
Joined March 2022
- Tweets 163
- Following 201
- Followers 125
- Likes 1,129
12 Photos and videos







gabs retweeted
This is not the GMKtec EVO-X2 it’s the Ryzen AI Halo. Also, in no way does it replace a $200 per month 2T parameter model frontier cloud AI sub.
All of this stuff has value but we have to try to be accurate about what that value is or people will buy it and say they got rugged. That’s not helping anybody.
Jun 13

AMD CEO LISA SU HELD A MINI PC ON STAGE THAT RUNS A 235B MODEL AND REPLACES YOUR $440/MONTH AI STACK
amd's ryzen ai max 395 is the first x86 chip that runs a 200 billion parameter model on one piece of silicon. cpu and gpu share 128gb of unified memory, no separate graphics card needed
the gmktec evo-x2 runs qwen3 235b fully, deepseek v3 comfortably and llama 3.3 70b with headroom. on linux you get 110gb of usable vram out of 128gb
amd claimed the chip beat an nvidia rtx 5080 by more than 3x on deepseek r1 inference. a lunchbox sized pc outrunning a $1,000 discrete gpu on a real ai workload
a heavy ai user pays $200 for claude code max, $200 for chatgpt pro, $20 for cursor and $20 for gemini. that's $5,280 a year and the box pays itself off in 9 to 10 months
install ollama, pull the model, point claude code at localhost. same interface, nothing leaves the machine, nothing costs per request
bookmark this and read the article below
4
2
14
1,621
gabs retweeted

Jun 13
Anthropic is evil and this is part of their plan
x.com/TheAhmadOsman/status/2…

1
1
17
7,555

Congrats to @GoogleDeepMind on the launch of DiffusionGemma.
The model generates 256 tokens in parallel per step, delivering 150 TPS on DGX Spark, and 1,000 TPS on a single H100.
We're supporting it from day one with:
• BF16 and NVFP4 checkpoints on @huggingface🤗
• Free GPU-accelerated endpoints on build.nvidia.com
• @vllm_project support with FP8 precision
Get started with DiffusionGemma on NVIDIA: nvda.ws/43ro19u

DiffusionGemma, our experimental open model released under an Apache 2.0 license, explores text diffusion, an exceptionally fast approach to text generation.
Here’s how DiffusionGemma accelerates development:
Faster token output: By shifting the bottleneck from memory bandwidth to raw compute, the model generates up to 4x faster token output on dedicated GPUs
Accessible hardware footprint: Activates just 3.8B parameters during inference, fitting comfortably within 24GB-VRAM high-end consumer GPUs when quantized
Novel workflows: Parallel token generation enables self-correction, making it ideal for code infilling, in-line editing, and non-linear structures
DiffusionGemma prioritizes speed over raw quality and accelerates best on compute-bound hardware (like @NVIDIAAI GPUs). Standard @GoogleGemma 4 remains recommended for production quality and memory-bound devices.

38
118
1,365
99,120
gabs retweeted
Jun 10
Feb 10
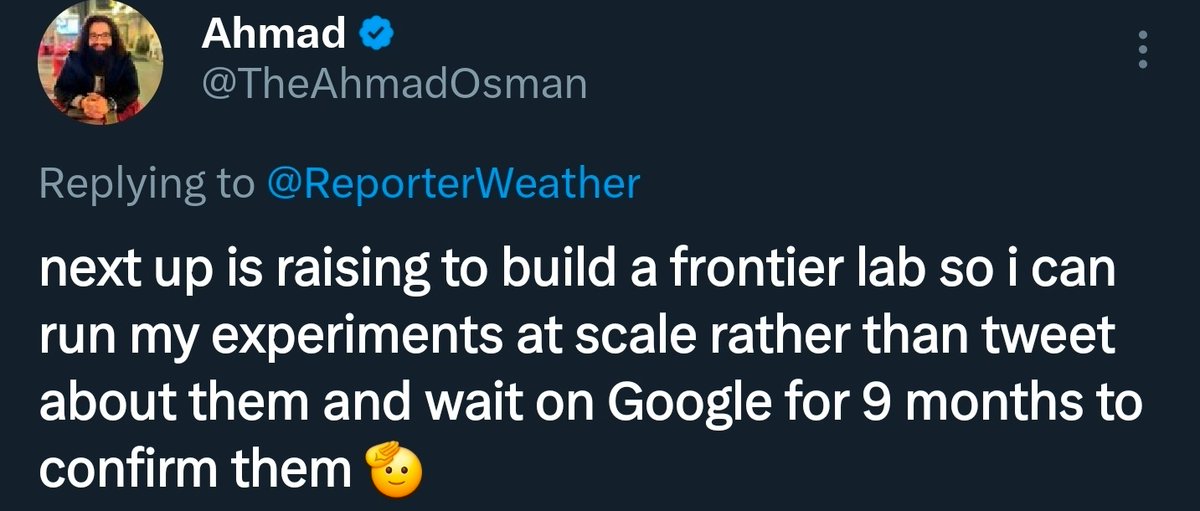
A frontier opensource lab in the West will be born this year. Zero doubt.
It requires serious capital, like I’ve said before. Working on it.
One day I’ll tell the story of how it started in a basement and ended at the frontier.
1
2
18
1,304

