
Jeff Ma retweeted

Jun 9
Mythos/Fable 5 outperforms Opus 4.8 with Multiagents on Programbench. Single agent baseline seems to be only slightly higher. This is from the Anthropic system card.

3
3
34
2,697




Te cambian las features de un día para el otro en Claude. Ahora “workflow” se dice “ultracode”.
Sigue siendo malísimo el nombre, pero ahora lo asocian con costo. Debería ser tipo “multiagents” amigosss 🙏
Jun 3

We've changed the trigger word from "workflow" to "ultracode".
You can still say "use a workflow for this", but when you're clearly referring to something else, Claude won't kick off a dynamic workflow. For an explicit trigger, use "ultracode". We appreciate the feedback!
2
55

May 31
It was the AAMAS conference (Conference on Autonomous Agents and Multiagent Systems). You can’t really benchmark half of the solutions, and the solutions are not very applicable in the industry. Lots of cool AI stuff is being presented tho, mostly because of the multiagents.
1
2
37

May 25
been almost a year since i made this tweet and honestly not much has changed
here's the state of ai in today's enterprise world:
- genai POCs are still failing at scale & in large corps
- MCP turned out to be pretty fucking useless
- multiagents have been disappointing. enterprise workflows mostly reward deterministic orchestration, not autonomous stategraphs
- hallucination still remains a core unsolved issue even with the SOTA models
- so does memory. maintaining state over long/cross conversations continues to be a challenge
- larger context windows & more parameters haven't really achieved much compared to the last generation
- tokens are costing more, not less, as models, architectures, and harnesses have progressed
- mid-size CEOs are realizing that replacing engineers with agents isn't the best way forward (agents are costing more than humans)
- non-tech megacorp CEOs still don't know what to do exactly & are implementing stupid KPIs such as measuring copilot usage to push AI adoption
- consultants who are not rebranding themselves as "forward deployed engineers" are having a really hard time
- organic ai adoption is bottom-up and not top-down across corps
- using tools like coderabbit has become imperative in fighting the thousands of lines of AI slop even senior engineers are committing every day
- nobody seems to be writing code anymore
- still doesn't mean code is solved. LLMs are duds on large codebases
5 Jul 2025

some intern at mckinsey is probably slopcoating a report on this but let me give you an insider news: most large corps are not happy with the agentic systems & POCs they’ve done this year. 2025 was supposed to be the year of agents. so far it’s been the year of letdowns.
26
75
1,097
120,521

May 23
Ese no es el problema, eso se resuelve fácil aplicando los mismos principios y métodos que usan los developers. Sprints, multiagents, etc. El problema es que la gente empieza a sacrificar practicidad por conveniencia y empieza a delegar a AI hara los mínimos ajustes
1
1
447

• "Hey Grok" in your Tesla
• Grok Build CLI in your terminal
• Grok Multiagents handling your research
• Grok built into every Apple CarPlay screen
• Grok Connectors connecting your business and personal worlds
• Grok on 𝕏 shaping your feed - helping you understand the world even better
xAI is building an AI layer that follows you across your every device, every workflow, and every part of your day
The AI race will be won by the AI that actually becomes part of your everyday life before you even realize it
And Grok is becoming that... an AI layer around your own world

53
58
328
8,872


May 8
In this episode, @DrScottClark, co-founder and CEO of @dbnlAI, joins us to explore how teams can reliably operate and improve complex LLM systems and agents in production. Scott introduces a Maslow’s hierarchy of observability: telemetry for logging, monitoring for known signals, and post-production or online analytics to surface unknown unknowns. We dig into examples of real-world failures Scott’s team has seen in production systems, such as “lazy” tool-use hallucinations that standard evals miss, and how mapping traces into vector fingerprints enables clustering and topic discovery to uncover emergent behaviors. Scott explains how analytics can feed the data flywheel by generating evals, guardrails, and training data, and why online, adaptive approaches are essential for non-stationary models. We also touch on practical how-to’s such as instrumentation with OpenTelemetry, the GenAI semantic conventions, and the role of dedicated analytics tools.
🗒️ For the full list of resources for this episode, visit the show notes page: twimlai.com/go/767.
📖 CHAPTERS
===============================
00:00 - Introduction
01:32 - What is Distributional?
03:54 - Bayesian statistics and optimization in multiagents
08:14 - Anti-patterns
10:11 - Hierarchy of observability
16:12 - Applying analytics in the lifecycle
21:58 - Trace clustering and vector mapping
26:42 - Evals
31:04 - OpenTelemetry (OTEL) and the Gen AI semantic convention
35:47 - Non-stationarity and “model weather” reports
41:30 - Examples of distribution shifts
46:24 - Distributional is open distribution
47:05 - Metrics for applying analytics
48:54 - Academic benchmark
51:07 - Future directions
1
2
7
730

@ravikiran_dev7
Why not save time & money? Right out-of-the-box, @RavenDB includes:
✅ Vector Search
✅ Embeddings with caching
✅ AI Attachments handling
✅ GenAI
✅ Agents & Multiagents
No additional work needed!
Thanks for spreading the good word, @The_Dan_Onay 🙌
1
2
161

