
🚀 Session Spotlight | Sangam AI Yatra 2026
🔗 Register Now: aioug.org/sangam26
AI is changing databases. But when production slows down, DBAs still need answers.
💡 Why This Session Matters
Oracle Database 26ai introduces a wave of new features, but not every feature matters when you're troubleshooting a production issue at 2 AM.
This session focuses on what performance DBAs actually need to know.
We'll look at practical performance enhancements in Oracle Database 26ai, including optimizer improvements, SQL Plan Management enhancements, and how AI-related features such as Vector Search and vector indexes impact database performance.
More importantly, we'll discuss how AI is changing the DBA toolkit while reinforcing why foundational skills around AWR, ASH, SQL Monitoring, execution plans, and performance diagnostics remain as important as ever.
If your role involves performance tuning, troubleshooting, or database optimization, this session is designed to help you separate the genuinely useful innovations from the marketing noise.
🎯 What You'll Learn
✅ SQL Plan Management and optimizer enhancements in Oracle Database 26ai
✅ Performance implications of AI Vector Search, vector indexing, and hybrid workloads
✅ How AI is reshaping the performance DBA's toolkit
✅ Where automation helps—and where traditional DBA expertise remains irreplaceable
✅ Practical guidance for diagnosing and tuning modern Oracle Database workloads
👤 About the Speaker
Aishwarya Kala @aishwaryakala13 is a Principal Consultant at Pythian with more than 17 years of experience across Oracle and other database technologies. An Oracle ACE, blogger at ORA Trails, and frequent international conference speaker, she is passionate about helping organizations solve real-world database performance challenges through a combination of deep technical expertise and practical experience.
🎟️ View Session Details: aioug.org/sangam26/session?i…
⏳ AI may be changing the database landscape, but good performance diagnostics never go out of style.
📍 Sangam AI Yatra 2026
Hyderabad: 19 Jul 2026
🔗 Register today: aioug.org/sangam26
#SangamAIYatra2026 #OracleDatabase #Oracle26ai #PerformanceTuning #AWR #ASH #SQLPlanManagement #DatabasePerformance #AIOUG
@Oracle @oracleugs @oracleace @OracleDevs @oracledevcomm @OracleDatabase @OracleCloud

1
4
69

Jun 11
Optimize your Progress @_OpenEdge_ database performance.
Join us on June 24th to learn how to identify bottlenecks, improve stability, and apply proven tuning techniques in our upcoming webinar.
➡️ prgress.co/4fxAvUe
#ProgressOpenEdge #DatabasePerformance

ALT Improving Your OpenEdge Database Performance NEW WEBINAR
1
48

"🗄️ DB Tip of the Day: Implement database caching strategies like query cache and result set caching to improve query performance and reduce server load 📊 #DatabasePerformance"
2
🚀 Session Spotlight | Sangam AI Yatra 2026
🔗 Register Now: aioug.org/sangam26
AI may be changing applications, but one truth remains: slow SQL creates slow applications.
💡 Why This Session Matters
As organizations embrace AI, analytics, and real-time decision-making, databases are being asked to process more data, more queries, and more complex workloads than ever before.
The foundation of every high-performing application still starts with one thing: efficient SQL.
This session takes a practical look at Oracle Database performance, the Oracle Optimizer, SQL tuning techniques, and the shared responsibility between developers, DBAs, and architects in delivering fast, reliable systems.
Whether you're supporting transactional applications, data warehouses, or AI-powered workloads, understanding how Oracle executes SQL remains one of the most valuable skills in your toolkit.
🎯 What You'll Learn
✅ How Oracle Database and application performance are connected
✅ SQL optimization techniques and performance tuning strategies
✅ How DBAs can evolve into AI-powered database experts while maintaining performance and reliability
👤 About the Speaker
Vivek Sharma @vivek_oracle is a Technical Lead in Oracle's Data Warehousing Development and Global Leaders Program. With nearly 25 years of experience and deep expertise in Oracle Database performance and the Optimizer, he works closely with Oracle's strategic customers across JAPAC to deliver successful Autonomous Data Warehouse implementations.
🎟️ View Session Details: aioug.org/sangam26/session?i…
⏳ New AI technologies may grab the headlines, but smart SQL is still what powers fast applications.
📍 Sangam AI Yatra 2026
Bengaluru: 18 Jul 2026
Hyderabad: 19 Jul 2026
🔗 Register today: aioug.org/sangam26
#SangamAIYatra2026 #OracleDatabase #SQLTuning #OracleOptimizer #DatabasePerformance #AutonomousDatabase #AI #PerformanceTuning #AIOUG
@Oracle @oracleugs @oracleace @OracleDevs @oracledevcomm @OracleDatabase @OracleCloud

