
May 27
Xiaomi just made MiMo V2.5 the cheapest vision model on the market.
97% price cut on cache hits.
New pricing (effective today):
Pro V2.5:
• Cache hit: $0.0036/M input (was $0.435)
• Cache miss: $0.435/M input
• Output: $0.87/M
Base V2.5:
• Cache hit: $0.0028/M input
• Cache miss: $0.14/M input
• Output: $0.28/M
At cache hit rates, Pro is now 97% cheaper than before. Base is practically free at $0.0028/M.
Why this matters:
MiMo V2.5 is a 310B MoE (15B active) vision-language model with 1M context and MIT license. It tops Claw-Eval for agentic vision tasks.
At these prices, you can run vision pipelines that were previously uneconomical — document processing, UI automation, real-time visual agents.
I've been using it on our stack for visual understanding tasks. At cache hit pricing, it beats every vision model on cost by a wide margin.
OpenRouter hasn't updated their pricing yet ($0.435/$0.87 still showing). Direct API is the move if you have predictable cache-hit workloads.
Source: platform.xiaomimimo.com/docs…
#AI #VisionModels #OpenSource #PricingWar
17

Apr 27
Are you just downloading vision models or actually understanding how they process images?
In this clip from @goinggodotnet 's Ultimate AI Workshop, Bill breaks down the "missing link" in vision models: projection files MTMD.
👉 youtu.be/dpcmUgtYqGA
The reality:
→ Vision inference requires a specific stack of model files, projection files, and correct formatting, not just a single download.
→ Vision models need projection files to translate raw image bytes into something the model can actually "see."
→ F16 is the gold standard for inference; don't waste resources on massive F32 or training-specific BF16 files.
→ Navigate Hugging Face with intent: If you don't grab the right sidecar files, your model will silently fail on image tasks.
Stop treating vision models like text-only systems. It's time to master multimodal architecture. 🛠️
#AI #VisionModels #AIEngineering #LocalAI #HuggingFace #Multimodal
2
228

Apr 11
📸 Gemma 4's vision capabilities are seriously impressive.
Google's open model now rivals closed-source alternatives on image understanding tasks — and it's built for on-device deployment.
Multimodal AI that doesn't need the cloud? That's the unlock we needed.
#Gemma4 #AI #VisionModels #GoogleAI
48

🚀 Hiring: Software Engineers (all levels) — Coram AI
📍 Remote (Global) | 💼 Not provided | 🧑💻 AI / Physical world | 🕐 Posted recently
Coram AI is hiring Software Engineers (all levels). They are building the intelligence layer for the physical world — turning real-world data into intelligent, actionable systems as a high-agency, AI-first team at the frontier of physical AI.
🔑 Role and impact
Problems solved are not theoretical — they evolve with cutting-edge AI breakthroughs and create real-world impact. Engineers take ownership, ship fast, and build systems operating across hardware, cloud, and AI models.
🛠 Core areas of work
— Edge of AI progress: LLMs, modern vision, multimodal models for extracting insights
— Scalable streaming systems and distributed architectures
— Architecting hybrid systems spanning edge devices and cloud infrastructure
Ideal for those excited by challenging engineering with meaningful outcomes.
📩 To apply: Reach out directly via DM to Purushotham Santhati on LinkedIn (linkedin.com/in/purush7) or connect with Vishwajitt 🧠 — follow their official process and contact the company directly.
🔗 Original post: linkedin.com/posts/purush7_w…
⚠️ DYOR — the poster doesn’t verify every job. If someone asks to run files (even from GitHub) or only replies via Telegram — 🚩 likely a scam.
❗️Not hiring. Just sharing real Web3 jobs with low competition — daily, for all levels!
💡 For Interns & juniors → t.me/crypto_vazima_english
💼 Mid/senior jobs → t.me/web3_jobs_crypto_vazima
#SoftwareEngineer #Hiring #AI #Engineering #TechJobs #RemoteJobs #ArtificialIntelligence #MachineLearning #LLM #VisionModels #DistributedSystems #EdgeComputing #Cloud #PhysicalAI #JobOpening

