
3 Sep 2023
#統計 #Julia言語
nbviewer.org/github/genkurok…
を更新した。
n = 2000 まで計算するように変更した。
新たな例
↓
dist = MixtureModel([Normal(), Normal(50)], [0.98, 0.02])
2
5
1,726
17 Aug 2023
#統計 #Julia言語
nbviewer.org/github/genkurok…
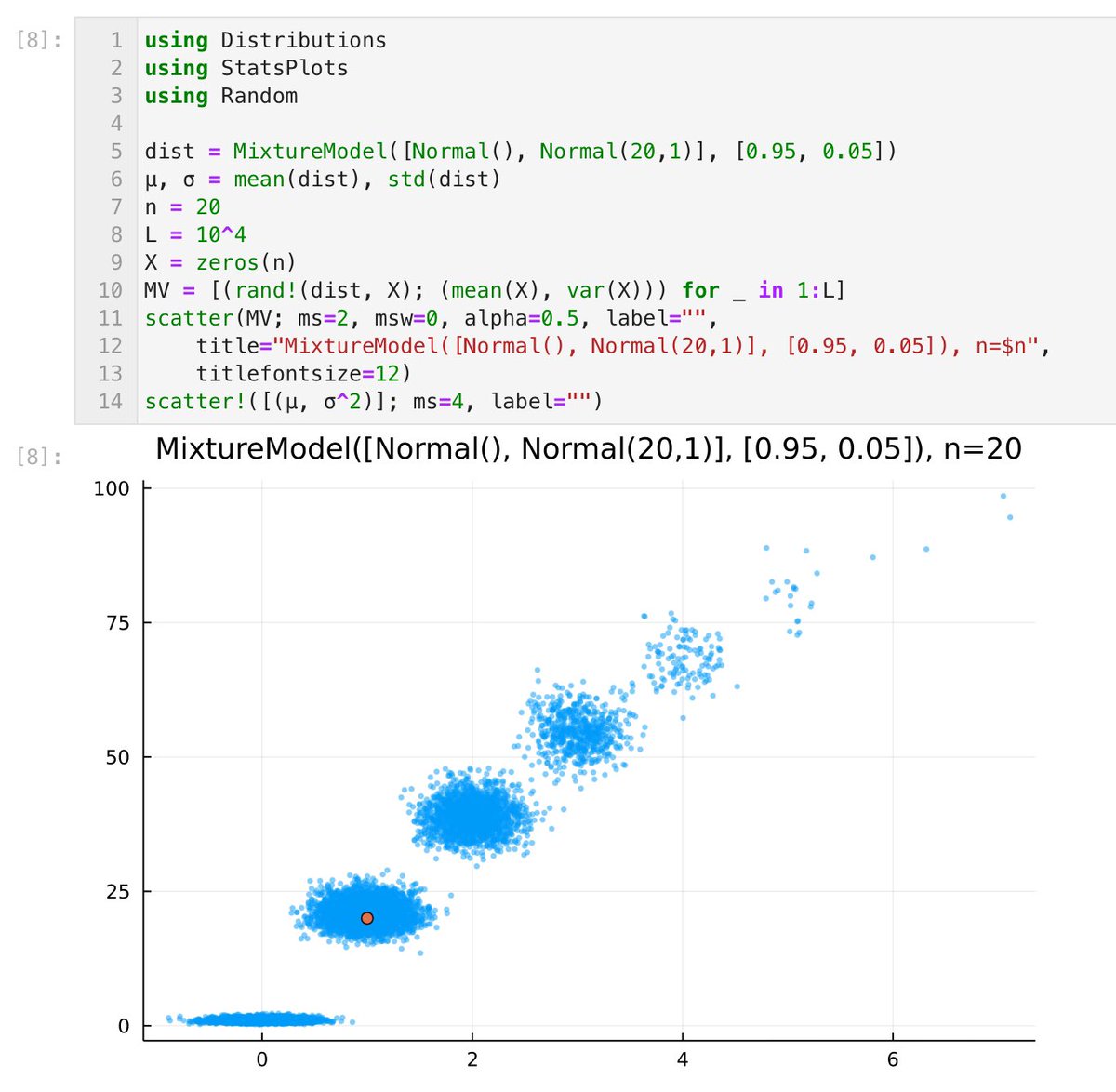
dist = MixtureModel([Normal(), Normal(20)], [0.95, 0.05])
この場合も非常に面白い。nが数十程度のとき、分布は複数の2変量正規分布達の混合分布に近い分布になる。
問題:そうなる理由を直観的に説明せよ。
1
4
6
3,081
17 Aug 2023
#統計 #Julia言語
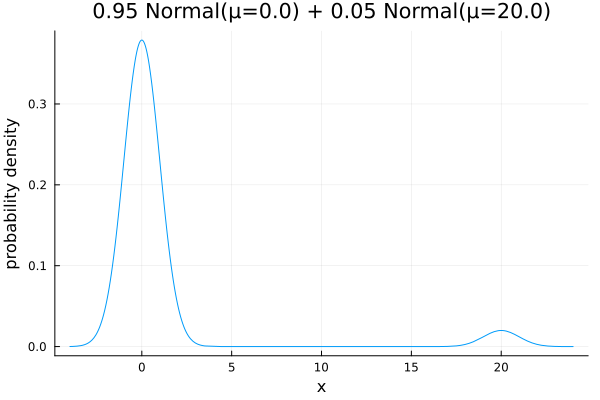
95%の標準正規分布と右側の5%の外れ値の分布の混合正規分布
dist = MixtureModel([Normal(), Normal(20)], [0.95, 0.05])
nbviewer.org/github/genkurok…
1
3
5,168

20 Mar 2023
📈🤔 Agree or disagree?
Latent class analysis (LCA) is an analytic tool which takes qualitative information (i.e., dichotomous observations) and uses a quantitative model to produce qualitative inferences (i.e., nominal latent classes).
