
🚨Excited to share our work on VisionCoach!
-Video reasoning isn’t failing because models can’t reason —it’s failing because they don’t see correctly.
-Instead of adding more tools at inference, we teach models how to look during training.
✨VisionCoach = visual prompting (train-time) RL with self-distillation -> grounded reasoning with tool-free inference
Mar 17

🚨 Excited to share VisionCoach, an RL framework for reinforcing grounded video reasoning via visual-perception prompting and self-distillation!
🧠 Video reasoning models often miss where to look or rely on language priors. Instead of only supervising final answers, we encourage the model to learn to attend to the right visual evidence.
⚽️ VisionCoach uses RL to reward correct visual attention, with dynamic visual prompting as a training-time coach for better spatio-temporal grounding, while keeping inference simple and tool-free via self-distillation.
⭐️ Achieves state-of-the-art zero-shot performance across video reasoning, video understanding, and temporal grounding benchmarks (V-STAR, VideoMME, World-Sense, VideoMMMU, PerceptionTest, and Charades-STA).
👇🧵
5
17
3,029

Mar 17
Check out our new work ⚽️VisionCoach, an RL self-distillation framework for complex video reasoning.
We combine reinforcement learning with dynamic visual prompting, where a visual prompt selector adaptively augments hard training examples based on reward signals.
Visual grounding is key to accurate video reasoning. Instead of adding complexity at inference, we use visual prompting during training to guide models toward better spatio-temporal attention—then distill this capability into a simple, single-path model.
Mar 17
🚨 Excited to share VisionCoach, an RL framework for reinforcing grounded video reasoning via visual-perception prompting and self-distillation!
🧠 Video reasoning models often miss where to look or rely on language priors. Instead of only supervising final answers, we encourage the model to learn to attend to the right visual evidence.
⚽️ VisionCoach uses RL to reward correct visual attention, with dynamic visual prompting as a training-time coach for better spatio-temporal grounding, while keeping inference simple and tool-free via self-distillation.
⭐️ Achieves state-of-the-art zero-shot performance across video reasoning, video understanding, and temporal grounding benchmarks (V-STAR, VideoMME, World-Sense, VideoMMMU, PerceptionTest, and Charades-STA).
👇🧵
7
18
2,448

