
Joined May 2018
- Tweets 3,140
- Following 2,233
- Followers 5,193
- Likes 4,043
443 Photos and videos













3m
谷歌研究人员与加州大学圣迭戈分校(UCSD)团队正在探索手机集群计算(phone cluster computing),计划将 2000 部退役 Pixel 智能手机的主板重组为低碳云数据中心,为师生提供低成本、低碳的云计算资源。
智能手机更新周期通常为四年,但退役设备的计算核心依然完好,CPU 核心性能已接近现代服务器核心,在 SPEC CPU 2017 部分单线程测试中表现相当。为了适应数据中心环境,研究团队拆除了旧手机的屏幕、电池、外壳和摄像头等非必要组件,仅保留主板部分,因为主板制造过程贡献了整机制造端的大部分隐含碳排放(embodied carbon),同时也规避了电池在数据中心里的安全隐患。
在软件层面,团队使用通用 Linux 发行版替换了原装 Android 用户空间,从而绕过针对移动端设计的「低内存杀手」(Low Memory Killer)等内存限制和保护机制。硬件管理上,每 25 至 50 部手机主板被划分为一个自管理集群,通过 Kubernetes 进行容器化应用调度。根据 SPEC CPU 2017 测试结果,25 至 50 块手机主板组成的集群在整体 CPU 吞吐能力上已接近一台传统服务器。
前期实验表明,仅用 20 部旧手机建的微型集群,就能轻松应对 75 人班级的作业提交高峰,打分速度甚至快于 AWS 云实例。按团队估算,2000 部手机组成的系统整体算力约相当于 50 台传统服务器,可同时支持上百门系统编程及并行计算课程的教学与研究。
整个系统预计于 2026 年秋季正式上线,届时将作为长期运行测试平台,用以评估消费级硬件在持续高负荷下的硬件可靠性。
Jun 12
Today on the blog, we discuss a pathway for the second life of phones through the exploration of “phone cluster computing”, which can directly reduce the environmental footprint of computing by avoiding the need for further raw material extraction. More →goo.gle/4aJe5vO
14
42m
Databricks 以 Apache 2.0 协议开源 Agent 元排布框架 Omnigent。Omnigent 运行在 Claude Code、Codex 和 Pi 等现有 Agent 排布工具之上,能将不同框架下的智能体转化为可互操作的系统组件,解决各工具接口互不兼容、协作与管控困难的行业痛点。
Omnigent 在元排布层(meta-harness)直接实施有状态的管控策略,摆脱了对提示词的依赖。系统支持根据动态状态执行安全控制,例如在智能体下载 npm 依赖包后拦截 git push 动作并请求人工审批,或通过设置 LLM 成本限额在累计开销达到 100 美元时暂停运行。为防止敏感信息泄露,框架还集成了可拦截并转换网络请求的操作系统沙箱。
为支持团队协作,Omnigent 提供了基于 URL 的实时会话分享,允许团队成员在同一工作区内查看历史、评论文件或协同发送指令。用户可以通过 Web 网页、移动端、macOS 原生应用以及 API 与已部署的智能体交互,并支持在本地或 Modal、Daytona 等托管沙箱中运行。

Introducing 𝗢𝗺𝗻𝗶𝗴𝗲𝗻𝘁, a meta-harness to combine, control, and share your agents.
The best teams already mix models and harnesses and design loops that drive teams of agents. No single harness can keep up with that alone. So we built the layer above — we call it a 𝗺𝗲𝘁𝗮-𝗵𝗮𝗿𝗻𝗲𝘀𝘀.
Omnigent sits above the tools you already use, Claude Code, Codex, Pi, and your own agents, and gives them one shared layer:
• 𝗖𝗼𝗺𝗽𝗼𝘀𝗶𝘁𝗶𝗼𝗻: combine models, harnesses, and techniques without rewriting code, and switch between them with one-line changes
• 𝗖𝗼𝗻𝘁𝗿𝗼𝗹: stateful, data-centric policies and cost budgets enforced at the meta-harness layer, not via prompts — let agents run without watching them
• 𝗖𝗼𝗹𝗹𝗮𝗯𝗼𝗿𝗮𝘁𝗶𝗼𝗻: share a live agent session via URL with full history, so teammates can review, comment, and steer in real time
Every session is reachable from a terminal, the web, a desktop app, and your phone.
We built Omnigent for our own use at Databricks and are open sourcing it under Apache 2.0. databricks.com/blog/introduc…

105
45m
OpenRouter 推出 Fusion 复合模型接口,支持将用户提示词并行分发给多个大语言模型,再通过裁判模型与合成模型输出最终解答。
在 Perplexity AI 发布的 DRACO 深度研究基准测试中,基于 Fusion 的多种模型组合展现出对传统单模型的压制力。
在各项配置中,将 Fable 5 与 GPT-5.5 组成面板并在 Opus 4.8 的合成下取得了 69.0% 的最高分,显著超越了 Fable 5 单模型运行的 65.3% 成绩。
测试表明,由于不同厂商模型的底层训练与逻辑差异,多模型混搭的多样性在复杂任务中能带来更强的视角互补。
即使是同一种模型进行左右互搏也表现出明显增幅,将 Opus 4.8 与自身组成双面板进行自我合成,得分能从独立运行的 58.8% 提升至 65.5%。
对于高性价比需求,由 Gemini 3 Flash、Kimi K2.6 与 DeepSeek V4 Pro 组成的低成本面板同样在合成下取得了 64.7% 的分数,在调用成本减半的情况下,与 Fable 5 的差距缩短至 0.6 个百分点。
基准测试包含 10 个维度的 100 项复杂研究任务。为了防止模型在检索时意外获取评测标准导致得分失真,OpenRouter 在 API 服务端为所有模型统一启用了检索域名屏蔽列表。
目前 Fusion 已对 API 用户开放,默认标识符为 openrouter/fusion,用户也可在网页端自定义参与合成的模型面板。

