
Joined October 2014
- Tweets 18,926
- Following 1,679
- Followers 1,644
- Likes 11,329
2,531 Photos and videos




Conan: A native Mac cockpit for Claude Code by @randydigital producthunt.com/products/con…
1
1
6
Memoriq: Your private AI memory for ChatGPT, Claude, Gemini and Grok by @giekaton and @memoriqme producthunt.com/products/mem…
2
13
Taste Lab: Extract any website's design DNA by @sunlinsen producthunt.com/products/tas…
5
HYDRA-X: Native Unified Multimodal Models with Holistic Visual Tokenizers
huggingface.co/papers/2606.1…
4
Dmitry Noranovich retweeted

Jun 13
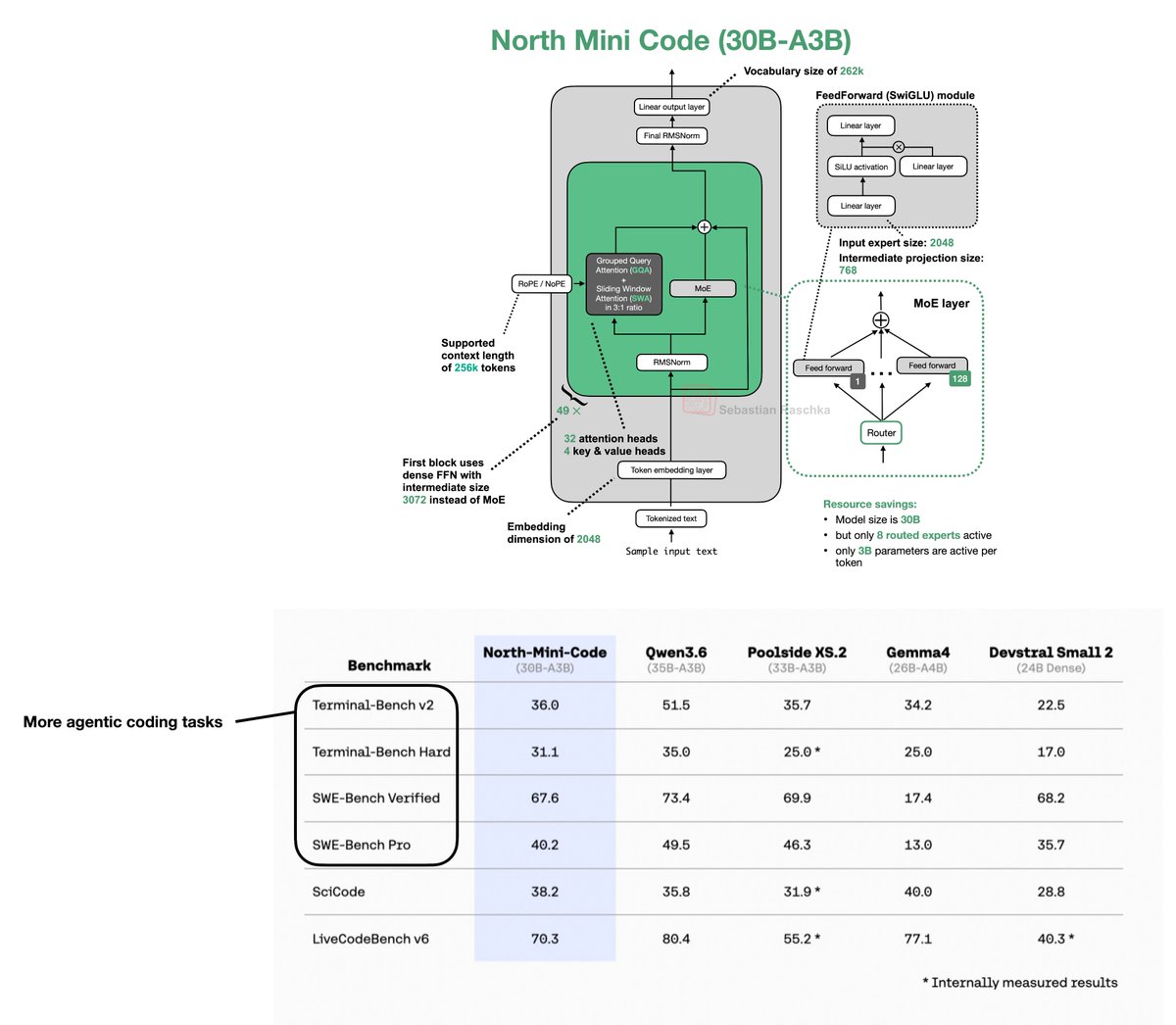
Cool new open-weight model by Cohere: a new lightweight 30B open-weight model for agentic coding tasks.
This one builds on Command A using the parallel transformer design. Interestingly, even though it's almost half as big, it almost doubles the number of layers.
Also, they say that it's been specifically developed for agentic coding, not just coding. I.e., the evaluation is inside a workflow, not just on a single prompt-to-code-answer task.
For Terminal-Bench, the model has to use a terminal, inspect the environment, run commands, read outputs, etc.
For SWE-Bench the model works on real GitHub-style software issues where it has to understand the repository, find relevant files, make a patch, pass tests, etc.
SciCode and LiveCodeBench are more traditional because they mostly test whether the model can produce correct code for a specified problem. Sure, this still requires reasoning, but it's more like “Implement a numerical routine to compute a scientific quantity from given equations and inputs.” which doesn't require any interaction with the environment, existing files, tests, etc.
The focus on the agentic code benchmarks is probably why it's far ahead of Gemma 4 on those.
Overall, it's pretty competitive although not quite Qwen3.6-level performance.
36
92
647
34,400
Dmitry Noranovich retweeted

