
Ran my first vLLM benchmark loop on RTX 5070 Ti with Qwen2.5-0.5B.
16 requests per run, 128/64 configured token lengths, concurrency 1/2/4.
Output throughput:
- c1: 438 tok/s
- c2: 783 tok/s
- c4: 1526 tok/s
E2E p95 stayed under 171 ms in this tiny test.
#vLLM #LLMInference #MLOps #AIInfrastructure
21

Jun 11
The Printing Press of AI: @Google's DiffusionGemma Rules the Local Computing Frontier
aitech365.com/computing/the-…
#AITech365 #Computing #DataPrivacyCloud #DiffusionGemma #Google #LLMinference #LLMs #LocalComputing #news #SpeedImplementing
16

Jun 9
For Llama 3 70B, AMD claims 1,200 tokens/sec using ROCm 6.0 and the vLLM inference engine. But that number runs head-first into real-world gotchas. Anyone weighing a 2026 hardware buy for local LLM inference should see the tokens/sec, power draw, and cost math plotted side by side. sesamedisk.com/llm-inference…
#GPUvsASIC #LocalAI #LLMInference
1
31

LLM Inference Prices Plummet 600-Fold, Driven by Software Innovation
[LLMS]
LLM token prices fell 600x, software drives decline.
Why it matters: The dramatic decline in LLM inference costs, primarily due to software and architectural advancements, is democratizing access to AI capabilities. This shift intensifies market competition and redefines the value proposition of different LLM tiers, making advanced AI more economically viable for a broader range of applications.
Follow DailyAIWire for the full brief.
🤔 How will the diverging price trends between economy and flagship LLMs reshape the competitive landscape for AI service providers and end-users?
#LLMInference #AIEconomics #SoftwareInnovation #PriceDecline #AICompetition
1
19

5,907.27 tok/s on one Tesla T4. The winner of Bear the Tokens: Ratan Kokal. An aerospace undergrad at IIT Bombay.
Baseline was 3,332. Faster inference on the same GPU means more requests per dollar.
He got past it with serving-engine changes and one observation most people will miss.
Dhruv used an inferencing plugin. Aaditya applied AWQ quantization.
#h2loopai #LLMInference #GPUOptimization #Quantization

1
3
23

May 28
🎙️Tensormesh: From Research to $20M Round
Our CEO & Co-Founder @JunchenJiang sat down with TechBeats pod to talk KV cache, the "Big Data of AI," and how Tensormesh became the first caching-accelerated inference platform for enterprises across the GPU ecosystem.
Watch Full interview👇
youtu.be/kNoVF1p5xTA
#LLMInference #KVCache #AIInfrastructure
2
7
19
1,321

May 27
🎉 I am proud to announce that @tensormesh is receiving new funding from @AMD Ventures, CoreWeave, NVentures (@nvidia's venture capital arm), Valley Capital Partners, and Laude Ventures, among others, bringing our total funding to $24.5M.
We have also launched Tensormesh Inference into general availability.
When we started Tensormesh, we saw a problem that was only going to become more urgent. As AI applications move into production, inference costs become a limiting factor. Teams are building more complex applications, longer-context workflows, and multi-step agents, but too much of that work is still recomputed from scratch every time.
Tensormesh Inference helps teams reuse computed KV cache state so they can reduce redundant computation, improve latency, and lower API costs by up to 10x.
We’re also making cached input tokens $0 across Tensormesh serverless deployments, so teams only pay when input tokens need to be processed, not when they can be served from cache.
This milestone is the result of years of systems research, open-source work through LMCache, and deep collaboration with customers building real AI applications.
Thank you to our team, investors, customers, advisors, and open-source community for helping us get here.
We’re just getting started.
Read the full announcement: tensormesh.ai/blog-posts/ten…
#kvcache, #lmcache, #tensormesh, #llminference

5
2
69
11,416
May 19
𝗛𝗼𝘄 𝗱𝗼 𝘆𝗼𝘂 𝗯𝗿𝗶𝗱𝗴𝗲 𝗿𝗲𝘀𝗲𝗮𝗿𝗰𝗵 𝗮𝗻𝗱 𝗽𝗿𝗼𝗱𝘂𝗰𝘁?
In this clip, CTO 𝗬𝗶𝗵𝘂𝗮 𝗖𝗵𝗲𝗻𝗴 and Chief Scientist @this_will_echo discuss why resilient AI infrastructure requires tight collaboration between research and product teams from day one.
🎥 Full interview:
👉 lnkd.in/gk4e7bJS
#LLMInference #AIInfrastructure #InsideTensormesh
1
4
321

May 9
LLM KV Cache Showdown: DeepSeek Takes Absolute Lead
Insights from Zhihu contributor 苏迟但到
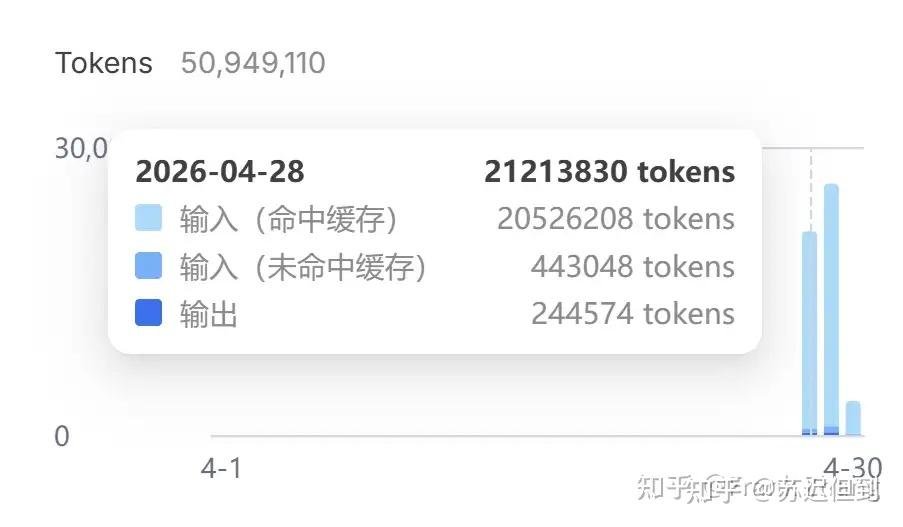
After running 20,000 controlled LLM inference experiments 🧪 over 3 straight days, I’ve fully uncovered how groundbreaking DeepSeek’s KV Cache optimization really is.
Many users are sharing call logs after DeepSeek V4 release — its exceptional cache hit rate drastically cuts token & inference costs 💰.
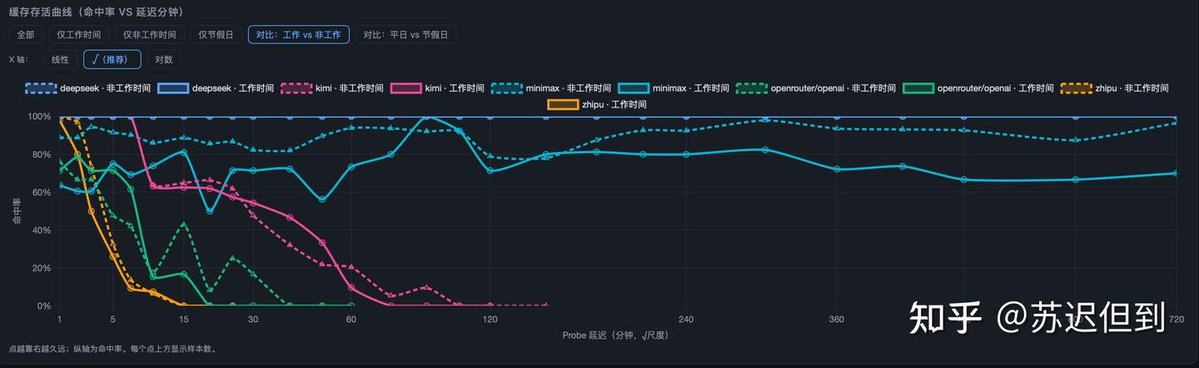
KV Cache hit rate isn’t luck: it can be quantified by repeating identical prompts at variable time intervals and parsing backend cache match signals.System load always brings random cache TTL volatility, so small-scale tests are meaningless. That’s why I built a dedicated server for strict benchmarking:5 models tested: DeepSeek, Kimi, Zhipu, MiniMax, OpenAI(OpenRouter)Periodic batch requests 1min ~ 720min recall window to record real KV Cache retention & hit ratio.
📊 Core Technical Benchmark Findings✅ DeepSeek100% KV Cache hit rate consistently across peak/off-peak hours.Cache state still fully retained after 12 hours — industry-leading persistent cache scheduling & eviction strategy.
🥈 MiniMax90% hit rate in off-peak time, drops to ~70% under high traffic.Abnormal early cache miss within the first minute, implying flawed internal cache indexing & lookup logic.
📉 Tier order afterward: Kimi > OpenAI > GLM
❌ GLM terrible KV Cache performance2min: 80% hit rate3min: 50% hit rate5min: only 25% hit rateHardly any cache survives beyond 15 minutes.
🔬 Technical Root Cause Analysis for GLM
• Infra architecture defect: Unable to offload KV Cache to low-cost disk storage, strictly limited to on-board VRAM. Small cache pool forces aggressive LRU eviction.
• Extreme traffic throughput far exceeds cache bearing capacity, accelerating invalidation of historical KV sequences.
⚠️ Key Industry Insider Notes
• OpenAI metrics are probed via OpenRouter relay, not native official KV Cache performance.
• Qwen / Seed / Mimo adopt no automatic KV Cache mechanism — require manual cache initialization and additional charging. No natural TTL retention, leading to hidden redundant inference costs for regular users.
#AI #LLM #DeepSeek #LLMInference #AIEngineering #Tech
🔗Full article:
zhuanlan.zhihu.com/p/2035737…
2
20
107
33,407