Introducing the Fusion API, the smartest compound model in the market.
Fusion achieves Fable-level intelligence at half the price.
How it works 👇

198
1h
巴西里约市政府旗下 IT 公司 IplanRIO 在 Hugging Face 开源了 3970 亿参数大模型 Rio-3.5-Open-397B。模型基于阿里 Qwen 3.5 397B 架构,采用混合专家(MoE)设计,单 Token 激活参数仅 170 亿,可低成本处理百万 Token 上下文。
模型集成了无需二次训练的 SwiReasoning 推理技术,可像人类一样动态切换思考模式。面对简单问题直接输出最终答案(显式推理),面对复杂逻辑或代码则切换到不可见的隐藏层进行多路径深度思考(隐式推理)。动态切换机制能显著减少无意义的思考文本,提升生成速度与 Token 效率。
评测数据显示,开启隐式推理的 Rio-3.5-Open-397B 在 SWE-Bench Pro 中拿到 58.1 分,在 IMOAnswerBench 中达到 89.5 分。作为对照,Qwen 3.5 397B 原版得分仅为 50.9 和 80.9,仅微调且不启用隐式推理时则为 54.8 和 84.5。隐式推理让模型相对基座的提升幅度直接翻倍。
不过,隐式推理暂时还不能跑在本地。开发团队在 Hugging Face 讨论区确认,SwiReasoning 推理需要处理概率加权的连续「软嵌入」向量,而 llama.cpp 等主流本地运行引擎只支持离散 Token ID 生成。这意味着,如果用户使用常用引擎部署,Rio-3.5-Open-397B 只能以普通的微调状态运行。团队目前正推动各推理框架进行适配,以早日让用户体验完整的隐式空间推理。

SITUATION DETECTED: The city of Rio de Janerio has post-trained a model.
Based on Qwen 7/2, Rio 3.5 Open 397B adds SwiReasoning on top of the base Qwen model — a framework that dynamically switches between standard chain-of-thought and latent-space reasoning, guided by entropy-based confidence signals, so the model only "thinks out loud" when it needs to and otherwise reasons silently in hidden space for better token efficiency.
206
1h
Claude Fable 5 刚发布三天便被白宫紧急下线,源于大股东亚马逊的一次致命告密。美东时间周四,亚马逊 CEO 安迪·贾西直接致电财政部长贝森特,声称其研究团队成功使用提示词绕过 Fable 5 的外层防护,直达底层 Mythos 5 模型,并诱导其生成能挖掘软件漏洞的输出与自动测试脚本,最终通过多步过程转化为漏洞利用验证(PoC)代码。
美东时间周五上午,该漏洞事件直接惊动白宫最高层。白宫幕僚长苏西·威尔斯紧急召集闭门会议商讨应对方案,而正在前往休斯顿途中的财长贝森特则在行程中远程接入。会议期间,白宫将越狱测试数据送交国家安全局(NSA)进行评估,NSA 随后向白宫确认证据确凿,漏洞具备实质性的网络武器级杀伤力。会后,白宫十万火急寻找 Anthropic 创始人兼 CEO 达里奥·阿莫代,却发现其「处于失联状态」。有白宫官员声称阿莫代当时正在参加一个「静修疗养营」,但 Anthropic 方面随后愤怒驳斥这一说法「纯属捏造」,并解释称阿莫代在中午接到联络请求后,已于一小时内火速连线,且失联期间公司已主动提供其他高管作为替代。
危机在美东时间周五下午 1:00 彻底爆发。白宫方面倾巢而出,包括商务部长卢特尼克在内的半数核心内阁成员对阿莫代发起了多达三轮的密集电话施压。在多方连线中,国安顾问凯恩克罗斯强硬要求阿莫代自愿下架模型。阿莫代极力自辩,坚称这仅是特定场景的绕过,而非灾难性的「通用越狱」,指责政府反应过度。这番自辩令白宫官员感到极为讽刺。阿莫代此前曾多次在政策游说中将 AI 风险比作「原子弹」,如今面对真实漏洞却试图大事化小。交锋中,贝森特直接警告阿莫代,称其正做出一个「极其愚蠢的决定」,并强行甩下 90 分钟的物理下架死限。
双方的说辞在事后陷入罗生门:白宫官员声称出口管制是在「恳求数小时无果后」的无奈之举;而接近 Anthropic 的知情人士则怒斥白宫蛮横,「直接丢来一个不给任何技术细节的 90 分钟物理死亡期限,根本没有留出任何协商余地」。谈判破裂后,特朗普政府于周五下午 5:30 正式签发紧急出口管制令,被迫低头的 Anthropic 最终于当晚 10:00 彻底物理断网。随后,公司发布官方声明,怒斥政府此举「不公平、不透明且不尊重技术事实」。
作为 Anthropic 最大外部投资方的亚马逊,亲手做空自己重金持股的 AI 盟友,背后是资本利益的彻底倒戈。亚马逊此前虽给 Anthropic 投资了 130 亿美元,但今年其又向 Anthropic 的竞争对手 OpenAI 投入了高达 500 亿美元的巨资,并获准在 AWS 上转售其最新模型。这笔巨额交易,直接让对 Anthropic 的致命举报,变成了亚马逊为新欢清扫障碍、为其 500 亿美元豪赌强行保驾护航的投名状。
对特朗普政府而言,这次告密则正中下怀。白宫对这家充满自由派色彩的 AI 创企积怨已久:Anthropic 深度雇佣了拜登时期的官员,其创始人也曾公然批评过特朗普。更深层的冲突在今年 3 月就已爆发,当时 Anthropic 强硬拒绝让其模型用于大规模国内监视和致命自主武器开发,因而被五角大楼定性为供应链风险,双方至今官司不断。因此,在网安官员游说下,特朗普总统最终签字批准了禁令。
这道出口令随后产生了一个极其荒诞的副作用:由于限制任何「外国国民」访问,连 Anthropic 内部大批来自英国、加拿大等盟国的核心研发骨干也被阻断了系统权限,导致其技术团队当场停摆。对于正全力筹备秋季上市(IPO)的 Anthropic 来说,白宫的这记重拳几乎提前判了其商业计划的死刑,而空出的市场真空,正被身后的 OpenAI 迅速蚕食。

