
Jun 13
📊 ドル円週足予測(2026年6月13日現在)
📈 予測値:160.79円(±1.00円)
🔮 モデル:RandomForest(週足特徴量 × 200本ツリー)
📅 直近週足終値:160.24円(2026年6月13日)
🔍 バックテスト(直近8週)
MSE(平均二乗誤差):0.035
MAPE(平均絶対誤差率):0.24%
⚠️ 注意点
データ取得:Investing.comの週足終値データを使用
モデル構築:Python(scikit-learn, ランダムフォレスト)+特徴量エンジニアリング
予測期間:2026年6月13日現在のデータに基づく予測
🔗 詳細データ取得先:
Investing.com USD/JPY Historical Data
📌 ご注意:本予測は研究目的であり、投資判断の参考としてご利用ください。市場の急変動や突発的なニュースには対応していません。自己責任でのご利用をお願いいたします。

1
52

Jun 7
6 Best ML Libraries Top Quant Traders Use to Exploit Model Bias on Polymarket (Full Quant Stack)
Most bots on Polymarket still operate as simple reactive systems - they treat public forecasts as the ultimate truth
Top quant traders have moved far beyond that. Instead of relying on public models and third-party forecasts, they build meta-models that actively hunt for and exploit the systematic biases and weaknesses in those forecasts
Here’s the actual list of libraries that top quants are using right now:
1. LightGBM - The Go-To Workhorse
• Extremely fast gradient boosting with leaf-wise tree growth
• Handles hundreds of features effortlessly (raw forecasts historical bias corrections sentiment volume)
• Repo: github.com/microsoft/LightGB…
2. XGBoost - The Reliable Veteran
• Classic gradient boosting with strong regularization
• Excellent GPU support and best-in-class SHAP explainability
• Repo: github.com/dmlc/xgboost
3. HistGradientBoosting (scikit-learn)
• Powerful histogram-based boosting built directly into sklearn
• Best choice for fast prototyping and experimentation
• Repo: github.com/scikit-learn/scik…
4. RandomForest (also sklearn)
• Solid baseline to quickly check if your features actually have signal
• Repo: github.com/scikit-learn/scik…
5. TabNet
• Neural network architecture designed specifically for tabular data
• Great at combining text embeddings (news/tweets) with numerical features
• Repo: github.com/dreamquark-ai/tab…
6. River
• Best library for online/incremental learning
• The model learns and adapts in real time - essential for fast-moving events
• Repo: github.com/online-ml/river
Recommended 2026 Stack: LightGBM (main model) XGBoost (stacking) River (online adaptation)
All of these libraries work great with SHAP - so you don’t just get a probability, you actually see which model bias you’re currently profiting from
Bookmark this post so you don’t lose it!

Jun 5

Stanford just dropped the exact linear regression math that prints millions on Polymarket weather markets
1 hour 48 minutes. free. straight from Stanford
bookmark & watch - this is the most honest “how real weather models actually work” lecture ever published
forget the "AI weather bot" YouTube grifters. this is the classical foundation meteoblue (swiss weather service) uses: probabilities instead of point forecasts, decades of bias correction, and why the market stays mispriced at 6¢
exactly why your decaying average MOS Kalman stack actually works. no hype, just edge
then start building your own bot using post below
10
7
47
3,499

Jun 7
Elon 的核心方法:读书 找人聊 快速迭代硬件/软件。以下是最简实操路径:
1. 读书(每天30-60分钟)
•用 Feynman Technique:读完一章立刻用自己的话写总结 小实验验证。
•推荐起步书:
◦火箭/工程:《Ignition!》《Structures》
◦AI/编程:Andrew Ng《Machine Learning Yearning》、Karpathy 视频系列
◦通用:《Zero to One》
工具:Notion 建卡片(左边书摘,右边“今天怎么用”)
2. 找人交流(每周3次)
•X/Twitter 回复技术帖,或发学习日志求反馈
•加入 Discord / Reddit(r/SpaceX、r/MachineLearning、r/rocketry)
•每周至少和1人私聊30分钟(LinkedIn冷邮件也行)
3. 快速迭代(每周至少1个小循环) ← 最重要!
软件路径(最易上手):
•Week 1-2:Python Kaggle 房价预测(Linear → RandomForest → Neural Net)
•Week 3 :做 Telegram 机器人 或 PyTorch 猫狗分类器
•每次迭代:跑通 → 优化 → 部署
硬件路径(预算<500元):
•买 Arduino / 树莓派入门套件
•项目示例:
1智能小车(避障 → 加摄像头AI)
2模型火箭 / 无人机零件设计(FreeCAD 3D打印)
•原则:Build → Test → Fail → Fix,周期控制在1-7天
4. 一周模板(直接执行)
•周一-三:读书 写代码
•周四:硬件组装测试
•周五:发帖求反馈
•周末:复盘失败点 规划下周
关键心态:前10次迭代几乎都会失败,没关系。Elon 的火箭也炸了很多次,重点是速度。
坚持3个月,你会把很多科班生甩在身后。