76

After 2 years probing #visionmodels at the #KempnerInstitute, @thomas_fel_ reflects on what he’s learned—and what pieces of the #interpretability puzzle remain hidden—as he heads to @GoodfireAI. Read the interview: bit.ly/4aEBzmp 🎙️🧩
1
6
67
12,902

It’s 2026 learn
RAG
LLMs
Agents
Multi-Agents
Embeddings
VectorDB
Fine-tuning
LoRA
QLoRA
Prompting
SystemDesign
LangChain
LlamaIndex
Transformers
Tokenization
Inference
Distillation
Quantization
RLHF
DPO
SFT
Guardrails
Eval
Benchmarks
RedTeaming
AI Safety
OpenWeights
OnDeviceAI
EdgeAI
FederatedLearning
Diffusion
GANs
VisionModels
OCR
ASR
TTS
Multimodal
GraphRAG
KnowledgeGraphs
Neo4j
Elastic
FAISS
Pinecone
Weaviate
Milvus
Chroma
Postgres
pgvector
Supabase
Docker
Kubernetes
Serverless
AWS
GCP
Azure
Vercel
Cloudflare
Rust
Go
TypeScript
Python
Node
FastAPI
NextJS
React
Tailwind
tRPC
GraphQL
REST
WebSockets
gRPC
Redis
Kafka
WebRTC
OAuth
JWT
ZK
zkSNARKs
zkSTARKs
MPC
TEE
Homomorphic
EVM
Solidity
Foundry
Hardhat
AccountAbstraction
ERC4337
Rollups
Optimistic
ZKRollups
EigenLayer
Layer2
DeFi
AMMs
Perps
MEV
IntentBased
Oracles
Chainlink
IPFS
Arweave
Filecoin
Bitcoin
Lightning
BCH
Ordinals
Runes
WalletConnect
Passkeys
DID
SSI
ZeroTrust
DevSecOps
CI/CD
GitHubActions
Testing
Vitest
Playwright
Cypress
UnitTests
IntegrationTests
LoadTesting
Observability
Prometheus
Grafana
OpenTelemetry
Sentry
FeatureFlags
A/BTesting
Analytics
SEO
Growth
ColdEmail
Copywriting
Storytelling
PersonalBrand
Distribution
Community
DevRel
OpenSource
Licensing
Roadmaps
PRDs
UX
UI
DesignSystems
Figma
Accessibility
MobileFirst
PWA
iOS
Android
Flutter
ReactNative
Swift
Kotlin
DataEngineering
ETL
Airflow
dbt
Snowflake
BigQuery
Pandas
NumPy
PyTorch
TensorFlow
JAX
CUDA
WebGPU
EdgeCompute
CDN
Caching
RateLimiting
API Design
Microservices
Monorepo
Turborepo
Nx
FeatureStores
VectorSearch
SearchRanking
Recommenders
TimeSeries
Backtesting
Quant
HFT
RiskModeling
Privacy
Compliance
GDPR
SOC2
BugBounty
ThreatModeling
IncidentResponse
ProductMarketFit
MVP
Bootstrap
Fundraising
PitchDeck
Angel
VC
Revenue
Monetization
SaaS
B2B
B2C
NoCode
LowCode
Automation
Zapier
n8n
Webhooks
CLI
DX
4
85

Learn how to build a low-cost WhatsApp bot that analyzes images using AI vision models like Llama and GPT-4V, with Python and MongoDB.
- hackernoon.com/how-i-built-a… #visionmodels #pythonwhatsappbot
1
2
187

