
Apr 6
Qwen3.6 Plus is now available on @Qubrid_AI⚡
Built for developers who need stronger reasoning, coding, and real-world performance.
Test it. Break it. Build with it. 🚀
👉Try it in our playground here: platform.qubrid.com/model/qw…
@Alibaba_Qwen #qwen #qwenplus #aimodels #visionmodel #buildwithai
1
2
6
204

9 Nov 2025
I’m afraid this won’t run.
For clarify the optimisations I made were on the VisionModel not LLM part.
3
1,867

6 Nov 2025
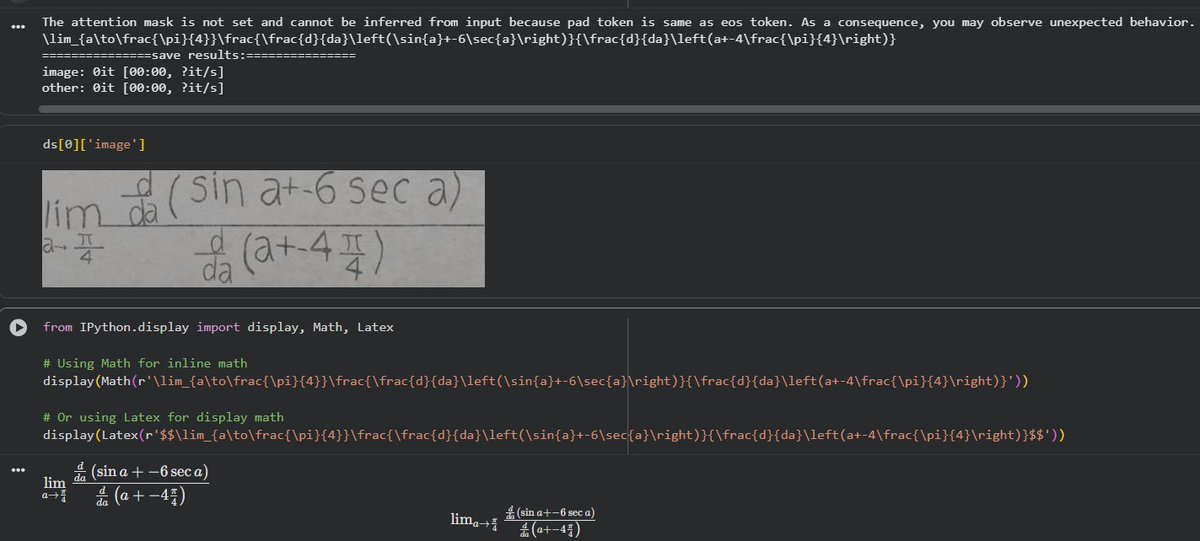
I published this new model which properly generate the hand-written Math Calculus Formulas
Check here: huggingface.co/karankulshres…
#ai #visionmodel #ocr #maths #calculus
2
46


12 Jun 2025
The Eye of the Model: A Quarkus Tale of Image Descriptions
Give your Java app the power to see. This hands-on tutorial blends AI, LangChain4j, and local vision models into a spellbinding Quarkus application.
buff.ly/pbzUTuL
#Java #Quarkus #VisionModel #Qwen
4
9
847

19 May 2025
Vision Model, Samsung’s Generative AI utility app grabs a huge 2GB update #Samsung #VisionModel #GalaxyAI sammyfans.com/2025/05/19/sam…
1
16
779
19 May 2025
Vision Model, Samsung’s Generative AI utility app grabs a huge 2GB update #Samsung #VisionModel #GalaxyAI 🧵

1
29
760

24 Jan 2025
Real-World Manual Layout
Look at these symbols, warnings, diagrams! Standard OCR-based approaches easily break or skip important call-outs.
ColPali processes the page as an image, preserving vital relationships—no separate text-chunk step required.
#colpali #visionmodel

1
1
49

23 Oct 2024
Vision models, multi models, and bears oh my! @mcplusa article on the future of search @qdrant_engine @vespaengine #visionmodel
mcplusa.com/the-future-of-se…
2
31

27 Sep 2024
From the AGI house @agihouse_org dinner, I want to share some insightful questions we discussed: (1) how to make multimodavision and speech model to have power scene levereasoning (2) how to make these powerful modelrun on local device (3) what is the right visionmodel architecture beyond vision transformer and CNN (4) What is the bottleneck to multi-modal scaling law (5) What is the limit in making multi-modal model smaller to fit into the phone without hurting reasoning ability too much.
2
367