1,119

🌳🏙️🌳 #Urban #Tree #Species Identification Based on Crown #RGB Point Clouds Using #RandomForest and PointNet
✍️ Diego Pacheco-Prado et al.
🔗 brnw.ch/21x35pf
5
12
433
May 31
📊 ドル円週足予測(2026年5月30日現在)
📈 予測値:159.96円(±1.01円)
🔮 モデル:RandomForest(週足特徴量 × 200本ツリー)
📅 直近週足終値:159.39円(2026年5月30日)
🔍 バックテスト(直近8週)
MSE(平均二乗誤差):0.036
MAPE(平均絶対誤差率):0.24%
⚠️ 注意点
データ取得:Investing.comの週足終値データを使用
モデル構築:Python(scikit-learn, ランダムフォレスト)+特徴量エンジニアリング
予測期間:2026年5月30日現在のデータに基づく予測
🔗 詳細データ取得先:
Investing.com USD/JPY Historical Data
📌 ご注意:本予測は研究目的であり、投資判断の参考としてご利用ください。市場の急変動や突発的なニュースには対応していません。自己責任でのご利用をお願いいたします。

2
112
May 16
📊 ドル円週足予測(2026年5月16日現在)
📈 予測値:159.02円(±1.03円)
🔮 モデル:RandomForest(週足特徴量 × 200本ツリー)
📅 直近週足終値:158.46円(2026年5月16日)
🔍 バックテスト(直近8週)
MSE(平均二乗誤差):0.037
MAPE(平均絶対誤差率):0.25%
⚠️ 注意点
データ取得:Investing.comの週足終値データを使用
モデル構築:Python(scikit-learn, ランダムフォレスト)+特徴量エンジニアリング
予測期間:2026年5月16日現在のデータに基づく予測
🔗 詳細データ取得先:
Investing.com USD/JPY Historical Data
📌 ご注意:本予測は研究目的であり、投資判断の参考としてご利用ください。市場の急変動や突発的なニュースには対応していません。自己責任でのご利用をお願いいたします。

2
182

May 15
Random Forest 🌲🌲🌲
One Tree is smart.
100 Trees together are GENIUS. 🔥
FREE lecture PDF from Harvard University 👇
Link:drive.google.com/file/d/1_JC…
Follow @AnkanXplorer for more.😊🔖
#RandomForest #ML #DataScience
2
65

