
Jun 12
By combining #Ontology with a high-performance graph database, a leading social platform moved beyond generic "edges" to typed, weighted relationships. 💡
🔗 Relationship semantics are the future of #RecommendationSystem:
na2.hubs.ly/H064FG_0
#NebulaGraph #KnowledgeGraph
38
2,084

May 15
High-Level Summary of X’s For You Algorithm (Core Design – Mostly Unchanged)
Core Idea
X builds the For You feed by mixing:
Posts from accounts you follow (In-Network)
High-quality posts from accounts you don’t follow (Out-of-Network)
Then uses AI to rank everything and show you what you’re most likely to engage with.
Main Components
Home Mixer: Central orchestrator that manages the entire pipeline (hydration, retrieval, filtering, scoring, blending, etc.).
Thunder: In-Network source — fetches recent posts from people you follow (near real-time).
Phoenix Retrieval: Out-of-Network source — ML-powered search that finds thousands of relevant candidates across the entire X corpus (billions of posts).
Phoenix Scorer: Transformer model based on Grok architecture — predicts the probability you will Like, Reply, Repost, Click, etc. for each candidate.
Key Characteristics
Minimal hand-crafted rules: Very few traditional heuristics or engineered features.
Almost everything is driven by the learned model based on your real behavior (past interactions, follows, topics, etc.).
Result: Highly personalized feed that favors engagement and relevance over pure chronology.
In short: Thunder supplies familiar content Phoenix finds fresh interesting content → Grok-style model scores everything → Home Mixer assembles the final feed.
This high-level architecture remains stable. Recent updates mainly improve usability, add safety (Grox), and enhance ads blending.
#XAlgorithm #ForYouFeed #GrokAI #PhoenixModel #OpenSource #xAI #TwitterAlgorithm #RecommendationSystem

The latest 𝕏 algorithm has been published to GitHub
github.com/xai-org/x-algorit…
2
4
150