Dream Server - some new updates will be coming soon
Using Hermes-agent to create anything, including based on Kanban MultiAgents.
@The_Only_Signal @Teknium @NousResearch
4
2
3
1,545

Je viens de terminer de tester claude design et certains modèles chinois ( moins chers et incroyables) qu'il faut déjà se plonger dans les multiagents de @MistralAI 😊 je voulais aussi tester les plateformes de création 3D en IA cette semaine ! Rester en veille est un effort !
1
3
425

Apr 27
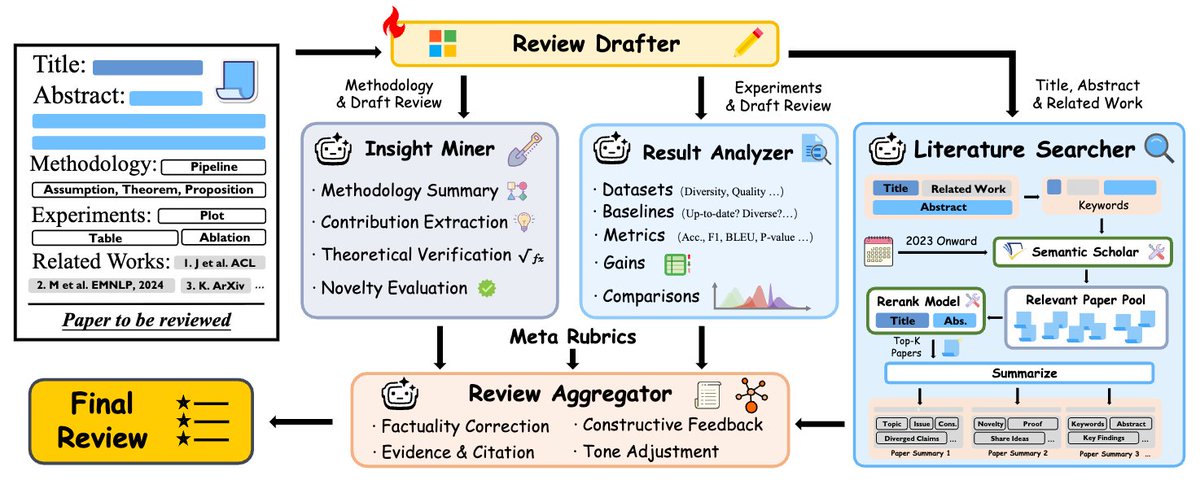
🎉 Excited to see our ACL 2026 @aclmeeting paper 🤖ReviewGrounder🤖 out!
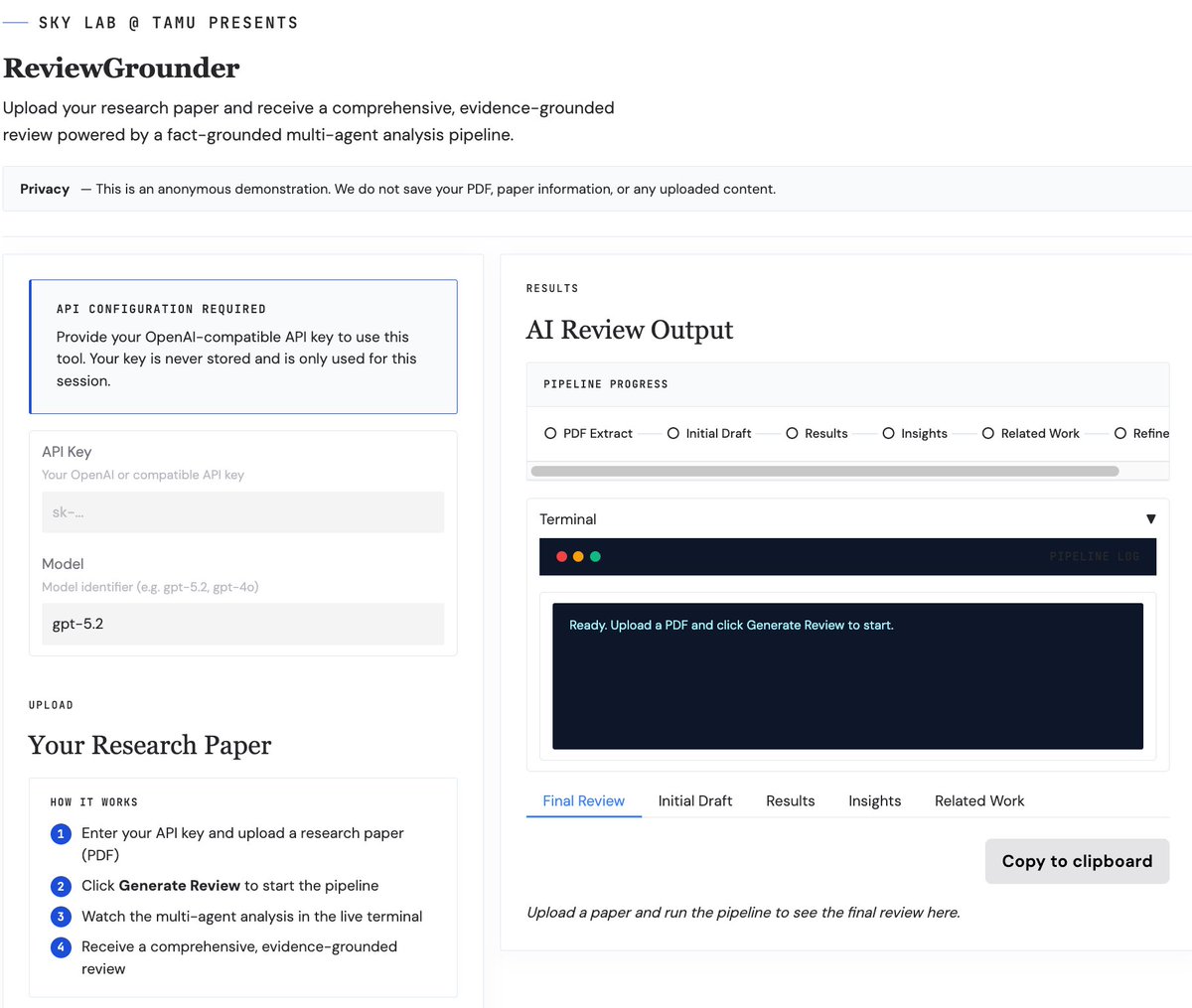
🚀Try out the demo here: huggingface.co/spaces/Review…
We designed a rubric-guided, tool-integrated multi-agent reviewer where specialist agents:
🔍 examine the paper
📚 search related work
✅ check evidence
🧠 synthesize grounded feedback
🤝 Proud of this collaboration and excited for the broader conversation on how AI-assisted peer review can become more rigorous, evidence-grounded, and genuinely useful.
@LambdaAPI @chuanli11 #ACL2026 #agents #MultiAgents #AIReviewer #NLP #neurips #icml
Apr 27