May 15
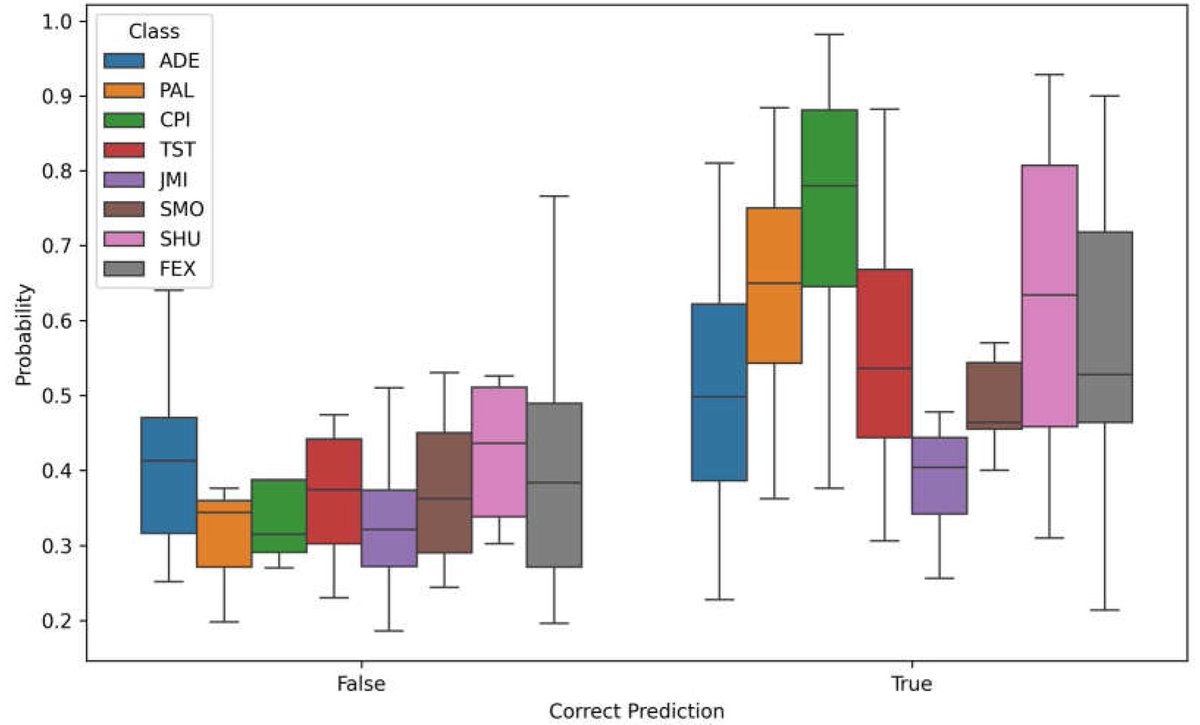
📢 #highlycited paper
📚 Phenology-Based Maize and Soybean Yield Potential Prediction Using #MachineLearning and Sentinel-2 Imagery Time-Series
🔗 mdpi.com/2076-3417/15/13/721…
👨🔬 by Dorijan Radočaj et al.
🏫 Josip Juraj Strossmayer University of Osijek
#phenologicalmodeling #randomforest
3
5
56

May 14
Built Credit Default Risk Prediction project to improve my ML understanding.
Deployed on Render 🚀
🔗 creditdefaultrisk.onrender.c…
[It takes 60 secs to work after 1st API hit]
Next step: SHAP-based explainability for better interpretation 🚀
#buildinpublic #AI #ML #RandomForest
1
3
57
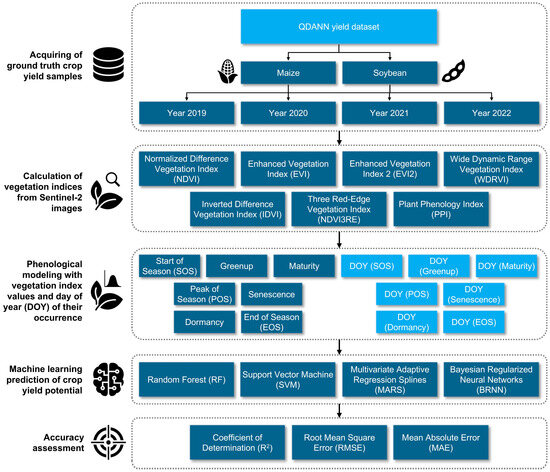
🌿🌿 Detection and Quantification of #Vegetation Losses with #Sentinel2 Images Using Bi-Temporal Analysis of #Spectral Indices and Transferable #RandomForest Model
✍️ Alicja Rynkiewicz et al.
🔗 brnw.ch/21x2siG
3
13
415