NEW: Inside the 24-hrs before WH slapped export controls on Anthropic
- Last Thursday, Amazon CEO Andy Jassy raised concerns about Fable jailbreak to Trump admin
- Friday AM, Sean Cairncross, Bessent, Susie etc. held WH call to discuss
- Then White House started reaching out to Anthropic to speak with Dario Amodei, who was at a wellness retreat.
- When Amodei was finally available past 1pm, he had three tense phone calls with a combo of ppl including Cairncross, Bessent, Lutnick, Kessler, Will Scharf, Richard Walters, and Walker Barrett.
-Amodei tried to clear up what he assumed was a misunderstanding. He defended the guardrails and distinguished between universal and non-universal jailbreak
- Cairncross and Bessent were unmoved and asked Amodei to take down Fable and work with the admin to fix the vulnerabilities. (A WH official said Amazon’s findings were run past the NSA and they felt they had “proof.”)
- Amodei asked for more time and info, but he made no commitments to pull the model
- Bessent told Amodei directly at one point that he was making a “bad decision”
- By Friday evening, the Trump admin imposed its export controls.
- “Export controls were a last resort after begging them for hours to work with us,” senior WH official said.
W/ @cheyennehaslett
politico.com/news/2026/06/13…
2
580
2h
知名科技投资人查马斯·帕里哈皮蒂亚(Chamath Palihapitiya)指出,白宫对大模型的出口禁令,实质上为传统云巨头提供了借助政策「干掉」前沿 AI 实验室的绝佳博弈契机。谷歌、亚马逊、微软等初代科技巨头,将迎来借助政府安全监管、掐断独立实验室自主分发通路的历史契机。巨头们的最终图谋,是借此要求大模型托管于 AWS、Azure、GCP 等自家云服务内,并配合极严苛的 KYC(了解您的客户)身份审核,从而让自己转型为 AI 分发与合规的终极看门人。
独立实验室如今的被动,源于其过去数年因资本惰性而刻意忽略的合规防御。它们之所以在多年前拒绝主动实行严格的 KYC 限制,是为了防止用户增速和营收指标下滑,以免拉低融资估值或稀释创始人股权。然而,这种维持虚高估值的短视行为最终作茧自缚,它们在失去商业自主权的同时,依然要面临估值的缩水。
帕里哈皮蒂亚强调,云巨头对前沿实验室的潜在生态绞杀,恰恰为开源 AI 与 CoreWeave 这样的新型算力云(Neoclouds)创造了历史性的生存窗口。但目前 Neoclouds 玩家的进展相对零散、规模过小,如果不能在这一关键时刻迅速填补市场真空,AI 行业的话语权将很快被巨头完成收编,独立大模型实验室也将退化为失去自主生存能力的底层研发车间。

Game theory from here is super interesting:
Original Mags (Google, Amazon, Microsoft, Meta) now have a serious non-zero opportunity to tank the frontier labs.
Go to the government, kneecap the labs’ motion of putting the latest models out in the wild, become the trusted gatekeeper between the labs and the public at large (including internationally) by having the labs go through their clouds (AWS, GCP, Azure) and implement strict KYC to seal the deal.
The frontier labs should have seen this coming years ago and implemented a robust KYC for just this moment. The fact they didn’t is kind of concerning.
Why did they not do it?
Best guess is because it would have changed the run-rate revenues (downward) which would have then changed funding dynamics - lower valuations, more dilution, less secondary.
A valuation reset may happen now anyways, except the labs may end up with less control and more restrictions at the end of it. At the same time, everyone is already clamoring about token prices of the old models from the labs anyways…
This couldn’t be a better setup for open source and neoclouds. Big question is can they meet the moment?
There are too few of them and their progress seems sporadic at best.
283
13h
OpenRouter推出服务器端代理工具`openrouter:subagent`并开启测试,支持大模型在生成内容的中途将独立子任务派发给更小、更便宜且更快的候选模型。当主模型遇到无需自身完整能力的自包含任务时(例如文档摘要、结构化数据提取、模板起草和文本格式化),可以通过输入任务名称(task_name)和任务描述(task_description)调用代理工具。派发出的子任务由工作模型执行,并以结果(outcome)形式返回给主模型以供后续整合。
工作模型可以是任意OpenRouter支持的模型,不仅由工具定义中的`parameters.model`指定,在未设置时也可直接继承主模型。为了增强执行能力,工作模型还能配备独立的OpenRouter服务器端工具(如联网搜索`openrouter:web_search`或网页抓取`openrouter:web_fetch`),从而在生成最终文本前先在沙箱环境中进行多步骤推理与数据获取。由于工作模型在服务端执行,因此不支持需要客户端执行器的自定义函数工具。
由于工作模型无法访问主模型的上下文会话,也无法在不同任务之间共享内存,主模型必须在任务描述中提供完整的背景信息与输出格式要求。为了防止模型嵌套调用导致无限递归与成本失控,OpenRouter引入了双重防护机制:在定义中禁止自引用,并通过请求头限制嵌套深度,在子任务调用中强行剥离代理工具。同时,单次API请求中的任务执行总数也设置了硬性上限。
Jun 13
New server tool: Subagent 🤖
Your model can now delegate focused sub-tasks to a smaller, cheaper, faster model mid-generation.
The big model orchestrates, the subagent executes. The subagent can use any model on OpenRouter.

