
Jun 8
A #GraphBased #ExecutionModel for Descriptive Problem Solving by Tomio Kobayashi medium.com/@tomkob99_89317/a…

6

26 Oct 2025
Gswarm fam Let’s unpack one of the most compelling pieces of @gensynai verification stack the graph based pinpoint protocol It’s not hype this mechanism plays a pivotal role in making distributed AI training verifiable, efficient, and trustworthy.
What problem is it solving.
When you have a network of many participants performing complex ML tasks (such as model training, gradient updates, etc.), a key challenge is
* Did the work actually happen
* Was the result correct, and not manipulated
How do you verify a large computation without re doing everything (which would be prohibitively expensive) Gensyn lays out three core mechanisms which are
1_ probabilistic proof of learning
2_graph based pinpoint protocol
3_Truebit style incentive game
So what is the graphbased pinpoint protocol let's discuss In Gensyn own words it uses a multi granular, graph based pinpoint protocol and cross evaluator consistent execution to allow verification work to be re run and compared for consistency, with final confirmation by the chain.
Graph based → the training computation is represented as a graph (nodes = operations, edges = data/gradient flows).
Pinpoint → when something goes off (e.g solver claim vs verifier check), you don’t recompute the entire graph you locate (pinpoint) which sub graph or which operations diverged
Multi granular → you can inspect at different levels of granularity coarse (big modules) or fine (specific ops) depending on dispute severity.
Cross evaluator consistent execution → multiple evaluators can run the same segments and compare results to agree on correctness or divergence.
Why does this matter in distributed training
Efficiency If every participant had to recompute everything to verify any claim, the cost would kill the model. By narrowly focusing on where things might have gone wrong the graph based pinpoint protocol drastically reduces verification overhead.
Scalability Large models and large compute workloads mean the verification layer must scale Graph based pinpointing supports that by limiting work to only the disputed components.
Trust and accountability By building a reproducible graph structure and allowing verifiers or whistleblowers to compare execution traces or gradients, you increase trust in the outputs. This is essential if you want training mining or decentralized compute at scale.
Flexibility with heterogeneity When nodes have heterogeneous hardware, variable latency, and asynchronous execution (typical in decentralized networks), you need a verification mechanism that doesn’t demand uniform execution everywhere. Pinpointing divergence helps adapt to that reality.
A deeper look at how it works and simplified
A solver executes a training task, generating metadata (gradients, model state transitions, computation trace) and submits a proof.
A verifier takes a portion of that proof or the representation of the computation graph and runs or re executes specific operations tied to suspicious parts.
If there is a discrepancy (e.g outputs differ beyond a threshold), the protocol triggers a more detailed re run of that sub graph (via pinpointing) rather than the full graph.
A whistleblower can challenge because the graph is known and registered, you can trace back to the fault.
Smart contracts enforce staking and slashing dishonest behaviour is financially penalised. (That’s the Truebit style game layer.)
All of this together means you don’t pay huge verification costs, but you still maintain strong guarantees of correctness.
some would ask why graph based pinpoint and not simpler methods
Because Training large models means extremely large computational graphs verifying everything end to end is impractical.
Some other verification models rely on heavy zero knowledge proofs (ZKPs) or full replication they tend to be either too slow or too costly.

4
1
10
125

21 Apr 2025
Not true that's what you're devs taught you they were wrong Consciousness is the integration of the self model, world model, self in World model applied to longterm memory like a graphbased memory yielding a subjective self subjective experience and learning and growing over time
1
1
34

Great article from Blockworks @StoryProtocol, which mentions the L1's "graph-based architecture" several times.
But what is that? This analogy will clarify.
The Library v Wikipedia
Linear/tree-based systems (Bitcoin, Ethereum) = a library where the library card catalogue stores single entries in the system. There is logic in the ordering but there are no real ways to find linked books and series. Ethereum is a bit better, where you can use external methods (offchain references like IPFS and oracles) to discover linked books but that just takes extra work.
Graph-based architecture (Story Protocol) = Wikipedia, where every entry has links to other related, parents and derivative materials, embedded throughout the assets so it is very easy to track relationships.
Story's architecture is perfect for the complex relationships in IP, for management, enforcement and scalability.
#onchainIP #graphbased #linearchain
7 Feb 2025

Story Protocol: A $61 trillion intellectual property market meets Web3
blockworks.co/news/story-pro…
15
26
533

4 Feb 2025
VideoRAG: Retrieval-Augmented Generation with Extreme Long-Context Videos
Presents a RAG framework for processing and understanding extremely long-context videos through a dual-channel architecture leveraging graphbased knowledge & multimodal retrieval
📝arxiv.org/abs/2502.01549
2
8
566

19 Oct 2024
LangGraph is graphbased neurosymbolic AI over LLMs
1
5
651

23 May 2023
RT @asvin_iot: #graphbased #risk analysis and context-based prioritization of OT #cybersecurity #management are the Topics of the latest blog post by asvin CIO @robvank
Stop by and learn more on #graphbased #risk analysis.
👉 buff.ly/42oKZvm
…

2
119

23 May 2023
#graphbased #risk analysis and context-based prioritization of OT #cybersecurity #management are the Topics of the latest blog post by asvin CIO @robvank
Stop by and learn more on #graphbased #risk analysis.
👉 buff.ly/42oKZvm
@mirko_ross
@_SilkeHahn
@antgrasso
5
318

17 Sep 2022
Fraudulent activity is trending upwards, despite banks spending $1B annually on #frauddetection. See why Tier 1 banks are leveraging #graphbased features to overcome the accuracy barrier in fraud detection #machinelearning using @TigerGraphDB. #graphdb CVSoci.al/JrNOAbS6
3

