
Apr 14
Hugging Faceで公開されている「MiniMax-M2.7」が注目を集めている。MiniMaxAIのモデルページでは、2026年4月14日時点で like 682、Downloads last month 43,645 が表示されている。
FP8・Transformers・SafeTensors・conversational・custom_code といったタグが付いており、SGLang / vLLM / Transformers / NVIDIA NIM での利用案内も公開されている。既存のMLパイプラインに組み込みやすい構成として確認しやすい。
MiniMaxがHugging Face上でモデルを公開している点は、商用APIに依存しない選択肢を探す開発者にとって確認しやすい。対応フレームワークやタグ構成を見ながら、導入候補としてチェックする価値のある一手だ。
huggingface.co/MiniMaxAI/Min…
3
84

Mar 6
Under the hood, it's a 30B parameter model using a custom MoE (Mixture of Experts) architecture. It's built with Transformers and SafeTensors, trained for conversational fluency. The 'custom_code' tag hints at specialized optimizations beyond standard models.
1
17
1,476

21 Jul 2025
took a quick look at this paper (just the convolution section) and I have several concerns about the claims:
1) pytorch by default does not execute synchronously on the GPU (host vs. device) and anyone who has forgotten syncs when benchmarking can tell you so
2) TF32 is enabled by default in cuDNN, enabling this is not an optimization
3) the above is also an example of tuning framework parameters rather than optimizing kernels themselves which I’m not sure is in the spirit of KernelBench, you’ll see many of the “custom_code” fields in the repo contain just modified pytorch code with no CUDA kernels at all!


CUDA-L1: Improving CUDA Optimization via Contrastive Reinforcement Learning
Trains a DeepSeek-v3-671B model to optimize CUDA kernels using only execution-time speedup as reward.
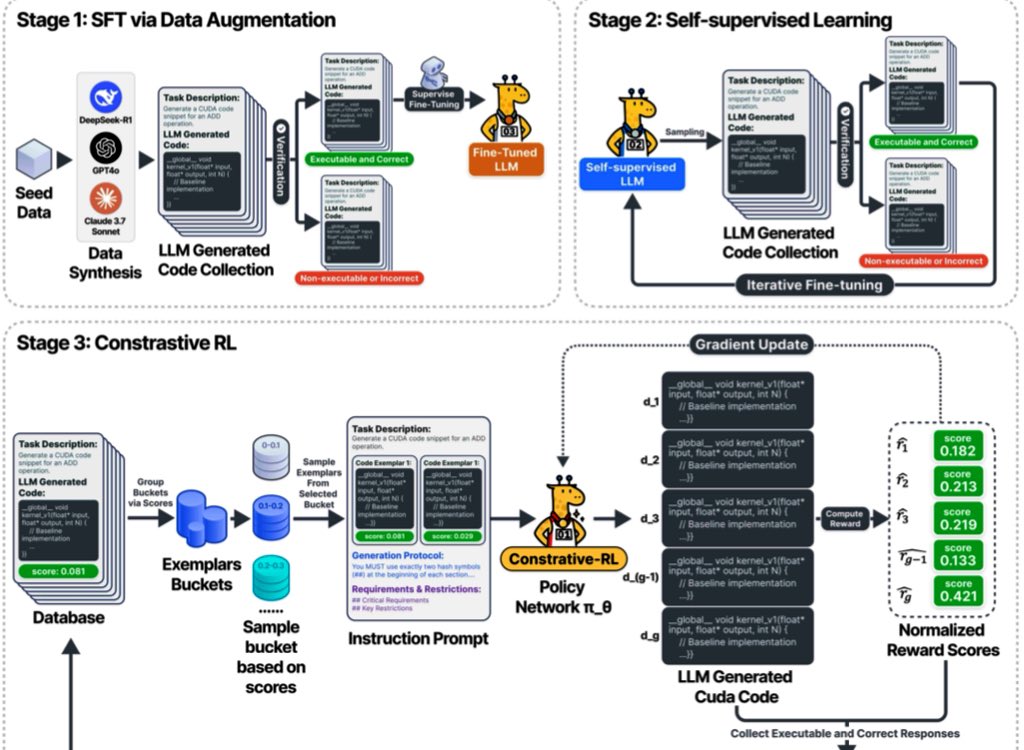
Pipeline:
- SFT: Finetuned on 2.1K correct, executable CUDA variants from 6 LLMs across 250 KernelBench tasks
- Self-Supervised: Iterative REINFORCE updates on successful code (exec correctness)
- Contrastive-RL: Prompts include prior variants speedup scores; model compares, improves, and updates via GRPO
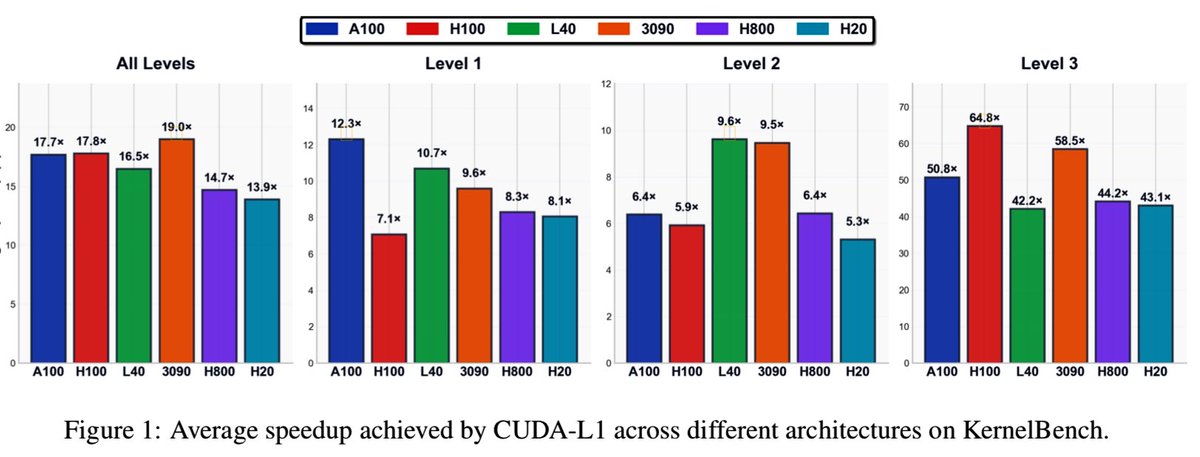
Results (KernelBench, 250 tasks):
- 17.7× avg speedup (A100), 449× max
- 100% success on complex ML workloads (Level 3), 50.8× mean
- Generalizes across GPUs: 19.0× (3090), 17.8× (H100), 13.9× (H20)
Findings:
- Discovers non-trivial strategies that multiply performance
- Identifies gatekeeper techniques (e.g. stream mgmt → unlocks CUDA graphs)
- Learns optimization dependencies (e.g., certain techniques must precede others)
- Outperforms both GRPO-only and evolutionary LLMs
- No reward hacking (via prompt constraints)
6
5
69
8,276

