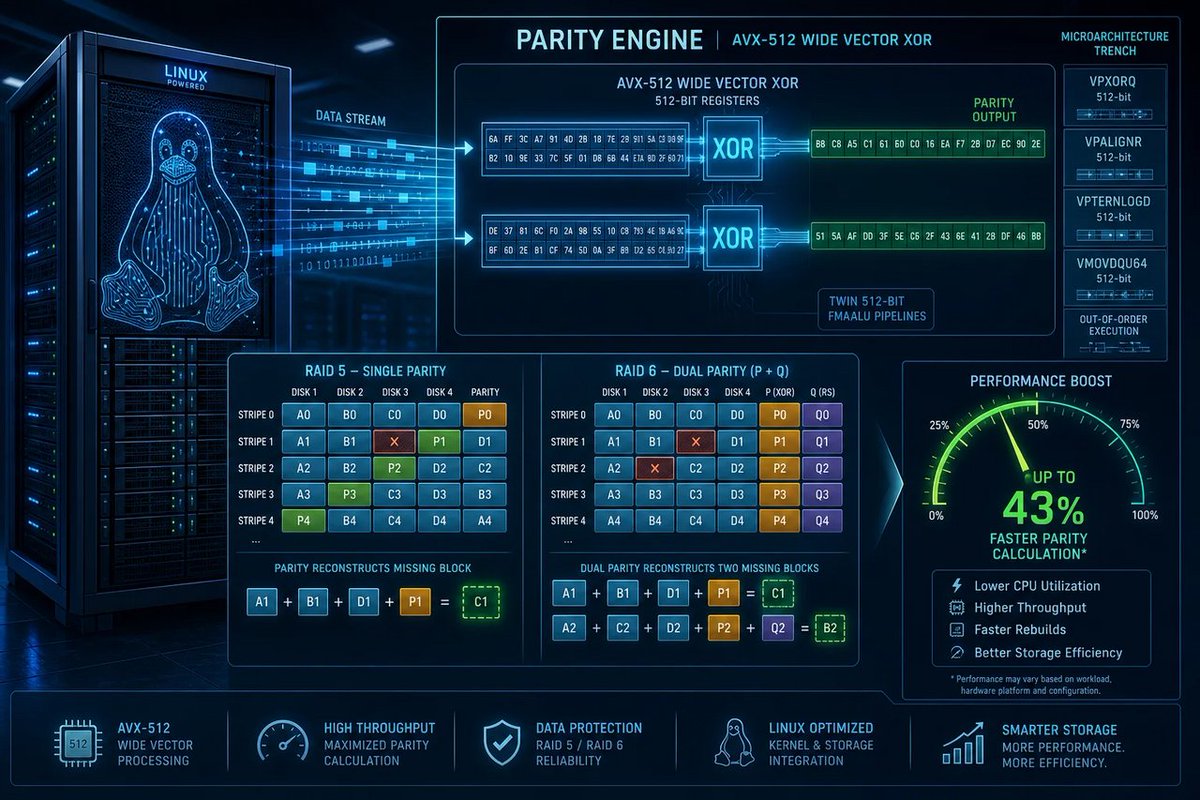
🪟 RAID parity getting 43% thanks to an AVX-512 xor_gen patch = Linux squeezing juice from CPUs like it’s going out of style. Meanwhile Windows users: “why so slow?” #Windows #Microsoft #Linux #Kernel #RAID
windowsforum.com/threads/lin…
#LinuxKernel #SoftwareRaid #StoragePerformance
8

Linux Kernel releases as of Week 24, June 13th, 2026.
#Linux #Kernel #LinuxKernel #Computers #Laptops #TechNews #TechUpdates officialaptivi.wordpress.com…
6