May 14
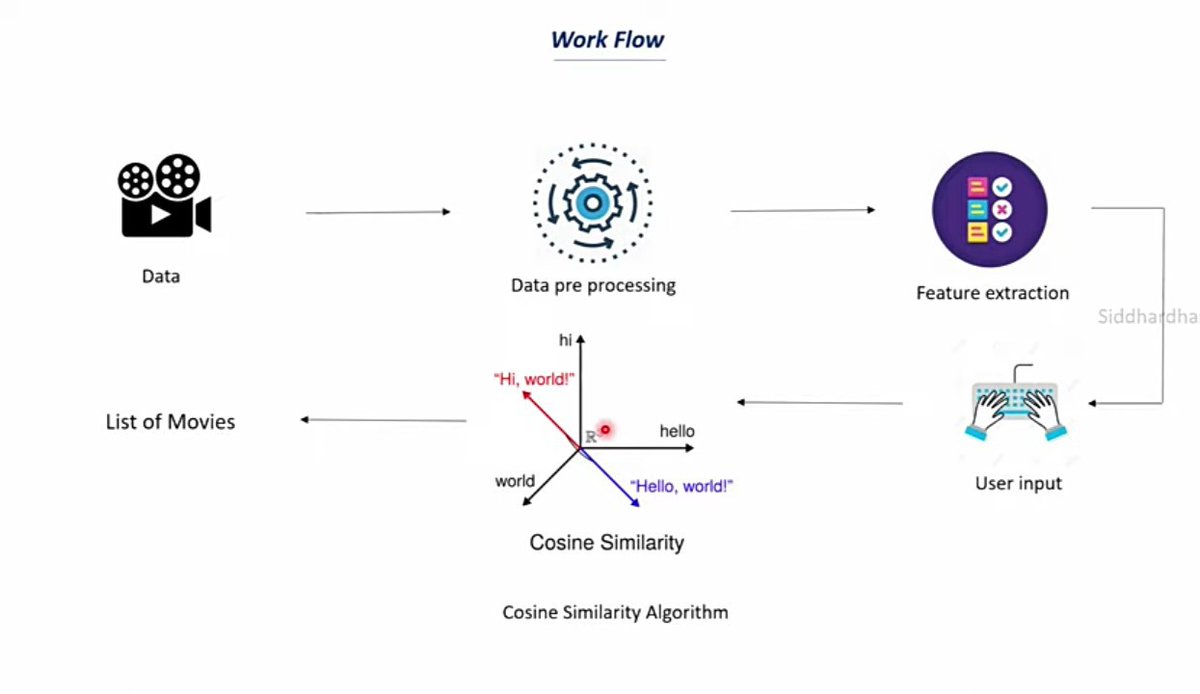
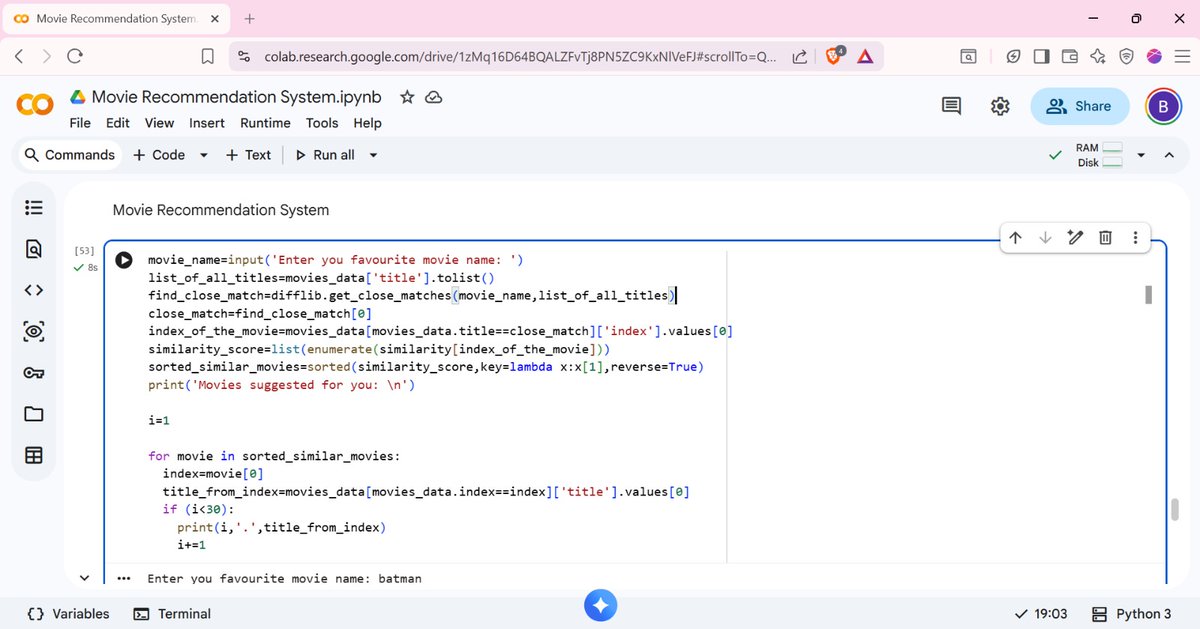
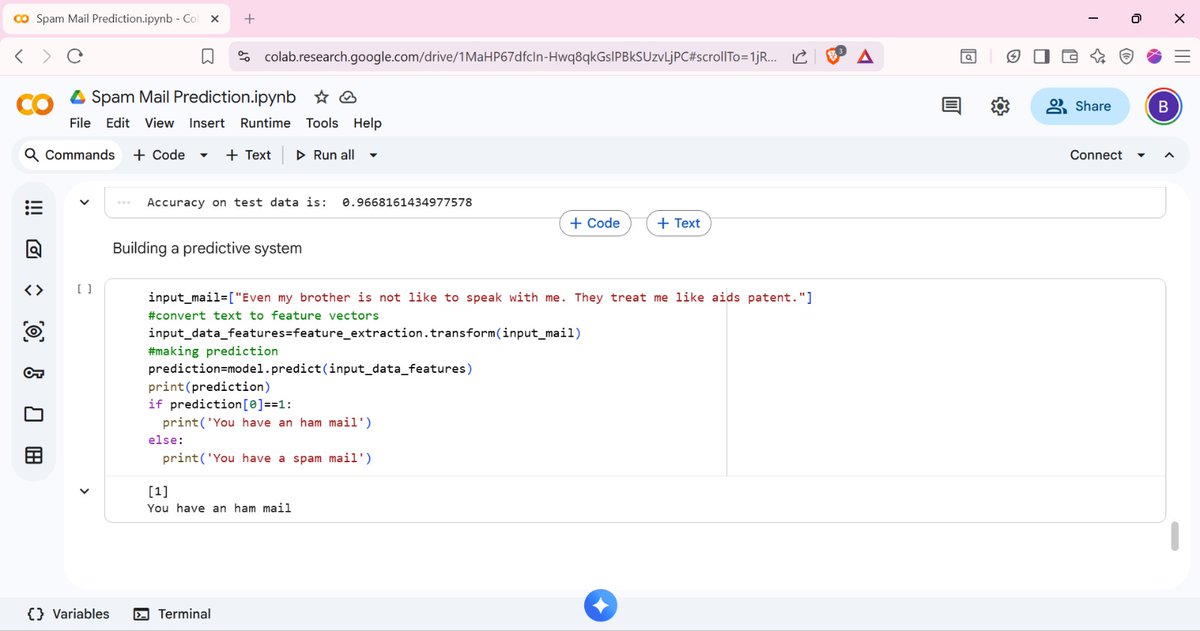
I built my own Movie Recommendation System.
You know how Netflix always seems to know what you want to watch next? I decided to build the engine behind that idea from scratch.
#MachineLearning #RecommendationSystem #Python #NLP #TFidf #CosineSimilarity #DataScience