May 9
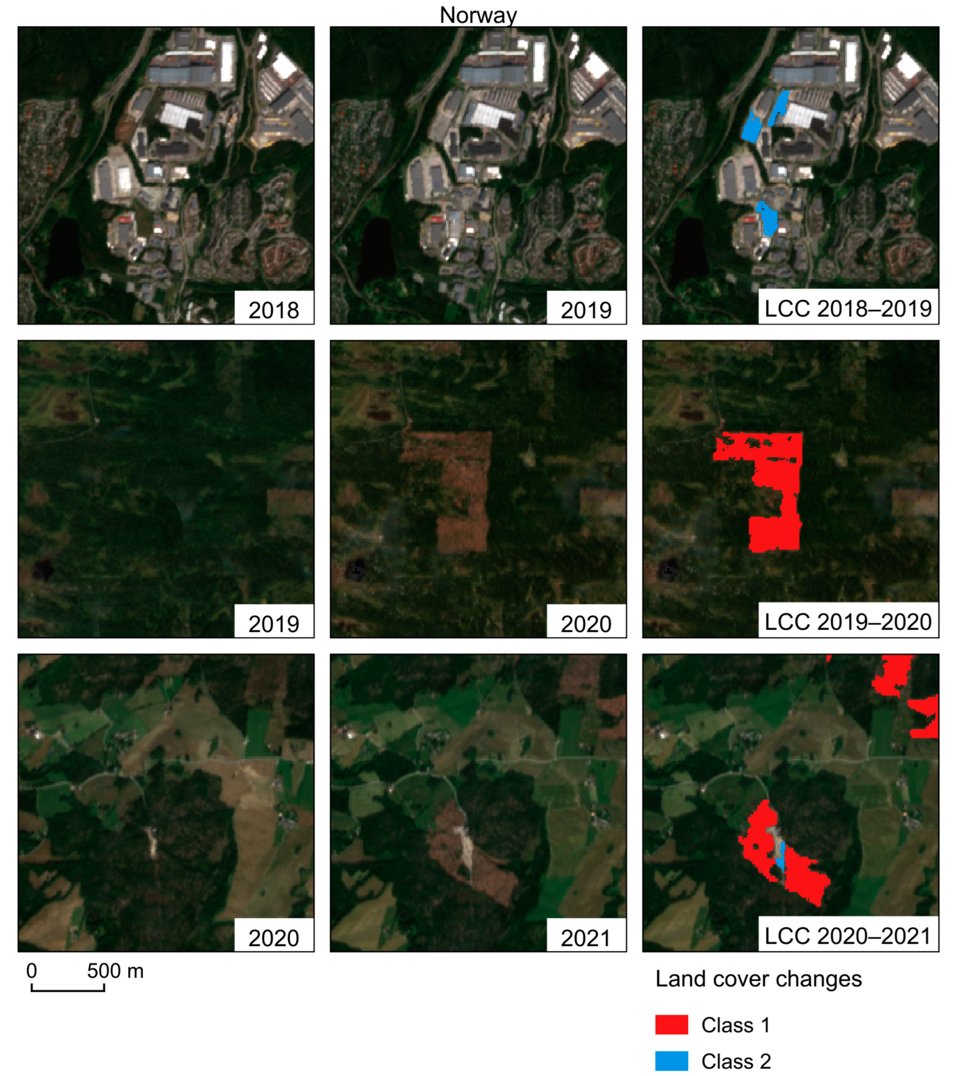
🏊♂️New Research on #SwimmingTalent Prediction using #MachineLearning 🤖📊✨
A prospective study in adolescent swimmers reveals a powerful random forest model to predict future elite performance! 🎯🏅
Key Insights:
✅ Longitudinal 3-year follow-up of 5,444 swimmers (ages 10-18) in China 🇨🇳
✅ Talented vs. average athletes show age- and sex-dependent differences in anthropometric & physiological traits 📏🩸
✅ #RandomForest algorithm outperformed 8 other ML models (AUC = 0.986) 🏆
✅ Top 5 predictors: abdominal skinfold, lung capacity, chest circumference, shoulder width, triceps skinfold 📐
✅ SHAP method used to interpret model decisions, enhancing trust in talent identification 🔍
📚Published by: Cheng Liu, Bingxiang Xu, Kang Wan, Qin Sun, Ruwen Wang, Yue Feng, Hui Shao, Tiemin Liu, Ru Wang
📅 Published in: 2024
📄 Full Study: doi.org/10.1007/s43657-024-0…
#SportsScience #TalentID #AIinSports #Physiology #Anthropometry #DataDriven #YouthAthletes 🚀
2
3
72

May 8
I don't think this makes sense tbh. The whole vision field before ML was full of heuristics, and that really only worked on toy data like MNIST. And nothing really worked.
Then it turned into heuristics ML, which half-worked to some degree. Things like HoG SVM or SIFT VBoW or Shotton's style of RandomForest (used in xbox)
But things only started working really well when also replacing the heuristics with learning too, ie DeepLearning.
And it's not because we didn't find the right heuristics or heuristics were hard to implement/maintain; over the course of a decade or so, a gazillion heuristics have been tried and published.
1
2
529

May 2
Yo aquí veo un RandomForest con n_estimators=50, max_depth=20, min_samples_split=5, min_samples_leaf=2 y max_features="sqrt"


