into units, though their exact algorithms differ🧵
1
8