Jan 28
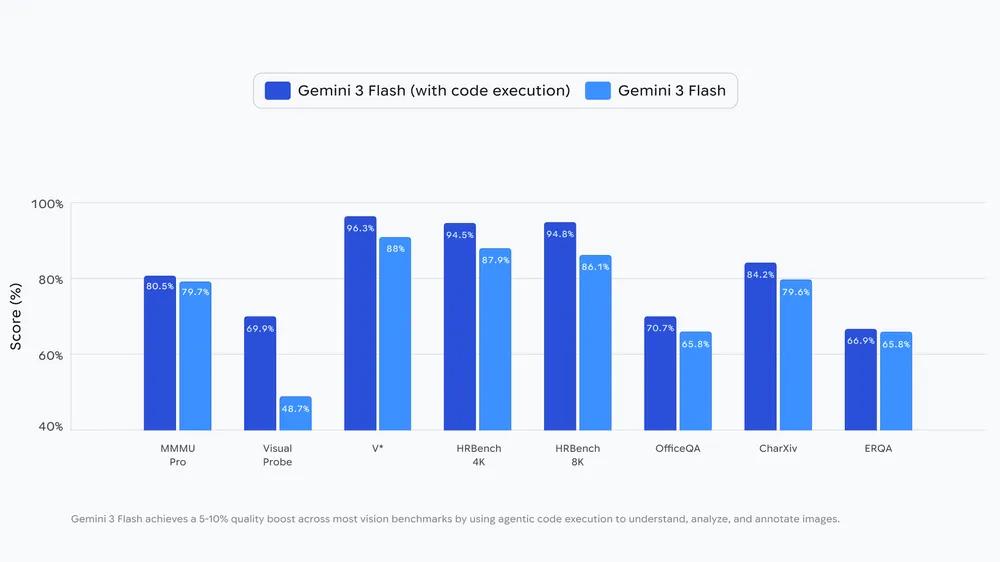
👁️ Google just launched Agentic Vision for Gemini 3 Flash
This feature turns image understanding from a static process into a dynamic one.
Instead of the usual:
“Look at the image and answer”
Gemini can now do:
“Look at the image, work with it, and then answer.”
Think–Act–Observe for vision
Agentic Vision introduces an explicit loop:
Think — analyze the image, build a plan
Act — run code for image processing, detection, calculations, etc.
Observe — feed results back into context and use them for the final response
So the model doesn’t just guess — it operates on the image.
Example: counting fingers.
Instead of replying “5” immediately, the model detects each finger with bounding boxes, counts them, and then produces the answer.
A simple example, but it captures the shift: the image becomes a kind of visual scratchpad for reasoning.
Where it shines
complex tables
small details
structured visual data
tasks requiring precise counting or localization
Google reports an average 5–10% metric improvement over vanilla Gemini 3 Flash.
Agentic Vision is already available in both the API and AI Studio.
More details:
blog.google/innovation-and-a…
#AI #Gemini #ComputerVision #AgenticAI #Multimodal #LLM #Google #AIEngineering #MachineLearning #VisionModels
60

Jan 20
PolyRead is an instant way to get a pic from camera or upload, gets OCR of the image, from state of the art Google and ChatGPT vision models #multimodal and translate to more than 50 human languages: polyread.cxloop.co #OCR #Gemini #ChatGPT #NLP #VisionModels
43

9 Dec 2025
Vision Models
Vision Models help AI see and understand images — objects, text, scenes.
Used in face unlock, product recognition, and self-driving tech.
When combined with language → Multimodal AI (GPT-4V, Gemini, Claude Vision)
#AI #VisionModels #Multimodal #ComputerVision

33

27 Nov 2025
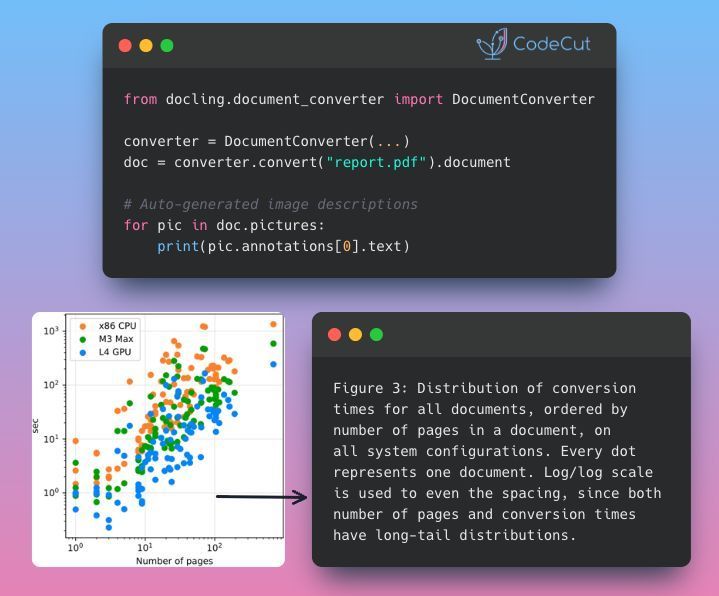
Auto-annotate PDF images with local vision models (data stays private) 🖼️
Images in PDFs like charts, diagrams, and figures are invisible to search and analysis. Manually writing descriptions for hundreds of figures is impractical.
You could use cloud APIs like Gemini or ChatGPT, but that means API costs at scale and your documents leaving your infrastructure.
Docling runs local vision language models (Granite Vision, SmolVLM) to automatically generate descriptive annotations for every picture in your documents, keeping data private.
Key benefits:
• Privacy: Data stays local, works offline
• Cost: No per-image API fees
• Flexibility: Customizable prompts, any HuggingFace model
🚀 Full article: bit.ly/4ioeuXm
☕️ Run this code: bit.ly/3XgRfVt
#Python #DataScience #MachineLearning #VisionModels
2
7
76
4,021