1
40

⚙️MAXDOP. Query Store. Compatibility Level. Cost Threshold.
You know the settings exist... but are they helping or hurting your SQL Server?🤔
Join @leemarkum at Nebraska.Code() to learn:
✅ Which defaults to change
✅ Performance tuning tips
✅ Query optimization features
✅ SQL Server configuration best practices
🔗 nebraskacode.amegala.com/
#SQLServer #DBA #DatabasePerformance #Tech #DataPlatform #Nebraska #MAXDOP #QueryStore

1
16
"🗄️ DB Tip of the Day: Optimize database connections by using connection pooling and reducing idle connection time to minimize resource consumption and improve performance 📊 #DatabasePerformance"
2
🚀 Session Spotlight | Sangam AI Yatra 2026
🔗 Register Now: lnkd.in/eGiU-qQf
Need to review performance across multiple AWR or Statspack reports? Here’s an open-source tool that can help.
💡 Why This Session Matters
Performance analysis is rarely about looking at one report in isolation. DBAs often need to compare multiple AWR or Statspack reports, identify patterns over time, spot bottlenecks, and understand which waits, SQLs, and statistics really matter.
That is where JAS-MIN comes in.
Inspired by Oracle’s internal AWR Miner tool, JAS-MIN is a free, open-source community tool written in Rust. It can parse hundreds of AWR and Statspack reports, visualize performance statistics, and integrate with modern LLMs to help build deeper performance insights.
🎯 What You'll Learn
✅ How to find patterns across AWR and Statspack reports
✅ How to use advanced statistics to identify bottlenecks
✅ How LLMs can support comprehensive performance reporting
👤 About the Speaker
@ora600pl Kamil Stawiarski is an Oracle ACE Director, Oracle Certified Master, OakTable member, blogger, and co-owner of ORA-600 Database Whisperers. Known for his deep Oracle performance expertise, Kamil combines technical depth with storytelling and community-driven innovation.
🎟️ View Session Details: aioug.org/sangam26/session?i…
⏳ When performance data is spread across many reports, the right tool can help the story emerge faster.
📍 Sangam AI Yatra 2026
Bengaluru: 18 Jul 2026
Hyderabad: 19 Jul 2026
🔗 Register today: lnkd.in/eGiU-qQf
#SangamAIYatra2026 #OracleDatabase #PerformanceTuning #AWR #Statspack #DatabasePerformance #LLM #OpenSource #AIOUG
@Oracle @oracleugs @oracleace @OracleDevs @oracledevcomm @OracleDatabase @OracleCloud

2
3
175

May 29
If you've ever stared at a table that's still 138 MB after deleting 600,000 rows, you already understand the problem.
Postgres doesn't return bloated space to the OS after a VACUUM - it just marks dead tuples as reusable. The only built-in ways to actually reclaim space, VACUUM FULL and CLUSTER, require an ACCESS EXCLUSIVE lock for the entire operation. On a 1TB table in a production system, that's a non-starter.
So DBAs have reached for tools like pg_repack and pg_squeeze - third-party utilities that rewrite tables with minimal locking by leveraging logical decoding. They work, mostly. But they operate outside the core engine's safety guarantees, and that's enough to make conservative shops nervous.
Postgres 19 may change the calculus entirely.
The new REPACK command brings this functionality into the core engine, with a CONCURRENTLY option that holds an ACCESS EXCLUSIVE lock only during the brief final swap - not for the entire rewrite. Shaun Thomas walks through the full demo: 138 MB down to 52 MB, space genuinely returned to the OS.
There's also a USING INDEX option that replaces CLUSTER, reordering rows physically to match an index. In his benchmark, that dropped a query from 3,300 buffer reads to 49, and execution time from 3ms to 0.6ms.
Worth noting: REPACK CONCURRENTLY isn't MVCC-safe in a narrow edge case (transactions that have a snapshot open but haven't yet touched the table). Shaun explains when that matters and when it doesn't.
Postgres 19 is still in development, so this could still change. But if it ships, it'll be one of the more practically useful additions for anyone running large, write-heavy databases.
Read the full post: hubs.la/Q04jqCKS0
#PostgreSQL #Postgres19 #DatabaseEngineering #DBA #OpenSource #Postgres #DatabasePerformance

