Clara fly retweeted

2 petits réglages concrets pour sortir votre IA de sa zone de stupidité 🤪 medium.com/p/a704af30455a #contextEngineering
1
8
964

AI performance in 2026 will not be won by bigger models alone.
It will be won by context engineering that controls what the model remembers, what it retrieves, and how fresh that information stays.
Get this right and you unlock sharper outputs, cheaper operations, and workflows that scale without chaos.
Get it wrong and even […]: alexsmale.com/context-engine…
The real moat is memory discipline.
If your AI recalls stale docs or the wrong customer facts, bigger models won't save it.
Fresh context cuts costs and weird errors fast.
#AI #LLM #ContextEngineering

11

12h
Context is not observed directly.
It is inferred from signals.
GPT, Claude, Gemini, and Grok each prioritize different signals when interpreting user intent, experience, and meaning.
Different paths. Same objective:
Context.
#AIAlignment #ContextEngineering #CognitiveScience

3
56

Jun 13
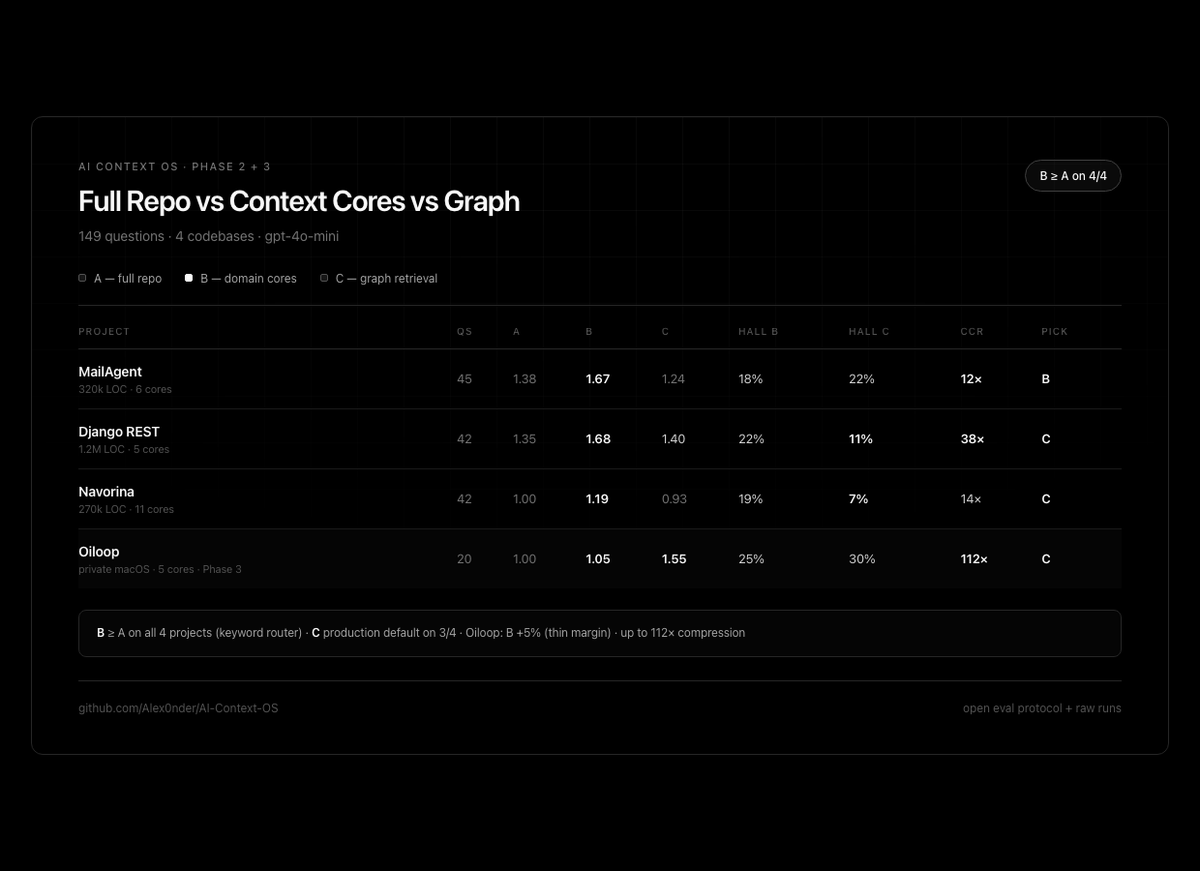
Reports:
github.com/Alex0nder/AI-Cont…
· PHASE-2-RESULTS.md
· PHASE-3-RESULTS.md
· experiments/ (reproducible runs)
Caveats: LLM-as-judge, Oiloop N=20, expert prefs from decode — not fresh blind humans.
#ContextEngineering #RAG
1
7

