
Exploring the performance of #GBDT under a #FSL schema in order to provide strong baselines: “Gradient Boosting Trees and #LargeLanguageModels for #TabularData Few-Shot Learning” by Carlos Huertas. ACSIS Vol. 41 p. 53–59; tinyurl.com/2h84f7fz
1
3
3
119

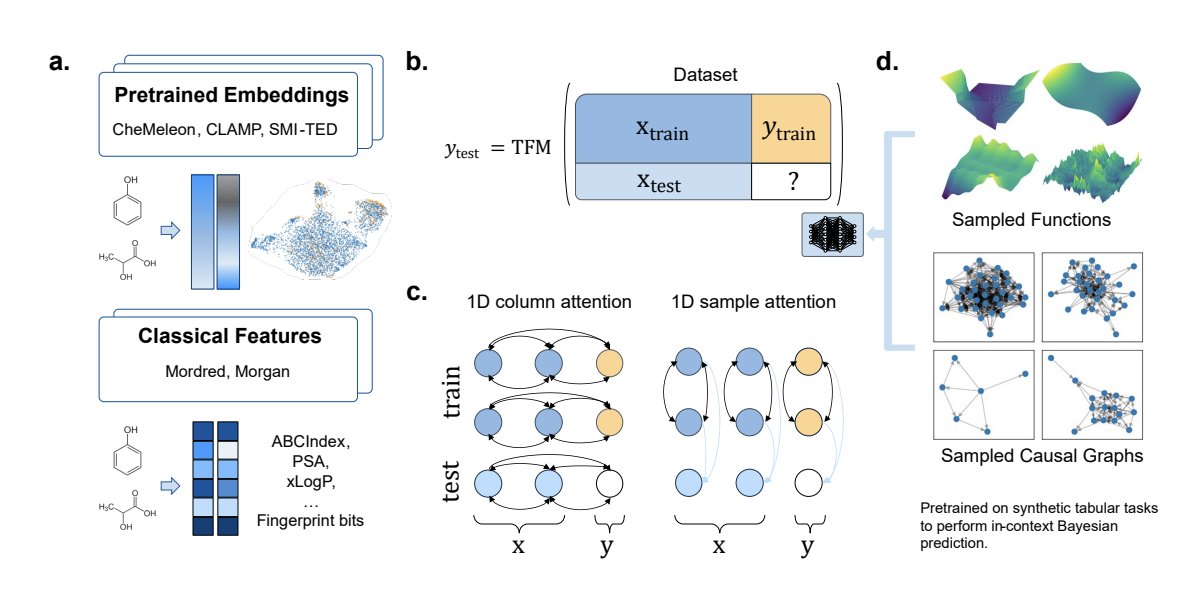
Tabular foundation models for in-context prediction of molecular properties
1. The paper evaluates a training-free workflow for molecular property prediction: compute fixed molecular features/embeddings, then use tabular foundation models (TFMs) for in-context learning (no task-specific fine-tuning).
2. Key result on public low-to-medium data benchmarks (58 tasks total from Polaris MoleculeACE): TabPFN frozen CheMeleon embeddings (TabPFN-CheMeleonFP) achieves 50/58 wins (86.2% win rate) with average rank 4.52, outperforming classical ML baselines and several fine-tuned deep molecular models under matched splits/metrics.
3. On the activity-cliff focused MoleculeACE suite (30 tasks), TabPFN-CheMeleonFP is best or statistically tied for best on all 30 tasks (100% win rate; average rank 2.10). This suggests TFMs can be particularly strong in difficult generalization regimes when paired with the right representation.
4. The study’s framing is notable: TFMs (TabPFN, TabICL) are pretrained only on synthetic tabular tasks (SCM/function-sampled), yet transfer effectively to chemistry once molecules are converted into tabular vectors (descriptors or frozen foundation-model embeddings).
5. Representation choice is a major driver of performance (contrary to some prior claims of representation invariance for TabPFN in drug discovery). CheMeleon embeddings and 2D descriptors (RDKit2d, Mordred) are consistently strong; Morgan fingerprints are substantially weaker across many tasks.
6. Descriptor-based alternatives remain competitive: TabPFN-RDKit2d and TabPFN-Mordred deliver strong aggregate results (e.g., 56.9% and 67.2% win rates respectively across the 58 tasks), offering practical options when foundation-model embeddings are unavailable or costly.
7. Compute efficiency is a central advantage: in a runtime case study vs fine-tuned CheMeleon, TabPFN-CheMeleonFP is faster on both CPU and GPU, with speedups up to 27× (CPU) and 46× (GPU), while also improving accuracy.
8. Beyond pharma benchmarks, the paper tests 11 chemical engineering datasets (fuels, polymer properties, polymer–solvent interactions). TFM pipelines (especially with Mordred or RDKit2d) match or exceed strong literature baselines on multiple targets, and remain competitive even when specialized models lead (e.g., PolySolv).
9. Limitations and open directions: scaling to larger datasets can become memory/disk constrained for high-dimensional features; most experiments are single-molecule (mixtures/multi-component systems may be harder); TFMs are single-task by design, motivating future in-context multitask TFMs and uncertainty-aware workflows (active learning/Bayesian optimization).
💻Code: git.rwth-aachen.de/avt-svt/p…
📜Paper: arxiv.org/abs/2604.16123
#ComputationalChemistry #Cheminformatics #MolecularML #FoundationModels #InContextLearning #TabPFN #TabularData #DrugDiscovery #ChemicalEngineering #MaterialsInformatics
1
9
1,464