#Measurement #MixtureModel #Education
2
1
13
3,947
24 Jun 2022
#統計 #Julia言語
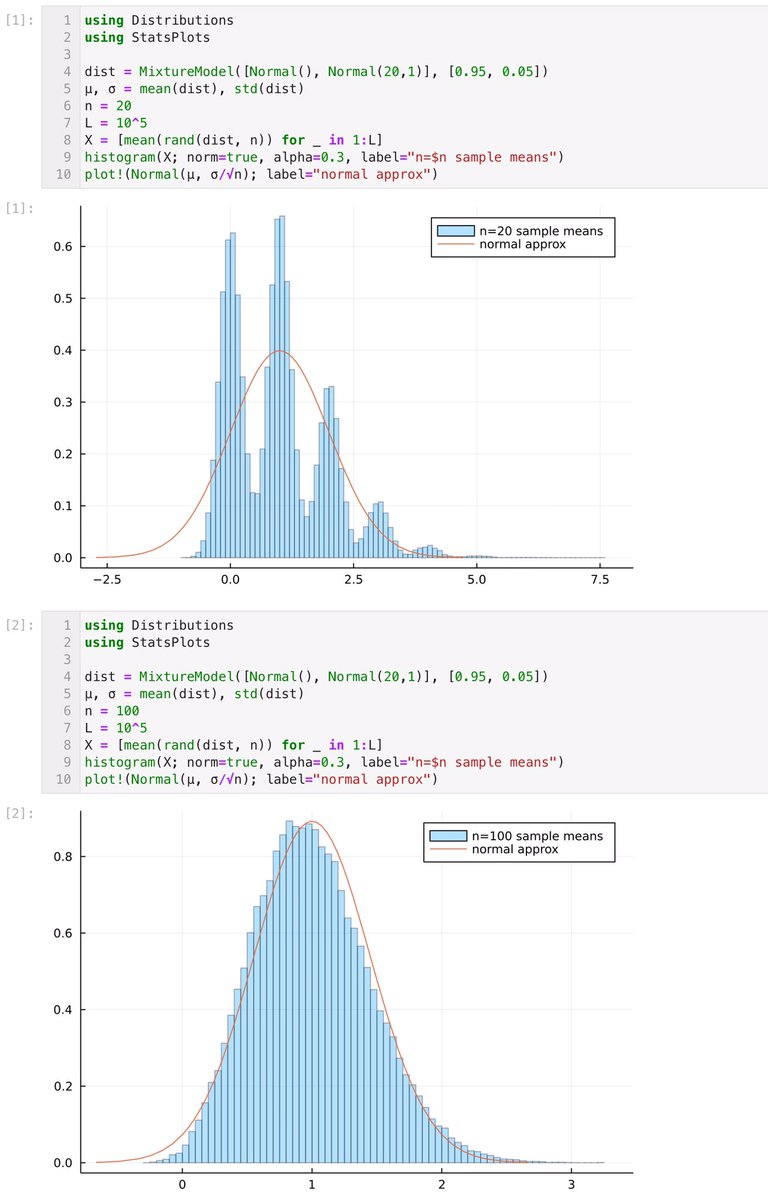
一様分布は例外的に中心極限定理による正規分布近似がものすごく速く収束する場合になっています。
対数正規分布や
MixtureModel([Normal(), Normal(20,1)], [0.95, 0.05])
などで試してみると印象が少し変わると思います。
非対称で外れ値が出易い分布では収束が遅くなる。
23 Jun 2022

#プログラミング勉強中
#programming
#中心極限定理 の #実験
#experiment of
#centrallimittheorem
#julia #julialang #julia言語
#jupyternotebook
#macos #monterey
#macmini #macminim1
3
3
13





22 Mar 2022
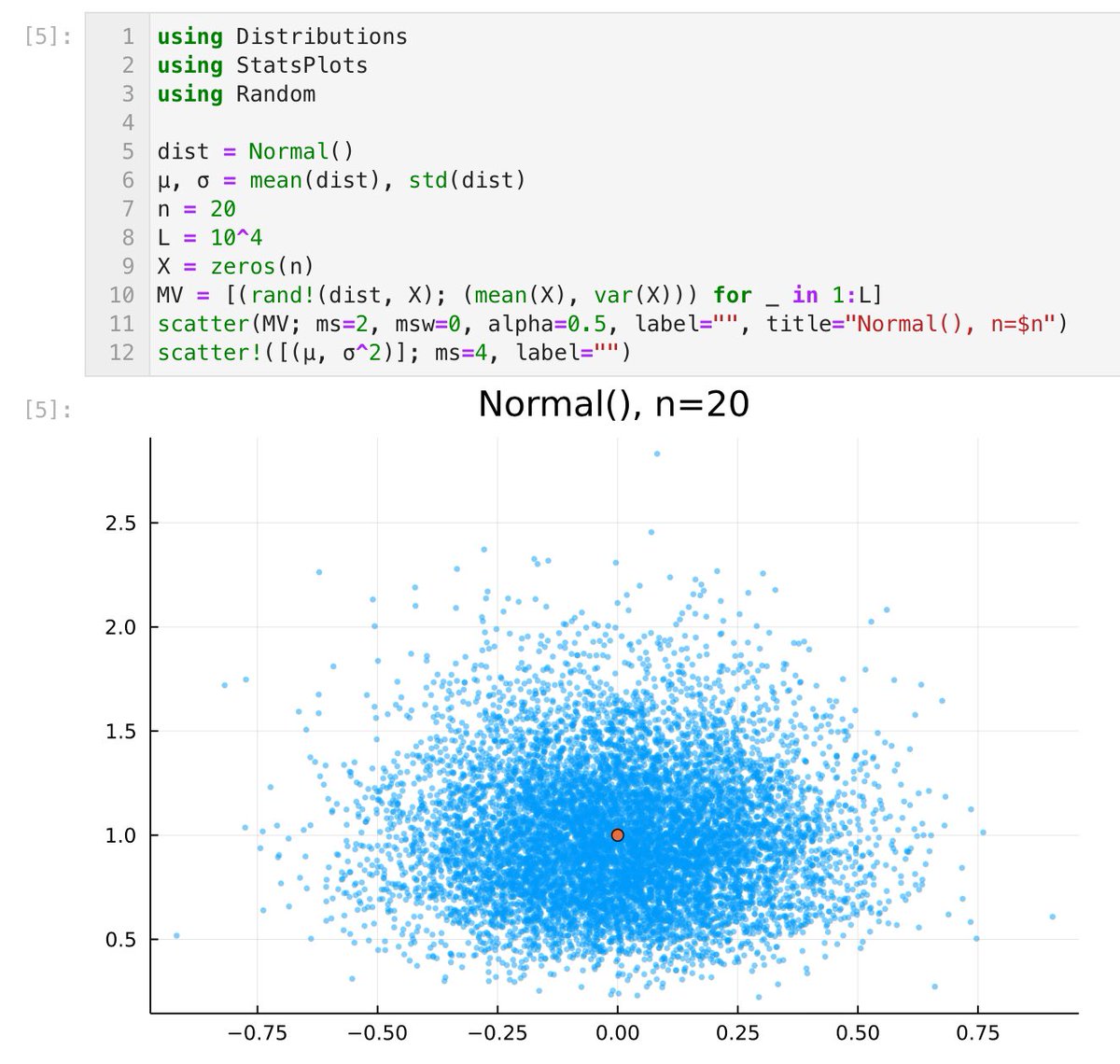
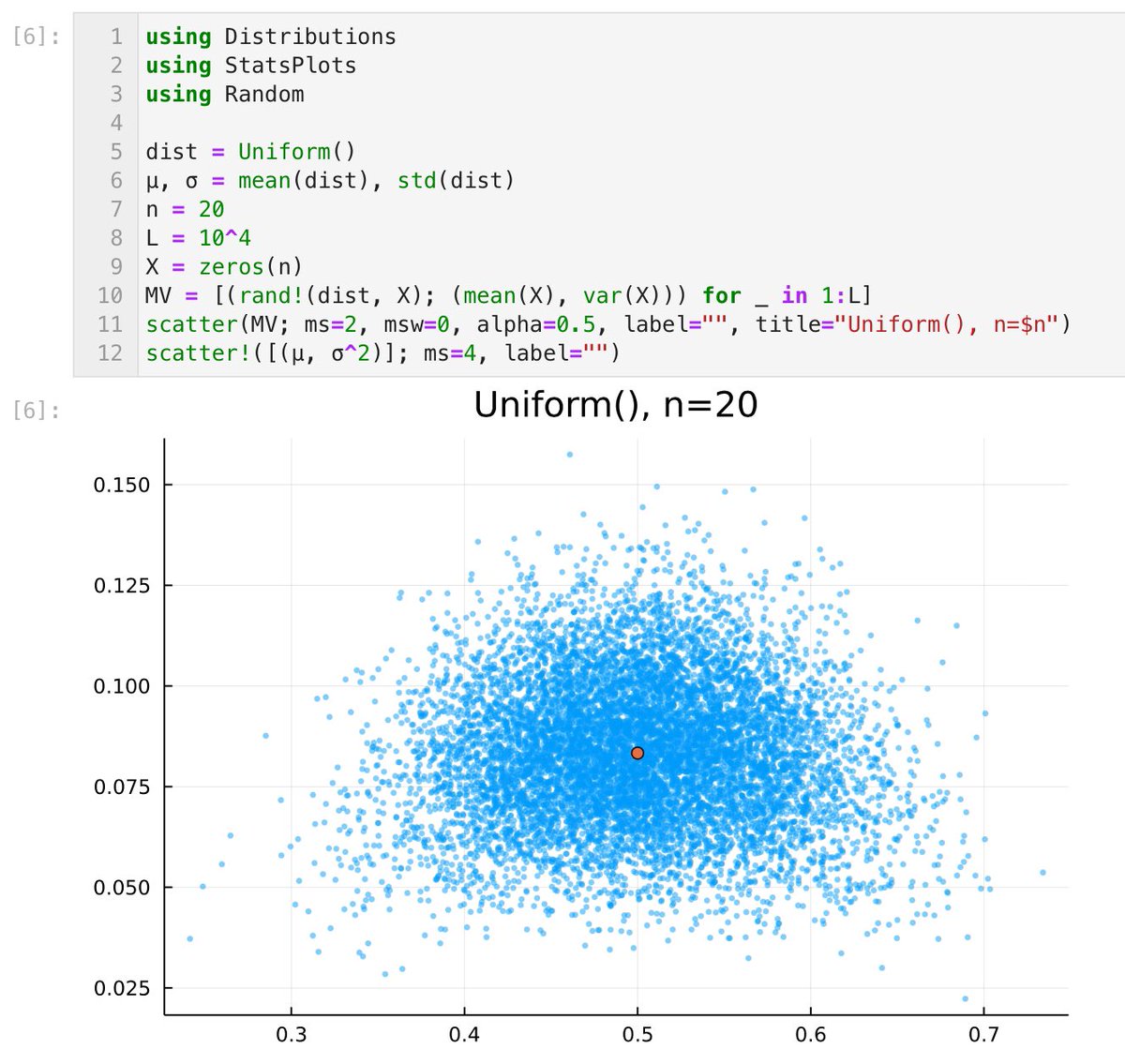