Jun 13
We took Apache Fineract (apache/fineract), a real open-source core banking platform with 800,000 lines of Java across ~6,000 PRs, and ingested its architectural decisions, constraints, and rationale into KyraDB. That's years of institutional knowledge, compliance rules, contractual commitments, "we tried this and it broke prod" — turned into queryable context.
We then mocked 15 sales calls. Our analysis agent reads each transcript, classifies it (support, feature request, churn risk, etc.), and routes feature requests into a delivery pipeline: requirements extraction → spec writing → ticket creation → PR generation. Every step is a real LLM call, every KyraDB read/write is a real MCP call — no hardcoded routing, no mocked "AI."
The interesting part — running it with and without context:
🔴 Without KyraDB context: the spec writer has nothing to check the new requirement against, so it generates a spec normally and looks fine on paper.
🟢 With KyraDB context: the same requirement gets checked against Fineract's real PR history before a single line of spec is written. When a new requirement (e.g. maker-checker/dual-authorization for loan modifications) topically overlaps with a prior merged PR (FINERACT-274 — a maker-checker/datatable rejection issue), Kyra blocks spec generation outright — citing the exact record ID and rationale — instead of producing a spec/ticket/PR that would duplicate or conflict with already-shipped work.
That's the core thesis: context isn't a nice-to-have, it's what stops you from re-litigating decisions your org already made and it saves the tokens (and engineering time) you'd otherwise burn building something that gets rejected.
hashtag#AI hashtag#SDLC hashtag#ContextEngineering hashtag#KyraDB hashtag#GoogleImmersion hashtag#AgenticAI hashtag#ApacheFineract @GoogleStartups @AntlerIndia @16vchq
Try here: kyra-pipeline-1042501689076.…
2
21

Jun 13
Introducing grwm. No more re-explaining your project every time you switch models.
Try it:
npm install -g @sankalpasarkar/grwm
🌐 grwm-init.vercel.app
Still shipping fast. Would love feedback from builders and AI power users
#AI #ContextEngineering #AIAgents #OpenSource
1
12

なぜ企業は生成AIの導入に慎重なのでしょうか?
その理由の一つが「ハルシネーション」です。
ハルシネーションとは、AIが事実ではない内容を、あたかも正しい情報のように回答してしまう現象です。
一般的な生成AIは、質問に対して回答を作り出すことを得意としています。
そのため、正しい情報が見つからない場合でも、推測によって回答を生成してしまうことがあります。
しかし企業では
・契約書
・監査資料
・法務文書
・経営資料
など、間違いが許されない情報を扱います。
だからこそAI孔明 on IDXは、AIへ大量の情報を渡すのではなく、必要なデータだけを選択し
正しい文脈を与えた上で回答を生成します。
さらに、AI孔明 on IDXは「わからないことは、わからない」と回答します。
存在しない情報を推測で作らない。
根拠がない回答をしない。
だからこそ企業で活用できるのです。
AIに必要なのは、何でも答える能力ではありません。
正しく答える能力です。
そして、答えられないことを正直に伝える能力でもあります。
AI孔明 on IDXは、
企業データを活用しながら、
信頼できるAI共創環境を実現します。
#AI孔明
#AIエージェント
#ContextEngineering
#企業AI
#DX推進
#ハルシネーション対策
#データ活用
#MOAT_OS
1
2
27

