
Why your gradient boosting model is secretly overconfident (and how CatBoost gives it a reality check)
We all know the feeling. You train an XGBoost or LightGBM model, and the training error drops beautifully. The metrics look amazing. Then you deploy it on new data, and performance degrades unexpectedly.
Beyond standard overfitting, there is a deeper, subtle mathematical flaw in standard gradient boosting that contributes to this. ItŌĆÖs called Prediction Shift.
Here is the hidden trap.
In standard boosting, in iteration $k$, you calculate the gradient (the error) for a specific data point. To do this, you use the current model built from iterations $1$ to $k-1$.
The problem is that the current model *was already trained using that exact data point* in those previous rounds.
The model has "seen" this data point before. Therefore, the gradient it calculates on the training set is biased. It's too optimistic compared to the gradient it would see on fresh, unseen test data.
ItŌĆÖs like practicing for a final exam using the exact questions that will appear on the test. You will score amazingly well in practice. Your confidence will soar. But when you face new questions on the real exam, you fail because you memorized specific answers instead of learning general concepts.
Your model is deluding itself about how well it's actually doing.
¤ÜĆ CatBoostŌĆÖs "Ordered Boosting" Reality Check
CatBoost is the only major library that fixes this fundamental mathematical bias using a technique called Ordered Boosting.
It utilizes the same "time-travel" permutation logic I mentioned in previous posts.
To calculate the gradient for data point X, CatBoost uses a version of the model trained **only** on data points that appear *before* X in the shuffled timeline.
It strictly forbids the model from peeking at point X when building the specific trees used to predict point X.
The Result:
By removing this bias from the gradient estimation, CatBoost gets a "reality check" during every step of training. The training process is harder, but the resulting model generalizes significantly better to new data, especially on smaller or noisier datasets where this overfitting bias is most damaging.
TL;DR
ŌØī XGBoost / LightGBM: Calculate gradients on data the model has already seen, leading to overconfidence (Prediction Shift).
Ō£ģ CatBoost: Uses Ordered Boosting to ensure gradients are unbiased, leading to better generalization on fresh data.
A little extra math in the training process saves a lot of headaches in production.
Check my book -> valeman.gumroad.com/l/MasterŌĆ”
#MachineLearning #DataScience #CatBoost #GradientBoosting #AI #Overfitting

8
1,651

¤ÜĆ First ever: Gradient Tree Boosting for production frontier estimation ŌĆö satisfying all microeconomic axioms.
Result? 35% lower MSE vs. FDH. When ML meets production theory, both win.
¤ōä ESWA 2023 w/ Guillen & Esteve ¤æē doi.org/10.1016/j.eswa.2022.ŌĆ”
#GradientBoosting #ML #Efficiency
2
2
56