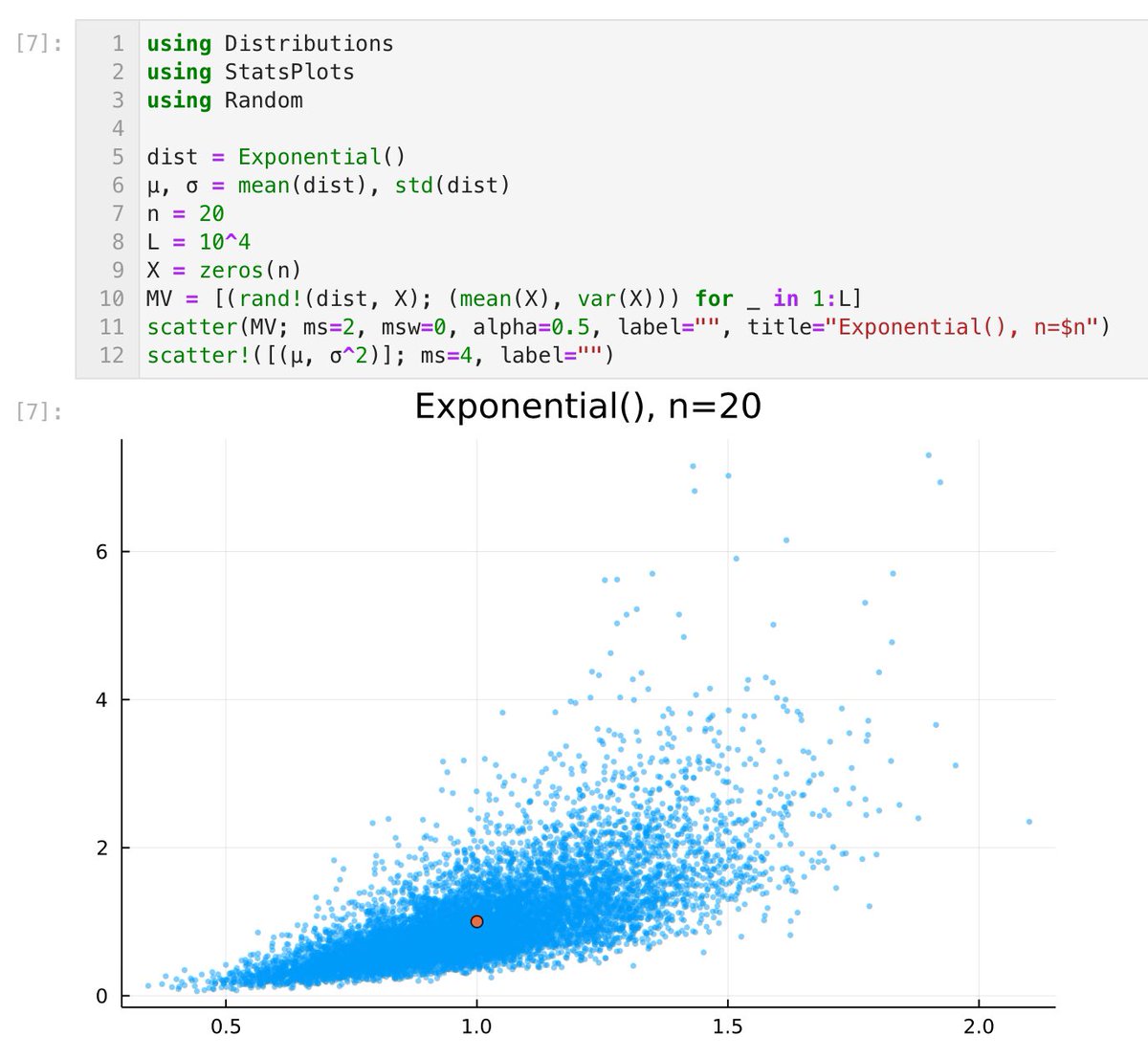
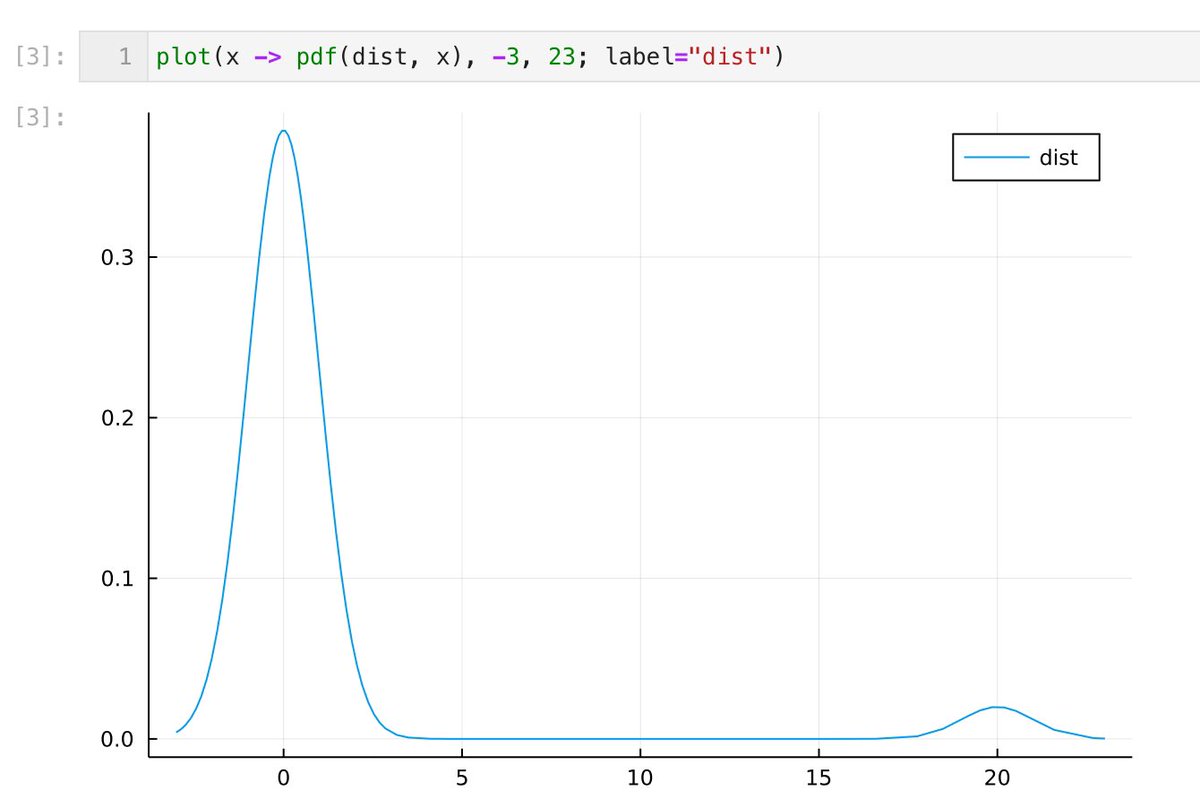
#Julia言語 左右対称もしくは対称に近い分布ほど中心極限定理による正規分布近似の誤差は速やかに小さくなります。
中心極限定理の確認は全然対称でない分布の場合にもやっておくべきです。例えば
dist = MixtureModel([Normal(), Normal(20,1)], [0.95, 0.05])
とか。右側の小さな山が!(笑)
22 Mar 2022

書いた!
ランダムな現象を感覚的に理解するには、やはりコンピュータが手軽だなあ。
中心極限定理とは:Juliaでの計算例、意味|趣味の大学数学 math-fun.net/20220322/23295/
1
2
4
12 Nov 2021
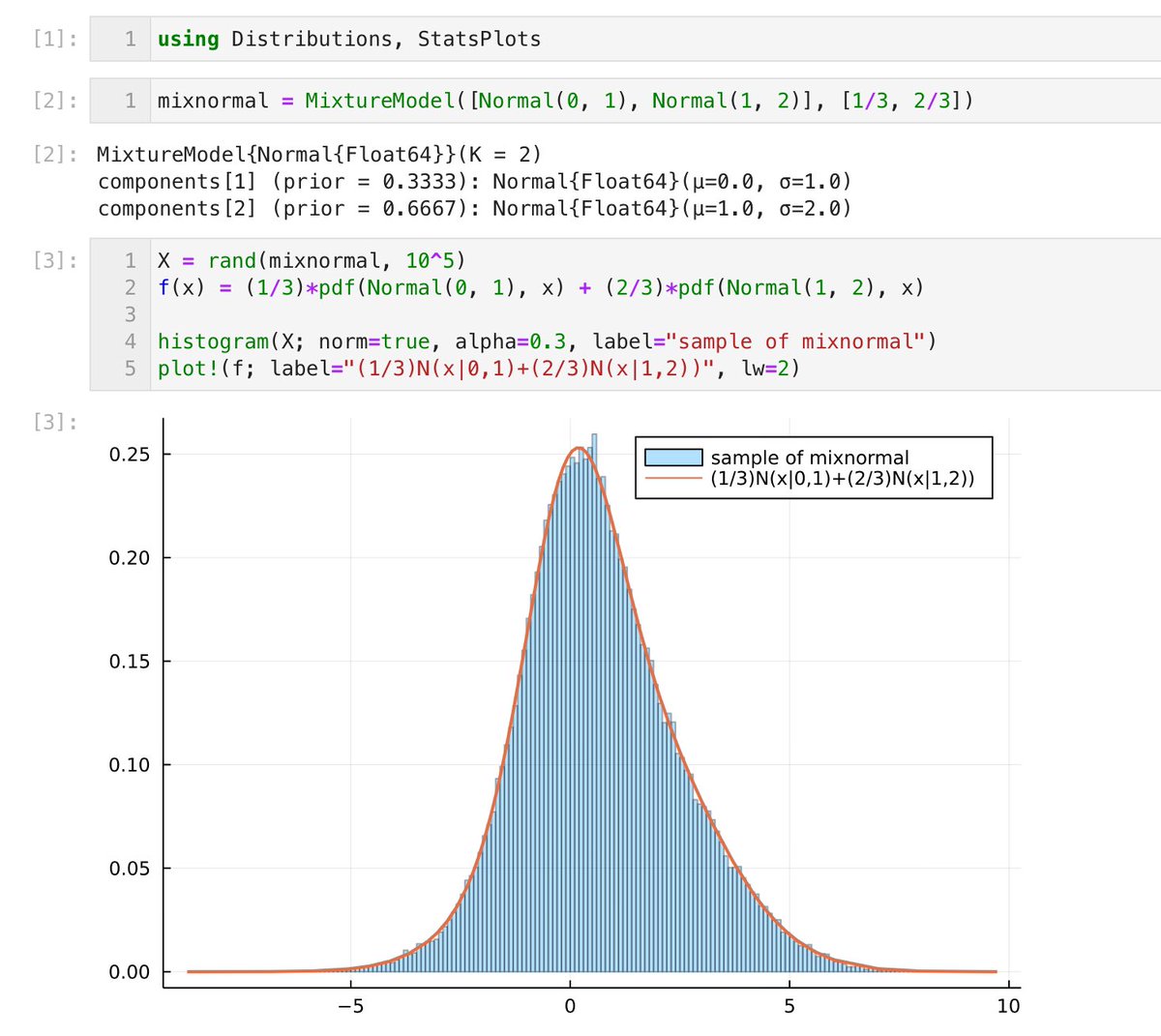
#Julia言語 1つ前のツイートの添付画像中にある自己チェック問題のJuliaでの解答はシンプルで自然。
mixnormal = MixtureModel([Normal(0, 1), Normal(1, 2)], [1/3, 2/3])
rand(mixnormal)
でよい。混合正規分布を意味するオブジェクトを作れば、randやpdfやcdfなどが全部使える。
2
3
5

23 Sep 2020
How to perform three-step latent class analysis in the presence of measurement non-invariance or differential item functioning
Wow! New #MixtureModel #LatentClassAnalysis #LatentGold paper by Vermunt & Magidson @TilburgU @StatInnovations
doi.org/10.1080/10705511.202…

1
2

25 Jun 2020
Have you ever used a Bayesian Mixture Model? Follow along with a tutorial by Dr Clair Alston-Knox as we apply Bayesian Mixture Models for soft clustering and density estimation!
