
🚀 Work in progress for Nelson!
Native Parquet file support is coming
This will make it easier to exchange large datasets with modern data analytics ecosystems while keeping a MATLAB-compatible workflow.
#apachearrow #arrow #Data #GNUoctave #scilab #Matlab #NelsonLang

6

mssql-python 1.6: Unblocking Your Threads
#python #bulkcopy #ApacheArrow
techcommunity.microsoft.com/…
8

Jun 3
Milliseconds. That's not a typo.
DADOS converts millions of live Sparkplug B messages into in-memory Arrow Tables faster than most systems can blink — then serves that decision-ready industrial state to every agent, dashboard, and analytics tool at once. One API. Zero stale reads. No repeated ingestion.
This is what industrial data velocity actually looks like.
See it on your data → dadostech.co
#IIoT #Industry40 #IndustrialAI #Sparkplug #ApacheArrow
3
5
9
2,926

May 29
Ladybug 0.17.0 is here!
Graph Lake support via Icebug Format v1, @huggingface datasets via XET and tighter integration with Icebug and Bugscope via @ApacheArrow memory. Link in Replies.

2
3
4
143

May 27
We wrote a book, with Codex, delving deep into @LakeSailHQ architecture. Sail is a modern data ecosystem with deep roots in @ApacheArrow, @ApacheDataFusio, and rebuilding the whole @ApacheSpark ecosystem in @rustlang. One of the key advantages of an AI-native stack is extensibility. We are convening the community to build Sail extensions. A proposal is on the table in github.com/lakehq/sail. In order to extend the engine as profoundly efficient as Sail, you need to operate at several levels — physical, logical plans, loading and linking, and performing at the top both in a single node and in cluster mode. The book is written as an exploration of the codebase, of the overall Sail architecture, its use of Arrow and DataFusion, its implementation of SparkConnect protocol, and everything else pertinent to the extensions.
github.com/alexy/sail-rust-b…
1
2
13
1,725
May 26
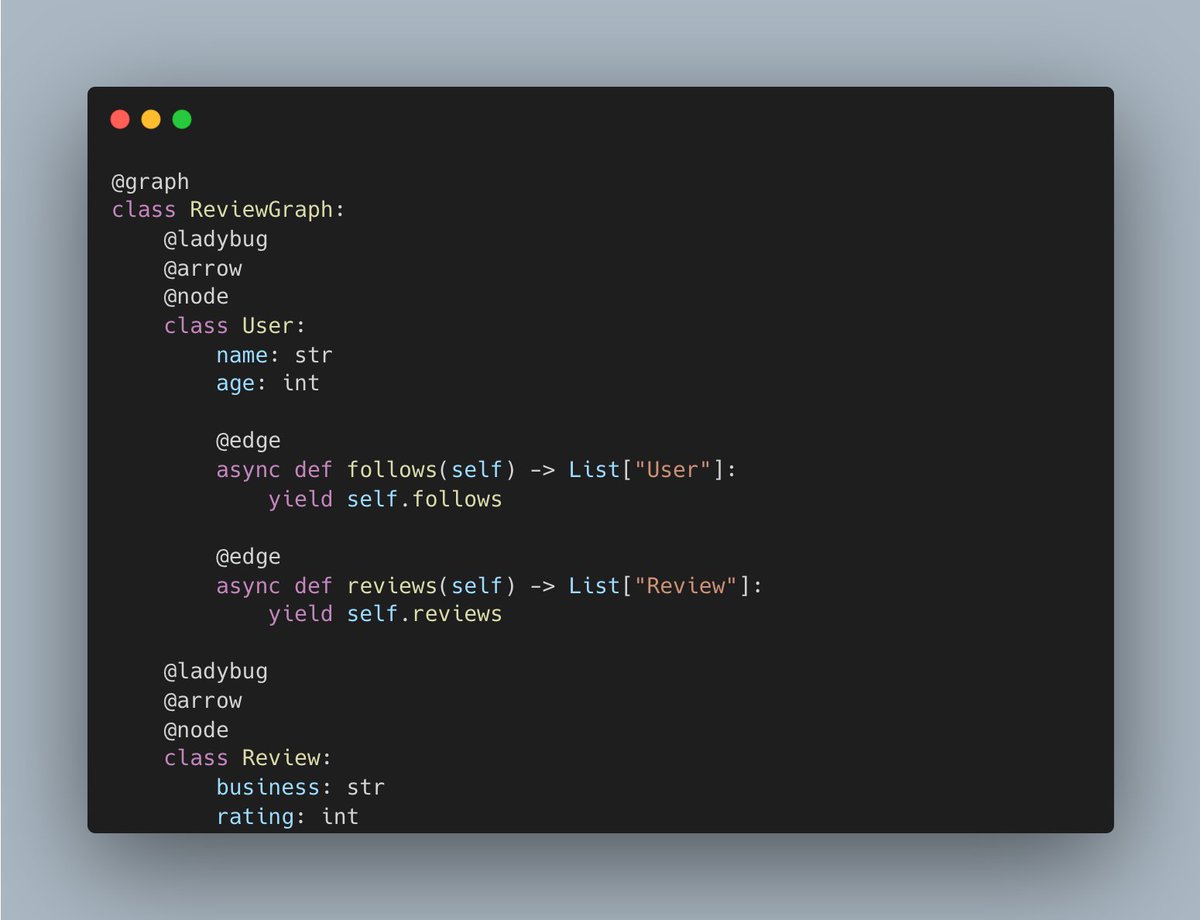
LadybugDB and Type Checkers
Demo covers LadybugDB native storage and @ApacheArrow
1
2
8
1,161