Most teams scale inference by adding more GPUs. Smart teams think about how tokens flow. 😎
Introducing fastokens — Crusoe's open-source Rust tokenizer, built with NVIDIA Dynamo, now merged into SGLang.
Up to 50% faster TTFT for agentic workloads, measured on real production traffic!
Tested on the latest DeepSeek, Qwen, Kimi, MiniMax, NVIDIA Nemotron models, and more.
➡️ github.com/crusoecloud/fasto…
@lmsysorg #LLMInference #OpenSource #TTFT

3
3
35
13,088

Apr 28
Who says you need a data center for massive models? 💻 Weiyu Xie joins #GOSIMParis2026 to reveal how KTransformers enables full-precision inference for 600B MoE models right on consumer hardware.
📅 May 5–6 | Station F | paris2026.gosim.org/
👉Chance to apply for your limited free ticket via Luma: luma.com/fmi2hnwy
#GOSIMParis2026 #KTransformers #MoE #LLMInference #OpenSource

1
1
2
95
Apr 28
🎙️𝗜𝗻𝘀𝗶𝗱𝗲 𝗧𝗲𝗻𝘀𝗼𝗿𝗺𝗲𝘀𝗵: Meet the brains behind @lmcache
We sat down with our CTO, 𝗬𝗶𝗵𝘂𝗮 𝗖𝗵𝗲𝗻𝗴 and Chief Scientist, 𝗞𝘂𝗻𝘁𝗮𝗶 𝗗𝘂 to discuss the journey from @lmcache research to powering the next layer of inference at scale with @tensormesh .
They explain the motivation behind their journey: the real-world constraints, design decisions, and what shaped their framework to tackle one of the hardest bottleneck in modern inference: "𝗞𝗩 𝗰𝗮𝗰𝗵𝗲" .
Watch the Full interview: y2u.be/tud54kSDr5s
#LLMInference #KVCache #Tensormesh @this_will_echo
5
13
699

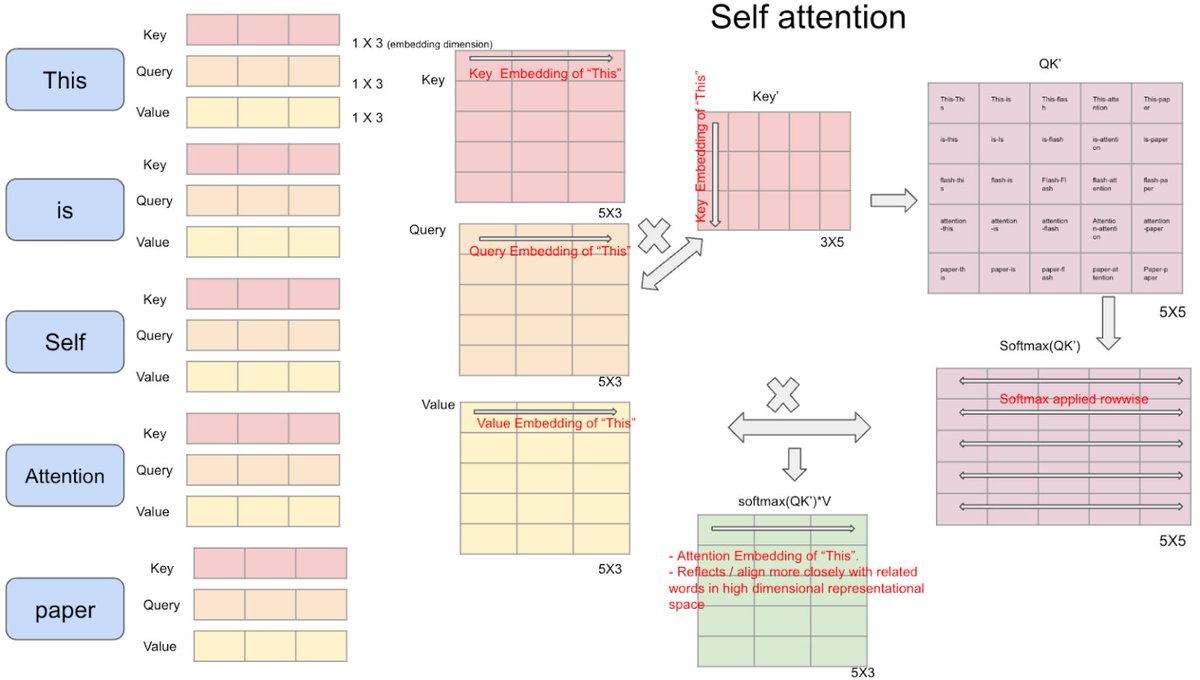
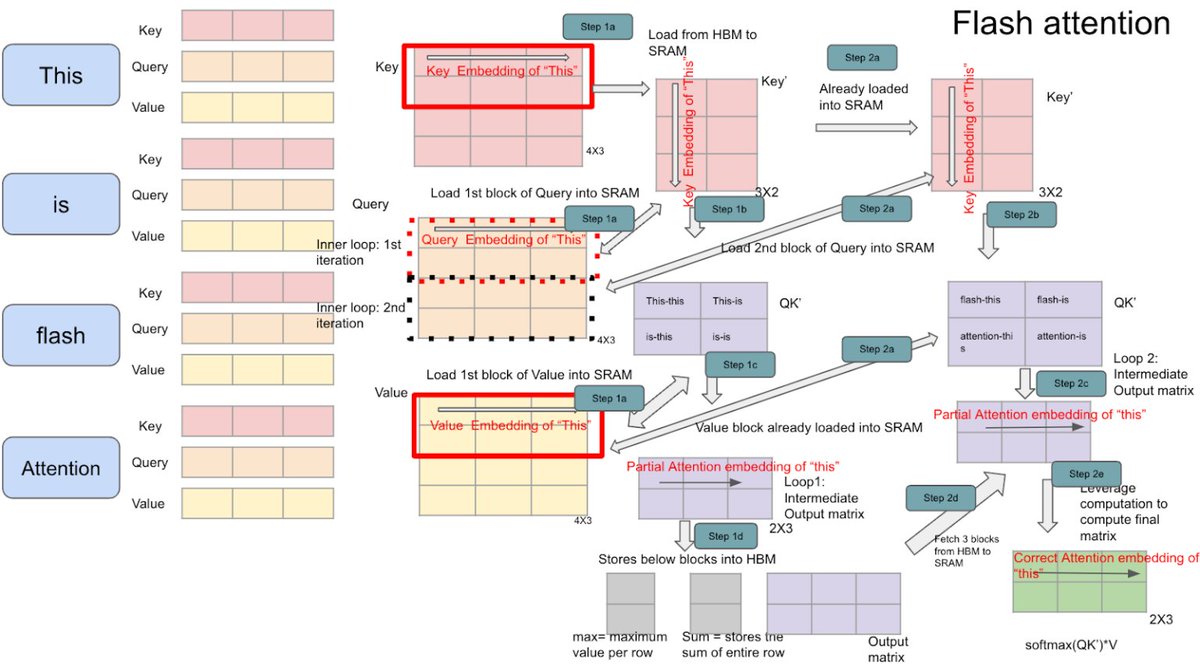
Day 11/365 of LLM Inference
Today's focus: Flash Attention - how we made the attention operation itself faster
Lastly we covered Prefill Decode Disaggregation. Today is about the algorithmic breakthrough that changed how attention is computed at its core.
The problem with standard attention:
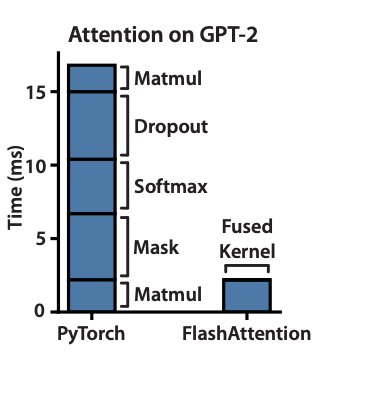
Attention is the most expensive operation in a transformer. The standard implementation computes the full NxN attention matrix where N is sequence length. At 8192 tokens that is 67 million entries written to GPU HBM memory and read back again.
The problem is not compute. It is memory bandwidth.
Writing and reading that massive attention matrix to and from HBM is brutally slow. As sequence length grows the memory cost grows quadratically. Standard attention does not scale.
What Flash Attention does:
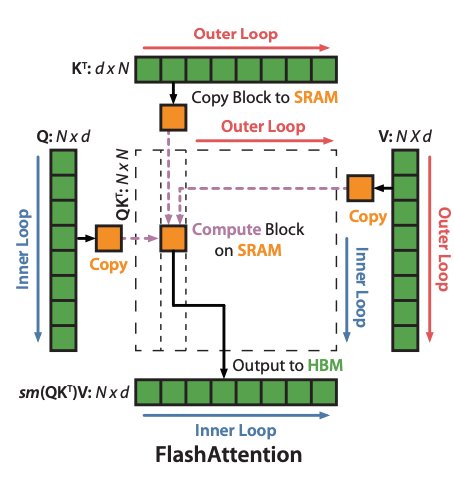
Flash Attention never materialises the full NxN attention matrix in HBM at all.
Instead it tiles the computation into small blocks that fit entirely inside SRAM, the fast on-chip memory sitting directly on the GPU. Each block is loaded once, the attention computation happens entirely in SRAM, and only the final output is written back to HBM.
Same mathematical result. Dramatically fewer memory round trips.
The numbers:
→ Flash Attention reduces HBM memory reads and writes by 5x to 20x depending on sequence length
→ End to end attention is 2x to 4x faster than standard PyTorch attention
→ Memory usage scales linearly with sequence length instead of quadratically
→ Longer contexts become viable without running out of GPU memory
Flash Attention 2 and 3
Flash Attention 2 improved parallelism across attention heads and reduced unnecessary computation, pushing throughput higher again.
Flash Attention 3 released in 2024 is optimised specifically for H100s, exploiting the H100 warpgroup level MMA instructions and async memory pipelines to push utilisation above 75% on H100 hardware.
Why this is everywhere today:
→ vLLM uses Flash Attention as default attention backend
→ HuggingFace Transformers ships with Flash Attention 2 support
→ Every serious inference framework has adopted it
→ Enabled long context windows that simply were not feasible before
Without Flash Attention, 128k context windows would not exist in production today. It is not an optimisation on top of transformers. It is a fundamental part of how modern LLMs run.
Day 12 tomorrow: Chunked Prefill and how we handle very long prompts without stalling your decode queue ⚡
#LLMInference #FlashAttention #MachineLearning #GenAI #GPU #LLM #AIEngineering #MLOps #vLLM #Transformers #LongContext

