haha, I mean, I get it, if the most common issue is something like "when calling an endpoint check providers.md for runtime information, you are expected to load models yourself"
That's great, positive prompting works best in my experience.
Negative prompting is never ending, and most of the time when you're editing page formatting or something the last thing it needs to know is
"Do not use pdf.default
Do not use PDFParser
Do not manually decompress streams"
The same way your model magically becomes more coherent when you say something like "you're a senior engineer" is why it can also become worse when you prime the tokens for the things you DONT want.
"DONT THINK ABOUT ELEPHANTS"
54

PrinsFrank/PDFParser now supports encrypted documents!
laravel-news.com/link/17946
4
313

9 Dec 2025
I love exact-match domains. I’ve got:
testimonial .to (ranks #1 for “testimonial”)
pdf .ai (ranks #1 for “pdf ai”)
And now I just added pdfparser .com to my collection ✌️
37
1
171
33,076

8 Dec 2025
🚨CVE-2025-66516: Critical XXE in Apache Tika tika-core (1.13-3.2.1), tika-pdf-module (2.0.0-3.2.1) and tika-parsers (1.13-1.28.5) modules on all platforms allows an attacker to carry out XML External Entity injection via a crafted XFA file inside of a PDF.
Scanner: github.com/Ashwesker/Blackas…
CVSS: 10
Vendor/Product: Apache Tika
Affected modules:
▪️Apache Tika Core: org.apache.tika:tika-core versions 1.13 through 3.2.1
▪️Apache Tika Parsers: org.apache.tika:tika-parsers versions 1.13 before 2.0.0, In 1.x releases, the PDFParser was bundled in this module.
▪️Apache Tika PDF Parser Module: org.apache.tika:tika-parser-pdf-module versions 2.0.0 through 3.2.1
Advisory: lists.apache.org/thread/s5x3…

2
18
106
11,954

28 Aug 2025
Argonne's AdaParse: PDF Processing for Scientific AI Training
wp.me/p3RLHQ-peL
@argonne @ENERGY #AIforscience #AI #HPC #PDFparser
2
270

30 Jun 2025
Horizontally split tables across pages? No problem for OCRflux! It recognizes and merges them seamlessly into one page.
Check out👇
Try demo: 2ly.link/27e87
#OCR #pdfparser #pdftomarkdown #OCRFlux #opensourceai
3
400
27 Jun 2025
😩Extract tables from PDFs = pure pain? Not anymore! OCRFlux transforms cross-page tables into structured ones, perfectly preserving layouts and auto-removing duplicate headers.
Check out the comparison between olmOCR and OCRFlux 👇
Or try it at: 2ly.link/28rzz
#OCRFlux #ocr #OpenSource #PDFparser #olmOCR
2
5
466
25 Apr 2025
📢 ChatDOC PDF Parser Update – April 23
🥳We are pleased to announce a new output option for the ChatDOC PDF Parser API: Markdown format is now supported, in addition to JSON.
This enhancement enables developers to directly obtain well-structured Markdown content from PDF documents — ideal for integration into technical documentation, wikis, and publishing workflows.
Learn more and get started: [api-reference.chatdoc.com/#t…]
#ChatDOC #PDFParser #Markdown #APIupdate #Developers
1
4
280

25 Mar 2025
【Writer社がLangChain統合を発表、AIモデルとツールが利用可能に】
Writer社のAI機能がLangChainエコシステム内で利用できるようになりました。`pip install langchain-writer`でインストール可能で、Python 3.11以上とWriter AI Studioアカウントが必要です。
この統合により、`ChatWriter`クラスを通じてPalmyraモデルによるテキスト生成が可能になり、ストリーミング、非ストリーミング、バッチ処理、非同期操作をサポートしています。
Palmyra X 004以降のモデルではTool Calling機能も利用可能で、以下のツールが提供されています:
- `GraphTool`: Knowledge Graphからの情報取得
- `NoCodeAppTool`: WriterのNo-codeアプリケーションをLLMツールとして活用
- `LLMTool`: 医療、金融、クリエイティブなど特定分野のWriterモデルに処理を委任
また、ドキュメント処理のための機能として:
- `PDFParser`: PDFからのテキスト抽出
- `WriterTextSplitter`: 文書を意味的にまとまりのあるチャンクに分割(`llm_split`、`fast_split`、`hybrid_split`の3つの分割戦略をサポート)
1
2
17
2,569

Not really . Structuring is an issue.
While working on a project recently,I was extracting data from ncert pdfs and the data wasn't structured at all, lines getting jumbled etc. (especially tables) etc.
Ended up using a pdfparser and used gemini to restructure and format the data
1
3
49