3
235

May 25
🚀 Excited for #PerconaLive this week?
Don't miss how #ProxySQL powers high-performance load balancing, read/write splitting, connection pooling, and query routing for MySQL, PostgreSQL, and Percona clusters — at scale, with zero downtime.
Join the conversation on intelligent proxies that make your databases faster and more resilient.
See you in Mountain View! 👋
proxysql.com/
#OpenSource #MySQL #PostgreSQL #DatabasePerformance #ProxySQL
2
129

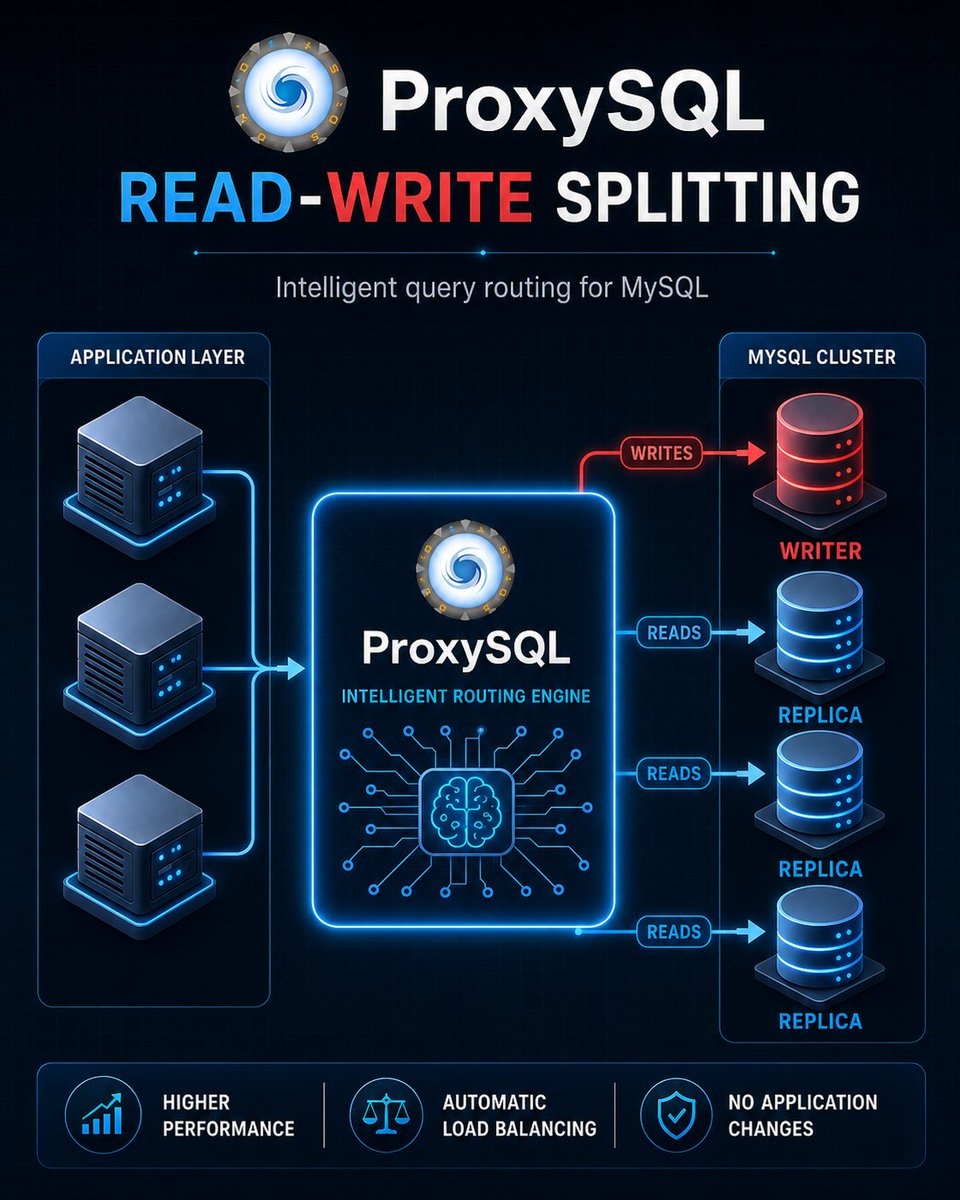
📌 ProxySQL Read-Write Splitting – The Smart Way to Scale MySQL
Tired of your database becoming a bottleneck?
With ProxySQL, you can automatically route read queries to replica servers and write queries to the writer node — without changing a single line in your application.
Key Benefits:
✅ Better performance & lower latency
✅ Automatic load balancing
✅ Higher availability
✅ No application changes needed
This is one of the most powerful features of ProxySQL for high-traffic applications.
👉 Save this infographic if you work with MySQL, MariaDB, or PostgreSQL!
What’s your biggest database scaling challenge right now? Drop it in the comments 👇
#ProxySQL #MySQL #DatabasePerformance #ReadWriteSplitting #DevOps #Backend #HighAvailability
1
1
10
590

