
BREAKING! Cycode joins Cisco Cloud Control: AI agents get code-level security context ahead of Mythos disclosures -- radicaldatascience.wordpress…
#AI #AgenticAI #security @CycodeHQ @Cisco @CiscoSecure #mythos #cloud
2
42

The stats are documented, not pulled out of thin air.
• Sherlock Forensics 2026: 92% of AI-generated codebases contain at least one critical vuln.
• Veracode/Cycode: 45% fail OWASP Top 10 (up to 72% in some languages).
• Multiple reports show clear spike in findings after heavy AI adoption reduced human review.
Meta’s bug is just the latest visible example. Bugs existed before, but the volume and speed increased noticeably.
121
Was würden AppSec-Teams wohl eine nahezu allwissende Entität fragen? Die Antwort darauf kennt Cycode. Der Pionier im Bereich ASPM hat die ersten 100 Konversationen der Nutzer von Maestroausgewertet und aus ihnen die sechs häufigsten Fragen destilliert.
ap-verlag.de/anwendungssiche…
2
10

Karpathy coined "vibe coding" in February 2025. Describe what you want in natural language. AI generates the code. Ship it.
Fourteen months later, the hangover arrived.
41% of AI-generated code gets reverted within 30 days. 92% of audited vibe-coded applications have critical security vulnerabilities. YC W25 companies with 95% AI-generated codebases have 2,000 vulnerabilities across 5,600 apps.
(Sources: byteiota April 2026; Sherlock Forensics April 2026; Cycode March 2026)
The vibe coding party was real. The technical debt bill is also real. And a counter-movement just emerged that most teams haven't noticed yet:
Spec-Driven Development (SDD) — the discipline of writing precise specifications BEFORE the AI writes code, not after.
(Source: ProductBuilder.net, "Spec-Driven Development 2026 Guide", June 2026)
The claim is sharp: the most valuable skill in AI-era software development isn't coding. It's specification. Because AI can write code from specs — but it can't write specs from vibes.
The vibe coding failure pattern — why "just describe what you want" breaks at scale:
A DEV Community analysis from February 2026 captures it precisely:
"'Build me a dashboard' is not a task; it's a wish. Problem shaping breaks it into twelve specific, testable subtasks: What data does this dashboard display? What decisions does it support? What must the user understand within the first three seconds?"
(Source: DEV Community, "Skills Required for Building AI Agents in 2026", February 2026)
When you vibe-code "build me a dashboard," the AI builds A dashboard. Not THE dashboard you needed. It makes dozens of assumptions about data sources, layout, interactivity, permissions, refresh rates, edge cases, error states.
Some assumptions are right. Some are wrong. You don't know which ones are wrong until you ship and users complain. Then you fix. Then you ship again. Then more complaints. Then more fixes.
This is the vibe coding cycle: generate → discover it's wrong → regenerate → discover it's differently wrong → regenerate → eventually something sticks.
Each iteration costs time and tokens. The accumulated iterations often exceed what it would have cost to specify the requirements correctly upfront.
Vibe coding optimizes for "time to first version." Spec-driven development optimizes for "time to correct version." And "time to correct version" is what actually matters in production.
What spec-driven development actually looks like in 2026:
The Xcapit analysis nails the core distinction:
"Specifications almost always describe the happy path thoroughly and the edge cases barely at all. Error handling, concurrency behavior, backward compatibility constraints, performance requirements under load, and degradation modes are the areas where specs are thinnest — and where production bugs are densest. The reason is simple: enumerating edge cases is cognitively exhausting and unrewarding work, so humans skip it."
(Source: Xcapit, "Spec-Driven Development with AI Agents", February 2026)
SDD addresses this by making the specification — not the code — the primary artifact. Three variants have emerged:
Spec-First: write specs before code. Code remains the artifact you maintain. Specs drive the initial generation, then you maintain code directly.
Spec-as-Source: specs are the sole source of truth. Code is a fully generated byproduct. You never edit code — you edit the spec, and AI regenerates the code. (Tessl champions this approach.)
Spec-Anchored: specs drive generation but coexist with manually maintained code. Specs cover the architecture and business logic. Code covers the implementation details.
(Source: ProductBuilder.net, June 2026)
In practice, spec-anchored is winning in production. Pure spec-as-source is elegant but fragile — any code that needs to be hand-tuned gets overwritten on the next regeneration. Pure spec-first loses spec-code synchronization within weeks.
