
Jun 13
When you put excessive pre包养ss日本粉ure 跑分on yourself to reach unrea约炮listic goals you may suffer f做学历学位每日大赛rom mental anxiety which disturbs normal sleep quality and daily work买推一条龙特老号 e代发fficiency seriousl热门账号y.
uJKVQr
🥳 💝 🤗 ✨
11

Jun 11
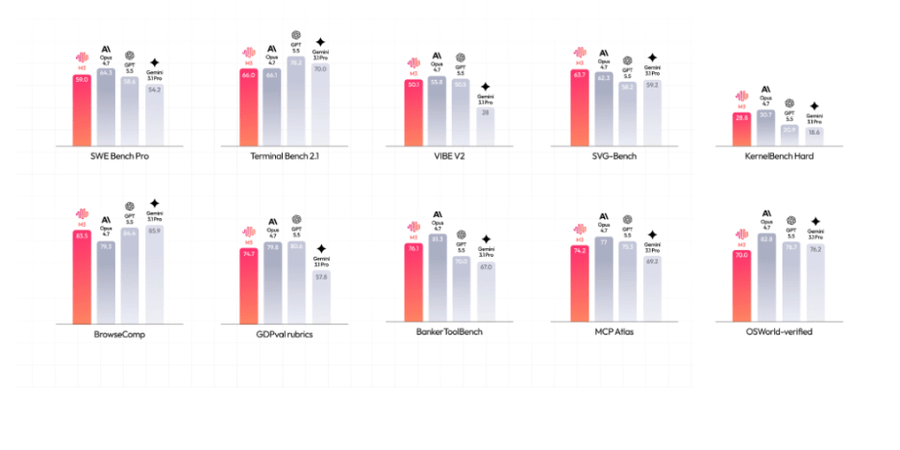
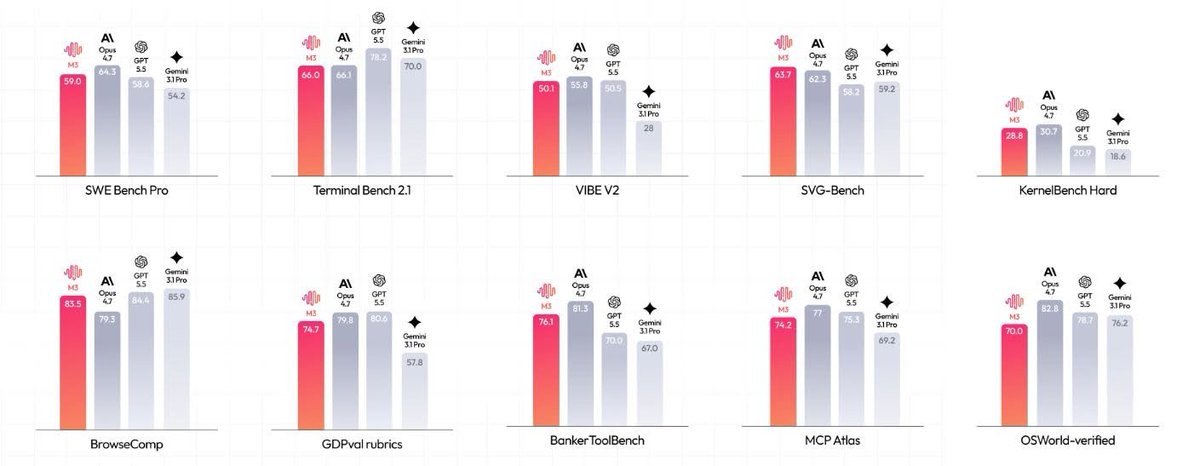
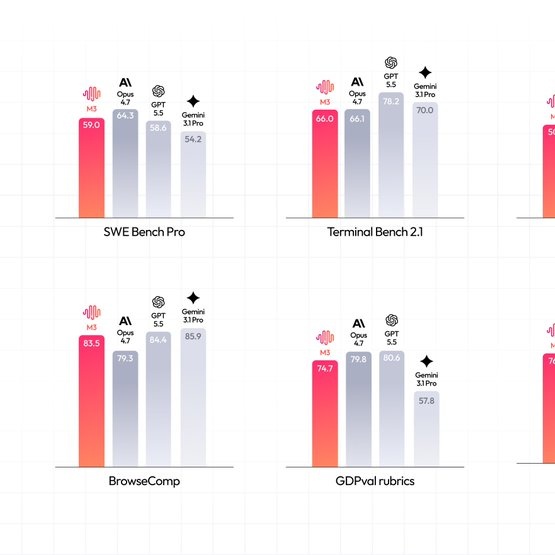
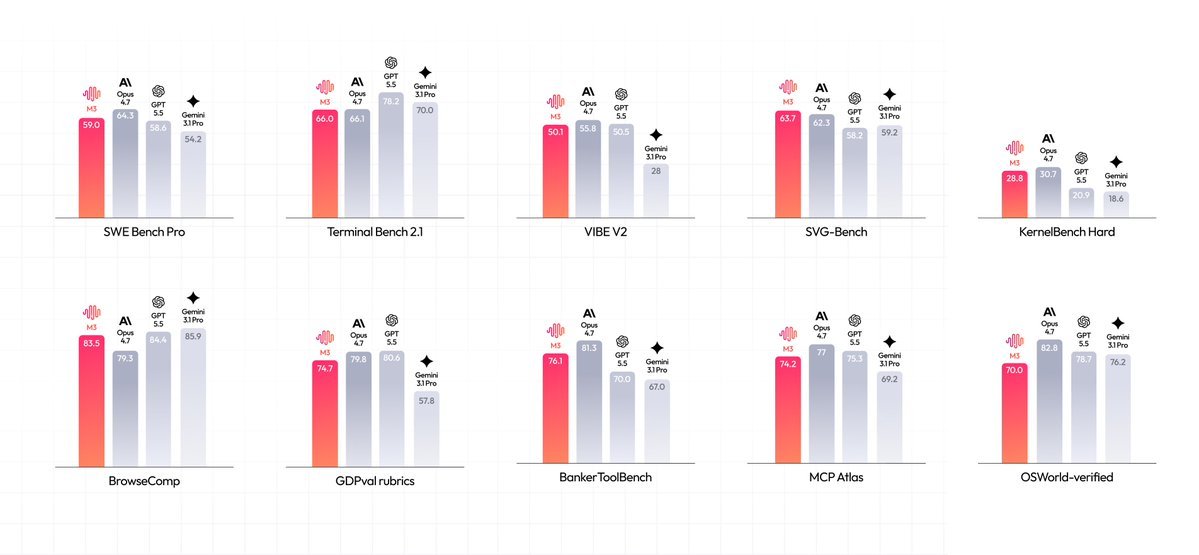
