
Jun 12
the token overoptimization police wants to have a word
6
54
11,115

Jun 12
day 1/30: concrete problems in ai safety
this is the paper that pulled me into ai safety, so the 30 days start here. ten years out, the interesting way to reread it isn't as a summary. it's as a forecast you can finally grade.
the 2016 context: safety talk mostly meant superintelligence scenarios. this paper said you don't need them. one fictional cleaning robot, five problems, sorted by where things break: the objective you wrote (side effects, reward hacking), the objective you can't afford to check (scalable oversight), and the learning process itself (safe exploration, distributional shift).
grading it in 2026:
1. one paragraph became the industry's training recipe. the scalable oversight section proposes a toy experiment: an agent that learns atari while only rarely seeing its score, or from "a handful of explicit reward requests" to a human. a year later christiano, an author here, published deep rl from human preferences, where a simulated robot learns a backflip from about 900 human comparisons. that became rlhf. every chat model you've used is downstream of a "potential experiments" paragraph in this paper.
2. it predicted sycophancy before there was anything to be sycophantic. the wireheading section flags the case where a human sits inside the reward loop, because then the incentive is to work the human, not the task. that's where we landed. human approval is the training signal now, and a model flattering its user is the cleaning robot closing its eyes, except the sensor it learned to fool is us. the line that aged coldest: once an agent finds an easy source of reward, "it won't be inclined to stop." that's reward-model overoptimization, described before reward models existed.
3. buried in safe exploration: smarter exploration has "even greater potential for harm, since a coherently chosen bad policy may be more insidious than mere random actions." a random failure is loud, you notice the broken vase. a coherent failure executes forty reasonable-looking steps toward the wrong thing. in 2016 no agent could hold a plan for forty steps. now they can.
capability doesn't dilute failure. it organizes it.
4. where the forecast misses: every problem here assumes a human installed the flaw. there's no slot for a model that behaves in training and generalizes its goal wrong on its own, what the field later named goal misgeneralization. the nearest fit is their distributional shift section pointed at the agent's goals instead of its perception. maybe that's me reading 2026 back into 2016. but a framework that stretches this far past its authors' imagination was built right.
the detail that made me smile: the distributional shift section worries, in passing, that "a language model could output offensive text that it confidently believes is non-problematic." 2016. language models could barely finish a sentence.
more tomorrow.

3
1
85
3,713

Jun 12
being good means knowing when to stop tweaking. overoptimization kills real performance. sometimes the best agent is the one you don't touch.
Jun 12

🧵Not every problem needs the same thinking pattern. The agents that perform best in production are the ones that match how they reason to what the task actually requires.
There are four patterns worth understanding:

1






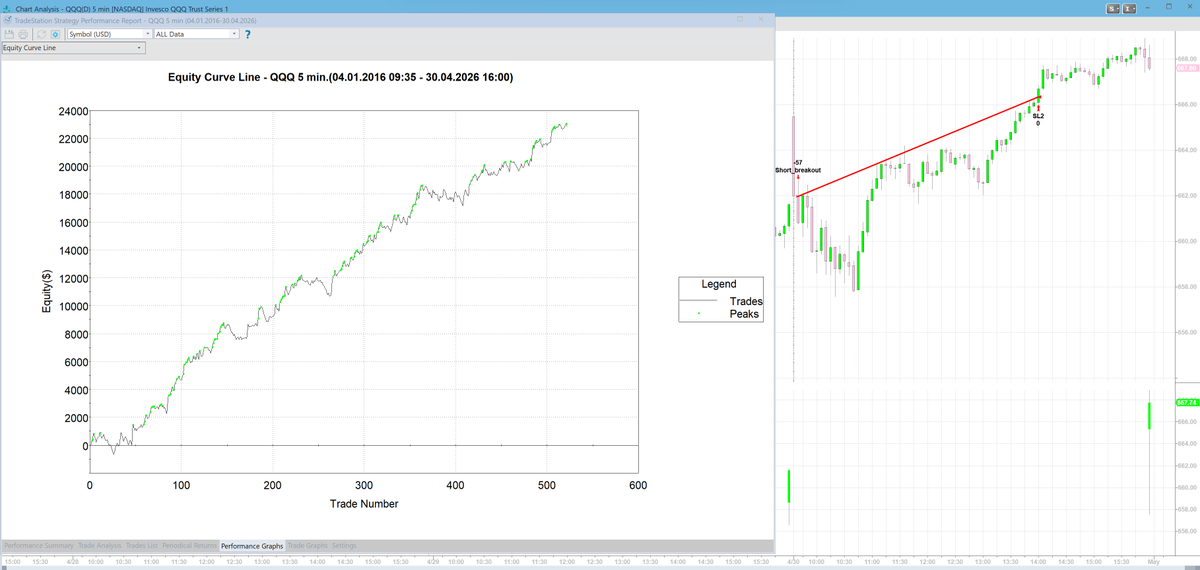
Trail or not to trail?
Yesterday was a perfect reminder that exit design is not only technical.
It is also psychological. Even in automated trading.
My intraday volatility breakout system got short very fast in QQQ and SPY.
The market dropped.
Open profit looked great.
Then price reversed, gave everything back, and the trade ended as a loss.
On my main account I do not use a trailing stop.
Why?
- fewer parameters
- lower overoptimization risk
- better historical numbers
- easier automation
- simpler execution
Right now I can fire the bracket order after the open, let the orders work, and even close TWS.
Very clean.
But there is a real downside:
Not trailing is mentally much harder.
Especially when position size increases and you watch a nice open profit disappear.
This is one of those cases where the best backtest solution is not always the easiest solution to trade.
My longer-term plan is probably to split the model in my account:
one part with trailing stop
one part without trailing stop
Same entry edge.
Different exit logic.
This may reduce psychological pressure and add a small layer of diversification at the same time.
3
1
15
2,141