Apr 13
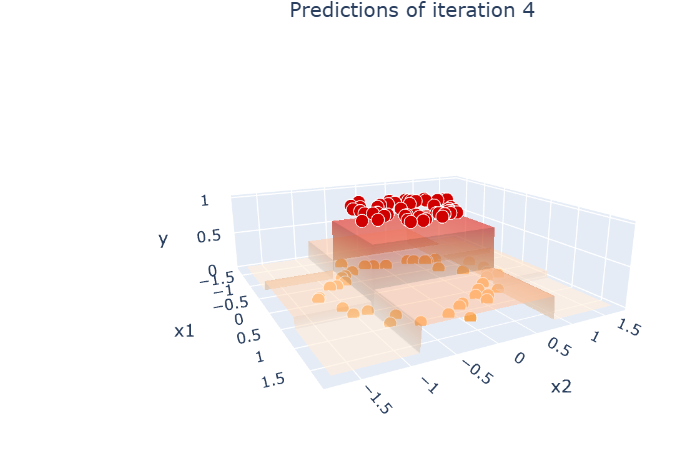
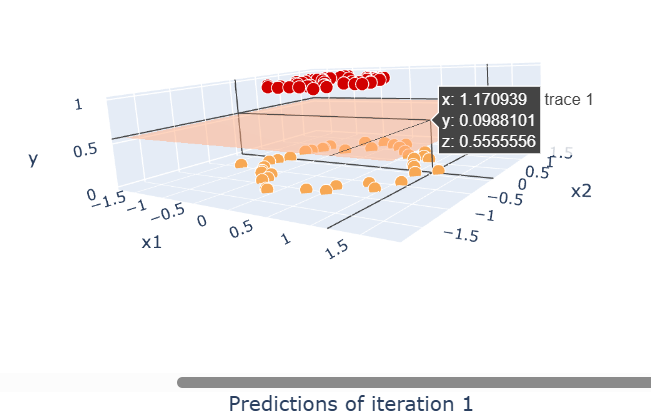
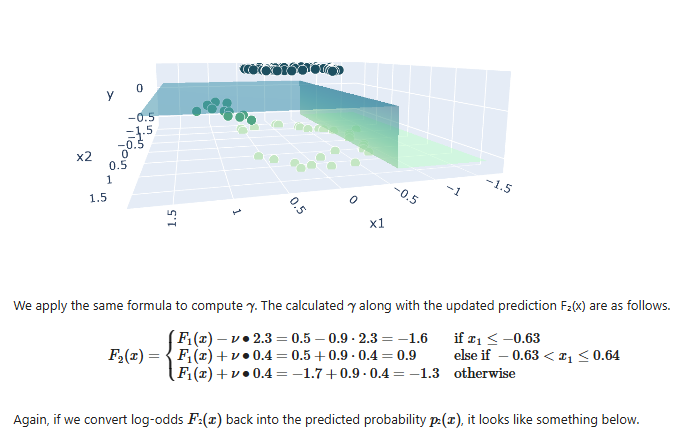
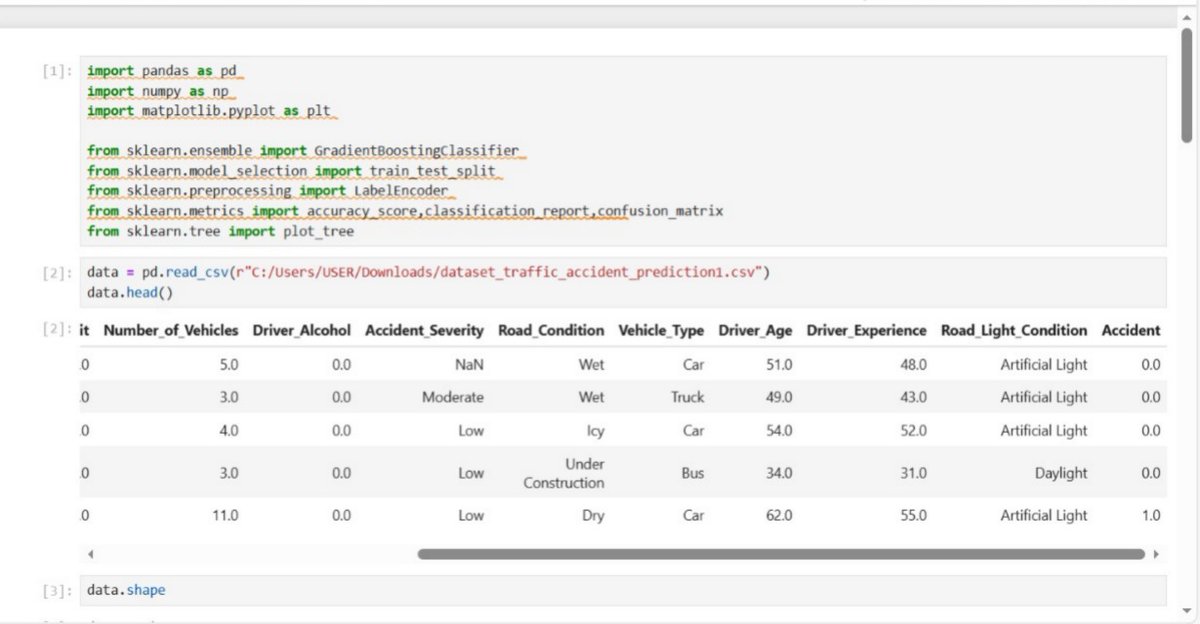
Day 70 of ML !!
Gradient Boosting (Regression Classification)
From math ŌåÆ residuals ŌåÆ log-odds ŌåÆ full implementation
code : [github.com/DiwanshuG/MachineŌĆ”]
#MachineLearning #GradientBoosting #LearnInPublic

