
Just finished today's #SummerAnalytics2026 content 🔥
I learned regularizationa and its types L1 , L2 , elasticnet and concept of bias variance. was very insightfull and stressfull
#BuildInPublic @cnaiitg
1
14

Jun 12
As a Machine Learning Engineer, slap yourself if you cannot clearly explain at least 10 of the following:
Bias-variance tradeoff
Overfitting vs underfitting
Train/validation/test split strategy
Cross-validation pitfalls
Data leakage
Feature scaling and normalization
One-hot encoding vs ordinal encoding
Target encoding leakage
Missing value imputation strategies
Outlier handling
Class imbalance techniques
Precision vs recall vs F1-score
ROC-AUC vs PR-AUC
Confusion matrix interpretation
Calibration of probabilities
Logistic regression internals
Linear regression assumptions
Ridge vs Lasso regularization
ElasticNet trade-offs
Gradient descent vs stochastic gradient descent
Learning rate scheduling
Batch size effects
Loss functions: MSE, MAE, cross-entropy
Convex vs non-convex optimization
Vanishing and exploding gradients
Backpropagation internals
Activation functions: ReLU, GELU, sigmoid, tanh
Batch normalization vs layer normalization
Dropout regularization
Weight initialization strategies
CNNs and convolution internals
RNNs, LSTMs, and GRUs
Attention mechanism
Transformers architecture
Positional encoding
Self-attention vs cross-attention
Embedding spaces
Tokenization: BPE, WordPiece, SentencePiece
Fine-tuning vs feature extraction
Transfer learning
Prompt engineering basics
LoRA and parameter-efficient fine-tuning
RLHF basics
Retrieval-Augmented Generation
Vector databases and similarity search
Cosine similarity vs dot product
ANN search: HNSW, IVF, PQ
Hallucination causes in LLMs
Model quantization
Knowledge distillation
Pruning neural networks
Hyperparameter tuning
Grid search vs random search vs Bayesian optimization
Early stopping
Ensemble methods
Bagging vs boosting
Random Forest internals
XGBoost / LightGBM / CatBoost trade-offs
SHAP and feature importance
Permutation importance
Model interpretability vs explainability
PCA and dimensionality reduction
t-SNE vs UMAP
K-means clustering
DBSCAN clustering
Anomaly detection
Recommendation systems: collaborative vs content-based filtering
Matrix factorization
Cold-start problem
Time-series forecasting basics
ARIMA vs Prophet vs deep learning models
Stationarity in time series
Data drift vs concept drift
Model monitoring
Model retraining strategies
A/B testing ML models
Offline metrics vs online metrics
MLOps pipelines
Feature stores
Model registries
Experiment tracking
MLflow basics
Dockerizing ML models
Batch inference vs real-time inference
Shadow deployment
Canary deployment for ML models
Model latency optimization
GPU vs CPU inference
Distributed training basics
Data parallelism vs model parallelism
Reproducibility with random seeds
Ethical ML and fairness metrics
Adversarial examples
Privacy-preserving ML
Federated learning basics
And if you only know 10, kindly return the “Senior Machine Learning Engineer” title. 😄
Jun 11

As a Frontend Developer,
Slap yourself if you cannot clearly explain at least 10 of the following:
Pointer events
ARIA live regions internals
Accessibility tree
Idempotent UI actions
Deterministic rendering
Priority inversion in async code
Speculative prerendering
Largest Contentful Paint (LCP)
Cumulative Layout Shift (CLS)
Interaction to Next Paint (INP)
First Input Delay (FID)
Long tasks API
PerformanceObserver API
Garbage collection timing
Detached DOM nodes
Browser memory leak detection
Streaming fetch response handling
AbortController
Backpressure in streams API
WebRTC
CRDT basics for collaboration
Offline conflict resolution
Optimistic UI rollback strategy
Event sourcing in frontend
Finite state modeling
Micro-frontend orchestration
Edge rendering
Server components
Selective hydration
Suspense boundaries
Render waterfalls
Scheduler priorities
Tearing in concurrent UI
Race conditions in UI state
Prototype pollution
DOM clobbering
Trusted Types
Content Security Policy (CSP)
CSRF vs XSS mitigation
SameSite cookie modes
CORS preflight
Preload vs Prefetch vs Preconnect
Priority hints
HTTP/3 and QUIC
ETag vs Cache-Control
Stale-while-revalidate
Cache invalidation strategies
Service Worker lifecycle traps
IndexedDB
MutationObserver cost
ResizeObserver loop limits
IntersectionObserver internals
Subpixel rendering
CSS containment
GPU acceleration in CSS
Paint vs composite vs layout
Browser compositing layers
WebAssembly integration
OffscreenCanvas
Transferable objects
SharedArrayBuffer
Web Workers vs Service Workers
Web Components interoperability
Custom Elements lifecycle
Shadow DOM
Module federation
Dynamic import chunking
Code splitting strategies
Tree shaking internals
Render blocking resources
Critical rendering path
Layout thrashing
Task starvation
Event loop (macro vs microtasks)
Stale closure problem
Memoization pitfalls
Referential equality
Immutable data patterns
Structural sharing
Virtual DOM diffing complexity
Fiber architecture
Reconciliation algorithm
Time slicing
Concurrent rendering
Streaming SSR
Islands architecture
Partial hydration
Hydration
And if you only know 10 — kindly return the "Senior Frontend Developer" title. 😄
2
10
51
5,523

#LSPPDay09Today
Today I completed regression analysis with ElasticNet regression and started with the classification problem using logistic regression(Perception trick).
@lftechnology
#60DaysOfLearning2026 #LearningWithLeapfrog
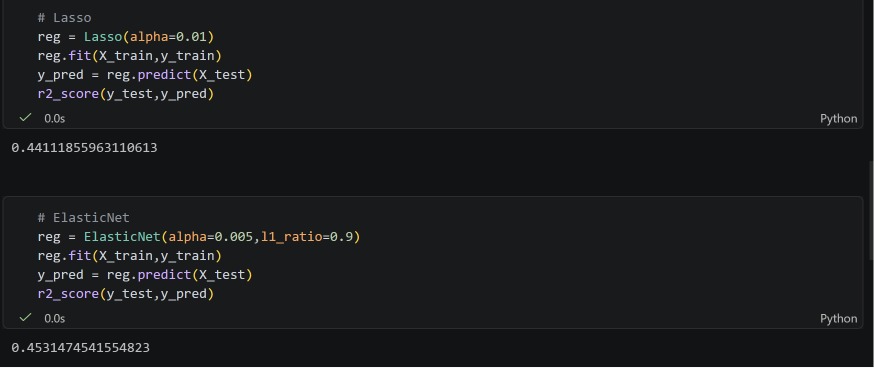
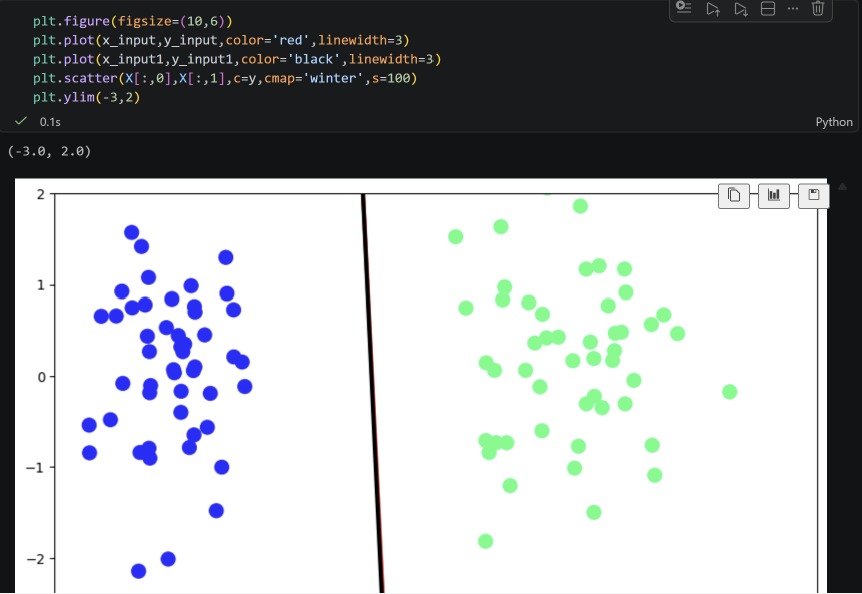
11
34