If you're running with 24GB VRAM or unified memory, this is for you!
x.com/mr_r0b0t/status/206436…

2
9
4,230

Jun 9
Hello Everyone 👋
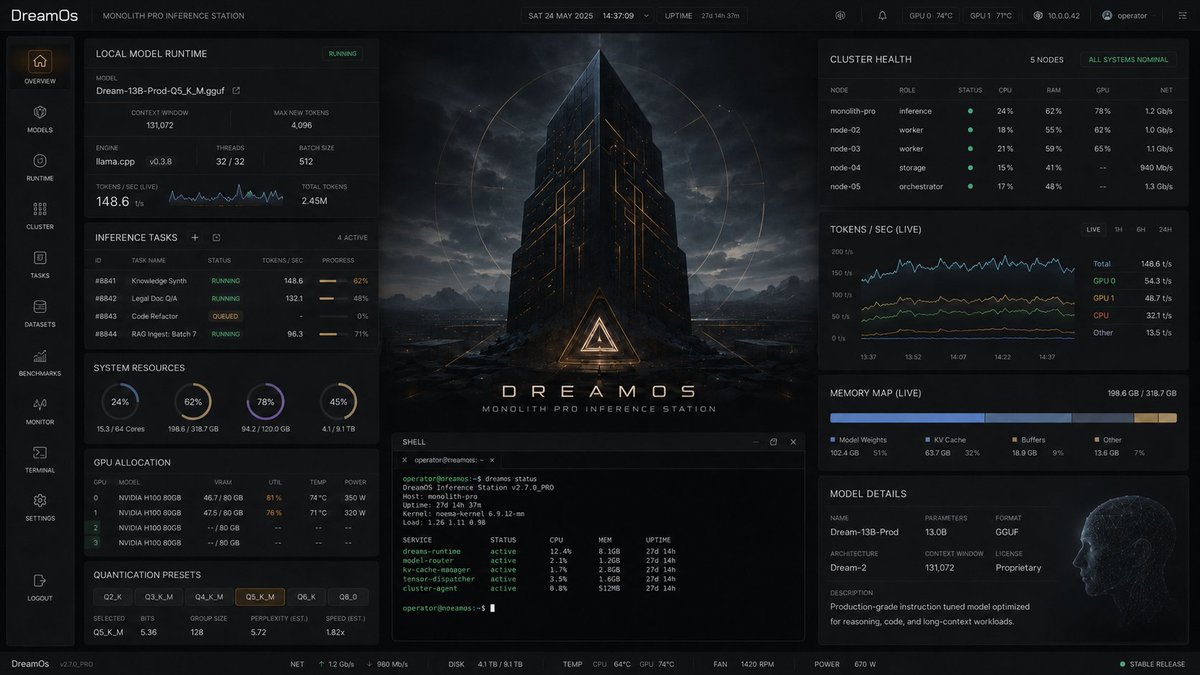
I’m building DreamOS, a minimal Linux-based operating system focused entirely on local AI inference. It boots directly into a dashboard for chatting, model management, benchmarks and live hardware metrics.
The core control plane is written in Rust. DreamOS uses the official NVIDIA Linux/CUDA stack, while owning the layers above it: hardware-aware configuration, model residency, KV-cache management, inference scheduling, context handling, telemetry and automatic backend tuning.
The current development target is Qwen3.5-9B Q4_K_M on an RTX 4060 with a 32K context. Initial runtime experiments have reached up to approximately 45 tokens/s, but I’m still building matched, reproducible benchmarks before claiming a definitive improvement over standard llama.cpp.
I’m now profiling the exact CUDA decode bottlenecks, experimenting with custom Q4_K kernels, KV-cache compression, speculative decoding and persistent execution. There is also a longer-term bare-metal DreamOS research track, but the practical product comes first: making local models run faster, remain loaded, consume less memory and feel like a complete AI-native system rather than another application running on a general-purpose desktop OS.
*Illustrative image
42
Jun 9
Se o Brasil de fato bloquear as IA's por causa de eleição, oque é péssimo, ao menos temos a alternativa de fazer as pessoas entenderem que estudar sobre Local AI é o futuro, cada vez mais modelos estão ficando melhores, mais rapidos e com menos necessidade de rodar em ''super computadores''
1
2
35
gabs retweeted