May 20
Apache Spark is great at petabytes. It can be heavy at 100 megabytes. Project Feather is a new SPIP to fix that. 👇
Three lines of work, all targeting Spark in local mode:
1️⃣ Compilation and scheduling. Skip unnecessary shuffles when the planner knows a scan is one file. Mark itSinglePartitionand let the next aggregate run in place.
2️⃣ Arrow-baseddf.cache. Swap the row-oriented cache for Apache Arrow IPC. Columnar, compressed, iterable.
3️⃣ Shuffle-free execution. On a single node, replace blocking shuffle with in-process channels and Java virtual threads. No disk round-trip.
Prototype today: a filter-and-sort query on a small in-memory table runs in 150 ms instead of 330 ms. One stage instead of two. The win compounds as the optimizations stack.
🔗 Project Feather: docs.google.com/document/d/1…
The SPIP is open for comment. Pull the prototype, run it against your hardest small-data pipeline, file the bug we missed.
✍ Authors: Daniel Tenedorio and Liang-Chi Hsieh.
#ApacheSpark #SPIP #OpenSource #DataEngineering #ApacheArrow
1
7
49
4,148
May 12
Hyukjin Kwon, Apache Spark PMC member, explains why Apache Arrow is becoming the universal language of data within the Spark ecosystem: it is not only about speed. 👇
🔸 Zero-copy columnar IPC → less memory overhead
🔸 One format to inspect data across JVM Python
🔸 Arrow as the stack’s common columnar layer
Full video: youtube.com/watch?v=zvq5UiVx…
#ApacheSpark #ApacheArrow
2
4
27
2,238

We contributed to @ApacheArrow making Parquet bloom filters smaller and more effective.
Full write up on what it means for Pydantic Logfire and the wider Parquet ecosystem.
pydantic.dev/articles/bloom-…
9
904

.@ApacheArrow is downloaded hundreds of millions of times each month. It's the columnar format behind Pandas 2.0, Polars, Spark, DataFusion, and Parquet.
@kszucs_, Arrow PMC Member and @huggingface Open Source Engineer, built Marrow, a pure-Mojo Arrow implementation, and it's already 1.3-3.9x faster than PyArrow on conversions. Mojo's SIMD abstractions enable vectorized conversion without Python overhead.
Zero-copy PyArrow interop, early GPU support via DeviceContext, and a lot more to come:
forum.modular.com/t/marrow-a…
3
5
67
3,008
Apr 6
Why did the Spark community build mapInArrow? 🤔
According to Apache Spark PMC member Hyukjin Kwon, the motivation was simple: enable vectorized processing of nested data without the overhead of Pandas conversion.
🔗 Watch the full breakdown of how Spark 3.3 introduced this shift: youtu.be/zvq5UiVxpEg
#ApacheSpark #DataEngineering #ApacheArrow #Python
3
14
2,281
Mar 31
Where is Apache Spark heading in Spark 4.2 and beyond? 🚀
Join @lisancao and Apache Spark PMC member Hyukjin Kwon as they break down the migration from Python "Pickle" to Apache Arrow and what’s next for the ecosystem.
🔗Watch the full interview: youtu.be/zvq5UiVxpEg
Key Insights:
🔥 The Serialization Breakthrough: How Arrow solved the JVM-to-Python bottleneck
🏎️ The Zero-Copy Roadmap: Direct memory access coming in Spark 4.2/4.3
🛠️ Spark 4 Updates: New byte-count batching to prevent OOM issues
💡 Expert Advice: When to enable Arrow for maximum performance
#ApacheSpark #ApacheArrow #Python