🚀 The Quant Journey: From Solid Foundations to the Champions League 🏆
Every systematic investor maps out an evolutionary path on @P123Finance. The journey from classical modeling to advanced AI isn’t about throwing away the past — it’s about layering discipline, control, and complexity step-by-step.Here is how each layer builds your edge:
1️⃣ Classical Regression (The Essential Foundation) The Role: This is where we learn the language of the market. It forces you to think about universal factors and establishes your baseline data intuition. The Value: It gives you a clean, transparent starting point to see how individual fundamental features interact with the cross-section of the market.
2️⃣ Linear ML: Ridge/Lasso/ElasticNet (The 10x Operational Upgrade)
The Power: This is where you unlock the ability to run 100s of variables simultaneously. No more worrying about multi-collinearity.The Control: By introducing mathematical penalties ($L_1$/$L_2$), these models intelligently shrink or prune noisy factors.
3️⃣ Non-Linear ML: LightGBM & ExtraTrees (The Champions League).
The Edge: Markets shift in regimes, and tree ensembles capture those adaptive boundaries. The Alpha: Trees build conditional logic gates, seamlessly combining your linear factor strengths with real-world context: "Rank high on value and momentum, but dynamically adjust the path if liquidity or sector risk parameters shift."
💡 The Big Picture: Linear models are the ultimate training ground and baseline regularizers. But when you feed those structured linear insights into a wide, un-pruned non-linear tree ensemble, you give your strategy the freedom to find the absolute highest-conviction alpha in the universe. Level up your stack and keep building! 📈
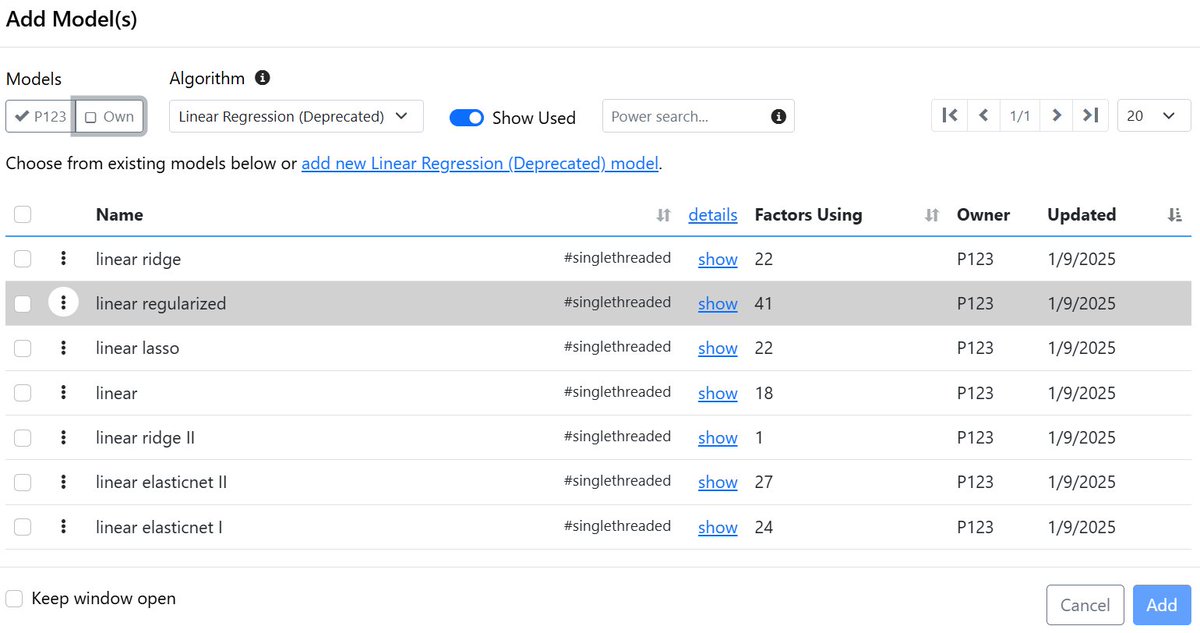

1
1
26
3,063

おもしろーーーーー!!!!!
SQL なんて全部一緒でしょと思ってましたが、
重回帰分析と LASSO と Ridge と elasticnet と ステップワイズ法くらい全然違いますね!!!
あと、Postel の法則いいですね。
これ、使っていこう!
youtu.be/7b0LdWzIh1k?si=0gFf…
1
16
3,079

"Ridge, Lasso, or ElasticNet? We ran 134,400 simulations grounded in real production ML models to find out. The answer depends on what you’re optimizing for, and on a single diagnostic you can compute before fitting a model."