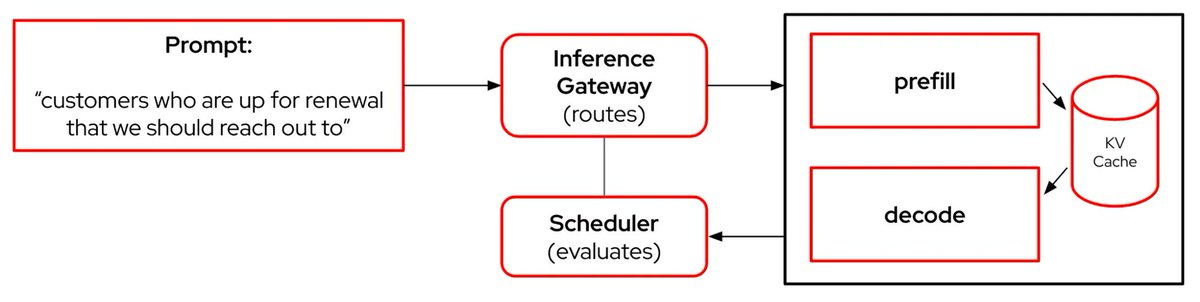
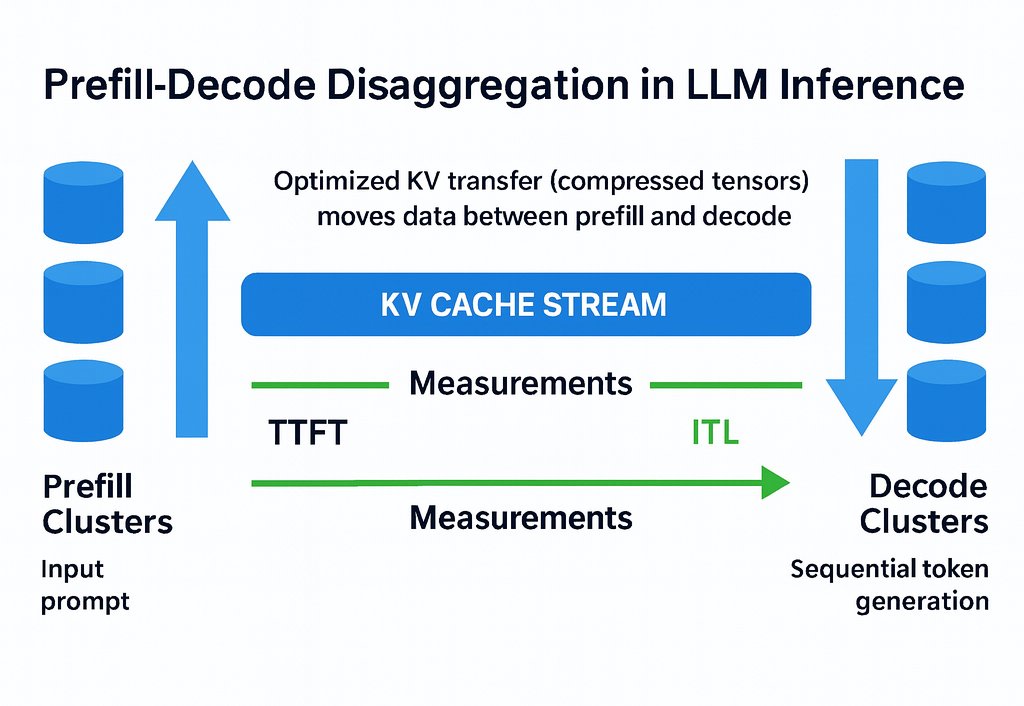
Day 10/365 of LLM Inference
Today's focus: Prefill and Decode Disaggregation - why the best inference systems separate them completely
Yesterday we covered Pipeline Parallelism. Today is about one of the most important architectural shifts happening in production LLM serving right now.
Quick recap of the problem:
Back on Day 2 we established that inference has two phases. Prefill is compute-bound. Decode is memory-bandwidth-bound. They have completely different resource profiles and completely different bottlenecks.
So why do we run them on the same GPU?
How traditional inference servers handle this:
In most inference servers today prefill and decode happen on the same set of GPUs interleaved together. A decode request and a prefill request compete for the same GPU resources at the same time.
This creates a fundamental conflict. Long prefill requests stall ongoing decode requests. Latency spikes. Time to first token suffers. The GPU is never fully optimised for either workload.
What disaggregation does:
Separate the two phases onto dedicated hardware entirely.
Prefill nodes handle only prompt processing. They are optimised for raw compute throughput. High tensor parallelism, large batch prefill, maximise FLOPS utilisation.
Decode nodes handle only token generation. They are optimised for memory bandwidth. Efficient KV Cache management, continuous batching, minimise memory bottlenecks.
Each pool of GPUs is tuned independently for exactly one job.
Why this matters at scale:
→ Time to first token drops dramatically on prefill nodes
→ Decode throughput improves because it is never interrupted by prefill
→ You can scale prefill and decode capacity independently based on actual load
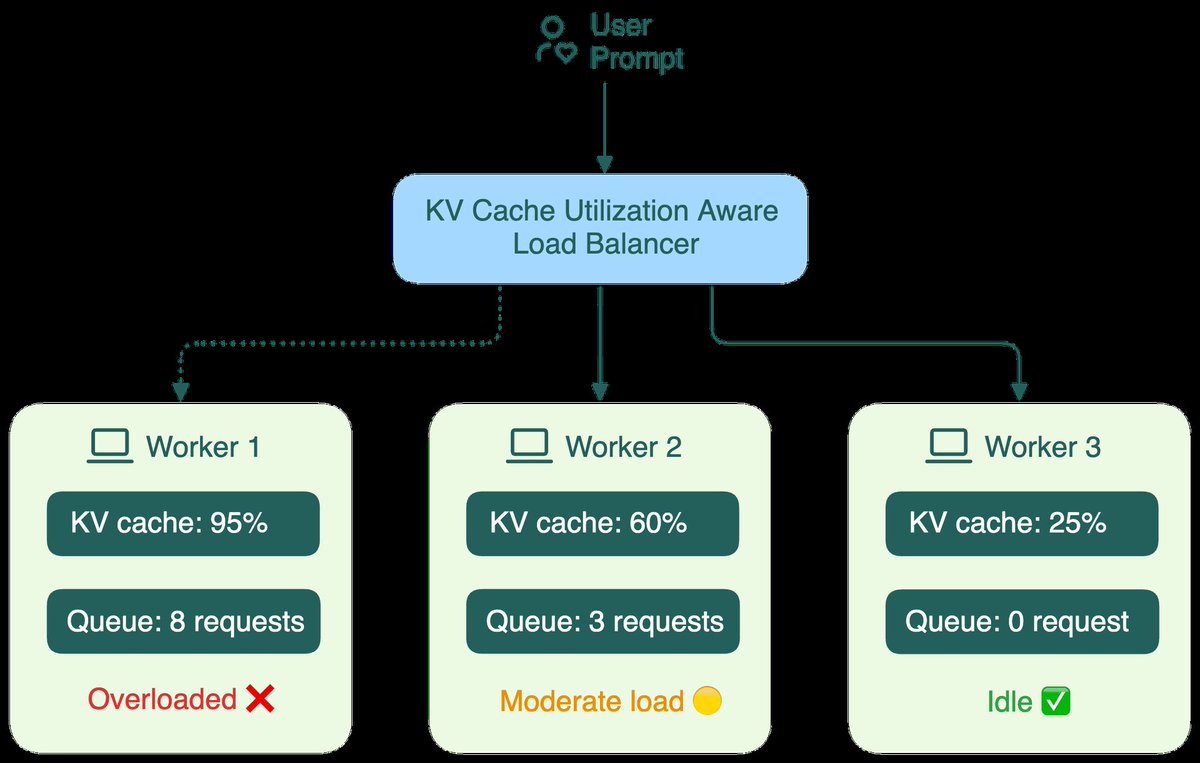
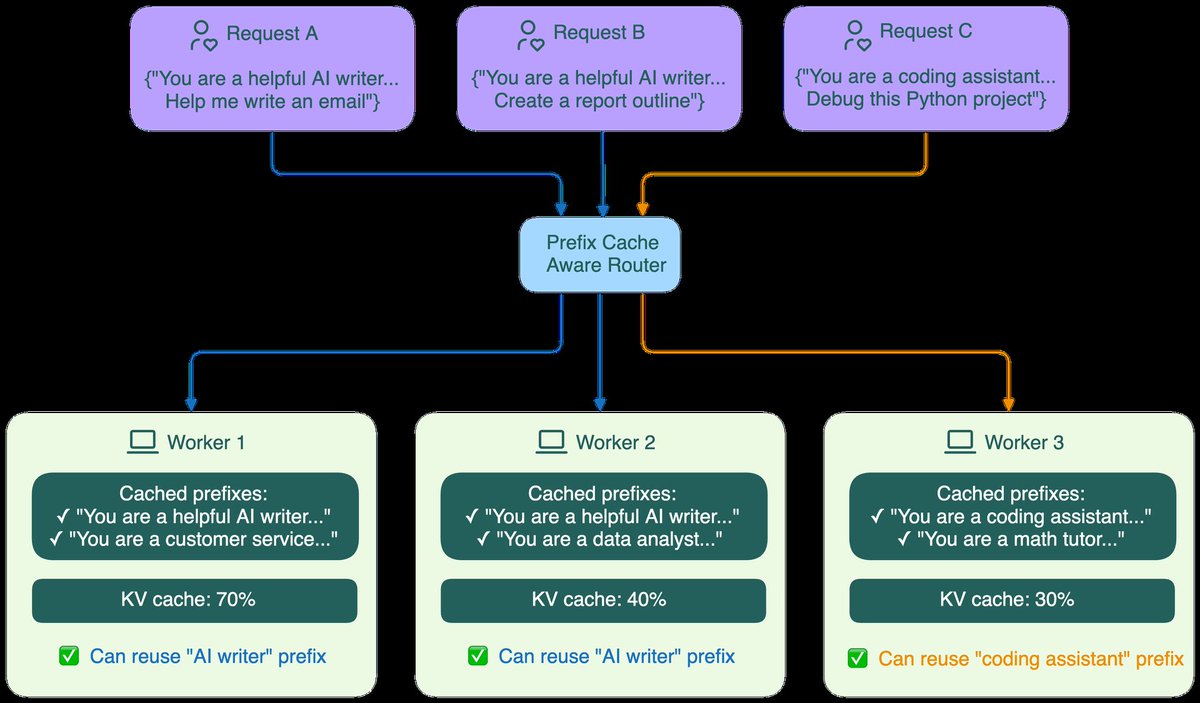
→ KV Cache can be transferred between nodes allowing smarter memory management across the cluster
Who is shipping this today:
This is not theoretical. Disaggregated prefill and decode is already in production.
→ Deepseek built their entire serving infrastructure around this model
→ NVIDIA TensorRT-LLM added disaggregated serving support
→ vLLM has active development on prefill decode disaggregation right now
→ Microsoft Splitwise paper formalised the architecture in 2024
The tradeoffs
→ KV Cache transfer between prefill and decode nodes adds network overhead
→ Cluster orchestration becomes significantly more complex
→ Requires careful load balancing to avoid prefill nodes becoming a bottleneck
→ Not worth the complexity at small scale, this is a large fleet problem
Most teams running fewer than 8 GPUs do not need this. But if you are operating inference at scale and your time to first token is hurting, disaggregation is where the industry is heading and fast.
Day 11 tomorrow: Flash Attention and how we made the attention operation itself faster 🔦
#LLMInference #PrefillDecodeDisaggregation #MachineLearning #GenAI #GPU #LLM #AIEngineering #MLOps #vLLM #Splitwise #DeepSeek
1
1
1
102
Apr 22
SGLang Workshop is officially live! ✨
Build faster, more efficient LLM & multimodal serving with RadixAttention & structured generation.
Hands-on learning for every AI builder & engineer.
📝Read more details: medium.com/@gosimfoundation/…
🔗Official website: paris2026.gosim.org/
🎫Chance to apply for your limited free ticket via Luma: luma.com/fmi2hnwy
#SGLang #LLMInference #AIInfra #OpenSource #GOSIM @sgl_project @lmsysorg