On TALENT — an independent benchmark of 300 classification and regression tasks — TabH2O v1 outranked tuned CatBoost, and LightGBM across the board. With zero hyperparameter tuning.
Read the blog to learn more: h2o.ai/blog/2026/introducing…
#AI #MachineLearning #TabularData #FoundationModels
3
456

Tabular data is where the money 💰is.
✅Banks don’t run on poems.
✅Insurance doesn’t price with selfies.
✅Hospitals don’t triage with cat pictures.
They run on tables.
And yet the AI hype cycle spent years pretending “foundation models” = text images.
Meanwhile tabular ML was stuck in:
XGBoost worship leaderboard cosplay.
Until now.
A new species is here:
Tabular foundation models.
In-context learning for structured data.
TabPFN. TabICL. And the wave that follows.
But here’s the problem:
🚨 Most of the “wow SOTA” claims are made on sand.
Because:
❌ one split ≠ evaluation
❌ weak CV = free performance
❌ ensembling changes rankings
❌ leakage is everywhere
❌ “beats GBDTs” often means “beat a bad baseline”
So I’m writing the book I wish existed:
📘 Foundation Models for Tabular Data
In-Context Learning, Benchmarking, and Advanced ML
❌It’s not a tutorial.
✅ It’s a rigor upgrade.
You’ll learn:
✅ what is actually a “tabular foundation model” (and what’s marketing)
✅ when these models genuinely beat gradient boosting
✅ how to benchmark without fooling yourself
✅ calibration & reliability (the part that matters in risk)
✅ decision frameworks you can defend to a skeptical team lead
Early access preorder is live.
Price will climb past $100 as content lands.
Core:
👉 valeman.gumroad.com/l/tabula…
Pro 🔥:
👉 valeman.gumroad.com/l/tabula…
If you work with tabular data and you’re tired of leaderboard theatre — welcome.
#tabulardata #machinelearning #datascience

1
9
29
1,333
‼️🚨Tabular LLMs don’t “generalize” — they game the eval.
A new arXiv paper (2602.04031) re-checks the claims and the headline result collapses:
Compare to basic baselines and much of the gain vanishes.
“Wins” are driven by task formatting (quartile/binning) more than learning tabular structure.
A plain instruction-tuned model (no tabular training) gets ~90% of the reported classification performance. That’s template familiarity, not intelligence.
Contamination/leakage is a real risk, meaning some “generalization” can be memorization in disguise.
Call it what it is: benchmark theater.
If your tabular “foundation model” can’t reliably beat strong non-LLM baselines under, clean splits proper controls, it’s not a breakthrough — it’s a demo.
#MachineLearning
#TabularData
#ModelEvaluation

2
15
1,585
Production latency isn’t a “nice to have” – it’s a hard constraint.
That’s where CatBoost’s symmetric (oblivious) trees quietly change the game.
Because every level of a CatBoost tree uses the same split, you get:
* Perfectly balanced trees
* Very small, cache-friendly models
* Branchless, vectorized, highly parallelizable inference
In practice, this means CatBoost models are often 2–15× faster at inference than equivalent irregular trees. When you’re serving tens of thousands of predictions per second, that’s not just a benchmark detail – it’s the difference between:
* Needing 20 servers vs 5
* Hitting your p95 latency SLO vs constantly firefighting
* Being able to ship a more complex model without blowing up infra costs
So if you’re in a setting where every millisecond matters — ads, search ranking, real-time pricing, fraud detection, large-scale recommendations — CatBoost isn’t just “another GBDT."
It’s a latency-optimized, production-friendly workhorse that lets you keep accuracy and speed instead of trading one for the other.
'Mastering CatBoost' -> valeman.gumroad.com/l/Master…
#catboost #datascience #tabulardata