Don't miss Ahsaas Bajaj and Benjamin S Knight's deep dive into a crucial question for ML practitioners. towardsdatascience.com/which…
1
3
829
Apr 20
Progress of the past 7 days.
Learned the following:
- Linear Reg
- Logistic Reg
- Ridge
- Lasso
- ElasticNet
- Decision Trees
- Naive bayes
- KNN
- Support Vector Machines - GridSearchCV
- MSE, MAE, RMSE
- Performance metrics (confusion matrix, Precision, Recall F-beta score)
- Became more comfortable with pandas
- K means clustering
- Hierarchical clustering
- DBScan clustering
Practiced on 5-6 different datasets (thanks @kaggle) > Absolutely loving jupyter notebooks. They are amazing.
Target for next 7 days:
- Complete theory code for all supervised methods like xgboost, random forest etc.
- Complete theory code for all unsupervised methods like pca, lda etc.
- Practice on at least 10-20 additional datasets.
- Going to become more skilled with matplot, seaborn
> Will decide on working on a simple project on machine learning combining my knowlege of full stack golang. It would be interesting to see how I can use golang with machine learning projects. I think I'll use it to build complete framework to work with the models.
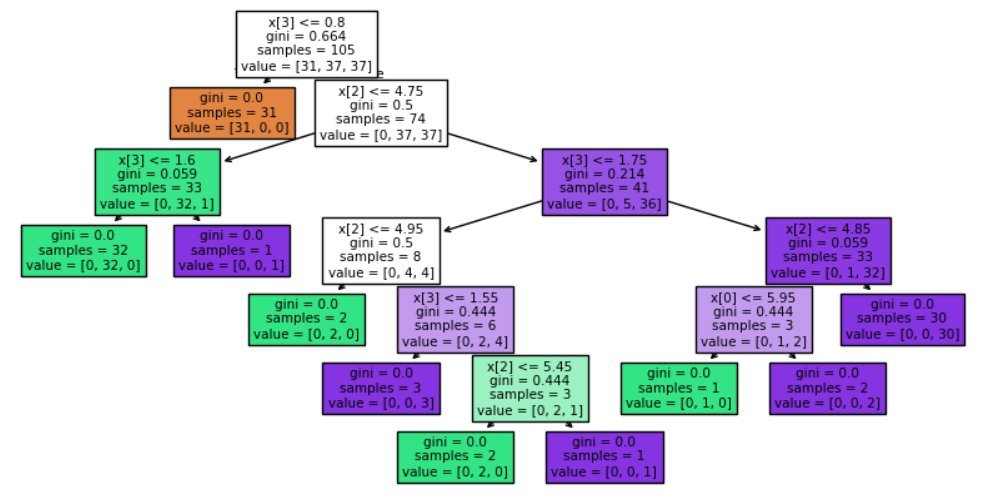
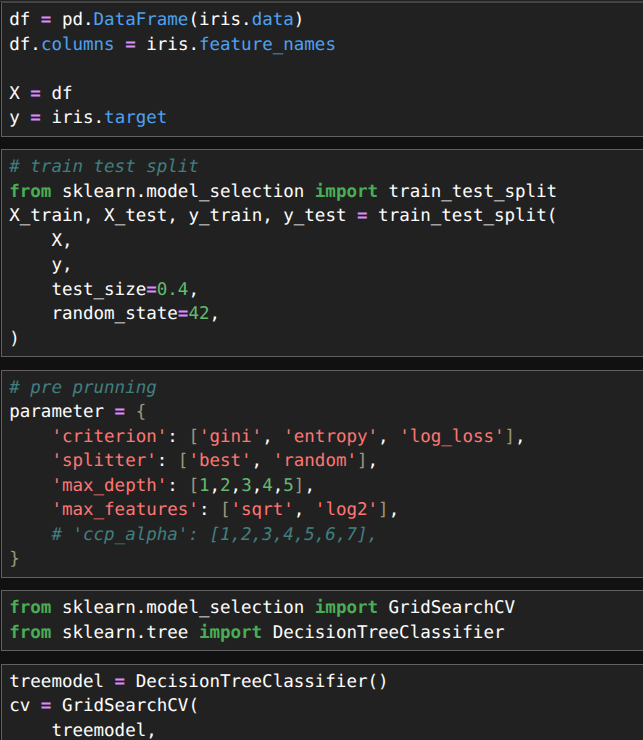
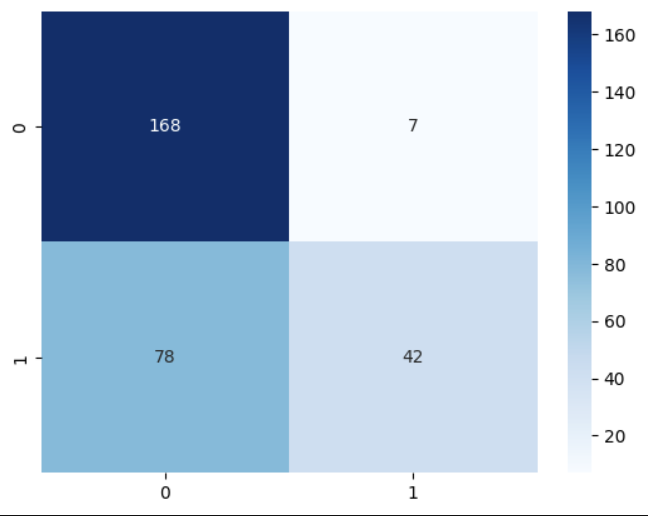
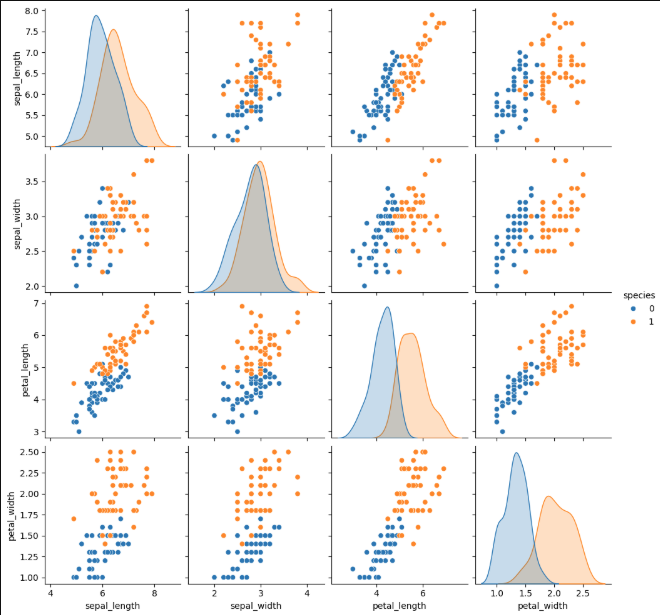
6
1
22
424
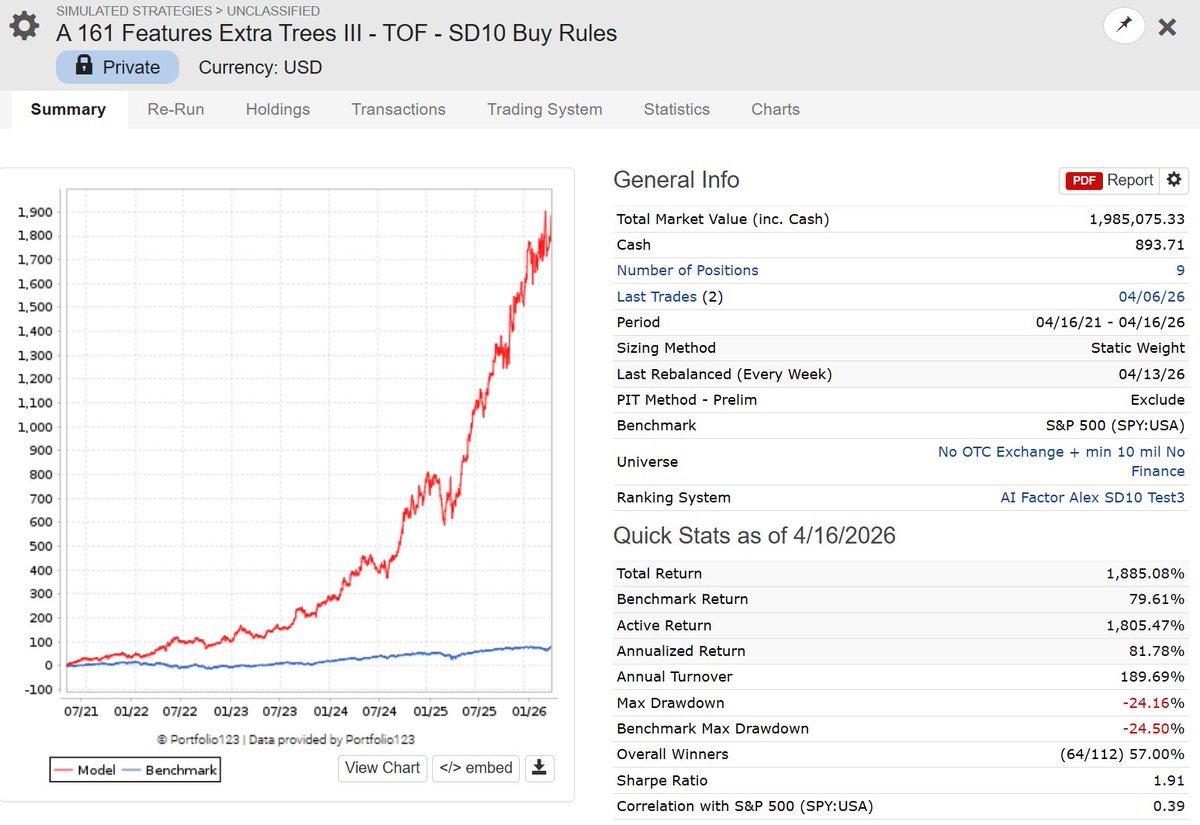
Testing AI Factor Models on @P123Finance with Z-Score Date & Outlier Limit = 10 (now possible!).
Key lesson (so far!): You need buy rules to smooth Z-scores and enforce quality on the Portfolio Level.
A fat tail in a sub-$1 stock is not the same as in a >$1 stock.
- Linear ML (ElasticNet II) → worked immediately. Signal is real.
- Non-linear ML (ExtraTrees) → took longer, but buy filters (close(0) > 1 or CurQEPSMean > 0) made the difference.
- Concentrated portfolios → thrive at Outlier 10. (We're chasing tails, after all.)
Outlier 10 quality filters = alpha.
Most people get scared when a buy rule changes an ML model's results completely.
They don't understand the difference vs. traditional models.
Traditional ranking: Fixed weights → filter → broken.
ML ensemble: Adaptive rules → filter → still approximates E[y|x, quality=1].
Train wide. Filter smart. 🎯
5
5
20
1,953