11 Feb 2025
将PDF分割成整洁的、机器可读的文本块,对于任何RAG系统来说都是一个巨大的难题。开源和专有解决方案都存在,但没有一个真正实现了准确性、可扩展性和成本效益的理想结合。ChatDOC 团队推出的PDFparser 性能远超其它同类产品pdfparser.io/?src=luckyleepd…,兼具效果、速度、性价比的三种优势。🥳🙋♀️
2
5
797
7 Feb 2025
💥How to Use DeepSeek with ChatDOC for PDF Analysis?
👾Utilize ChatDOC with DeepSeek. Configure API, analyze PDFs precisely. Multi-doc support. Switch models easily.
Ready to get started? Here's a quick guide on how to set up DeepSeek in ChatDOC! 👇
#ChatDOC #ChatDOCPDF #ChatPaper #PDFParser #ChatDOCAPI #ChatPDF #arXiv #PDFRAG #PDFAI
1
2
273

16 Jan 2025
🚀Exciting news! ChatDOC PDF Parser is now available!
Transform your document processing with:
🔹Accurate table extraction
🔹Complex format handling
🔹JSON output
🔹Simple API integration
🔥Try it now: pdfparser.io/
#PDFParser #Developertools #API #PDFAI #LLMRAG #RAGPDF
3
238

8 Nov 2024
Using Nix to Fuzz Test a PDF Parser (Part One) # FuzzTesting #Nix #PDFParser #Honggfuzz #Workflow mtlynch.io/nix-fuzz-testing-…
16
39
2,485

25 Aug 2024
PHP | 様々な形式のファイルからテキストデータを取得する方法
analyzegear.co.jp/blog/2720
#PHP #PHPWord #PhpSpreadsheet #PHPPresentation #PdfParser #アナライズギア #analyzegear #AG
3
51


pdf-parse(node)を利用したPDFの文字パーサー、
どうやら文字コードくさい。
一旦PDFをWordにして、文字スタイル等を揃えてPDF化し、パースしたらできた。
GoogleAPIだとCloudStrage必要なので使いたくない。
クライアントにどう伝えるべきか…
#PDF #PDFparser #PDF文字読み取り
1
2
155

