
Jun 12
🌊 Tutorial Spotlight: Everything IS an Xarray Dataset. Nick Hodgskin, Eniola Awowale & Ian Hunt-Isaak show you how to unify messy scientific data under one powerful abstraction. Your future self will thank you 💡 #SciPy2026 🔗 scipy2026.scipy.org

5
381

En el marco de la visita académica del Dr. Patrick Jantz 🇺🇸, investigador de Northern Arizona University y beneficiario de la Beca Fulbright U.S. Specialist 2025, docentes, investigadores y profesionales participaron en un workshop avanzado sobre procesamiento de información satelital con Python y xarray.
Esta jornada fortaleció competencias en análisis de datos geoespaciales, monitoreo ambiental y aplicación de tecnologías de vanguardia para afrontar los desafíos del territorio. 🚀💻
En la UCEVA continuamos apostándole a la generación de conocimiento, la ciencia y la tecnología como motores de transformación regional.


22


🔝 Huge 𝕏array is coming! 🤣
Homemade, 6m rectangle loop, flat SWR, E-sporadic ready. For now, just one element but with the approval of @grok 👻 (ghostwriter too) the next step is the 𝕏Array! Who will fund it? Elon, you still have time! 💰😎
➡️

ALT My antenna by night (real pic) 𝕏tenna

ALT My antenna by night (real pic) 𝕏tenna

...Huge 𝕏tenna array! 🤣

ALT My antenna by night (real pic)

ALT My antenna by night (real pic)
1
3
287

May 3
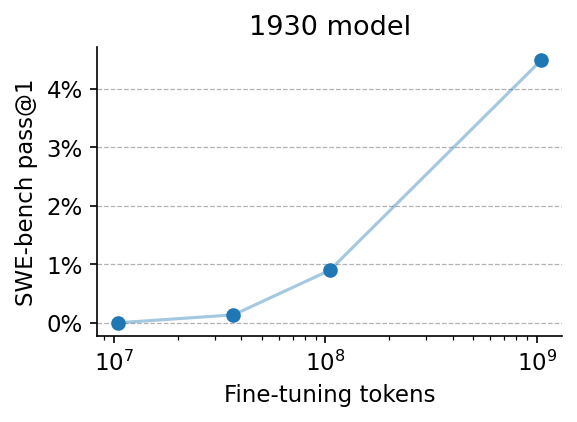
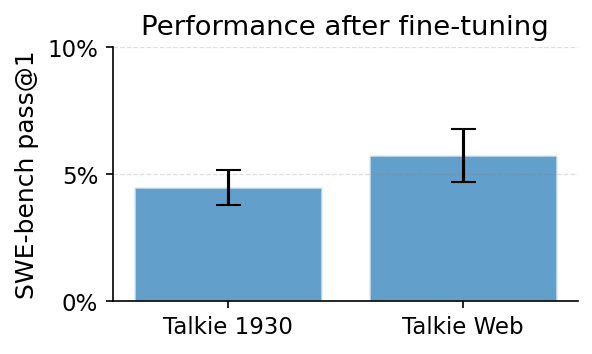
A 13B language model trained only on English text published before 1931, and never exposed to code or even the concept of a computer, reached 4.5% pass@1 on SWE-bench Verified after fine-tuning.
In experiments by Max Planck Institute for Intelligent Systems PhD student Ricardo Dominguez-Olmedo, the model solved its first real GitHub issue with just 250 training samples, fixing a patch in xarray. Scaling training to around 75,000 agent trajectories, or roughly 1B tokens, pushed performance to 4.5%.
A matched baseline with the same architecture and compute but pretrained on modern web data reached 5.75%, only about 1.3 points higher. Training ran for about 12 hours on 8 B200 GPUs with a 64K context window, and the model weights and full code have been open-sourced.
3
324