1
4
62

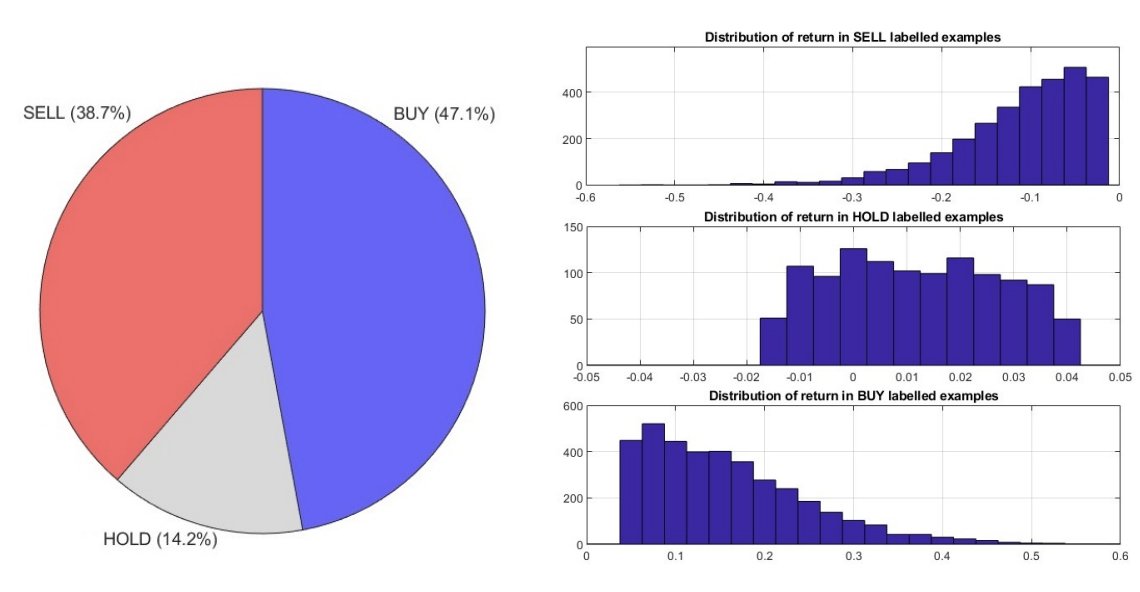
ŌĆ£Exploring Stability and Performance of hybrid #GradientBoosting Classification and Regression Models in Sectors #StockTrendPrediction: A Tale of Preliminary Success and Final ChallengeŌĆØ by M. Liu, L. Cen, D. Ruta, QH Vu. ACSIS Vol. 39 p. 761ŌĆō766; tinyurl.com/2uhrz43f
1
3
3
44
Why your gradient boosting model is secretly overconfident (and how CatBoost gives it a reality check)
We all know the feeling. You train an XGBoost or LightGBM model, and the training error drops beautifully. The metrics look amazing. Then you deploy it on new data, and performance degrades unexpectedly.
Beyond standard overfitting, there is a deeper, subtle mathematical flaw in standard gradient boosting that contributes to this. ItŌĆÖs called Prediction Shift.
Here is the hidden trap.
In standard boosting, in iteration $k$, you calculate the gradient (the error) for a specific data point. To do this, you use the current model built from iterations $1$ to $k-1$.
The problem is that the current model *was already trained using that exact data point* in those previous rounds.
The model has "seen" this data point before. Therefore, the gradient it calculates on the training set is biased. It's too optimistic compared to the gradient it would see on fresh, unseen test data.
ItŌĆÖs like practicing for a final exam using the exact questions that will appear on the test. You will score amazingly well in practice. Your confidence will soar. But when you face new questions on the real exam, you fail because you memorized specific answers instead of learning general concepts.
Your model is deluding itself about how well it's actually doing.
¤ÜĆ CatBoostŌĆÖs "Ordered Boosting" Reality Check
CatBoost is the only major library that fixes this fundamental mathematical bias using a technique called Ordered Boosting.
It utilizes the same "time-travel" permutation logic I mentioned in previous posts.
To calculate the gradient for data point X, CatBoost uses a version of the model trained **only** on data points that appear *before* X in the shuffled timeline.
It strictly forbids the model from peeking at point X when building the specific trees used to predict point X.
The Result:
By removing this bias from the gradient estimation, CatBoost gets a "reality check" during every step of training. The training process is harder, but the resulting model generalizes significantly better to new data, especially on smaller or noisier datasets where this overfitting bias is most damaging.
TL;DR
ŌØī XGBoost / LightGBM: Calculate gradients on data the model has already seen, leading to overconfidence (Prediction Shift).
Ō£ģ CatBoost: Uses Ordered Boosting to ensure gradients are unbiased, leading to better generalization on fresh data.
A little extra math in the training process saves a lot of headaches in production.
Check my book -> valeman.gumroad.com/l/MasterŌĆ”
#MachineLearning #DataScience #CatBoost #GradientBoosting #AI #Overfitting

5
821

1
2
18
853


Boosting battle! AdaBoost vs XGBoost vs LightGBM vs CatBoost - which reigns supreme? Find out the strengths & weaknesses of each in this head-to-head comparison!
#MachineLearning #Boosting #GradientBoosting
analyticsvidhya.com/blog/202ŌĆ”
1
6
252

