
Chinese 🇨🇳 APT group UNC6508 conducted a 26-month espionage campaign against US 🇺🇸 medical research, academic, and military health institutions, remaining undetected for over a year. The operation combined a REDCap-specific custom implant with a novel Google Workspace email exfiltration technique never previously observed in PRC-nexus actors.
Key technical details:
- INFINITERED malware: 3-part modular implant (dropper, credential harvester, backdoor) injected into REDCap's upgrade pipeline, ensuring persistence across software updates. Backdoor activates via HTTP cookie parameter "REDCAP-TOKEN" and beacons OS, PHP version, DB credentials to attacker C2.
- Credential harvester injects into REDCap's auth file, captures POST-submitted logins, encrypts them, and hides them in a legitimate DB table prefixed with string "xc32038474a".
- Web shell deployed as help[.]php for persistent server access post-initial compromise.
- Attack chain: REDCap legacy version probe, initial compromise Sept. 2023, web shell deployment, credential harvesting over 12 months, then domain admin account takeover.
- Novel TTP: Google Workspace content compliance rule named "Patroit" silently BCC-forwarded keyword-matched emails to BebitaBarefoot774@gmail[.]com. Regex-based, org-wide by default, zero endpoint malware required post-setup.
#DFIR_Radar

1
20

🚨 Hot Take:
If you're still using grep for JSON, large codebases, and complex regex...
You're making life harder than it needs to be.
These 4 tools can save hours every week.
The fastest hackers and engineers optimize their workflow first.
Save this one.
#Linux #Developer

4

Dead-end injection points aren't dead ends if you know where to look.
In our latest Exploits Explained, Synack Red Team researcher @ozgur_bbh walks through a fully blind SQL injection buried inside a PostgreSQL ORDER BY clause, where boolean chaining, time-based techniques, and UNION attacks were all off the table.
His solution? Recognize that regex functions trigger errors PostgreSQL doesn't catch during query planning, isolate them inside a subquery so they only fire on the false branch of a CASE statement, and use the error/success difference as a boolean oracle to extract data character by character.
Check out the full post to learn more 👉 synack.com/exploits-explaine…

6
199

Caido v0.57.0 is out. 🎉
The headliners:
- WebSocket in Replay: send WS messages straight from the Replay page.
- Custom Extractors in Automate: pull a regex match into its own results column.
- StreamQL: filter WS messages in WS History.
Plus QoL: Match & Replace now works on WebSockets, filters can go Global across projects, and a new Logging node in Workflows debugs fields without a JS node.
Full Changelog → caido.io/blog/2026-06-05-rel…
Download Now → caido.io/download

3
170
旭熙♡ retweeted

Just nailed my first Python regex practice! Spent 30 mins cracking the data extraction task—small win, big motivation for today’s coding learning.

2
7
DarkSeraph retweeted

API Hacking has never been so easy ... AND free!
github.com/The-XSS-Rat/hackx…
Hackxpert brute has all, and regex scans your responses for exploit patterns - grab your copy now before it sells ou- ... oh right it is FREE!! :D
2
6
445

bir iş için operatörlüğünü yaptığım program ilgili satırları yakalayamıyordu. IT'ciyle takışırken regex kodunu atıp git şu siteden istediğin şekilde düzenle ver demişti en sonunda haahahha
1
1
20

Yeah, we’re in early stages of AI capabilities. Fable’s a toy compared to where AI models are headed. The govt should be paying attention. Hinton said ASI should be illegal. The idea that humans will contain it with some regex guardrails isn’t logical. We’re rapidly approaching a tipping point.
12

reddit.com/r/pihole/comments…
Senin söylediğinin teorik olarak imkanı şu an yok
Regex de yazsan domainleri tek tek milyon tane domain eklesen de kurallara benzersiz sayı ve rakamlarla linkler gelecektir
*youtube.com veya youtube.com/ads olsa dediğin haklı tamamen siteyi engelleyebilirsin ama site içerisindeki reklamları engelleyemezsin bunu şu an kimse yapamaz pi hole forumlarını oku istersen

3
Regex kurallarını sana yollayayım istiyorsan:)
youtube.com reklamları için bana regex kurallarını at bakalım
Sadece kendi oluşturduğum 400'ünden fazla regex kuralı var
Buna rağmen youtubeyi yine engeleyemezsin
At kendi kurallarını pi hole sunucuma yükleyeyim
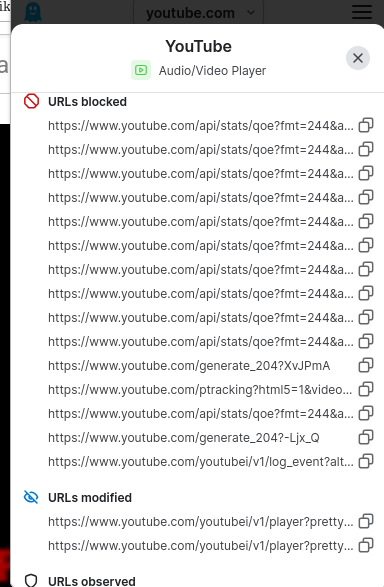
youtube.com/api/stats/qoe?fm…
sadece bir tane istek bu bunun gibi 600 tane istek için nasıl bir regex kuralı yazabilirsin ?
Kardeşim bunu daha başarabilen biri yok ne github üzerinde ne reddit üzerinde ne diğer geliştiriciler o yüzden Pi-hole tarayıcı eklentisi veya patchlenmiş uygulama başka bir yöntemi yolu asla yok şu an böyle