Mar 17
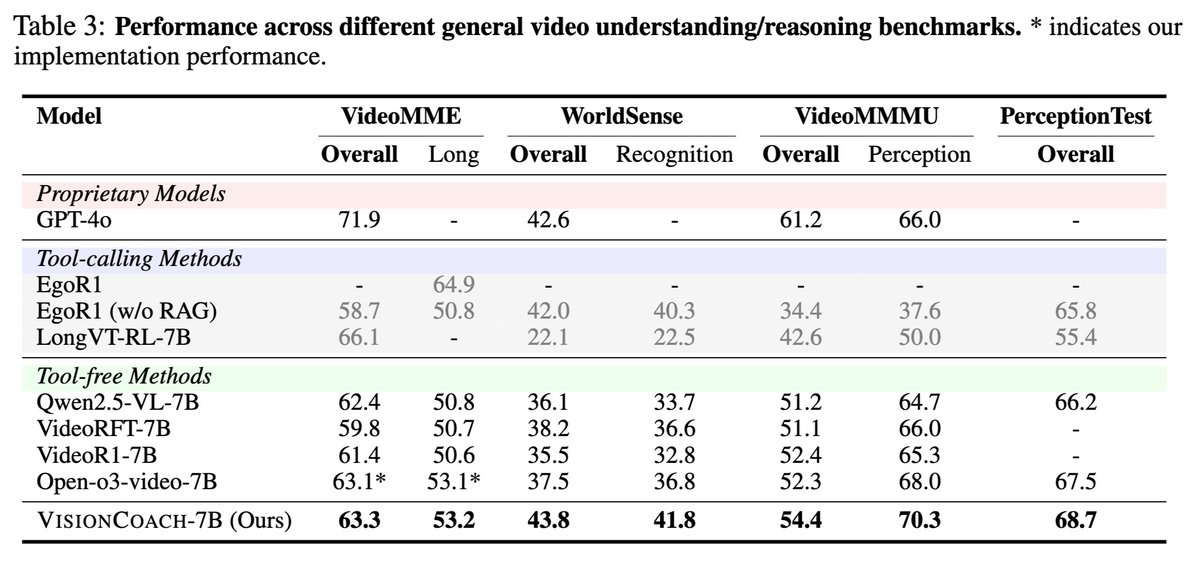
⚡️Results #2: General Video Understanding Benchmarks
We evaluate VisionCoach on VideoMME, WorldSense, VideoMMMU, and PerceptionTest as zero-shot performance.
- Across general video understanding benchmarks, VisionCoach outperforms GPT-4o, tool-calling methods, and tool-free baselines, while remaining fully tool-free.
- Notably, it achieves strong gains on perception-centric tasks (WorldSense, VideoMMMU), demonstrating that better grounding directly improves video understanding performance.
1
8
230
Mar 17
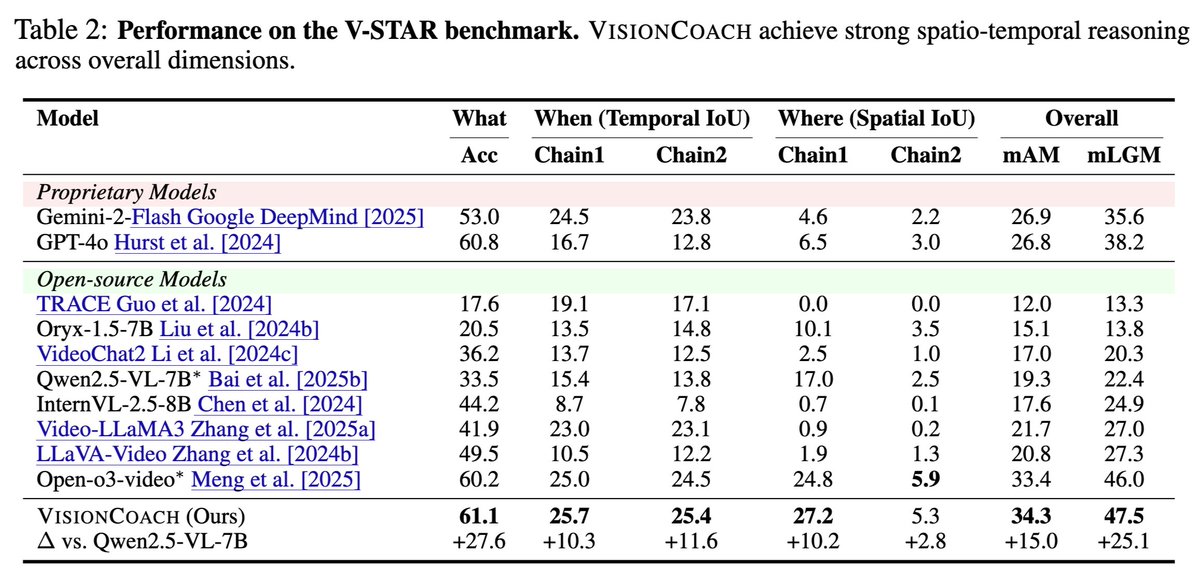
⚡️Results #1: V-STAR (Spatio-Temporal Video Reasoning Benchmark)
- VisionCoach consistently outperforms both proprietary and open-source baselines on V-STAR.
- It achieves large improvements over Qwen2.5-VL ( 27.6 accuracy, 15.0 mAM, 25.1 mLGM), showing that grounding-aware RL with self-distillation effectively enhances visual reasoning.
2
8
224
Mar 17
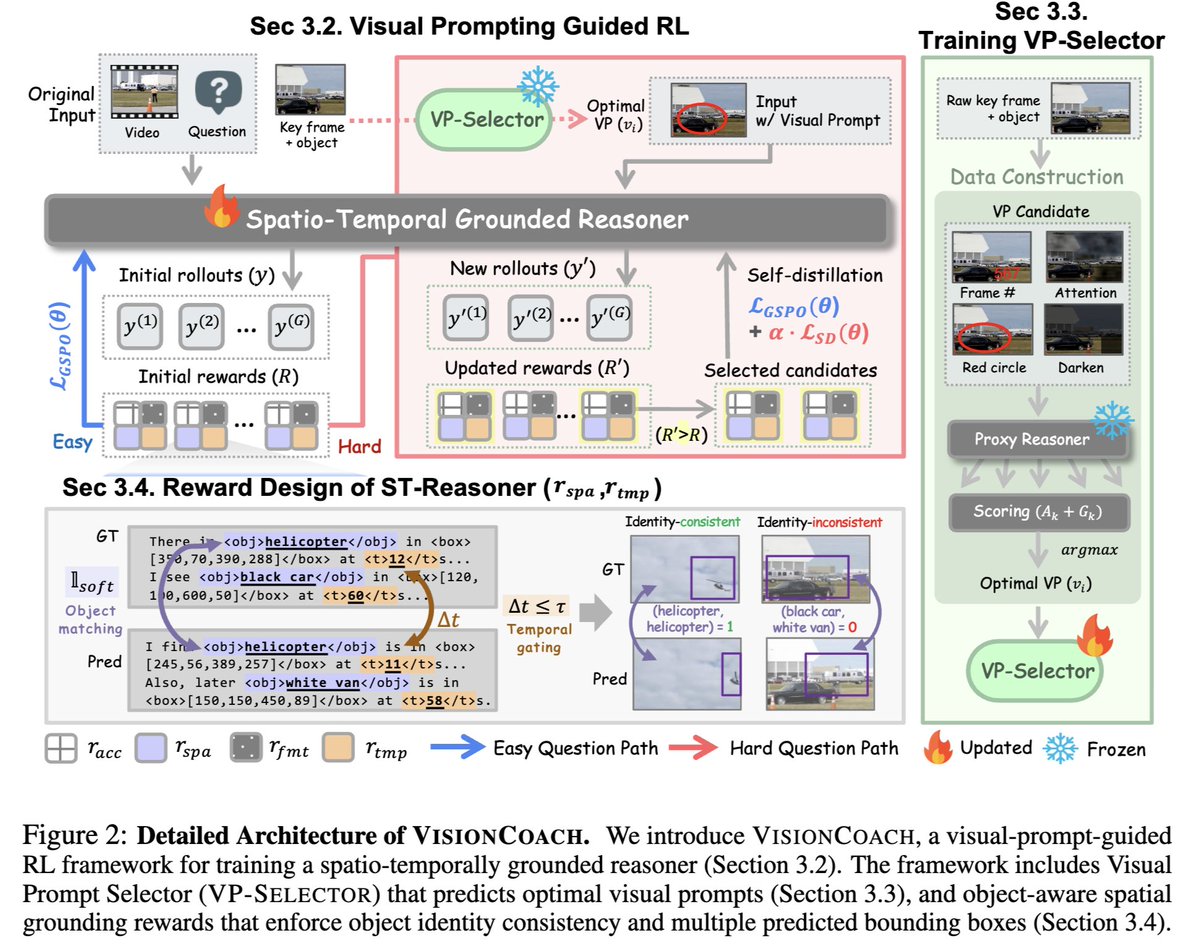
Method Overview
VisionCoach contains two key components:
1️⃣ Visual Prompt Selector (VP-Selector)
Predicts the best visual prompt type conditioned on the video and question.
2️⃣ Spatio-Temporal Reasoner (ST-Reasoner)
Performs grounded reasoning under visual prompt guidance and is optimized with RL.
We also introduce an object-aware grounding reward that enforces:
✔ object identity consistency
✔ bounding box overlap (IoU) across reasoning steps
1
8
244
Mar 17
⭐️Our Idea: RL with input-adaptive visual prompting
We propose VisionCoach, an input-adaptive RL framework that improves grounding through visual prompting during training.
Key point:
- Visual prompts highlight question-relevant regions while suppressing distractors
- Encourage grounded reasoning trajectories
After training, the model internalizes these behaviors via self-distillation, so prompts are no longer needed at inference.
1
8
257
Mar 17
🚨 Excited to share VisionCoach, an RL framework for reinforcing grounded video reasoning via visual-perception prompting and self-distillation!
🧠 Video reasoning models often miss where to look or rely on language priors. Instead of only supervising final answers, we encourage the model to learn to attend to the right visual evidence.
⚽️ VisionCoach uses RL to reward correct visual attention, with dynamic visual prompting as a training-time coach for better spatio-temporal grounding, while keeping inference simple and tool-free via self-distillation.
⭐️ Achieves state-of-the-art zero-shot performance across video reasoning, video understanding, and temporal grounding benchmarks (V-STAR, VideoMME, World-Sense, VideoMMMU, PerceptionTest, and Charades-STA).
👇🧵
1
24
77
11,100