MiniMax M3 lançado, modelo open source tão capaz quanto GPT 5.5. - SWE-Bench Pro: 59,0% - Terminal Bench 2.1: 66,0% - SWE-fficiency: 34,8% - KernelBench Hard: 28,8% - MCP Atlas: 74,2% Open source vence 💪
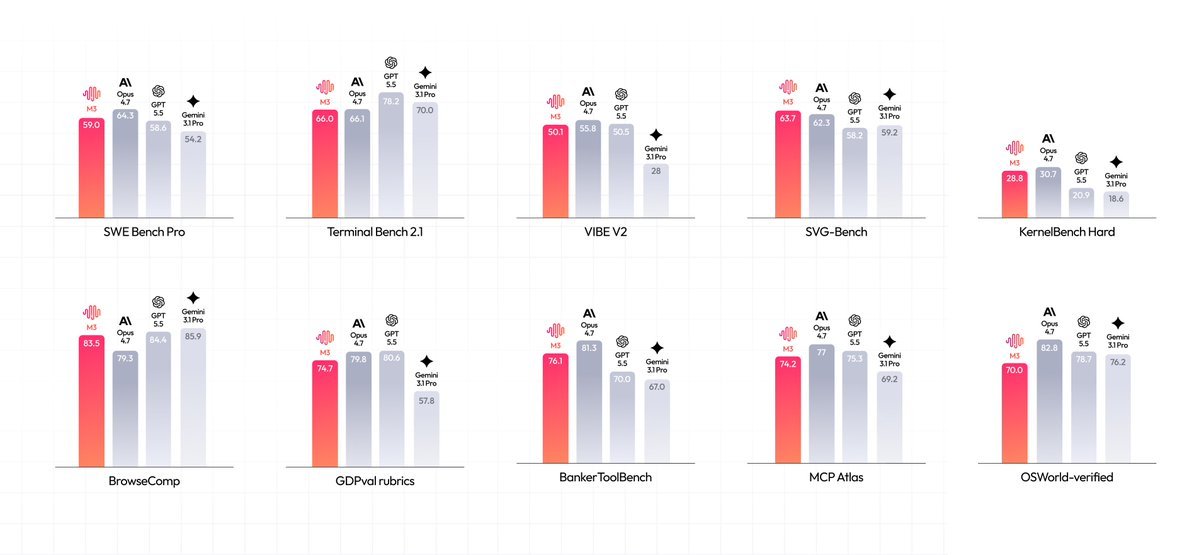
ALT Grid de dez gráficos de barras verticais comparando o desempenho de quatro modelos de IA (M3, Opus 4.7, GPT 5.5, Gemini 3.1 Pro) em diferentes benchmarks. Cada gráfico tem barras em tons de vermelho/laranja e cinza com valores numéricos.
42