1
3
23
1,390

Mar 31
PolarsはRustで実装されたDataFrameライブラリで、LazyAPIによりクエリプランを構築してから最適化・実行する設計になっているようだ…列指向のApacheArrow形式と並列処理を前提としており、大規模データ処理で効率的に動作するケースが多い。設計思想はデータベースエンジンのクエリ最適化にも近く、個人的にはDataFrameツールの進化の方向性としてとても興味深い…
1
41
7,584

Mar 25
Introducing quiver: a (type-safe) place to keep your @ApacheArrow
quiver is a small schema library for Arrow, built on @uwdata flechette
- Define table schemas in TS
- Validate schemas at IPC parse time
- Get back fully typed Tables (no type-casting)
github.com/manzt/quiver
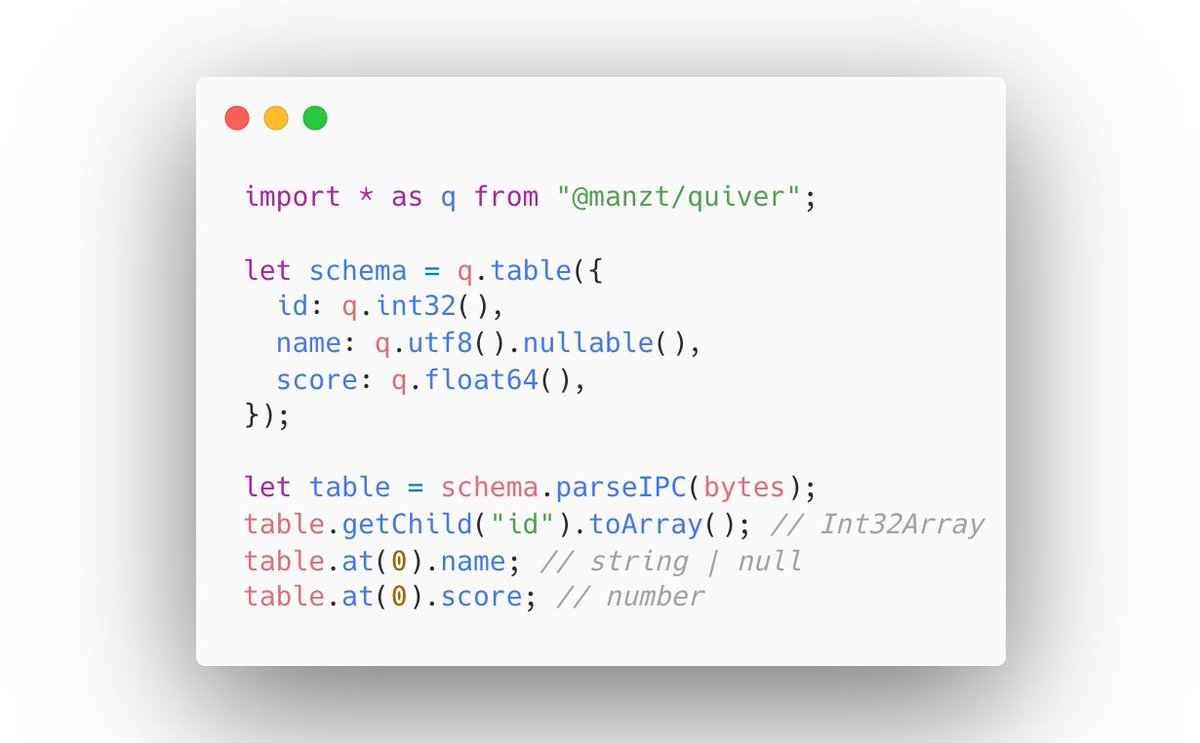
ALT Code snippet showing quiver's API: import quiver, define a table schema with int32, nullable utf8, and float64 columns, then call parseIPC on bytes. Accessing row values returns fully typed results — name is string | null, score is number.
1
7
194
Mar 18
You know what's missing from that diagram? The fact that @ApacheArrow is the data format used to communicate between all those systems given that cuDF and Rapids are built on top of the Arrow format...
1
3
101