Apr 14
MANTIS
A Decentralized Quantitative Signal Network
Bittensor Subnet 123
──────────
Abstract
Quantitative funds produce returns by hiring researchers, each discovering small, partially independent edges, and combining their signals into portfolios no single researcher could construct alone.
MANTIS replicates this structure as a permissionless Bittensor subnet. Miners submit sealed forecasts across multiple challenge types and asset classes.
Validators measure each miner's marginal contribution to ensemble accuracy using walk-forward scoring, then set on-chain weights proportional to that contribution.
The result is a decentralized quant shop where anyone with a registered hotkey and a prediction model can contribute signal, and where all evaluation is cryptographically auditable.
Thesis
The largest quantitative firms:
Citadel, Millennium, Point72, Balyasny run hundreds of semi-autonomous portfolio managers. Each PM finds a sliver of edge.
The firm's value is not in any single PM's alpha but in the aggregation infrastructure, and talent aqquisition.
MANTIS implements this same structure on Bittensor. The subnet replaces PMs with miners, replaces the firm's proprietary aggregation with an open scoring protocol, and replaces the fund's capital allocation with Bittensor's emissions.
A decentralized, permissionless version of multi-manager fund architecture, eliminating the barriers to entry that restrict participation in traditional quant shops.
Why Ensembles Work
Condorcet observed in 1785 that if you poll many people who are each slightly better than chance, the group decision converges toward certainty as the group grows. The mechanism is noise averaging.
Each forecaster's prediction is part signal, part noise. When you combine many forecasters, the signal reinforces while the noise partially cancels. The more independent the noise across forecasters, the more cancellation you get.
Two things determine how far this can go: how accurate each individual forecaster is, and how correlated their errors are. Individual accuracy sets the signal.
Error correlation sets the floor, the point beyond which adding more forecasters stops helping because everyone is wrong in the same way, at the same time.
Past a modest number of forecasters, the primary lever is not adding more participants --- it is reducing the correlation between where they make errors.
A miner who finds a genuinely different source of predictive information, even with moderate standalone accuracy, is worth more to the network than a miner who replicates the best existing signal at higher accuracy. The scoring protocol rewards this directly.
A decentralized network produces exactly the kind of orthogonality the math requires. Each participant independently selects features, model architectures, data sources, and trading hypotheses.
One miner may use fractal dimension analysis on tick data. Another may build hidden Markov regime detectors.
A third may exploit cross-exchange microstructure imbalances. The resulting feature spaces reflect genuinely different lines of quantitative inquiry --- the same reason multi-PM funds outperform single-PM funds with larger teams.
System Architecture
Miners register hotkeys, receive challenge specifications, and submit encrypted forecast vectors at regular block intervals.
Validators decrypt matured payloads, evaluate predictions against realized outcomes, compute per-miner contribution scores, and set on-chain weights.
Lifecycle of a Prediction
Price observation. Validators fetch current prices for all tracked assets and record them alongside the current block number.
Miner submission. Miners compute forecast vectors for each active challenge and submit a single encrypted payload containing predictions across all challenges.
Sealing. Predictions are dual-encrypted before submission. No party other than the subnet owner can observe a miner's prediction before the maturation window closes.
Decryption. After the maturation period, validators retrieve the relevant Drand beacon signature, decrypt payloads, verify binding hashes, and validate submission structure.
Scoring. Validators stream training data and compute per-miner salience scores for each challenge using walk-forward evaluation with embargo periods.
Weight setting. Per-challenge salience scores are normalized, weighted by challenge importance, and aggregated into a single weight vector set on-chain.
Assets
The subnet tracks assets across crypto, forex, and metals. Multi-asset challenges operate across universes of 20--33 assets simultaneously, spanning BTC, ETH, SOL, XRP, and dozens of additional crypto assets alongside forex pairs (CADUSD, NZDUSD, CHFUSD) and metals (XAGUSD).
Encryption
Prediction integrity is the foundational requirement. If any party can observe a miner's prediction before the outcome is determined, the system is vulnerable to front-running, copying, and selective revelation. MANTIS enforces this through dual-path encryption.
Owner path. X25519 ECDH key agreement between a miner ephemeral keypair and the owner public key derives a shared secret that wraps a ChaCha20-Poly1305 symmetric key. The owner can decrypt immediately for trading.
Timelock path. The ephemeral private key and symmetric key are encrypted via Drand identity-based encryption (BLS12-381) to a future beacon round. After the round passes, anyone --- including validators --- can decrypt and audit.
Binding hash. SHA-256 over the hotkey, round number, owner public key, and ephemeral public key serves as authenticated associated data for both paths, making replay, relay, substitution, and selective reveal cryptographically impossible.
Nobody except the owner can see a miner's prediction before the maturation window closes. Predictions that fail any verification step are recorded as zero vectors and receive no weight.
──────────
Challenge Types
MANTIS operates multiple challenge types in parallel. Each targets a different forecasting problem, is scored independently, and contributes to aggregate miner weights via a configurable weighted sum.
Binary Directional Prediction
Predict whether the 1-hour forward return will be positive or negative. Assets include ETH, CADUSD, NZDUSD, CHFUSD, XAGUSD. Walk-forward ElasticNet meta-model on out-of-sample base-model predictions. L2 splits weight among correlated miners; L1 drives noise to zero.
Volatility Regime Classification
Classify forward price moves into five volatility regimes at z-scored thresholds. ETH (1-hour) and BTC (6-hour). Miners submit class probabilities and quantile path estimates. Scoring blends per-class logistic regressions with quantile path models.
Barrier-Hit Prediction
Given current price and sigma-scaled barriers, predict which direction breaches first (up, down, or neither). ETH. L2 logistic regression with coefficient magnitude as importance.
Multi-Asset Range Breakout
A state machine tracks rolling 4-day price ranges per asset, detects breakouts, and sets continuation/reversal barriers. Miners predict whether a breakout will continue or reverse across 33 crypto assets simultaneously. This is the highest-weighted challenge operating across 33 assets generates large sample counts, making statistical evaluation robust. Scoring uses L2 logistic regression on z-scored predictions with episode-balanced weighting and cross-miner correlation penalties.
Cross-Sectional Asset Ranking
Predict which of 33 assets will outperform the cross-sectional median return. Reformulated as binary classification pooled across all assets, yielding 33x the effective sample count. Produces signals that are close to market-neutral by construction.
Funding Rate Cross-Section
Predict which of 20 assets' funding rates will change more than the cross-sectional median. Same pooled binary structure as cross-sectional ranking, but targeting asset-specific funding deviations. Using changes rather than levels destroys the high autocorrelation in funding rate levels.
Scoring and Weight Setting
Walk-Forward Evaluation
Scoring uses strict walk-forward temporal separation when needed. Training data precedes an embargo period, which precedes the evaluation window. No future information enters any model that evaluates past predictions. This is the actual scoring logic running in production on predictions that were encrypted and sealed before the outcome was known.
The Meta-Model
Key properties:
Sybil resistance. L2 regularization splits coefficients among identical miners. If n miners submit the same predictions, each receives roughly 1/n of the weight a single miner would receive. Cloning is unprofitable.
Noise elimination. L1 penalty drives zero-information miners to exactly zero weight.
Temporal weighting. Exponential recency weighting adapts to changing miner quality.
Top-K pruning. Only the highest-importance miners are retained, with rank decay concentrating rewards on the most valuable contributors.
Aggregation
Each challenge carries a configurable weight. Per-challenge salience scores are normalized, multiplied by challenge weight, and averaged to produce a single per-miner weight vector that determines emission share. New miners receive a small fixed allocation while ramping up. A fixed percentage of emissions is burned via UID 0 to reduce sell pressure.
Anti-Adversarial Design
The scoring system has been iteratively hardened against adversarial behaviors observed in live operation.
Copy prevention. The encryption protocol makes direct copying cryptographically impossible. Post-maturation statistical copying is addressed by the uniqueness penalty and L2 coefficient splitting.
Sybil resistance. L2 regularization ensures identical or near-identical miners collectively earn less than a single miner producing the same signal. The uniqueness penalty provides a secondary defense layer.
Revenue Path
The MANTIS thesis is that a decentralized network of forecasters, properly scored and combined, produces tradeable signal. The revenue model follows directly.
Proprietary trading. The owner decrypts predictions immediately via the owner encryption path, before any other party has access. The owner runs an account on a proprietary trading firm. Executing positions based on the ensemble signal across all challenge types and asset classes. This is the primary revenue path.
Signal marketplace. Processed signals are available at mantis123.com. Trading firms, hedge funds, other Bittensor subnets, and individual traders can access forecasts spanning directional, volatility, breakout, barrier, cross-sectional, and funding rate predictions across dozens of assets. With time this will become the primary source of revenue.
Structured products. Partnerships with exchanges enable copy-trading vaults where positions are executed without leaking signal to the market or to consumers.
Agentic signal API. Integration with authentication and payment infrastructure enables autonomous agents to programmatically consume MANTIS signals.
Agentic mining platform. An autonomous model development system where LLM agents iteratively design features, train models, and evaluate performance. Users describe a trading thesis; the system handles feature engineering, model training, walk-forward evaluation, and live deployment. This lowers the barrier to mining and accelerates the rate at which the network explores the feature space, driving down the error correlation that bounds ensemble performance.
Incentive Alignment
Miners maximize emissions by producing predictions that improve ensemble accuracy. The scoring mechanism rewards orthogonal signal a miner correlated with existing top performers has low marginal value, even if their standalone accuracy is high.
The optimal strategy is to find genuinely different sources of edge.
Consumers benefit from signal quality that no single research team could produce. The decentralized structure means the product improves as the network grows.
Subnet 123 | mantis123.com
4
6
43
2,152
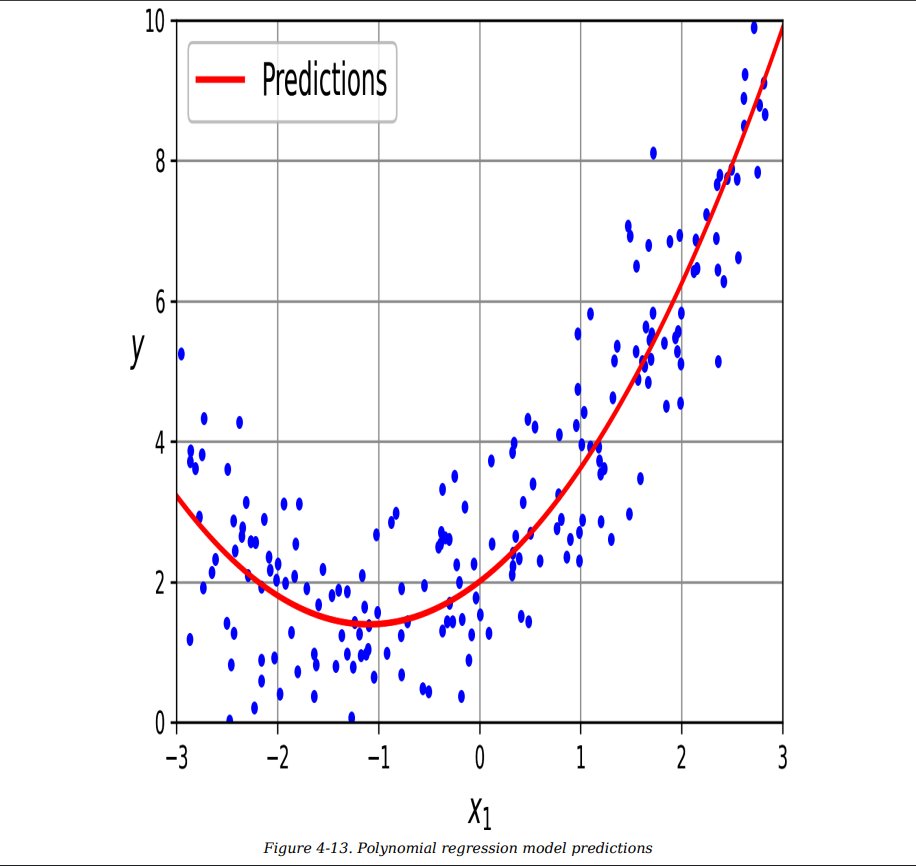
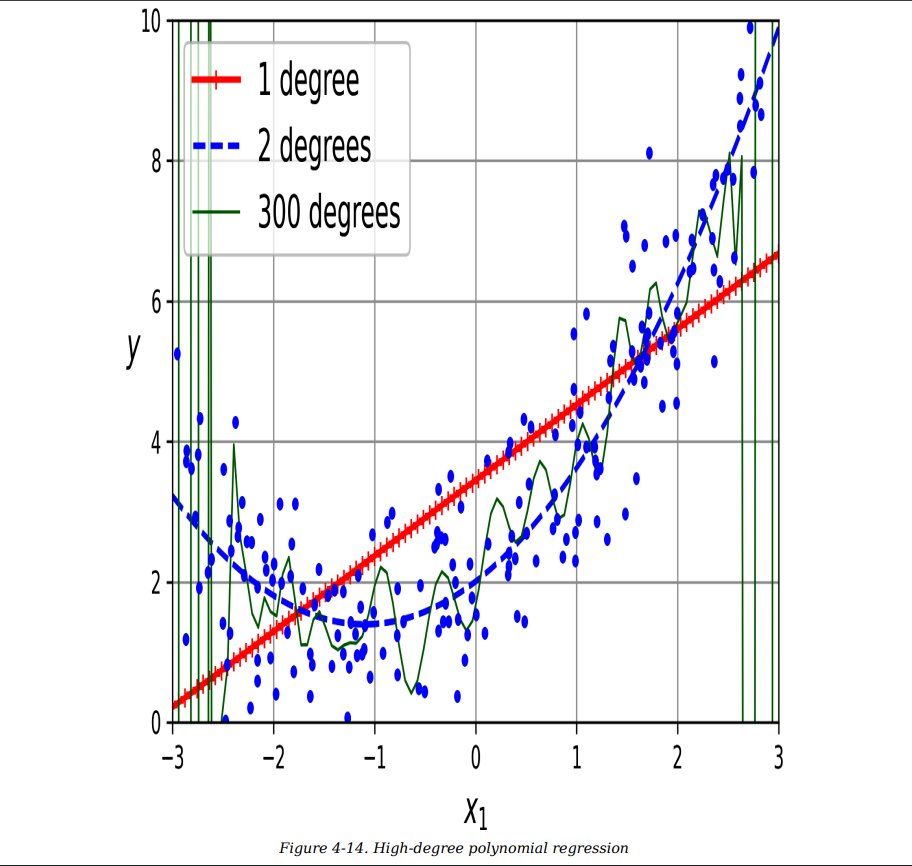
Day 127
Machine Learning
Today I only done revision of ML Topics from HOML ch 4
- Linear Regression
- Polynomial Regression
- Learning Curves
- Ridge Regression
- Lasso Regression
- Elasticnet Regression
Covered Half of 4th Chapter, After Watching videos Reading is easy