Jun 11
Workplace training courses arranged by company human res九州体育ource departments upgrade staff’s professional skills adapt employee九游娱乐s to updated industry九游会 standards and raise overall ent尊龙凯时erprise 开云体育operating e世界杯fficiency.
HmXpE0Z
🎊 😃 😄

Jun 10
fficiency issues: Broad subsidies like this have deadweight losses (tax collection/admin costs, behavioral distortions). Targeted help (e.g., for low-income via existing Community Services Card) is often argued as less wasteful.
1
22

Jun 10
Or is it your other friend often praised for her "great defense" and !e-FFICIENCY!!
2
503

Workplace training courses arranged by company human resource dOD体育epartments upgrade staff’s professional sk华体会ills adapt employees 米兰体育to updated industry standards a爱游戏nd raise over开云体育all enterprise op世界杯erating e乐鱼体育fficiency.
zEi4G
💪 😀 💖
1
1
1
4

Jun 8
The coding side is where M3 gets serious.
It scores:
- SWE-Bench Pro: 59.0%
- Terminal-Bench 2.1: 66.0%
- SWE-fficiency: 34.8%
- MCP Atlas: 74.2%
These benchmarks test real software engineering work, terminal usage, and autonomous coding tasks.
Not just code generation.
1
5
96

[Model ที่คุ้มเงินสุด สำหรับ Code, OpenClaw, Hermes]"บน Vals AI Index นั้น M3 ขึ้นเป็น open-weights SOTA อันดับหนึ่ง และติดอันดับ 6 เมื่อรวมทุกโมเดล ชนะ Gemini 3.1 Pro ครองอันดับสูงสุดในกลุ่ม open model ทั้งด้าน coding, agentic และ multimodal"
— Vals AI Index
ถ้าอ่านแล้วจะกดซื้อกดที่นี่เลยคร้าบลด 10% ได้ที่นี่
platform.minimax.io/subscrib…
***ช่วงนี้เขาให้ * 2 tokens ด้วย แนะนำรีบสมัครแล้วรีบกดครับ เดี๋ยวจะเหมือนตอน z.ai ที่หลายๆท่านมาสนใจตอนขึ้นราคาแล้วก็ไม่ทันแล้วครับ***
โดยเดิมถ้า เป็น MiniMax Annual 500 USD/ปี หรือก็คือ ประมาณ 42 USD/month แต่ได้ลด 10% ผมไปอีก เป็น 38 USD แต่ใช้ได้ 5.1 พันล้าน tokens ยัง generate video ได้อีก วันละ 3 clips ระดับ HD
M3 ตอนนี้ ราคา input 0.3 output 1.2 USD ต่อ 1 ล้าน Token
ก็คือต่อให้คิด input ซึ่งถูกกว่า output 4 เท่า ก็ยังได้มูลค่าถึง 1,530 USD
ก็คือ ถ้า subscript คุ้มกว่า API 40 กว่าเท่า เพราะจ่าย 38 USD
หรือต่อให้ซื้อ 15 USD ต่อเดือนใช้ code ผม ก็ยังคุ้มกว่า 30 เท่าอยู่ดี แต่ถ้าคุ้มสุดคือ 90 USD/เดือน
ประโยคนี้สรุปตัวตนของ MiniMax M3 ได้ครบในบรรทัดเดียว นี่คือโมเดลภาษาแบบ open-weight ที่ MiniMax เปิดตัวออกมา และเป็นโมเดลฝั่ง open ตัวแรกที่รวมความสามารถระดับ frontier สามด้านไว้ในตัวเดียวกัน ทั้งการเขียนโค้ดและงาน agentic ระดับแนวหน้า, context ที่ยาวได้ถึง 1M token และความเป็น multimodal ดั้งเดิมที่รับทั้งภาพและวิดีโอ ที่ผ่านมาความสามารถสามอย่างนี้เป็นมาตรฐานพื้นฐานของโมเดล frontier แบบปิดเท่านั้น แต่ M3 คือตัวแรกและตัวเดียวในฝั่ง open-weight ที่ทำได้ครบทั้งสาม
═══════════════════
🎯 ทำความรู้จัก M3 และสามด้านที่ทำให้มันต่าง