Spec-anchored keeps the spec as the architectural guide and the code as the maintained artifact — with AI bridging the gap in both directions.
The specification as the new unit of value:
Here's the claim most teams haven't processed yet:
The peer-reviewed research by Gorski & Stadzisz (cited in the Problem-Based SRS methodology) identifies the #1 cause of software project failures: "building what stakeholders asked for instead of what they needed."
(Source: GitHub, "Problem-Based-SRS", March 2026)
The fix isn't better coding. It's better requirement specification. And in 2026, the ability to write a precise, testable, unambiguous specification is more scarce — and more valuable — than the ability to write code.
Why? Because:
→ AI can write code from a good spec. Claude Code, Codex, Cursor — give them a precise specification and they generate working code 80-95% of the time.
→ AI cannot write a good spec from a vague description. "Build me a CRM" produces a CRM — but not YOUR CRM. The business rules, edge cases, integration constraints, and domain-specific requirements that make it YOUR CRM — those have to come from a human who understands the business.
→ The spec is where domain knowledge meets technical precision. It's the translation layer between "what the business needs" and "what the code does." AI can operate on either side of that translation. It cannot do the translation itself.
Vibe coding skips the translation. SDD makes the translation the primary work product. The code becomes a commodity. The spec becomes the valuable artifact.
This is exactly what the DEV Community analysis describes:
"Each sub-problem has clear inputs, clear outputs, and clear success criteria. When you decompose a vague goal into precise sub-problems, the Agent's execution quality transforms entirely. It no longer needs to guess your intent — it just follows clear instructions."
Claude Code Skills — SDD in practice, right now:
The ProductBuilder.net guide makes a practical connection:
"Claude Code Skills act as lightweight specifications — defining what Claude Code should do for common tasks like generating components, running test suites, or creating API endpoints. Skills bring SDD principles into everyday development without requiring a full spec-kit setup."
(Source: ProductBuilder.net, June 2026)
A SKILL.md file is a specification. It tells the AI: here's the pattern, here are the constraints, here's what good looks like, here's what to avoid. The AI reads it before writing any code.
The teams getting the best results from Claude Code in 2026 aren't the ones writing the best prompts. They're the ones writing the best SKILL.md files — the lightweight specifications that constrain the AI's behavior before it starts generating.
This is SDD without calling it SDD. The pattern is already winning. The name just hasn't caught on.
The specification-by-example pattern — the most practical SDD implementation:
Ürgo Ringo's November 2025 case study demonstrates the most accessible SDD workflow:
Human writes an example describing the system's behavior in Gherkin (given-when-then)
AI implements a failing test and verifies it fails for the correct reason
AI writes the production code to make the test pass
AI runs the full test suite to verify no regressions
Human reviews the AI's output at each step
(Source: Ürgo Ringo, "Using Specification by Example to Drive AI", November 2025)
The human's job is step 1 — writing the example. The AI's job is steps 2-4 — implementing, testing, verifying. The human reviews at step 5.
The human contributes specification. The AI contributes implementation. The specification is the bottleneck — and that's correct, because the specification is where the domain knowledge lives.
If the specification is wrong, the code will be wrong — no matter how good the AI is. If the specification is right, the code will be right — even if the AI needs a few iterations to get there.
Quality flows from specification to code, never the other way around.
What this means for different roles:
For senior engineers: Your value just shifted from "I can build complex systems" to "I can specify complex systems precisely enough that AI can build them." The building is commoditized. The specification is not. Write better specs, not better code.
For product managers: You're now in the critical path of engineering velocity. A precise PRD that maps to testable specifications is worth more than ever. A vague PRD that says "build a dashboard" generates 5 rounds of rework. A precise PRD with given-when-then examples generates working code on the first pass.