26 Nov 2025
Crowd Map: Detects up to 5,000 people simultaneously with 2× extended range. Reliable in rain and at night! Sharper, dependable crowd management from Dahua Xinghan. tiny.cc/xinghanweb
#CrowdMap #DahuaXinghan #SmartCity #CrowdManagement #VisionModels

1
32

25 Nov 2025
Second day on Symbiote and things are clicking. Started with Phi3-mini (3.8B) for generating test steps decent, but too hit-or-miss for reliable automation🧐. Now pivoting to vision models so the agent can literally “see” the UI and act like a human tester. Tested LLaVA → instructions solid, vision still fuzzy on dense UIs. Today I am gonna give BakLLaVA & Moondream try. Drop your favorite open-source vision model below (bonus if <7B and actually good at UI screenshots).
Let’s crowd-source the best eyes for autonomous testing agents 👀
#AITesting #LocalFirst #OpenSourceAI #VisionModels #LLaVA #Moondream #BakLLaVA #TestingTools #IndieDev #BuildInPublic #WebDev #TypeScript #AI #Automation #Builders #Python
24 Nov 2025

Started to work on SYMBIOTE this weekend. My goal is to give world a AI powered tester that can help all #Founder build fast and reliable product that can be consume by whole world.
still early age (literally 2 days long), but keep eyes out for daily updates and new feature.
Founders, investors, weird-systems nerds if local-first agentic runtimes excite you, come yell at me. Open to chats, ideas, or even angel money if the vibe is right 😛
#LocalFirst #CRDTs #AITesting #P2P #TypeScript #BuildInPublic #OpenSource

1
248
NEW: 🐰Into the Rabbit Hull — Part II
🚀 @Napoolar @WangBinxu & collaborators ask: Is the linear view of DINOv2 enough to explain how deep vision models actually organize information?
Read more: bit.ly/4rlgJyH
#AI #VisionModels #Interpretability
1
6
11
1,280
21 Nov 2025
WizTracking: Stop losing targets! Dahua Xinghan AI uses Multi-posture Tracking for continuous detection, even when the target’s posture changes. Always detected, always secure. tiny.cc/xinghanweb
#WizTracking #DahuaXinghan #SeamlessSecurity #VisionModels

32

16 Nov 2025
Ridicoulous discussion. Both are needed: LeJEPA a fantastic theortical work that simplifies training of visionmodels immensely as validated using pytorch
66

8 Nov 2025

1
1
3
330

👀 Built to read like a human.
DataWoz’s layered processing engine blends OCR and vision-language models to achieve human-level accuracy and dependable document intelligence. #AI #OCR #VisionModels

4
30 Oct 2025
AI WDR: Flawless images, automatically. Dahua Xinghan Vision Models use scene adaptivity to intelligently configure WDR, ensuring clear facial details and balanced exposure in any light.
See the difference: tiny.cc/xinghanweb
#DahuaXinghan #VisionModels

1
83

29 Oct 2025
มาสด้า เปิดโฉม Vision Models ยนตรกรรมต้นแบบ 2 รุ่น ครั้งแรกของโลก ในงาน Japan Mobility Show 2025
#มาสด้า #VisionModels #รถต้นแบบ #JapanMobilityShow2025 #BTimes
btimes.biz/whatsup/ม…
49