27 Jul 2023
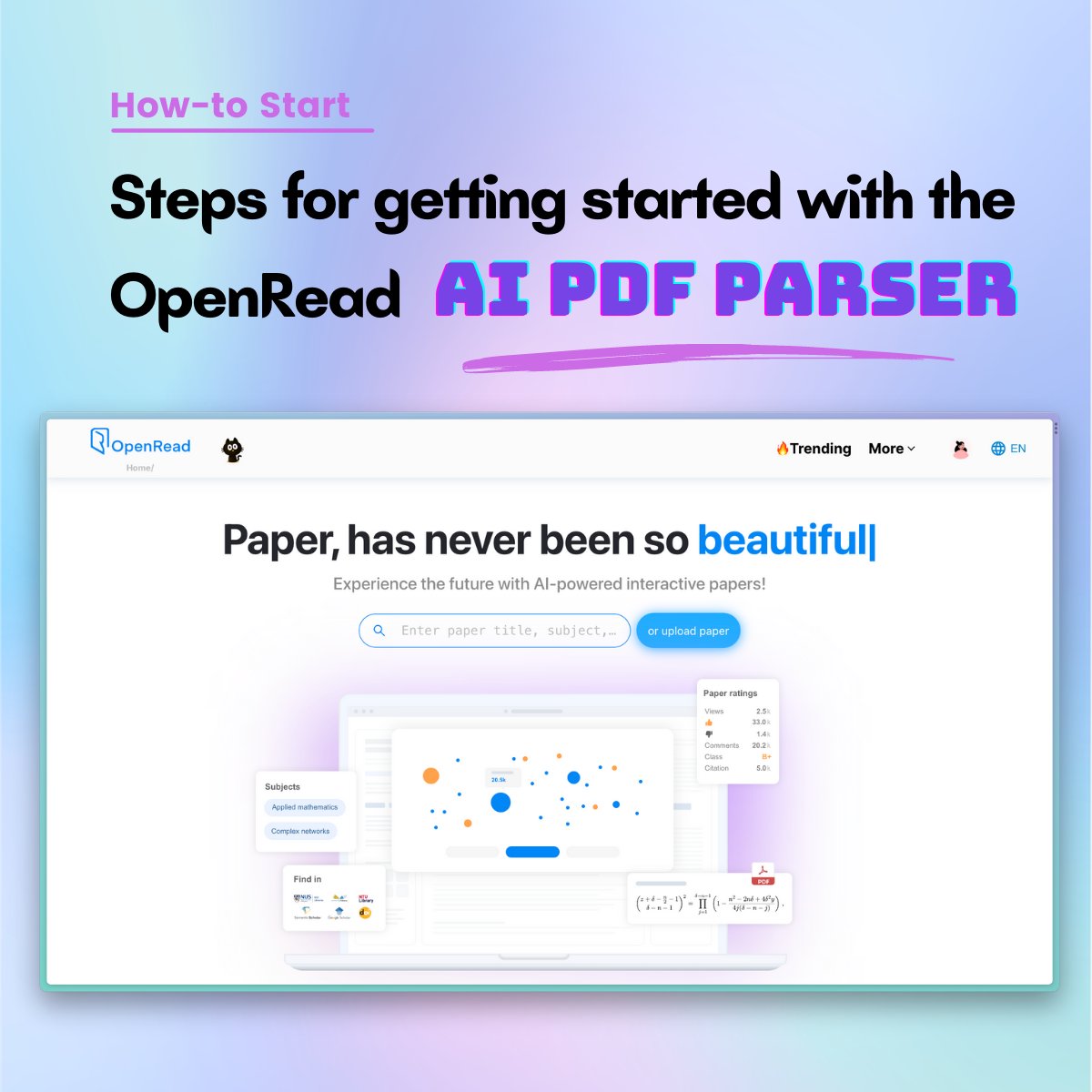
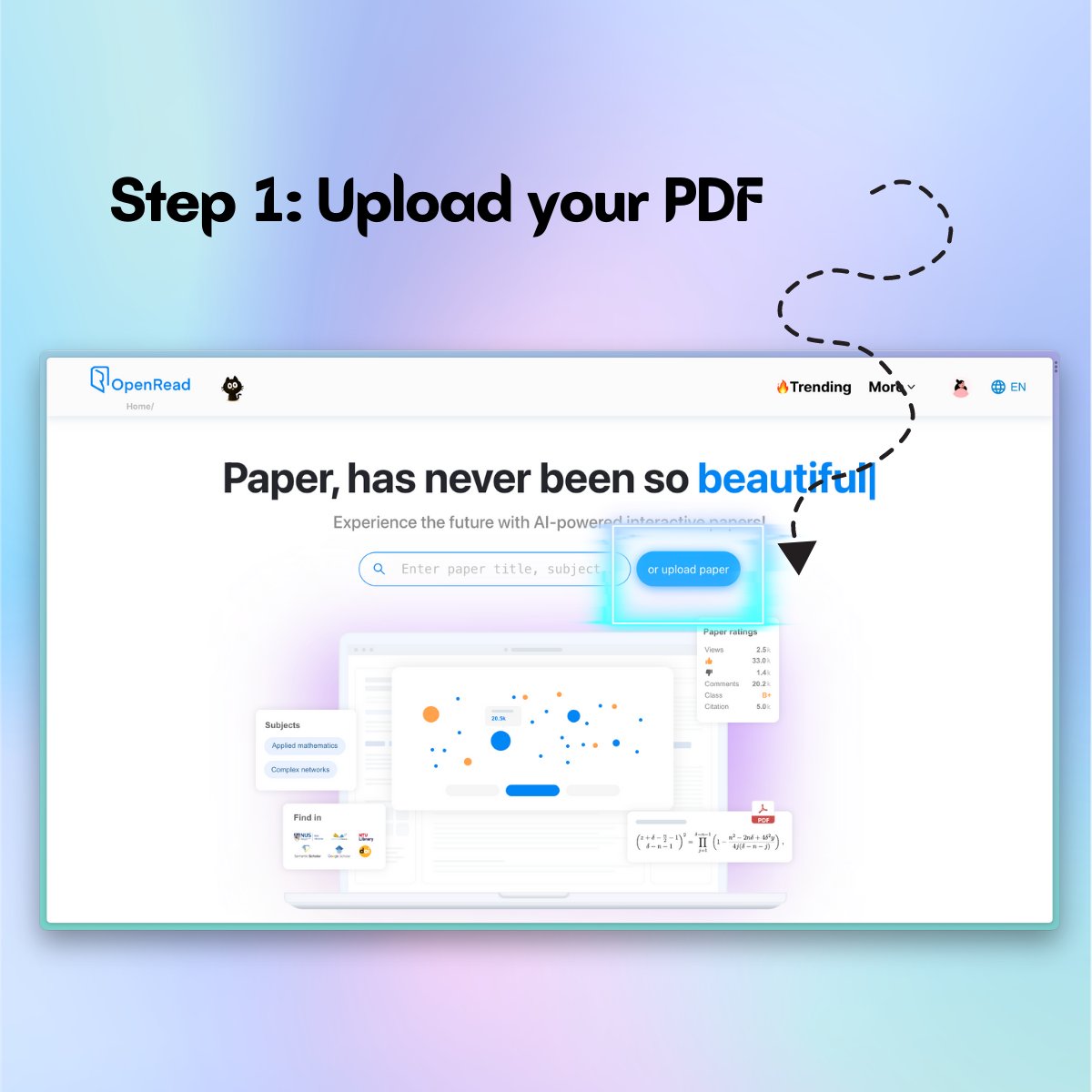
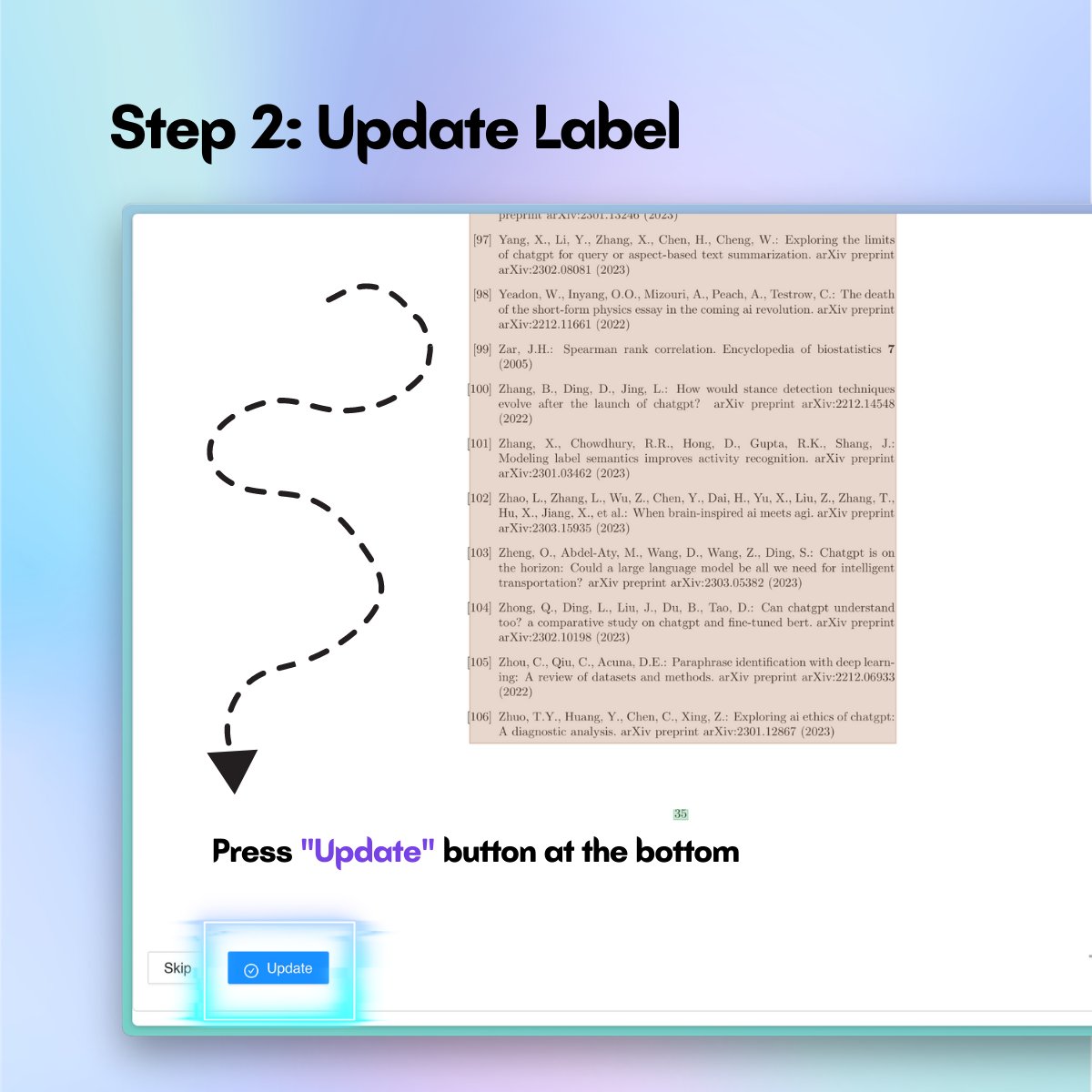
PDF reader again? BORING!
Oh, but you use #AI to parse PDF papers and turn them into #interactive #papers? That's more interesting 🎉
Use OpenRead's double-column PDF parser to ask questions and take notes to increase your #reading #efficiency.
Try OpenRead for #free now: openread.academy/
Here are simple steps to get started! ⬇️
#paperparser #pdfparser #efficiency #research #notetaking #gpt #gpt4

3
53
40
12,202