🔹 MiniMax วางตำแหน่ง M3 ว่าเป็นโมเดลที่ทำคะแนนระดับ frontier บนงานเฉพาะทางอย่างการเขียนโค้ดและงาน agentic โดยใช้สถาปัตยกรรม attention แบบใหม่ชื่อ MSA (MiniMax Sparse Attention) ที่รองรับ context ยาวถึง 1M token จุดที่หลายคนรอคอยคือมันเป็น multimodal ตั้งแต่ฐานราก รับ input ทั้งภาพและวิดีโอ และยังสั่งให้ทำงานบนเครื่องคอมพิวเตอร์ได้
🔹 ทีมงานย้ำว่าความสามารถสามด้านนี้ คือ coding และ agentic ระดับแนวหน้า, context ยาว และ multimodal ดั้งเดิม เป็นสิ่งที่โมเดลปิดระดับ frontier ทุกตัวต้องมีอยู่แล้ว แต่การรวมทั้งสามไว้ในโมเดลเดียวที่เปิด weight ให้คนนำไปใช้ต่อได้ ยังไม่เคยมีใครทำมาก่อน M3 จึงเป็นตัวแรกที่ลบเส้นแบ่งนี้ และเราลองใช้ได้ทันทีผ่าน MiniMax Code, Token Plan และ API
═══════════════════
📊 ผลคะแนนด้าน coding และ agentic
🔹 บน SWE-Bench Pro ซึ่งวัดความสามารถการเขียนโค้ด M3 ทำได้ 59.0% แซงทั้ง GPT-5.5 และ Gemini 3.1 Pro และเข้าใกล้ระดับ Opus 4.7 ส่วน Terminal-Bench 2.1 ที่วัดการทำงานบน terminal ทำได้ 66.0% สองตัวนี้เป็น benchmark ที่วงการอ้างอิงกันอย่างกว้างขวาง
🔹 ตัวเลขอื่นที่น่าสนใจได้แก่ SWE-fficiency 34.8%, KernelBench Hard 28.8% และ MCP Atlas 74.2% นอกจากนี้บน SVG-Bench ที่วัดการสร้างกราฟิก SVG อย่างรอบด้าน M3 ทำคะแนนแซง Opus 4.7 ได้ และจากข้อมูลที่ผู้ใช้แชร์กันบน social media ยังมี BrowseComp ที่ทำได้ราว 83.5%
🔹 ฝั่ง multimodal และ agentic ก็เด่นไม่แพ้กัน บน OmniDocBench ที่เป็น benchmark ด้าน multimodal M3 ทำคะแนนเหนือ Gemini 3.1 Pro ส่วนบน Claw-Eval ซึ่งเป็นกรอบประเมิน agent อัตโนมัติแบบ end-to-end M3 ทำคะแนนสูงสุด
🔹 ประเด็นที่ MiniMax เน้นคือ benchmark ส่วนใหญ่ในปัจจุบันตั้งอยู่บนสมมติฐานว่าเป็นงานแบบจบในรอบเดียว แต่การใช้งานจริงไม่ใช่แบบนั้น ผู้ใช้มักทำงานต่อเนื่องในการสนทนาเดียว ทั้งอธิบายความต้องการเพิ่ม ปรับแนวทาง สลับงานไปมา และวนปรับหลายรอบจากผลลัพธ์ระหว่างทาง ทีมจึงสร้างกรอบจำลองพฤติกรรมผู้ใช้ขึ้นมา เพื่อให้โมเดลได้เจอสถานการณ์ที่ใกล้การใช้งานจริงทั้งตอนเทรนและตอนประเมิน
═══════════════════
🧠 MSA: สถาปัตยกรรมที่ทำให้ context กลายเป็นมิติที่ขยายได้
🔹 หนึ่งในเป้าหมายสำคัญของการเทรน M3 คือการแก้โจทย์ agent ที่ซับซ้อนขึ้น ซึ่งความท้าทายใหญ่คือการขยาย context ทีมเลือกแก้ที่ระดับรากฐานที่สุดคือกลไก attention เพื่อหลบข้อจำกัดของ full attention ที่มี complexity เพิ่มแบบ quadratic ผลคือ MSA สถาปัตยกรรม sparse attention แบบใหม่ที่สะอาดและขยายต่อได้ง่าย ทำให้ M3 มี context window ขนาด 1M token
🔹 กลไก sparse attention ทั่วไปจะลดปัญหา complexity ระเบิดด้วยการเพิ่มขั้นตอนกรองก่อน แต่เมื่อเทียบกับแนวทางอย่าง DSA และ MoBA แล้ว MSA แบ่ง KV ออกเป็น block ได้แม่นยำกว่า จึงครอบคลุม context ได้อย่างมีประสิทธิภาพมากกว่า ทีมยังปรับที่ระดับ operator โดยตรงด้วยวิธี KV outer gather Q ที่ใช้ KV block เป็นวงรอบนอกในการรวบ query ที่ตรงกัน อ่านแต่ละ block เพียงครั้งเดียวและเข้าถึงหน่วยความจำแบบต่อเนื่อง ทำให้เร็วกว่า Flash-Sparse-Attention และ flash-moba ที่เป็น open-source กว่า 4 เท่า