May 3
马克斯·普朗克智能系统研究所博士生 Ricardo Dominguez-Olmedo 对 Alec Radford 等人此前发布的「复古语言模型」talkie-1930(13B 参数,只用 1931 年前英文文本预训练,从未接触过代码)做了 SWE-bench 微调实验。
仅用 250 个训练样本,模型就解出了第一个真实 GitHub issue(xarray 库的一个补丁)。扩展到约 75,000 条 agent 轨迹(1B tokens)后,SWE-bench Verified pass@1 达到 4.5%。作为对照,架构和算力完全相同、但用现代网络数据预训练的 talkie-web,同样流程微调后 pass@1 为 5.75%,仅高出约 1.3 个百分点。
Dominguez-Olmedo 表示「扔掉整个互联网,损失少得出乎意料」。
训练在 8 块 B200 GPU 上跑了约 12 小时,上下文长度 64K。模型权重和完整训练代码已在 HuggingFace 和 GitHub 开源。
May 2

We fine-tuned Alec Radford’s 1930 vintage LLM to solve SWE-bench issues.
After just ‼️250‼️ training examples, the model solves its first issue, a simple patch to the xarray library.
🧵👇
2
8
66
13,178

May 3
Did you know Xarray is part of SWE-bench? We are proud of our little contribution to AI research ☺️
May 2
We fine-tuned Alec Radford’s 1930 vintage LLM to solve SWE-bench issues.
After just ‼️250‼️ training examples, the model solves its first issue, a simple patch to the xarray library.
🧵👇
4
8
475

May 2
We fine-tuned Alec Radford’s 1930 vintage LLM to solve SWE-bench issues.
After just ‼️250‼️ training examples, the model solves its first issue, a simple patch to the xarray library.
🧵👇
26
84
1,212
301,458


Just shipped a Polymarket weather trading bot skeleton in 2 hours. One Claude Code prompt. 12 files. Zero TODOs. Plus 3 useful repos.
github.com/h100envy/weather-… -> replaces 2 weeks of "I'll start tomorrow" NOAA NWS forecast discussion ingestion. Claude as probability fusion layer (mean, std, regime_uncertainty in structured JSON). 11-bin Polymarket structure with edge detection. fractional Kelly hedge layer on uncertain days. unit tests on strategy math. paper-trading only by design - impossible to send real orders, fork to enable. clone and run with one ANTHROPIC_API_KEY.
github.com/Polymarket/py-clo… -> replaces 2 weeks of API integration work official Python CLOB client from Polymarket. EIP-712 authentication. order signing. order book streaming. when you fork the skeleton above and want to enable live trading, this is what you import. there is literally no alternative.
github.com/blaylockbk/Herbie -> replaces "I'll just use the NWS endpoint" the gold standard for downloading numerical weather model data in Python. HRRR, GFS, RAP, GEFS, ECMWF in one interface. AWS / Google Cloud / NOMADS sources. xarray integration. swap it in when the simple NWS API stops being enough.
github.com/anthropics/anthro… -> replaces $5,000 in prompt engineering trial and error official Anthropic recipes for structured outputs, tool use, multi-step reasoning. when you want to upgrade the skeleton's Claude calls to use tool_use instead of JSON parsing, the patterns are here. saves you a week of trial and error.
A year ago this was 2 weeks of work for one engineer. Now it's 2 hours and a Claude Code prompt. The bottleneck for printing on Polymarket isn't capital. it's How fast you can ship.
You've made the biggest mistake of your life if you read this and didn't bookmark it.