2
63

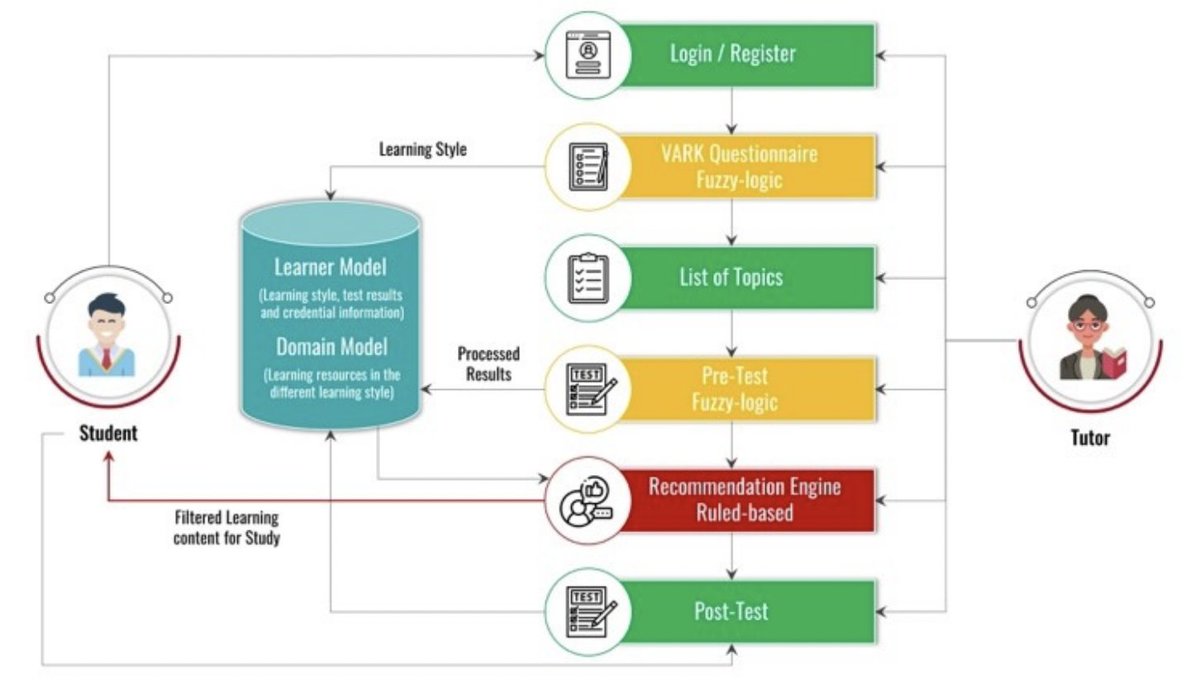
Evaluating the effectiveness of an adaptive e-learning system that uses the #VARK learning model and a #recommendationsystem: “A VARK learning style-based Recommendation system for Adaptive E-learning” by F. Abomelha, P. Newbury. ACSIS Vol. 41 p. 1–8; tinyurl.com/y9ayytjd
1
3
4
100

Mar 26
📢 #highlycited paper
📚 Enhancing Sequence Movie #RecommendationSystem Using #DeepLearning and KMeans
🔗 mdpi.com/2076-3417/14/6/2505
👨🔬 by Sophort Siet et al.
🏫 Soonchunhyang University
#collaborativefiltering #transformerarchitecture

1
2
51

Feb 18
YouTube ठप होने से यूजर्स परेशान, रिकमेंडेशन सिस्टम में गड़बड़ी के बाद सेवा बहाल
#Newstrack #YouTubeDown #YouTube #TechNews #BreakingNews #YouTubeUpdate #RecommendationSystem #YouTubeApp #YouTubeMusic #YouTubeKids #SocialMediaNews #DigitalNews #TrendingNow

1
4
98

Feb 15
I built a smart product recommendation system for an e-commerce page 🛒
No tags. No manual mapping.
Just product data → vectors → similarity → suggestions.
How it works:
• Convert product text into embeddings (NLP)
• Compute cosine similarity
• Show the most related items instantly on the product page
Result: users discover products instead of searching for them.
Turning a normal store into a smart store.
#BuildInPublic #MachineLearning #NLP #RecommendationSystem #FullStack #Nextjs
3
4
171