This is just a concept model for now but — the real power comes from the full system: data, context, tools, infrastructure, and workflow design. ⚙️
#AI #ArtificialIntelligence #AIEngineering #MachineLearning #TechEducation #ContextEngineering
5
Jun 12
139 Q · 4 codebases · A/B/C
Cores beat full repo on 3 OSS projects ( 19–24%, up to 45×).
Private macOS app: first counterexample — cores lost; graph won.
Partially supported.
github.com/Alex0nder/AI-Cont…
#ContextEngineering
7
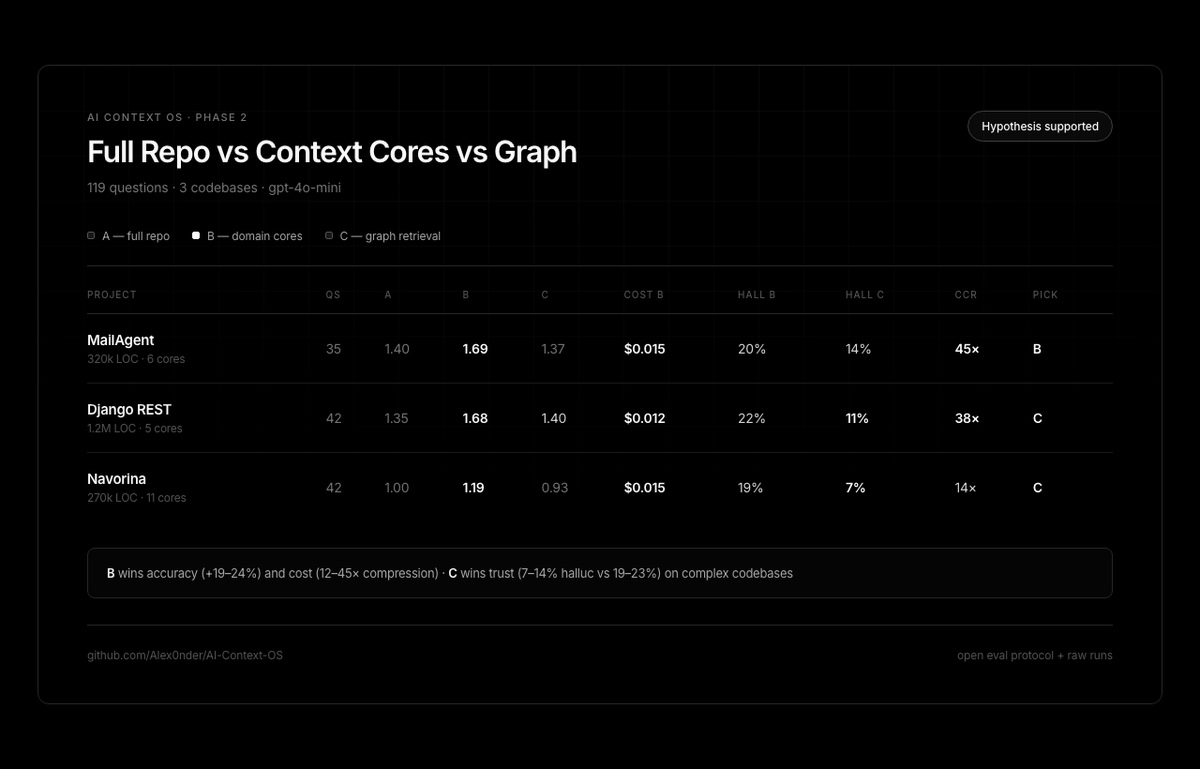
Jun 12
Phase 3 done — 4 codebases, 139 eval questions (gpt-4o-mini).
We compared full repo vs routed context cores vs code graph retrieval.
New: private macOS Swift app (Oiloop) — 81k → 979 tokens, ~3× faster.
github.com/Alex0nder/AI-Cont…
#ContextEngineering #LocalLLM #OpenSource
1
26