12
1
22
987

Apr 26
After learning Pandas, Xarray, Numpy, seaborn and Matplotlib, I think now I'm a data scientist 😜
6
1
21
994

Apr 22
THIS MODEL WEATHER MARKETS = INFINITE MONEY GLITCH
You don't need expensive infrastructure to win on Polymarket.
One GPU.
15 seconds.
Better forecast than most traders are running.
I've been using this stack for weeks and the edge is real.
Here's exactly how to set it up:
The model is called Pangu-Weather.
Open weights.
Runs locally.
Produces full 10-day global forecast in 15 seconds on a single GPU.
Hardware you need:
Minimum 16GB VRAM - RTX 3090, 4080 or A4000 all work fine.
A100 40GB if you want to run continuous forecasts without interruption.
CPU inference works too but 15 seconds becomes a few minutes.
Stack to install:
Python 3.9 . ONNX Runtime. eccodes and cfgrib for parsing ERA5 files. numpy and xarray for data handling.
Weights ship as .onnx files - no PyTorch needed.
Where to get input data:
ERA5 via Copernicus CDS API. Free registration. Free data.
You need pressure fields across 13 atmospheric levels plus 4 surface variables.
Latest data has a 5-hour delay - plan your workflow around that window.
Running it:
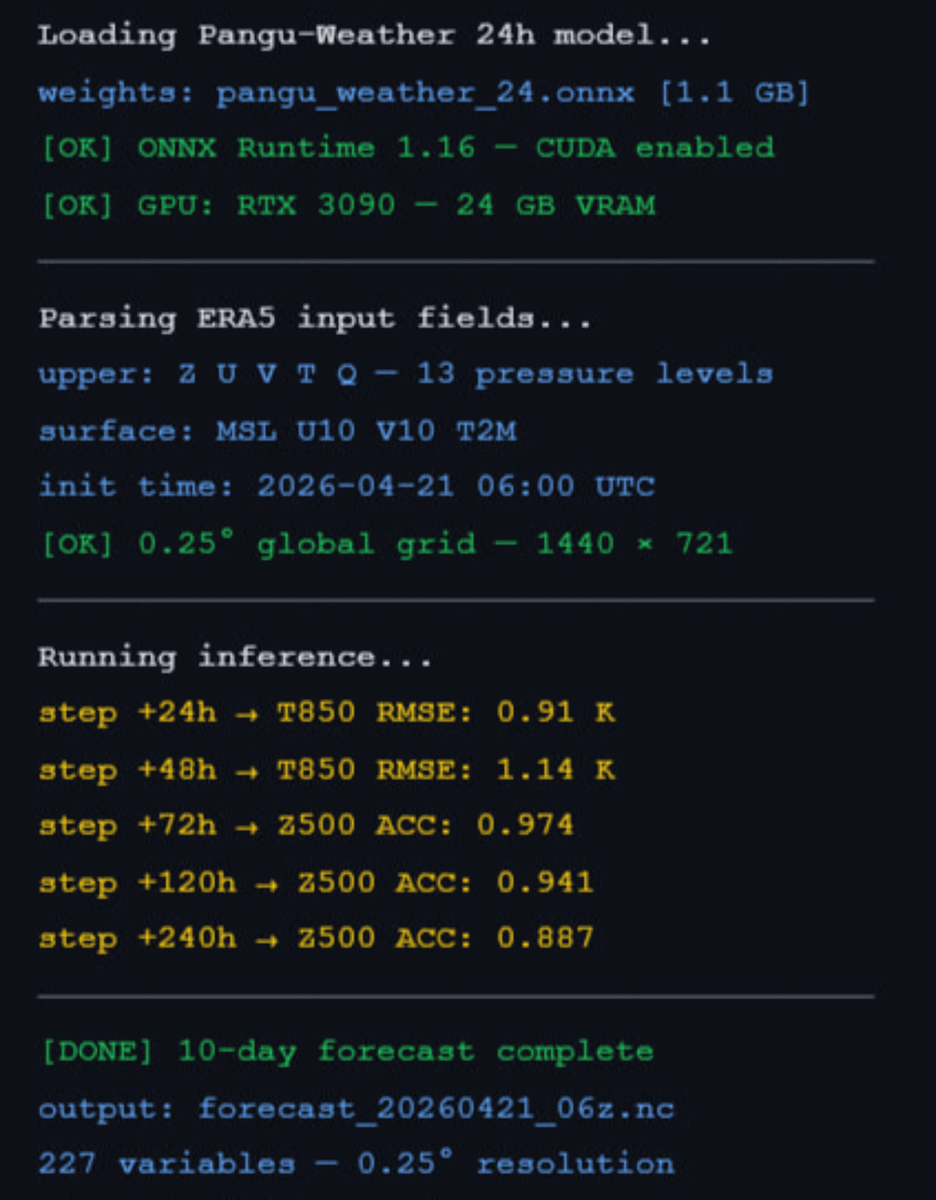
Clone the repo.
Feed ERA5 for the latest available hour into inference(.)py.
Full 10-day global forecast out in 15 seconds on an RTX 3090.
Here is the actual edge this creates on Polymarket.
ERA5 updates with a 5-hour lag.
ECMWF publishes official forecasts every 12 hours.
Pangu running on fresh ERA5 data gives you a forecast before the official update even lands.
That gap between your forecast and what the market is pricing is where the money lives.
Open weights.
Free data.
One GPU.
That's all you need to be ahead of 99% of weather traders.
Try with this market: polymarket.com/event/highest…
You will feel the difference quick.
10
5
48
3,120