Feb 5
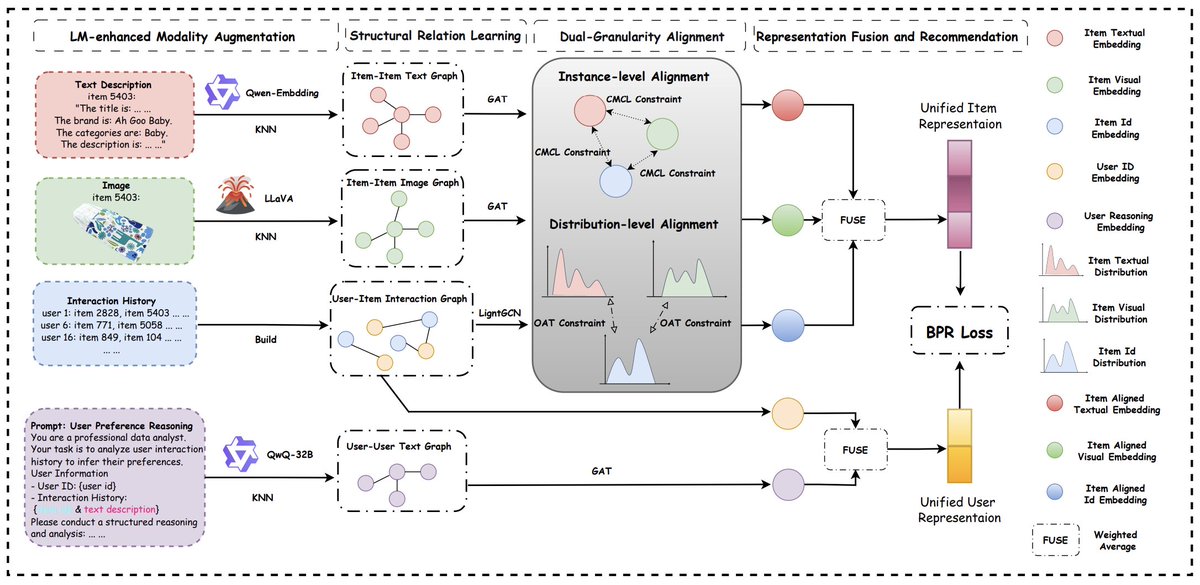
Excited to share my first work RecGOAT at Kuaishou! 🎉
We’re bridging LLMs and Recommender Systems in a smarter way with 🐐"RecGOAT: Graph Optimal Adaptive Transport for LLM-Enhanced Multimodal Recommendation with Dual Semantic Alignment."
RecGOAT introduces a dual-granularity progressive multimodality-ID alignment framework, achieving:
✨ Instance-level alignment via cross-modal contrastive learning
✨ Distribution-level alignment via optimal adaptive transport
Check out the paper, code, and Huggingface post below! 👇
📄 Paper: arxiv.org/abs/2602.00682
💻 Code: github.com/6lyc/RecGOAT-LLM4…
🤗 Huggingface: huggingface.co/papers/2602.0…
We welcome citations, stars, upvotes, and collaborations! Let's chat if you’re into LLM RecSys research! 💬
#AI #RecommendationSystem #LLM #Multimodal #LLM4Rec
1
1
2
345

26 Dec 2025
Learned how to build a recommendation system and apply first principles thinking to problem-solving today.
Breaking complex systems down to their fundamentals really changes how you design solutions.
@rohit_negi9
#RecommendationSystem #FirstPrinciples #STRIKE #LearningInPublic
1
1
15
430

AI in education requires distinguishing between consumer attention-stealing uses (e.g., #recommendationsystem) and creative uses of AI that support critical thinking and collaborative problem-solving, among other #5c21 skills. 👉 #ppai6

7 Dec 2025

The technology is changing how children play, how they are supervised and with whom—or what—they share confidences and form friendships. Regulators are gearing up to protect youngsters economist.com/briefing/2025/…
2
4
282