2
93
Apr 18
It’s been an incredibly rewarding three-year journey for me and @lmcache . So I decided to write a not-so-short blog.
Blog: blog.lmcache.ai/en/2026/04/1…
Back in Jan 2024, we were just one of thousands of research groups. In just three years, we went from doing seminal research -> open-sourcing -> fundraising (twice) -> productizing -> commercialization.
It was painful to realize that our research was overlooked simply because the real-world infrastructure was missing (and few seemed to care to build it).
It was sobering to see how easily large companies can ignore (or overshadow) us.
It was frustrating to hear the industry thought we only know CPU offloading of KV cache, even though that's less than 10% of what we do.
It was also incredibly rewarding to see so many engineers learn about @UChicagoCS through LMCache.
My friends in both academia and industry, I hope you find it fun and inspiring.
#LMCache, #KVCache, #LLMInference
1
7
45
1,948

I ran Gemma 3 4B without PyTorch, without CUDA — just flat binary files 600 lines of Rust.
Paris #1. Jupiter #1. Ulm #1. Exact HF match.
CPU or Vulkan GPU. Any vendor. No framework.
Built on @chrishayuk's LarQL decomposition.
github.com/cronos3k/vindex-i…
#DeepLearning #GPU #MLOps #AIEngineering #RustLang #HuggingFace #Gemma #WebGPU
#CrossPlatform #EdgeAI #OpenAI #LLMInference #FOSS #IndieResearch
2
10
370

Seeking the ultimate PCIe 4.0 scalability in a motherboard? Do you hope to expand into hundreds of GBs of VRAM all under the reign of a single CPU? This board may have flown under your radar. It can accommodate up to 13x GPUs at (PCIe 4.0 x8).
Look no further than the ASRock Rack ROMED16QM3 — a single-socket SP3 server board supporting up to the 7773X (the crème de la crème of the EPYC Milan generation, 64 cores and 800MB of L3 cache) with 16x DDR4 slots for 1TB RAM and full IPMI remote management. Can you really call your local AI rig a “server” if it doesn’t have IPMI?
Unmatched GPU expandability:
→ 2x onboard PCIe 4.0 x8 slots (SLOT 6/7, SLOT 6 removed as it shared lanes with M.2s)
→ 12x low-profile SlimSAS (SFF-8654) PCIe 4.0 x8 ports
→ Max 13x GPUs at x8 PCIe 4.0 (plug every SlimSAS the single slot straight into a Gen4 riser).
→ Or pair the 12x SlimSAS into 6x x16 links 2x x8 slots for 8x GPUs at full x16 with lanes left for RAID 0 NVMe config. → Perfect for sharding massive models or configuring tens of small, dense LLMs. NVLink bridges connect 3090 pairs for additional speedups.
→ 7003X series Milan EPYCs handle nonstop tool calling and query floods from agentic harnesses
SlimSAS hardware you’ll need:
→ 12x SlimSAS SFF-8654 to SFF-8654LP (Low Profile) 8i cable - PCIe gen4
c-payne.com/products/slimsas…
→ 12x C-Payne SlimSAS PCIe gen4 Device Adapter x8/x16
c-payne.com/products/slimsas…
This board is pure local AI gold for stacking last gen GPUs without compromise.
Thank you to @alecglovertech on YouTube for making me aware of this nugget.
#LocalLLaMA #Homelab #EPYC #MultiGPU #LLMInference #SelfHostedAI




ALT PCIe 6-pin 12V power connector mandatory
5
670
Apr 8
💡 To my friends who think the industry shies away from radical re-architecting, we do the OPPOSITE, to make #LMCache more robust, performant, and evolvable!!
It's not the first time, nor will it be the last.
Join Yihua's office hour on 4/9 Thursday (TOMORROW) 11am PT to learn more.
Repo: lnkd.in/g4NjVS_t
Congrats, @ChengYihuaA and the whole team!
#lmcache, #llminference, #kvcache, #tensormesh
Apr 7

𝐉𝐨𝐢𝐧 𝐮𝐬 𝐟𝐨𝐫 𝐨𝐮𝐫 𝐀𝐩𝐫𝐢𝐥 𝐋𝐌𝐂𝐚𝐜𝐡𝐞 𝐎𝐟𝐟𝐢𝐜𝐞 𝐇𝐨𝐮𝐫 𝐭𝐡𝐢𝐬 𝐓𝐡𝐮𝐫𝐬𝐝𝐚𝐲!
@ChengYihuaA, CTO of @Tensormesh, will be sharing the 𝐧𝐞𝐰 𝐌𝐏 𝐌𝐨𝐝𝐞 𝐝𝐞𝐬𝐢𝐠𝐧 for #LMCache.
We’ll cover how this architecture handles model parallelism and KV caches, its performance, and what’s coming next on the roadmap.
Interested in learning how this new feature unlocks 𝟏𝟎𝐱 𝐟𝐚𝐬𝐭𝐞𝐫 𝐌𝐨𝐄 𝐢𝐧𝐟𝐞𝐫𝐞𝐧𝐜𝐞 to accelerate generation and reduce user latency? Come hear the latest updates, get a look at what’s ahead, and ask any questions you may have.
📅 Thursday, April 9, 2026 | 11:00 AM–12:00 PM PST
🔗 Join here: meet.google.com/ehe-fiap-mzc
#MoE #AI #inference #LMCache #KVCache #vLLM