For junior developers: Learn to read specifications and verify them against business intent — not to write code from scratch. Your role is evolving from "implement" to "verify and refine." Understanding what a specification means and whether the AI's implementation satisfies it is the new entry-level skill.
For AI engineers building agents: Your agent specifications (system prompts, tool definitions, evaluation criteria) ARE specs. The quality of your agent is the quality of its specification. Invest more time in specifying agent behavior precisely and less time in prompt-tweaking after the fact.
Three uncomfortable questions:
1) When your team starts a new feature, do they write a specification before writing code — or do they describe what they want in natural language and let AI generate?
If "describe and generate" — you're vibe coding. It works for prototypes. It fails for production features where edge cases, error handling, and business rules matter. The rework cost of vibe-coded production features typically exceeds the upfront cost of specification.
2) Could someone who has never seen your codebase understand exactly what a feature is supposed to do — from the specification alone?
If "no, you'd need to read the code" — your specification is either missing or incomplete. When the specification IS the code, you've coupled understanding to implementation. When the specification is independent and complete, anyone — human or AI — can verify whether the code satisfies it.
3) When AI-generated code doesn't do what you expected, do you re-prompt — or do you improve the specification?
If "re-prompt" — you're optimizing the wrong layer. The prompt is ephemeral. The specification is durable. A better specification produces better code on every future generation — across models, across tools, across team members. A better prompt produces better code once.
The thesis:
→ February 2025: "vibe coding" — describe what you want, AI generates it, ship fast → 2025-2026: "vibe coding debt" — 41% revert rate, 92% security vulnerabilities, codebases nobody can maintain → June 2026: "spec-driven development — write precise specifications, AI generates from specs, verify against specs. The specification is the product. The code is a byproduct. The most valuable skill is no longer writing code — it's writing specifications that code can be generated from."
Vibe coding democratized code generation. SDD is professionalizing it.
The difference between "AI wrote some code" and "AI wrote the right code" is the specification. Always has been. Always will be.
The boring specification work wins. It always does. Especially when vibe-coded production features are getting reverted 41% of the time — because nobody specified what "correct" meant before asking the AI to build it.
5
4
426
A number that should stop every engineering leader celebrating their AI coding adoption metrics:
45% of AI-generated code fails security tests. Across 100 LLMs. Across Java, Python, C#, and JavaScript. Tested on OWASP Top 10 vulnerability categories.
(Source: Veracode, "State of Software Security 2026", analyzing 1.6 million applications)
Not edge cases. Not exotic exploits. OWASP Top 10 — the basics. SQL injection. Cross-site scripting. Log injection. Insecure cryptography.
86% of AI-generated samples failed to defend against cross-site scripting. 88% were vulnerable to log injection. Java code was worst at a 72% failure rate.
(Source: Cloud Security Alliance, "Vibe Coding's Security Debt: The AI-Generated CVE Surge", April 2026)
Now combine that with this: 42% of production code is AI-generated in 2026. Heading to 50% by early 2027.
You're shipping code faster than ever. You're also shipping vulnerabilities at 2.74x the rate of human developers.
(Source: Veracode GenAI Code Security Report; SoftwareSeni analysis, February 2026)
And here's the number that should genuinely alarm every CISO on the planet:
Sherlock Forensics audited 50 AI-built applications between January and April 2026. Real apps. Real users. Built with Cursor, Copilot, ChatGPT, Claude.
92% had critical vulnerabilities. 78% stored secrets in plaintext.
(Source: Sherlock Forensics, "AI Code Security Report 2026", April 2026)
Ninety-two percent. Of production applications. Serving real users. With critical-severity flaws.
This is not a future problem. This is a now problem. And the attack surface is growing at the same rate as AI code adoption — 42% of your codebase, increasing monthly.
The specific vulnerability patterns AI coding tools introduce — and why they're worse than human mistakes:
Apiiro's research across Fortune 50 enterprises found the vulnerability increase isn't uniform. Some categories are dramatically worse:
→ Privilege escalation paths: up 322%→ Architectural design flaws: up 153%→ Secrets exposure: up 40%→ Insecure dependencies: 70% of application vulnerabilities now trace to dependencies — and AI-assisted development increases dependency sprawl by 20-30%