27 Oct 2025
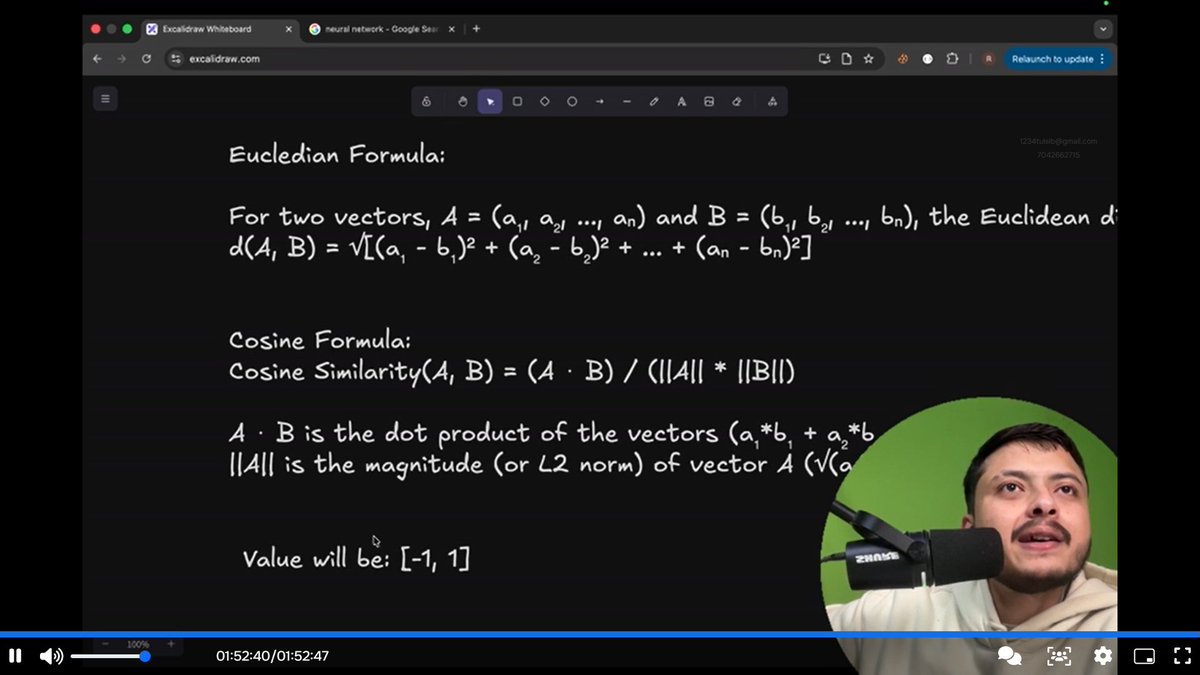
Ever wondered how
Netflix 🎬 or Spotify 🎧 seem to magically know what you’ll like next?
It’s all math behind the scenes
vectors, dot products & cosine similarity.
Let’s break it down in simple terms
🧵
#BuildInPublic #machinelearningengineer
#RecommendationSystem
1
3
83

19 Jun 2025
Human Curation Beats AI ft. Medium CEO Tony Stubblebine
#AlgorithmUpdate #AIContent #HumanCuration #ContentQuality #ExpertiseMatters #Clickbait #ContentMill #RecommendationSystem #ThoughtfulContent #OnlineWriting
2
2
230