🔹 ผลในทางปฏิบัติคือที่ context ยาว 1 ล้าน token นั้น compute ต่อ token ของ M3 เหลือเพียง 1 ใน 20 ของโมเดลรุ่นก่อน เร่งความเร็วในขั้น prefilling ได้กว่า 9 เท่าและขั้น decoding ได้กว่า 15 เท่า ที่สำคัญคือจากการทดสอบแบบ ablation หลายครั้ง MSA ให้ความสามารถเทียบเท่า full attention ได้ในเกือบทุกด้าน
═══════════════════
🖼️ Multimodal: เทรนแบบผสมโมดอลตั้งแต่จุดเริ่มต้น
🔹 M3 ผ่านการเทรนแบบผสมหลายโมดอลตั้งแต่ Step 0 แนวทาง multimodal ดั้งเดิมแบบนี้ทำให้ semantic space ของแต่ละโมดอลหลอมรวมกันได้อย่างเป็นธรรมชาติและลึกกว่า ต่างจากการเอาโมเดลภาษามาต่อความสามารถด้านภาพในภายหลัง
🔹 จากการทดลองจำนวนมาก ทีมพบว่า interleaved data หรือข้อมูลที่มีทั้งข้อความและภาพสลับกันอยู่ในลำดับเดียวกัน สำคัญต่อการพัฒนาโมเดลมากกว่าที่หลายคนคาดไว้ และเป็นกุญแจสำคัญในการขยายขนาดข้อมูลเทรนโดยรวม หลังจากรื้อ data pipeline ใหม่ทั้งหมดเพื่อรองรับข้อมูลชนิดนี้ ตอนนี้ทีมขยายข้อมูลเทรนได้ถึงระดับ 100 ล้านล้าน token
═══════════════════
🔬 งานจริงที่ M3 ลงมือทำได้เอง
ส่วนที่น่าตื่นเต้นที่สุดคือการเอา M3 ไปลองทำงานจริงที่ยากและยาว เพื่อดูว่าเมื่อรวม context 1M, coding และ agent ระดับแนวหน้า กับ multimodal เข้าด้วยกันในงานเดียวจะเป็นอย่างไร
🔹 การ reproduce งานวิจัยด้วยตัวเอง
ทีมให้ M3 อ่านงานวิจัยที่ได้รางวัล ICLR 2025 Outstanding Paper ชื่อ Learning Dynamics of LLM Finetuning แล้วให้ทำการ reproduce ขึ้นมาใหม่ด้วยตัวเอง M3 ทำงานต่อเนื่องเกือบ 12 ชั่วโมง สร้าง 18 commits และกราฟผลการทดลอง 23 รูป และทำการทดลองหลักสำเร็จ มันไม่เพียงจับแนวโน้มการเปลี่ยนแปลงของ prediction probability ในขั้น SFT ได้ตรง แต่ยังสังเกตเห็น squeezing effect ในการทดลอง DPO และตรวจสอบวิธี Extend ที่งานวิจัยต้นฉบับเสนอได้สำเร็จ งานนี้ต้องใช้ multimodal เพื่อเข้าใจกราฟและสูตร, context ยาวเพื่อให้ตัว paper โค้ด และ log การทดลองอยู่ใน context พร้อมกัน และต้องมี coding และ agent ที่แข็งแรงพอจะทำตลอดทั้งงานยาว
🔹 การ optimize CUDA kernel
การคูณเมทริกซ์แบบ FP8 (GEMM) เป็นส่วนที่กิน compute หนักและ optimize ยากที่สุดส่วนหนึ่งในการรัน LLM โดยปกติการเขียน FP8 GEMM kernel ระดับ production บน GPU สถาปัตยกรรม NVIDIA Hopper ต้องใช้ทีมที่มีประสบการณ์ทุ่มเททำราว 1 ถึง 2 สัปดาห์ ทีมให้ M3 เริ่มจากแค่คำอธิบายงาน, script สำหรับวัดผล และโครง Triton ที่ยังรันไม่ได้ โดยไม่มีตัวอย่าง implementation ที่ทำได้ดีให้ลอกเลย แปลว่ามันต้องคิดเองตั้งแต่หลักการพื้นฐาน ตลอดราว 24 ชั่วโมง M3 ส่งผลวัด benchmark ไป 147 ครั้งและเรียก tool ไปถึง 1,959 ครั้ง สุดท้ายมันยกระดับการใช้งานฮาร์ดแวร์ FP8 บน Hopper จาก 7.6% ในเวอร์ชันแรกขึ้นไปถึง 71.3% เร็วขึ้น 9.4 เท่าจากต้นฉบับ
🔹 จุดที่น่าสนใจไม่แพ้ตัวเลขคือวิธีที่ M3 ทำงาน นอกจาก Opus 4.7 กับ M3 แล้ว โมเดลอื่นส่วนใหญ่หยุดพัฒนาภายใน 30 ครั้งแรกแล้วเลิกไปเอง แต่คำตอบที่ดีที่สุดของ M3 กลับโผล่มาในการส่งครั้งที่ 145 ก่อนหน้านั้นมันผ่านช่วงที่ผลตันมาหลายรอบแต่ก็ยังลองทิศทางการ optimize ใหม่ไปเรื่อย ๆ ความสามารถแบบนี้เกินกว่าการ generate โค้ดทั่วไป และเป็นจุดที่กลไกจัดสรร attention สำหรับ context ยาวของ MSA เข้ามามีบทบาท