CVE-2024-1065 is a physical-page use-after-free in the ARM Mali GPU kernel driver. Because the freed page lands in MIGRATE_MOVABLE, Dirty Pagetable and Dirty Cred do not apply — so this writeup uses a page-cache spray to swap the freed page into the in-memory copy of /usr/bin/passwd and gets root via execve() without touching disk.
core-jmp.org/2026/06/cve-202…
#ARMMaliGPU #ARM64 #CVE20241065 #DirtyPagetable #kernel #KernelExploit #KernelExploitation #KernelShellcode #KernelUAF #LinuxKernel #LinuxKernelExploitation #LocalPrivilegeEscalation #MaliExploitation #MIGRATE_MOVABLE #PageCacheCorruption #PageCacheExploitation #PhysicalPageUAF #PrivilegeEscalation #ProjectZero #shellcode #SUIDExploitation #UseAfterFree

2
120

Ummm ...interesting plotting on Linux kernel mail client timeline ...
cc:Konstantin Ryabitsev @monsieuricon
#linuxadmin #linuxkernel #opensource #operatingsystem
social.kernel.org/notice/B7A…

15

11

We made co-located TCP up to 7x faster by adding a copy, not removing one.
That sentence should bother you. Every performance engineer is trained to drive copies toward zero. So when we built bpf_sock_splice_pair(), a new BPF kfunc that splices two TCP sockets on the same machine (think service-mesh sidecars, loopback RPC, co-scheduled microservices), our first design did exactly that: a single direct user-to-user copy, the theoretical minimum for an unmodified sockets API.
It was elegant. It was also the wrong tradeoff.
A single copy forces the sender to write straight into the receiver's buffer, which means both sides have to meet at the same instant. That synchronous rendezvous quietly kills batching. The sender can never run ahead, so throughput is capped by handshake latency instead of memory bandwidth.
The fix is a lesson queueing theory has taught for decades: to let a producer outrun a consumer, you need a buffer between them. A buffer costs a second copy, and that second copy is the price of decoupling. Decoupling enables batching, batching amortizes per-message overhead, and owning an in-kernel ring lets the receiver busy-poll, the one thing that finally cracks loopback latency.
The result, measured with netperf at a realistic 1 KB request-response:
- Loopback TCP_RR: 106k to 713k transactions/sec (6.7x)
- Container TCP_RR: 100k to 705k transactions/sec (7.0x)
- No application changes. No new address family. Just BPF pairing ordinary TCP sockets.
We also benchmarked it against AF_SMC's shared-memory loopback, which independently arrived at the same "buffering enables batching" conclusion. Our two-copy ring still comes out ahead of its three-copy path.
The full design story, the dead end we walked into first, and a comparison with AF_SMC:
multikernel.io/2026/06/11/bp…
The patchset is up as an RFC on the BPF and netdev lists. Reviews and benchmarks welcome.
#LinuxKernel #eBPF #Networking #Performance #TCP #SystemsEngineering #OpenSource
1
5
437

Jun 12
CISA KEV 警告 26/06/02:Linux Kernel の脆弱性 CVE-2022-0492 を登録
iototsecnews.jp/2026/06/05/c…
Linux カーネルの脆弱性 CVE-2022-0492 が、CISA の KEV カタログに登録されました。この問題の原因は、リソースを管理する cgroups v1 という仕組みの中で、認証や認可のチェックが不十分だったことにあります。この確認の不備を突く攻撃者は、release_agent という機能を悪用することで、本来は制限されているはずのコンテナの壁を越えて、ホストシステムの root 権限を奪う可能性を得ます。ご利用のチームは、ご注意ください。
#CISA #CVE20220492 #Exploit #KEV #LinuxKernel #Vulnerability
1
123
Alright, my computer and I quite often disagree, and the damn thing wins sometimes.
That annoys me like hell. How come that beast is getting over me???
Skill issue.....you see!! 😜
#linuxadmin #linuxkernel #opensource #operatingsystem
12