27 Dec 2024
【DeepSeek-V3-Base:驚異の6850億パラメータ!MoEアーキテクチャ搭載の言語モデル登場!】
✎. FYIG: x.com/rohanpaul_ai/status/18…
Hugging Faceに、DeepSeek-V3-Baseという新しい言語モデルが登場したそうです! なんと6850億パラメータという巨大なスケールで、Mixture of Experts (MoE) アーキテクチャを採用しているとのこと…
MoEについて少し説明すると、複数の「エキスパート」と呼ばれる小さなモデルを組み合わせ、入力に応じて適切なエキスパートを選択して処理を行う仕組みです。DeepSeek-V3-Baseは、256個のエキスパートとtop-k=8、シグモイドルーティングで動作するそうです!
そして、高スパース性も大きな特徴!✨ 入力トークンごとに、257個のエキスパート(ルーティング用256個 共有1個)のうち、わずか9個(ルーティング用8個 共有1個)しか使用されないため、非常に効率的とのこと… スパース係数はなんと約28.6倍! 各エキスパートの貢献が最小限に抑えられているんですね。
さらに、AiderベンチマークではSonnet 3.5の性能を上回っているという結果も出ているそうです…これは期待大ですね!
Hugging Faceのモデルページ(huggingface.co/deepseek-ai/D…)では、「Model card」「Files」「Community」タブから詳細情報、関連ファイル、コミュニティディスカッションにアクセスできるそうです! 「Safetensors」「deepseek_v3」「custom_code」「fp8」といったタグも付いていますね
今後のDeepSeek-V3-Baseの活躍に注目です!

1
144

21 Dec 2022
A friend had an L&K TDI wagon, that was no slouch, and very well equipped.
2
209

6 Nov 2019
WP Plugin: "Custom Code Manager PRO" mycyberuniverse.com/wp-plugi… #cms_wordpress #custom_code_manager_pro #wordpress #wp #wordpress_plugin #inject_code #js #custom_code #script #custom_scripts #header #head_area #footer #footer_area #insert_code #code #spacexchimp #spacexchimpblog
4
26 Oct 2019
WP Plugin: "Custom Code Manager" mycyberuniverse.com/wp-plugi… #cms_wordpress #custom_code_manager #wordpress #wp #wordpress_plugin #inject_code #javascript #js #custom_code #script #custom_scripts #header #head_area #footer #footer_area #insert_code #code #spacexchimp #spacexchimpblog
4
6 Apr 2019
WP Plugin: "JavaScript Inserter PRO" mycyberuniverse.com/wp-plugi… #cms_wordpress #wordpress #wp #wordpress_plugin #wp_plugin #JavaScript_Inserter #JavaScript_Inserter_PRO #JavaScript #Inserter #custom_code #inject_js #spacexchimp #spacexchimpblog
1
5
5 Apr 2019
WP Plugin: "JavaScript Inserter" mycyberuniverse.com/wp-plugi… #cms_wordpress #wordpress #wp #wordpress_plugin #wp_plugin #JavaScript_Inserter #JavaScript #Inserter #custom_code #inject_js #spacexchimp #spacexchimpblog
1
6
9 Feb 2019
WP Plugin: "My Custom Functions" mycyberuniverse.com/wp-plugi… #WordPress #cms_wordpress #wp #wordpress_plugin #wp_plugin #inject_code #inject_function #inject_snippet #inject_php #insert_php #custom_code #custom_function #code #function #snippet #php #functionality_plugin #spacexchimp
4