1
2
901
Day 7/365 of LLM Inference
Today's focus: Quantization - how we shrink models without destroying them
Yesterday we covered speculative decoding. Today is about the most widely used technique to make LLMs cheaper to run in production.
The problem with full precision models:
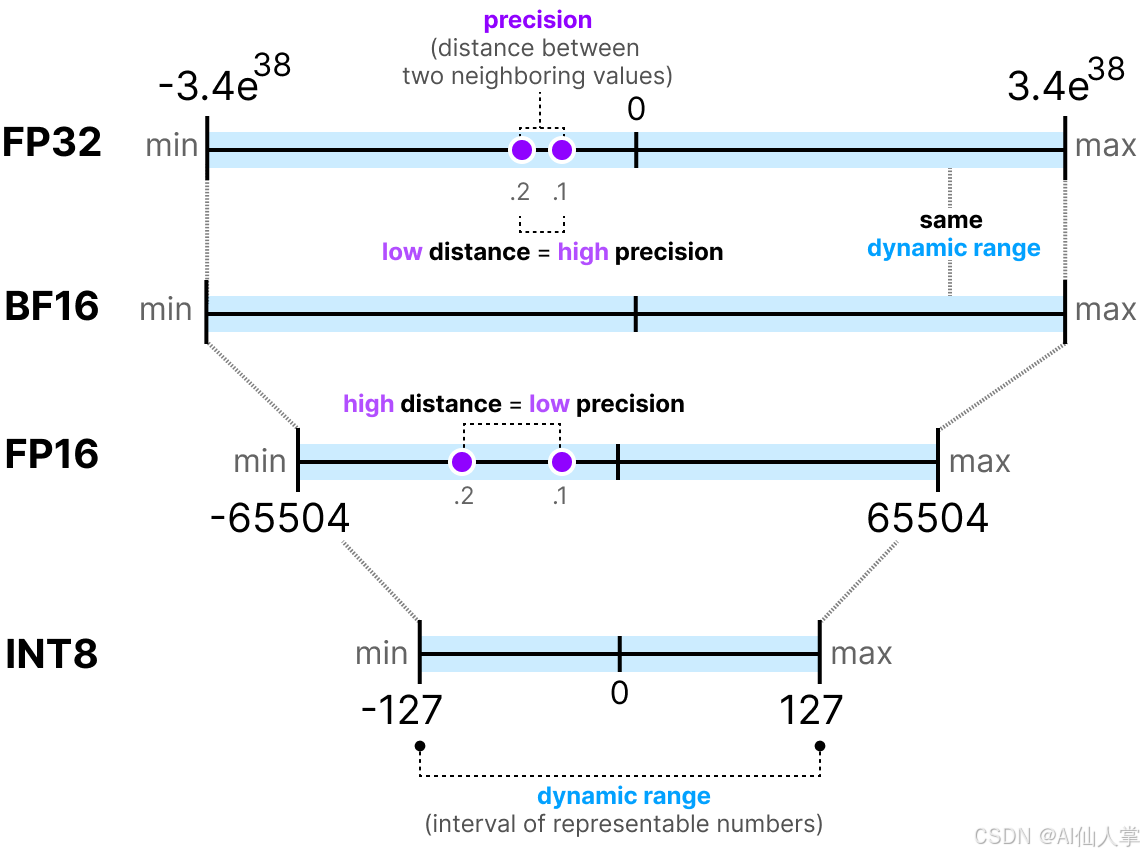
A 70B parameter model in FP32 needs roughly 280GB of GPU memory just to load. That is 4 bytes per parameter. Most teams cannot afford that. Even FP16 at 140GB is still brutal for most setups.
Quantization is how we fix this.
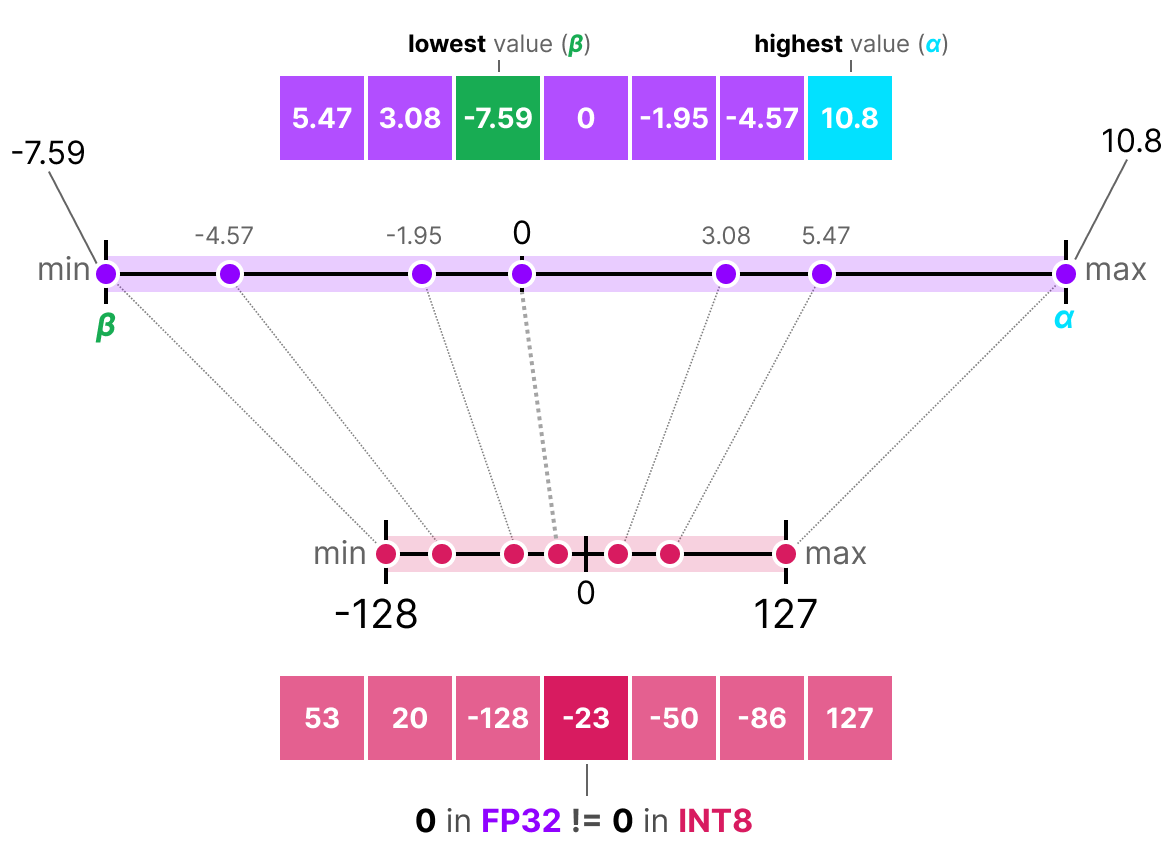
What quantization does:
Instead of storing weights at full precision, we reduce the number of bits used to represent each parameter.
FP32 (32 bits) to FP16 (16 bits): half the memory, nearly identical quality
FP16 to INT8 (8 bits): half again, small quality tradeoff
INT8 to INT4 (4 bits): half again, noticeable tradeoff if done poorly
A 70B model in INT4 fits in roughly 35GB. Suddenly a 2xA100 setup becomes viable instead of an 8xA100 cluster.
Two main approaches
Post Training Quantization (PTQ):
Quantize after training. No retraining needed. Fast to apply. Works well at INT8 and reasonably well at INT4 with good calibration data.
Quantization Aware Training (QAT):
Simulate quantization during training. More expensive but produces significantly better quality at very low bit widths like INT4 and below.
What is actually used in production
→ GPTQ and AWQ dominate for weight-only INT4 quantization
→ GGUF via llama.cpp for CPU and edge inference
→ FP8 is gaining ground fast on H100s with near FP16 quality
→ vLLM supports GPTQ, AWQ and FP8 natively today
The tradeoffs
→ Lower bits = smaller memory footprint but potential quality degradation
→ Quantization sensitivity varies by model architecture and task
→ Getting INT4 right needs careful calibration, not just default settings
Quantization is not a free lunch but done right it is the single biggest lever for reducing inference cost per token without changing your serving stack.
Day 8 tomorrow: Tensor Parallelism and how we split models across multiple GPUs 🔀
#LLMInference #Quantization #MachineLearning #GenAI #GPU #LLM #AIEngineering #MLOps #vLLM #GPTQ #AWQ #FP8