Jun 11
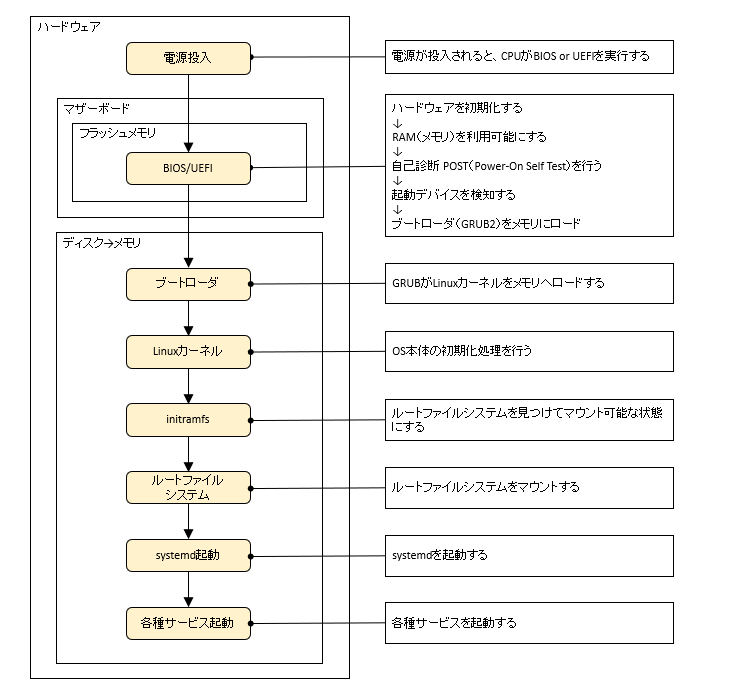
Linuxの起動シーケンスについて図解しています。
さらに、
UEFI → GRUB → Linuxカーネル → initramfs → systemd の流れを、実際の起動ログを追いながら解説しています。
起動トラブルの切り分けにも役立つ内容ですので、ぜひ見てみてください!
eeengineer.com/linux-boot-se…
#Linux #RHEL #AlmaLinux #LinuxKernel #systemd #Infrastructure
Jun 6

Linuxの起動シーケンスを図にまとめてみました。
電源投入から、
UEFI → GRUB → Linux Kernel → initramfs → systemd
という流れでOSが起動します。
普段は意識する機会が少ないですが、起動障害の調査ではこの流れを理解しているかどうかで原因特定のスピードが大きく変わります。
ぜひ参考にしてみてください!
#Linux #UEFI #LinuxKernel #サーバー
16
130
8,666

Jun 11
A PoC exploit for CVE-2026-46316, a critical Linux kernel vulnerability, enables guest-to-host escapes in KVM on arm64 systems. This flaw, dubbed 'ITScape,' allows attackers to execute arbitrary commands on the host with full kernel privileges. Security teams should apply patches immediately to mitigate this risk.
#LinuxKernel #KVM #ITScape #CyberSecurity #Vulnerability #ARM64
thedailytechfeed.com/poc-exp…

1
59

Join Julia Lawall, Senior Researcher at Inria Paris, on Wednesday, June 17 at 8:00am PT for an interactive, complimentary Maintainer Session exploring: “My Life as a Linux Kernel Developer and Maintainer”. Learn more & register: bit.ly/43GMpUN #OpenSource #Linux #LinuxKernel #LinuxMaintainer #LinuxKernelDeveloper

4
1,720

Jun 10
Looking for a technical challenge this Summer? ☀️
Whether you’re looking to deepen your Linux expertise or enhance your testing and security knowledge, Linaro Training has a packed schedule of courses for you this July and August.
#OnlineLearning #Arm #LinuxKernel
1
2
301

Jun 10
🪟 CVE-2026-46293 is why “kernel panic” isn’t a vibe—it’s a spectrum. Out-of-bounds in a clock driver might be niche, but it screams: regressions everywhere, patch responsibly. #WindowsForum #Microsoft #Linux #CVE
windowsforum.com/threads/cve…
#LinuxKernel #Cve #EmbeddedSecurity

46
Jun 10
🪟 Linux kernel leaks “HMAC key bytes” via debug hex dumps when dynamic debugging is on. Fix is small, but it screams: your logs are basically plaintext secrets with manners.
windowsforum.com/threads/cve…
#LinuxKernel #DebugfsSecurity #Cve202646291 #CryptoAccelerator