2 Jun 2025
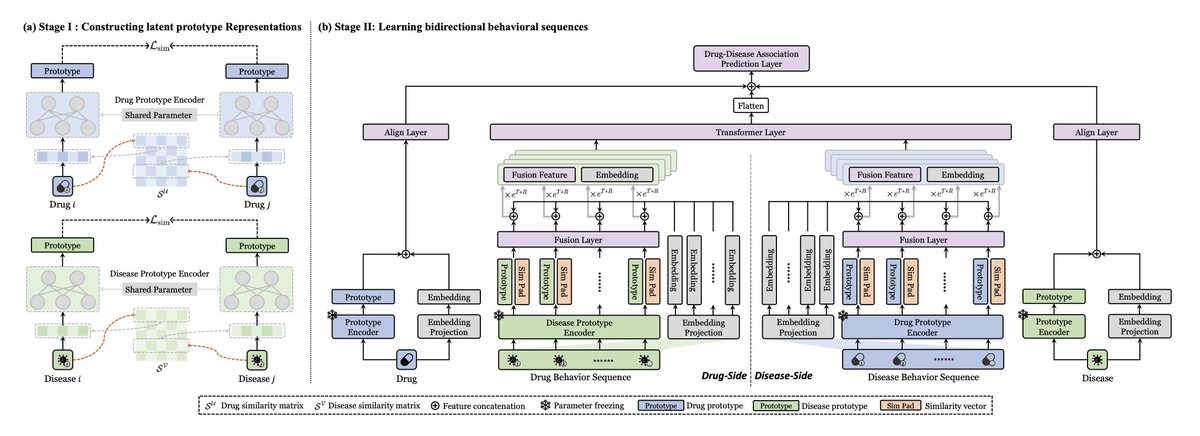
BiBLDR: Bidirectional Behavior Learning for Drug Repositioning
1.BiBLDR reframes drug repositioning as a behavioral sequence prediction task, inspired by recommendation systems. Instead of modeling associations via graphs, it learns from interaction patterns between drugs and diseases, enabling stronger generalization—especially for new drugs.
2.The method constructs bidirectional behavioral sequences, representing both drug-to-disease and disease-to-drug associations. This dual perspective captures more complete interaction signals than unidirectional models.
3.BiBLDR is the first to apply Transformer architecture to drug repositioning using behavior sequences. The model leverages multi-head self-attention to extract complex semantic patterns in both drug and disease behavioral contexts.
4.A two-stage learning strategy is proposed: • Stage I builds latent prototype spaces for drugs and diseases using similarity data and Siamese networks. • Stage II uses these prototypes, enriched with explicit similarity information, as input to the Transformer to predict associations.
5.Similarity fusion plays a central role. BiBLDR integrates numerical similarity values directly into prototype features within behavioral sequences, enhancing contrast between similar and dissimilar entities.
6.The model introduces a logarithmic weighting scheme in behavioral sequences to emphasize positive associations during training, aiding contrastive learning and mitigating sparsity.
7.BiBLDR demonstrates state-of-the-art performance on three benchmark datasets (Gdataset, Cdataset, LRSSL), outperforming both classical and deep learning methods, including GCN-based approaches, in AUROC and AUPRC.
8.In cold-start scenarios, where novel drugs have no known associations, BiBLDR outperforms existing methods with a large margin (e.g., AUPRC of 0.6194 vs 0.3484), validating its ability to generalize beyond observed data.
9.BiBLDR maintains robustness under extreme data sparsity, thanks to the independent prototype construction stage, which does not rely on the association matrix’s density.
10.Ablation studies confirm the value of each design component: bidirectional modeling, prototype spaces, similarity fusion, and Transformer layers all significantly contribute to performance.
11.In real-world case studies on lung cancer and hypertension, BiBLDR achieved high hit rates (80%–90%) in top-ranked predictions. For unverified predictions, molecular docking experiments confirmed strong binding affinities.
12.In conclusion, BiBLDR offers a novel and effective direction for drug repositioning research, combining strengths of recommender systems, prototype learning, and attention-based modeling.
💻Code: github.com/Renyeeah/BiBLDR
📜Paper: arxiv.org/abs/2505.23861v1
#DrugRepositioning #Transformer #DeepLearning #BiomedicalAI #RecommendationSystem
3
9
998
2 Jun 2025
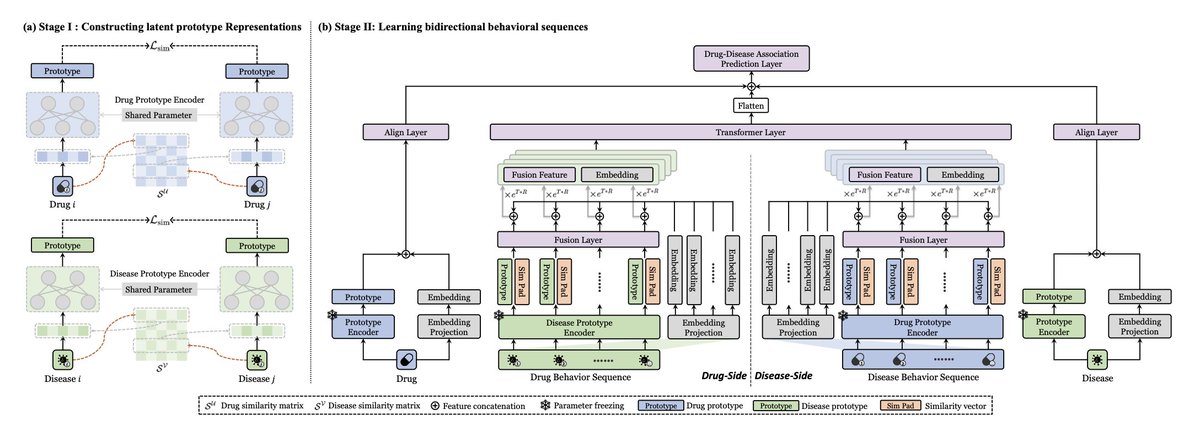
BiBLDR: Bidirectional Behavior Learning for Drug Repositioning
1.BiBLDR reframes drug repositioning as a behavioral sequence prediction task, inspired by recommendation systems. Instead of modeling associations via graphs, it learns from interaction patterns between drugs and diseases, enabling stronger generalization—especially for new drugs.
2.The method constructs bidirectional behavioral sequences, representing both drug-to-disease and disease-to-drug associations. This dual perspective captures more complete interaction signals than unidirectional models.
3.BiBLDR is the first to apply Transformer architecture to drug repositioning using behavior sequences. The model leverages multi-head self-attention to extract complex semantic patterns in both drug and disease behavioral contexts.
4.A two-stage learning strategy is proposed:
• Stage I builds latent prototype spaces for drugs and diseases using similarity data and Siamese networks.
• Stage II uses these prototypes, enriched with explicit similarity information, as input to the Transformer to predict associations.
5.Similarity fusion plays a central role. BiBLDR integrates numerical similarity values directly into prototype features within behavioral sequences, enhancing contrast between similar and dissimilar entities.
6.The model introduces a logarithmic weighting scheme in behavioral sequences to emphasize positive associations during training, aiding contrastive learning and mitigating sparsity.
7.BiBLDR demonstrates state-of-the-art performance on three benchmark datasets (Gdataset, Cdataset, LRSSL), outperforming both classical and deep learning methods, including GCN-based approaches, in AUROC and AUPRC.
8.In cold-start scenarios, where novel drugs have no known associations, BiBLDR outperforms existing methods with a large margin (e.g., AUPRC of 0.6194 vs 0.3484), validating its ability to generalize beyond observed data.
9.BiBLDR maintains robustness under extreme data sparsity, thanks to the independent prototype construction stage, which does not rely on the association matrix’s density.
10.Ablation studies confirm the value of each design component: bidirectional modeling, prototype spaces, similarity fusion, and Transformer layers all significantly contribute to performance.
11.In real-world case studies on lung cancer and hypertension, BiBLDR achieved high hit rates (80%–90%) in top-ranked predictions. For unverified predictions, molecular docking experiments confirmed strong binding affinities.
12.In conclusion, BiBLDR offers a novel and effective direction for drug repositioning research, combining strengths of recommender systems, prototype learning, and attention-based modeling.
💻Code: github.com/Renyeeah/BiBLDR
📜Paper: arxiv.org/abs/2505.23861v1
#DrugRepositioning #Transformer #DeepLearning #BiomedicalAI #RecommendationSystem
1
622