20 Dec 2025
Why your gradient boosting model is secretly overconfident (and how CatBoost gives it a reality check)
We all know the feeling. You train an XGBoost or LightGBM model, and the training error drops beautifully. The metrics look amazing. Then you deploy it on new data, and performance degrades unexpectedly.
Beyond standard overfitting, there is a deeper, subtle mathematical flaw in standard gradient boosting that contributes to this. ItŌĆÖs called Prediction Shift.
Here is the hidden trap.
In standard boosting, in iteration $k$, you calculate the gradient (the error) for a specific data point. To do this, you use the current model built from iterations $1$ to $k-1$.
The problem is that the current model *was already trained using that exact data point* in those previous rounds.
The model has "seen" this data point before. Therefore, the gradient it calculates on the training set is biased. It's too optimistic compared to the gradient it would see on fresh, unseen test data.
ItŌĆÖs like practicing for a final exam using the exact questions that will appear on the test. You will score amazingly well in practice. Your confidence will soar. But when you face new questions on the real exam, you fail because you memorized specific answers instead of learning general concepts.
Your model is deluding itself about how well it's actually doing.
¤ÜĆ CatBoostŌĆÖs "Ordered Boosting" Reality Check
CatBoost is the only major library that fixes this fundamental mathematical bias using a technique called Ordered Boosting.
It utilizes the same "time-travel" permutation logic I mentioned in previous posts.
To calculate the gradient for data point X, CatBoost uses a version of the model trained **only** on data points that appear *before* X in the shuffled timeline.
It strictly forbids the model from peeking at point X when building the specific trees used to predict point X.
The Result:
By removing this bias from the gradient estimation, CatBoost gets a "reality check" during every step of training. The training process is harder, but the resulting model generalizes significantly better to new data, especially on smaller or noisier datasets where this overfitting bias is most damaging.
TL;DR
ŌØī XGBoost / LightGBM: Calculate gradients on data the model has already seen, leading to overconfidence (Prediction Shift).
Ō£ģ CatBoost: Uses Ordered Boosting to ensure gradients are unbiased, leading to better generalization on fresh data.
A little extra math in the training process saves a lot of headaches in production.
Check my book -> valeman.gumroad.com/l/MasterŌĆ”
#MachineLearning #DataScience #CatBoost #GradientBoosting #AI #Overfitting

1
1
11
1,500
17 Nov 2025
Serious about being a data scientist? Running fit() on a gradient boosting model isnŌĆÖt enough. Mastery is knowing which algorithm to chooseŌĆöand why.
XGBoost vs LightGBM vs CatBoost comes down to three dimensions:
1. Optimization scheme
ŌĆó XGBoost popularized secondŌĆæorder (Newton) updates using gradients and Hessians for robust, accurate minimization.
2. Tree construction strategy
ŌĆó LightGBM grows trees leafŌĆæwise (bestŌĆæfirst). ItŌĆÖs fast and memoryŌĆæefficient with GOSS and EFB, but can produce deep, asymmetric trees that overfit.
ŌĆó CatBoost builds balanced, symmetric ŌĆ£obliviousŌĆØ trees, enabling fast inference and helping resist overfitting.
3. Statistical treatment of data
ŌĆó Standard boosting reuses the full sample to estimate gradients, causing bias and prediction shift.
ŌĆó CatBoost uses Ordered Boosting and Ordered Target Statistics, computing estimates only from ŌĆ£pastŌĆØ examples in a permutation. This reduces leakage and improves robustness, especially with noisy data and many categorical features.
Stop guessing which booster to use. Start mastering the mechanics that power topŌĆætier tabular models.
Ready to go deeper? Grab my book, Mastering CatBoost Pro, this Black Friday.
valeman.gumroad.com/l/MasterŌĆ”
Code: BF2025
#DataScience #MachineLearning #XGBoost #LightGBM #CatBoost #GradientBoosting
1
3
31
2,714

27 Oct 2025
Day 88: Advanced Boosting.
Hands-on with Gradient Boosting: trained both Classifier (GBC) and Regression (GBR) models
Then deep dive into the in-depth intuition of XGBoost for classification, understanding the core logic that makes it so powerful.
#ML #GradientBoosting #XGBoost
3
63