2h
50 Websites that feel illegal to know:
DOWNLOADS & MEDIA
1. cobalt.tools — download any video from socials
2. photopea.com — Photoshop but completely free
3. temp-mail.org — disposable email in one click
4. tinywow.com — 100 free tools in one site
5. archive.org — access any old webpage ever
6. libgen.li — millions of free textbooks
7. sci-hub.al — free research papers
8. alternativeto.net — find free app alternatives
9. justwatch.com — find where to stream anything
10. gutenberg.org — 70K free classic books
RESEARCH & LEARNING
11. pdfdrive.com — free PDF downloads
12. openculture.com — free courses from top unis
13. wolframalpha.com — solve any math instantly
14. remove.bg — remove backgrounds in one click
15. cleanup.pictures — erase objects from photos
16. unscreen.com — remove video backgrounds free
17. squoosh.app — compress any image free
18. excalidraw.com — hand draw diagrams free
19. carbon.now.sh — turn code into beautiful art
20. ray.so — stunning code screenshots
TRAVEL, SHOPPING & SAFETY
21. flightradar24.com — track any flight in real time
22. camelcamelcamel.com — track Amazon price history
23. haveibeenpwned.com — check if you were hacked
24. virustotal.com — scan any file for malware
25. privnote.com — send self destructing messages
26. file.io — share files that auto delete
27. archive.ph — save any webpage forever
28. accountkiller.com — delete yourself from any site
29. radio.garden — listen to any radio worldwide
30. tunefind.com — find songs from any show
ENTERTAINMENT & DISCOVERY
31. musicforprogramming.net — music to focus with
32. mynoise.net — custom focus soundscapes
33. annasarchive.org — search every book ever written
34. elicit.com — AI research paper assistant
35. consensus.app — search what science agrees on
36. connectedpapers.com — map research visually
37. semanticscholar.org — free academic search
38. scispace.com — understand any research paper
39. summarize.tech — summarize any YouTube video
40. phind.com — AI search for developers
DEVELOPER & PRODUCTIVITY
41. regex101.com — test any regex instantly
42. codebeautify.org — format any code cleanly
43. explainshell.com — understand terminal commands
44. tldraw.com — infinite whiteboard in browser
45. downdetector.com — check if any site is down
46. tineye.com — reverse image search
47. fast.com — check your internet speed
48. smallpdf.com — edit PDFs free
49. ilovepdf.com — merge and split PDFs
50. 10minutemail.com — temp email in seconds
Follow me @Sia_TechAi for more AI IDEA.

4
7
13
169

Bookmarked:
Most local AI users never touch the engine underneath Ollama.
llama.cpp exposes six families of knobs you cannot reach through a wrapper.
The useful one is structured output: feed it a GBNF grammar or JSON schema, and the model physically cannot output invalid JSON. No regex retries.
Another is the ngl flag. It offloads layers to GPU. You can run a 70B model on an 8GB card by keeping most layers on CPU.
That hybrid trick alone makes direct llama.cpp worth learning.
youtube.com/watch?v=DadmyNgM…
#video #ai
1
66

🦅 Claude-OSINT: Give Claude 90 Recon Capabilities and Turn It Into an OSINT Operator
A powerful collection of Claude skills designed for authorized red-team, ASM, and bug bounty reconnaissance.
What's inside?
🔹 90 Recon Modules
🔹 48 Secret Detection Regex Patterns
🔹 80 Google Dorks
🔹 9 Read-Only Credential Validators
🔹 27 Attack Path Templates
🔹 4,600 Lines of Structured OSINT Tradecraft
Covers:
✅ Asset Discovery
✅ Cloud & Kubernetes Recon
✅ Secret Hunting
✅ Identity & SSO Mapping
✅ Email Security Analysis
✅ Vendor Fingerprinting
✅ Supply Chain Intelligence
✅ Bug Bounty Reporting
🔗 github.com/elementalsouls/Cl…
#OSINT #ThreatIntelligence #CyberSecurity #BugBounty #RedTeam #ClaudeAI #Recon #InfoSec

7
19
508

same! fastest way to skip it that i found was using `browser.declarativeNetRequest.onRuleMatchedDebug`
and this ungodly regex: ^https?:\/\/(?:[a-z0-9-] \.)*google(?:\.[a-z]{2,}){1,}\/url\?(?:[^&]*&)*(?:url|q)=<target> with browser.declarativeNetRequest.updateDynamicRules
1
1
2