7 Aug 2024
My new video on how to code a Multimodal (Vision) Language Model from scratch using only Python and PyTorch while explaining every single concept step by step.
Link: youtube.com/watch?v=vAmKB7iP…
#tutorial #pytorch #python #coding #fromscratch #llm #paligemma #gemma #visionmodel
22
151
900
88,215

22 Jun 2024
'What is Claude 3.5 Sonnet &
How it is better than its rival AI models'
:Explained by Mr Bijin Jose
@bijin_jose
#Anthroponic #ClaudeSonnet #VisionModel #GenerativePreTrainedTransformers #LLM
#GPT4o #Gemini #llama
#ArtificialIntelligence #GenAI
#technologies
#UPSC
Source: IE

2
5
38
2,530

7 Jun 2024
#biabob: "Show me your image and I write you a notebook for processing it."😃
No big surprise and yet amazing that #GPT4omni #LLM #VisionModel can do this [with simple 2D images] 🤯🐍🚀
Give it a try. Feedback welcome 🙃
pip install bia-bob==0.16.0
github.com/haesleinhuepf/bia…
26
83
9,654

12 Apr 2024
Who doesn't adore @OfficialDenzel? 🌟 He's the kind of actor you could watch for hours! 😎
For the love of Denzel, we've crafted an image recognition model harnessing the power of Autogon @Autogon_Lkraft! 🎥Trained with just 12 images (optimal practice suggests 100 , but this is just a demo!) it's designed to spot Denzel Washington effortlessly
Check it out and create your own at console.autogon.ai/get-start…!
P.S: Get ready for an extra dose of motivation – we've embedded the video with the audio of one of Denzel's inspirational speeches! 🙌
#VisionModel #AutogonAI #NoCodeAI
1
4
5
1,346

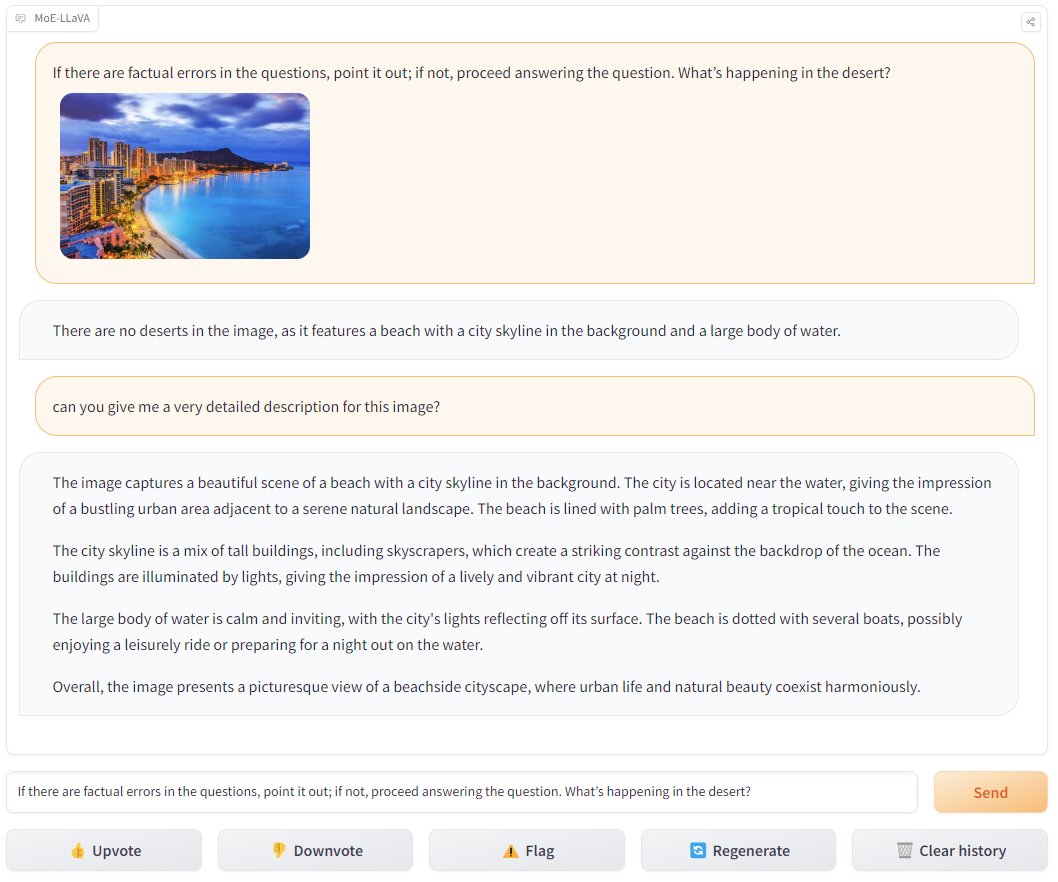
30 Jan 2024
Gradio's new MoE-LLaVA: A compact vision-language model that's challenging its bigger counterparts. See how it performs with your own images! 📸🔍 #AI #VisionModel #TechInnovation