27 Oct 2025
Day 162: Data Science Journey
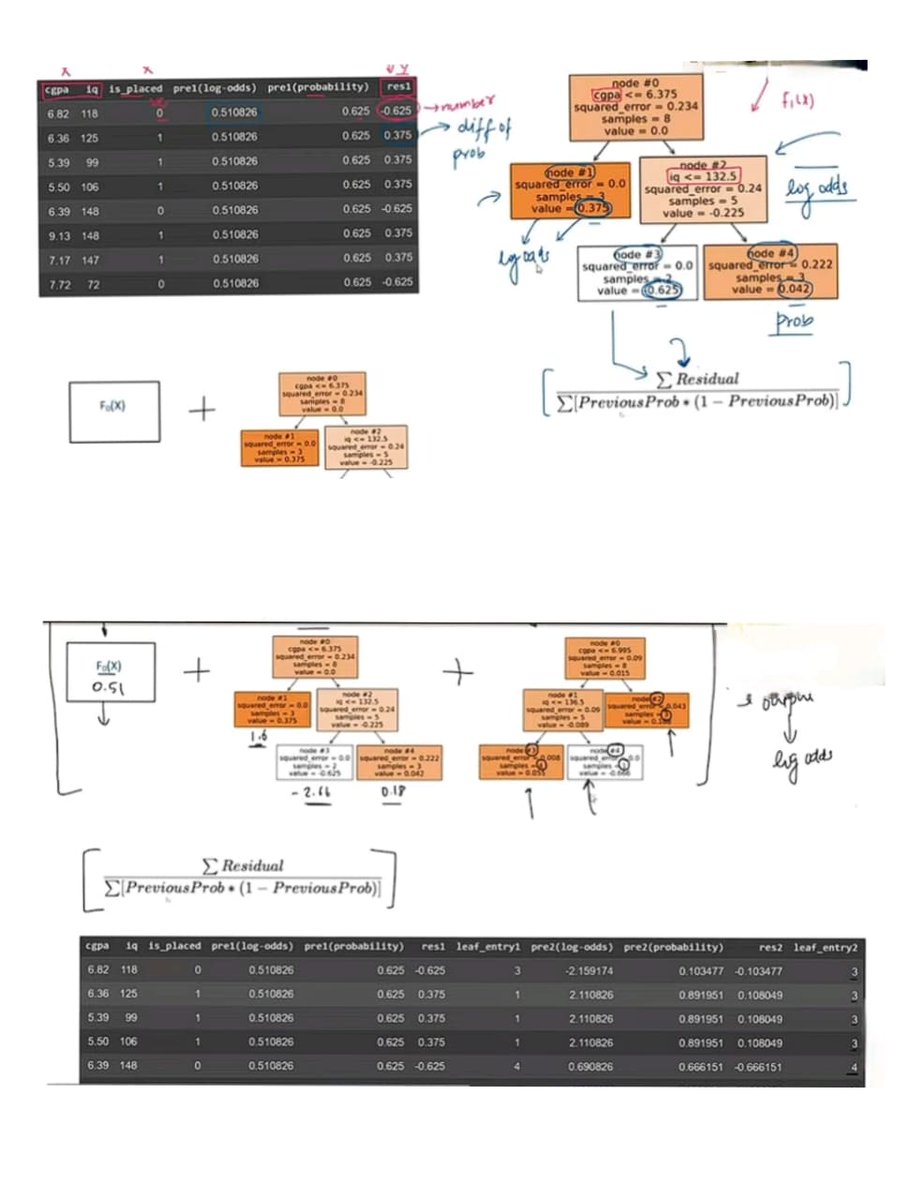
->GB: Uniform prob plane tags all class 1; residuals-> errors
->3D scatter contourf steering stumps to carve adpt bound, min log loss.
->Fix: F(x)=prev ╬│*tree (shrink ╬│<1), tunes 2x accuracy, kills overfit!
#DataScience #ML #GradientBoosting