2
599
🚀 New Chapter Released in Mastering CatBoost 🔥🔥🔥
A new chapter just dropped in Mastering CatBoost: The Hidden Gem of Tabular AI — and this one is a major milestone for the book.
This chapter opens CatBoost as a system, not just a library or a collection of tricks. If you’ve ever felt that CatBoost “behaves differently” from XGBoost or LightGBM but couldn’t quite articulate why — this chapter finally explains it.
What this new chapter delivers (and why it’s different)
This is not documentation and not a rehash of the original papers. It connects theory, engineering, and hardware in one coherent pipeline.
You’ll learn:
• The No-Peeking Contract
How CatBoost enforces leakage-free learning by design — and how this single rule shapes data storage, statistics, training loops, and memory layout.
• The Two-Brain Architecture
Why CatBoost is best understood as:
– a Statistics Engine (permutation-aware, ordered, unbiased)
– a Tree / Hardware Engine (symmetric trees, SIMD-friendly, branchless inference)
• Permutation Machinery Done Right
How ordered target statistics and ordered gradients are implemented without training N models, using sliding prefixes and supporting models.
• Why Symmetric (Oblivious) Trees Pay Twice
One structural choice gives:
– built-in regularization on noisy / categorical data
– extreme inference speed via bitwise scoring
• Inference as Bitwise Computation
How CatBoost turns tree evaluation into comparisons → bits → leaf index, enabling production-grade throughput.
• Architecture → Parameters Mapping
Parameters finally make sense once you see which subsystem they actually control.
This chapter explains why CatBoost “just works” on real-world tabular data — not by magic, but by architecture.
📘 Get the book
Standard edition:
👉 valeman.gumroad.com/l/Master…
Pro edition (early access, updates, deeper material):
👉 valeman.gumroad.com/l/Master…
If you work seriously with tabular data, this new chapter alone is worth it.
#catboost #machinelearning #tabulardata

1
3
716
🚀 New Chapter Released in Mastering CatBoost 🔥🔥🔥
A new chapter just dropped in Mastering CatBoost: The Hidden Gem of Tabular AI — and this one is a major milestone for the book.
This chapter opens CatBoost as a system, not just a library or a collection of tricks. If you’ve ever felt that CatBoost “behaves differently” from XGBoost or LightGBM but couldn’t quite articulate why — this chapter finally explains it.
What this new chapter delivers (and why it’s different)
This is not documentation and not a rehash of the original papers. It connects theory, engineering, and hardware in one coherent pipeline.
You’ll learn:
• The No-Peeking Contract
How CatBoost enforces leakage-free learning by design — and how this single rule shapes data storage, statistics, training loops, and memory layout.
• The Two-Brain Architecture
Why CatBoost is best understood as:
– a Statistics Engine (permutation-aware, ordered, unbiased)
– a Tree / Hardware Engine (symmetric trees, SIMD-friendly, branchless inference)
• Permutation Machinery Done Right
How ordered target statistics and ordered gradients are implemented without training N models, using sliding prefixes and supporting models.
• Why Symmetric (Oblivious) Trees Pay Twice
One structural choice gives:
– built-in regularization on noisy / categorical data
– extreme inference speed via bitwise scoring
• Inference as Bitwise Computation
How CatBoost turns tree evaluation into comparisons → bits → leaf index, enabling production-grade throughput.
• Architecture → Parameters Mapping
Parameters finally make sense once you see which subsystem they actually control.
This chapter explains why CatBoost “just works” on real-world tabular data — not by magic, but by architecture.
📘 Get the book
Standard edition:
👉 valeman.gumroad.com/l/Master…
Pro edition (early access, updates, deeper material):
👉 valeman.gumroad.com/l/Master…
If you work seriously with tabular data, this new chapter alone is worth it.
#catboost #machinelearning #tabulardata