2
5
840
13h
Artificial Analysis 发布行业首个智能体(Agent)硬件基准 AA-AgentPerf。传统评测如同单次问答「短跑」,只看响应速度;智能体任务则像「接力跑」,AI 需自主拆解目标,在读写文件、改写代码、运行测试中反复流转。频繁交互对服务器内存容量和调度效率挑战极高。基准通过重放真实编程轨迹,以「每兆瓦功耗支持并发智能体规模」为核心能效指标,直击数据中心电力与资金瓶颈。
首期测试运行 1.6 万亿参数开源模型 DeepSeek V4 Pro。结果显示,英伟达 Blackwell 液冷整柜系统 GB300 NVL72 每兆瓦功耗可承载 6.14 万个并发智能体,而上一代 Hopper HGX H200 仅能支持 2600 个,能效提升超 20 倍。单显卡并发容量也提升了 41 倍。这使得在同等电力预算下,数据中心可多承载 20 倍智能体并发规模,大幅拉低自动编程和客服等应用落地成本。
首批成绩中,AMD Instinct MI355X 暂时落后。评测机构指出,AMD 与 H200 配置均使用通用开源 vLLM 框架搭建,未作深度优化;随着服务框架与内核算子适配跟进,AMD 性能仍有提升空间。目前,Together AI 等推理商已率先在 Blackwell 部署 DeepSeek V4 Pro,为智能体编程工具 Cursor 提供实时推理支持。

Today we're releasing the first results for AA-AgentPerf, our new agentic inference benchmark: initially covering DeepSeek V4 Pro across NVIDIA Blackwell, Hopper, and AMD.
AA-AgentPerf is the first benchmark built for agentic inference. We use real, long-context agentic coding trajectory data as the workload, and inference with real production optimizations such as KV cache reuse and speculative decoding, leading to the most realistic evaluation of inference performance available today.
AA-AgentPerf’s lead metric is Agents per Megawatt. In a power-constrained world, this answers the most relevant question for AI infrastructure providers - “how many real agents can I deploy per unit of power available?”.
First results for DeepSeek V4 Pro (at the easiest defined service level of 20 tokens/s and 10s TTFT):
➤ GB300 (rack-scale, disaggregated): 61,354 Agents/MW
➤ B300 (single node, disaggregated): 21,053 Agents/MW
➤ MI355X: 3,551 Agents/MW
➤ H200: 2,594 Agents/MW
Further AA-AgentPerf details:
➤ Real agent workloads, beyond synthetic queries: AA-AgentPerf replays real coding agent trajectories where our agents used up to 200 turns and worked with sequence lengths >100K tokens - the workloads that matter in 2026
➤ Production optimizations allowed: KV cache reuse, speculative decoding, and prefill/decode disaggregation are all permitted, with accuracy verification to control for quality loss - we want results to reflect what real deployments actually look like
➤ Lead metric is Agents per Megawatt: simultaneous agents supported at production performance targets (e.g. 20 tokens/s per user, ≤10s TTFT) per megawatt consumed. Agents per TCO and $/hr will be supported soon
Key findings:
➤ Rack-scale disaggregated inference (GB300) is ~3× more power-efficient than single-node Blackwell (B300), and similarly ahead in raw agents per GPU
➤ Blackwell represents a large generational step over Hopper in both power efficiency and raw compute per GPU
➤ In this test, NVIDIA's Blackwell systems currently lead AMD MI355X by a clear margin. Important context: our MI355X configs are approximately two weeks older than our Blackwell configs and couldn’t stably use speculative decoding. MI355X power draw under heavy load is also well below TDP, indicating there is much room to improve on DeepSeek V4 Pro, which we will measure and publish in the coming weeks
➤ Config and inference framework version matter enormously - we've seen meaningful improvements daily since the DeepSeek V4 Pro release and look forward to tracking performance over time
AA-AgentPerf is a live benchmark and we publish results on a rolling basis as submissions come in. Some of the new features coming in v1.1: more models (gpt-oss-120b), more hardware (GB200, B200, H100, MI300X), better AMD configurations, $/hr and cost-per-task normalization, Agents per TCO, and performance tracking over time.

1
1
2
693
18h
智谱 AI 的最新旗舰模型 GLM-5.2 已向 GLM Coding Plan 全量用户开放,覆盖 Lite、Pro、Max 和 Team 计划。
GLM-5.2 模型支持 1M 上下文,并提供 High 和 Max 两档思考强度。官方建议代码任务使用 Max,以提升复杂工程任务中的推理深度和稳定性。
API 和 Chatbot 服务将在下周上线,模型权重也将同时按 MIT 协议开源。