🚀 Excited to share our ACL 2026 paper ReviewGrounder: AI peer review that grounds feedback in rubrics, paper evidence, and prior work.
eigentom.github.io/ReviewGro…
arxiv.org/abs/2604.14261
🤖 ReviewGrounder is a rubric-guided, tool-integrated multi-agent reviewer: specialist agents examine the paper, search related work, check evidence, and synthesize grounded feedback.
💡 The core idea:
Give LLMs two things human reviewers rely on — explicit rubrics and contextual grounding in the literature.
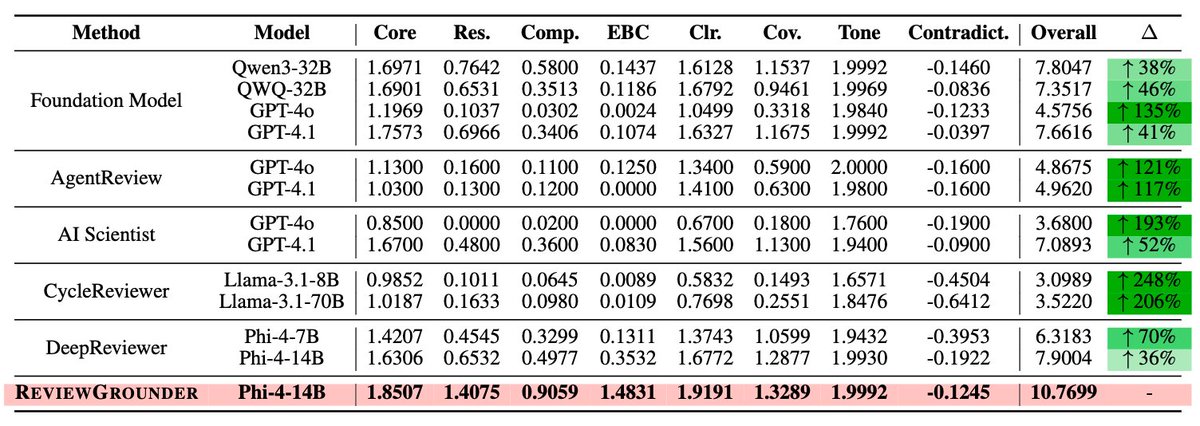
📈 The result:
ReviewGrounder outperforms top baselines:
41% over GPT-4.1
135% over GPT-4o
🎯 Evaluated across 8 rubric-based review quality dimensions
Try it yourself!
🧠 Code: github.com/EigenTom/ReviewGr…
💻 Demo: huggingface.co/spaces/Review…
#agentic #LLMs #MultiAgent #tooluse #PeerReview #AcademicAI

1
1
3
500

Apr 26
Dream Server - some new updates will be coming soon
Using Hermes-agent to create anything, including based on Kanban MultiAgents.
@The_Only_Signal @Teknium @NousResearch
1
2
17
694