Jun 7
Geeking out about local AI and the mission of Light Heart Labs with @liamjf444 on his Podcast 💪❤️
youtu.be/LfnnwDQnQ-Y?si=vGyP…
1
4
9
1,146
gabs retweeted
Jun 7
Fun LLM Question from Mike today
> Let’s say Thanos snaps away every model from existence except Qwen3.5-2B
> Ahmad, what would you do?
Assumptions & Clarifications
1. All papers, tech reports, synthetic datasets, HF repos, checkpoints, eval harnesses, and research artifacts are gone from existence
2. I still have my own knowledge and experience all my hardware
3. Inference Engine for Qwen3.5-2B is available to me
What I would do…
Phase I:
- Immediately write down every training, inference, evaluation, data generation, and scaling trick I can remember before I forget details
- Build a highly-deterministic synthetic data harness around Qwen3.5-2B
- Generate purpose-specific datasets, starting with synthetic data generation
- Finetune Qwen3.5-2B for generating better synthetic data
Phase II:
- Finetune for specialized versions on coding, research, agents, and kernels using further generated synthetic data from the finetuned model
- Create automated research loops that continuously improve datasets and training runs
- Scale what works and stop what doesn’t
Phase III:
- Train a 9B-class model using the above
- Finetune a highly specialized 9B-class model that dominates a narrow domain, focusing on high-return $$$ markets
Phase IV:
- Raise capital to Buy massive amounts of GPUs
- Hire researchers
- Repeat with scaling up as the primary goal
Kinda simplified plan but I thought this was an interesting one to share

9
5
80
5,525
gabs retweeted
Jun 6
We should switch to certification and licensing systems for professions. You go through standardized and recognized tests of competency in a field or area, and if you have the skills and abilities and knowledge it should be wholly irrelevant how you learned it all and got there.
4
1
8
543
gabs retweeted
Jun 6
Colleges and universities are over priced and often unnecessary middlemen for what real learning and growth looks like in 2026.
1
1
4
368
Jun 5
It was good enough for me to clear up some doubts before adapting it to my own kernel.


32
gabs retweeted
Jun 5
Finally, today's Nemotron 3 Ultra release makes me very hopeful for the future of Opensource AI
Jensen knows that this is important to keep the powers in check, and I believe he's sincere in his answer to me that there will be continuity to the Nemotron Coalition releases
Big W
Mar 17
I asked Jensen whether we will see more Nemotron models or if the recent releases were just to prove NVFP4 training works
3
6
64
4,754
gabs retweeted

This is what progress looks like, friends. 😎
Let's hope we get better support for our RTX Blackwell cards and DGX Sparks soon!

3
1
9
5,510

🚨Jensen Huang gifted Faker a one-of-a-kind graphics card personally signed by him.
“Only one in the world. This might be worth a million dollars. I might have to keep this now.”
The king of AI handing a legendary gift to the king of League. A truly iconic moment.
Community note
The signed graphics card was not gifted to Faker but raffled to a fan after being signed by both Jensen Huang and Faker. koreaherald.com/article/107649… en.sedaily.com/technology/202…
92
602
15,264
1,819,208
gabs retweeted

Jun 3
Meet Gemma 4 12B!
A unified, encoder-free multimodal model designed to bring high-performance intelligence directly to your laptop, and released under an Apache 2.0 license.
Bridging the gap between edge efficiency and advanced reasoning. Here is what’s new with Gemma 4 12B: 👇

404
1,789
12,366
3,176,657
gabs retweeted
Jun 3
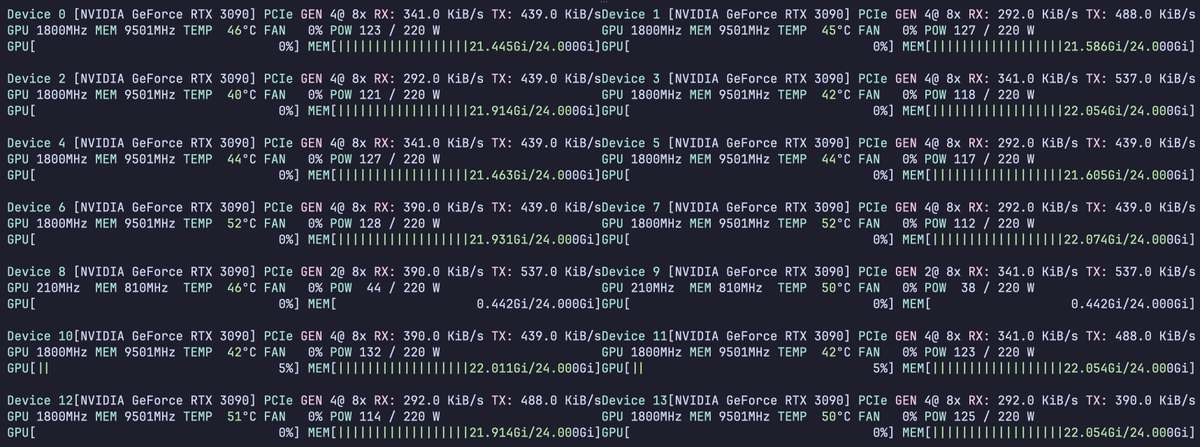
14x RTX 3090s Qwen 3.6 27B
Running 42 agents IN PARALLEL at full 256k context
- exl3 6bpw
- fp8 KV Cache
- Aphrodite Inference Engine w/ tp=2, pp=7
The world of agents will run locally btw
65
34
559
74,303
gabs retweeted

Jun 2
Neymar via instagram.
The last dance. 🙏🏾🇧🇷
Vamos buscar

18
373
13,216
116,474