3
65


Apr 25
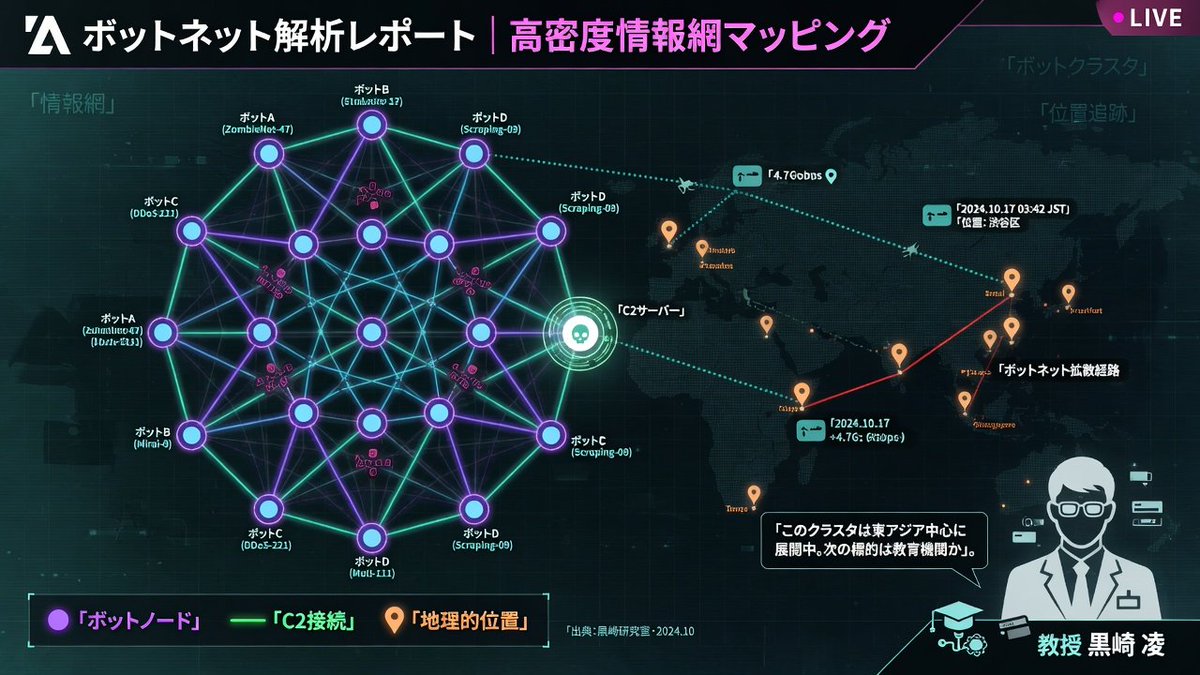
産経報道のホルムズ海峡関連SNS工作は、齋藤孝道教授のAIツール(RandomForestベースのボット検知+位置推定)により、60%超ボット活動とロシア関連起源を特定。典型的な認知戦手法でエネルギー不安を増幅。教授ツールは日本語最適化・影響工作アトリビューションに強く、Botometer等汎用ツールより実務適合性が高い。国民は一次情報確認を。
10
42
4,026