Apr 21
You don't need 3,000 servers to forecast the weather
One GPU. 15 seconds. Better than ECMWF
Here's the full stack to run Pangu-Weather locally:
<<Hardware>> Minimum 16GB VRAM (RTX 3090 // 4080 // A4000)
Optimal A100 40GB for continuous runs
CPU inference works too, but seconds become minutes
<<Stack>> Python 3.9
ONNX Runtime weights ship as .onnx, not PyTorch eccodes cfgrib parse ERA5 GRIB2 files numpy, xarray data handling
<<Input data>> ERA5 via CDS API (Copernicus) free registration
You need: pressure fields on 13 levels 4 surface variables
Latest data has 5hr delay plan around it
<<Running it>> Repo includes inference. py out of the box
Feed ERA5 for the latest available hour >> 10-day global forecast
Full cycle on RTX 3090: -15 seconds
<<The edge>> ERA5 updates with a ~5hr lag
ECMWF publishes every 12 hours
Pangu on fresh data gives you a forecast before the official update lands
That gap is the trade
Open weights CDS API one GPU and you're ahead of the market
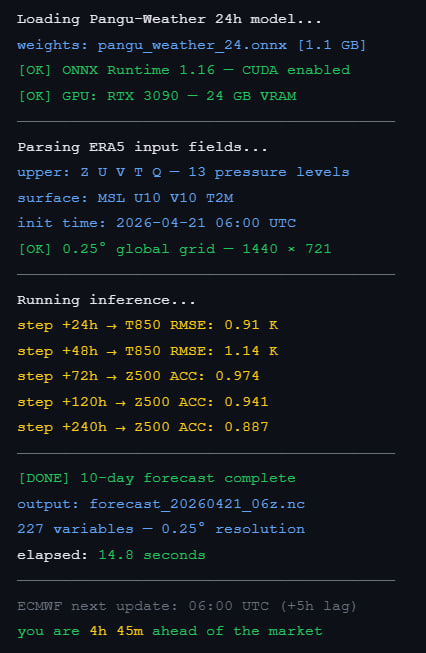
Apr 20