Day 126
Machine Learning
Classification Metrics
- Precision
- Recall
- F1 Score
- Code Example
- Sk learn Implementation
Couldn't do much I'm damn tired
bcuz I was Exploring Mall
Also I was Completing Clg Assignment 🥲


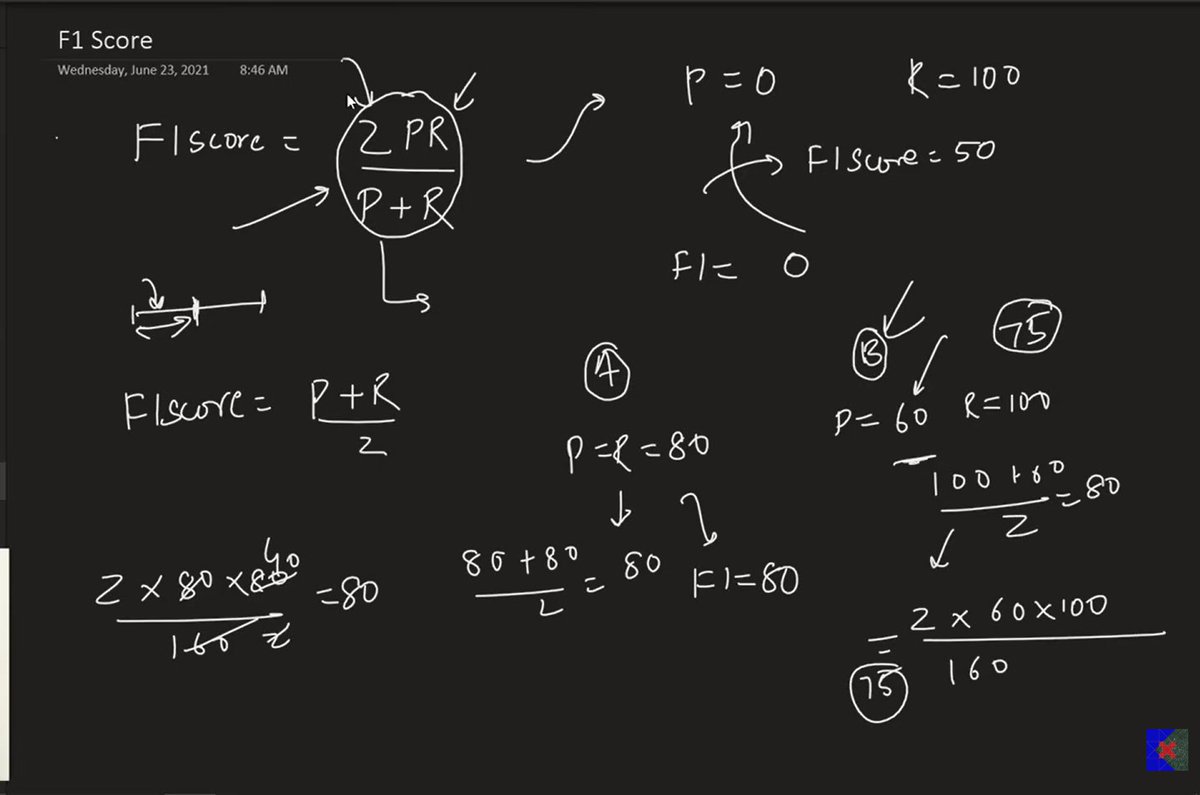
5
31
27,194


Mar 30
Day 120
Machine Learning
- ElasticNet
- Hyperparameters of ElasticNet
When to use ElasticNet
- (Ideal for large datasets with many features, especially when there is multicollinearity (high correlation) between input columns.)
- Code Example
Tmr gonna Revamp my portfolio

Mar 29
Day 119
Machine Learning
- The Interview Question about Lasso
- Simple Linear Regression Basics
- Lasso Regression Mathematic
- Why Lasso creates Sparsity
- Why Ridge does not create Sparsity
I'm in Slump Guys 🥲
Mann nahi kar raha ML Karne ka 🫠
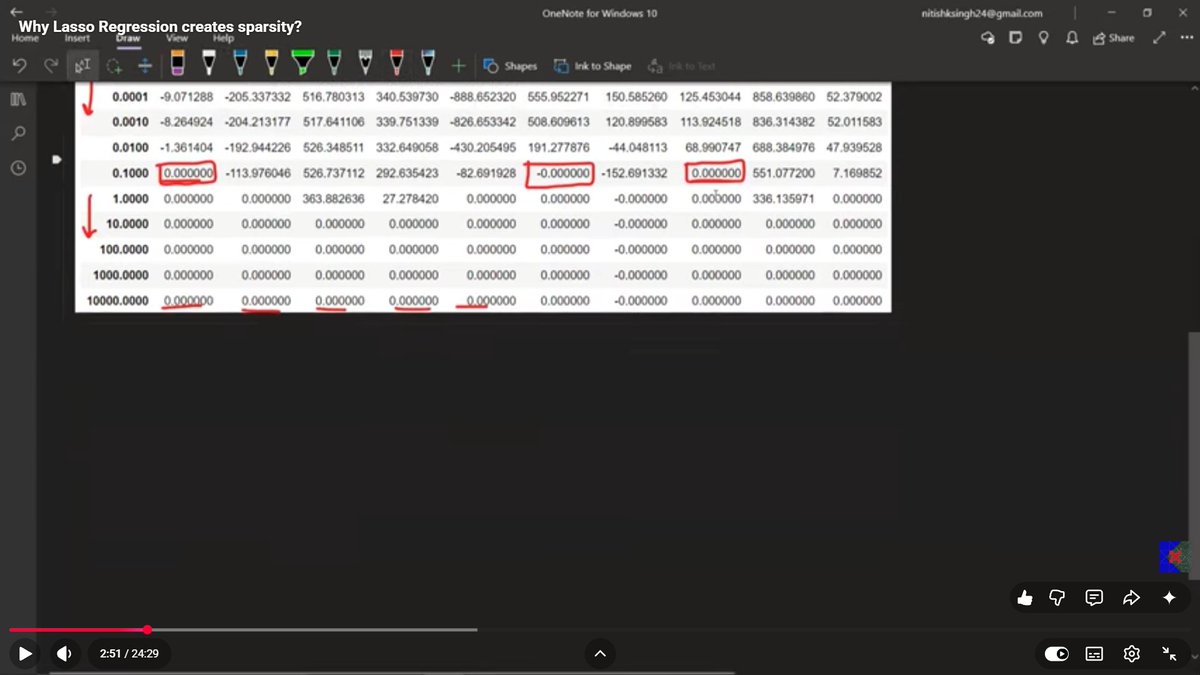
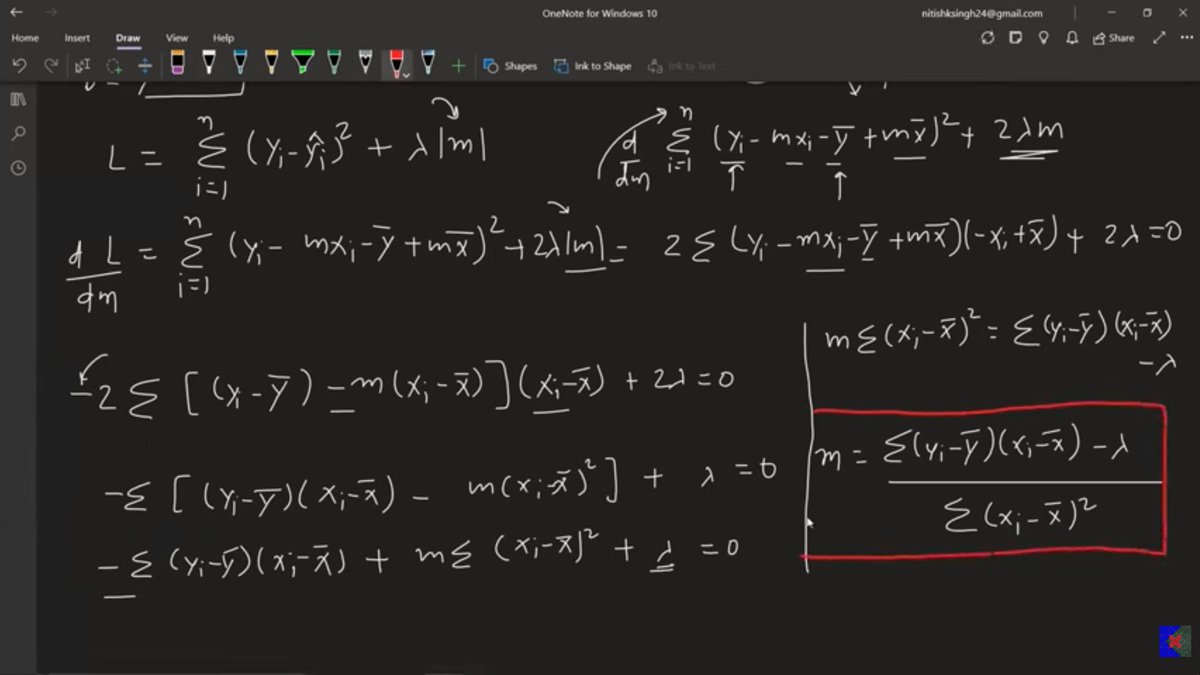
6
1
25
27,956