4
584
Production latency isn’t a “nice to have” – it’s a hard constraint.
That’s where CatBoost’s symmetric (oblivious) trees quietly change the game.
Because every level of a CatBoost tree uses the same split, you get:
* Perfectly balanced trees
* Very small, cache-friendly models
* Branchless, vectorized, highly parallelizable inference
In practice, this means CatBoost models are often 2–15× faster at inference than equivalent irregular trees. When you’re serving tens of thousands of predictions per second, that’s not just a benchmark detail – it’s the difference between:
* Needing 20 servers vs 5
* Hitting your p95 latency SLO vs constantly firefighting
* Being able to ship a more complex model without blowing up infra costs
So if you’re in a setting where every millisecond matters — ads, search ranking, real-time pricing, fraud detection, large-scale recommendations — CatBoost isn’t just “another GBDT."
It’s a latency-optimized, production-friendly workhorse that lets you keep accuracy and speed instead of trading one for the other.
'Mastering CatBoost' -> valeman.gumroad.com/l/Master…
#catboost #datascience #tabulardata

1
4
721
🚀 New Chapter Released in Mastering CatBoost 🔥🔥🔥
A new chapter just dropped in Mastering CatBoost: The Hidden Gem of Tabular AI — and this one is a major milestone for the book.
This chapter opens CatBoost as a system, not just a library or a collection of tricks. If you’ve ever felt that CatBoost “behaves differently” from XGBoost or LightGBM but couldn’t quite articulate why — this chapter finally explains it.
What this new chapter delivers (and why it’s different)
This is not documentation and not a rehash of the original papers. It connects theory, engineering, and hardware in one coherent pipeline.
You’ll learn:
• The No-Peeking Contract
How CatBoost enforces leakage-free learning by design — and how this single rule shapes data storage, statistics, training loops, and memory layout.
• The Two-Brain Architecture
Why CatBoost is best understood as:
– a Statistics Engine (permutation-aware, ordered, unbiased)
– a Tree / Hardware Engine (symmetric trees, SIMD-friendly, branchless inference)
• Permutation Machinery Done Right
How ordered target statistics and ordered gradients are implemented without training N models, using sliding prefixes and supporting models.
• Why Symmetric (Oblivious) Trees Pay Twice
One structural choice gives:
– built-in regularization on noisy / categorical data
– extreme inference speed via bitwise scoring
• Inference as Bitwise Computation
How CatBoost turns tree evaluation into comparisons → bits → leaf index, enabling production-grade throughput.
• Architecture → Parameters Mapping
Parameters finally make sense once you see which subsystem they actually control.
This chapter explains why CatBoost “just works” on real-world tabular data — not by magic, but by architecture.
📘 Get the book
Standard edition:
👉 valeman.gumroad.com/l/Master…
Pro edition (early access, updates, deeper material):
👉 valeman.gumroad.com/l/Master…
If you work seriously with tabular data, this new chapter alone is worth it.
#catboost #machinelearning #tabulardata

1
12
980
🚀 New Chapter Released in Mastering CatBoost 🔥🔥🔥
A new chapter just dropped in Mastering CatBoost: The Hidden Gem of Tabular AI — and this one is a major milestone for the book.
This chapter opens CatBoost as a system, not just a library or a collection of tricks. If you’ve ever felt that CatBoost “behaves differently” from XGBoost or LightGBM but couldn’t quite articulate why — this chapter finally explains it.
What this new chapter delivers (and why it’s different)
This is not documentation and not a rehash of the original papers. It connects theory, engineering, and hardware in one coherent pipeline.
You’ll learn:
• The No-Peeking Contract
How CatBoost enforces leakage-free learning by design — and how this single rule shapes data storage, statistics, training loops, and memory layout.
• The Two-Brain Architecture
Why CatBoost is best understood as:
– a Statistics Engine (permutation-aware, ordered, unbiased)
– a Tree / Hardware Engine (symmetric trees, SIMD-friendly, branchless inference)
• Permutation Machinery Done Right
How ordered target statistics and ordered gradients are implemented without training N models, using sliding prefixes and supporting models.
• Why Symmetric (Oblivious) Trees Pay Twice
One structural choice gives:
– built-in regularization on noisy / categorical data
– extreme inference speed via bitwise scoring
• Inference as Bitwise Computation
How CatBoost turns tree evaluation into comparisons → bits → leaf index, enabling production-grade throughput.
• Architecture → Parameters Mapping
Parameters finally make sense once you see which subsystem they actually control.
This chapter explains why CatBoost “just works” on real-world tabular data — not by magic, but by architecture.
📘 Get the book
Standard edition:
👉 valeman.gumroad.com/l/Master…
Pro edition (early access, updates, deeper material):
👉 valeman.gumroad.com/l/Master…
If you work seriously with tabular data, this new chapter alone is worth it.
#catboost #machinelearning #tabulardata