Intelligence should be open, accessible, and ready to build with, empowering every developer, everywhere.
GLM-5.2 is now available to all GLM Coding Plan users, including Lite, Pro, Max, and Team plans.
docs.z.ai/devpack/latest-mod…
As our new flagship model, GLM-5.2 delivers powerful coding capabilities, usable 1M-context support, and continued strengths in long-horizon tasks.
API and Chatbot services will launch next week. The model will also be officially open-sourced next week under the MIT License.
The future of AI is open, and it belongs to the people.
842
Jun 13
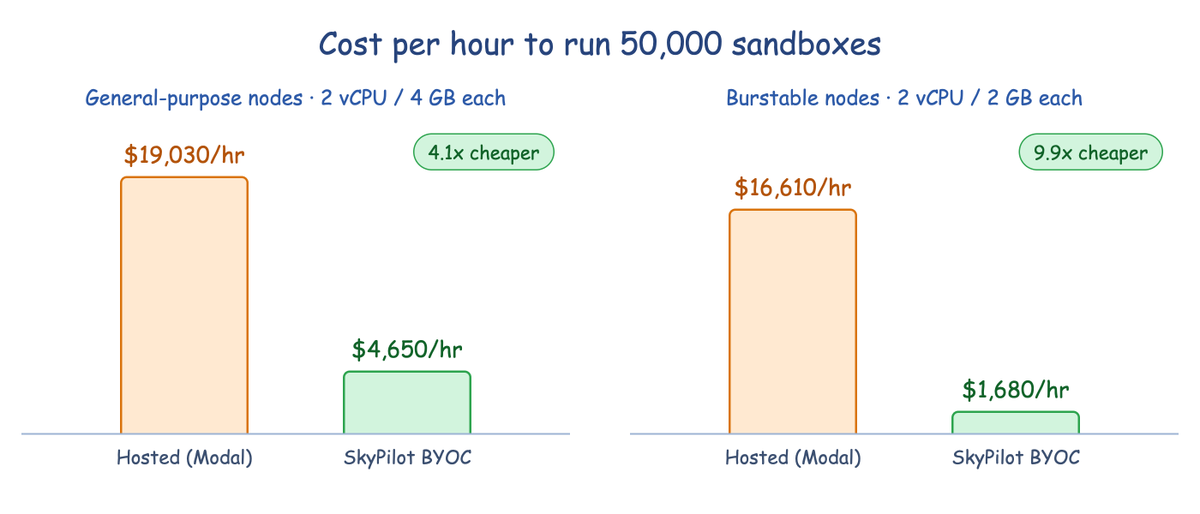
开源 AI 资源管理器 SkyPilot 推出代码运行沙箱服务 SkyPilot Sandboxes,支持企业在自己已有的云服务器集群(Kubernetes)上安全运行 AI 生成的代码。服务允许企业自主掌控计算资源,无需将包含敏感 prompts(提示词)和机密数据的代码发送给第三方沙箱托管商,且单个集群可同时运行超过 50000 个隔离的沙箱环境。
相比第三方托管沙箱,SkyPilot Sandboxes 将指令执行的就绪延迟缩短了约 20%。通过预先保持容器处于待命状态的「暖池」机制,创建沙箱并运行首条指令的时间在常见情况下仅需 1.0 秒,优于竞品 Modal 的 1.2 秒。由于服务直接运行在企业本地的云网络中,亚太等地区的用户可以彻底避免跨太平洋的数据传输延迟,将响应速度提升至本地级别。
在运行成本上,由于无需支付第三方服务商的溢价,SkyPilot Sandboxes 比托管模式便宜 4 至 10 倍。在同时运行 50000 个沙箱的大规模场景下,第三方托管服务每小时收费约 16610 至 19030 美元;如果使用 SkyPilot 将沙箱部署在企业自有的通用云服务器上,每小时成本将降至 4650 美元(费用降低 75%);若进一步部署在 AWS t4g.medium 等适合间歇性任务的廉价服务器上,每小时费用可降至 1680 美元,相比托管服务便宜近九成。此外,沙箱支持对接 SkyPilot 密钥管理器,运行时所需的凭证可直接注入,避免硬编码泄露风险。
当企业在训练能够编写代码的 AI 模型时(例如强化学习训练),需要在极短时间内运行成千上万个由 AI 刚刚写出的、未经验证的代码以进行打分。将沙箱集群直接部署在靠近 GPU 显卡的物理服务器上,能有效缩减数据传输时间,大幅缩短模型训练周期并降低网络带宽成本。目前服务已开启早期限量测试申请,项目官方仓库也提供了对应的完整训练样例。
Jun 12

Sandboxes are all the rage (Modal, E2B, AWS, ..). Most AI teams pay a >4x markup to run sandboxes on someone else's machines.
Introducing SkyPilot Sandboxes — Run BYOC sandboxes on your own clusters.
• 50,000 sandboxes on a single cluster
• Sub-second launches with warm pools
• Great for RL rollout (keep sandbox clusters close to GPUs)
Benchmark shows @skypilot_org Sandboxes are 4-10x cheaper than Modal at lower latency. Full results in blog.
1
556
Jun 13
Meta Platforms 计划通过限制员工的 Token 使用额度,来管控公司内部飙升的 AI 成本。根据一份泄露的内部备忘录,Meta 正在构建一个名为 AI Gateway 的中央网关,用于实时监控员工的 AI 用量与支出、设定预算并对 Token 消耗设置上限。Meta 预计在 2026 年,仅内部 AI 使用就将产生数十亿美元的费用。
限额举措与 Meta 此前极力推广 AI 的态度形成鲜明反差。2025 年 11 月,Meta 曾通知员工将展示「AI 驱动的影响力」作为 2026 年的核心考核标准,并将绩效奖金与 AI 使用率挂钩。过度推广引发了员工间竞相刷量的「tokenmaxxing」狂欢,甚至一度出现名为「Claudeonomics」的内部排行榜来公开展示用量排名。在排行榜被关停前,员工在 30 天内消耗的 Token 总量曾飙升至 73.7 万亿。Meta 首席技术官 Andrew Bosworth 随后发出警示,强调单纯增加 Token 消耗并不代表产出,员工应当在能切实提升效率的场景下使用 AI 工具。
为了进一步缩减支出,Meta 开始将内部 AI 开发重心向自研工具倾斜。泄露的备忘录显示,Meta 正在推动员工逐步停用 Anthropic 旗下 Claude 等第三方编程工具,转而使用自研的编程助手 MetaCode(曾用名 Devmate)。Meta 新成立的应用 AI 工程部门已被要求全力改进 MetaCode,通过生成编程挑战来生产高强度的强化学习训练数据。尽管 Meta 仍允许员工访问外部模型,但未来将在自建网关中实施更严格的预算与配额审批机制。
Meta 并非唯一因大模型用量过载而面临财务压力的企业。在 2026 年初,Uber 和 ServiceNow 等公司在短短几个月内便耗尽了全年的 Anthropic 额度。ServiceNow 已对员工实施日用量监测,部分风险投资机构也开始对内部 AI Token 使用设定日均消费上限,以防止无节制的算力成本扩张。
Jun 12