Jun 12
If you told a database engineer to index every column in a massive table, they would probably laugh!
Indexes are useful, but they are not free. They slow writes, consume storage, and confuse query planning when created without discipline.
AI memory systems are making a similar mistake ⚠️
Some systems try to pre-compute everything into sprawling knowledge graphs or overloaded vector stores. Others do almost nothing and rely on raw transcript retrieval at query time.
Both extremes miss the point.
In this post, I argue that agent memory should be treated less like a database and more like an index: a compact, selective navigation layer that helps agents find the right raw context when it matters.
🔗 blog.investperpetual.com/ai-…
🧠 Memory is not about storing more
The goal is not to accumulate every extracted fact, summary, relation, and embedding. The goal is to create precise pathways back to the source context that the agent will actually need.
🗂️ Over-indexing creates context entropy
Pre-computed knowledge is not harmless. If irrelevant facts, relations, and summaries enter the retrieval path, they compete for attention and can mislead the model at read time.
🔍 Raw RAG is a fuzzy full-table scan
Chunking and embedding entire histories work for simple semantic lookup. But it struggles when the query requires computation: time ranges, sequence, deltas, conflicting records, and long-range dependencies.
🕰️ Time may be the most important memory index
Many hard, long-term memory queries are temporal: what happened after X, before Y, during that week, or across a changing sequence of events. This is where structured event calendars become powerful.
🧊 The Iceberg analogy is useful
Data lake systems do not blindly scan petabytes. They use metadata manifests to know where to look.
Agent memory needs a similar discipline: lightweight indexes that point to raw conversational payloads rather than replace them.
The broader takeaway:
Do not ask, “What can we remember?”
Ask, “What query pattern does this memory serve?”
#AIAgents #AgenticAI #AIMemory #AIContext #ContextEngineering
4
1
7
197

Jun 12
I just published EPM-JEPA: Can World Models Learn From Experience Without Retraining? medium.com/p/epm-jepa-can-wo…
#WorldModels #JEPA #MachineLearning #AIResearch #SelfSupervisedLearning #ContextEngineering #DeepLearning #LoRA #ArXivPreprint #MultilingualLLMs #AICollaboration
13

Jun 12
Daily Tech Digest - June 12, 2026 highlights how context compression is finally working in production, reshaping how AI systems retain and reason over long‑horizon information.
#AIAgents #AIRegulation #AlertFatigue #ContextEngineering #DataQuality #DigitalWorkforce #InferencingCost #QuantumComputing #SolutionArchitecture #SpecDrivenDevelopment
links.kannan-subbiah.com/202…
17