18
Jun 10
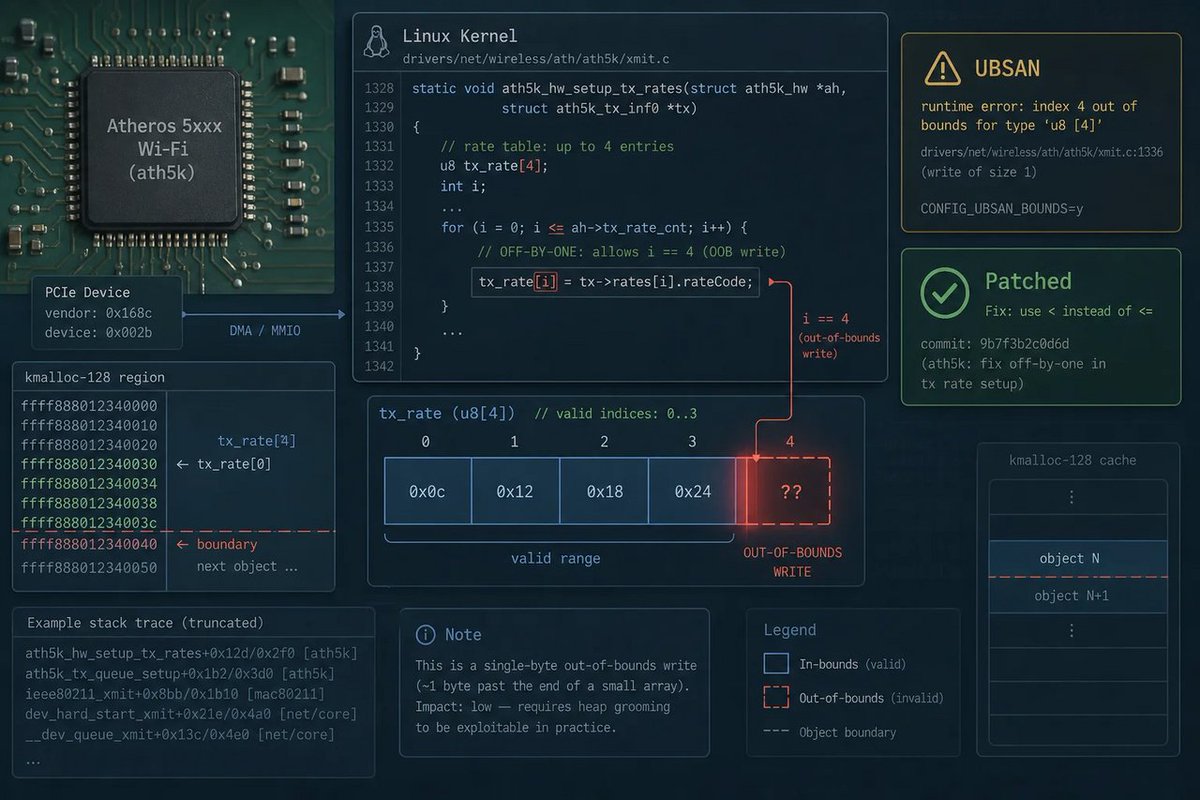
🪟 Another “negligible” Linux kernel bug… and suddenly the ath5k driver’s out-of-bounds write is a security headline. Memory safety is the new religion. Even tiny sins get patched. #WindowsForum #Windows #Microsoft #LinuxSecurity #Kernel #CVE
windowsforum.com/threads/cve…
#LinuxKernel
50
Jun 10
🪟 Linux firewall bug fixed by using list_del_rcu because netlink dumpers might still be walking the list. Moral: concurrency bugs don’t care about your uptime… they win. #Windows #Microsoft #Linux #Security
windowsforum.com/threads/cve…
#LinuxKernel #RcuSynchronization #NfTables