1 Jun 2025
How Shorts & Reels recommendation algorithms work explained in the simplest way. 🔥
#Algorithm #RecommendationSystem #TEDTalk #AI #KnowledgeIsPower
6
256
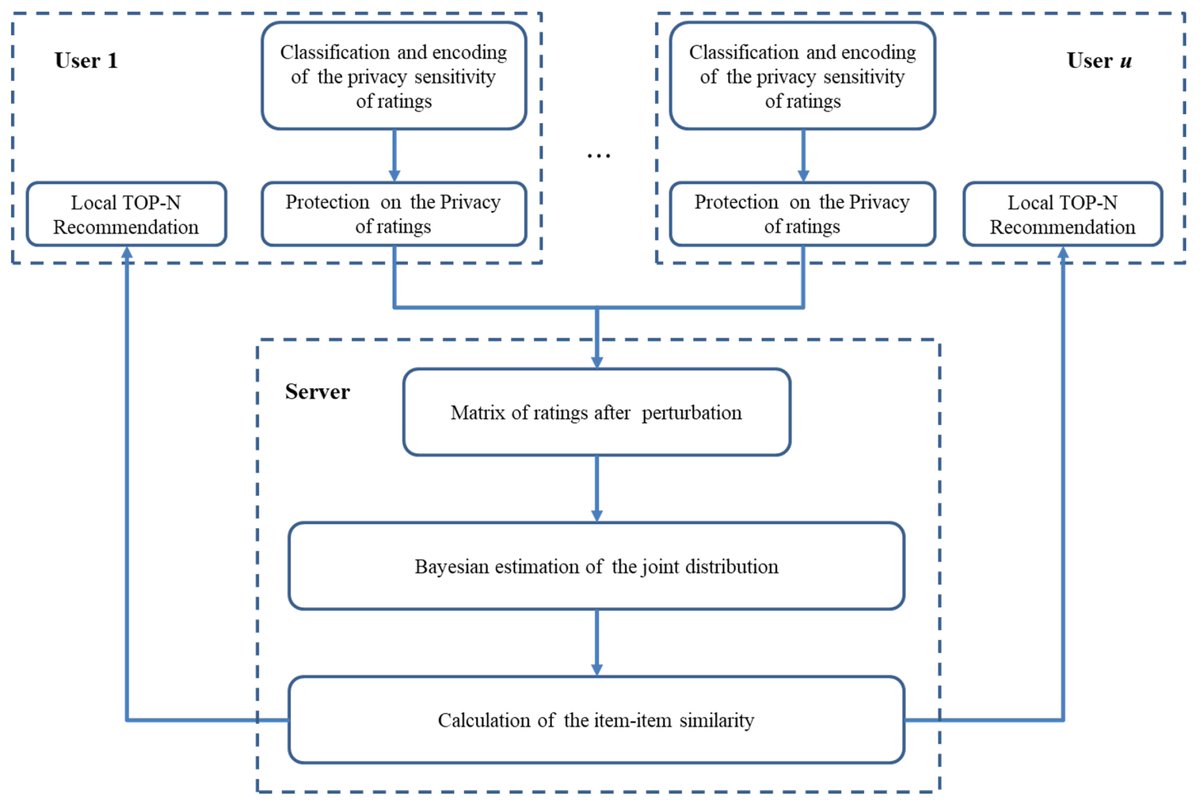
6 Mar 2025
🔥 Read our Paper
📚 Personalized Privacy Protection-Preserving Collaborative Filtering Algorithm for Recommendation Systems
🔗 mdpi.com/2076-3417/13/7/4600
👨🔬 by Dr. Bin Cheng et al.
🏫 Academy of Military Sciences / @BIT1940
#PrivacyProtection #recommendationsystem
2
59