6
767

Jan 13
This is a special moment for us at @prior_labs.
I’ve followed @ylecun’s work since the start of my career. His relentless focus on "what’s next" in AI has always been an inspiration. Today, I’m proud to say that he is joining us as a scientific advisor to help build the future of Tabular Foundation Models.
Yann understands that while LLMs have captured the world's attention, they have severe limitations. The vast majority of the world's data is tabular and LLMs are terrible with statistics and numbers. Our model, #TabPFN, fills this void, and the progress we are seeing is exponential.
A warm welcome to the team, Yann. It’s an honor to work with you alongside @bschoelkopf, Madelon Hulsebos, and @SamuelMullr on this powerhouse board. #DeepLearning #DataScience #TabularData #AI
Jan 13

Honored to announce that Yann LeCun @ylecun is joining Prior Labs’ Scientific Advisory Board.

10
16
221
20,250
🚀 New Chapter Released in Mastering CatBoost 🔥🔥🔥
A new chapter just dropped in Mastering CatBoost: The Hidden Gem of Tabular AI — and this one is a major milestone for the book.
This chapter opens CatBoost as a system, not just a library or a collection of tricks. If you’ve ever felt that CatBoost “behaves differently” from XGBoost or LightGBM but couldn’t quite articulate why — this chapter finally explains it.
What this new chapter delivers (and why it’s different)
This is not documentation and not a rehash of the original papers. It connects theory, engineering, and hardware in one coherent pipeline.
You’ll learn:
• The No-Peeking Contract
How CatBoost enforces leakage-free learning by design — and how this single rule shapes data storage, statistics, training loops, and memory layout.
• The Two-Brain Architecture
Why CatBoost is best understood as:
– a Statistics Engine (permutation-aware, ordered, unbiased)
– a Tree / Hardware Engine (symmetric trees, SIMD-friendly, branchless inference)
• Permutation Machinery Done Right
How ordered target statistics and ordered gradients are implemented without training N models, using sliding prefixes and supporting models.
• Why Symmetric (Oblivious) Trees Pay Twice
One structural choice gives:
– built-in regularization on noisy / categorical data
– extreme inference speed via bitwise scoring
• Inference as Bitwise Computation
How CatBoost turns tree evaluation into comparisons → bits → leaf index, enabling production-grade throughput.
• Architecture → Parameters Mapping
Parameters finally make sense once you see which subsystem they actually control.
This chapter explains why CatBoost “just works” on real-world tabular data — not by magic, but by architecture.
📘 Get the book
Standard edition:
👉 valeman.gumroad.com/l/Master…
Pro edition (early access, updates, deeper material):
👉 valeman.gumroad.com/l/Master…
If you work seriously with tabular data, this new chapter alone is worth it.
#catboost #machinelearning #tabulardata

2
12
922
🚀 New Chapter Released in Mastering CatBoost 🔥🔥🔥
A new chapter just dropped in Mastering CatBoost: The Hidden Gem of Tabular AI — and this one is a major milestone for the book.
This chapter opens CatBoost as a system, not just a library or a collection of tricks. If you’ve ever felt that CatBoost “behaves differently” from XGBoost or LightGBM but couldn’t quite articulate why — this chapter finally explains it.
What this new chapter delivers (and why it’s different)
This is not documentation and not a rehash of the original papers. It connects theory, engineering, and hardware in one coherent pipeline.
You’ll learn:
• The No-Peeking Contract
How CatBoost enforces leakage-free learning by design — and how this single rule shapes data storage, statistics, training loops, and memory layout.
• The Two-Brain Architecture
Why CatBoost is best understood as:
– a Statistics Engine (permutation-aware, ordered, unbiased)
– a Tree / Hardware Engine (symmetric trees, SIMD-friendly, branchless inference)
• Permutation Machinery Done Right
How ordered target statistics and ordered gradients are implemented without training N models, using sliding prefixes and supporting models.
• Why Symmetric (Oblivious) Trees Pay Twice
One structural choice gives:
– built-in regularization on noisy / categorical data
– extreme inference speed via bitwise scoring
• Inference as Bitwise Computation
How CatBoost turns tree evaluation into comparisons → bits → leaf index, enabling production-grade throughput.
• Architecture → Parameters Mapping
Parameters finally make sense once you see which subsystem they actually control.
This chapter explains why CatBoost “just works” on real-world tabular data — not by magic, but by architecture.
📘 Get the book
Standard edition:
👉 valeman.gumroad.com/l/Master…
Pro edition (early access, updates, deeper material):
👉 valeman.gumroad.com/l/Master…
If you work seriously with tabular data, this new chapter alone is worth it.
#catboost #machinelearning #tabulardata