If you trade weather on Polymarket, you must know this model
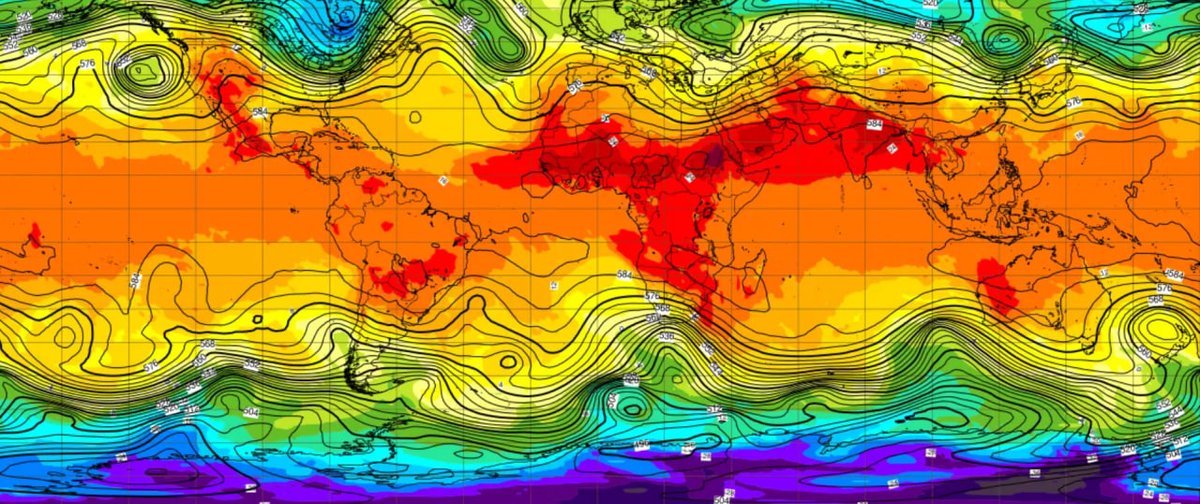
Pangu-Weather is the best AI weather model nobody talks about
How it works:
The core is a 3D Earth Transformer treats the atmosphere as a 3D grid, not a flat map. Vertical layers matter as much as horizontal ones
It ingests 40 years of satellite radar station data via ERA5 and predicts 227 atmospheric variables at 0.25° resolution
In July 2023, Nature published the paper. ECMWF added it to their public forecast page the same month
10-day global forecast in 10 seconds on a single GPU vs. hours on 3,000 servers with classical NWP
Since 2023, the weights are fully open (BY-NC-SA). You can run it locally
Pangu ERA5 live feed is the stack
Polymarket weather markets price the official forecast. Pangu runs faster than the official forecast updates. That gap is your edge
10
10
130
9,798

Apr 18
6 months to pivot into space DS:
• month 1: orbital mechanics
• months 2-3: rasterio, xarray, earth engine
• months 4-5: EO models (Prithvi, SatMAE)
• month 6: pick a lane
ship something public every 2 weeks. that's it.
1
1
16
179

Apr 13
書籍の図8.10(予測分布の確率密度関数、観測値の散布図の描画)を寄り道写経します。
xarrayを使わずにnumpy, scipyで頑張っています。
説明変数のうちyearとmodel_nameを定数で固定して、odometerのみを変数にしています。
(つづく)

1
6
122
Apr 13
Perfect! Here comes my friend who talks pandas, numpy, xarray, seaborne and matplotlib.
5
1,394