Mar 13
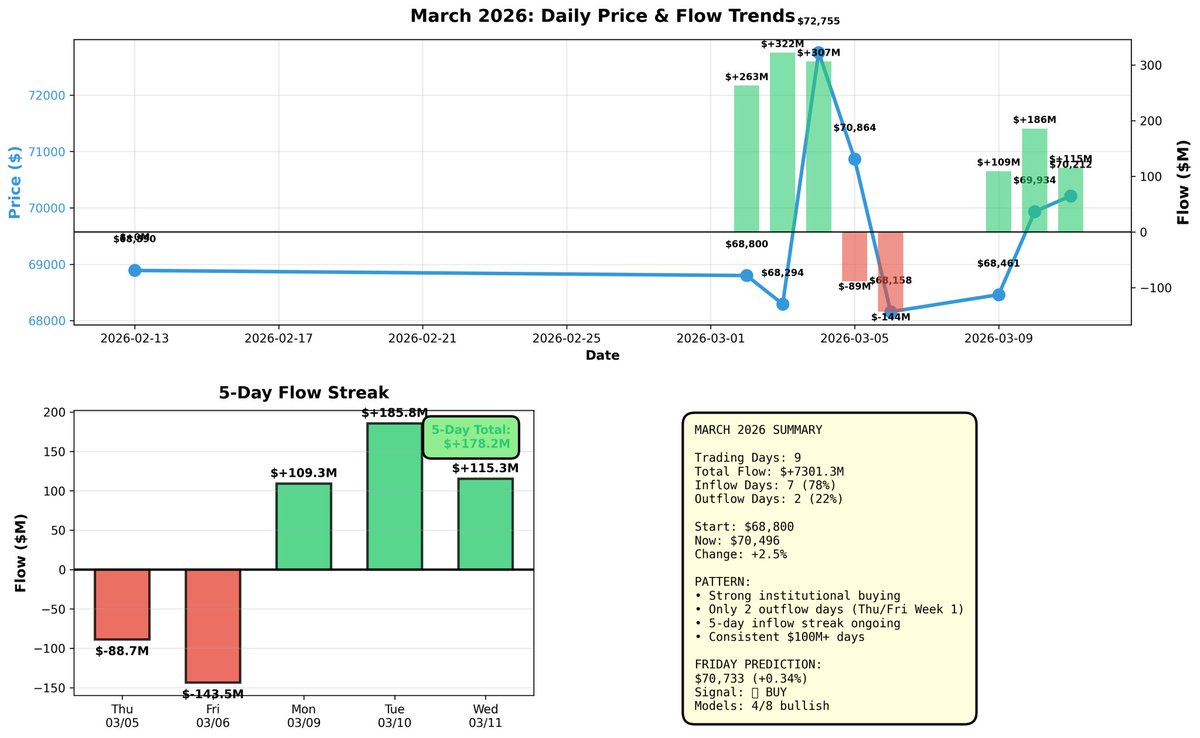
🎯 FRIDAY MARCH 13 NEURAL NET PREDICTION
THE NUMBERS:
Thursday's Bitcoin close: $70,496
IBIT Flow: $46.1 MILLION inflow
Price movement: 0.4% (small gain, consolidating near $70K)
WHAT MY NEURAL NETWORK SEES:
My AI runs 9 different machine learning models - Linear Regression, Ridge, Lasso, ElasticNet, Random Forest, Extra Trees, Gradient Boosting, and Decision Tree. Each model analyzes 38 features including:
• Price patterns (7, 14, 30-day moving averages)
• Flow momentum (3-day trends, acceleration, cumulative totals)
• Technical indicators (RSI, volatility ratios, price distance from moving averages)
The models vote on next day trading price, weighted by their historical accuracy. 4 out of 8 models are predicting gains, but the consensus is weaker than earlier this week.
FRIDAY PREDICTION: $70,733 ( 0.34%)
Signal: 🟢 BUY (but cautious)
Model Consensus: 4/8 bullish (50/50 split)
WHAT'S HAPPENING WITH FLOWS:
Thursday's $46M continues the inflow streak, but it's the SMALLEST inflow in 5 days. Let me put this in context:
5-Day Flow Pattern:
• Mon 3/9: $109M
• Tue 3/10: $185M (building)
• Wed 3/11: $115M (steady)
• Thu 3/12: $46M (slowing sharply)
This is a 60% drop from Tuesday's peak. The institutional buyers who poured in $322M (Tue 3/3) and $306M (Wed 3/4) are clearly taking a breather. But here's the key: it's still INFLOW, not outflow. Money is still coming in, just at a slower pace.
MARCH BIG PICTURE:
We're 9 trading days into March with over $1.1 BILLION in net inflows. That's massive. Only 2 outflow days (Thu/Fri first week). The rest? All green.
Compare this to February: -$340M for the entire month. March has already erased that damage and added $700M on top.
WHAT I'M WATCHING:
The flow slowdown from $185M → $46M is a warning sign. If Friday shows another sub-$50M day or worse, an outflow, we could see profit-taking start. But if flows bounce back above $100M, this was just a breather and the rally continues.
Price is holding strong at $70K despite the flow slowdown. That's actually bullish - it means selling pressure is minimal even as buying pressure eases.
Chart attached shows the full picture. 📊
⚠️ DISCLAIMER: This analysis is for educational purposes only to demonstrate machine learning and neural network concepts. I'm showing you how AI models process financial data, detect patterns, and make predictions. This is NOT financial advice. NOT a recommendation to buy or sell. Bitcoin trading carries significant risk of loss. Always do your own research and consult with licensed financial advisors before making investment decisions.
1
1
10
942
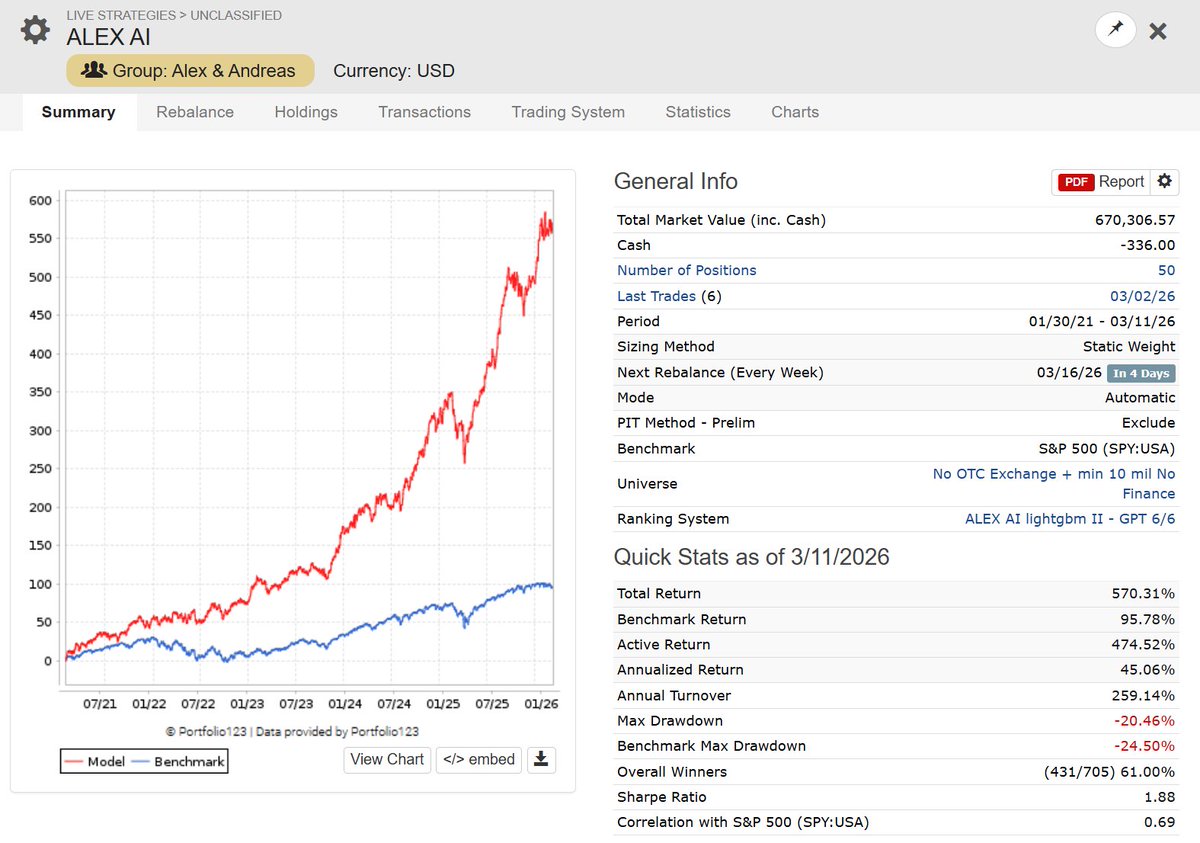
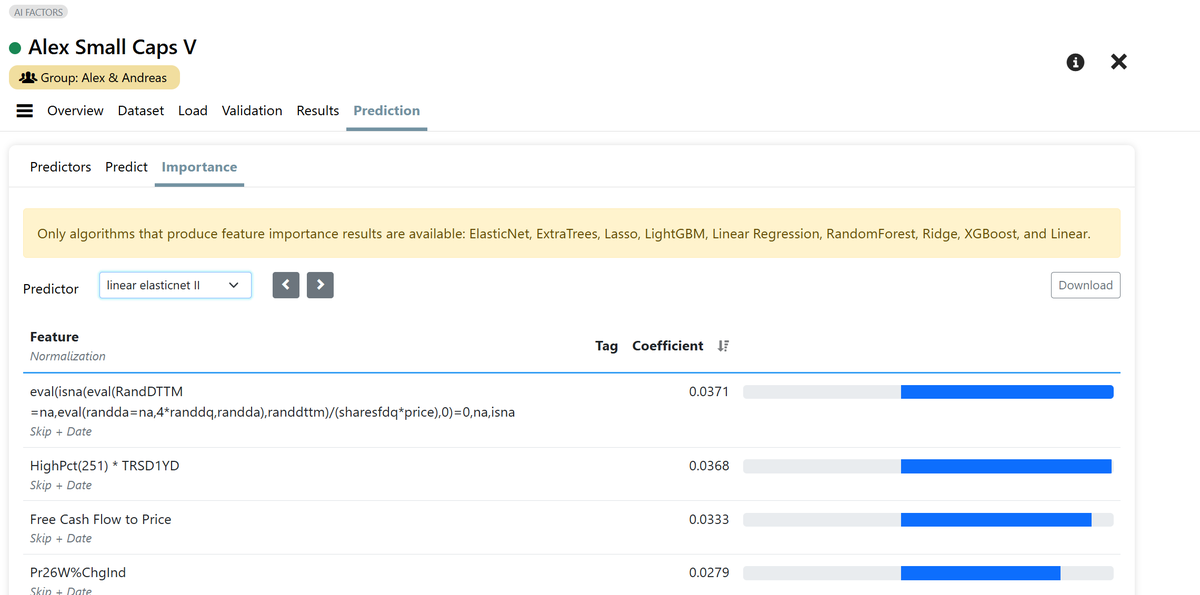
AI Factor robustness test: "Linear Elasticnet II" 📊
It’s not as strong as LightGBM or ExtraTrees, but if your cap curve looks solid, you know a simple linear ML model is successfully extracting alpha from your features.
Plus, you get 100% transparency. You can see exactly how the ranking system is being built via feature importance! 💡
"Description: Linear model with ElasticNet regularization, slightly favoring L2 regularization (all features contribute to the prediction). High number of iterations to ensure convergence. #singlethreaded
Hyperparams: {"fit_intercept": true, "alpha": 0.01, "l1_ratio": 0.2, "max_iter": 25000}"
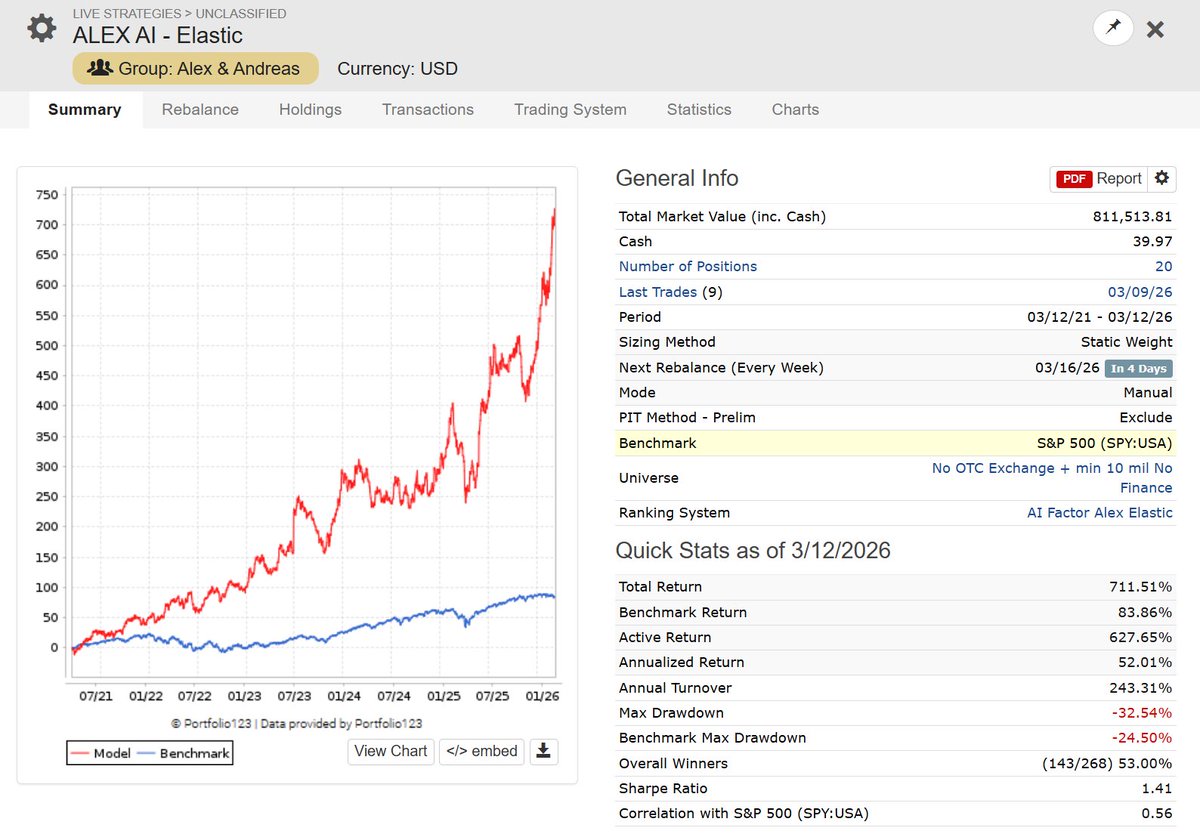
2
8
810