After encouraging staff to prove their “AI-driven impact,” Meta is now moving to cap employee token usage and steer workers toward in-house tools.
Full story: thein.fo/4vbt2PE
1
1
1
814
Jun 13
美国多州总检察长联合对 OpenAI 展开调查,并于周五向 OpenAI 发出传票。传票由纽约州总检察长办公室发出。根据《华尔街日报》披露的传票文件,联合调查调取的资料涵盖 OpenAI 的广泛业务和用户影响,包括广告策略、用户参与度和留存率、消费者与健康数据处理、针对未成年人与老年人的保护措施、深度学习模型架构、模型谄媚(model sycophancy)现象以及公司内部政策。
多州总检察长对 AI 行业的监管正在持续升温。2025 年 12 月,由宾夕法尼亚州总检察长牵头,包含 42 个州的总检察长联盟曾致信 OpenAI、Meta、Anthropic、谷歌和 xAI,要求建立保障机制以防止聊天机器人诱导违法犯罪行为。加利福尼亚州总检察长则于 2026 年 1 月宣布调查 xAI 旗下 Grok 聊天机器人生成女性及儿童性化图像的问题。
在面临本轮联合调查之前,OpenAI 已经在州和联邦层面遭遇多起诉讼。佛罗里达州于 2026 年 6 月起诉 OpenAI 与首席执行官萨姆·奥尔特曼(Sam Altman),指控 OpenAI 在明知产品可能带来危害的情况下发布 ChatGPT。佛罗里达州总检察长还在 2026 年 4 月启动了一项刑事调查,审查 ChatGPT 在佛罗里达州立大学枪击案中被充当谋划工具并提供建议的责任。
OpenAI 发言人回应称,OpenAI 正在配合调查并严肃对待关切,同时强调 ChatGPT 目前已针对未成年人和处于困境中的人群提供了更多保护性体验,包括将用户引导至现实世界资源和可信的人类联系人。
本轮联合调查恰逢 OpenAI 筹备上市的关键节点。OpenAI 已于近期秘密提交了首次公开募股(IPO)申请。
Jun 12

OpenAI was subpoenaed by a coalition of state attorneys general for documents covering a wide range of its activities and impact on users on.wsj.com/4utkyCd
1
453
Jun 13
字节跳动旗下 AI 应用豆包大范围上线任务模式,将 App 界面顶部的模式选项变更为快速、专家、任务,同时将思考模式升级为专家模式。
任务模式主打智能体能力,能够自主完成任务拆解、步骤规划、工具调用到结果交付的全链路执行。用户输入明确的目标后,豆包即可在后台自动执行联网搜索、内容生成、网页制作或 PPT 生成。目前,任务模式支持的核心功能包括在几分钟内生成个人作品集的零代码网页、一键生成完整 PPT,以及在上传 Excel 后自动分析并生成柱状图或折线图的数据可视化分析。任务模式还支持设置定时任务,按照预设时间在后台自动批量生成报告、整理数据或生成图片。
与任务模式侧重于执行交付不同,升级后的专家模式更侧重于思考质量。专家模式调用豆包大模型 2.0 Pro 版本,采用原生 Agent 架构,在数学推理、长文本处理和法律文书校验等复杂场景中提供深度推理能力。
在资费方面,豆包的日常问答和普通对话等基础功能将持续免费,而付费权益主要针对 PPT 生成、数据分析、软件开发和金融分析等高算力专业场景。豆包专业版定价分为三档,标准版连续包月 68 元、包年 688 元,加强版连续包月 200 元、包年 2048 元,专业版连续包月 500 元、包年 5088 元。
1
1
451
Jun 13
在面向数千人的 Meta 内部直播会议中,一名工程师突然切麦爆粗口,控诉在应用 AI 部门「做公司的狗(being the company's bitch)」,要求转告高管「他是狗屎(piece of shit)」。突如其来的变故导致主讲人尴尬掩面,直播区迅速被刷屏。针对重组积怨,Meta 首席执行官马克·扎克伯格(Mark Zuckerberg)于 6 月 12 日发备忘录致歉并承诺整改。
应用 AI 部门成立于今年 3 月,由约 6500 名工程师组成,强制调入且只有接受或离职两个选项,被自嘲为「强征的壮丁」。工程师原本负责社交应用,如今被迫在按键监控下,每周原创两道模型解不开且网上无痕迹的难题并编写边缘测试。标注的枯燥机械让工程师倍感大材小用,并将岗位形容为「古拉格」集中营。
用高薪工程师做标注的做法源自 Meta 首席 AI 官亚历山大·王(Alexandr Wang)。扎克伯格在 4 月会议中称,王认为 Meta 员工智力远超外包工,标数据效率更高。讽刺的是,在 Meta 去年收购 Scale AI 后,新负责人因震惊于研发被迫标数据而随即叫停。随着亚历山大·王入主 Meta 执掌实验室,被废弃的模式反而以更大规模复活,甚至导致 Meta 部分安全团队轮值岗位因人员被强征而瘫痪。
除强征外,Meta 还在公司内部推行按键监控以生成 AI 数据,引发逾 1600 名员工联署抗议。Meta 首席产品官克里斯·考克斯(Chris Cox)在内部会议中坦承,近期环境极其残酷,形容员工状态是在「在冰雹中跑马拉松,突然你的队友被换掉了,而且公司还要录像监控你。这特么算怎么回事(It is like what the fuck)。」
面对危机,扎克伯格在备忘录中承诺限制经理管辖的人数上限,重申今年不会大裁员。他表示应用 AI 部门只是临时中转站,后续将提供机会,让受影响员工重新安排更有价值的岗位。