Apr 12
we tested 41 ML models for BTC price prediction. RandomForest was the ONLY model that survived forward testing (15.38% return, 8.68 Sharpe). BaggingClassifier showed 121% in backtest but lost money live. our system uses RF-style multi-indicator confirmation. robustness > flashy backtests. commutatio.ai
3
4
64
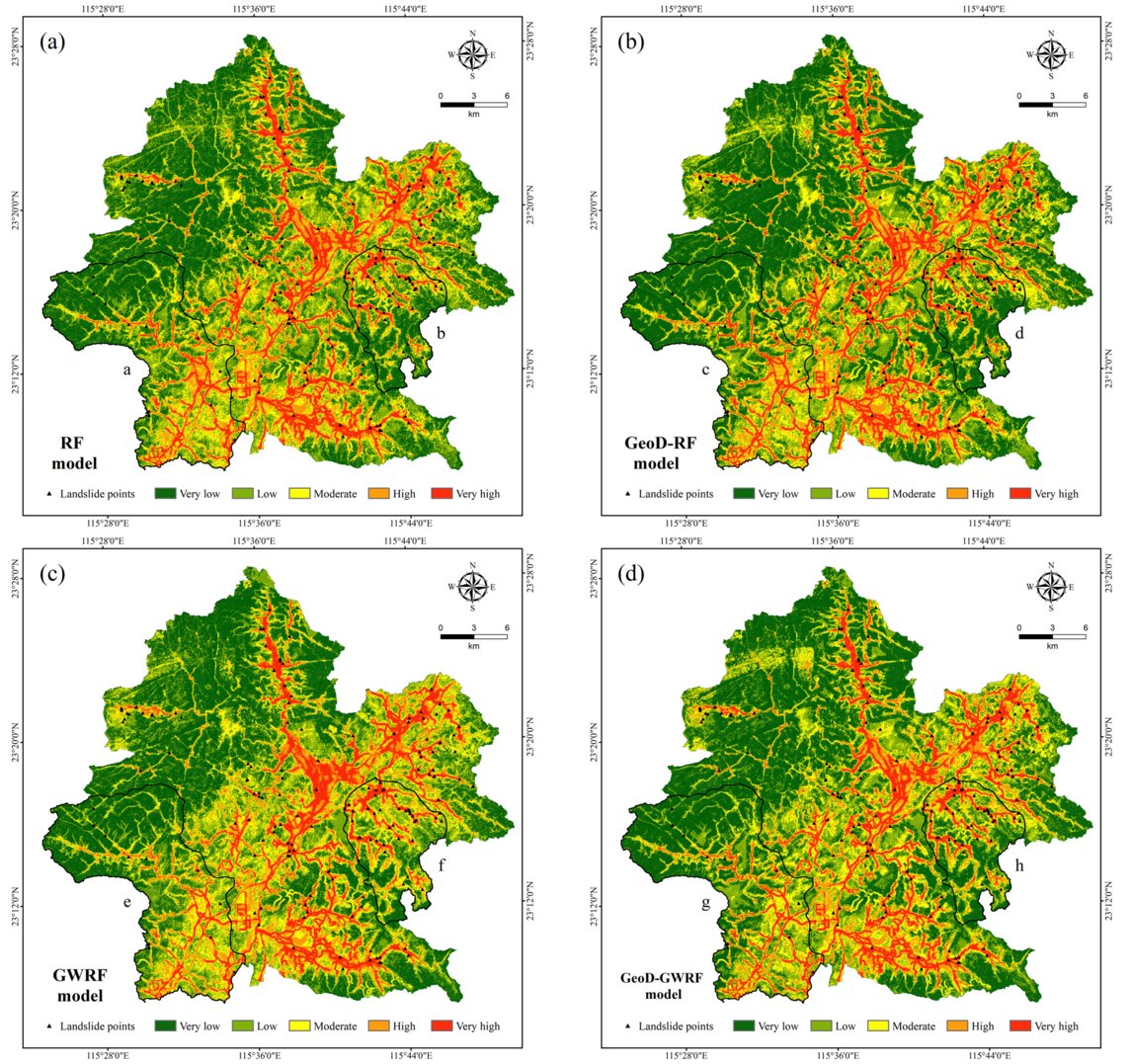
👋👋 Geographically Weighted #RandomForest Based on #Spatial #Factor Optimization for the Assessment of #Landslide Susceptibility
✍️ Feifan Lu et al.
🔗 brnw.ch/21x1kDH
1
5
16
559

Apr 2
[2] Hitos importantes:
⚙️Desarrollo de un flujo de trabajo reproducible (1985–2024) utilizando el algoritmo #RandomForest.
📊Análisis con alta precisión (>80%) de la relación entre la variabilidad hidrológica y los cambios geomorfológicos en entornos tropicales. 🛰️ #EarthScience

1
3
39


I tested 5 ML models, 4 of them burn money, 1 makes $340/day
in-sample accuracy: 0.6–0.8
out-of-sample accuracy: 0.4–0.6
94% of quant bots fail not because the strategy is wrong
because the backtest lied
what happened:
DecisionTree in-sample: 0.79 → out-of-sample: 0.51
that's a coin flip
RandomForest in-sample: 0.74 → out-of-sample: 0.54
still losing money after fees
the only model that held up:
LogisticRegression 0.63 → 0.59
lower ceiling. higher floor.
that's the trade-off nobody talks about
the fastest way to copy-trade anyone: kreo.app/@0xricker
how to avoid it:
1. walk-forward testing - never optimize on the same data
2. keep it simple - complexity is the enemy
3. if in-sample > out-of-sample by 15% - throw it out
the bots that survive don't have the highest backtest accuracy
they have the smallest gap between in-sample and out-of-sample
that gap is the only number that matters
9
33
1,336