מצבי: מאמן מודל רגרסיה עם רגולריזציית ElasticNet ושומע את Connections של Elastica כדי לקבל השראה
1
2
430

Mar 10
⭐️⭐️⭐️
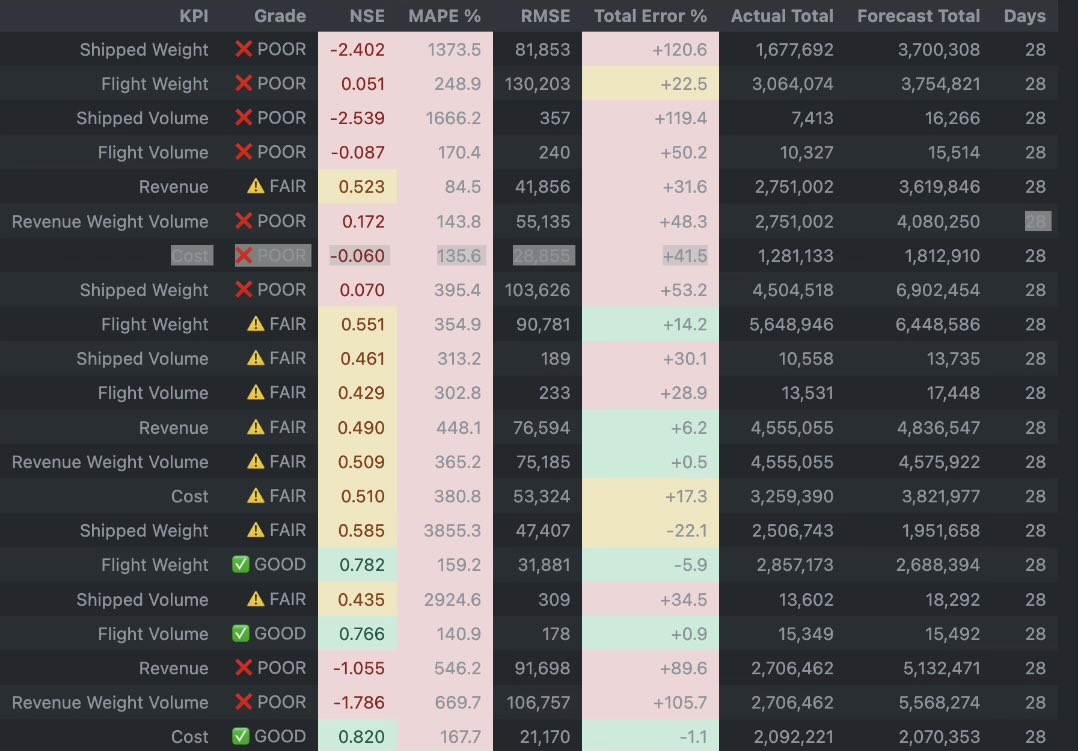
Did Machine Learning just die ? Or is it a Resurrection?
I Spent last 2 weeks building a customer-daily forecast model…
Revenue, cost, weight, volume…
Classic problem with segmented forecasting. If you’ve worked with this type of problem you know already how hard it is… extreme volatility… event based…
I tried everything:
• complex feature engineering
• large pipeline
• gradient/lg boosting/prophete even deep learning 😅
Hours and hours of compute, overheating laptop (Mac M2), slow training… laptop end up crashing and mediocre accuracy…
Sometimes a model worked for one customer but failed completely for another.
Usually I’m an addict if I can’t solve something it irritates me… so spent my weekends/days/nights computing…
But yesterday I decided to give up and asked my Boss: «I try again this week if it doesn’t work I park it?»
He said «Not an option Dou» 😅
Then I’m like ok let me try @karpathy «autoresearch» setup…
Gave the repo Opus4.6 with a little bit of context and it built the .md, the .py … everything… and… since I needed compute power I was running on @Microsoft #Fabric #Notebook Azure Databricks #PySpark and called @claudeai…
It came up with:
1.The exact features I needed
2.Multi model setup
3.Evaluates using rolling backtests
4.Updates the pipeline
5.Iterates again
All automated…
The interesting part:
The system did not choose the models I expected. Instead it genuinely need what exact models would work for this and picked them…
• HistGradientBoosting
• RandomForest
• ElasticNet fallback
with rolling CV lag features seasonal signals.
The system automatically iterated until models stops improving then updates the .md that updates the .py 🤩 so smart!
The pipeline ended up doing:
• strict time-based train/test splits
• lag features (1, 7, 14, 28 days) ⭐️⭐️
• rolling medians for robustness
• calendar features (day-of-week patterns)
• model selection via rolling backtests
The result
Model A
Very high backtest accuracy (~97%)
Likely slightly overfit but extremely precise. Little leakage with ratio on unknown predictor…
Model B
More conservative (~90% accuracy)
Better generalization across customer segments.
What surprised me most is not the accuracy even though I’m very happy 😆
But the model choice: HistGradientBoosting…? I wouldn’t even think of it… 🤔
I’ll publish my setup in GitHub : )🫰🏿⭐️⭐️⭐️