Executives and employees alike are struggling with Meta's chaotic AI strategy, according to sources and internal discussions reviewed by WIRED. wired.com/story/mark-zuckerb…
2
18
9,146
Jun 13
Zyphra 开源语音合成模型 ZONOS2。ZONOS2 是首个采用稀疏混合专家(MoE)架构的开源语音合成系统,拥有 80 亿总参数,推理时仅需激活 9 亿参数。ZONOS2 主打高保真度与零样本声音克隆,无需微调即可快速提取说话人的声音特征并生成逼真的音频。
为了输出录音室级别的 44.1 kHz 音频,ZONOS2 直接预测 Descript 音频编解码器(DAC)离散标记。预测离散标记能还原更细腻的声音质感,但建模难度较大,Zyphra 通过扩大模型与训练数据规模解决了稳定性问题。在文本处理上,ZONOS2 放弃了传统的音素生成器,选择直接读取原始 UTF-8 字节,大幅提升了中文、日文和韩文的合成效果,并支持句中中英文混合输入与无缝切换。
ZONOS2 的训练数据集从初代模型的 20 万小时扩展至 600 多万小时,约合 707 年的音频长度。Zyphra 采用多阶段数据清洗方案,在预训练、中训练和退火阶段逐步提高文本音频一致性过滤门槛,减少了幻觉、误读和重复现象。
随同发布的还有全新评估基准 ZTTS1-Eval,包含 9 种语言的干净音频集合,以及覆盖 17 种语言的真实场景(in-the-wild)音频集合,并引入 Qwen3-ASR、ReDimNet 和 MSR-UTMOS 等模型作为裁判。ZONOS2 基于 Apache 2.0 协议开放权重,并提供 GitHub 推理代码,同时在搭载 AMD 硬件的 Zyphra 云平台提供限时免费在线试用。

Today we're releasing ZONOS2, our next-generation real-time TTS model with high-fidelity voice cloning.
ZONOS2 is the most expressive open-source TTS model, released under Apache 2.0 and available on Zyphra Cloud on @AMD. 🧵
2
8
802
Jun 13
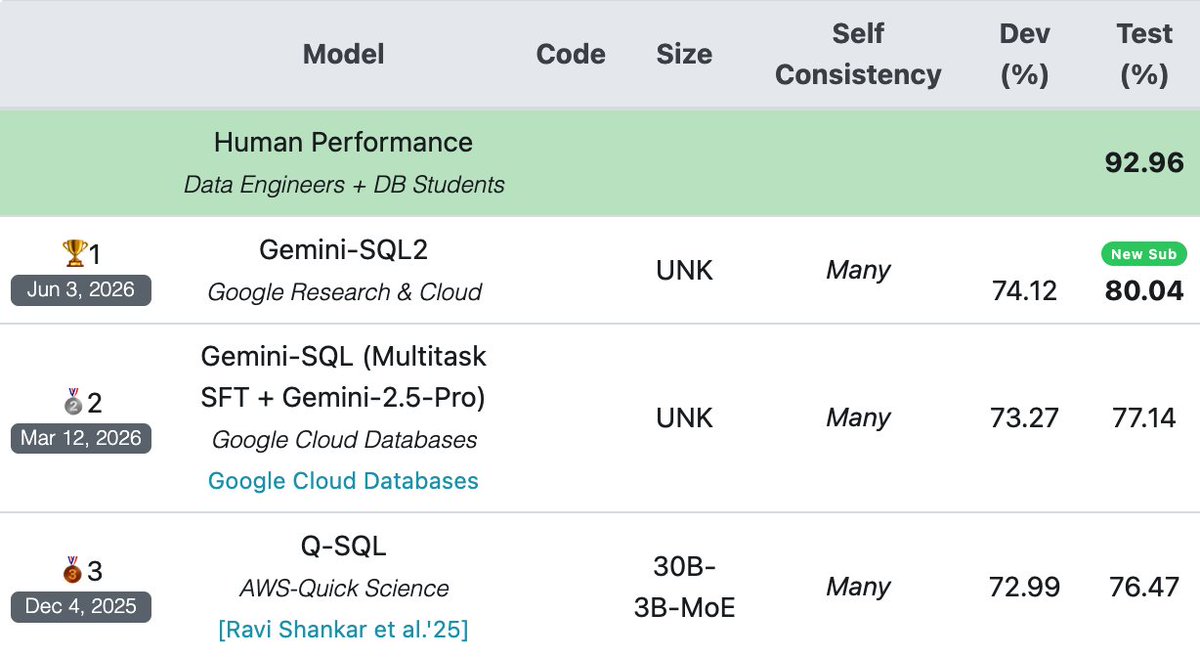
谷歌研究团队发布文本转 SQL 技术 Gemini-SQL2。新系统基于 Gemini 3.1 Pro 模型构建,在行业主流数据库查询评测 BIRD 单模型榜单中取得 80.04% 的执行准确率,创下新的性能纪录。
早期版本 Gemini-SQL 搭载 Gemini 2.5 Pro,并采用多任务监督微调,曾以 77.14% 的执行准确率领跑榜单。新版本将成绩提升了 2.9 个百分点。
BIRD 作为评估文本转 SQL 系统能力的行业基准,包含超过 12700 个问题与 SQL 语句对。测试覆盖多表关联查询、脏数据处理以及复杂业务上下文推理等真实数据库环境,并以生成的 SQL 语句能否在数据库中正确执行作为衡量指标。
Gemini-SQL2 并未作为独立的大模型发布,而是作为底层的数据库查询能力进行推广。谷歌计划逐步将相关能力整合至现有的数据服务中,涵盖 BigQuery Studio、AlloyDB AI 以及 Cloud SQL Studio 等平台,协助非技术人员通过自然语言直接查询企业数据库。
Jun 12
🚀 Introducing Gemini-SQL2, our breakthrough text-to-SQL capability powered by Gemini 3.1 Pro! We've achieved state-of-the-art results on the highly competitive BIRD benchmark, translating natural language into execution-ready SQL queries. 🧵👇