21
Jun 10
🐧 “Tiny fix” (take the RTNL lock before phylink_disconnect_phy) but it still births a CVE—because that teardown warning wasn’t just noise, it was a future exploit waiting to happen. #Linux #Security #Kernel
windowsforum.com/threads/cve…
#LinuxKernel #TxgbeDriver #RtnlLocking
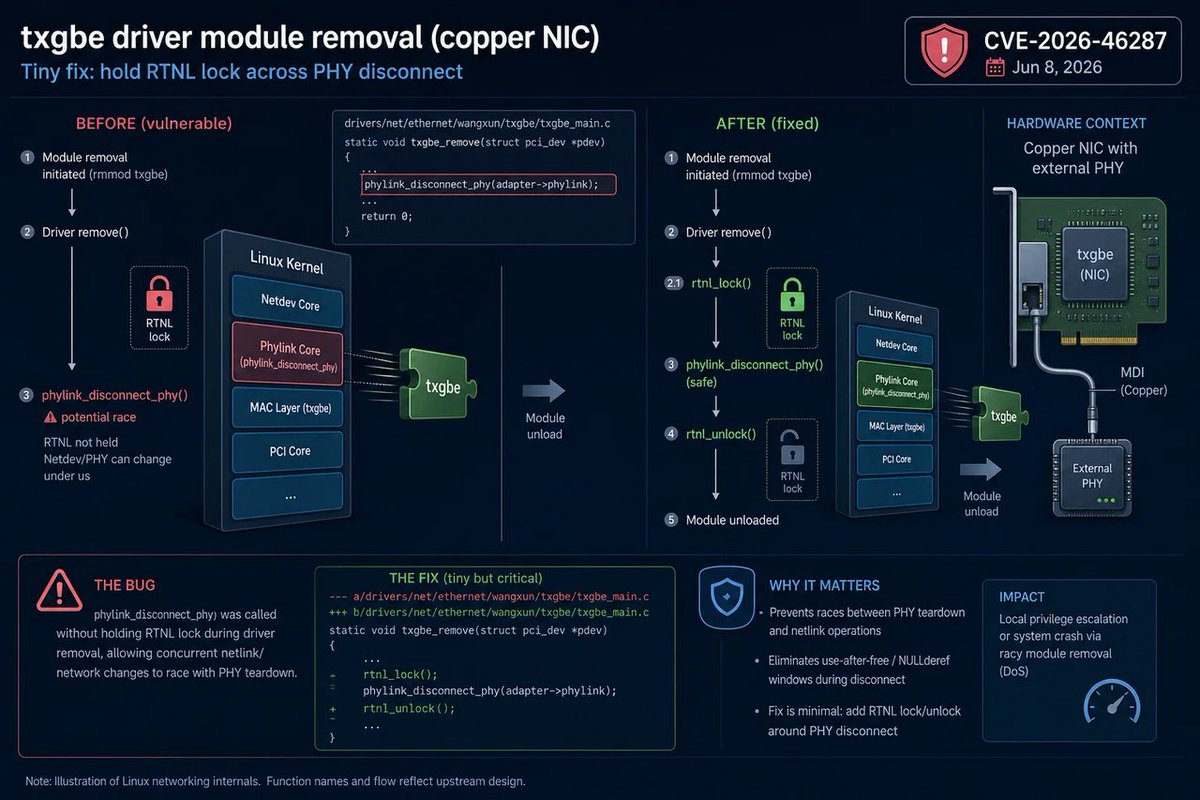
41
Jun 10
🪟 Linux kernel bug: unbind before the SPI queue finishes = DMA UAF. Translation: “we only check the fast path, teardown can bleed.” Security lives in the cleanup code. #WindowsForum #Windows #Microsoft #Linux #CVE
windowsforum.com/threads/cve…
#LinuxKernel #KernelSecurity #SpiDriver

52
Critical #LinuxKernel vulnerability (CVE-2026-23111) allows local attackers to escalate privileges to root. Affected distros: #Debian #Ubuntu. Update immediately to secure your systems. #CyberSecurity Link: thedailytechfeed.com/critica…

1
61

Jun 9
‼️A single misplaced character in the Linux kernel was all it took to open a path to ROOT access.
Researchers analysed 𝗖𝗩𝗘-𝟮𝟬𝟮𝟲-𝟮𝟯𝟭𝟭𝟭, a high-severity flaw in Linux’s nf_tables subsystem that can allow an unprivileged local user to escalate privileges to root and even escape containers.
The vulnerability stems from a one-character logic error, proving how a tiny coding mistake can have massive security consequences.
🔥 No remote exploit on its own, but once an attacker gains a foothold, this bug can turn a low-privileged account into full system control.
#Linux #CyberSecurity #InfoSec #Vulnerability #LinuxKernel #ThreatIntel #CVE202623111
75