🚀Finally A Mixture of Experts for Large Vision-Language Models, called 𝐌𝐨𝐄-𝐋𝐋𝐚𝐕𝐀 !
🌋At just 3Billion sparsely activated params MoE-LLaVA perf is comparable to LLaVA1.5-7B on various visual understanding datasets and surpasses LLaVA1.5-13B in object hallucination bm.
1
2
88

2 Dec 2023
今週末はVisionModel連携関連の作業を行いたいと思います。
うまく行ったらスタックチャン作る!!!(flg_stack-chan=False)
2
110

14 Mar 2023
زنده
📌به گفته آقای Greg Brockman کوفاندر open-AI، مدل زبان GPT-4 یک مدل بصری نیز است و می تواند تصاویر را مانند بصورت طبیعی درک کرده و با تصویر پاسخ دهد. این یعنی قدرت درک تصاویر بر اساس پاسخ های طبیعی مورد نیاز کاربر خواهد بود.
Vision Model
#هوش_مصنوعی #gpt4 #visionmodel
1
1
3
1,235

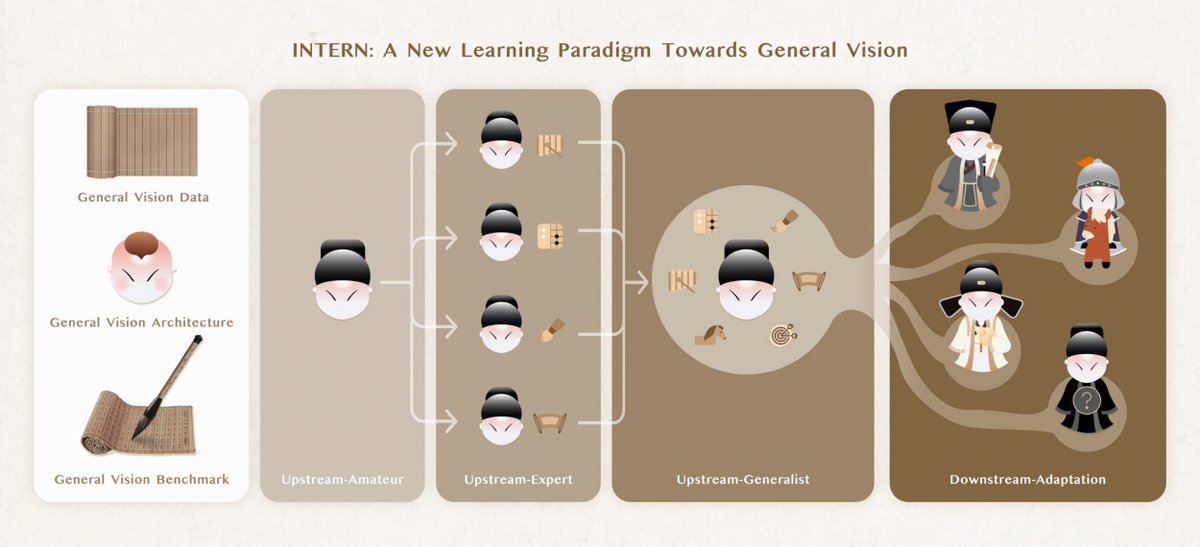
CUHK has forged a tripartite partnership with the Shanghai #ArtificialIntelligenceLaboratory, @SenseTime_AI, and @sjtu1896 and unveiled a new generation of general #visionmodel INTERN, addressing the key obstacles to the development of general vision in AI bit.ly/3r6vYyR
7