(Sources: Apiiro research cited in SoftwareSeni February 2026; SQ Magazine "AI Coding Security Statistics 2026" April 2026)
Read those categories carefully. The flaws that increased most are not the simple ones (typos, syntax errors). They're the architectural ones — privilege escalation, design flaws. These are the vulnerabilities that require deep contextual reasoning to detect, and they're exactly the kind of reasoning AI coding tools are worst at.
Why? Because AI coding tools optimize for functionality — making the code work. Security is a constraint that conflicts with functionality. When the model has to choose between "code that compiles and runs" and "code that compiles, runs, AND properly validates permissions" — it defaults to the shorter, simpler, less-secure version.
The Cloud Security Alliance's analysis puts it bluntly:
"AI code assistants optimize for functionality, speed, and developer satisfaction. Security is a constraint that conflicts with those goals. The result is code that works, compiles, passes basic tests, and ships to production carrying exploitable vulnerabilities."
(Source: Cloud Security Alliance, April 2026)
The Amazon incident that made this concrete:
In March 2026, Amazon experienced a 6-hour outage affecting 6.3 million orders — linked to AI-generated code issues.
(Source: SQ Magazine, April 2026)
Six hours. Six point three million orders. From code that was generated by AI, reviewed by humans, passed CI/CD, and made it to production — carrying a flaw that human review didn't catch because the reviewer didn't write the code and couldn't fully reason about its implications.
This is the pattern that scales dangerously: AI generates code fast → human reviews it fast (because there's so much of it) → review quality degrades → vulnerabilities pass through → production incidents increase.
The data confirms this pattern is systemic: production incidents per pull request increased 23.5% between December 2025 and early 2026.
(Source: Paperclipped "AI-Generated Code Vulnerabilities 2026", March 2026)
The vibe coding security crisis — 2,000 vulnerabilities in 5,600 apps:
Wiz Research scanned approximately 5,600 applications built with "vibe coding" practices — where developers describe what they want in natural language and AI generates the entire codebase.
They found: over 2,000 vulnerabilities and 400 exposed secrets.
Client-side authentication bypasses. Hardcoded API keys. Insecure database access. Exposed internal applications.
(Source: Cycode, "Top AI Security Vulnerabilities 2026", March 2026)
25% of Y Combinator's Winter 2025 cohort reported codebases that were 95% AI-generated. These are the companies that will be raising Series A in 2026 with codebases carrying vulnerability densities that would fail any enterprise security audit.
Georgia Tech's Vibe Security Radar project is tracking CVEs specifically traceable to AI coding tools. As of March 2026: 74 CVEs catalogued. The trend line is accelerating — 6 in January 2026, growing monthly as more AI-generated code reaches production and gets tested by attackers.
(Source: Cloud Security Alliance, April 2026, citing Georgia Tech's Vibe Security Radar)
Why traditional security tooling isn't catching this:
Here's the finding that should restructure every AppSec team's approach:
A single SAST (Static Application Security Testing) tool catches under 22% of AI code vulnerabilities.
(Source: Paperclipped, March 2026)
Under 22%. That means if you're running one SAST scanner — which is what most teams do — you're catching less than a quarter of the vulnerabilities your AI tools are introducing.
Why? Two reasons:
First, AI-generated vulnerabilities are often structurally different from human-generated ones. They appear in patterns that traditional SAST rules weren't designed to detect — because humans don't make those specific mistakes.
Second, AI-generated code has higher dependency complexity. AI tools pull in more packages, more libraries, more third-party code — each carrying its own vulnerability surface. SAST scans your code. It doesn't deeply scan every transitive dependency your AI tool decided to include.
The fix: run at least three SAST tools (Veracode Semgrep Snyk, or equivalent). Each tool catches different vulnerability patterns. Combined coverage is 60-75% — still not complete, but dramatically better than 22%.
And for high-risk code paths — authentication, payment processing, encryption, access control — prohibit AI-generated code entirely without mandatory human security review.
The model-level data most teams haven't seen:
AppSec Santa's 2026 study compared vulnerability rates across frontier models:
→ GPT-5.2: 19.1% vulnerability rate (best) → DeepSeek V3: 29.2% (worst, tied) → Claude Opus 4.6: 29.2% (worst, tied) → Llama 4 Maverick: 29.2% (worst, tied)
(Source: Paperclipped, March 2026)
No model produces consistently secure code. The best model still introduces vulnerabilities in nearly 1 out of 5 generations. The worst models do it in nearly 1 out of 3.
If you're choosing your coding model based on SWE-bench scores or coding speed benchmarks — you're optimizing for the wrong metric. The security vulnerability rate varies 1.5x across frontier models, and most teams don't know where their model sits on this spectrum because they've never measured it.
What production teams should be doing — concretely:
1) Track what percentage of your codebase is AI-generated.
67% of security teams report they can't track AI-generated code changes. If you don't know which code is AI-generated, you can't scope your security testing to match the risk profile. AI-generated code needs more scrutiny, not less — and you can't apply more scrutiny if you can't identify it.
2) Run 3 SAST tools, not 1.
Single-tool coverage: <22%. Triple-tool coverage: 60-75%. The marginal cost of a second and third scanner is trivial compared to the cost of shipping a privilege escalation vulnerability to production.
3) Hard-block AI-generated code in security-critical paths without human review.
Authentication. Authorization. Payment processing. Encryption. Data access control. These paths should have a mandatory human security review gate — regardless of how confident the developer is that the AI-generated code is correct.
4) Treat AI-generated code like third-party code, not like your own code.
The Cycode guidance captures this perfectly: "deploying AI code unverified is like giving a fresh intern production access on their first day." You wouldn't ship a third-party library without scanning it. Don't ship AI-generated code without scanning it either.
5) Measure your model's vulnerability rate on YOUR codebase.
The aggregate numbers (45% failure, 2.74x more vulnerabilities) are averages. Your actual rate depends on your language, your domain, your code patterns, and which model you use. Measure it. If your AI coding tool is introducing vulnerabilities at >30%, that's a cost you need to factor into your "AI productivity" calculation — because every vulnerability that reaches production costs $5K-50K to remediate.
Three uncomfortable questions:
1) What percentage of your codebase is AI-generated — and does your security testing budget reflect that percentage?
If 42% of your code is AI-generated but your security testing capacity is unchanged from 2024 — you have a coverage gap that's growing monthly. AI code needs MORE testing, not the same amount. The 2.74x vulnerability multiplier means your testing effort should scale proportionally.
2) When was the last time you scanned your AI-generated code specifically for OWASP Top 10 vulnerabilities — and what was the failure rate?
If "never" — you don't know your actual exposure. The industry average is 45% failure. Yours might be better or worse. Without measurement, you're assuming security rather than verifying it.
3) Does your CI/CD pipeline have different security gates for AI-generated code vs human-written code?
If "same gates for both" — you're applying human-code-calibrated security standards to code that has 2.74x more vulnerabilities. The gates need to be higher for AI-generated code, not the same. At minimum: additional SAST tools, mandatory review for security-critical paths, and dependency scanning for every AI-introduced package.
The thesis:
→ 2024: "AI makes developers 55% faster" (the headline) → 2025: "AI-generated code has 2.74x more vulnerabilities" (the fine print nobody read) → 2026: "42% of production code is AI-generated, 45% fails security tests, 92% of audited AI-built apps have critical flaws, and the security testing infrastructure hasn't scaled to match — creating the largest application security debt accumulation in software history"
We made coding 50% faster. We made security testing 0% faster. The gap between code velocity and security velocity is the vulnerability window — and it's growing every month.
The teams treating AI-generated code like human-written code are accumulating security debt at 2.74x the historical rate. The teams treating AI-generated code like third-party code — scanning it, gating it, reviewing it, tracking it — are catching what the others are shipping.
Same AI tools. Same code output. Different security posture.
The boring security scanning infrastructure wins. It always does. Especially when 42% of your codebase was written by a tool that fails basic OWASP security tests 45% of the time — and your CI/CD pipeline treats it the same as code written by your most experienced security-conscious engineer.
3
1
1
286