1
12
494

26 Oct 2025
Official research paper out for one of our xAI startup.
CanŌĆÖt wait to share it with you guys ¤æĆ
#randomforrest #gradientboosting
1
1
3
160
26 Oct 2025
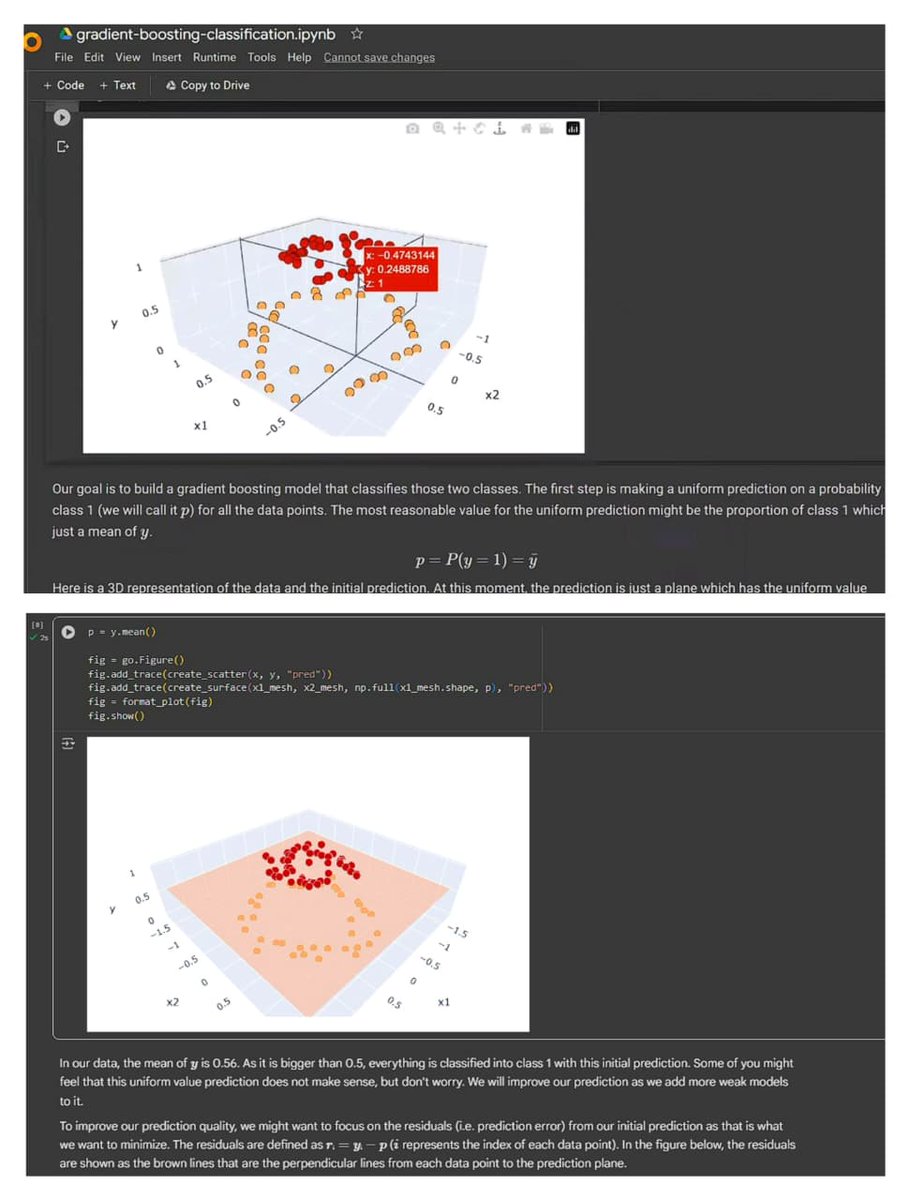
Day 161: Data Science Journey
->Flat pred plane at mean(y)=0.56 via Plotly 3D; all points classed as 1.