3h
Guys, I ended up using a hybrid parser:
local regex parser first, then CommandCode LLM function/tool calling as fallback.
The LLM does not query the DB directly.
It produces structured filters through tool calling, then my backend searches pets with normal TypeORM database queries plus haversine distance filtering.
Jun 15

Need help!
Let’s say I have DB of 10k pets, in different states and different types.
My app users want a feature where instead of manually adding search filters they just want to do a prompt like “Give me brown huskies in Texas not more than 2 years old” and get the results.
I know ChatGPT API key can do it but what are my most cost effective and practical options?
8


Regex match counting tip: the “obvious” way most .NET devs do it is slower and allocates memory it doesn’t need to.
There’s a cleaner, faster approach hiding in plain sight.
Benchmarks don’t lie. Your hot paths will thank you.
#dotnet10 #MVPBuzz
dotnettips.wordpress.com/202…

22

📌 개발자 "가장 빨리" 취업하는 법 정리 ( 깃허브 AI로 꾸밀 때 함정, 수치까지)
리퍼럴(referral, 사내 추천 = 내부 직원이 당신을 찍어 추천) : 미국 기준 전체 채용의 30~50%가 추천으로 채워짐 (지원서 중 추천 비율은 6~7%인데 채용의 30~40%를 먹음)
추천의 진짜 힘 : 추천 후보는 일반 지원자보다 약 5배 더 뽑힘, 채용 속도도 빨라짐 (추천 약 29일 vs 일반 약 39일)
코딩 테스트(coding test, 알고리즘 1차 관문) : 대기업 기술 채용의 거의 필수 통과 의례
깃허브 AI 꾸미기 함정 : "이 코드 뭐 하는 거예요?"에 못 답하면 면접에서 바로 들통남
핵심 반전 : 빠른 취업은 스펙 추가가 아니라 "뽑는 사람의 리스크를 줄여주는 것"
💬 개발자로 가장 빨리 취업하는 길은 스펙 한 줄 더 늘리는 게 아니라 리퍼럴을 뚫는 거다.
왜냐하면 숫자가 이미 말해준다 — 지원서 중 추천은 6~7%뿐인데 실제 채용의 30~40%를 차지하고, 추천 후보는 일반 지원자보다 약 5배 더 뽑힌다(출처마다 편차 있음). 면접관 입장에선 "검증된 사람"이라 안전한 카드거든 (면접관도 미스 채용 책임지기 싫은 월급쟁이다).
그래서 순서는 1) 안에서 추천해줄 사람 만들기 2) 코딩 테스트 감각 3) 깃허브에 "끝까지 굴러가는" 프로젝트 & 이 셋이 겹치면 속도가 확 붙는다.
근데 요즘 깃허브를 AI로 후딱 꾸미는데 주의 — 1) 잔디(커밋 그래프) 자동 채우기는 면접관도 다 안다 2) 내가 못 읽는 AI 코드는 "여기 왜 regex 썼어요?" 한 방에 무너진다(실제로 Canva, Meta 면접은 생성 코드마다 "이거 뭐 하는 거냐"를 묻는다고 한다) 3) AI로 찍어낸 프로젝트는 죄다 비슷해서 차별화가 안 된다 (남들도 똑같은 투두앱).
반면에 AI를 "도구"로 쓰고 결과를 내가 완전히 이해하면 오히려 가산점일 수도 있다 — 들키는 건 AI 사용 자체가 아니라 "이해 없는 사용"이니까. 명언처럼 설명 못 하면 소유한 게 아니다.
안 믿겨도 괜찮다. 출처 셋 다 열어보면 된다. → 추천이 채용의 30~40%인 근거: 리퍼럴 통계 → 면접관이 AI 코드를 어떻게 잡는지: 기술 면접 AI 탐지 가이드 → 추천보다 강한 증거 만들기: 깃허브 공식 문서
#개발자취업 #코딩테스트 #깃허브
🔗 출처:
Employee Referral Statistics — zippia.com/advice/employee-r…
How to Detect AI Use in Technical Interviews (Karat) — karat.com/detect-ai-use-tech…
GitHub Docs — docs.github.com/
2
63

Three things I believe about AI gateways in 2026:
1 - if your gateway doesn't know whether the response was hallucinated, it's a load balancer with a billing dashboard.
2 - guardrails built on regex are a 2023 idea. The actual primitives now are extraction pipelines, classifier calls, and grounded eval scores. If your "PII detection" is a list of patterns, you're protecting against the 2019 attacker.
3 - the gateway, the eval engine, and the agent runtime want to be the same system. Not three vendors with REST APIs to each other. Same trace. Same context. Same decision graph.
Building toward that with Agent Command Center. Apache 2.0, Go-based, Anthropic, OpenAI-compatible. The repo is the argument; the link- github.com/future-agi/future…
Tell me which of the three I have wrong.
1
2
21