May 13
Postdoc Position in Data Warehousing @ TU Wien (Vienna)
Research on #dataWarehousing, #analytics & #databasePerformance bridging #dataSystems and #LLM interfaces.
Deadline: May 21, 2026
Application portal:
jobs.tuwien.ac.at/Job/266692
Lab:
dmki-tuwien.github.io

1
7
318

May 6
Every slow query leaves clues.
Sometimes it is blocking.
Sometimes it is high CPU.
Sometimes it is wait stats quietly waving from the corner.
Sometimes it is a poor execution plan doing “creative work” in production. 🙂
That is why performance tuning is not just about fixing one query. It is about following the evidence, reading the plan, asking better questions, and understanding what SQL Server is really trying to do.
I am excited to present:
SQL Server Performance Survival Kit for the AI Era
May 11
Workshop • Techorama Belgium
In this workshop, we will explore practical ways to identify performance problems, analyze execution plans, understand wait stats, and use AI-driven insights without losing the human judgment that real production systems still need.
Follow the clues. Fix the performance.
See you at Techorama Belgium.
#SQLServer #PerformanceTuning #QueryTuning #ExecutionPlans #WaitStats #AI #DatabasePerformance #Techorama #PinalDave

3
326
May 5
PRESS START TO SURVIVE 🎮
Slow queries. Blocking. Deadlocks. High CPU. Wait stats. Bad plans.
Every SQL Server professional has faced this game before. The only difference is that in production, there is no reset button. 😄
That is exactly why I am excited for my workshop:
SQL Server Performance Survival Kit for the AI Era - May 11
Workshop • @TechoramaBE Belgium
We will talk about real-world SQL Server performance problems, practical tuning methods, execution plans, Query Store, troubleshooting patterns, and how AI can help us work faster without replacing the experience that comes from years in the field.
AI can assist.
Good judgment still wins the game.
Looking forward to seeing many of you there.
techorama.be/schedule/worksh…
#SQLServer #PerformanceTuning #DatabasePerformance #AI #DBA #Techorama #TechoramaBelgium

2
248
May 3
Sometimes the best way to explain a serious workshop is with crayons, scribbles, and pure childhood confidence. 🎨
On May 11, I’ll be at @TechoramaBE Belgium with:
SQL Server Performance Survival Kit for the AI Era
The topic is serious: SQL Server performance, execution plans, Query Store, tuning, troubleshooting, and what changes when AI enters the room.
A joyful reminder that learning can still be fun.
See you there.
#Techorama #SQLServer #SQLAuthority #DatabasePerformance #QueryStore #AI #DataEngineering

4
486
May 2
On May 11, I’ll be at @TechoramaBE Belgium with my workshop:
SQL Server Performance Survival Kit for the AI Era
We’ll talk about the performance problems that still hurt in real systems, including slow queries, execution plans, indexing mistakes, wait stats, Query Store, and the new pressure AI is bringing into the database world.
AI can help.
But when performance breaks, experience still matters.
No dancing backup servers planned. Probably.
#Techorama #SQLServer #SQLAuthority #DatabasePerformance #QueryStore #AI #DataEngineering