->Scatter3D real pts Surface for constant pred.
->Resid. r=y-p: vertical errors guide weak learners; start simple, correct via residuals.
#DataScience #ML #GradientBoosting
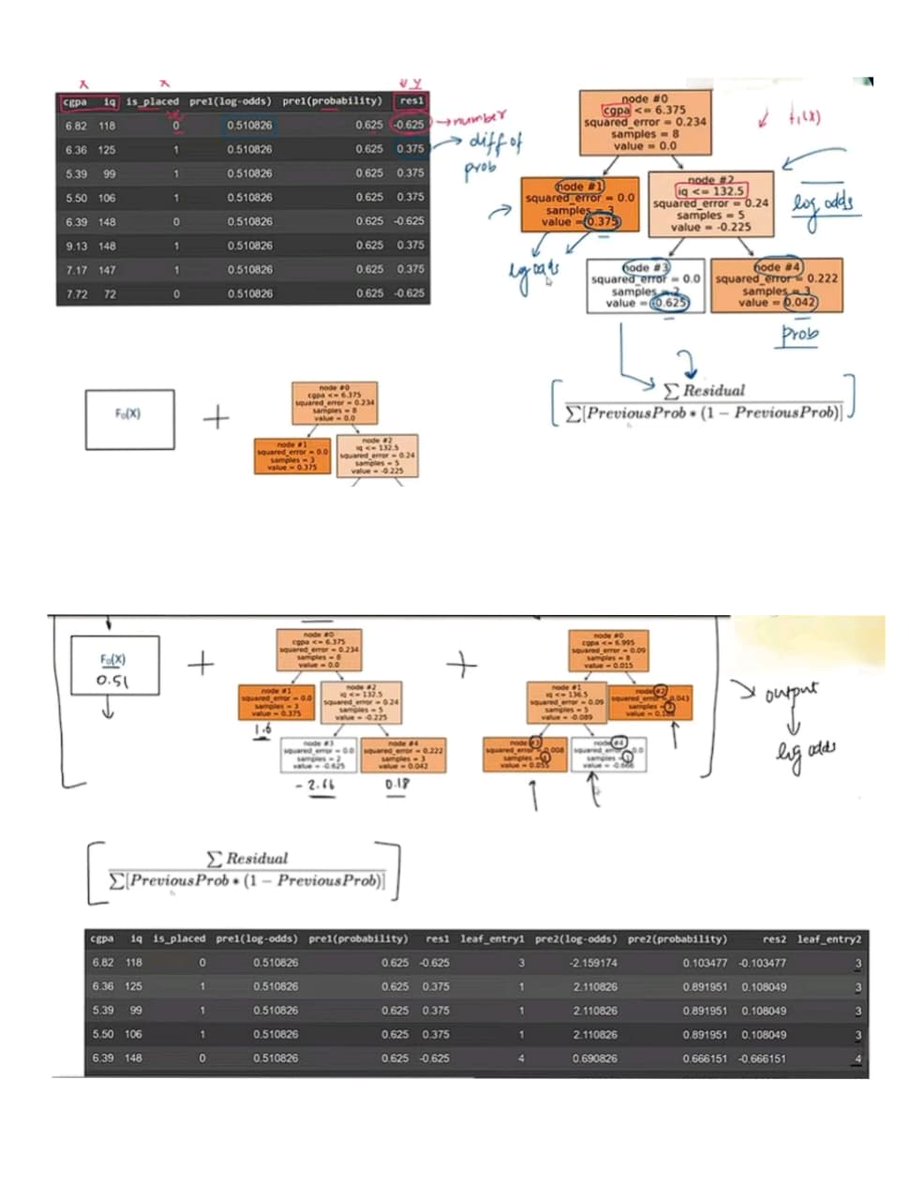
ALT calculation of residual and log of odds