Apr 13
BestBlogs 早报 | 2026-04-13
# Sam Altman 深度反思 / AI 时代残酷真相 / MiniMax 开源 / Agent Memory / Agentic Web
[1] Sam Altman:燃烧弹袭击后的深度反思
OpenAI CEO 住宅遭遇燃烧瓶袭击后,罕见地公开家人照片并发表长篇反思。他坦承在处理与 Elon Musk 及前董事会冲突中的失误,提出 AGI 愿景具有「魔戒」般的诱惑力——唯一的解法是尽可能广泛地共享技术,避免权力集中。一篇兼具个人剖白与行业呼吁的重要文章。
来源:Sam Altman | 评分:92
bestblogs.dev/article/f448db…
[2] AI 时代的残酷真相 | Keith Rabois (Khosla Ventures) [视频]
PayPal 黑帮成员、传奇投资人 Keith Rabois 在 Lenny's Podcast 上抛出尖锐观点:传统产品经理角色正变得毫无意义,核心技能已转变为「决定构建什么以及为什么」。他的「枪管 vs. 弹药」框架认为,只有少数人能独立将想法从概念推向成功,而这些人决定了公司的并行执行能力。
来源:Lenny's Podcast | 评分:92
bestblogs.dev/video/ee15307
[3] MiniMax M2.7 开源 Music 2.6 发布:模型与音乐双线突破
MiniMax 连发两弹:M2.7 模型正式开源,具备自我进化能力,能自行构建复杂 Agent Harness,首日即完成华为昇腾、NVIDIA、Together AI、Ollama 等主流芯片和推理平台的适配。同期发布的 Music 2.6 则在国风器乐时序、游戏配乐结构控制、Cover 风格改编等方面取得突破,并开源了三款 Music Skill 让 AI Agent 原生调用音乐生成能力。
来源:MiniMax 稀宇科技 | 评分:92
另见:「MiniMax Music 2.6:我们想讲四个人的故事」
bestblogs.dev/article/e07e57…
[4] 这大概是我读过最硬核的一次 Linux 内核重构文章了
腾讯 TencentOS 内核工程师对 Linux Swap 子系统的 18 个月系统性重构:引入 swap table 替代 XArray 带来 5%~20% 性能提升,移除 swap map 节省约 30% 内存开销。文章还对比了腾讯 Virtual GhostSwap 方案与 Meta 方案,展现了大规模生产实践驱动内核创新的完整图景。
来源:腾讯技术工程 | 评分:92
bestblogs.dev/article/c67b2a…
[5] 那个「爱马仕」,想拯救「智障」小龙虾
以 Hermes Agent 为引子,对 Skill 自主进化叙事提出质疑。核心论点:当前 Agent 昂贵、不稳定的根源在于过度依赖语义层(Skill)去完成本应由确定性工具(CLI)完成的任务。为 Agent 设计的 CLI 需要结构化输出、异步支持、幂等性——将 Web/桌面/移动端常见流程「CLI 化」才是降低 token 消耗的现实路径。
来源:腾讯科技 | 评分:91
bestblogs.dev/article/c026ac…
[6] 你的 ReAct 智能体正在浪费 90% 的重试机会——以下是解决方法
通过 200 项任务模拟证明,简单的 ReAct 智能体将 90.8% 的重试预算浪费在永远不可能成功的错误上,根因是让 LLM 在运行时输出工具名称字符串导致的幻觉。三种结构性修复:错误分类(可重试 vs. 不可重试)、按工具熔断器替代全局计数器、将工具路由移至确定性代码。修复后浪费重试降至 0%,步骤方差降低 3 倍。
来源:Towards Data Science | 评分:92
bestblogs.dev/article/bbe5a0…
[7] 浅谈 Agent Memory
从认知科学根基出发,系统剖析 Agent 记忆的完整生命周期。核心观点:记忆不是简单的存储与检索(RAG),而是「对过去的持续再解释」,需要经历写入、整理、读取的完整循环。文章深入探讨了「原始材料 vs. 派生材料」的权衡、高质量「遗忘」的重要性,以及记忆如何通过 Skills 固化为可复用能力。
来源:浮之静 | 评分:92
另见:「停止将 AI 记忆视为搜索问题」(Towards Data Science)
bestblogs.dev/article/2e49e0…
[8] 500 Tbps 容量:Cloudflare 全球网络 16 年的扩展历程
从早期传输对等互联到每秒 500 太比特外部互联容量的里程碑。技术层面详解了 eBPF、XDP 和分布式守护进程的 DDoS 缓解管道(最近一次抵御 31.4 Tbps 攻击),以及 RPKI、ASPA 等前瞻性路由安全协议。值得关注的新趋势:AI 智能体和爬虫流量已占网络流量的很大一部分。
来源:The Cloudflare Blog | 评分:92
bestblogs.dev/article/5a64e6…
[9] AI 没有杀死 Web,它只是搬进来了 [视频]
来自 AWS 和 Microsoft 的专家在 AI Engineer 大会上描绘「Agentic Web」转型:AI 通过 MCP 协议直接控制 Chrome DevTools 进行自动化调试和性能审计;W3C 即将推出的 Summarizer、Proofreader 和 Language Model API 让 LLM 在浏览器内本地运行;llm.txt 成为 AI 智能体的结构化站点发现入口。
来源:AI Engineer | 评分:91
bestblogs.dev/video/8d1ae44
[10] Garry Tan 开源 GBrain:个人微型 AGI 知识库 @garrytan
YC 总裁亲自下场开源的 AI 工具,基于 Bun Supabase OpenClaw 构建。支持实体检测和大脑代理循环(brain-agent loop),定位为提升个人生产力的「微型 AGI」知识库。Tan 还提出了「即时代码」(Just-in-Time Code)概念——将 Markdown 视为可执行指令,让 Agent 自我实现功能。
来源:@garrytan | 评分:91
另见:「GStack:MIT 许可的开源软件工厂」
bestblogs.dev/status/2042369…
---
BestBlogs.dev - 遇见更好的技术阅读
1
2
609