#bayesianstatistics #mixturemodel #rstats #DataScience
youtube.com/watch?v=gupg1yob…
1
3
3 Jun 2020
#Julia言語 Distributions.jlの使い方の例
添付画像
1. MixtureModel
2. product_distribution
3. LocationScale
4. truncated
nbviewer.jupyter.org/gist/ge…
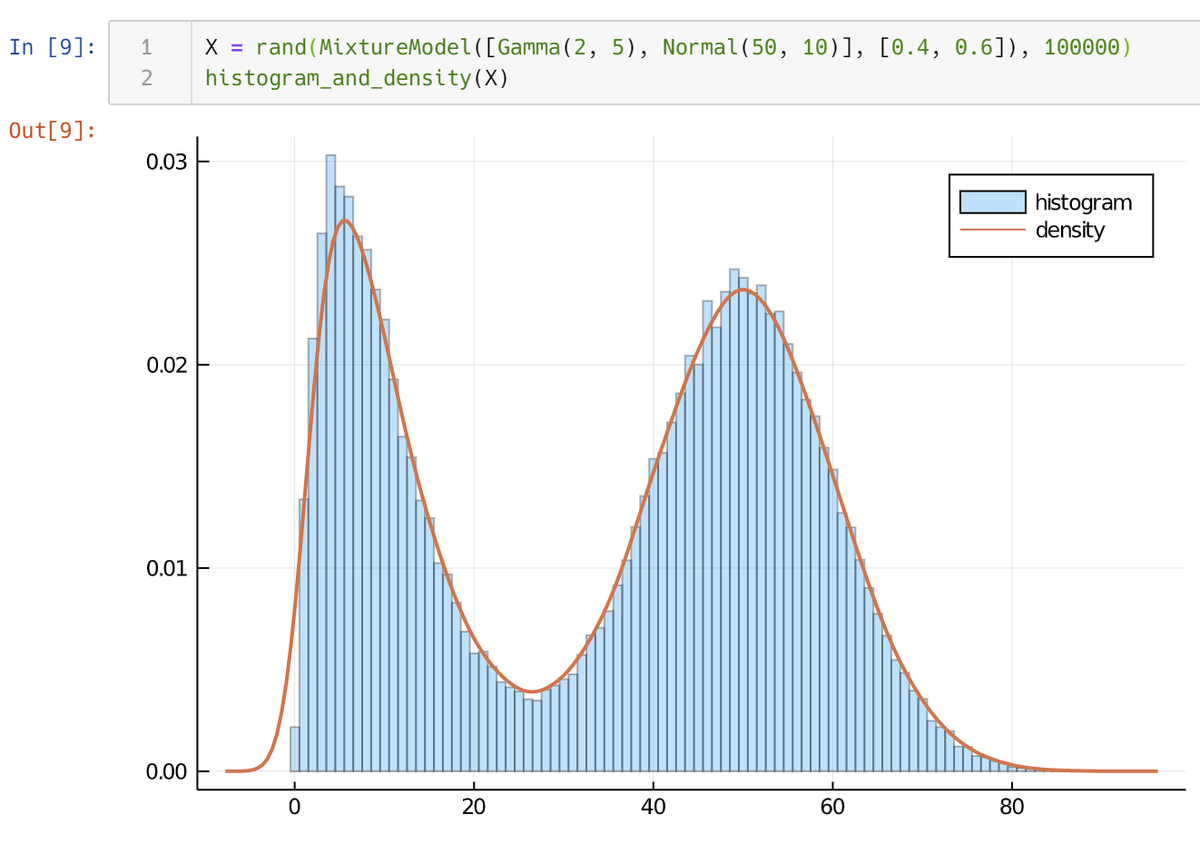
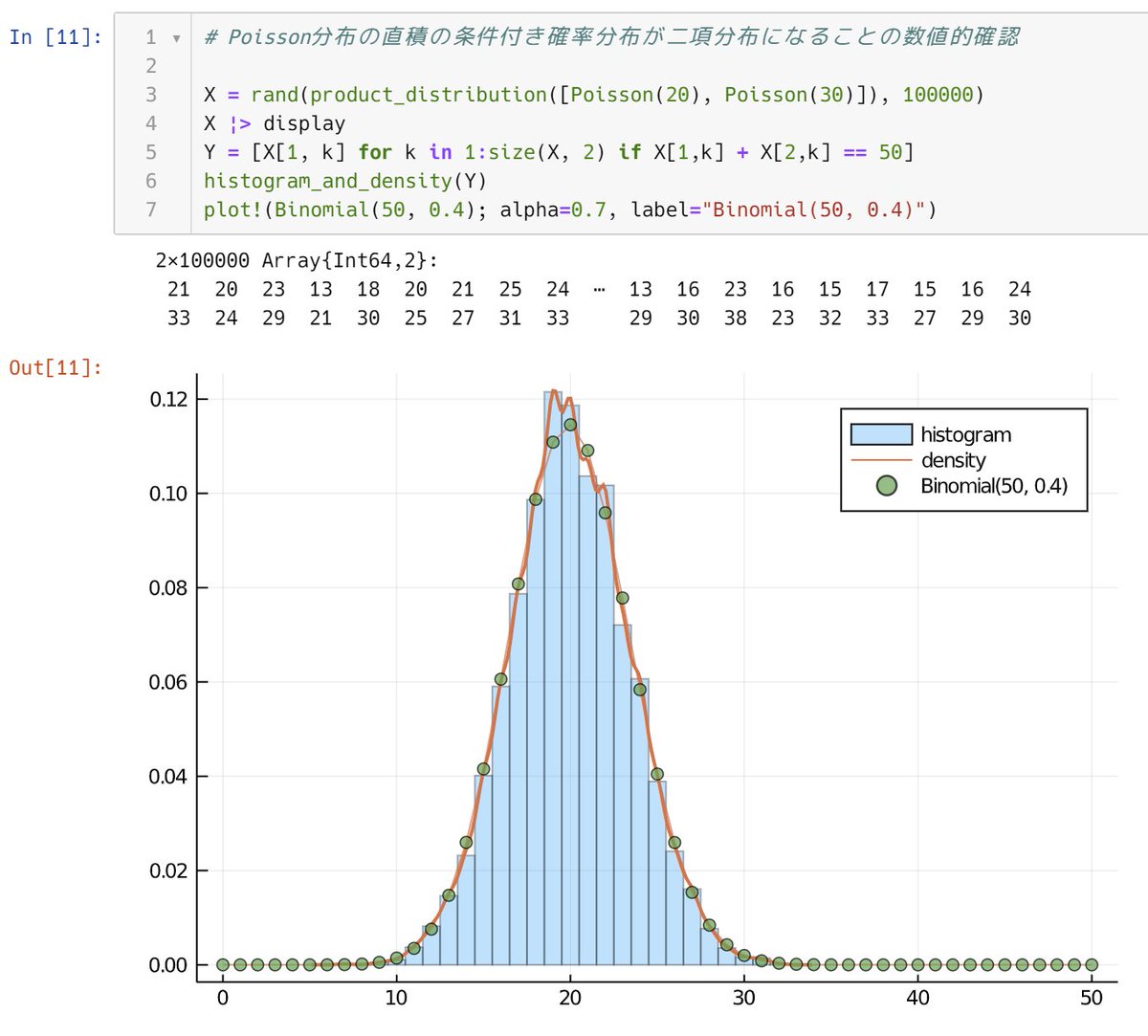

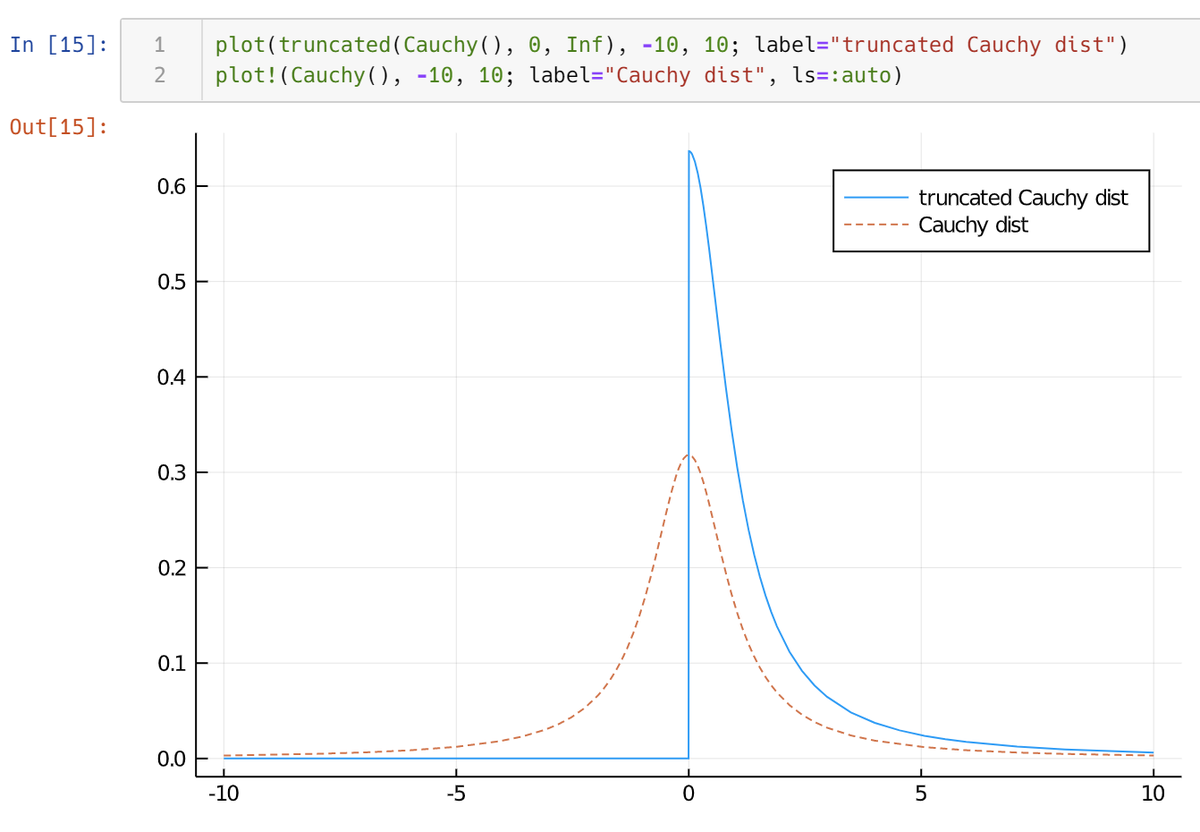
1
4
3 Jun 2020
#Julia言語 Distributions.jl では分布から分布を作る方法も幾つか用意されています。
MixtureModel([dist1, dist2, ...], [prob1, prob2, ...]) 混合分布