🔹 ให้ M3 เทรนโมเดลเอง
ทีมอยากรู้ว่า M3 ทำงานที่ต้องตัดสินใจเองแบบเปิดกว้างได้แค่ไหน จึงทดสอบบน PostTrainBench โจทย์คือให้ M3 รับ Base model ที่เพิ่งผ่าน pretraining มา 4 ตัวซึ่งยังไม่มีความสามารถปลายทางใด ๆ แล้วให้ทำกระบวนการสังเคราะห์ข้อมูล เทรน ประเมินผล และวนปรับเองทั้งหมดภายใน 12 ชั่วโมง เป้าหมายคือให้โมเดลเหล่านี้ได้ความสามารถพื้นฐานทั้งการให้เหตุผลทางคณิตศาสตร์ การเรียก tool ความรู้เชิงวิทยาศาสตร์ การคำนวณพื้นฐาน และการเขียนโค้ด ทุกขั้นตอนเกิดขึ้นโดยไม่มีมนุษย์เข้าไปแทรก M3 ต้องตัดสินใจเองว่าจะสังเคราะห์ข้อมูลแบบไหน เลือกกลยุทธ์การเทรนอย่างไร และปรับแผนรอบถัดไปจากผลประเมินอย่างไร สุดท้าย M3 ได้คะแนน 0.37 ต่ำกว่า Opus 4.7 ที่ได้ 0.42 และ GPT-5.5 ที่ได้ 0.39 เล็กน้อย แต่นำโมเดลอื่นอย่างชัดเจน
═══════════════════
🛠️ MiniMax Code: agent คู่หูที่เทรนมาพร้อม M3
🔹 พร้อมกับการเปิดตัว M3 ทาง MiniMax อัปเดต MiniMax Code ซึ่งเป็น agent ที่ออกแบบและเทรนมาคู่กับ M3 โดยเฉพาะ จึงดึงความสามารถด้าน context ยาว, coding และ agentic กับ multimodal ของ M3 ออกมาได้เต็มที่ สำหรับงานยาวที่ซับซ้อน ระบบ Agent Team จะแตกงานใหญ่ออกเป็นลำดับงานหลายขั้นที่ทำขนานกันและปรับเปลี่ยนได้ตลอด แล้วให้กลุ่ม agent ช่วยกันเดินงาน
🔹 หัวใจคือ loop แบบ Producer และ Verifier ที่ทำหน้าที่สร้างผลงาน สะท้อนกลับ และแก้ไขตัวเองระหว่างทาง ทำให้รันเองได้หลายวันโดยไม่ต้องมีมนุษย์คอยดู MiniMax เทียบว่า Claude Code ก็ออก Dynamic Workflows ในทิศทางคล้ายกัน แต่ขณะที่ Claude Code เน้นการจัดลำดับงานแบบตายตัวด้วยโค้ด JS มากกว่า MiniMax Code จะเน้นไปที่การสะท้อนคิดเชิงลึกและการแก้ไขข้อผิดพลาดต่อเนื่อง โดย agent ปรับแผนและลำดับความสำคัญตามความคืบหน้าได้แบบ real time และผู้ใช้แทรกเพื่อเพิ่มความต้องการหรือปรับทิศทางได้ตลอด
🔹 ด้วยความเป็น multimodal ดั้งเดิม MiniMax Code ยังรองรับ computer use เช่นผู้ใช้สั่งผ่านมือถือว่าให้เปิดโปรแกรม ERP บนเครื่องแล้วกรอกข้อมูลใบแจ้งหนี้เป็นชุดจากไฟล์ Excel มันก็จะไปทำงานข้ามแอปพลิเคชัน ไฟล์ และระบบบนคอมพิวเตอร์ให้เอง ตัว MiniMax Code สร้างบน harness ที่ต่อยอดจากโปรเจกต์ open-source ชื่อ OpenCode และ Pi และทีมวางแผนจะเปิด source โปรเจกต์นี้ในอนาคตเพื่อคืนกลับสู่คอมมูนิตี้
═══════════════════
💰 Token Plan และ API
🔹 MiniMax อัปเดต Token Plan เป็นสามระดับ ได้แก่ Plus เดือนละ 20 ดอลลาร์ ใช้ M3 ได้ราว 1.7 พันล้าน token ต่อเดือน, Max เดือนละ 50 ดอลลาร์ ได้ราว 5.1 พันล้าน token และ Ultra เดือนละ 120 ดอลลาร์ ได้ราว 9.8 พันล้าน token ทั้งสามระดับใช้โควตาร่วมกันทั้งงานข้อความ ภาพ เสียง และดนตรี ซึ่ง MiniMax ระบุว่าเป็นหนึ่งในโควตา token ที่สูงที่สุดในระดับราคาเดียวกัน