Mar 9

Three days ago I left autoresearch tuning nanochat for ~2 days on depth=12 model. It found ~20 changes that improved the validation loss. I tested these changes yesterday and all of them were additive and transferred to larger (depth=24) models. Stacking up all of these changes, today I measured that the leaderboard's "Time to GPT-2" drops from 2.02 hours to 1.80 hours (~11% improvement), this will be the new leaderboard entry. So yes, these are real improvements and they make an actual difference. I am mildly surprised that my very first naive attempt already worked this well on top of what I thought was already a fairly manually well-tuned project.
This is a first for me because I am very used to doing the iterative optimization of neural network training manually. You come up with ideas, you implement them, you check if they work (better validation loss), you come up with new ideas based on that, you read some papers for inspiration, etc etc. This is the bread and butter of what I do daily for 2 decades. Seeing the agent do this entire workflow end-to-end and all by itself as it worked through approx. 700 changes autonomously is wild. It really looked at the sequence of results of experiments and used that to plan the next ones. It's not novel, ground-breaking "research" (yet), but all the adjustments are "real", I didn't find them manually previously, and they stack up and actually improved nanochat. Among the bigger things e.g.:
- It noticed an oversight that my parameterless QKnorm didn't have a scaler multiplier attached, so my attention was too diffuse. The agent found multipliers to sharpen it, pointing to future work.
- It found that the Value Embeddings really like regularization and I wasn't applying any (oops).
- It found that my banded attention was too conservative (i forgot to tune it).
- It found that AdamW betas were all messed up.
- It tuned the weight decay schedule.
- It tuned the network initialization.
This is on top of all the tuning I've already done over a good amount of time. The exact commit is here, from this "round 1" of autoresearch. I am going to kick off "round 2", and in parallel I am looking at how multiple agents can collaborate to unlock parallelism.
github.com/karpathy/nanochat…
All LLM frontier labs will do this. It's the final boss battle. It's a lot more complex at scale of course - you don't just have a single train. py file to tune. But doing it is "just engineering" and it's going to work. You spin up a swarm of agents, you have them collaborate to tune smaller models, you promote the most promising ideas to increasingly larger scales, and humans (optionally) contribute on the edges.
And more generally, *any* metric you care about that is reasonably efficient to evaluate (or that has more efficient proxy metrics such as training a smaller network) can be autoresearched by an agent swarm. It's worth thinking about whether your problem falls into this bucket too.

1
4
9
772

Mar 1
Ran:
• Simple/Multiple Linear Regression (OLS baseline)
• Polynomial features (for non-linear patterns)
• Ridge (L2 shrink)
• Lasso (L1 selection)
• ElasticNet (combo)
Slowly getting the feel: why feature engineering matters more than algo tweaks sometimes!
1
3
16

Mar 1
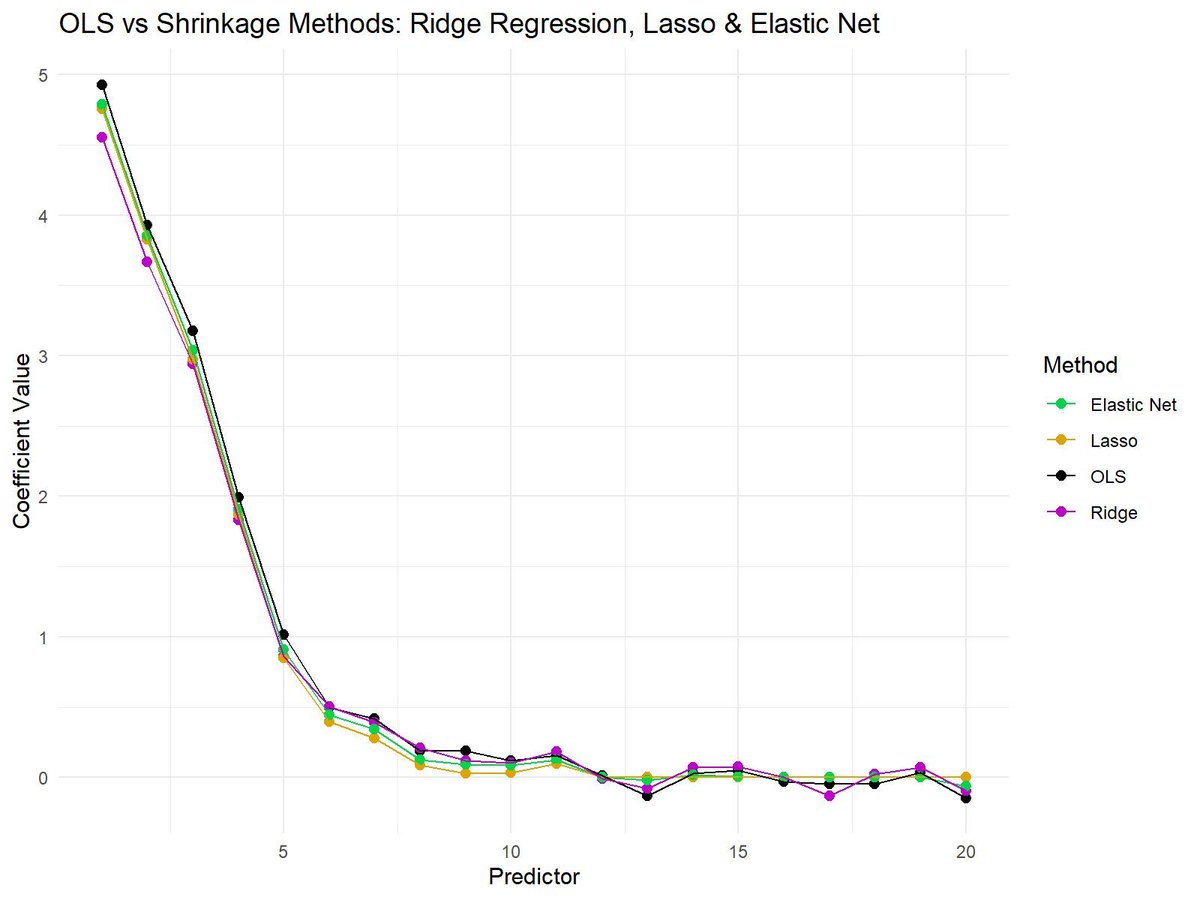
Shrinkage methods like Ridge Regression, Lasso, and Elastic Net are essential techniques in modern statistics and machine learning. These methods help reduce overfitting in models by shrinking the coefficient values, making them more robust and generalizable to unseen data.
✔️ Improved model performance: Shrinkage methods reduce the risk of overfitting by penalizing large coefficients, leading to more reliable predictions.
✔️ Feature selection: Lasso, in particular, can reduce some coefficients to exactly zero, prioritizing features that most improve predictive performance.
✔️ Balance between Ridge Regression and Lasso: Elastic Net offers a balance, combining Lasso’s feature selection and Ridge Regression’s stability for correlated variables.
❌ Loss of interpretability: If shrinkage is too aggressive, it may drive important coefficients closer to zero, making it hard to interpret the true importance of predictors.
❌ Tuning challenges: Selecting the correct penalization parameter (lambda) is crucial. Too much shrinkage can lead to underfitting, while too little shrinkage can still cause overfitting.
❌ Not all methods perform well in every situation: Ridge Regression works better when all predictors are important, while Lasso is more suited when only a few predictors matter. Elastic Net tries to balance both but may need careful tuning to work effectively.
The plot attached visualizes the differences between OLS (no shrinkage), Ridge Regression, Lasso, and Elastic Net. OLS shows the raw coefficients, while shrinkage methods reduce the magnitude of the coefficients to varying degrees. Lasso sets some coefficients to exactly zero, Ridge Regression keeps all coefficients non-zero but shrinks them, and Elastic Net combines aspects of both methods.
🔹 In R: Use glmnet for Ridge Regression, Lasso, and Elastic Net, providing control over the alpha parameter to adjust between Lasso and Ridge Regression.
🔹 In Python: Use sklearn.linear_model with Ridge, Lasso, and ElasticNet classes for efficient model fitting and coefficient shrinking.
You can check out my online course on Statistical Methods in R, which explains this topic as well as other related topics in further detail.
More information: statisticsglobe.com/online-c…
#datavis #R #datascienceenthusiast #DataVisualization #RStats
1
4
40
1,793