product_distribution([dist1, dist2, ...]) 直積分布
LocationScale(μ, σ, dist) 平行移動とスケール変換
truncated(dist, a, b) 区間に制限
1
2
3 Jun 2020
#Julia言語
理解するためにコードを書くときにはライブラリの機能をあえて使わないようにすることが基本なのですが、Distributions.jl で混合分布をMixtureModelで作れることを知っているとforループの部分を1行に短縮できます。
nbviewer.jupyter.org/gist/ge…
x.com/vin_tea01/status/12679…
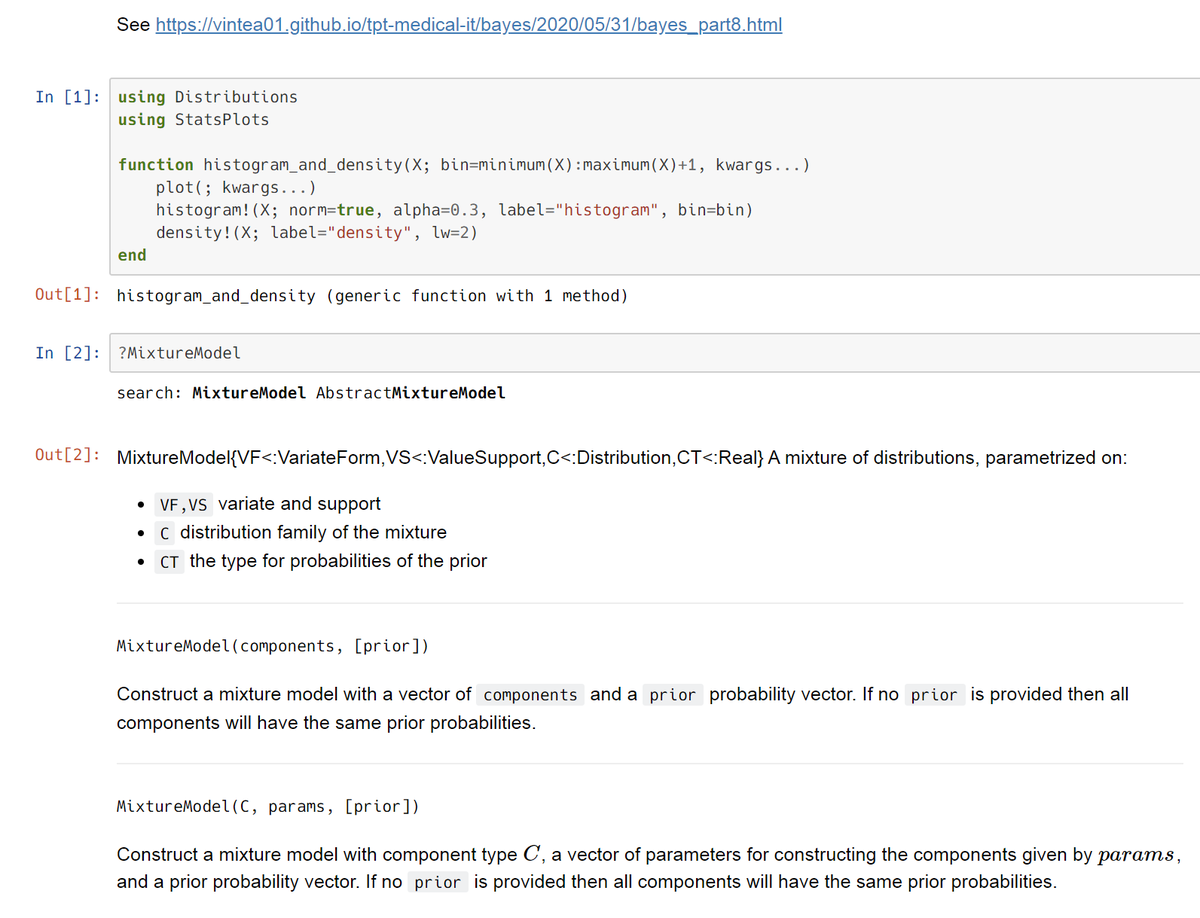
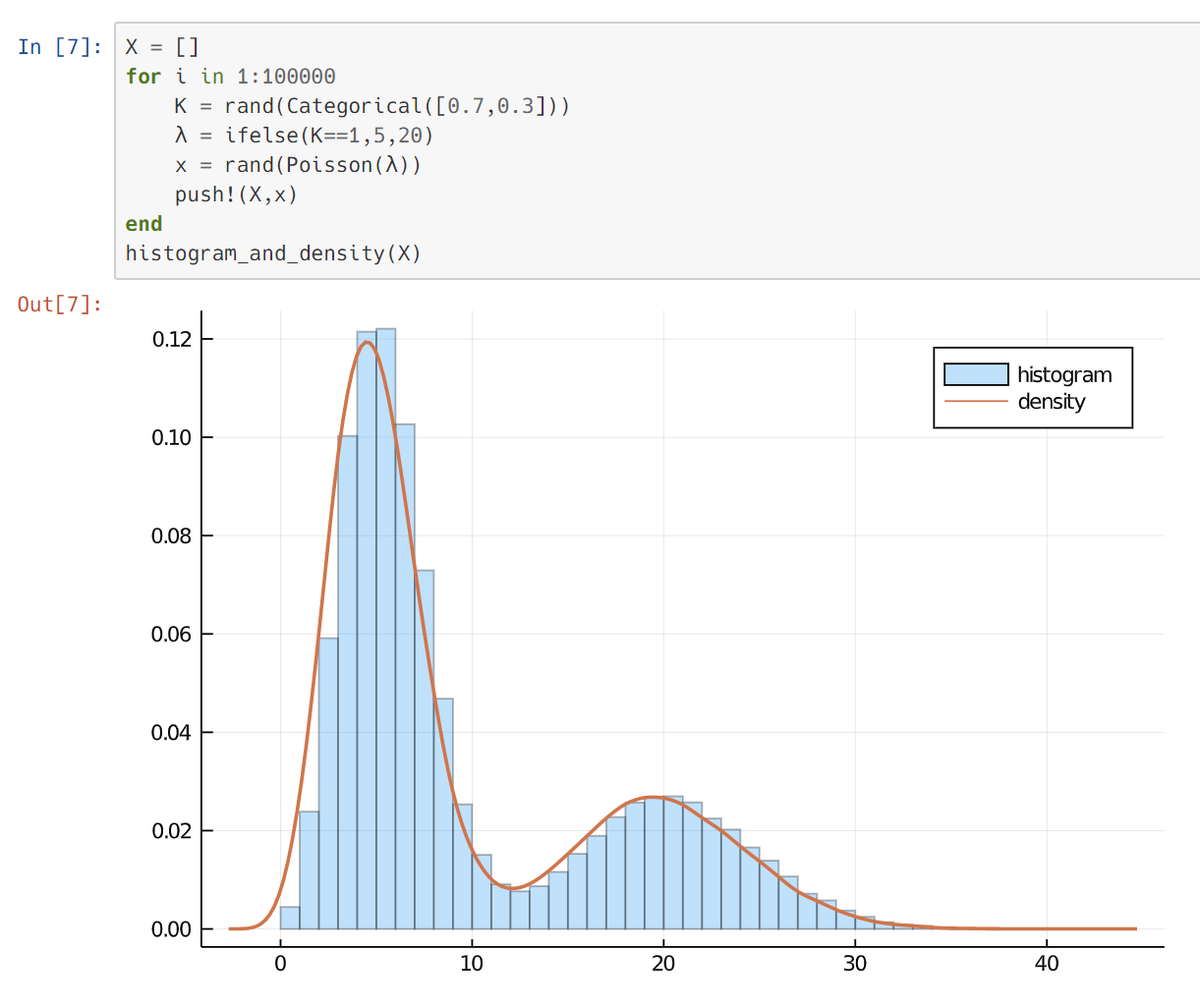
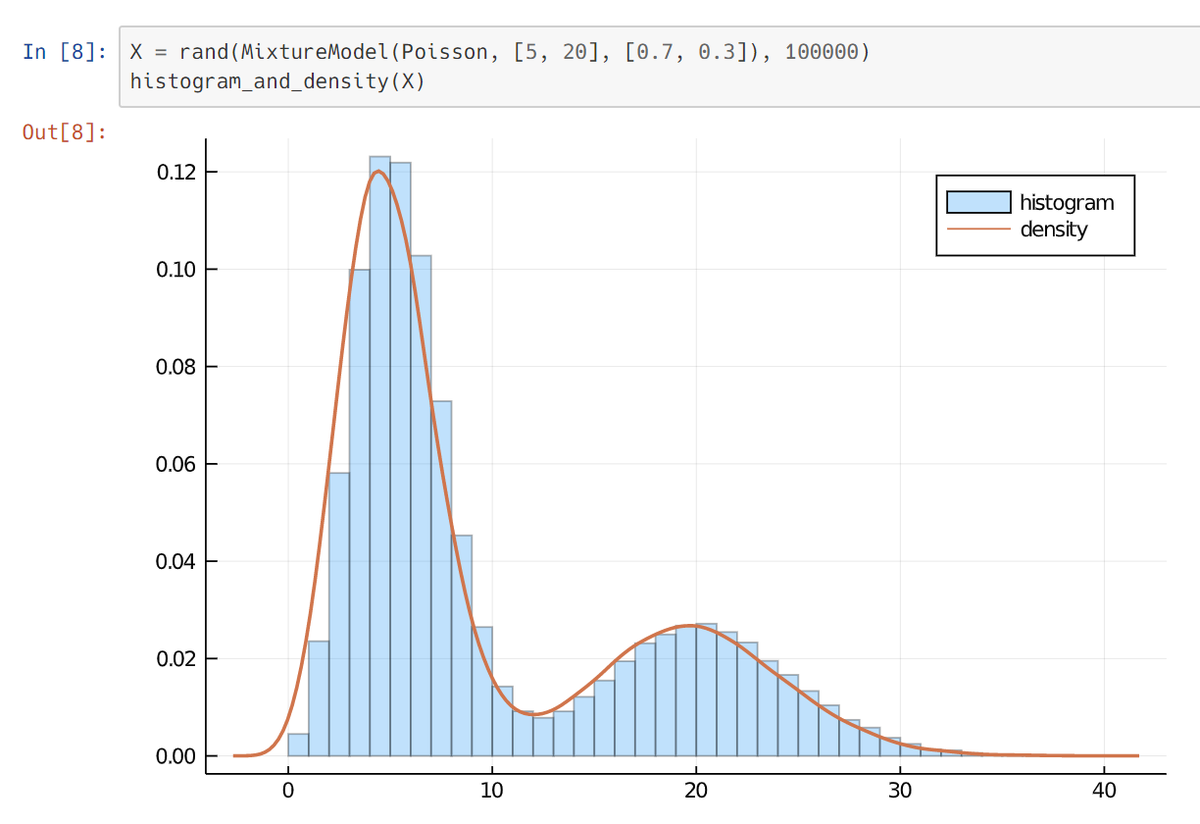