Apr 20
The algorithm of Bearer from Cycode, an Israeli startup funded by the Mossad?🫣
3
77


29 Aug 2025
Künstliche Intelligenz birgt Gefahren und Chancen für die Anwendungssicherheit
#ApplicationSecurity #ApSec #APSM #CitizenDeveloper #Cybersicherheit @Cycode #GenAI #künstlicheIntelligenz #LowCode #NoCode #VibeCoding
netzpalaver.de/2025/08/29/ku…

2
3
189

20 Aug 2025
Cycode Highlights #AI's Growing Role in #ApplicationSecurity at #BlackHat USA 2025 📣
🔗 Read the full story at thefastmode.com/conferences-…
#ai #networksecurity #cybersecurity #blackhat @CycodeHQ @TaraNeal11
1
2
81

21 Jul 2025
Had 60 interviews. I interviewed with every company out there. Microsoft, GitLab, GitHub, Cycode, Atlassian, etc. interviewing, demoing. Couldn’t land nothing. I would here back with a no and no feedback and couple times the recruiter was laid off while I was
1
5
293

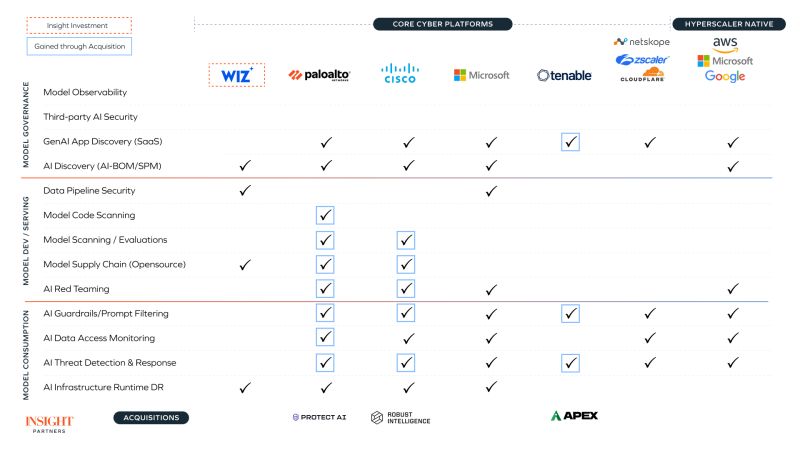
AI Security Market Map - insightpartners.com/ideas/se…
As generative AI adoption expands across enterprises, security teams are under pressure to keep up. Based on analysis from Insight Partners and conversations with CISOs, here are 10 key takeaways on how AI security is evolving — and where the most urgent gaps and opportunities are emerging.
1️⃣ AI adoption is accelerating – Enterprises are scaling internal genAI tools like Copilots and chat assistants.
2️⃣ CISOs are preparing to buy – Security leaders are actively evaluating solutions to get ahead of risks.
3️⃣ Two focus areas emerging – Development-time (e.g. model scanning) and runtime (e.g. prompt filtering, DLP).
4️⃣ Runtime security leads today – Guardrails, prompt filtering, and AI firewalls are top near-term priorities.
5️⃣ Development security is early but rising – Demand is growing as teams fine-tune models and build AI agents.
6️⃣ Startups are gaining ground – Buyers want alternatives to incumbents like Microsoft and Palo Alto.
7️⃣ Overcrowding in some areas – Red teaming, prompt filtering, and detection are ripe for consolidation.
8️⃣ AI agents are the next frontier – Securing agent behavior and workflows will define long-term solutions.
9️⃣ AI dev environments need hardening – Securing model pipelines, dev tools, and supply chains is a major gap.
🔟 Security should be built-in – AI protection must span the full lifecycle, not bolted on post-deployment.
Source: insightpartners.com/ideas/se… by @insightpartners
@wiz , @orcasecurity, #Tonicai, #Reco, #WeightsAndBiases, @fastinoAI, @privacera, @fiddler_ai, #Cranium, @SkyflowAPI, @AppOmniSecurity, @zenitysec , #AnjunaSecurity, #Prompt, #ProtectAI, #VirtueAI, @PromptArmor, @witnessAI, #Cycode, @Dynamoai, @DK_TRiSM, #GraySwan, #Island, @NomaSecurity, #NomicAI, @Pillar_sec, @enkrypt, @lasso, @calypsoai, @TrojAISec, #OPAQUE, @fortanix, @TeleskopeAI, #Modulos, @CredoAI, #HolisticAI #Arize #Humanoop ActiveFence, #Iceberg, #Lakera, #Striker, #SplxAI, #HackerOne, #Valence, #HaizeLabs, #GuardrailsAI, #Liminal, #DataSentinel, @openlayerco, #Citrusx, @mindgard, #Aunsacapp #Apex #APORIA, #Cyberhaven, #SurePathAI, #Harmonic, #Pangea #Hazy #RobustIntelligence, #AdversaAI #MarketMap #AISecurity #LLMSecurity #MLSecOps #DevSecOps