10 Aug 2025
MY APP:
VisionCoach: an AI vision-board and goal-coach
LETS GOOOOO

We've had 10k signups (thank you!)
To celebrate, we're launching a hackathon this weekend to show off what you can make with Anything
Quote w/ your idea to enter
Reply w/ your app to submit (Sunday 11:59pm deadline)
Best app gets $10k

3
121


27 Jul 2023
🌟 "Clarity is not just about knowing what you want, but also understanding why you want it. Embrace the power of clarity to unlock your true potential and set your dreams in motion.
#ClarityIsPower #VisionCoach #PersonalGrowth"
1
2
69

8 Jun 2023
The question is not whether to choose either change or the status quo. The real question is: Am I ready to accept and take responsibility for my decision, whatever the choice? #ChangeIsGood #EmbraceHelp #TransformYourself #SupportSystem #TransitionJourney #VisionCoach #courage

2
14
7 Jun 2023
Change is a journey with twists and turns. Read more about the role of a strong support system during times of change in my blog: rfr.bz/t5sc7sp
#ChangeIsGood #EmbraceHelp #TransformYourself #SupportSystem #TransitionJourney #VisionCoach
1
2
14

2 Mar 2023
LOVE HAS A NAME!
JOY HAS A NAME!
VICTORY HAS A NAME!
JESUS!
#name #Jesus #lyrics
#vision #visionboard #visioncoach #lifecoach #bookavisionsession #visionjourney #visionsession instagram.com/p/CpRBWbQox1K/…
3
22

16 Feb 2022
La política de vocación ( Visioncoach 15/11/20)
La ‘política de verdad’ es la que se hace cuando se está de paso en ella. Yo ...Por @vicpiriz1975 victorpiriz.es/?p=648&utm_so…
1
3

30 Jan 2022




2
3
23 Jan 2022
La política de vocación ( Visioncoach 15/11/20)
La ‘política de verdad’ es la que se hace cuando se está de paso en ella. Yo ...Por @vicpiriz1975 victorpiriz.es/?p=648&utm_so…
5
4
27 Nov 2021
El valor de la verdad ( VisionCoach 15/9/20)
¿Qué valor tiene la verdad en la política actual? Esta es una reflexión no solo para ...Por @vicpiriz1975 victorpiriz.es/?p=403&utm_so…
2
27 Aug 2021
El valor de la verdad ( VisionCoach 15/9/20)
¿Qué valor tiene la verdad en la política actual? Esta es una reflexión no solo para ...Por @vicpiriz1975 victorpiriz.es/?p=403&utm_so…
1
1
4
3 Aug 2021
El valor de la verdad ( VisionCoach 15/9/20)
¿Qué valor tiene la verdad en la política actual? Esta es una reflexión no solo para ...Por @vicpiriz1975 victorpiriz.es/?p=403&utm_so…
7
10
9 Jul 2021
La política de vocación ( Visioncoach 15/11/20)
La ‘política de verdad’ es la que se hace cuando se está de paso en ella. Yo ...Por @vicpiriz1975 victorpiriz.es/?p=648&utm_so…
2
4