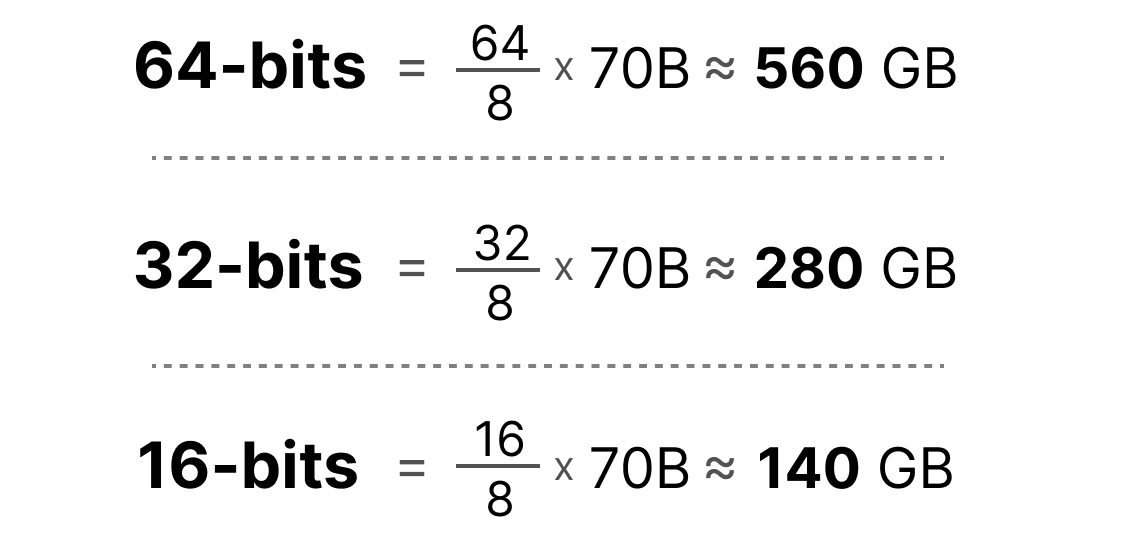
Day 6/365 of LLM Inference
Today's focus: Speculative Decoding - how we trick the model into going faster
Yesterday we covered PagedAttention. Today is about one of the most clever tricks in modern LLM inference.
The core problem with decoding
Decoding is sequential. One token at a time. You cannot parallelize it because each token depends on the previous one. The big model sits waiting between each step. Pure latency.
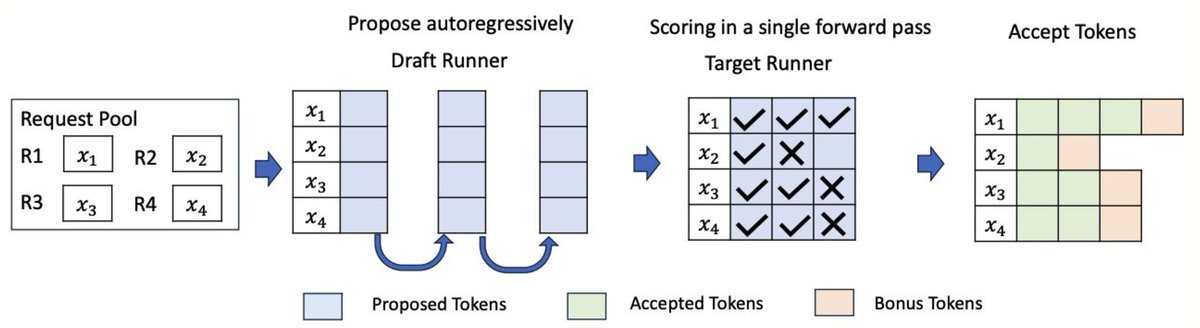
The insight behind speculative decoding
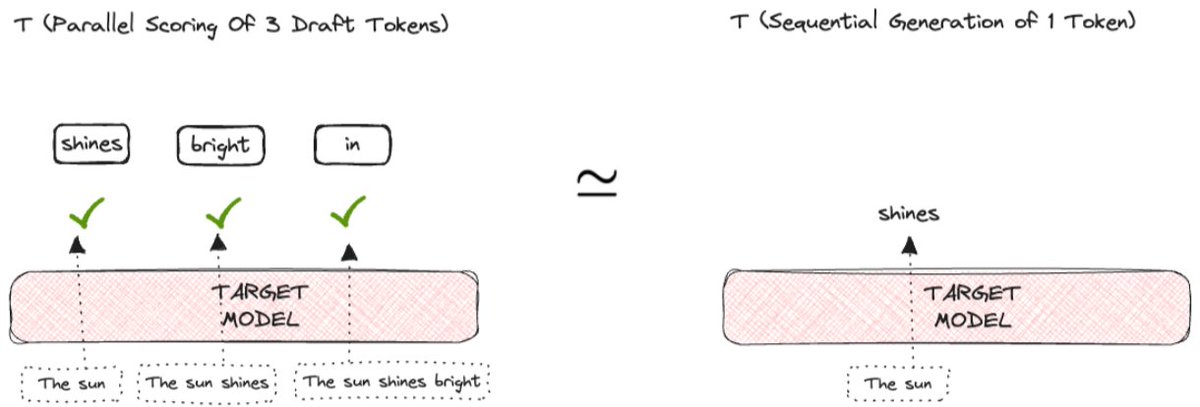
What if a small cheap model drafted multiple tokens ahead and the big model just verified them in parallel?
That is exactly what speculative decoding does.
How it works:
→ A small draft model generates N tokens speculatively and quickly
→ The large target model verifies all N tokens in a single forward pass
→ If the draft tokens are correct, you accept them all at once
→ If a draft token is wrong, you reject from that point and fall back to normal decoding
The big model still does all the verification. Output quality is mathematically identical. But instead of N sequential forward passes on the large model, you get N tokens from one pass.
Why this is a big deal:
The large model's forward pass cost is roughly the same whether it processes 1 token or 8 tokens. Verification is nearly free compared to generation.
On tasks where the draft model guesses well (code, repetitive text, structured outputs) you can see 2x to 3x latency improvements with zero quality loss.
The tradeoffs:
→ Needs a good draft model that matches the target model's distribution
→ Works best on predictable output patterns
→ Adds system complexity with two models running together
→ Acceptance rate varies heavily by task
Speculative decoding is now shipping in production inside vLLM, TensorRT-LLM and Hugging Face TGI.