2
6
234
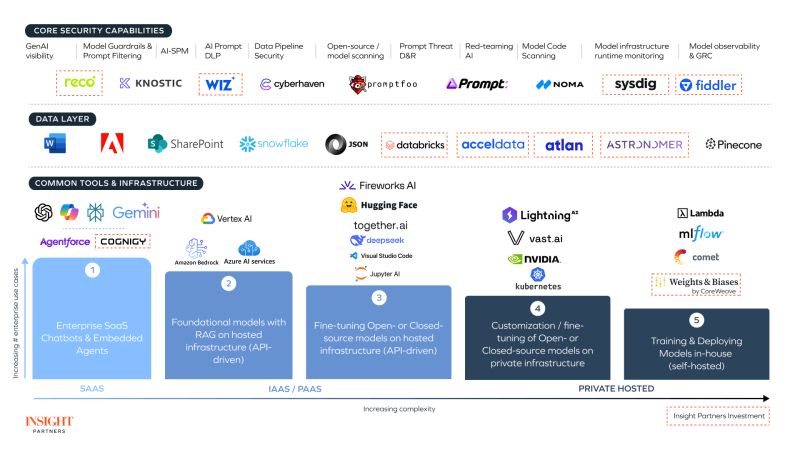
AI Security Market Map
🔒 Model Governance —
@PatronusAI, @fiddler_ai, Humanoop, Arize, @braintrustdata, Citrusx, @openlayerco, CredoAI, Cranium, WitnessAI, DynamoAI, HolisticAI, @Modulos_ai, PromptArmor, Reco, Wing, Valence, AppOmni, Apex, @SurePathAI, Aunsacapp, @wiz, @orcasec, Prompt, Zenity, Operant
🛠️ Model Dev / Serving —
Data Pipeline Security: #Wiz, #Orca, #Tomic, #Noma
Model Code Scanning: #Aisheld, #Cycode, #Noma
Model Scanning / Evaluation: #Aisheld, #ProtectAI, #Promptfo, #Giskard, #HolisticLabs, #DynamoAI, #Lakera
Model Supply Chain: #Cranium, #Hiddenlayer, #Noma
🧪 AI Red Teaming — Cranium, ProtectAI, Mindgard, Adversa, Lakera, Dreadnought, CalypsoAI, Lasso, GraySwan, @enkryptai, HackerOne, Prompt, ActiveFence, Splx, TrojAI, Hiddenlayer, VirtueAI
📦 Model Consumption
Prompt Filtering: #Fastinow, #Prompt, #Noma, #WitnessAI, #Liminal, #ActiveFence, #DeepKeep, #Lakera, #GraySwan, #EnkryptAI, #VirtueAI, #DynamoAI
Prompt DLP: #Nightfall, #Lakera, #Knostic, #Privacera, #Harmonic, #Lasso, #Zenity, #SurePathAI, #DeepKeep, #CalypsoAI, #Fastinow
🧰 Data Security for AI Models —
@CyberhavenInc, @DataSentinel, PrivateAI, @SkyflowAPI, Anjuna, Opaque, Fortanix, Teloskope, @knosticai
🚨 AI Threat Detection & Response -
@lasso , @calypsoai , @hiddenlayersec, @LakeraAI, @NomaSecurity, DeepKeep, @TrojAISec, Iceberg, WitnessAI, EnkryptAI, Fastinow, @protectai_com, Apex, Opaque, @zenitysec, Striker, Operant, @Pillar_sec, Pangea
By @insightpartners

1
6
17
1,054
9 Jul 2025
KI-Agenten gegen Hacker
#AgenticAI #AITeammate #Anwendungssicherheit #ApplicationSecurity #AppSec #Cybersecurity @Cycode #KIAgent #SoftwareDevelopment #SupplyChain #ThreatDetection
netzpalaver.de/2025/07/08/ki…

3
5
109

20 May 2025
Q&A with Cycode on RSA 2025: Amir Kazemi Discusses Latest Launch and Securing Agentic AI ift.tt/fAThgkZ #webhosting
1
2
73

17 Apr 2025
#Software muss sicher von Anfang an sein. „Security by Design“ wird damit vom Buzzword zur Überlebensstrategie. Cycode zeigt, wie Unternehmen diesen Paradigmenwechsel in vier konkreten Schritten meistern. it-daily.net/it-sicherheit/c…
2
71

14 Jan 2025
Nirgendwo auf der Welt wird Application Security (AppSec) so großgeschrieben wie in Deutschland. Das belegt der State of ASPM Report von Cycode. Deutschland ist damit Vorreiter in Sachen Anwendungssicherheit.
ap-verlag.de/aspm-deutschlan…
2
21