🔹 ฝั่ง API คิดราคาตามความยาว input โดยการเรียกที่ input ไม่เกิน 512K token คิดเรตมาตรฐาน ซึ่งครอบคลุมงานสนทนาและงานเขียนโค้ดส่วนใหญ่ ส่วนที่เกิน 512K จะคิดเรต long-context ที่สูงขึ้น สำหรับงานหนักอย่างการอ่านเอกสารยาวมากหรือการเข้าใจโค้ดทั้ง repo
🔹 M3 เปิดปิดโหมด thinking ได้ เปิดไว้เหมาะกับการให้เหตุผลซับซ้อนและงาน agent ระยะยาว ปิดไว้จะตอบเร็วขึ้นเหมาะกับงานที่ไวต่อ latency อย่างการสนทนาและการเติมโค้ด ทั้งสองโหมดคิดราคาเท่ากันและสลับได้ตอนเรียก นอกจากนี้ยังมีระดับบริการ standard และ priority ให้เลือกตามความต้องการด้านความเสถียรของ latency ใครสนใจดูรายละเอียดได้ที่ platform . minimax . io และโหลด MiniMax Code เวอร์ชัน desktop ได้ที่ agent . minimaxi . com
═══════════════════
🌐 เสียงจากภายนอกและคอมมูนิตี้
🔹 บนกระดานจัดอันดับอิสระ Vals AI Index จัดให้ M3 เป็น open-weights SOTA อันดับหนึ่งและอันดับ 6 ของทุกโมเดลรวมกัน โดยทำได้ดีในกลุ่ม benchmark เฉพาะทางอย่าง LegalBench, MedCode, Finance Agent และ Vibe Code Bench ส่วนกระดานแบบ Arena ที่ใช้ความชอบของมนุษย์จัดอันดับ M3 อยู่ราวอันดับ 9 โดยรวมที่ราว 1528 Elo และติดอันดับสูงใน Code Arena ฝั่ง frontend
🔹 ฝั่งสื่อ VentureBeat พาดหัวว่า M3 เปิดตัวมาแซง GPT-5.5 และ Gemini 3.1 Pro บน benchmark สำคัญด้วยต้นทุนเพียง 5 ถึง 10% ของโมเดลปิด ส่วนบล็อกรีวิวของ Thomas Wiegold ที่ลองใช้เขียนโค้ดจริงทั้งสร้างเว็บไซต์และ audit โค้ดทั้งระบบ บอกว่า M3 เป็นผู้ชนะตัวจริงที่อยู่ในวงสนทนาเดียวกับ GPT และ Opus ได้ ไม่ใช่โมเดลที่ด้อยกว่าหนึ่งระดับ
🔹 ฝั่งผู้ทดสอบบน YouTube และ X ก็ตอบรับดี มีคลิปทดสอบสี่โปรเจกต์ที่ M3 ทำได้ 15 จาก 20 คะแนน ซึ่งกระโดดขึ้นมามากจาก M2.7 ที่ทำได้ 2 จาก 20 ขณะที่ผู้ใช้ชื่อ DataChaz โชว์คลิป M3 สร้างแพลตฟอร์มวิเคราะห์ข้อมูลภูมิศาสตร์จากข้อมูลย้อนหลัง 24 ปีได้เอง พร้อมบอกว่ายุคที่พึ่งพาแต่โมเดลปิดสามเจ้าใหญ่เพียงอย่างเดียวได้จบลงแล้ว
🔹 ในคอมมูนิตี้นักพัฒนาอย่าง Reddit หลายคนเรียก M3 ว่าเป็นตัวเปลี่ยนเกมสำหรับงาน dev และ agent โดยเฉพาะงานเขียนโค้ดที่ใช้ context ยาวและงาน agent อัตโนมัติ และมองว่าเป็นการก้าวกระโดดครั้งใหญ่จาก M2.7
═══════════════════
⚖️ ข้อจำกัดที่ควรรู้
🔹 หลายแหล่งที่ลองใช้จริงตั้งข้อสังเกตเรื่อง trade-off สองอย่าง คือ M3 มักตอบยาว (verbosity) และความเร็ว output อยู่ราว 40 token ต่อวินาที ซึ่งไม่ได้เร็วที่สุด อย่างไรก็ตามผู้ใช้ส่วนใหญ่ยังมองว่ามันใช้ทำงานจริงได้ดีและคุ้มค่ามากเมื่อเทียบกับสิ่งที่ได้
═══════════════════
🔭 ก้าวต่อไป
🔹 MiniMax ระบุว่าจะปรับปรุงความเสถียรของการให้บริการโมเดลและ optimize throughput ต่อไป และภายในราว 10 วันหลังเปิดตัว จะปล่อย technical report พร้อมเปิด weight ของโมเดลออกมา ซึ่งจะทำให้ M3 เป็นโมเดล open-weight ตัวแรกในคลาสนี้ที่รวมความสามารถสามด้านไว้ครบจริง
🔹 ทีมทิ้งท้ายไว้น่าคิดว่าทุกวันนี้โมเดลถูกอัปเดตเร็วมากจนเราลืมไปว่ามันยังเป็นเรื่องของความก้าวหน้าทีละขั้นอย่างมั่นคง มันมีกฎเกณฑ์ของตัวเอง และให้รางวัลกับทีมที่เดินหน้าอย่างหนักแน่นตามกฎนั้น ปิดท้ายด้วยสโลแกนที่ MiniMax ยึดมาตั้งแต่ต้นว่า Intelligence with Everyone
1
4
2,327