3
453

Apr 15
Is your Rails application suffering from slow database queries? We've put together a comprehensive guide covering everything from ActiveRecord's explain method to gems like Bullet and PgHero, plus database-specific tools for PostgreSQL, MySQL, and SQLite. Read More...blog.saeloun.com/2026/04/15/… #RubyOnRails #Rails #PostgreSQL #MySQL #DatabasePerformance #WebDevelopment #Ruby

2
6
151

Behind every high-performing database is an expert who knows how to unlock its true potential—and Nitin Mare is exactly that expert. With 19 years of hands-on experience in database administration and architecture.
#OracleDBA #DatabasePerformance #TechLeadership #CloudComputing

2
6

Mar 11
Your SQL Query Might Be 10× Slower… And You Probably Don’t Know Why.
Early in my career, I wrote a query that looked perfectly fine.
SELECT *
FROM Sales
WHERE OrderDate >= '2025-01-01'
It worked.
It returned the data.
The dashboard refreshed.
So I moved on.
Then the complaints started.
- “Why is this report so slow?”
- “Why does it take 30 seconds to load?”
- “Why is the database under pressure every morning?”
At first glance, nothing looked wrong.
Until I saw the real problem.
SELECT *
Three harmless characters that quietly destroy performance.
Let’s break down what’s actually happening.
What Happens When You Use SELECT *
When SQL sees SELECT *, it retrieves every column in the table.
Even the ones you don’t need.
Imagine a table like this:
Sales Table has this columns -
OrderID, CustomerID, Product, Amount, Discount, Notes, CreatedBy, UpdatedBy, AuditFlag, Metadata
But your report only needs:
• OrderID
• Product
• Amount
Yet SQL still pulls all 10 columns.
Which means:
• More disk reads
• More memory usage
• More network transfer
• Slower query execution
Multiply that across millions of rows and suddenly your database is doing 10× the work it actually needs.
The Hidden Problem Most People Miss
The real issue isn't just performance.
It's future breakage.
Let’s say a developer adds a new column:
LargeDocumentBlob
Suddenly your query now retrieves huge objects you never intended to load.
Your report becomes slower overnight.
And nobody understands why.
This is why experienced database engineers treat SELECT * as a code smell.
What Happens When You Specify Columns Instead
Instead of this:
SELECT *
FROM Sales
Do this:
SELECT OrderID, Product, Amount
FROM Sales
Now the database engine:
• Reads fewer pages from disk
• Uses less memory
• Transfers less data across the network
• Allows indexes to work more efficiently
In large systems, this single change can turn 30-second queries into 2-second queries.
A Real-World Analogy
Imagine ordering food at a restaurant.
You ask for:
“Everything in the kitchen.”
The chef brings:
• rice
• soup
• bread
• steak
• desserts
• raw ingredients
• cooking utensils
You only needed one plate of pasta.
That’s SELECT *
Now imagine saying:
“I want pasta.”
That’s specifying columns.
The Best Practice
Professional SQL developers follow a simple rule:
Always request only the data you actually need.
Do this consistently and you get:
• Faster queries
• More stable dashboards
• Predictable performance
• Safer schema changes
Small habit.
Massive impact.
Most performance problems in analytics systems aren't caused by complex algorithms.
They're caused by small habits repeated thousands of times.
And SELECT * is one of the most common.
If you work with SQL, bookmark this rule:
Request only the data you need.
Your database will thank you for it.
#SQL #DataEngineering #DataAnalytics #DatabasePerformance #PowerBI #AnalyticsEngineering #DataArchitecture #SQLTips

1
10
312

Mar 2
Spring Boot Performance Killers 🚨 7 Mistakes 90% Developers Ignore
#SpringBoot #JavaPerformance #BackendEngineering #PerformanceEngineering #MicroservicesArchitecture #JPAOptimization #Hibernate #HikariCP #Resilience4j #RedisCaching #DatabasePerformance #SoftwareArchitecture
2
20

Strong systems start with strong fundamentals. 🛠️
At #Devnexus, Sean McNealy revisits transaction isolation and database behavior to sharpen your understanding of consistency and performance.
devnexus.com/events/isolatio…
🎟️ Get tickets: devnexus.com
✉️ Sign up to keep up to date with all the conference info atlj.ug/Xconnect
#Databases #Java #DatabasePerformance #TransactionManagement #SoftwareEngineering #DeveloperEducation #DatabaseFundamentals #TechConference #DevCommunity

1
2
147