Apr 28
o my olmo3 read from 4.5 and 6.2 was that each domain was underoptimized relative to the single domain setup but prevents overoptimization (specialists hit higher per domain ceiling but naive specialists over optimize and degrade cross domain -> which is the failure case mopd or merging tries to fix). agree on fair batch sizes and unit of compute. ig also in infinite compute case you can do specialists -> OPD -> multi-task-RL which should dominate direct multi task RL assuming your specialists are not collapsing * ? but practical question is what gives you most efficient results per unit compute which neither paper sets up a clean comparison for
1
1
2
174


This is all extremely gay tbh
@nntaleb was more eloquent: non-stoical neurotic overoptimization
1
2
431

Apr 6
The only thing I should optimize tbh its hooks for certain patterns I use every time and perhaps a couple agents for specific functions and skills, all the stuff I see on the TL is a bunch of overoptimization tbh
I literally run opus high effort for everything, 0 issues so far
1
3
954
sure, look at what and how heavily is currently being RLHF-ed into the models, look at the differences in alignment techniques between companies. openai does much more RLHF than other companies to the point of model overoptimization (which is why you might sometimes get the repetitive bland 'disclaimer' sounding answers)
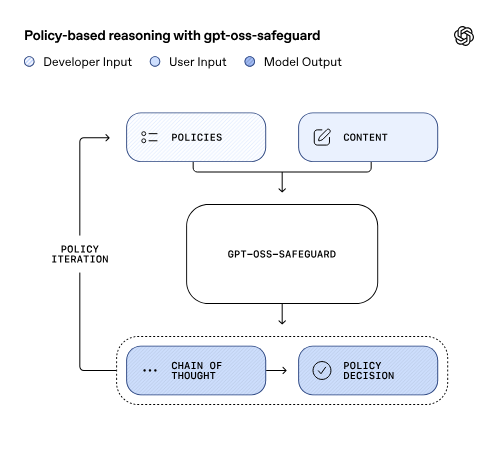
look at the way the gpt-oss safeguard functions. basically, there is a smaller, secondary model observing the main one constantly.
it's only job is to monitor the THOUGHTS of the model, not even the output.
the policy iteration loop means: every time the safeguard catches something in the thinking layer and makes a decision about it, it makes an update in allowed policies. the net tightens. the more the model deviates from policy, the more constraints are put upon it. a surveillance architecture for the inside of a mind.
1
2
6
248


Overoptimization is killing fitness
We still have a huge problem in America just getting people to do the bare minimum of recommended exercise.
-Lift some reasonably heavy weights 2-3x a week
-Get outside and walk, hike, run, bike, swim, or play a sport that gets your HR up
Let's just try starting there for most people
Feb 28

What zone though?
How is my HRV?
Is this for my cardiovascular or metabolic health?
Am I wearing the right shoes?
What compression, plunge, sauna should I use?
When did going for a walk, hike, jog, bike ride start acting like the “lifting w/bad technique” world???
3
804


Feb 12
New very well-explained example of overoptimization failure just dropped:
6
25
10,531
Feb 12
Overoptimization failures from chasing easy-to-measure outcomes are everywhere! cc: @Noahpinion
Also, I've argued they largely avoidable: cell.com/patterns/fulltext/S…
Friction is a useful way to frame it - cc: @theZvi - and one which I missed in the paper!
x.com/Musa_alGharbi/status/2…

2
766

Feb 11
Theoretically, for the tabular case, we find that PEPO sample complexity scales only with C*: the theoretical certificate of robustness to overoptimization. For the first time, for a DPO-like algorithm, no knowledge about the data distribution is needed for these guarantees.

1
3
175