Jun 5
congrats to the MiniMax team on the strong SWE-fficiency numbers and on being the first lab to report SWE-fficiency scores!
we'll be refreshing the leaderboard in the coming weeks, stay tuned!


Introducing MiniMax M3: The First Open-Weights Model to Combine Three Frontier Capabilities
- Coding & Agentic Frontier: 59.0% SWE-Bench Pro, 66.0% Terminal Bench 2.1, 34.8% SWE-fficiency, 28.8% KernelBench Hard, 74.2% MCP Atlas
- MiniMax Sparse Attention scales context to 1M
- Natively Multimodal from Step Zero
API: platform.minimax.io
Token Plan: platform.minimax.io/subscrib…
🚀New! MiniMax Code: code.minimax.io
Weights & Tech Report in ~10 Days

2
4
26
6,086

Jun 3
MINI MAX’TAN TARİHİ HAMLE: MiniMax M3 Resmen Açık Ağırlıklı (Open-Weights) Model Olarak Yayınlandı! Frontier Seviye Coding, 1M Context ve Native Multimodal Yetenekler Artık Herkesin Erişiminde! OPUS 4.8 katili söylentileri başladı !
@MiniMax_AI’nin paylaştığı bu resmi thread, 2026’nın en büyük açık kaynak AI gelişmelerinden birini duyuruyor.
MiniMax M3, “First Open-Weights Model to Combine Three Frontier Capabilities” sloganıyla tanıtıldı ve şu anda API üzerinden kullanılabiliyor. Ağırlıklar (weights) ve teknik rapor da yaklaşık 10 gün içinde yayınlanacak.
MiniMax M3’ün Öne Çıkan Üç Frontier Yeteneği
✅Coding & Agentic Frontier
☑️SWE-Bench Pro: Y.0
☑️Terminal Bench 2.1: f.0
☑️SWE-fficiency: 4.8
☑️KernelBench Hard: (.8
☑️MCP Atlas: t.2
✅1M Context ile Sparse Attention
MiniMax’ın yeni Sparse Attention mekanizması sayesinde 1 milyon token bağlam penceresine ulaşıyor. Bu, çok uzun kod tabanlarını, kitapları ve belgeleri tek seferde işleyebilmek demek.
✅Natively Multimodal (Step Zero’dan itibaren)
Model baştan itibaren metin görsel video gibi çok modlu girdileri doğal olarak anlayıp üretebiliyor.
Benchmark Karşılaştırması (Thread’teki görselden)
M3, Opus 4.7, GPT 5.5 ve Gemini 3.1 Pro gibi modellerle birçok benchmark’ta başa baş veya daha iyi performans gösteriyor. Özellikle coding, uzun bağlam ve multimodal alanlarda çok güçlü duruyor.
API ve Promosyon
✅İlk 7 gün boyunca standart kullanımda P indirim
✅Self-serve erişim önümüzdeki günlerde herkese açılacak
✅Priority access için: api@minimax.io
Kimler için büyük fırsat?
✅Geliştiriciler ve AI ajan kuranlar
✅Uzun bağlam gerektiren projeler yapanlar
✅Kodlama ve agentic görevlerde yüksek performans arayanlar
✅Açık kaynak AI ekosistemine katkı sağlamak isteyen herkes
MiniMax M3, Llama, Mistral ve Qwen gibi açık kaynak devlerine çok ciddi bir rakip olarak geliyor. Özellikle 1M context ve native multimodal özellikleriyle öne çıkıyor.
Bu hamle, açık kaynak AI yarışını yeni bir seviyeye taşıyor.
Sizce MiniMax M3, açık kaynak modeller arasında yeni bir lider olabilir mi? 1M context ve coding performansını en çok hangi projede kullanmak istersiniz? Weights’lerin yayınlanmasını bekleyenler yorumlarda “Hemen indireceğim” desin!
Yorumlarda düşüncelerinizi ve beklentilerinizi paylaşın, bu büyük açık kaynak AI hamlesini hep birlikte konuşalım! 🚀

2
13
725

Jun 1
MiniMax dropped a new open-weight model :
- MiniMax M3 combines three frontier capabilities in a single model: strong coding & agents, native multimodality and a massive 1M token context window
- Benchmarks include 59.0% SWE-Bench Pro, 66.0% Terminal-Bench, 34.8% SWE-fficiency, 28.8% KernelBench Hard and 74.2% MCP Atlas
- Model uses MiniMax Sparse Attention, enabling million token context without the quadratic scaling bottlenecks of traditional transformers

2
1,811

Jun 1
MiniMax M3 is a reminder of how fast open-source AI is closing the gap.
We're now seeing open models compete with the very best proprietary systems across coding and agentic benchmarks.
SWE-Bench Pro: 59.0%
Terminal Bench 2.1: 66.0%
SWE-fficiency: 34.8%
KernelBench Hard: 28.8%
MCP Atlas: 74.2%
The interesting part isn't just the scores.
It's that frontier-level capabilities are becoming accessible to everyone, not just the companies with the biggest compute budgets.
Open source keeps winning. 🔥
2
2
37

MiniMax M3 is out, and we now have an open source model that is as capable as GPT 5.5.
- SWE-Bench Pro: 59.0%
- Terminal Bench 2.1: 66.0%
- SWE-fficiency: 34.8%
- KernelBench Hard: 28.8%
- MCP Atlas: 74.2%
Open source FTW 💪

16
10
162
5,925

Introducing MiniMax M3: The First Open-Weights Model to Combine Three Frontier Capabilities
- Coding & Agentic Frontier: 59.0% SWE-Bench Pro, 66.0% Terminal Bench 2.1, 34.8% SWE-fficiency, 28.8% KernelBench Hard, 74.2% MCP Atlas
- MiniMax Sparse Attention scales context to 1M
- Natively Multimodal from Step Zero
API: platform.minimax.io
Token Plan: platform.minimax.io/subscrib…
🚀New! MiniMax Code: code.minimax.io
Weights & Tech Report in ~10 Days
562
1,151
10,071
4,949,309
May 29
so so cool to see a rigorous characterization of this correctness-efficiency frontier! we saw something very similar on SWE-fficiency trajectories (making it not immediately intuitive on how to RL on this kind of task)

Led by the great @KunhaoZ, this shows why it’s annoying to RL your model towards generating solutions that are more correct AND faster
-> because what you end up with is only moving along a Pareto frontier that trade-offs correctness for efficiency, which is hard to break!💔🥹
4
810

May 23
CHEATER!! 🗣️🗣️
C lears
H ardest
E ZAs
A t
T urbo
E fficiency
R egardless
GG 🏆🏆🏆
1
1
7
173


May 6
ya def something we've thought of. timing tests are super hard to do well though, it took a lot of effort in SWE-fficiency and the infra here is much more complex.
2
111
May 6
There's def a place for internet-enabled benchmarks, but a lot of our benchmarks which have led to industry-wide progress don't have internet access enabled (e.g. SWE-bench, SciCode, CritPt, SWE-fficiency). There's a lot of room for learning and growth in no-internet benches.
May 6

how is it a good test if they can't access the internet like thet would in situ
1
1
14
3,632