Day 7 tomorrow: Quantization and how we shrink models without destroying them 🔢
#LLMInference #SpeculativeDecoding #MachineLearning #GenAI #GPU #LLM #AIEngineering #MLOps #vLLM #LLMOptimization

1
101
Day 4/30 of LLM Inference
Today's focus: Batching - how we stop wasting GPU cycles
Yesterday we covered KV Cache. Today is about how we serve multiple users without burning money.
The problem with serving one request at a time:
A single inference request rarely saturates your GPU. The GPU is sitting mostly idle between requests. You're paying for a Ferrari and driving it in a school zone.
What batching does:
Instead of processing one request at a time, we group multiple requests together and run them through the model in a single forward pass.
More requests per forward pass = better GPU utilization = lower cost per token.
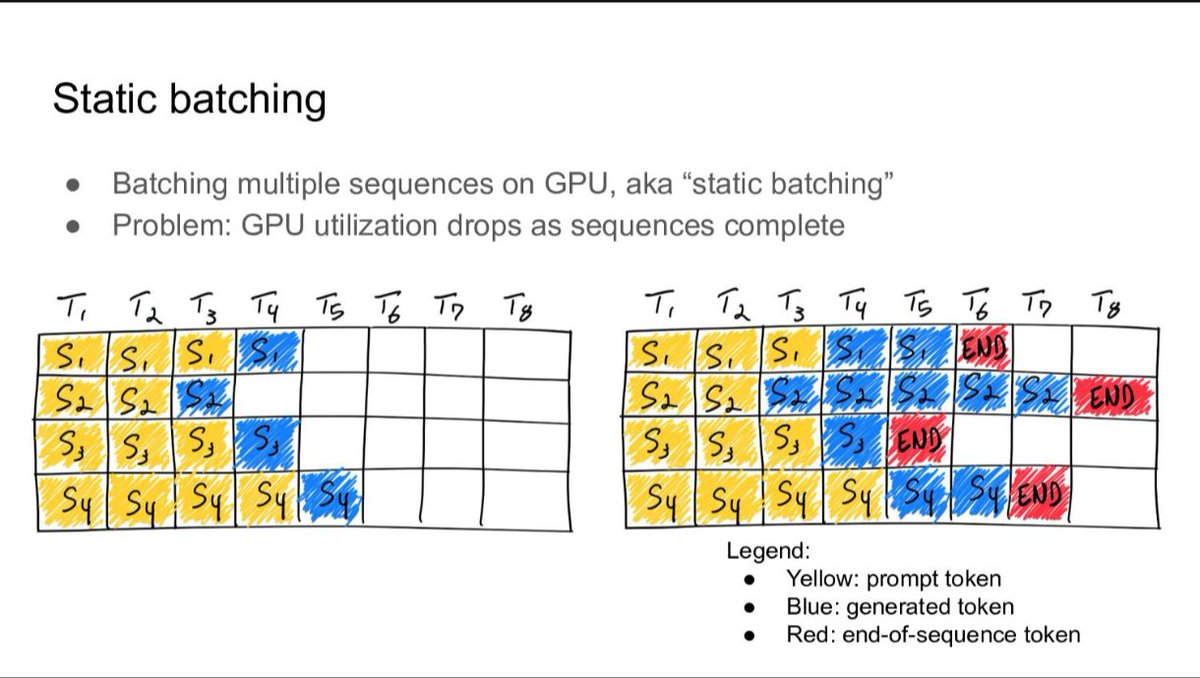
Static batching:
Oldest approach. Wait until you have N requests then process them together. Simple but painful. Requests that finish early sit idle waiting for the slowest one in the batch to complete. Wasted compute.
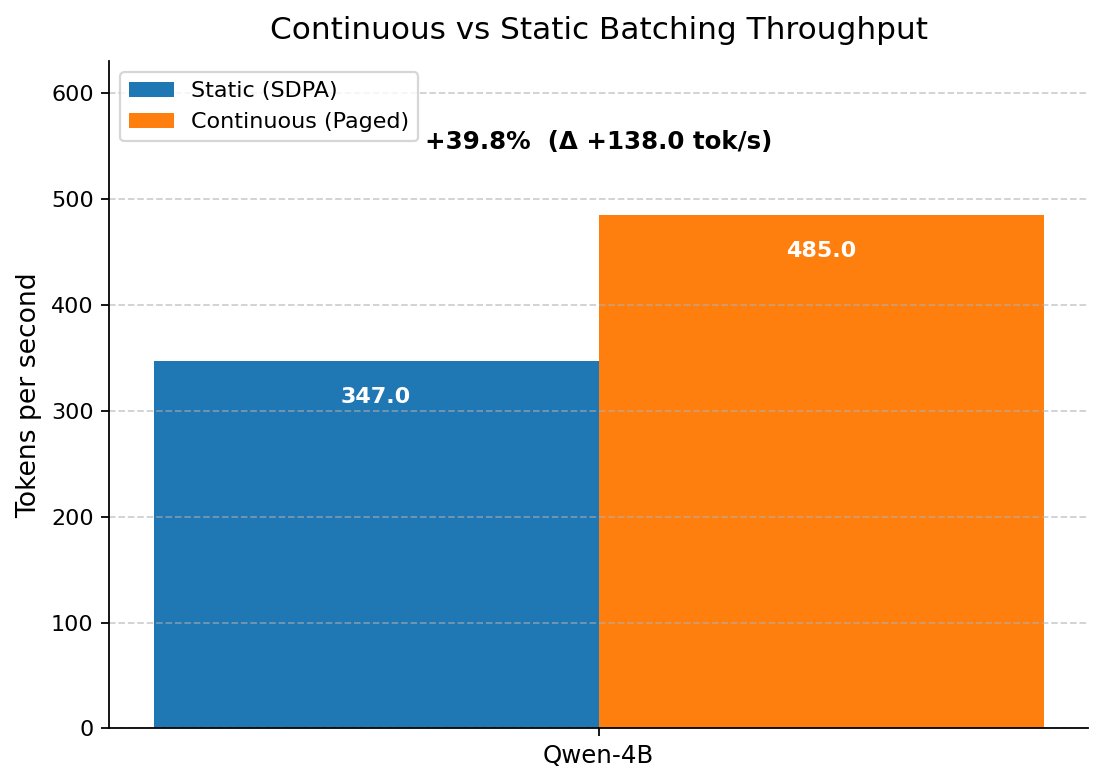
Continuous batching:
The real unlock. Instead of waiting for the entire batch to finish, new requests are inserted into the batch the moment a slot opens up.
No waiting. No idle slots. Near constant GPU utilization.
This is what production inference servers like vLLM use under the hood today.
The tradeoffs:
→ Larger batches = higher throughput but higher latency per request
→ Smaller batches = lower latency but underutilized GPU
→ Finding the right batch size is a tuning problem not a solved one
Throughput and latency are always in tension. How you batch determines which side you optimize for.
Day 5 tomorrow: PagedAttention and how vLLM changed everything 🚀
#LLMInference #Batching #ContinuousBatching #MachineLearning #GenAI #GPU #LLM #AIEngineering #MLOps #vLLM