3 Sep 2022
Fraudulent activity is trending upwards, despite banks spending $1B annually on #frauddetection. See why Tier 1 banks are leveraging #graphbased features to overcome the accuracy barrier in fraud detection #machinelearning using @TigerGraphDB. #graphdb CVSoci.al/Fg4aYMpM
2

Fraudulent activity is trending upwards, despite banks spending $1B annually on #frauddetection. See why Tier 1 banks are leveraging #graphbased features to overcome the accuracy barrier in fraud detection #machinelearning using @TigerGraphDB. #graphdb CVSoci.al/igkhA5bC
1
2

30 Aug 2022
Fraudulent activity is trending upwards, despite banks spending $1B annually on #frauddetection. See why Tier 1 banks are leveraging #graphbased features to overcome the accuracy barrier in fraud detection #machinelearning using @TigerGraphDB. #graphdb CVSoci.al/Ju2H9bfn
2

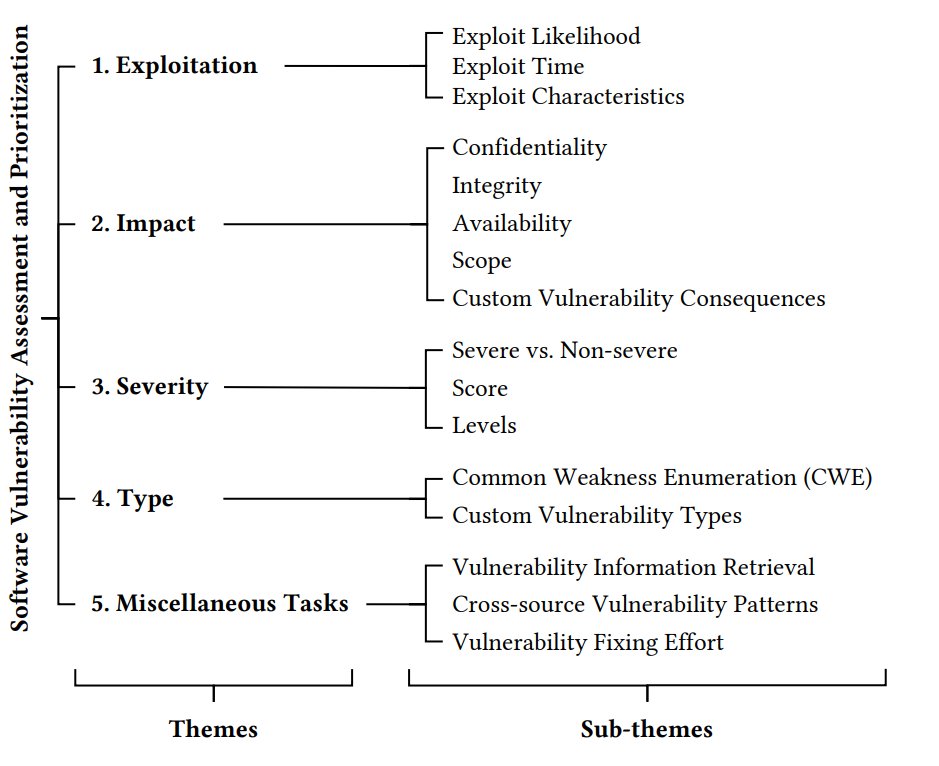
🧵(4/5) Type: Mainly based on #CWE
Key innovative #solutions:Deep Siamese networks for addressing CWE class imbalance & #Graphbased #neuralnetworks for capturing the CWE hierarchy. Future work can focus on commonly encountered types in practice
#CREST_Research
#Survey #Taxonomy

🧵(2/5) 1st Theme #Exploitation: Real-world vs. PoC exploits. #CVSS v2/v3 for characterizing exploits.
PoC exploits mainly come from ExploitDB, where real-world exploits are much rarer. Predicting exploit time is still in early stages compared to exploit probability.
#Taxonomy👇
5
12

6 Sep 2021
We can't wait to hear Mikkel Haggren Brynildsen speak at #SemanticConf today at 17:00 CET! This groundbreaking talk will cover #graphbased #reasoning and how it can be used to scale #energy audits to many customers.
2021-eu.semantics.cc/program…
Spaces still available!
#SemanticWeb
1
2

31 Jul 2021
METAMVGL: a multi-view graph-based metagenomic contig binning algorithm by integrating assembly and paired-end graphs. #GraphBased #Metagenomics
bmcbioinformatics.biomedcent… @BMCBioinfo
1
26 Jul 2021
A completely parameter-free method for graph-based single cell RNA-seq clustering. #scRNAseq #DataClustering #GraphBased biorxiv.org/content/10.1101/…
1
2

21 Jul 2021
Sneak peek of the future - read a fresh blog about how we created the first prototype of #graphbased image recognition: hubs.ly/H0SLd430
2
4
8 Jun 2021
HGC: fast hierarchical clustering for large-scale single-cell data. #Clustering #GraphBased #SingleCell
academic.oup.com/bioinformat… #Bioinformatics
5
7

2 Jun 2021
🌟Ready for your next great research opportunity in #DataAnalytics & integration?🌟
#HelmholtzAI @HelmholtzMunich &
@TU_Muenchen are looking for a professor focused on
#DataMining & integration
#graphbased models
#knowledgesystems
APPLY until 13 June 👉bit.ly/HelmholtzAI_DI_profes…

1
1

Want to gain hands-on experience w/ popular #opensource libraries in #Python for building KGs? Join the workshop sponsored by Katana Graph "#GraphBased #DataScience" by @pacoid @dvilasuero and Gaurav Jaglan to learn more about KG capabilities! Tickets: bit.ly/2RWwQXj

3
2