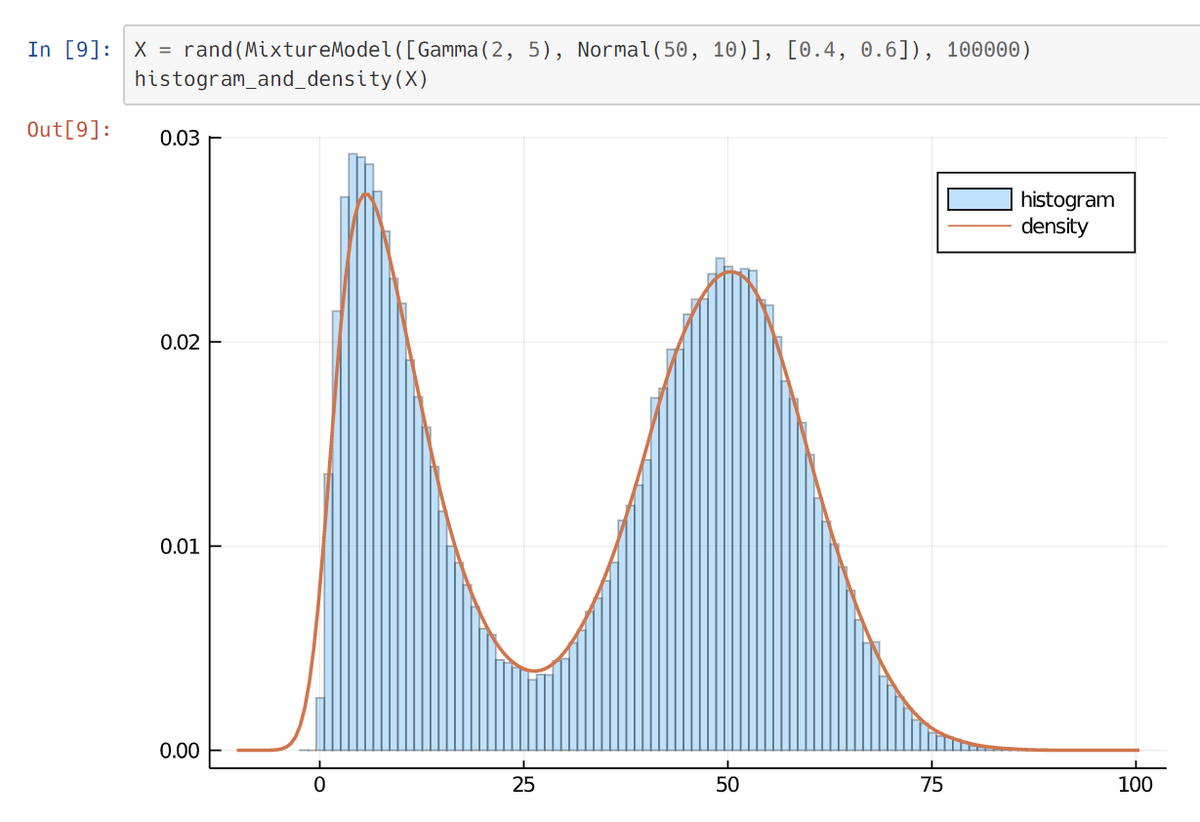
1
1
5
9 Mar 2020
#Julia言語 の確率分布を扱うパッケージのDistributions.jlの基本は
確率分布の型を定義して、
確率分布のオブジェクトを作って、
確率分布を扱う
です。混合分布のオブジェクトは
mixdist = MixtureModel([dist1, dist2, ...], [p1, p2, ...])
で作れます。
1
1
3

29 Oct 2019
Some tough days require a little calculus. (Thinking about clonal evolution in my #SingleCell expt.) #EMalgorithm #compbio #mixturemodel #phylogenetics #doyourmathinpen

3

9 Jul 2019
3) classic statistical methods help to analyse #mobility #data: #logit #LatentClass #semiparametric #MultipleLinearRegression #MixtureModel #ROC #clustering
1
3
2

O3M (the overall mean mixture model): a new #MixtureModel to study bimodal fitness data that considerably improves the precision of the estimates and the power of the analysis.
bit.ly/2AFn4fp

3
25 Nov 2017
#JuliaLang でのDistributionsパッケージのMixtureModelで定義した確率分布をMambaパッケージでのMCMCシミュレーションで使うと計算が遅くなる感じ。混合モデルの定義を自分でやると速くなります。ただし、警告が出るような書き方で定義したまま気付かないと3桁くらい遅くなる。やってしまった(笑)。
1
2
2