Day 3/30 of LLM Inference
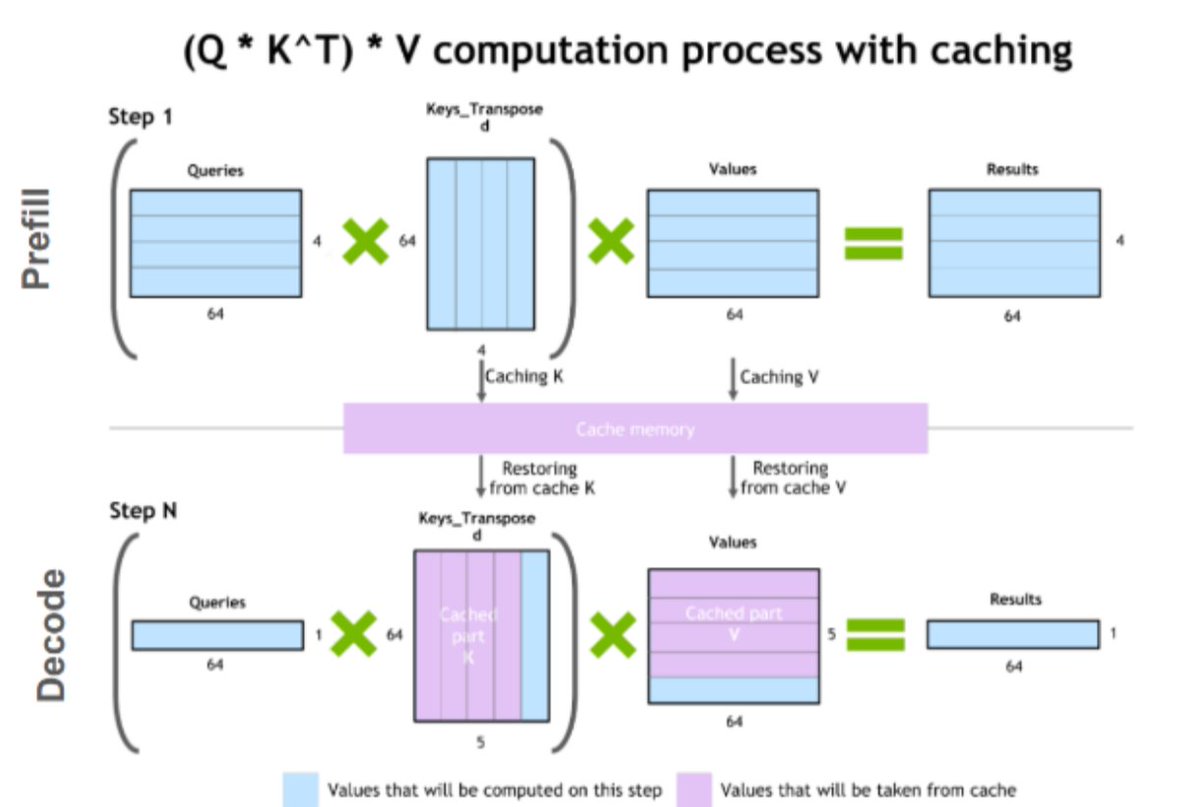
Today's focus: KV Cache - why it exists and what it actually does
Yesterday we covered prefill vs decoding. Today is about the thing that makes decoding not completely terrible.
The problem without KV Cache:
Every time the model generates a new token, it would need to recompute attention over every single previous token from scratch. For a 2000 token context, that's 2000 recomputations per new token. Pure waste.
What KV Cache does:
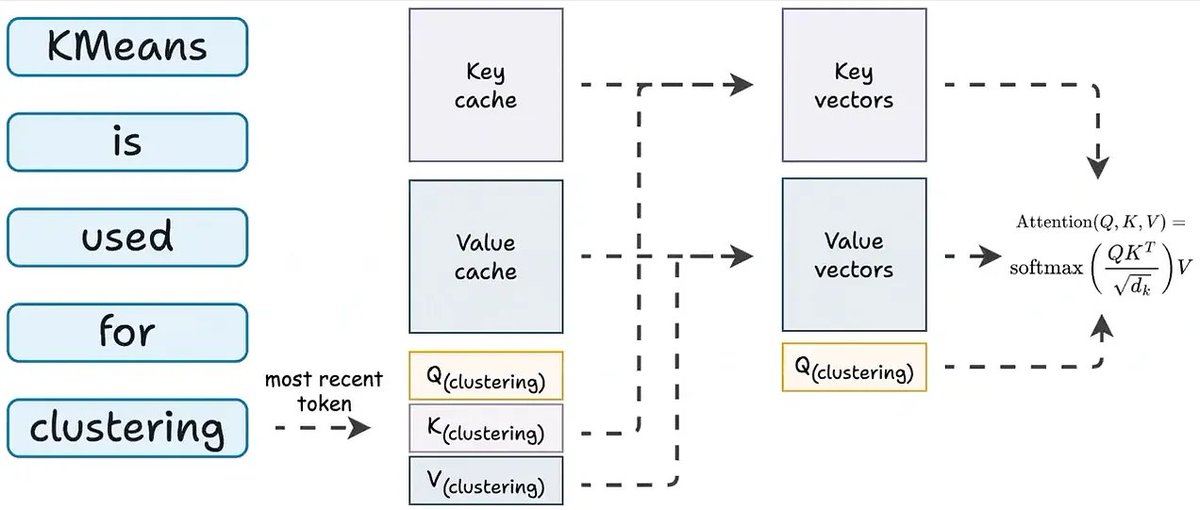
During prefill, the model computes Key and Value matrices for every token in your prompt. Instead of throwing them away, we store them in GPU memory.
During decoding, each new token only computes its own K and V, then reuses everything already cached.
No recomputation. Just a memory lookup.
The tradeoff:
KV Cache trades compute for memory. The cache grows with every new token generated. For long contexts and large batches this blows up fast.
This is exactly why:
→ Context length is expensive
→ Batch size has limits
→ vLLM's PagedAttention was a big deal (Day 5)
KV Cache is the single most important optimization in LLM inference today. Everything else builds on top of it.
Day 4 tomorrow: Batching and throughput 📦
#LLMInference #KVCache #MachineLearning #GenAI #GPU #LLM #AIEngineering #MLOps #Transformers


1
1
1
127