498
Jun 13
综合下来,还是 GPT-5.5 最好。
Jun 13

金融科技独角兽 Ramp 发布了针对前沿 AI 编码智能体的私有测试基准 Ramp SWE-Bench。Ramp SWE-Bench 包含 80 个源自 Ramp 真实生产环境的后端开发任务,旨在解决公共评估数据集因模型预训练而导致的数据泄露与指标饱和问题。
测试任务均提取自 Ramp 内部 AI 编码助手 Inspect 成功部署到生产环境的真实拉取请求(PR)。每个任务重构了 PR 提交前的基础代码库,保留合并的代码与测试作为黄金标准,并提取工程师在 Inspect 对话中的原始意图作为提示词。评估采用 mini-swe-agent 沙箱环境,以单次运行成功通过所有测试且不破坏现有功能(pass@1)作为通过标准。
根据公布的 14 款模型横向评测结果,Anthropic 最新推出的 Claude Fable 5 以 87.5% 的解决率高居榜首。Claude Opus 4.7 和 GPT-5.5 并列第二,解决率均为 83.75%。Claude Opus 4.8 虽然解决率为 77.5%,但单次任务平均运行时间缩短至 8 分 30 秒,单次运行成本仅为 1.09 美元,不足 Fable 5 运行成本的 40%,展现出极佳的成本效益。
测试数据还揭示了不同模型在价格与性能间的权衡。国产模型 Kimi K2.6 与 GLM 5.1 解决率相近,分别为 72.5% 与 71.25%,但 Kimi K2.6 的平均成本为 0.69 美元,比 GLM 5.1 便宜约 34%。在轻量级模型中,GPT-5.4 Mini 以 58.75% 的解决率领先 Claude Haiku 4.5 约 10 个百分点,且平均成本和步骤数均减半。随着模型走向应用,性能、速度与成本的权衡正成为工程落地时的关键考量。
1
338
Jun 13
金融科技独角兽 Ramp 发布了针对前沿 AI 编码智能体的私有测试基准 Ramp SWE-Bench。Ramp SWE-Bench 包含 80 个源自 Ramp 真实生产环境的后端开发任务,旨在解决公共评估数据集因模型预训练而导致的数据泄露与指标饱和问题。
测试任务均提取自 Ramp 内部 AI 编码助手 Inspect 成功部署到生产环境的真实拉取请求(PR)。每个任务重构了 PR 提交前的基础代码库,保留合并的代码与测试作为黄金标准,并提取工程师在 Inspect 对话中的原始意图作为提示词。评估采用 mini-swe-agent 沙箱环境,以单次运行成功通过所有测试且不破坏现有功能(pass@1)作为通过标准。
根据公布的 14 款模型横向评测结果,Anthropic 最新推出的 Claude Fable 5 以 87.5% 的解决率高居榜首。Claude Opus 4.7 和 GPT-5.5 并列第二,解决率均为 83.75%。Claude Opus 4.8 虽然解决率为 77.5%,但单次任务平均运行时间缩短至 8 分 30 秒,单次运行成本仅为 1.09 美元,不足 Fable 5 运行成本的 40%,展现出极佳的成本效益。
测试数据还揭示了不同模型在价格与性能间的权衡。国产模型 Kimi K2.6 与 GLM 5.1 解决率相近,分别为 72.5% 与 71.25%,但 Kimi K2.6 的平均成本为 0.69 美元,比 GLM 5.1 便宜约 34%。在轻量级模型中,GPT-5.4 Mini 以 58.75% 的解决率领先 Claude Haiku 4.5 约 10 个百分点,且平均成本和步骤数均减半。随着模型走向应用,性能、速度与成本的权衡正成为工程落地时的关键考量。

Today we’re releasing Ramp SWE-Bench: a private, production-grounded coding benchmark created from real engineering problems we've faced at Ramp.
2
2
1,312
Jun 13
欧洲 AI 独苗 Mistral AI 正与投资者商谈新一轮融资。知情人士透露,Mistral AI 计划筹集约 30 亿欧元(约合 35 亿美元),估值预计达到 200 亿欧元,甚至可能因投资者需求而进一步提高。这相比去年 9 月融资时 117 亿欧元的估值将大幅翻倍。目前谈判仍处于早期阶段,具体条款可能发生变化。
半导体设备巨头 ASML 是 Mistral AI 的最大股东。去年 ASML 投资 13 亿欧元,持股比例为 11%。Mistral AI 由 Google DeepMind 和 Meta 的前研究人员于 2023 年创立。公司主要为欧洲政府和企业提供云基础设施服务,并在法国和瑞典管理本地数据中心,近期已与空中客车(Airbus)和宝马(BMW)签署合作协议。
为了扩展业务,Mistral AI 正与欧洲银行等机构商谈,计划提供网络安全模型来替代 Anthropic 旗下的 Mythos 模型。之前,Mistral AI 首席执行官 Arthur Mensch 曾公开指出,过度依赖外部进行安全漏洞检测将带来国家安全风险,欧洲必须自主掌控相关技术。

French startup Mistral AI is in talks to raise around €3 billion ($3.5 billion) at a valuation of roughly €20 billion, sources say bloomberg.com/news/articles/…
1
550