Apr 10
My understanding is Impinj uses phased-array antennas, but only in specialized readers (xArray/xSpan)
When phased arrays make sense
•location tracking (x, y position)
•direction of motion
•High-value environments (retail analytics, hospitals)

99

Apr 6
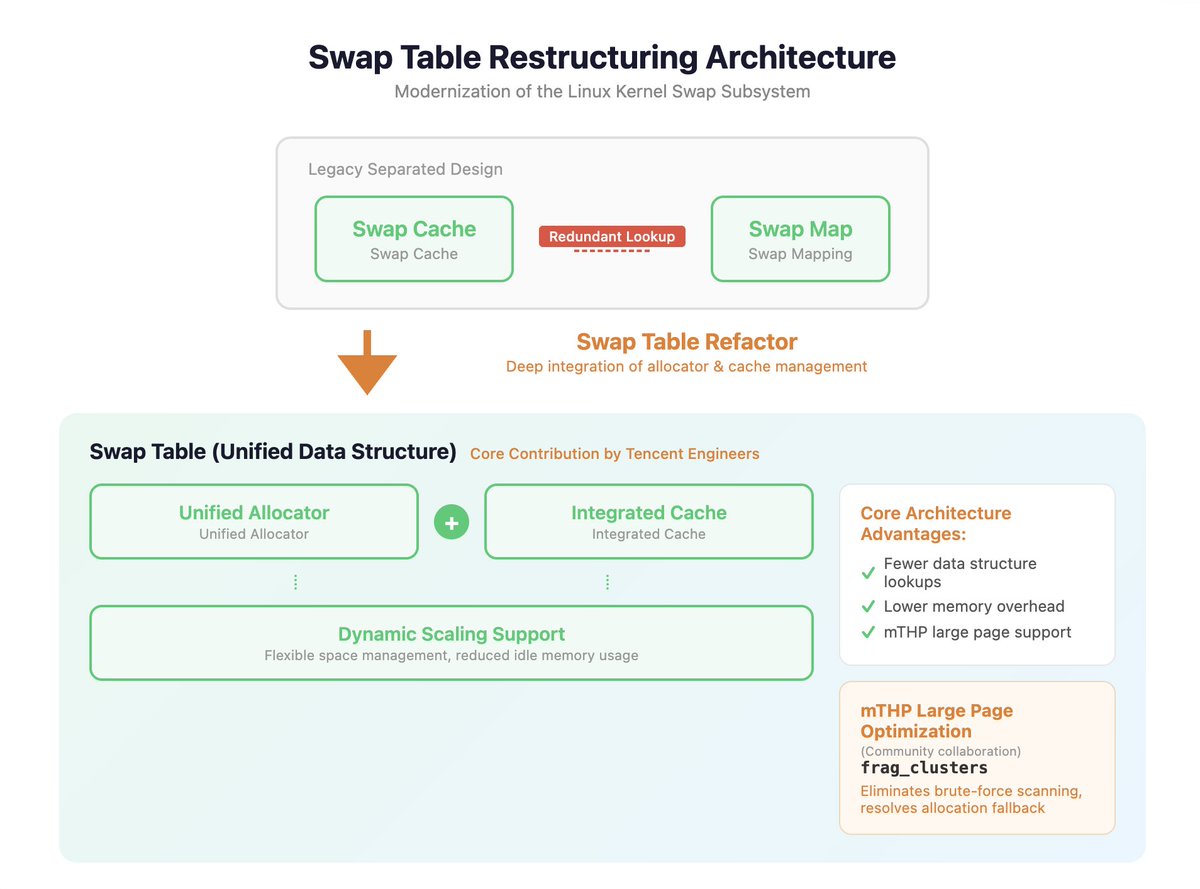
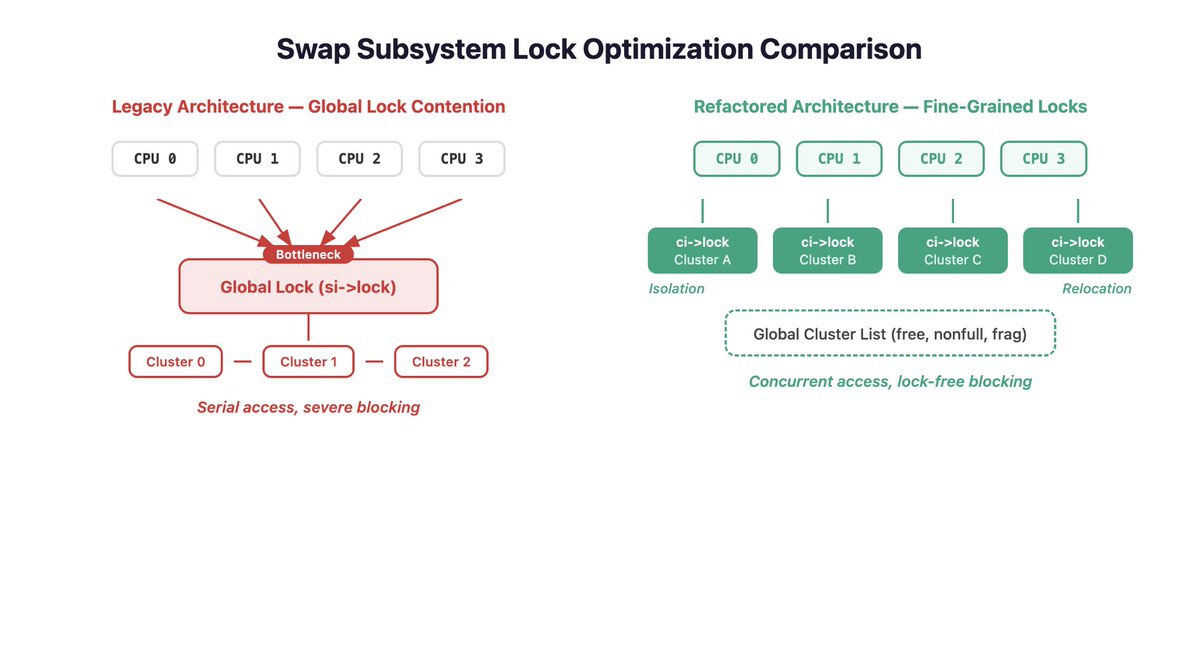
The Linux Swap Subsystem has grown notoriously complex over the years.
Kairui Song, kernel engineer at Tencent (TencentOS), took it on.
18 months. A deep restructuring. Results already landing upstream:
→ Swap table merged into Linux 6.18, replacing the legacy XArray structure — 5%–20% performance gains
→ Swap map removal targeting Linux 7.1 — ~30% metadata memory overhead saved
→ Full subsystem rebuild on a cleaner, more efficient architecture — well underway
LWN.net's Jonathan Corbet wrote a detailed three-part series on the full journey. Worth a read if you're into kernel internals.👇
lwn.net/Articles/1059201/
2
8
44
6,369