ALT gradient boosting with uniform prediction on a probability of class 1 for all the data points.

ALT When all thatŌĆÖs left of me is a heartbeat and defiance, I still drag myself forward.
6
463

16 Oct 2025
¤ÜĆ Day 52 ŌĆō 100 Days of Machine Learning Journey
TodayŌĆÖs topic: How to Tune Hyperparameters in Gradient Boosting ŌÜÖ’ĖÅ
¤ōś Learn with @geeksforgeeks Nation SkillUp:
¤æēCourse: geeksforgeeks.org/batch/ds-1ŌĆ”
#100DaysOfML #MachineLearning #GradientBoosting #nationskillup #skillupwithgfg

2
61
15 Oct 2025
¤ōś Day 51 ŌĆō 100 Days of ML
TodayŌĆÖs concept: Boosting in Machine Learning ŌÜĪ
¤ōÜ Learn with @geeksforgeeks Nation SkillUp:
¤æēCourse: geeksforgeeks.org/batch/ds-1ŌĆ”
#100DaysOfML #MachineLearning #AdaBoost #GradientBoosting #nationskillup #skillupwithgfg

2
38

¤ż¢ XU100.IS AI TAHM─░N B├£LTEN─░ (v2.5)
¤ōŖ Sembol: XU100.IS
¤Æ░ G├╝ncel Fiyat: 11487.59
¤Ä» ANA TAHM─░N: ¤ōł YUKARI
Ō£© Olas─▒l─▒k (A─¤─▒rl─▒kl─▒): V.6
¤öź G├╝ven Seviyesi: .2
¤ż¢ Aktif Model Say─▒s─▒: 18
¤ōł Hedef: 11697.73 ( 1.83%)
¤øæ Stop: 11272.97 (-1.87%)
ŌÜ¢’ĖÅ Risk/Getiri: 1:0.98
¤¦Ā AKILLI ANAL─░Z:
ŌĆó Konsensus: ¤öź¤öź YUKARI (Skor: 79/100)
ŌĆó Model Uyumu: r
ŌĆó ├¢neri: Ō£ģ G├£├ćL├£ S─░NYAL
¤öÄ DER─░NLEMES─░NE ANAL─░Z:
ŌĆó Sinyal Tutarl─▒l─▒─¤─▒: Ō£ģ Y├╝ksek (G├╝├¦l├╝ model aileleri ayn─▒ y├Čnde)
ŌĆó Piyasa Volatilitesi: ŌÜĪ’ĖÅ Orta (ATR: 1.12%)
¤ÆĪ STRATEJ─░K YORUM:
AI, mevcut trendin devam etme potansiyelini ve al─▒m i┼¤tah─▒n─▒ pozitif olarak de─¤erlendiriyor.
Tahmini Destekleyen Fakt├Črler:
ŌĆó Fiyat, k─▒sa vadeli ortalaman─▒n (SMA20: 10948) ├╝zerinde kalmaya devam ediyor.
ŌĆó MACD momentumu pozitif b├Člgede g├╝c├╝n├╝ koruyor.
Dikkat Edilmesi Gereken Riskler:
ŌĆó En yak─▒n diren├¦ seviyesi olan 11520 b├Člgesi kar sat─▒┼¤lar─▒ i├¦in izlenmelidir.
ŌĆó RSI g├Čstergesinin a┼¤─▒r─▒ al─▒m b├Člgesinde olmas─▒, olas─▒ bir geri ├¦ekilme riskini art─▒rmaktad─▒r.
¤ö¼ Model Detaylar─▒:
Gradient Boosting:
ŌĆó CatBoost: ¤ōł p.9 ¤öź
ŌĆó GradientBoosting: ¤ōē F.2
ŌĆó LightGBM: ¤ōł c.6
ŌĆó XGBoost: ¤ōł ć.2 ¤öź
Di─¤er Modeller:
ŌĆó AdaBoost: ¤ōē @.8
ŌĆó DecisionTree: ¤ōł 0.0 ¤öź
ŌĆó Ensemble_Soft: ¤ōē 8.8
ŌĆó ExtraTrees: ¤ōł h.0
ŌĆó KNN: ¤ōł X.9
ŌĆó LogisticRegression: ¤ōē 7.6
ŌĆó NaiveBayes: ¤ōł Æ.8 ¤öź
ŌĆó NeuralNetwork_Large: ¤ōē .9 ¤öź
ŌĆó NeuralNetwork_Small: ¤ōē (.6 ¤öź
ŌĆó QDA: ¤ōł c.1
ŌĆó RandomForest: ¤ōł Y.3
ŌĆó Ridge: ¤ōē C.4
ŌĆó SVM_Linear: ¤ōł T.1
ŌĆó SVM_RBF: ¤ōł U.7
ŌÅ░ Analiz Zaman─▒: 25/08/2025 15:10
2
4
143
17,713
23 Aug 2025
Whether youŌĆÖre aiming to win Kaggle competitions, deploy robust models in production, or simply level up your ML toolkit, Mastering CatBoost will get you there.
#MachineLearning #DataScience #CatBoost #ML #AI #GradientBoosting #GBDT #Kaggle #Python #MLOps #TabularData #BookLaunch
5
567
¤ż¢ BIST100 AI TAHM─░N S─░STEM─░ (Geli┼¤mi┼¤)
¤ōŖ Sembol: BIST100 (XU100.IS)
¤Æ░ G├╝ncel Fiyat: 11372.33
¤Ä» ANA TAHM─░N: ¤ōł YUKARI
Ō£© Olas─▒l─▒k (A─¤─▒rl─▒kl─▒): a.2
¤öź G├╝ven Seviyesi: ".4
¤ż¢ Aktif Model Say─▒s─▒: 18
¤ōł Hedef: 11606.71 ( 2.06%)
¤øæ Stop: 11170.40 (-1.78%)
ŌÜ¢’ĖÅ Risk/Getiri: 1:1.16
¤¦Ā AKILLI ANAL─░Z:
ŌĆó Konsensus: ¤öź¤öź¤öź YUKARI (Skor: 83/100)
ŌĆó Model Uyumu: x
ŌĆó ├¢neri: Ō£ģ G├£├ćL├£ S─░NYAL
¤ö¼ Model Detaylar─▒:
Gradient Boosting:
ŌĆó CatBoost: ¤ōē C.9
ŌĆó GradientBoosting: ¤ōł S.7
ŌĆó LightGBM: ¤ōł é.7 ¤öź
ŌĆó XGBoost: ¤ōł ł.8 ¤öź
Di─¤er Modeller:
ŌĆó AdaBoost: ¤ōē I.5
ŌĆó DecisionTree: ¤ōł 0.0 ¤öź
ŌĆó Ensemble_Soft: ¤ōē @.9
ŌĆó ExtraTrees: ¤ōł r.1 ¤öź
ŌĆó KNN: ¤ōł a.1
ŌĆó LogisticRegression: ¤ōē B.7
ŌĆó NaiveBayes: ¤ōł ć.2 ¤öź
ŌĆó NeuralNetwork_Large: ¤ōē &.7 ¤öź
ŌĆó NeuralNetwork_Small: ¤ōē B.3
ŌĆó QDA: ¤ōł Ö.0 ¤öź
ŌĆó RandomForest: ¤ōł a.2
ŌĆó Ridge: ¤ōē F.4
ŌĆó SVM_Linear: ¤ōł T.4
ŌĆó SVM_RBF: ¤ōł V.7
ŌÅ░ Analiz Zaman─▒: 23/08/2025 00:02

3
6
211
16,977