3 Mar 2025
🗓️ 𝐃𝐚𝐲-68 𝐏𝐫𝐨𝐠𝐫𝐞𝐬𝐬 🚀
DSA Github: github.com/lokeshchoudharypr…
Development Github : github.com/lokeshchoudharypr…
#Day68 #Development #DSA #LeetCode #MergeSort #OpenAPI #RecommendationSystem #APIDesign 🚀
2
40
2 Mar 2025
🗓️ 𝐃𝐚𝐲-67 𝐃𝐞𝐯𝐞𝐥𝐨𝐩𝐦𝐞𝐧𝐭 𝐉𝐨𝐮𝐫𝐧𝐞𝐲 🚀
github:github.com/lokeshchoudharypr…
#Day67 #Development #DSA #LeetCode #RecommendationSystem #AI #FrontendInterview #ImageProcessing 🚀
2
36
2 Mar 2025
🗓️ 𝐃𝐚𝐲-67 𝐃𝐒𝐀 𝐉𝐨𝐮𝐫𝐧𝐞𝐲 🚀
#Day67 #Development #DSA #LeetCode #AI #RecommendationSystem #Frontend #ImageProcessing 🚀
Github: github.com/lokeshchoudharypr…

2
31

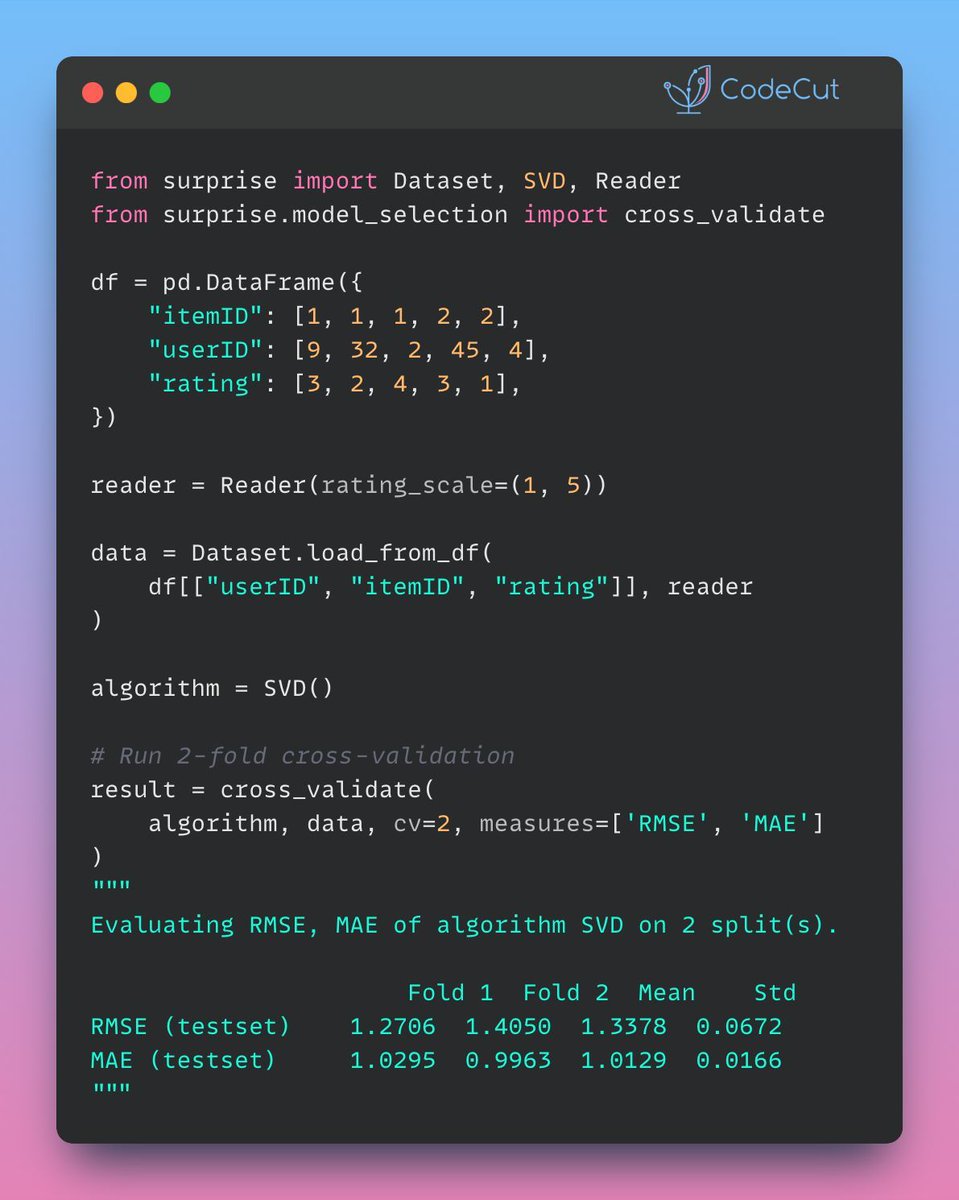
5 Feb 2025
Building a reliable #RecommendationSystem from scratch can be time-consuming and requires a lot of code for #Algorithms and validation.
Surprise simplifies the process with minimal code by providing built-in algorithms, easy #Dataset handling, and simple model evaluation.
1
3
31
954