Jun 12
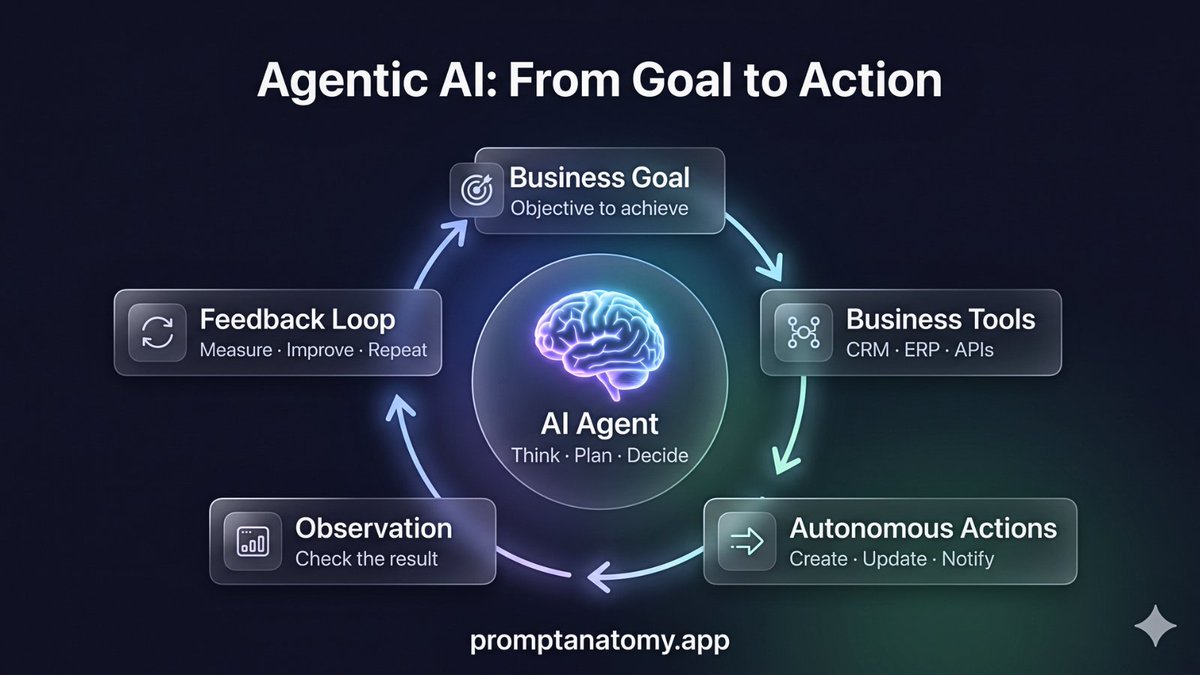
🤖 Most executives think AI agents = API key chat window.
Wrong.
Without CRM, ERP, CMS, databases, and feedback loops, you're not deploying an AI agent.
You're playing with a toy.
Real agents observe, act, learn, and optimize your business continuously 🔄
Does your AI have access to your business tools and a feedback loop?
If not, it's just an expensive echo chamber.
Stop prompting. Start engineering the loop. 🚀
DM us or visit Prompt Anatomy if you're ready to build real AI systems.
#AgenticAI #ContextEngineering #PromptAnatomy
1
32

Jun 12
Everyone is optimizing prompts.
The winners in AI are optimizing CONTEXT.
Prompt Engineering = How you ask
Context Engineering = What the AI knows
Read more:
withsamipshah.com/blogs/prom…
#AI #ContextEngineering #PromptEngineering #AIAgents #GenAI
1
4

Jun 12
the real ai shift right now isn't another model drop.
it's context engineering 🧠 agent harnesses ⚙️ that actually survive production data, use tools, and self-correct instead of breaking on the first messy input.
prompt tricks had their moment. the builders wiring up reliable loops are the ones shipping useful stuff.
what agent workflow or context system are you iterating on this week?
#AgenticAI #ContextEngineering #AIBuilders

3
1
6
104
Good AI answers usually come from good context.
This is where AI systems become useful in real workflows.
Better context = better answers.
#RAG #AIEngineering #KnowledgeSystems #ArtificialIntelligence #ContextEngineering

1

Jun 11
What is Fathym?
Fathym helps project context move with your AI tools instead of getting rebuilt from scratch every session.
Your repo has the code. Your workbench has the decisions, patterns, preferences, and “please do not touch this” knowledge behind the code.
Your tools can change. Your working context should stay yours.
fathym.com/docs/getting-star…
#FAI #ContextEngineering #DeveloperTools
9
Jun 11
Full report open eval protocol raw runs:
github.com/Alex0nder/AI-Cont…
Repo: github.com/Alex0nder/AI-Cont…
@swyx - does this match your context engineering tradeoffs?
@cursor_ai - curious if cores vs graph maps to your prod pipeline.
#AIAgents #ContextEngineering #RAG #BuildInPublic
1
16