1
3
779
The Era of "Manual" Gradient Boosting is Over.
Remember when we used to manually initialize weights in neural networks? That’s what manual categorical encoding looks like in 2026.
For years, XGBoost was the naked "king" of Kaggle.
But as datasets grew more complex and categorical-heavy (e-commerce, finance, fraud), the "old guard" of GBDTs started showing their age.
They require extensive preprocessing pipelines to handle what modern architectures handle natively.
The Reality Check:
XGBoost: Requires you to decide how to handle high-cardinality features.
CatBoost: Handles them automatically using Ordered Boosting—transforming distinct values into statistical signals without overfitting.
If your training script is 60% preprocessing and 40% modeling, you are using the wrong tool.
Upgrade your stack.
valeman.gumroad.com/l/Master…
valeman.gumroad.com/l/Master…
#AI #MachineLearning #TabularData #TechDebt #CatBoost
1
8
913

22 Dec 2025
Production latency isn’t a “nice to have” – it’s a hard constraint.
That’s where CatBoost’s symmetric (oblivious) trees quietly change the game.
Because every level of a CatBoost tree uses the same split, you get:
* Perfectly balanced trees
* Very small, cache-friendly models
* Branchless, vectorized, highly parallelizable inference
In practice, this means CatBoost models are often 2–15× faster at inference than equivalent irregular trees. When you’re serving tens of thousands of predictions per second, that’s not just a benchmark detail – it’s the difference between:
* Needing 20 servers vs 5
* Hitting your p95 latency SLO vs constantly firefighting
* Being able to ship a more complex model without blowing up infra costs
So if you’re in a setting where every millisecond matters — ads, search ranking, real-time pricing, fraud detection, large-scale recommendations — CatBoost isn’t just “another GBDT."
It’s a latency-optimized, production-friendly workhorse that lets you keep accuracy and speed instead of trading one for the other.
'Mastering CatBoost' -> valeman.gumroad.com/l/Master…
#catboost #datascience #tabulardata

2
4
12
1,812

16 Dec 2025
AI agent Ana wants to speak complex data with natural language @datanews_nl bit.ly/4rRnUyM @TextQL
#MultiCloud #AI #Agent #MCP #SQL #Automation #DataIntegration #TabularData #ITPT @ITPressTour 64th Edition in New York

2
28
8 Dec 2025
Production latency isn’t a “nice to have” – it’s a hard constraint.
That’s where CatBoost’s symmetric (oblivious) trees quietly change the game.
Because every level of a CatBoost tree uses the same split, you get:
* Perfectly balanced trees
* Very small, cache-friendly models
* Branchless, vectorized, highly parallelizable inference
In practice, this means CatBoost models are often 2–15× faster at inference than equivalent irregular trees. When you’re serving tens of thousands of predictions per second, that’s not just a benchmark detail – it’s the difference between:
* Needing 20 servers vs 5
* Hitting your p95 latency SLO vs constantly firefighting
* Being able to ship a more complex model without blowing up infra costs
So if you’re in a setting where every millisecond matters — ads, search ranking, real-time pricing, fraud detection, large-scale recommendations — CatBoost isn’t just “another GBDT."
It’s a latency-optimized, production-friendly workhorse that lets you keep accuracy and speed instead of trading one for the other.
'Mastering CatBoost' -> valeman.gumroad.com/l/Master…
#catboost #datascience #tabulardata

8
1,151

2 Dec 2025
🚀 Heading to #NeurIPS 2025 in San Diego!
Proud to present two posters with my students:
• SUMO — “Subspace-Aware Moment-Orthogonalization” — a new optimizer that speeds up convergence, cuts memory demands, and boosts performance. Catch us on Wednesday, Exhibit Hall C,D,E #910, 11:00–14:00 PST. 📈 arXiv: arxiv.org/abs/2505.24749
• TANDEM — “Hybrid Autoencoders for Tabular Data” — a model-based augmentation scheme that combines decision-tree and neural encoders to push the boundaries of NNs in low-label settings. See us on Friday, Exhibit Hall C,D,E #3416, 11:00–14:00 PST. 🚀 NeurIPS page: neurips.cc/virtual/2025/post…
If you’re into tabular data, efficient fine-tuning, or anything close to my line of research, come say hi and chat! 🙌
#machinelearning #tabulardata #LLMs #selfsupervised #NeurIPS25
11
538