Mar 17
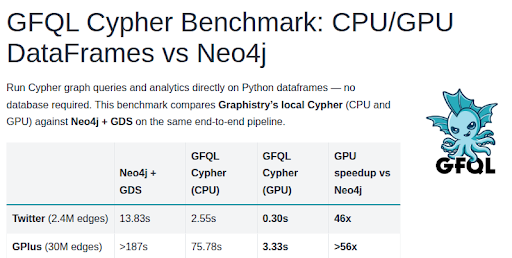
You can now run Cypher without a database - and 50× bigger & faster. Just directly query your dataframes and go.
Last year, Graphistry announced GFQL, the first open source GPU property graph query engine. This year, we've brought it to Cypher.
Think of GFQL as what Pandas, DuckDB, or Spark do for tabular analytics, dashboards, and ML - but now for graph-shaped data like networks, relationships, and paths.
The new GFQL support brings massive performance, cost savings, and architectural freedom for the most widely used graph query language used by half the Fortune 500. GFQL Cypher is the latest member of the @ApacheArrow and @NVIDIAaidev @RAPIDSai OSS ecosystem.
We will announce more at GTP 2026 (RSAC week in SF livestream) and are happy to chat directly
Notebook is linked below so you can try for yourself.
1
3
19
1,410

Mar 15
The fastest operation is the one you don’t have to do.
When a database natively supports @ApacheArrow, ADBC can speed up fetching and ingestion by eliminating costly row/column conversions.
How much faster is it in practice? We ran some benchmarks to find out. Link below 👇

ALT An abstract hyperspace warp image inspired by the comedic "going plaid" effect from the 1980s cult film "Spaceballs".
1
3
6
363
Mar 12
For a decade, PySpark developers have wrestled with a specific architectural tax: the overhead of moving data between the JVM and Python. It was the bottleneck that kept Python from feeling truly native to the Spark engine.
Then came Apache Arrow. 🏹
To celebrate 10 years of Arrow, we’re diving deep into the technical journey that transformed Spark into a zero-copy performance beast. In this video, @lisancao (@databricks), Matt Topol (Columnar), and Hyukjin Kwon (Databricks) map out exactly how this convergence happened and where it’s going in Spark 4.1. 🚀
🎥 Watch the full 10-year retrospective here: youtu.be/EiEgU4m8XfM
They dive deep into:
🔸 𝗕𝗲𝘆𝗼𝗻𝗱 𝗣𝗶𝗰𝗸𝗹𝗲: Why the original serialization protocols couldn't scale and how Arrow’s columnar memory layout changed the game
🔸 𝗧𝗵𝗲 𝗥𝗼𝗮𝗱𝗺𝗮𝗽: From the first integration in Spark 2.3 to the "Map in Arrow" API in 3.3
🔸 𝗧𝗵𝗲 𝗙𝗶𝗻𝗮𝗹 𝗙𝗼𝗿𝗺: In Spark 4.1, Arrow isn't just a transport layer anymore—it’s the native execution format
🔸 𝗧𝗵𝗲 𝗣𝗲𝗿𝗳𝗼𝗿𝗺𝗮𝗻𝗰𝗲 𝗛𝗶𝗲𝗿𝗮𝗿𝗰𝗵𝘆: A definitive "Tier List" for 2026. Should you use Catalyst, Scala, or Arrow-Native UDFs?
#ApacheSpark #ApacheArrow #PySpark #OpenSource

1
6
61
3,496

Mar 10
🤓 Tech Insight #003 : Moving Petabytes with Zero-Copy
(or how we built the @MosaicoLabs Communication Stack)
⭐️ Check out the repo: github.com/mosaico-labs/mosa…
When handling high-frequency sensor data, the bottleneck isn't just storage, it's communication.
For the Mosaico backend (mosaicod), we didn't just want a "fast" database; we wanted a high-throughput data vault. That’s why we built our architecture on @ApacheArrow Flight and @rustlang .
Here’s why this matters for your robotics infrastructure:
1) Arrow Flight (gRPC-based): we use Flight for ultra-fast transfer of large tabular datasets. It’s designed for modern hardware, allowing us to stream batches of data between our Rust core and Python SDK with minimal overhead.
2) Tiered Storage & Lazy Loading: handling 500GB logs? Mosaico decouples the metadata index from raw binary blobs. You can query a specific 2-second telemetry spike without downloading the entire file, slashing latency and cloud egress costs.
3) The DataFusion Engine: by integrating Apache DataFusion in Rust, we enable complex analytical queries directly on the archive, treating your robotics data like a high-performance data warehouse.
We are bridging the gap between "event-driven" robotics and "tensor-driven" AI.
2
42