Jun 12
MiniMax M3, Open-Weight, Now On Hugging Face , with only ~428B parameters and ~23B activated parameters
Weights:
huggingface.co/MiniMaxAI/Min…
MiniMax Sparse Attention:
huggingface.co/papers/2606.1…

Introducing MiniMax M3: The First Open-Weights Model to Combine Three Frontier Capabilities
- Coding & Agentic Frontier: 59.0% SWE-Bench Pro, 66.0% Terminal Bench 2.1, 34.8% SWE-fficiency, 28.8% KernelBench Hard, 74.2% MCP Atlas
- MiniMax Sparse Attention scales context to 1M
- Natively Multimodal from Step Zero
API: platform.minimax.io
Token Plan: platform.minimax.io/subscrib…
🚀New! MiniMax Code: code.minimax.io
Weights & Tech Report in ~10 Days

114
328
2,767
636,305
Dmitry Noranovich retweeted

Jun 11
We've just added two new Claude Managed Agents features:
1. Scheduled deployments - run tasks on a schedule
2. Environment variables - expose vault credentials for CLIs as environment variables

139
267
3,689
449,259

We heard you wanted to use Codex rate limit resets on your own time.
Starting today, we’re rolling out the ability to save rate limit resets to use later.
We’re starting Go, Plus, Pro, and Business users with one free reset:
1,276
1,728
21,483
4,221,246

Jun 12
Basedash: AI data analyst: AI-native Business Intelligence Platform by @MaxMusing and @drk producthunt.com/products/bas…
14
Jun 12
When GPU Utilization Lies: The Hidden Systems Problem Slowing Modern AI in @TDataScience
towardsdatascience.com/when-…
11
Dmitry Noranovich retweeted

Jun 11
Gemma 4 now runs 2x faster with MTP GGUFs! Run locally on just 6GB RAM. ⚡️
MTP enables Google Gemma 4 run ~1.4–2.2× faster with no accuracy loss.
Gemma 4 12B MTP can run at 162 t/s vs. 52 t/s without MTP. 31B reaches 101 t/s.
GGUFs Guide: unsloth.ai/docs/models/mtp

60
254
2,150
210,531
Dmitry Noranovich retweeted

Jun 10
Imagine a model that can reason about images and text together. That's Gemma 4, a 31B parameter vision-language model from Google, now optimized for fast inference with GGUF format. It's huge, it's smart, and it's ready for your multimodal projects.
1
1
23
1,414
Jun 11
Nodey: Your n8n command center, now on your phone by @TweetsHesham producthunt.com/products/nod…
8
Jun 11
SlimSnap: Your AI doesn't know which button you mean by @bickov producthunt.com/products/sli…
1
20
Jun 11
Slashspace AI: Canvas first AI agent harness. MCP native. Local first. by @praneethpike producthunt.com/products/sla…
16
Jun 11
Crustdata: People and company search APIs built for AI agents by @TheChowdhary producthunt.com/products/cru…
1
52
Jun 11
Agentic Environment Engineering for Large Language Models: A Survey of Environment Modeling, Synthesis, Evaluation, and Application
huggingface.co/papers/2606.1…
18
Dmitry Noranovich retweeted

Jun 10
Today I'm publishing a new essay, Policy on the AI Exponential. AI is progressing extremely fast—much faster than the policy process was built to handle. The essay lays out where I think the technology is now, and the action needed to close the gap: darioamodei.com/post/policy-…
1,307
2,407
13,418
6,367,824
Dmitry Noranovich retweeted

Jun 10
DiffusionGemma is our new experimental open model with up to 4x faster output on dedicated GPUs.
Instead of predicting word-by-word, it generates entire blocks of text simultaneously. This lets the model self-correct and format complex markdown in real time.

ALT Intelligence vs Latency chart showing DiffusionGemma 26B A4B is much faster than Gemma 4 models with high intelligence.
108
261
2,364
180,736